文章目录
- 一、摘要
- 二、问题
- 三、Method
-
- [3.1 Latent Diffusion Model](#3.1 Latent Diffusion Model)
- [3.2 Motion-guided Diffusion Sampling](#3.2 Motion-guided Diffusion Sampling)
- [3.3 Temporal-aware Decoder Fine-tuning](#3.3 Temporal-aware Decoder Fine-tuning)
- 四、实验设置
-
- [4.1 训练阶段](#4.1 训练阶段)
- [4.2 训练数据](#4.2 训练数据)
- 贡献总结
论文全称: Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution
代码路径: https://github.com/IanYeung/MGLD-VSR
更多RealWolrd VSR整理在 https://github.com/qianx77/Video_Super_Resolution_Ref
一、摘要
现实世界中的低分辨率(LR)视频存在多样化和复杂的退化现象,这对视频超分辨率(VSR)算法在高质量地再现其高分辨率(HR)对应物时提出了巨大的挑战。最近,扩散模型在图像还原任务中展现出了令人信服的生成真实细节的性能。然而,扩散过程具有随机性,使得控制还原图像内容变得困难。当将扩散模型应用于视频超分辨率(VSR)任务时,这个问题变得更加严重,因为时间一致性对视频的感知质量至关重要。
在本文中,我们通过利用预训练的潜在扩散模型的优势,提出了一种有效的实际应用视频超分辨率算法。为了确保相邻帧之间内容的一致性,我们利用低分辨率视频中的时间动态,通过优化潜在采样路径并引入运动引导损失,来指导扩散过程,从而确保生成的高分辨率视频保持一致且连续的视觉流。为了进一步减轻生成细节的间断性,我们在解码器中插入了时间模块,并使用一种创新的序列导向损失对其进行微调。所提出的基于运动引导潜在扩散(MGLD)的超分辨率算法在真实世界的超分辨率基准数据集上实现了显著优于现有技术的感知质量,验证了所提模型设计和训练策略的有效性。代码和模型可在 https://github.com/IanYeung/MGLD-VSR 获取。
二、问题
1、CNN Transformer架构表现不好
2、diffusion模型时序细节稳定性差
三、Method
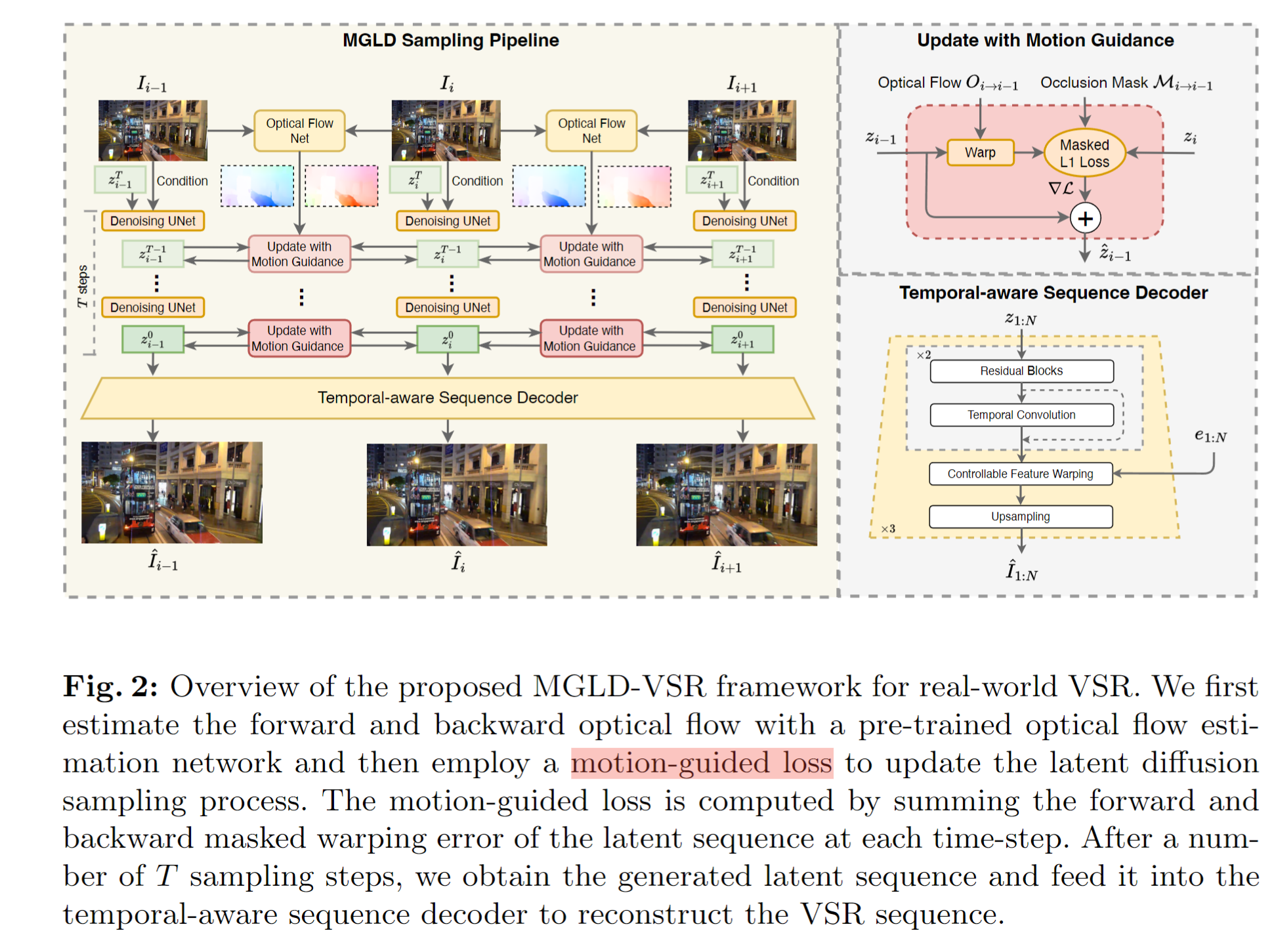
3.1 Latent Diffusion Model
介绍下LDM基本过程
3.2 Motion-guided Diffusion Sampling
在采样过程中引入了一种创新的运动引导模块,以测量跨帧的潜在特征的变形误差。
1、计算光流(前向和反向),下采样光流图去适应latent feature的尺寸
2、warp latent feature到相邻帧,然后计算两个方向上的累计误差
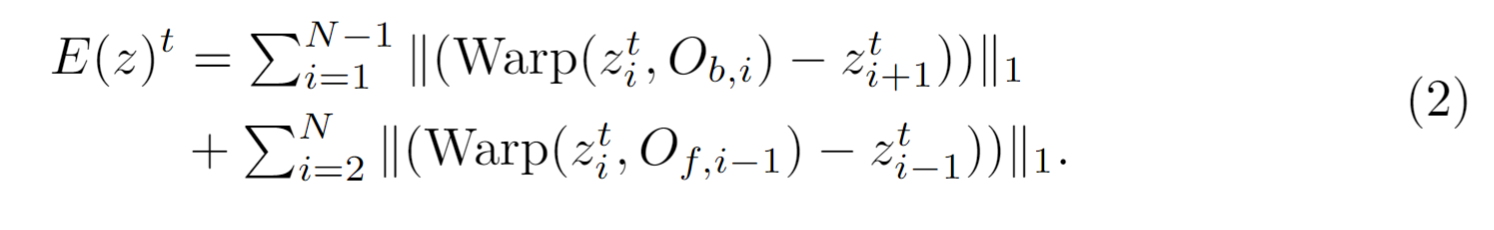
3、计算occlusion区域,增加一个mask,仅这些位置提供梯度
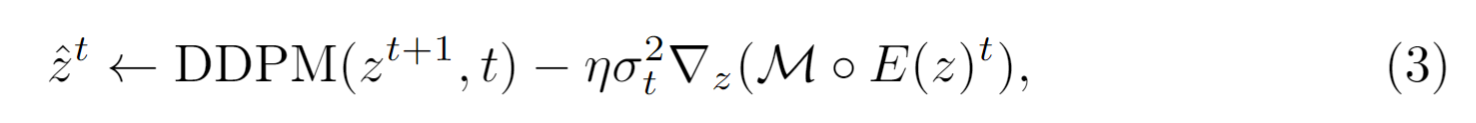
3.3 Temporal-aware Decoder Fine-tuning
latent的稳定性得到提升了,但是毕竟latent尺度是x8以下的,放大后可能又不稳定了,所以VAE-Dec也需要微调下
1、如图2所示,其中时序方面(temporal convs)的卷积是 1D convolutions(计算成本小)
2、从encoder通过CFW模块引入编码器特征,实现保真的效果
3、训练时候冻结原始空间卷积spatial convs
4、ℓ1 loss and perceptual loss、GAN-loss、frame difference loss、结构加权一致性损失 Lswc (structure weighted consistency loss)
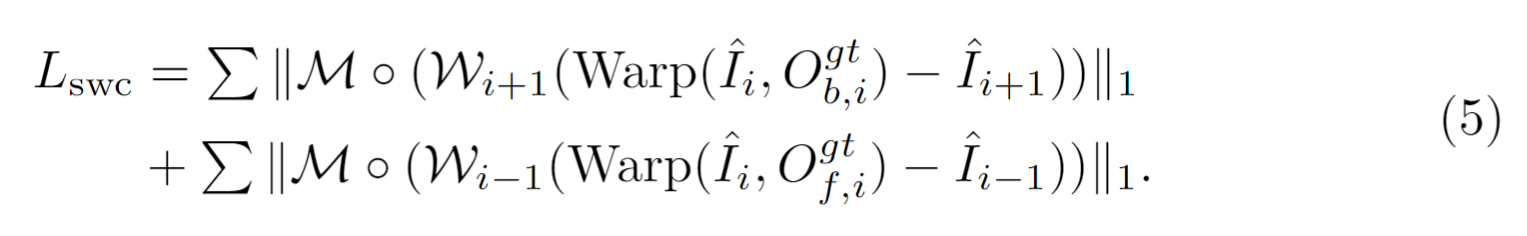
其中w=1+wS,代表着边缘位置,这个损失看起来是为了让前后帧的特征对齐
总的loss
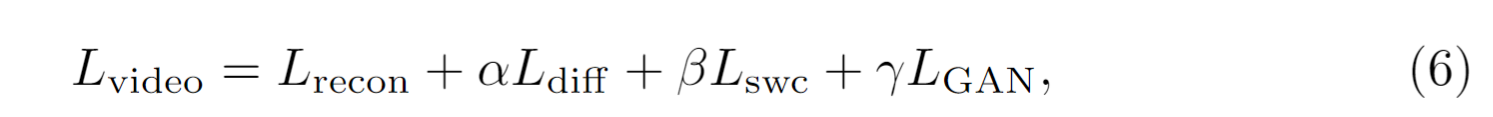
四、实验设置
4.1 训练阶段
两个训练阶段
1、finetune 去噪U-Net,权重使用sd2.1初始化,插入1D temporal convolution ,原始U-Net权重冻结,仅训练条件 和 时序模块
条件模块:包括小的时间感知的encoder,负责编码LR,然后注入去噪U-Net (使用SFT模块注入)
时序模块 :每个卷积块后面的1D temporal convolution
batch size设置24,序列长度设置6,latent尺寸设置64x64
2、首先生成干净的latent 序列,然后finetune 时间感知序列decoder (使用LR序列、生成的latent序列、HR序列)
这个阶段固定的VAE的decoder,然后插值时序模块和CFW模块来训练
batch size 设置4,序列长度设置5,图像尺寸设置512x512
4.2 训练数据
GT: REDS
LQ: RealBasicVSR的降质
贡献总结
1、提出了一种基于运动引导损失的扩散采样过程,使得输入帧的时间动态可以用于生成时间一致的潜在特征。
2、提出了一种时间感知序列解码器,以及两个面向序列的损失,以进一步增强生成视频的连续性。