我自己的原文哦~https://blog.51cto.com/whaosoft/1394644
#自动驾驶领域,VLM适合上车吗?
去年业界朋友交流的时候就被VLA这个概念吸引到了,最近无论是xx智能还是自动驾驶都出现了大量的VLA相关的研究进展,有一种莫名的直觉,这种范式很可能会改变自动驾驶业界的玩法,那么正好借着Waymo的EMMA工作,来和大家学习交流下VLA这种范式。
VLA概念及背景介绍
视觉-语言-动作模型(Vision-Language-Action, VLA),通过整合视觉、语言和行为信息 的互联网规模数据集,使机器人不仅能够识别和描述其环境,还能够根据上下文进行推理并在复杂、动态的环境中执行适当的动作。VLA强调一体化多模态端到端架构,非感知规控的模块化方案,标志着智能xx(Embodied AI)重要发展的里程碑。
因此VLA并非自动驾驶原生技术,其本质是机器人领域技术范式的跨界延伸
众所周知,自动驾驶的模型大家都在往感知决策一体化来推进,感觉整体都可以说成是VLA以及某种变体(本质上都是端到端了),总结以下有三个路径:
不依赖MLLM/LLM:Tesla为代表的FSD V12/V13版本 E2E,最近增加了语音输入,算是多模态端到端方案
依赖LLM : 理想所提出的MindVLA的升级架构
依赖MLLM(多模态一般泛指语音、文本、图像视频输入):Waymo的EMMA方案、百度的X-driver方案
另外还有一些非VLA范式,是结合了VLM的工作:比如VLM仅用决策,和下游解耦合串并联。
代表工作:地平线的SENNA、AlphaDrive ,理想DriveVLM
当然xx智能也有不同的VLA探索架构形式,类似Physical Intelligence 的pi0 , VLM+(diffusion policy/flow matching)的VLA形式或者是智元GO1的Vision-Language-Latent-Action(ViLLA)架构,采用隐式空间进行特征对齐增强来获得更好的动作。本文暂不开展xx智能领域VLA,重点关注自动驾驶语境下的VLA范式。
以往的自动驾驶系统模块化设计,虽然这种设计有助于更轻松地调试和优化单个模块,但具有模块之间的累积错误和模块间通信延迟等问题。
FSDV12/13产品化已经证明端到端成为一种优秀的方案,直接学习从传感器数据中生成驾驶动作。这种方法消除了模块之间对接口的需求,并允许从原始传感器到轨迹控制的端到端优化。
基于以上背景,我认为VLA更是一种端到端的架构升级,当然是否需要Language部分,以及Language是以特征还是常识还是COT等方式注入,业界还处于探索阶段。特斯拉也并没有宣传使用L部分,更多的还是VA(vision-action)的范式。以下一个图标来描述模型的优劣
|--------|------------------|---------------|-------|
| | 多模态大模型(VLM/MLLM) | 端到端模型(E2E/VA) | VLA模型 |
| 精准3D感知 | ❌ | ✅ | ✅ |
| 精准数值预测 | ❌ | ✅ | ✅ |
| 常识理解 | ✅ | ❌ | ✅ |
| 逻辑思维 | ✅ | ❌ | ✅ |
| 可解释性 | ✅ | ❌ | ✅ |
EMMA
原文链接:https://arxiv.org/abs/2410.23262arxiv.org/abs/2410.23262
EMMA,这是一种由 Gemini 提供支持的端到端多模态自动驾驶模型 。它将 Gemini 视为核心组件,并将自动驾驶任务重新构建为视觉问答问题 ,以适应 MLLM 的范式,旨在最大限度地利用 Gemini 的世界知识和配备思维链(COT)工具的推理能力 。与传统模块化方案不同,EMMA 直接将原始摄像头传感器数据映射到各种特定于驾驶的输出,包括规划轨迹 、感知目标 和道路图估计 。所有任务输出都表示为纯文本 ,因此可以通过特定任务的提示在统一的语言空间中联合处理。
Motivation:
如何利用MLLM海量的知识辅助自动驾驶任务,解决长尾特殊场景?思考以下几个case:
- 拥堵路段时,静止大车轮胎转角,本身没有产生压线等意图,但产生了转向意图,可以训练一个轮胎转角预测的模型来辅助下游决策
- 多车交互博弈的时候,比如另外一辆车摇下车窗对你进行挥手示意我方先通行,感知如何构建这类信息?
- 交警的手势场景,也可以训练一个交警分类模型,重建手势姿势
- 具有高级别语义的车道/红绿灯信息,比如公交车道,潮汐车道,绿灯可逆行车道等不同地区路网/红绿灯标准不统一。如果训练一个强大的分类模型,怎么优雅的穷举全国/全球的场景
目前来说其实自动驾驶大部分问题,还可以分类为感知系统不完备(感知背下了一切的锅)
感知系统的不完备导致自动驾驶的场景泛化困难,虽然已有的3D 动态E2E /Online mapping /Occ /红绿灯等感知模块已经尽可能获取完备的感知,但是目前的感知系统仍然不好处理上述的长尾场景,有没有一种可能存在一种较为完备的系统,比较优雅的处理上述的长尾场景(先叠个甲,大部分简单驾驶场景完全没必要用VLA这种范式,但是这里VLA看起来一种能通用解决的思路)
因此大算力、大模型的背景下,尝试使用MLLM可以作为一个潜在的解决方案
模型架构图
模型总体架构
输入:
- 传感器类型输入:Surround-view camera videos (V):
- 非传感器输入:均表达为文本格式
- 导航指令:High-level intent command : "go straight", "turn left", "turn right", etc.
- 历史自车状态:Set of historical ego status :表示为鸟瞰图 (BEV) 空间中的一组waypoints坐标。所有航点坐标都表示为纯文本,没有专门的token。这也可以扩展到包括更高阶的ego status,例如速度和加速度。
输出:
均表达为文本格式,自回归的方式预测n个token
1. 核心输出:未来5s轨迹,BEV(鸟瞰图)位置 (x, y)
轨迹两种表达形式:
- 文本转浮点数:将文本直接转换为浮点数。具体数值精度取决于距离单位(m/cm)来确定保留几位小数。优点在于所有任务都可以共享相同的统一语言表示空间,并且可以最大限度地重用来自预训练权重的知识。但是用自然语言描述坐标,token 数可能更多,效率和速度可能下降(如输入长度长,计算更慢),需要整体 trade-off 。
- special tokens to represent each location/action:分辨率由学习或手动定义的离散化方案确定。参考MotionLM利用这种方法进行运动预测,意味着 每一个token代表未来某一个时刻对应的location /action。这样方案输出的token数量较少,输出更快,但无法统一文本表达形式。
本文这里采用文本转浮点数的表达形式。
2.可选输出:
- 3D目标检测信息,如 3D box的位置和大小
- 可驾驶引导线检测,可以驾驶的waypoints组成的路网
- 场景语义理解(堵车场景判断)
- 思维链推理(文本表示) ,可以要求模型在预测轨迹之前解释其基本原理(如架构图右上角),通过思维链推理增强了模型的性能和可解释性。这里可以包括:
核心组件:Gemini 1.0 Nano-1
这个多模态大模型是非开源的,知乎有其他大佬解读,大家可以移步:段淇源:解读 Gemini 技术报告(Gemini: A Family of Highly Capable Multimodal Models)
大概总结几点:
- Transformer Decoder-only 的架构
- 训练32K 的 Context Length
- 参数规模:Nano-1 为 1.8B(18 亿)参数 的轻量级模型,专门针对低内存移动设备优化
- 4 位量化部署:采用 4 位量化技术(即模型权重以 4 位精度存储),显著降低内存占用和计算资源需求,同时保持推理性能
- 原生多模态支持:基于原生多模态架构(非 Flamingo 范式/非其他对齐的范式),支持同时处理 文本、图像、音频 输入,例如实时图像描述、语音转录和文本摘要
- 模型效率:相比云端模型(如 Ultra),Nano-1 在保持较高准确率的前提下,推理速度更快且能耗更低,Attention 部分采用 Multi Query Attention.
这样的大模型具备两个特点:
(1) 在庞大的互联网规模数据集上接受训练,这些数据集提供了超出常见驾驶日志所包含的丰富"世界知识" (2) 通过思维链推理等技术展示了卓越的推理能力, 但这在自动驾驶系统由于效率问题几乎不可用 。因此也需要探索一种结合cot方式的自动驾驶VLA模型
能力一:End-to-End Motion Planning
通过上述的Gemini模型,也可以做端到端规划,具体来说
(1) 使用导航系统(例如谷歌地图)进行路线规划和意图确定
(2) 利用过去的行为来确保随着时间的推移平稳、一致地驾驶。
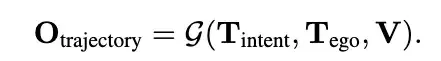
那么就是输入1,2表示的文本,和环视视频,输出对应的轨迹。
那么这样的公式,很容易构建真值,需要导航意图-历史轨迹-未来轨迹-视频数据,这四个元素,那么就可以给Gemini大模型进行监督微调(Supervised Fine-Tuning, SFT)
这样也无需高精地图,仅使用来自 Google Maps 的导航信息。
这里是利用 2 秒的历史轨迹来预测未来 5 秒的轨迹。
能力二:Planning with Chain-of-Thought Reasoning
将思维链 推理纳入端到端规划器轨迹生成中,这里要求模型在预测最终未来轨迹航点 trajectory 的同时阐明其驾驶决策理由 。
因此这种VLA模型不仅具备端到端planning的能力,还可以通过思维链推理来提高轨迹推理能力,利用输出驾驶原因来具备一定的可解释性。
从 4 种类型的粗粒度信息发展到细粒度信息
R1 - 场景描述 :大致描述驾驶场景,包括天气、日期、交通状况和道路状况。例如:天气晴朗,阳光明媚,现在是白天。这条路是四车道的无分隔街道,中间有一条人行横道。街道两旁停着汽车。
R2 - 关键目标 :是可能影响自主车辆驾驶行为的道路agent,我们要求模型识别其精确的 3D/BEV 坐标。例如:行人为 9.01, 3.22,车辆为 11.58, 0.35。
R3 - 关键目标的行为描述 描述已识别关键目标的当前状态和意图。具体示例如下:行人目前站在人行道上,望向道路,可能正准备过马路。这辆车目前在我前面,朝着同一个方向行驶,它的未来轨迹表明它将继续直行。
R4 - 原始驾驶行为决策:包括 12 类高级驾驶决策,总结了给定先前观察的驾驶计划。"I should keep my current low speed."
关键目标的3D/BEV信息的标注可以通过现有的3D 感知模型来预刷,(这就不得不提到我们之前在图森实习做的离线3D检测跟踪器,CTRL方案 原文链接:Once Detected, Never Lost: Surpassing Human Performance in Offline LiDAR based 3D Object Detection)
关键目标的行为描述,可以通过预测模块来获得。
那么在训练和推理期间,该模型在预测未来的waypoints之前预测驾驶决策理由的所有四个组成部分(R1-R4)
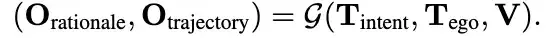
注意这里是可选的,驾驶决策理由肯定会带来大量的token消耗,造成推理效率低下
能力三:EMMA Generalist(通才网络)
图中绿色部分都是用来微调的task prompts和context信息,最终回答就如蓝色框所示,里面的信息可以可视化成polyline、3D box,自车轨迹等
虽然端到端运动规划是最终的核心任务,但全面的自动驾驶系统需要额外的功能。也就是感知 3D 世界并识别周围的物体、驾驶引导线预测(Road graph estimation)和交通状况。 EMMA 构建为一个通才模型,能够通过训练混合物处理多个驾驶任务。
采用指令调优(instrunction tuning, IT),这是 LLM 中一种常用调优方法。
关于指令调优知乎上也有一些学习资料
输入 Task prompts 中包含的特定任务提示一起联合训练所有任务。具体的任务分为三个主要类别:空间推理、驾驶引导线预测(Road graph estimation)和交通场景理解。当然这种形式感觉很灵活,可以继续拓展不同的任务。
空间推理:
其实就是3D 目标检测的文本形式,这里遵循 Pix2Seq ,并将输出的 3D 边界框表述为 OboxesO_{boxes }O_{boxes } = set{text(x, y, z, l, w, h, θ, cls)},其中 (x, y, z) 是车辆中心位置,l、w、h 是框的长度、宽度和高度,θ 是航向角,cls 是文本中的类标签。
通过编写具有两位小数的浮点数 将 7D 框转换为文本,每个维度之间用空格分隔 。然后使用固定的 prompt: 表示检测任务,例如 "detect every object in 3D",然后输出对应的box(文本形式),如下公式所示:
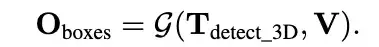
驾驶引导线预测(Road graph estimation):
这里如果用Road graph estimation,我一开始还以为是online mapping那种任务,但其实是类似道路可驾驶的中心线的概念。
输出包括语义元素(例如车道标记、标志)和物理属性(例如车道曲率)。这些 road 元素的集合形成了一个 road graph。例如,车道段由 (a) 节点表示,其中车道遇到交叉、合并或拆分,以及 (b) 这些节点之间沿交通方向的边缘。完整的 road-graph 由许多这样的polyline组成
虽然每条polyline内的边都是定向的,但每条polyline不一定相对于其他元素具有唯一的顺序。这与目标检测类似,其中每个框都由有序属性(左上角、右下角)定义,但框之间的相对顺序不一定存在。有几项现有工作使用 Transformer 对polyline进行建模与语言模型有类似的地方。
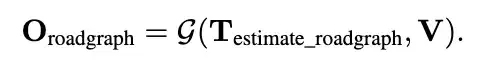
交通场景理解:
任务测试模型对整个场景上下文的理解。例如,由于施工、紧急情况或其他事件,道路可能会暂时阻塞。及时检测这些障碍物并安全地绕过它们;但是,场景中需要多个提示来确定是否存在阻塞。使用以下公式关注模型如何执行此临时阻塞检测任务:
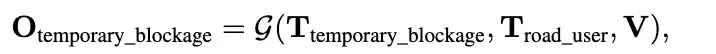
其中是指示潜在障碍物的模型输出,答案就是"是"/"否
表示前方道路上的所有物体
是文本提示"前方道路是否暂时被阻塞? "
实验部分(重点部分):
其实上述的指令调优,任务定义方式都是比较简单也好理解。重点看一下这里的实验结果,表露出来了什么信息。
端到端规划 waymo open datasets数据集实验:
waymo在自己家的数据集刷了一遍,EMMA+对比EMMA其实就是预训练用了waymo内部数据集。这里wayformer之前是一个agent运动预测模型,这里修改成了用于预测自车未来轨迹的模型。
ADE就是平均距离误差的指标,当然是越小越好。
端到端轨迹采样数量实验:
在推理过程中,从多个候选轨迹中对最终轨迹进行采样对最终性能很关键。MotionLM 和 Wayformer 都生成了 192 个候选轨迹,随后使用 k-means 聚类将其聚合为 6 个cluster,从而产生 6 个代表性轨迹 。最终轨迹是根据它们的相关概率从这 6 个代表性轨迹中选择的。
为了公平起见,我们还使用 Top-K 解码策略对多个轨迹进行采样,最高可达 K = 24 。然后,我们计算所有轨迹之间的成对 L2 距离,并选择平均 L2 距离最低的轨迹作为最终预测轨迹,它可以被视为所有预测中的 "中位数 "轨迹。
可以看见在wod数据集上还是轨迹越多越好,但边际效益递减,即增加候选轨迹数量的优势在某个点之后会减弱。
端到端规划nuScenes实验:
这里有个值得关注的点,与 Waymo数据集不同,在nuScenes对多个轨迹进行采样并没有产生明显的改进。这里推测是由于 nuScenes 在更简单的驾驶场景中的预测时间范围 (3s) 较短。因此只用top1 预测就够了
端到端规划的 COT实验:
ablation里面思维链对最终e2e planning的影响,看起来是否添加R1的scene description对最终规划没有什么用,但是其他三个部分是有用的。
端到端规划的Scaling实验:
如图 4 所示。在更大的训练集上训练模型时,会在过拟合之前观察到较低的 eval 困惑度。
结果表明,即使使用当前的大规模数据集,EMMA 的驾驶质量也尚未趋于稳定
在内部数据集上的 EMMA 数据scaling实验。每条曲线都表示随着训练步骤的增加,端到端运动规划的 eval 困惑度。x 轴是训练计算,由对数刻度的浮点运算 (FLOP)(大模型scaling law中常用的度量指标), 相同的 EMMA 模型在四种大小的数据集上进行训练,这些数据集以从 3% 到 100% 的不同百分比
一般来说,当给予更多的训练计算时,EMMA 往往会获得更好的质量,直到过拟合 ,但它也会在较小的数据集上快速过拟合。但观察到,在使用完整的大规模数据集时,轨迹质量也未饱和。
这里就很值得关注了,意味着10^ 21次方的flop计算迭代仍不能收敛,还需要多少计算资源未知,这个玩法在waymo这种资源的公司,都没有探索明确出来多少训练资源能收敛.....
所以如何在越大的模型 + 越多的数据 + 越多的训练轮数上面进行拓展还有很多可探索的工作,而且低成本的训练方案也至关重要。
3D Object Detection实验:
由于EMMA输出的检测框,没有置信度分数,因此直接比较精度/召回率,可以看见EMMA+的检测性能看起来还好,当然比较的都是一些很早期的3D检测器,个人猜测,VLA这种面向规划模型,3D感知性能有个大概还行的样子就够了
**驾驶引导线预测(Road graph estimation)**实验
用于预测一组无序的折线,每条折线都表示为一系列waypoints。用两个指标来衡量道路图预测的质量:
(1) 车道级精度和召回率,当且仅当它们的chamfer distance 在 1 米以内时,我们定义预测的车道折线和真实车道折线之间的真正正匹配;
(2) 像素级精度和召回率,其中折线被栅格化为分辨率为 1 米的 BEV 网格------然后我们将 BEV 网格视为图像,并根据每个像素的匹配计算精度和召回率。
此任务涉及多种设计选择。
- 关于polyline的表示 ,定义是每个车道的起点和终点,其中根据需要添加中间点以准确捕获道路的曲率。
- 关键设计:构建用于模型训练的目标标签序列,参考了Pix2Seq 文章,知乎上也有大量对应的解读,为了方便理解,来一张图,主要是离散输出的形式,来自:我爱计算机视觉:Pix2Seq V2 ,一个用于视觉任务的统一序列接口
- 关键设计:填充waypoints并应用随机打乱顺序。此技术可帮助模型处理无序输出,并防止在训练期间过早终止。
pix2seq任务输入输出
以上的关键设计进行对应ablation:
图 6 各种设计选择的消融研究
从最佳设计开始,系统地消融以下每一种配置,并评估由此产生的质量下降。
这里并没有具体量化具体的指标参数,如ADE之类的,更多的还是这种指标下降的百分比的比较,也是论文写作的一种表现手法,看的更直观。
首先第一个部分:基于车道曲率和长度的道路图折线动态采样 (最左侧)被证明是最重要的因素,导致车道级精度和召回率发生 70% 到 90% 的大幅变化。相比之下,将模型与类似语言的表示形式对齐,即语义标点符号(最右侧),效果变化不大,对任何指标的精度和召回率仅产生 <10% 的变化。
具体来解释每一部分(这里细节比较多,感觉花了很大精力来做这个任务的):
- polyline表达:动态采样优于固定采样。简单的折线表示是在每个通道中对固定数量的稀疏控制点进行采样,例如,两个端点加上固定数量的中间点来捕获曲率。但是,发现更好的方法是根据车道的曲率和长度动态调整每条折线的点数。通过保持一致的航路点密度而不是一致的航路点数量,实现了一种更准确地捕捉车道结构复杂性的表示,从而在指标中产生大约 40% 到 90% 的差异,如图 6 所示。
- polyline表达:ego-origin 对齐的采样间隔比 naviely 对齐采样间隔要好。这种驾驶引导线通常在全局坐标系中存储和访问,这意味着车道起点和延伸线独立于自主车辆位置。为了提高准确性,必须调整车道点样本,使其从 ego 车辆坐标系原点开始。具体来说,相对于ego位置 的多段线点采样可避免将全局坐标系中采样的点直接转换为自我坐标系时可能产生的任意偏移量。这可以防止预测质量下降 25% 到 60%。
- 序列构建:shuffled ordering 优于任意排序。我们根据折线目标与 ego 车辆的端点距离将折线目标组织到bin 中,从而提供粗略的全局排序。例如,我们将车道分为附近的车道和较远的车道,这些车道用作连接车道。在训练期间,我们动态地打乱每个距离区间内的折线,以提高模型的稳健性和覆盖率。每个 bin 内的这种动态洗牌提高了模型跨不同通道配置进行泛化的能力,从而实现更准确的预测。
- 序列构建:填充方案优于 非填充方案。与 Pix2Seq类似,发现防止提前终止的填充目标是非常有效的。除了填充折线目标的总数外,我们还填充每条折线内的点数。使用 "无效" 标记来表示折线中的填充点。每条折线还显式标记了最终的"有效"或"无效"标记,以指示它是否包含任何非填充点。这种方法可确保输入大小的一致性,这有助于在训练期间保持模型的完整性,并降低过早截断的风险,从而获得更可靠和准确的预测。
- 序列构建:添加标点符号和其他语义冗余的标记可以提高质量。在目标序列构建中,注意到使用类似语言的结构和标点符号对目标进行分组是有益的(例如,"(x,y )和 (x,y);..."而不是 "xy xy;...")。此外,显式包含语义冗余标记(例如将填充的目标标记为"无效",而不是依赖于"有效"标记的隐式省略)可以提高性能。这种方法结合了标点符号和冗余,使车道级指标提高了 10%。将这种改进归因于 Gemini 的语言相关预训练。通过利用类似的结构化表达式,Gemini 可以更轻松地适应其他任务。
Scene Understanding实验
针对临时堵塞的场景理解任务研究,这里并没有展开其他的复杂交通场景,应该可以加更多其他特殊场景。
如图7所示,有三种比较方案:
- human baseline :我们通过向人类展示图片并要求他们判断车道是否暂时阻塞作为baseline,他们可以回答"是"、"否"或"不确定"。
- human baseline +fliter:所有"不确定"的答案 本身就是一种错误, 所以过滤掉所有答案为 "不确定" 的示例,作为最新的指标,效果也最好
- EMMA:模型经过微调以预测所有示例的 "是 "或 "否"。
第一个实验:相当于是直接FT,效果就不错。
第二个实验:和驾驶线估计的任务联合FT,会掉指标(典型多任务打架)
第三个实验:先短暂预训练驾驶线预测任务,然后联合两个任务FT,指标正常了
第四个实验:先较长时间的预训练驾驶线预测任务,然后联合两个任务FT,指标更好了。多任务上的不同训练策略很重要,这种大家平常训练多任务感知模型的时候也会遇见(多任务打架)。
指令调优联合训练实验:
从三个任务来看:端到端规划、3D 目标检测、驾驶引导线预测。 所有三项任务的联合训练产生了较显著的改进,通才模型的性能比单任务模型高出 5.5%。
其中,当共同训练两项任务时,某些组合会比其他组合带来更大的收益。例如,当与planning相结合时,检测性能的提升最大,而驾驶引导线预测在与planning相结合时同样受益最大,但是plannning的指标掉了,估计是因为驾驶引导线某种程度也很类似planning的轨迹,导致模型的一些confused。
但总体来说, 可以看到任务的互补性。例如,当模型可以准确识别车辆的位置时,道路图估计会变得更加容易。同样,驾驶质量与理解目标的交互密切相关,3D 目标检测增强了这项技能。
这些发现表明,追求通才模型是未来研究的一个有前途的方向,有可能更深入地了解任务协同和性能优化。
可视化验证:
这里就重点放一些有意思的可视化,更多大家可以去原文看
三个图从左到右分别是planning结果(轨迹横向扩张了大概车宽的距离)、3D detection 、 驾驶引导线
垃圾袋避让
梯子避让,其实做occ的同学应该知道,这类稀疏带空的低矮目标真值也挺难构建的
小松鼠刹停,这种近距离小目标,如果occ如果做的好,也可以预测出来,但是如果是mllm的形式思维链推理也包含准确的松鼠信息,那这个能力还是挺牛逼的
白色的狗 刹停,还是一个比较复杂的路口,驾驶引导线的预测看起来也没有特别大问题。
道路表示为左变道,但是左侧有施工牌,这个planning就考虑这些复杂信息,直接沿着当前车道开
道路避障的场景
交警避让
黄灯 刹停 ,可见大量的常识信息包含了这些交通知识
存在的问题和未来的解决方案:
内存和视频帧数问题:目前,模型仅处理有限数量的帧(最多 4 帧),这限制了其捕获驾驶任务所必需的长时空依赖关系的能力。有效的驾驶不仅需要实时决策,还需要在更长的时间范围内进行推理,依靠长期记忆来预测和响应不断变化的场景。增强模型执行长期推理的能力是未来研究的一个有前途的领域。这可以通过集成内存模块或扩展其有效处理较长视频序列的能力来实现,从而实现更全面的时间理解。
扩展到 LiDAR 和雷达输入:(waymo车上有很多lidar,但是这个模型明显没有利用到这些信息)由于无法将摄像头输入与 LiDAR 或雷达融合,因此 3D 空间推理受到限制 。严重依赖于预先训练的 MLLM,这些 MLLM 通常不包含 LiDAR 或雷达输入。集成这些 3D 传感模式会面临两个关键挑战:1) 可用相机和 3D 传感数据量之间存在显着不平衡,导致与基于相机的编码器相比,3D 传感编码器的通用性较差。2) 3D 传感编码器的发展尚未达到基于摄像头的编码器的规模和复杂性。应对这些挑战的一个潜在解决方案是使用与相机输入仔细对齐的数据来预训练大型 3D 传感编码器。这种方法可以促进更好的跨模态协同,并显著提高 3D 传感编码器的泛化能力。
规划轨迹的验证:模型可以直接预测驾驶轨迹,而无需依赖中间输出。增加额外的数据,会有实时性和可解释验证的矛盾。通才模型也可以联合预测额外的人类可读输出,例如目标和驾驶引导线,并且驾驶决策可以用思维链驾驶原理进一步解释。但不能保证这些输出100%一致的(大模型推理过程错了,但结果对了情况也是有的)。此外,额外的输出会为部署带来巨大的运行时延迟开销。
用于闭环评估的传感器仿真:大家也都知道开环评估不靠谱。与闭环性能没有很强的相关性。所以为了在闭环环境中准确评估端到端自动驾驶系统,需要一个全面的传感器仿真解决方案。然而,传感器仿真的计算成本通常比行为仿真器高(如苹果的GIGAFLOW)。除非进行实质性优化,否则这种巨大的成本负担可能会阻碍端到端模型的全面测试和验证。
这里给没有做过仿真的同学科普一下:
一段式端到端: 一般需要传感器的闭环仿真,这里推荐一下 乃岩老师在图森的开展闭环仿真工作(基于神经渲染的下一代真实感仿真)Naiyan Wang:基于神经渲染的下一代真实感仿真 ,这里实习的时候也有幸在mentor闫岩的指导下优化了里面的部分模块。当时在图森参与的是传感器的联合仿真:也就是图像+点云的传感器仿真。当然现在有很多拿3D GS来进行图像仿真部分。二段式端到端 :一般就是行为仿真,只需要模拟感知的一些结构化信息(车道线、感知目标、红绿灯等信息),比如苹果GIGAFLOW、地平线的GUMP。这样的仿真成本更低,一般可以用于二阶段端到端的闭环仿真、强化学习来使用。
当然还有一些生成类的工作可以实现类似的事情,比如地平线的UMGen工作:半闲:CVPR 2025 | UMGen:多模态驾驶场景生成统一框架 ,也是超哥带领的地平线World model项目中的收尾工作~
车载部署的挑战 :自动驾驶需要实时决策,这在部署大型模型时构成了重大挑战,因为它们的推理延迟会增加。这就需要优化模型或将其提炼成适合部署的更紧凑形式,同时保持性能和安全标准,相对于传统模型,计算要求更高。在模型大小、效率和质量之间实现这种微妙的平衡。
总结
EMMA利用MLLA实现了端到端planning的方案,并且通过额外的COT输出,具备了一定的可解释性,让端到端不再是黑盒模型。这种方案也属于自动驾驶VLA领域的初期探索工作,后续可发展可探索空间也有很多,还有一些工作比如OpenEMMA,LightEMMA这些,后续计划进一步学习这些内容,以文章的形式发出来
个人认为,自动驾驶应该会出现于自动驾驶的用于车端平台的垂域大模型,也可能并不需要L部分,如果高效率在车端芯片上推理,综合来看特斯拉FSDV13很接近这种形态。
#MAC-VO
新型基于学习的立体视觉里程计框架
当前VO的局限性
视觉里程计(VO)通过图像序列预测相机的相对位姿,通常作为同时定位与建图(SLAM)系统的前端模块。过去几十年间,几何方法和基于学习的方法均取得了显著进展,在泛化性和精度方面实现了重要突破。然而,在真实场景中,VO仍面临诸多挑战,特别是在低光照、动态物体和纹理缺失等视觉退化环境中。
为提高复杂场景下的鲁棒性,基于几何的VO算法采用了离群点过滤策略,并通过观测特征的协方差矩阵对优化残差进行加权。然而,如何有效选择可靠关键点并建立其协方差模型仍是两大核心挑战。现有方法通常基于局部强度梯度设置人工阈值进行关键点选择,这类方法未建模环境的结构或上下文信息(例如重复图案区域虽具有高图像梯度但并非理想候选特征),易导致误差和离群点。此外,协方差模型常被简化为恒定参数的经验模型,这种次优方案难以适应不同环境,且参数需针对不同场景进行大量调整。
随着学习型视觉特征的进步,更多算法利用学习特征优化相机位姿。这些特征点的置信度分数或权重通常以无监督方式获取,其学习得到的置信度虽有助于特征跟踪和优化可靠性建模,但存在尺度无关性问题------即无法反映三维空间中的真实估计误差。这种尺度无关性带来双重局限:
- 首先,导致室内外等不同尺度场景的协方差不一致
- 其次,难以融合多模态或多传感器的约束。
为解决上述挑战,本文提出为三维关键点建立度量感知协方差模型,通过两项创新实现:第一,我们设计学习型二维度量感知特征匹配不确定性模型,借鉴FlowFormer和GMA框架,采用迭代更新模块和运动聚合器预测图像空间的不确定性,有效过滤遮挡区域或低光照区域的不可靠特征;第二,基于学习得到的二维不确定性,通过度量感知三维协方差模型建立特征点的空间协方差。相较于DROID-SLAM采用的尺度无关对角协方差矩阵,我们的方法通过建模三维特征点协方差(包含轴间相关性)实现了更精确的表征,消融实验验证了该协方差模型的帧间一致性与帧内一致性。
本文介绍的MAC-VO是一个具有卓越关键点选择和基于度量感知协方差模型的姿态图优化能力的立体视觉里程计系统。实验表明,与现有VO算法相比,MAC-VO在复杂场景下展现出更高的跟踪精度,甚至无需调参和多帧优化即可超越部分SLAM系统。
项目链接:https://mac-vo.github.io/
核心贡献可概括为:
- 度量感知的二维不确定性学习网络:利用迭代运动聚合器捕捉特征匹配的不一致性,通过度量感知不确定性评估特征质量,指导关键点选择与后端优化。
- 新型度量感知三维协方差模型:基于特征匹配和深度估计的二维不确定性构建,消融实验验证了尺度一致性与非对角项在姿态图优化中的必要性。
- MAC-VO系统实现:提出完整立体视觉里程计框架,通过度量感知协方差实现相机位姿估计与三维特征配准,在复杂环境下的性能超越现有VO及部分SLAM算法。
该工作为视觉里程计在真实复杂场景中的应用提供了新思路,其建立的度量感知协方差模型也为多传感器融合等扩展应用奠定了基础。未来工作将探索该模型在集束调整、多帧优化和闭环检测中的潜力,以进一步提升系统性能。
具体方法
如图2所示,MAC-VO通过度量感知协方差模型实现了学习型前端与几何约束后端的有效集成。前端通过训练不确定性感知匹配网络建模特征缺陷导致的对应不确定性。利用学习得到的不确定性,我们在第III-B节开发了关键点选择器来筛选可靠特征。提出了度量感知协方差模型。在后端优化中,我们通过最小化由3D协方差加权的配准关键点距离来优化相对运动。
网络与不确定性训练
我们的网络以连续两帧图像作为输入,预测光流估计及其对应不确定性。采用FlowFormer的transformer架构作为光流估计主干网络,其循环解码器通过代价体匹配空间的特征对应模糊性,利用编码代价记忆的全局上下文迭代优化光流预测。
为扩展该框架并融合全局运动线索与局部特征,我们引入协方差解码器预测对数空间的不确定性迭代更新量。在迭代更新过程中,对数方差通过指数激活函数转换为最终不确定性。
采用保形预测中的负对数似然损失函数进行不确定性监督:
其中y为真实光流,表示第i次迭代的网络输出,为指数衰减的迭代权重(衰减率0.8)。网络编码器参数使用FlowFormer预训练模型初始化,在合成数据集TartanAir上训练协方差模块,实验表明该模型可零样本迁移至真实数据集。
基于不确定性的关键点选择
相较于DPVO的随机选择器和ORB-SLAM的手工特征选择器,我们通过三级级联过滤器筛选可靠特征: 非极大值抑制(NMS):防止关键点候选聚集,确保空间均匀分布
几何过滤器:剔除图像边界和无效深度观测区域的关键点
不确定性过滤器:滤除光流和深度不确定性高于当前帧中位数1.5倍的像素
如图3所示,在KITTI轨迹中,不确定性过滤器可有效去除动态车辆上的关键点候选,同时过滤遮挡物体、反光表面和无纹理区域的关键点,生成更鲁棒的特征集。
度量感知3D协方差模型
在针孔相机模型下,3D关键点的协方差由深度不确定性和匹配不确定性(, )共同决定。建立精确的3D协方差模型需要解决两个核心问题: 匹配点的深度不确定性估计
2D-3D投影过程中的非对角协方差项建模
2D不确定性到3D协方差的投影
设相机焦距为, ,光心为(, ),关键点坐标计算为:
协方差矩阵主对角线元素为:
考虑深度的公共乘数效应,3D关键点在相机坐标系下的协方差矩阵需包含非对角项:
其中:
关键点匹配后的不确定性校正
如图5(b)所示,匹配特征点可能位于物体边缘等敏感区域,微小的特征匹配扰动会导致3D配准误差放大。为此,我们基于局部深度图块(核尺寸32)的加权方差估计深度不确定性:
其中权重为由和构建的2D高斯核。
姿态图优化
通过最小化配准关键点间的马氏距离优化世界坐标系下的相机位姿:
其中表示以协方差矩阵加权的马氏距离。相较于DROID-SLAM使用的对角协方差矩阵,我们建模了轴间相关性以更准确捕捉空间依赖关系。该优化问题通过PyPose库的Levenberg-Marquardt算法求解。
实验效果
总结一下
MAC-VO是一种基于学习的立体视觉里程计方法,在挑战性数据集上超越了大多数视觉里程计甚至部分SLAM算法。当前工作聚焦于两帧姿态优化,我们相信结合多帧优化(如集束调整)和闭环检测将进一步提升精度。此外,我们计划将度量感知协方差模型应用于多传感器(如IMU)融合领域。
参考
1 MAC-VO: Metrics-aware Covariance for Learning-based Stereo Visual Odometry
#FutureSightDrive
阿里FutureSightDrive:基于时空思维链的视觉思考
摘要
本文介绍了FutureSightDrive:自动驾驶中基于时空思维链的视觉化思考。视觉语言模型(VLMs)因其强大的推理能力而引起了人们对其在自动驾驶中应用的兴趣。然而,现有的VLMs通常利用了针对当前场景的离散文本思维链(CoT),这本质上代表了视觉信息的高度抽象和符号压缩,可能会导致时空关系模糊和细粒度信息丢失。与纯符号逻辑相比,自动驾驶是否能够在现实世界仿真和想象中被更好地建模?本文提出了一种时空思维链推理方法,它使模型能够进行视觉化思考。首先,VLM作为一种世界模型来生成统一的图像帧,用于预测未来的世界状态:其中感知结果(例如车道分隔线和3D检测结果)代表未来的空间关系,以及普通的未来帧表示时间演变关系。然后,这种时空思维链作为中间推理步骤,使VLM能够作为一种基于当前观测和未来预测的轨迹规划的逆动力学模型。为了在VLMs中实现视觉生成,本文提出了一种集成视觉生成和理解的统一预训练范式,以及一种渐进式视觉思维链来增强自回归图像生成。大量实验结果证明了所提出方法的有效性,从而将自动驾驶推向了视觉推理。
主要贡献
本文的主要贡献总结如下:
1)本文提出了一种时空思维链(CoT)推理方法,它允许模型通过从未来时间和空间维度上进行视觉化思考来增强轨迹规划;
2)本文提出了一种统一的预训练范式,用于视觉生成和理解。同时,本文还引入了一种渐进式生成方法,从施加物理约束到补充细节信息;
3)本文对轨迹规划、未来帧生成和场景理解任务进行全面评估,以证明所提出的FSDrive的有效性。
论文图片和表格
总结
本文提出了FSDrive,这是一种基于时空思维链(CoT)的自动驾驶框架,它使VLMs能够进行视觉化思考。FSDrive通过中间图像形式推理步骤来统一未来场景生成和感知结果,消除了跨模态转换引起的语义差距问题,并且建立了一个端到端视觉推理流程。VLM具有双重作用:1)作为世界模型,它预测了未来图像帧;2)作为逆动力学模型,它根据当前观测和未来预测来规划轨迹。为了在VLMs中实现视觉生成,本文提出了一种统一视觉生成和理解的预训练范式,以及一种渐进式从易到难的视觉CoT来增强自回归图像生成。大量的实验结果证明了所提出的FSDrive方法的有效性,从而将自动驾驶推向了视觉推理。
局限性和更广泛的影响:尽管自动驾驶需要对周围环境进行感知,但是考虑到实时效率,目前仅生成前视图的未来帧。未来工作可以尝试生成环视图,以实现更安全的自动驾驶。在社会影响方面,LLMs带来的道德挑战将延伸到自动驾驶领域。技术和法规上的进展将推动更安全、更高效系统的发展。
#VLM和自动驾驶/xx智能的碰撞
VLM + 强化学习
- Visual-RFT: Visual Reinforcement Fine-Tuning
- 在 Qwen2-VL-2B上用 GRPO 强化学习,提升模型在 Open Vocabulary detection, few-shot detection, 以及 reasoning grounding 任务的 few-shot 能力。
- AlphaDrive
- 在 Qwen-VL 模型上,用 GPT-4o生成+人工筛选数据的方式,采用 SFT + GRPO做端到端的自动驾驶。输入单帧图片和语言prompt, 输出动作规划(加速减速,左转右转直行)

AlphaDrive 的训练过程 & reward model
VLA + xx智能
- GR-2
- 两阶段的训练,第一阶段看视频,学习如何根据文字描述预测视频的后续画面;第二阶段用机器人实际操作的数据训练模型,根据输入图片和语言生成 action.
- OpenVLA
- 用 97万个机器人控制数据上对模型(视觉:Dino-V2 + SigLP, 语言:Llama) 做微调,使得Llama 输出 action token.

Open-VLA 模型结构
- FAST
- 类似 OpenVLA 的方法把输出 action 由连续的空间按照相同大小量化到有限的离散 token 中,对于高频次空间且精细动作不友好。本文受到 byte-pair-encoding 的启发设计了压缩的量化tokenize 方法,提升泛化能力的同时减少了计算复杂度。
- OFT: 对 OpenVLA 做高效的微调
- (1)并行Decoder,一次 forward 输出所有 token; (2) 把 discrete action token 改成了连续的 action token, 可以实现更精细的控制;(3)基于L1-regression损失函数,可以达到跟Diffusion差不多的效果,但训练和推理速度都更快。
慢思考 + 快思考 的双系统配合
- LeapAD: 新手期积累经验 + 老司机阶段靠直觉
- 新手:仔细分析,基于 GPT-4;把经验存到 memory bank;熟练后:肌肉记忆,基于 Qwen-1.5. 输出单帧图片,输出驾驶 action.
- RoboDual:通用系统给出大致指导意见 + 专家系统精细化执行
- 通用系统:输入图片和 prompt, 给出初步指导和通用表征,具体输出是 action token & Latent representation. 具体模型是 OpenVLA + LoRA 微调
- 专家系统:输出多传感器、以及通用系统提供的特征,以 de-noise 的方式输出 action. 具体模型是 DiT
- VLM-E2E:
- 使用 VLM 对场景进行描述,该文本信息转成 embedding 之后与 BEV 特征做融合,从而增强模型对关键障碍物的语义理解。
Multi-agent motion prediction
- MotionLM
- 把 multi-agent motion prediction 任务建模成语言模型的自回归的序列生成任务,以 next token prediction 的方式生成轨迹预测
- Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
- 看点一:Next-K step prediction, 一次预测接下来 K 个时间步的动作。
- 看点二:用 EMA 的方式更新上上次、上次、这次, xxx 的预测,保持连贯。
World Model 相关
- DriveDreamer4D
- 用世界模型生成大量复杂场景的数据。技术创新点:改进世界模型,给定车辆位置和道路地图,可以生成多样且符合交通规则的视频。
#FSDrive
时空视觉推理SOTA!基于时空CoT可视化的思考(高德和西交)
视觉语言模型(VLMs)因其强大的推理能力,在自动驾驶领域受到日益广泛的关注。然而,现有VLMs通常采用针对特定场景设计的离散文本思维链(Chain-of-Thought, CoT),这种表征本质上是对视觉信息的高度抽象和符号化压缩,可能导致空间-时间关系模糊以及细粒度信息丢失。自动驾驶是否更适合通过真实世界模拟与想象建模,而非纯粹依赖符号逻辑?本文提出一种时空思维链(spatio-temporal CoT)推理方法,使模型可视化地思考。首先,VLM作为世界模型生成统一图像帧以预测未来世界状态:其中感知结果(如车道分隔线和3D检测)表征未来的空间关系,普通未来帧则表征时间演化的动态关系。该时空思维链作为中间推理步骤,使VLM能够充当逆动力学模型,基于当前观测和未来预测进行轨迹规划。为实现VLM的视觉生成能力,提出了统一视觉生成与理解的预训练范式,并设计渐进式生成过程增强自回归图像生成方法。大量实验结果验证了该方法的有效性,推动自动驾驶迈向视觉推理。
- 项目链接:https://misstl.github.io/FSDrive.github.io
- 论文链接:https://arxiv.org/abs/2505.17685
- 代码链接:https://github.com/missTL/FSDrive
关键词:视觉-语言模型(Vision-Language Models, VLMs)、链式思维(Chain-of-Thought, CoT)推理、自动驾驶、统一视觉生成与理解预训练

简介
近年来,鉴于多模态大语言模型(MLLMs)在世界知识、推理能力和可解释性方面的卓越表现,它们已被广泛应用于自动驾驶领域。一个具有前景的方向是端到端视觉-语言-动作(VLA)模型,该模型利用预训练视觉-语言模型(VLM)直接从视觉观测和语言指令中提取场景特征,进而生成车辆控制指令(如速度和轨迹)。这种范式不仅简化了系统架构并最小化信息损失,还能利用模型的世界知识分析驾驶环境,在复杂场景中进行安全决策的推理。
在语言领域,思维链(CoT)通过鼓励逐步推理显著提升了推理能力和可解释性。然而,现有自动驾驶研究通常将离散文本CoT(如针对当前场景的语言描述和边界框坐标)作为中间推理步骤。这种方法本质上是对视觉信息的高度抽象和符号化压缩,可能导致时空关系模糊、细粒度信息丢失以及模态转换鸿沟,如图1顶部所示。对于需要深度物理世界交互的自动驾驶系统而言,其思考过程是否应更接近对世界的模拟和想象,而非单纯依赖语言逻辑推理?
受人类驾驶员直接在脑海构建未来场景视觉表征的认知机制启发(而非将思维转化为语言描述进行推理),我们提出了一种更直观的时空思维链(spatio-temporal CoT)方法,如图1底部所示。该方法避免了文本抽象带来的信息损失,使模型能以视觉化方式进行轨迹规划。具体而言,VLM作为世界模型生成统一图像帧以预测未来世界状态:受视觉提示工程(在图像上绘制红色圆圈引导模型注意力)和VLIPP(生成未来帧时先预测未来边界框以引入物理先验)的启发,我们在预测的统一帧上通过未来红色车道分隔线和3D检测框表征未来世界的空间关系。这些粗粒度视觉线索引导模型关注未来场景中的可驾驶区域和关键物体,同时施加物理合理性约束。时间关系则通过常规未来帧表征,其视觉内容的动态演变直观呈现了时间进程和场景发展的内在规律。随后,时空CoT作为中间推理步骤,使VLM能够作为逆动力学模型,基于当前观测和未来预测进行轨迹规划。与传统的离散文本CoT及图像-文本CoT方法(如图1中部所示)相比,我们的方法将未来场景表征和感知输出统一为图像格式,更有效传递了时空关系。这消除了跨模态转换(如将视觉感知转换为文本描述进行推理)导致的语义鸿沟,建立了端到端的视觉推理pipeline,使模型能够进行直接的视觉因果推理。
为赋予VLM图像生成能力,我们提出了一种预训练范式,既能保持现有MLLM的语义理解能力,又能激活其视觉生成能力。具体而言,在语义理解保持部分,我们沿用先前方法,通过视觉问答(VQA)任务实现当前场景理解。在视觉生成激活方面,我们探索了图像与文本的共享词汇空间,仅需极少量数据(约为现有方法的0.3%),无需复杂模型架构修改即可直接释放现有MLLM在自动驾驶领域的视觉生成潜力。然而,直接生成完整详细的未来场景可能违背物理规律。因此,我们提出渐进式由易到难生成方法:首先利用VLM的世界知识推理未来场景中的可行驶区域和关键物体位置,生成粗粒度未来感知图像(如车道线和3D检测),以约束物理规律;随后在该约束下生成完整未来帧以补充细粒度细节,使模型能可视化思考未来准确预测。
在轨迹规划、未来帧生成和场景理解任务上的大量实验验证了FSDrive中预训练范式和时空CoT的有效性。FSDrive通过建立像素级xx化环境关联实现道路场景理解,而非依赖人工设计的抽象语言符号,推动自动驾驶向视觉推理迈进。综上所述,我们的主要贡献包括:
- 提出时空思维链推理方法,使模型能通过未来时空CoT的可视化思考增强轨迹规划能力。
- 提出统一的视觉生成与理解预训练范式,同时引入从物理约束到细节补充的渐进式生成策略。
- 在轨迹规划、未来帧生成和场景理解任务中进行全面评估,验证了FSDrive的有效性。

方法详解
预备知识
端到端轨迹规划
端到端自动驾驶直接从传感器数据生成未来轨迹,可转换为加速度和转向控制指令。给定时间步的个环视图像,模型输出BEV轨迹,其中每个航路点。该过程表示为:
其中表示可选的导航指令和自车状态(如速度、加速度)。
统一视觉生成与理解
近期研究将多模态理解和视觉生成统一于单一LLM中。理解能力与标准LLM一致,生成能力通常使用VQ-VAE将图像编码为离散token。首先,图像分词器将像素量化为离散token (其中,,为下采样因子,表示图像码本索引)。这些个token按光栅顺序排列,用于训练基于Transformer的自回归模型。生成时通过最大化每个token的似然值,采用通用语言建模(LM)目标自回归预测下一个token:
其中表示视觉token,为LLM参数。最终VQ-VAE的 detokenizer将token还原为图像像素。
视觉生成与理解的统一预训练范式
为实现统一预训练,MLLM需具备视觉生成能力。如预备知识所述,现有方法(如Lumina-mGPT)通常使用VQ-VAE编码图像,但这些token缺乏语义信息,影响下游任务性能。此外,当前方法需从零训练,依赖大规模数据集且无法利用现有LLM知识。
我们的方法基于任意使用ViT编码器的现有MLLM构建,保持原有架构以兼容预训练权重。唯一修改是将VQ-VAE的图像码本加入大模型的词汇表,将词汇空间扩展到涵盖视觉和文本的多模态空间。这一增强使MLLM能预测图像token,并通过VQ-VAE detokenizer还原图像。
视觉理解预训练
为在预训练阶段保留原始MLLM的语义理解能力(如图2左部所示),我们沿用前人方法,采用VQA任务。给定图像-文本问答对,其中为当前场景的环视图像,为指令问题,模型生成答案:
视觉生成预训练
受自动驾驶中生成未来帧以学习物理规律的世界模型启发,激活视觉生成能力后,我们让VLM预测未来帧。给定图像-指令对,模型通过自回归生成预测未来前视帧的下一个视觉token:
预测的token通过VQ-VAE detokenizer还原为像素。由于视频数据集中天然存在未来帧且无需标注,此方法可利用大量视频数据提升生成质量。
渐进式图像生成
直接生成完整未来场景可能违反物理规律。因此,在预训练阶段,我们提出渐进式(由易到难)生成方法,结合车道线分割和3D检测标注数据。在生成未来帧token 前,先利用VLM的世界知识推理车道线token (作为道路场景骨架以定义可行驶区域,施加静态物理约束),再推理3D检测框token (表示关键物体运动模式,施加动态物理约束)。这一渐进序列引导模型推断未来场景的结构布局和几何细节,最终生成符合物理规律的预测:
基于时空链式思考的视觉推理
自动驾驶规划需不仅理解当前场景,还需预见未来演变。此过程应模拟物理世界而非纯文本逻辑推理。由于模型已在预训练阶段学习物理约束,且为提高效率,我们不再单独生成车道线、3D检测和未来帧,而是将其整合为统一帧。如图2右部所示,VLM作为世界模型生成预测未来状态的统一图像帧:借鉴视觉提示工程(用红圈引导注意力)和VLIPP(先预测边界框引入物理先验),我们在预测帧中用红色车道线和3D检测框表示未来空间关系。这些粗粒度视觉线索引导模型关注可行驶区域和关键物体,同时施加物理约束。时间关系则由普通未来帧体现,视觉内容的动态演变直观呈现时间进展。随后,时空链式思考作为中间推理步骤,使VLM作为逆动力学模型,基于当前观测和未来预测规划轨迹:
实验结果分析




结论
本文提出了FSDrive,一种基于时空CoT的自动驾驶框架,使视觉语言模型(VLMs)能够可视化地思考。通过中间图像形式的推理步骤,将未来场景生成与感知结果统一起来,FSDrive有效消除了跨模态转换带来的语义鸿沟,并建立了端到端的视觉推理流程。该视觉语言模型承担双重角色:作为世界模型,通过车道线分隔线和三维检测预测未来图像帧;同时作为逆动力学模型,基于当前观测和未来预测共同规划行驶轨迹。为实现VLM的视觉生成能力,我们提出了融合视觉生成与理解的预训练范式,并设计了渐进式由易到难地生成制以增强自回归图像生成效果。大量实验结果验证了FSDrive方法的有效性,推动自动驾驶技术迈向视觉推理。
#DriveGEN
生成模型全面提升视觉3D感知鲁棒性
随着新能源汽车产业的持续发展,智能驾驶辅助技术的应用越来越广泛。其中,基于纯视觉的自动驾驶方案只需使用多视角图像进行环境感知与分析,具有成本低、效率高的优势,因而备受关注。然而在实际应用中,视觉感知模型的泛化能力至关重要。来自香港中文大学(深圳)等单位的学者们提出了一种名为DriveGEN 的无训练自动驾驶图像可控生成方法。该方法无需额外训练生成模型,即可实现训练图像数据的可控扩充,从而以较低的计算资源成本提升三维检测模型的鲁棒性。DriveGEN通过"自注意力物体原型提取"和"原型引导生成"的两阶段策略,在准确保留三维物体信息的前提下,将训练数据扩展至各类现实但难以采集的场景(如恶劣天气),目前代码已开源。
任务背景
据路透社消息1,作为自动驾驶行业领先者的Waymo于2025年5月14日宣布召回超过1200辆自动驾驶车辆,原因在于算法在识别链条、闸门等道路障碍物时存在潜在风险,自动驾驶再次陷入安全风波。

图1 行业领先者的Waymo于近期宣布召回超过1200辆自动驾驶车辆
诸如此类事件的背后共同折射出一个深层的技术难题:即使是最先进的自动驾驶系统,在面对真实世界场景时,仍然需要着重考虑系统的鲁棒性 。一条普通的施工链条、一个临时设置的闸门,就可能成为算法的盲区。
自动驾驶中视觉感知模型的鲁棒性至关重要
不难看出,视觉感知模型的鲁棒性直接影响系统能否可靠地理解复杂的环境并做出安全的决策,其对驾驶安全至关重要。然而,传统的机器学习方法通常依赖大量预先收集的训练数据,而实际部署环境中的数据分布往往与训练时不同,这种现象称为"分布偏移"。通俗地说,就像学生备考时只复习了往年的题型,而正式考试却出了很多新题,导致很难发挥出应有水平。 在自动驾驶中,分布偏移可能表现为天气状况与光照条件的变化,或因车辆行驶时的摄像头抖动导致的画面模糊等情况。这些常见但棘手的分布偏移问题会严重影响视觉感知模型的性能,往往导致性能显著下降,严重制约了其在现实场景的广泛部署与应用。
自动驾驶中分布偏移的解决难点是什么?
要解决分布偏移问题并不容易,因为用于训练的数据大部分来自理想的天气状况(如晴天),而那些特殊天气(如大雪、大雾、沙尘暴)的数据很难大量获得,采集起来成本高,标注起来也费时费力。实际上,我们在自然环境下就会观察到这种明显的场景"数量不均衡":晴天的数据特别多,而雪天甚至沙尘暴的场景却非常少,有些情况甚至根本从未被模型见过。这就像一个长期生活在南方的人,从来没有在雪天里开过车,第一次遇到大雪路面时,很难马上做出正确、安全的驾驶决策。同样的,自动驾驶模型在面对这种未曾经历过或极少见的场景时,也难以保证稳定可靠的表现。
那么该如何解决分布偏移呢? 为了应对在实际应用中可能出现的各种场景,以及算法对快速扩展和实时响应能力的要求,我们不禁思考:**是否能通过数据可控扩增的方法,将已有的训练图像转化为一些尚未出现或极少出现的场景呢?**其中,一种可行的范式是无训练可控生成(Training-free Controllable Image Generation)。该范式在生成新图像的过程中不对生成模型本身的参数做任何修改,而是通过用户输入的文本指令,灵活地控制生成的图像效果,如图2所示。这种方式不仅成本低、效率高,还能够快速实现,因此引起学术界和工业界越来越多的关注。

图2 生成模型快速赋能自动驾驶视觉感知模型示意图
现存无训练可控生成方法主要面向通用图像编辑
无训练可控生成方法简单来说,就是在无需额外训练模型的情况下,对图像进行灵活且可控的编辑。目前该类方法主要用于通用图像修改,比如可以对图像主体进行变换,或添加、删除特定物体,快速生成所需图像内容。然而,在借助该技术将感知任务的训练图像扩充到各类分布偏移场景时,必须确保物体的三维信息与原始标注相匹配 ,否则就会给视觉感知模型带来额外噪音干扰。
技术方案
基于前面的讨论,我们不禁思考:**要怎么去设计一个无需额外训练的可控生成方法,在准确保留物体三维信息的前提下,实现感知模型训练图像的可控扩充?**来自香港中文大学(深圳)等单位的学者们给出了他们的看法。学者们提出了一个名为DriveGEN的方法,如图3所示。该方法由以下两个阶段所组成:1)自注意力物体原型提取;2)原型引导图像生成。具体细节阐述如下:

图3 DriveGEN方法整体框架图
自注意力物体原型提取
该阶段旨在获取带有几何信息的标注物体特征,从而为后续引导图像生成奠定基础。如图3上半部分所示,给定输入图像及其文本描述,通过DDIM Inversion可以得到时序潜空间特征,再输入到生成模型(U-Net based)进行生成。从中提取解码器的首层自注意力特征用于主成分分析,所得到的图像主成分带有丰富的语义信息2。然而,现存方法往往通过类别名称与图像特征之间的交叉注意力掩码以选取前景区域,学者们发现这很可能会产生物体信息遗漏,尤其是对那些体积相对小的物体。因此,给定标注物体区域下的某一点(p, q),学者们引入一个峰值函数为掩码中的每个物体区域进行重新加权:
最终,借助带有准确物体区域信息的指导,对图像主成分进行重加权从而得到自注意力物体原型。
原型引导图像生成
该阶段会通过两个层级的特征对齐以确保生成过程中,物体的三维信息能够被更好地保留。一方面,由于解码器的首层自注意力特征带有丰富的语义信息,DriveGEN设计了语义感知特征对齐项,旨在借助自注意力物体原型引导在转换图像场景时保留原有物体:
另一方面,学者们通过观察发现:在自动驾驶视觉感知中,相对深层的图像主成分难以精细地表示每个物体信息,尤其对小目标更是如此。举例而言,一个高20像素、宽5像素的行人框经多次(如32倍)下采样后,最终在主成分中无法占据一个独立的单元。因此,DriveGEN基于时序潜在特征对浅层特征进行对齐,以确保相对小的物体的信息也能够被准确保留:
最终,模型的整体优化目标为:
其中,代表无文本描述输入,DriveGEN 是一个基于无分类器引导3(classifier-free guidance)的过程。
实验
方法有效性
一方面,DriveGEN能为现存单目三维检测方法带来可观的性能提升,实验结果展示了探索的新方法可以在模拟的域外分布测试场景(包括Noise,Blur,Weather,Digital四类)中带来显著的改进:

表1 基于KITTI-C数据集的实验结果
其中分别探索了三种训练图像增广设定,即1)仅额外增广雪天(Only Snow aug.)下的场景;2)额外增广雪天、雨天和雾天下的场景(3 scenarios aug.);3)额外增广训练图像到雪、雨、雾、黑夜、失焦以及沙尘暴6种场景下(6 scenarios aug.),广泛地验证了所提出方法的有效性。

图4 基于KITTI-C数据集的实验结果(蓝色区域对应DriveGEN)
另一方面,DriveGEN基于现存多目三维检测方法做进一步实验,仅基于nuScenes数据集上五百个场景所增广的三千张雪天训练图片,即可为模型带来可观的性能提升:
表2 基于nuScenes-C以及真实场景下实验结果
其中nuScenes-C是应用更广泛但挑战难度更大的任务基准,而nuScenes-Night以及nuScenes-Rainy则代表两个真实的现实世界下分布偏移数据场景。
消融实验
如下图3所示,一方面表明了所提出方法各个优化项的有效性,比如加上物体原型能初步得到保留物体信息的生成结果,而浅层特征对齐则进一步促使生成模型能够比较好地保留在图片中相对小的物体。

图5 基于KITTI数据集的消融实验示意图
结果可视化
进一步提供了单目和多目的可视化结果如下图所示:
图6 基于KITTI数据集的单目三维检测图像增广示例

图7 基于nuScenes数据集的多目三维检测图像增广示例

基于上述实验结果,有理由相信通过对视觉三维检测训练数据的有效扩充,该论文所设计的方法能够有效地提高视觉感知模型的泛化性能,从而提升三维检测在自动驾驶中的落地和应用。
关于作者
论文第一作者林宏彬来自香港中文大学(深圳)理工学院的Deep Bit 实验室、深圳市未来智联网络研究院,导师为李镇老师。目前实验室的研究方向包括:自动驾驶、医学成像和分子理解的多模态数据分析和生成等。
感兴趣的同学可以浏览https://mypage.cuhk.edu.cn/academics/lizhen/。****
References:
2 Sicheng Mo, Fangzhou Mu, Kuan Heng Lin, Yanli Liu, Bochen Guan, Yin Li, and Bolei Zhou. Freecontrol: Training-free spatial control of any text-to-image diffusion model with any condition. In CVPR, 2024.
3 Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
#小米、商汤、理想汽车世界模型对比
垃圾大对比来了~~
图片来源:华中科技大学论文《The Role of World Models in Shaping Autonomous Driving: A Comprehensive Survey》
世界模型即利用历史场景观测信息加上预设条件预测未来智能驾驶场景变化和自车响应的模型。
图片来源:浙江大学论文《A Survey of World Models for Autonomous Driving》
世界模型的核心任务有两个:一个是预测未来场景,二是动作规划。实际两者可以看做一个任务,那就是预测未来场景与智能体做出的响应(动作规划)。世界模型从这两个核心任务出发,分为三大类:第一类是生成未来的物理世界;第二类是智能体的场景决策与动作规划;第三类实际是将前两类合二为一,既有生成物理世界也有场景决策和动作规划,同时也会增加智能体的数量,让智能体之间产生交互,从单一物理世界变为交通场景物理世界。
生成未来的物理世界,即合成高保真数据,这些数据可以做智能驾驶训练、场景理解、动作预测和仿真评估算法。场景决策和动作规划结合了基于规则的决策规划和基于数据学习的决策规划,采用代价函数优化,增强学习微调。目前业内主要工作是合成高保真数据做端到端智能驾驶训练,学术界则比较多研究场景决策和动作规划。
合成高保真数据方面分为三大类,2D、3D和无场景。
2D 场景方法主要利用生成技术(如自回归 Transformer 和diffusion模型)生成高保真、物理一致的驾驶场景:
- 时空动态捕获:GAIA-1 通过diffusion解码器捕获驾驶场景中的时空动态和高层结构。
- 多模态控制:DriveDreamer 扩展了条件diffusion框架,支持多模态控制和合成数据生成。
- 一致性提升:Vista 通过stable video diffusion 和新颖的损失函数,提升了场景生成的结构完整性和动态合理性。
3D 场景演化
- 3D 场景方法利用栅格占有occupancy和点云数据,捕获精确的空间几何关系和动态信息:Occupancy生成 OccWorld 使用时空 Transformer 生成未来场景和自车位姿,确保全局一致性。
- 点云生成:Copilot4D通过离散diffusion实现高效的点云生成和预测。
- 基于视觉的3D生成:ViDAR 从多视图图像预测未来点云演变,捕捉语义、3D结构和时间动态的协同学习。
- 多模态融合:BEVWorld 将图像和点云数据融合为统一的鸟瞰视图(BEV)表示,生成未来场景并支持自监督学习。
无场景不关注物理世界的逼真程度,主要关注时空联合一致性、多个智能体交互发生的真实性。
截止2025年1月的世界模型总结
表来源:华中科技大学论文《The Role of World Models in Shaping Autonomous Driving: A Comprehensive Survey》
目前世界模型合成数据发展方向有几个,一是高保真,特别是长时间高保真,领先企业是小米的MiLA。二是高帧率,多视角,高分辨率,领先企业是华为的MagicDrive。三是长视频,超过30秒,领先企业是商汤。四是3D,领先企业是理想汽车。
目前常见的世界模型生成视频对比
来源:论文《InfinityDrive: Breaking Time Limits in Driving World Models》,"Ours"指的是InfinityDrive
目前常见的世界模型生成视频对比,商汤的2分钟是目前最长的,视频越长,上下文关联性越强,包含的状态越多,场景越复杂,有助于提高智能驾驶复杂场景下的表现。
华为的MagicDriveDiT
图片来源:华为
华为的MagicDriveDiT,可以生成6个视角视频,帧率碾压其他模型,分辨率也是最高。
理想汽车的ReconDreamer,3D效果最好,即IoU分数最高
图片来源:理想汽车
评价视频生成主要指标有两个,即FID/FVD。
FID(Fréchet Inception Distance)是一种用于评估生成模型,尤其是在图像生成任务中,生成图像的质量和多样性的指标。它通过比较生成图像与真实图像在特定空间内的分布来工作。这个特定的空间通常是通过预训练的Inception网络的某一层来定义的。对于生成图像集和真实图像集,分别通过Inception网络(通常是Inception V3模型)计算它们的特征表示。这一步骤会得到每个图像集的特征向量。计算每个集合的特征向量的均值和协方差矩阵,并做对比。FVD和FID接近,相当于把FID的图像特征提取网络换成视频特征提取网络,其他都差不多。
小米MiLA FID和FVD成绩(数字越小,保真度越高)
来源:论文《InfnityDrive: Breaking Time Limits in Driving World Models》,这里的Ours就是商汤的InfinityDrive
来源:华为云和华为诺亚方舟实验室论文《MagicDrive-V2: High-Resolution Long Video Generation for Autonomous Driving with Adaptive Control》
单论FVD,小米的MiLA拥有绝对优势,不过帧率只有12Hz。人眼的帧率在50-220Hz之间,有研究表明飞行员平均人眼帧数为220Hz,而对于普通人而言大概是50-60Hz,智能驾驶的摄像头刷新频率一般是30Hz,少数低像素摄像头可以到45Hz。在这方面,小米MiLA还有很大的进步空间。
小米MiLA与其他世界模型生成视频对比
图片来源:小米论文《MiLA: Multi-view Intensive-fidelity Long-term Video Generation World Model for Autonomous Driving》
可以看出在保真度不高的生成视频模型上,8秒后红框内的车辆和右侧变得模糊。小米的MiLA可以在30秒内都保持清晰。
小米MiLA多视角表现
图片来源:小米论文《MiLA: Multi-view Intensive-fidelity Long-term Video Generation World Model for Autonomous Driving》
Open-Sora架构
图片来源:论文《Open-Sora: Democratizing Efficient Video Production for All》
小米MiLA并未有创新架构,其骨干网沿用了新加坡初创公司HPC-AI的Open-Sora,Open-Sora的参数量很低,在5.8亿到11亿之间。MiLA不包括VAE和T5文本编码的模型尺寸是7亿,训练视频分辨率是360*640。训练硬件平台是64个英伟达A100,Batch size是64。
MiLA架构
图片来源:小米论文《MiLA: Multi-view Intensive-fidelity Long-term Video Generation World Model for Autonomous Driving》
MiLA采用多级粗到细的生成框架,该方法首先生成低帧率的锚帧,然后在恢复锚帧的同时插值生成高帧率的帧,以保持长时间序列的保真度。初始阶段根据多个维度过滤视频,包括时间一致性和运动动态。细粒度筛选,利用视觉-语言模型生成信息丰富的字幕并过滤有问题的文本-视频对,以确保语义准确性。在(重)细化过程中,调整锚帧中的不现实运动,提高生成视频的整体质量和一致性。
细化后,Joint Denoising and Correcting Flow(联合去噪与校正流),该模块解决了预测锚帧中的缺陷,并通过同步增强低帧率锚帧和高帧率插值帧来优化整体视频的平滑性。Temporal Progressive Denoising Scheduler(时间渐进去噪调度器),该调度器通过基于先前生成的帧引导去噪过程,从而增强最终帧的保真度,使得早期帧可以以更大规模进行去噪。
目前端到端智能驾驶领域基本定型,那就是LLM做核心,做场景理解,MLP或扩散模型做路径规划,合起来就是VLA,LLM基本就是Qwen2.5,输入基本是BEV特征向量或者再加上激光雷达高斯分布。厂家的发力点转移到训练数据领域,真实采集视频有效率低于1%,必须有大量合成视频,即世界模型来帮助,目前技术方向五花八门,还看不到统一的可能,这就是八仙过海各显神通了。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。
#同济大学最新思维链综述
关于自动驾驶和思维链的一切~
自然语言处理中大型语言模型的快速发展大大提高了它们的语义理解和逻辑推理能力。这种熟练程度在自动驾驶系统中得到了利用,有助于显著提高系统性能。OpenAI o1和DeepSeek-R1等模型利用了思维链(CoT)推理,这是一种模拟人类思维过程的高级认知方法,在复杂任务中表现出卓越的推理能力。通过在系统推理框架内构建复杂的驾驶场景,这种方法已成为自动驾驶领域的一个突出研究重点,大大提高了系统处理具有挑战性案例的能力。本文研究了CoT方法如何提高自动驾驶模型的推理能力。基于全面的文献综述,我们对自动驾驶CoT的动机、方法、挑战和未来的研究方向进行了系统分析。此外,我们提出了将CoT与自学习相结合的见解,以促进驾驶系统的自进化。

自动驾驶的COT基础
本节深入探讨相关背景,从以下几个方面探索基础概念:自动驾驶(II-A)、大型语言模型在自动驾驶中的应用(II-B)以及链式思维(II-C)。
A. 自动驾驶的发展
自动驾驶技术近年来取得了显著进展。通过结合先进的传感器、算法和计算能力,自动驾驶系统能够感知环境、做出决策并控制车辆。然而,这些系统仍面临诸多挑战,例如复杂交通场景的理解和应对能力不足、决策过程缺乏透明性等。因此,提升系统的推理能力和可解释性成为研究的重点。
B. 大型语言模型在自动驾驶中的应用
大型语言模型(LLM)因其强大的自然语言处理和多模态推理能力,在自动驾驶领域得到了广泛关注。这些模型可以整合视觉、语言和其他模态数据,从而实现对复杂驾驶场景的全面理解。例如,一些研究尝试将LLM用于驾驶行为预测、风险评估和路径规划等任务。此外,LLM还可以通过生成类似于人类的推理链条,增强自动驾驶系统的可解释性和可信度。
C. 链式思维的概念与应用
链式思维是一种模拟人类逐步推理过程的方法,其核心思想是将复杂的决策问题分解为一系列逻辑连贯的中间步骤。这种方法不仅有助于提高系统的推理能力,还能为决策过程提供清晰的解释。在自动驾驶中,链式思维被应用于多种任务,例如驾驶意图推断、运动预测和场景理解。通过将链式思维与多模态数据相结合,研究人员进一步提升了自动驾驶系统在复杂环境中的表现。
本节旨在为链式思维提供简洁的背景介绍,并总结其后续发展,帮助读者清晰理解这些关键概念及其在自动驾驶中的应用。
自动驾驶中的COT方法
链式思维(Chain-of-Thought, CoT)方法正逐渐应用于自动驾驶领域,以增强系统在复杂环境中的推理能力和决策水平。本节从两个维度对现有方法进行系统分类:结构特征(III-A)和任务领域(III-B)。任务领域的视角侧重于CoT的具体应用,而结构特征的视角则揭示了CoT在结构设计上的差异。这种双重分类框架有助于全面回顾当前的研究成果。
A. 管道范式
本文将从管道范式的角度对自动驾驶中COT的结构特征进行深入分析。表I对自动驾驶COT模型进行了比较分析。

B. 结构特性

本节对自动驾驶中COT的结构特性进行详尽分析。目前的方法可以分为几种主要类型:反射性方法、生成性方法、模仿学习方法以及强化学习方法。每种方法在处理复杂驾驶场景时都有其独特的优劣势。
- 反射性方法:这类方法通过实时感知和快速响应来处理动态驾驶环境。例如,Agent-Driver模型利用多视图输入检测关键对象,并通过高级意图推断优化轨迹规划。
- 生成性方法:这些方法通过生成详细的推理链条来模拟人类的逐步思考过程。这种方法提高了系统的解释性和透明度,尤其是在复杂的决策过程中。
- 模仿学习方法:模仿学习方法通过模仿人类驾驶员的行为来训练自动驾驶系统。这种方法依赖大量的驾驶数据,并通过监督学习的方式提升系统的驾驶能力。
- 强化学习方法 :受到DeepSeek-R1语言模型技术方法的启发,强化CoT结合了强化学习(RL)与推理技术。在GRPO训练期间,DeepSeek-R1经历了"顿悟时刻",实现了长推理链条的涌现,同时显著减少了数据需求。这表明强化学习在将模型从模仿智能转变为涌现智能方面的潜力。强化CoT采用两步训练过程,在第一步中类似于模仿CoT,使用监督学习。
C. 任务领域
从任务领域的角度来看,CoT方法在自动驾驶中的应用包括但不限于以下方面:
- 感知与理解:通过多模态数据融合,CoT方法能够提高系统对驾驶环境的理解能力。例如,视觉问答(VQA)任务中的CoT应用能够通过理论测试分析视觉语言模型的推理能力。
- 行为预测:CoT方法在预测其他交通参与者的行为方面表现出色。通过结合常识知识和上下文理解,系统可以更准确地预测行人、车辆等的未来动作。
- 路径规划与决策:在复杂的驾驶场景中,CoT方法能够通过逐步推理生成合理的路径规划和决策策略。这种方法不仅提高了系统的决策水平,还增强了其可解释性。
- 端到端自动驾驶:端到端自动驾驶通过从感知到控制的统一建模简化了系统架构,但缺乏可解释性。引入CoT推理有助于构建统一的认知表示和透明的推理路径,从而增强系统的可验证性和可解释性。

数据集


挑战和未来前景
A.CoT在自动驾驶方面面临的挑战
虽然CoT推理在自动驾驶中的应用前景广阔,但在实践中仍面临几个关键挑战。根据对当前研究的回顾,这些挑战可以概括为四个关键方面:
- 跨模态差距:在CoT框架下,自动驾驶系统通常依赖于多种模式,如视觉、语言和运动。然而,在感知层面上,视觉和语义特征之间存在差异,导致场景理解中的模态间语义偏差。在复杂的驾驶场景中,当前的模型难以将关键图像细节准确地映射到高质量的语言描述中。此外,在从语义理解到动作执行的推理链中,随着CoT的展开,多步骤推理错误会累积,导致最终动作出现重大偏差。弥合跨模式差距是开发值得信赖的自主系统的基本要求。
- 与人类认知的一致性:CoT试图模拟人类的思维过程,以逐步完成推理任务。然而,人类的推理依赖于常识知识、领域专业知识和上下文理解。这些因素很难通过简单的规则或纯粹的数据驱动方法进行建模,导致生成的推理链与人类认知之间的不一致。确保CoT推理与人类思维过程保持一致,以提高系统的可解释性和可靠性,仍然是一个亟待解决的问题。
- 平衡推理深度和速度:CoT推理依赖于一系列中间步骤,这与自动驾驶的严格实时要求不符。当前的大规模预训练模型存在高延迟和巨大的计算成本,这使得它们在嵌入式、资源受限的平台上部署不切实际。在不影响决策质量的情况下,压缩推理链和计算负载是CoT部署的持续障碍。
- 安全验证:尽管CoT推理增强了可解释性,但它通过扩展推理链引入了不确定性。在极端情况下,系统可能会产生逻辑上连贯但事实上不正确的输出,称为大模型幻觉,导致误导性决策。在自动驾驶等安全关键任务中,即使是微小的错误也会产生严重的后果。CoT流程中缺乏动态风险评估和干预的稳健机制,这进一步增加了可靠部署的复杂性。
B.未来方向
- 干扰机制:在自动驾驶的复杂推理任务中,缺乏自校正机制可能会导致链式推理结构中单步错误的逐渐放大。建议在培训和测试阶段引入"干扰机制"。在训练过程中,可以通过系统地构建具有提示偏差、语义歧义和噪声干扰的训练案例来引入"对抗性QA干扰样本",以提高模型识别和处理异常输入的能力。同时,在验证阶段应进行动态干扰测试,以评估模型在模拟驾驶场景中的抗干扰性能。
- 高级CoT:目前,自动驾驶领域主要依赖于思维链进行多步推理,但其计算开销很大。最近的研究提出了明确紧凑的CoT变体,如草稿链,这显著提高了推理效率。此外,隐式潜在CoT变体通过大幅减少文本量和利用潜在状态压缩高级语义信息来实现低延迟响应,同时保持决策准确性,使其适用于自动驾驶应用。
- 协作快速和慢速思维:受人类神经机制研究的启发,一些研究采用了协作慢速和快速思维系统,该系统将快速直观推理与深入的逻辑分析相结合。这种方法在自动驾驶系统中动态分配计算资源,以实现推理深度和实时性能之间的平衡。
#数据稀缺时代的解法
Zero-Shot学习如何让机器人"无师自通"?
ZeroShot学习(ZeroShot Learning, ZSL)是xx智能(Embodied AI)领域的一项关键技术,它使机器人或智能体能够在未见过的任务、环境或硬件配置下直接执行操作,而无需额外的训练或微调。 我们从2025ICRA、CVPR、RSS会议中选取了几项相关研究,来对zeroshot的重要性一探究竟。
1. 解决数据稀缺问题,降低机器人训练成本
传统方法依赖大量真实世界数据或仿真训练,而数据收集(如机器人演示、环境建模)成本高昂。
ZeroShot方案(如VidBot、RoboSplat)利用合成数据、人类视频或单次演示生成泛化策略,减少对真实数据的依赖。例如: VidBot 仅需人类视频即可训练机器人操作策略,无需机器人专属数据。 RoboSplat 通过高斯泼溅技术,从单次演示生成多样化训练样本,数据效率提升50倍。
2. 实现跨平台、跨xx的泛化能力
机器人硬件形态多样(如不同自由度机械臂、多指灵巧手),传统方法需为每种硬件单独训练策略。
ZeroShot方法(如XMoP、UniGraspTransformer)通过统一表征学习,支持跨硬件迁移: XMoP 在7DoF机械臂上实现零样本运动规划,无需针对新机器人微调。 UniGraspTransformer 将数千种抓取策略蒸馏到单一网络,适配不同手型与物体。
3. 适应动态与未知环境
真实环境充满不确定性(如新物体、动态障碍),传统方法需在线学习或重新训练。
ZeroShot方法(如ZeroGrasp、NaVILA)通过多模态推理实时适应变化: ZeroGrasp 从单目图像重建未知物体3D形状并规划抓取,适用于工业分拣。 NaVILA 通过语言指令理解复杂导航任务(如"绕过障碍物"),无需预定义地图。
4. 推动机器人通用化(GeneralPurpose Robotics)
ZeroShot学习是迈向通用机器人(如"机器人ChatGPT")的关键步骤,使单一模型处理多任务: XMoP 和 UniGraspTransformer 证明统一策略可覆盖不同运动与操作任务。 NaVILA 结合视觉语言动作模型,实现开放指令下的自主决策。
5. 加速仿真到真实(SimtoReal)的迁移
传统SimtoReal依赖域随机化或精细调参,而ZeroShot方法(如RoboSplat)通过合成数据直接泛化到真实世界,成功率提升30%以上。
总结:ZeroShot学习的核心价值
- 降低成本:减少数据收集与训练时间。
- 增强泛化:跨硬件、跨任务、跨环境适用。
- 提升适应性:实时应对未知场景。
- 推动通用AI:迈向多任务、多模态的智能体。
XMoP: WholeBody Control Policy for Zeroshot CrossEmbodiment Neural Motion Planning
https://arxiv.org/pdf/2409.15585
会议/来源:ICRA 2025
文章提出了一种面向多机械臂的零样本跨xx运动规划框架 ,解决了传统神经运动规划(NMP)无法泛化到不同机器人形态的核心问题。其亮点在于首次实现了无需微调的跨xx泛化能力,通过合成数据训练的策略可直接部署到7种不同自由度(6DoF和7DoF)的商业机械臂上,在动态障碍环境中达到70%的平均规划成功率,并验证了从仿真到真实的强鲁棒性。
模型架构
- 配置空间(Cspace)的神经策略设计 XMoP的核心创新是将运动规划问题转化为链接级SE(3)位姿变换序列 的预测任务。模型输入为当前机械臂各连杆的SE(3)位姿序列(通过URDF解析)和环境的点云观测,输出为未来时间步的连杆位姿变换矩阵 T_{t+1:t+H} ,最终通过逆运动学求解关节空间轨迹。这种设计避免了传统任务空间策略对特定机器人形态的依赖,直接学习跨xx的运动约束。
- 基于扩散模型的策略学习采用扩散模型(Diffusion Policy)生成多步运动规划,通过逐步去噪过程增强轨迹的平滑性和碰撞规避能力。训练数据来自300万组程序化生成的合成机械臂(涵盖不同连杆长度、关节限制和自由度)在多样化环境中的规划演示,利用OMPL生成专家轨迹。
- 零样本泛化机制
- 物理描述编码:通过URDF文件动态编码新机械臂的形态学参数(如连杆几何、关节限制),使策略能自适应不同构型空间。
- 碰撞检测模块(XCoD):联合训练一个3D语义分割模型,以98%的召回率检测跨xx环境中的碰撞区域,与规划策略形成模型预测控制(MPC)闭环。
- 仿真到真实的迁移 尽管完全基于合成数据训练,XMoP在Franka FR3和Sawyer等真实机械臂上展示了零样本部署能力,成功处理动态障碍(如移动物体)和长程规划任务。其泛化性源于合成数据对运动学分布的充分覆盖,以及SE(3)位姿表示对形态变化的解耦特性。
ZeroGrasp: ZeroShot Shape Reconstruction Enabled Robotic Grasping
https://arxiv.org/pdf/2504.10857
会议/来源:CVPR 2025
文章提出了一种突破性的机器人抓取框架,通过零样本3D形状重建与抓取位姿预测的联合优化,实现了对未知物体的实时、高成功率抓取。其核心亮点在于无需物体先验数据,仅凭单目RGB或RGBD输入即可完成复杂场景下的几何推理与抓取规划,在GraspNet1B基准测试和真实机器人实验中分别达到92.4%的抓取成功率,显著优于传统需要物体特定训练的抓取方法。
模型架构
- 多任务联合学习框架ZeroGrasp采用神经隐式表示(Neural Implicit Representation)统一形状重建与抓取预测任务。输入的单视角图像通过共享的视觉编码器(如ResNet50)提取特征,随后分两路处理:
- 形状重建分支:基于Occupancy Networks生成连续的3D占用场,通过可微分渲染与输入图像对齐,重建被遮挡部分的几何结构。
- 抓取预测分支:结合重建的3D几何与物理约束(如摩擦系数、力闭合条件),输出6DoF抓取位姿及夹持器参数。
- 大规模合成数据驱动训练数据来自包含12000个ObjaverseLVIS物体的合成数据集,涵盖100万张照片级渲染图像、高精度3D重建及113亿组物理验证的抓取标注。通过域随机化(Domain Randomization)增强光照、纹理多样性,确保仿真到真实的零样本迁移能力。
- 空间关系与遮挡推理创新性地引入图注意力机制(GAT)建模物体间的空间关系,例如堆叠物体的分离边界预测,避免抓取时的碰撞。实验表明,该设计使系统在杂乱场景中的抓取成功率提升19%。
- 实时性能优化采用轻量级网络架构与并行计算流水线,在NVIDIA Jetson AGX上实现200ms内的端到端推理,满足实时操作需求。
NaVILA: Legged Robot VisionLanguageAction Model for Navigation
https://arxiv.org/pdf/2412.04453
会议/来源:RSS 2025
文章提出了一种突破性的两级框架,通过结合视觉语言动作(VLA)模型与实时运动控制策略,实现了腿式机器人(如四足/人形机器人)在复杂场景下的零样本语言指令导航。其核心亮点在于无需预训练仿真器或特定机器人数据,即可将自然语言指令(如"绕过障碍物并找到红色门")直接转化为跨平台的关节动作,在真实世界的Unitree Go2/G1等机器人上达到88%的导航成功率,较传统方法提升17%。
模型架构
- 两级分层框架设计
- 高层VLA指令生成:基于视觉语言模型(VLM)处理单目RGB输入和语言指令,通过视觉编码器(ResNet)+投影器(MLP)+LLM的架构,输出自然语言形式的中间指令(如"向左转30°并前进1米")。创新性地引入导航提示机制,区分历史帧与当前观测,确保多步任务的可追踪性。
- 低层运动策略:采用强化学习(PPO)训练的实时控制模块,将高层指令转化为1218个关节的精确运动。通过LiDAR构建高度图并随机化域参数,显著降低仿真到真实的差距。该策略以10Hz频率运行,支持动态避障与复杂地形穿越。
- 多模态数据训练与泛化能力
- 训练数据融合了YouTube人类游览视频(20K轨迹)、仿真导航数据(Isaac Lab)及通用VQA数据集,通过熵采样增强指令多样性。VLA部分通过监督微调实现跨模态对齐,而运动策略仅需仿真训练即可零样本迁移至真实机器人。
- 提出的VLNCEIsaac基准包含高保真物理模拟场景,支持评估低层控制与语言理解的协同性能,在透明表面、崎岖地形等挑战性场景中成功率提升14%。
- 实时性与安全机制
- 采用双频运行架构:VLA以1Hz生成高层指令,而运动策略以10Hz实时调整动作,平衡规划与执行效率。通过LiDAR的实时高度图分析,有效识别玻璃门等透明障碍物,避免碰撞。
VidBot: Learning Generalizable 3D Actions from IntheWild 2D Human Videos for ZeroShot Robotic Manipulation
https://arxiv.org/pdf/2503.07135
会议/来源:CVPR 2025
文章提出了一种突破性的框架,通过从单目RGB人类视频中学习与xx无关的3D动作表征,实现了机器人零样本操作任务泛化。其核心亮点在于无需机器人专属演示数据,仅利用互联网海量人类视频(如EpicKitchens100数据集)即可训练模型,在13项家务任务(如开关橱柜、推抽屉)的零样本测试中成功率显著超越基线方法,并可直接部署到Stretch 3等真实机器人平台。
模型架构
- 3D Affordance表征提取流水线VidBot首先通过运动恢复结构(SfM)和度量深度基础模型(如90)从单目视频中重建3D手部轨迹,并优化相机姿态与全局尺度一致性。结合手部物体分割掩码,提取时空对齐的接触点(c)和交互轨迹(τ),形成3D Affordance表征 a = {c, τ}。这一流程解决了传统方法依赖静态摄像机或深度传感器的限制。
- 由粗到细的Affordance学习框架
- 粗略模型(π_c):基于ResNet的编码器从RGBD输入中预测目标点(g)和接触点(c),通过高斯混合模型拟合概率分布,并引入辅助向量场损失增强空间感知。
- 精细模型(π_f):采用条件扩散模型生成细粒度交互轨迹,以粗略预测为条件,并集成碰撞规避、法线对齐等测试时成本函数引导轨迹优化。这种设计显著提升了新场景下的泛化能力。
- 多模态训练与泛化机制训练数据融合了18,726段人类视频和合成演示,通过语言视频对齐损失(余弦相似度)将视频嵌入与预训练语言向量(如CLIP)关联,确保语义一致性。在推理时,模型支持语言指令或视频输入,通过FiLM层调节策略网络,适配不同任务需求。
RoboSplat: Novel Demonstration Generation with Gaussian Splatting Enables Robust OneShot Manipulation
http://export.arxiv.org/pdf/2504.13175
会议/来源:RSS 2025
文章提出了一种基于3D高斯泼溅(Gaussian Splatting)的机器人示范生成框架,通过单次专家演示自动合成多样化、高质量的视觉动作训练数据,解决了传统机器人策略学习依赖海量人工数据的问题。其核心亮点在于仅需一条真实演示,即可生成覆盖6类泛化场景(如物体姿态、光照、相机视角等)的合成数据,在真实世界的抓取、关抽屉等任务中达到87.8%的平均成功率,较传统数据增强方法提升30.6%。
模型架构
- 3D高斯场景重建与编辑流水线
- 重建阶段:通过多视角RGBD输入,利用3D高斯泼溅技术(3DGS)重建场景的可微分3D高斯点云,每个高斯点包含位置、协方差、不透明度与球谐系数,支持高保真渲染。
- 编辑阶段:提出五大编辑技术:
- 高斯替换:替换物体类型或机器人形态(如将夹持器从二指改为三指);
- 等变变换:调整物体位姿(如旋转抽屉把手);
- 视觉属性编辑:动态修改光照与材质;
- 新视角合成:生成多摄像机视角的观测;
- 3D内容生成:添加未见过的物体(如不同形状的餐具)。
- 动作迁移与数据生成机制
- 将专家演示的末端执行器轨迹物理约束嵌入高斯点云,通过刚体动力学仿真迁移到编辑后的场景中,确保动作的物理合理性。例如,抓取轨迹会根据新物体的几何特征自动调整接触点。
- 引入自适应密度控制(ADC)优化高斯分布,避免编辑后的场景出现空洞或过饱和,提升合成数据的真实性。
- 策略训练与泛化验证
- 生成的数据用于训练视觉运动策略(如扩散策略),通过域随机化损失强制模型忽略无关特征(如纹理变化),专注于几何与动力学泛化。
- 在Franka Emika等真实机器人上验证了零样本迁移能力,尤其在动态干扰(如移动障碍物)下的成功率较基线提升47%。
UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping
https://arxiv.org/pdf/2412.02699
会议/来源:CVPR 2025
文章提出了一种基于Transformer的通用灵巧抓取框架,通过简化策略蒸馏流程实现了跨物体、跨形态的零样本泛化能力,其核心亮点在于仅需单次离线蒸馏即可将数千种物体的专用抓取策略统一到一个网络中,在仿真与真实场景中分别取得3.5%~10.1%的成功率提升。
模型架构
- 分层训练框架
- 专用策略生成:针对每个训练集物体,通过强化学习(PPO算法)训练独立的策略网络,输入包含272维状态向量(如关节角度、物体位姿、手物距离等),输出24维动作控制序列。训练时通过随机旋转物体增强初始姿态多样性。
- 轨迹数据集构建:每个专用网络生成1,000条成功抓取轨迹,最终形成包含320万条轨迹的大规模数据集,覆盖3,200种物体。
- Transformer蒸馏架构
- 多模态输入编码:将物体点云、机器人状态等异构数据通过线性投影统一为序列化向量,并加入时间嵌入编码时序信息。
- 12层自注意力块:通过堆叠自注意力层捕捉物体几何与动作的全局依赖关系,例如识别手柄与抓取方向的关联性。相比传统MLP网络,注意力机制显著提升了跨类别泛化能力。
- 监督蒸馏损失:采用L2损失对齐预测动作与专家轨迹,并引入多样性正则项避免抓取策略趋同(如UniDexGrasp++的重复抓取问题)。
- 双模态推理能力
- 状态模式:输入高精度仿真状态数据,成功率较基线提升7.7%(未见类别物体)。
- 视觉模式:处理噪声点云与估计位姿,通过跨模态注意力融合视觉特征与物理约束,真实机器人实验成功率超90%。
但Zero-Shot Learning(ZSL)也存在一些局限性:
1. 领域偏移(Domain Shift)问题
ZSL依赖训练阶段已知类别的特征分布来推断未知类别,但实际应用中,未见类别的特征分布可能与训练数据存在显著差异。例如,训练数据中的动物识别模型可能无法泛化到工业场景中的缺陷检测,因为纹理、光照等特征分布完全不同。
2. 语义表征的质量与局限性
ZSL需依赖辅助信息(如文本描述、知识图谱)建立已知与未知类别的关联,但语义表征的完整性和准确性直接影响模型性能: 人工标注 手动定义的属性(如"斑马有条纹")可能过于简化或遗漏关键特征(如条纹的密度变化)。 自动化嵌入可能无法捕捉领域特异性关系(如医疗术语的细微差异)。
3. 评估偏差与数据泄露风险
ZSL的评测标准常因数据设计问题导致性能被高估 : 数据集中已知和未知类别共享相同属性(如"有翅膀"同时描述鸟类和飞机),使模型通过简单关联而非真实理解完成任务。 模型可能在少数简单样本上表现良好,但面对真实世界的长尾分布(如工业缺陷的罕见类别)时失效。
4. 对预训练知识的强依赖
ZSL的性能高度依赖预训练模型的知识广度,但模型仅能处理与预训练任务相似的领域(如CLIP在视觉-文本对齐任务中表现优异,但对医疗图像的解释力有限)。
5. 复杂任务的处理能力不足
ZSL在需要多步推理或动态交互的任务中表现较差: 如VidBot从人类视频学习操作时,对透明物体或遮挡场景的轨迹预测误差较大。 在导航任务中,语言指令的歧义(如"绕过障碍物"未指定具体路径)可能导致决策失败。 根本原因是因为ZSL缺乏在线学习机制,无法通过环境反馈实时调整策略。
6. 数据效率与泛化的矛盾
尽管ZSL旨在减少数据依赖,但高质量预训练数据的需求反而增加: 如RoboSplat通过高斯泼溅生成数据,但对可变形物体(如绳索)的仿真精度不足。
ZSL的局限性本质是语义鸿沟 (训练与目标域的认知差距)与动态适应性不足的综合结果。当前研究通过以下方向突破:
- 跨模态增强:如检索增强分类(RAC)通过相似样本扩展上下文;
- 混合学习框架:结合Few-Shot微调提升特定任务鲁棒性;
- 仿真-真实协同:如工业场景中构建领域特异性基准。
#3DGS如何构建自动驾驶闭环仿真?
随着神经场景表征的发展,之前出现了一些方法尝试用神经辐射场重建街道场景。为了提高建模能力,Block-NeRF 将场景划分为几个块,并用 NeRF 网络表示每个块。虽然这种策略可以实现大规模街道场景的逼真渲染,但由于网络参数数量庞大,Block-NeRF 的训练时间较长。此外,它无法处理街道上的动态车辆,而这是自动驾驶环境模拟中的关键方面。最近,一些方法提出将动态驾驶场景表示为由前景移动汽车和静态背景组成的组合神经表示。为了处理动态汽车,他们利用跟踪的车辆姿态来建立观察空间和规范空间之间的映射,在那里他们使用 NeRF 网络来模拟汽车的几何形状和外观。虽然这些方法产生了合理的结果,但它们仍然局限于高训练成本和低渲染速度。
下图是在Waymo数据集上的渲染结果。street gaussians的方法在训练半小时内以 135 FPS的速度产生高质量的分辨率为1066×1600渲染视角。这两个基于NeRF的方法存在训练和渲染成本高的问题。
以前的方法通常面临训练和渲染速度慢以及车辆姿态跟踪不准确的挑战。给定从城市街道场景中的移动车辆捕获的一系列图像,street gaussians的目标是开发一个能够生成逼真图像以进行视图合成的高效模型。为了实现这一目标,street gaussians基于3DGS,提出了一种新颖的场景表示,专门用于建模动态街道场景。
动态城市街道场景表示为一组基于点的背景和前景物体,具有可优化的跟踪车辆姿势。每个点都分配有一个 3D 高斯,包括位置、不透明度和由旋转和缩放组成的协方差,以表示几何形状。为了表示外观,street gaussians为每个背景点分配一个球面谐波模型,而前景点与动态球面谐波模型相关联。显式的基于点的表示允许轻松组合单独的模型,从而实现高质量图像和语义图的实时渲染(如果在训练期间提供 2D 语义信息),以及分解前景对象来进行场景编辑。
Street Gaussians用单独的神经点云表示静态背景和每个移动车辆对象。
接下来,我将首先介绍它的背景模型,详细说明与对象模型共享的几个常见属性。随后,我将深入讲解它的动态物体模型设计。
背景模型表示为世界坐标系中的一组点。每个点都分配有一个 3D 高斯,来表示连续场景的几何形状和颜色。高斯参数由协方差矩阵 Σb 和位置向量 µb ∈ R3组成。为了避免优化过程中出现无效值,每个协方差矩阵进一步简化为缩放矩阵 Sb 和旋转矩阵 Rb,其中 Sb 以其对角线元素为特征,Rb 转换为单位四元数。协方差矩阵 Σb 可以从 Sb 和 Rb 中恢复。
除了位置和协方差矩阵之外,每个高斯还被分配一个不透明度值和一组球面谐波系数来表示场景几何和外观。为了获得与视图相关的颜色,球面谐波系数进一步乘以从视图方向投影的球面谐波基函数。为了表示3D语义信息,每个点都添加了一个语义的概率。
对于物体模型,考虑一个包含 N 个移动前景物体车辆的场景。每个物体都用一组可优化的跟踪车辆姿态和点云表示,其中每个点都分配有一个 3D 高斯、语义概率和动态外观模型。物体和背景的高斯属性相似,不透明度 αo 和比例矩阵 So 具有相同的含义。然而,它们的位置、旋转和外观模型与背景模型不同。位置 µo 和旋转 Ro 在物体局部坐标系中定义。为了将它们转换为世界坐标系(背景的坐标系),我们引入了物体跟踪姿势的定义。具体而言,车辆的跟踪姿势定义为一组旋转矩阵 {Rt} Nt t=1 和平移向量 {Tt} Nt t=1,其中 Nt 表示帧数。转换可以定义为:xxx。
其中 µw 和 Rw 分别是世界坐标系中相应物体的高斯分布的位置和旋转。经过变换后,物体的协方差矩阵 Σw 可以通过前面的公式 和 Rw 以及 So 得到。需要注意的是,street gaussians还发现现成跟踪器的跟踪车辆姿态有很多噪声。为了解决这个问题,street gaussians将跟踪车辆姿态视为可学习的参数。
但是仅用球谐函数系数表示物体外观不足以对移动车辆的外观进行建模,因为移动车辆的外观受其在全局坐标系场景中的位置影响。一种直接的解决方案是使用单独的球谐函数来建模每个时间点的物体。但是,这种建模会显著增加存储成本。相反,street gaussians引入 4D 球谐函数模型,用一组傅里叶变换系数 f ∈ R k 替换每个 SH 系数 zm,l,其中 k 是傅里叶系数的数量。给定时间点t,通过执行逆离散傅里叶变换来得到渲染特征:xxx。
利用所提出的模型,street gaussians将时间信息编码到外观中,而无需高存储成本。物体模型的语义表示与背景的语义表示不同。主要区别在于,物体模型的语义是一个可学习的一维标量,它表示来自跟踪器的车辆语义类别。
4D球谐函数的效果。第一行显示输入的序列图像,展示不同的外观。第二行演示了利用所提出的4D球谐函数对渲染结果的影响。如果没有4D球谐函数,则可以观察到明显的伪影。
3D Gaussian 中使用的 SfM 点云适用于以物体为中心的场景。然而,它不能为具有许多观察不足或无纹理区域的城市街道场景提供良好的初始化。street gaussians使用自车捕获的聚合 LiDAR 点云作为初始化。LiDAR 点云的颜色是通过投影到相应的图像平面并搜索像素值获得的。为了初始化物体模型,street gaussians首先收集 3D 边界框内的聚合点并将它们转换为局部坐标系。对于 LiDAR 点少于 2K 的对象,street gaussians改为在 3D 边界框内随机采样 8K 点作为初始化。对于背景模型,street gaussians对剩余的点云执行体素下采样并过滤掉训练相机不可见的点,并且结合 SfM 点云来弥补 LiDAR 在大面积上的有限覆盖范围。
#自动驾驶场景测试遇到瓶颈?
大语言模型是破局之道!
随着自动驾驶系统(ADS)逐步迈向量产落地,如何高效验证其安全性与可靠性成为关键问题。传统的实车测试动辄需要数亿公里的里程积累,不仅成本高、周期长,也很难覆盖那些"罕见但关键"的场景。于是,"场景测试"成为一种不可或缺的验证手段。
而最近,大语言模型(LLM)的崛起,也正在为自动驾驶测试领域注入全新活力。那么,大语言模型在场景测试中能扮演什么角色?又有哪些应用实践与挑战?本文将基于我们近期完成的一篇综述论文,带大家全面了解这一交叉前沿。
论文名称:A Survey on the Application of Large Language Models in Scenario-Based Testing of Automated Driving Systems
📌 论文链接:https://arxiv.org/abs/2505.16587****
一、为什么关注"大语言模型 + 场景测试"?
自动驾驶系统的验证不能靠"堆里程",而是要"造场景"。但传统的场景生成往往依赖人工脚本、规则库,效率低、不具备泛化能力。而大语言模型天生擅长语言理解与生成,具备:
- 🧠 强语言理解能力,可从自然语言中解析需求
- ✍️ 强生成能力,可自动构建脚本、代码、甚至完整场景
- 🔍 强知识泛化能力,可在未知场景中推理出潜在冲突或问题
这使得它们在自动驾驶的场景构建、执行、分析等多个阶段,都具备"参与感"。
二、大语言模型在哪些阶段"插得上手"?
我们将整个场景测试流程分为六大阶段,并分析LLM在每个阶段的作用:
✅ 1)场景源获取:从数据和知识中"挖故事"
- 数据合成:如用自然语言生成驾驶轨迹、视频;
- 风险分析辅助:LLM辅助进行HARA / STPA自动化;
- 数据标注与检索:自动标注Corner Case或进行语义检索。
📌 降低数据准备成本,是LLM的重要作用之一。
✅ 2)场景生成:最热也最成熟的应用方向
LLM可承担多种角色:
- 人机接口:将自然语言转换为结构化信息、代码、损失函数;
- 数据解释器:解析事故报告、地图等非结构化数据;
- 中间格式生成器:生成驾驶策略、行为、语义要素;
- 标准格式生成器:生成OpenSCENARIO、SUMO、SCENIC等格式;
- 端到端生成器:从"描述一个场景"到"输出可运行脚本"。
📌 当前应用最集中,相关文献数量最多的阶段!
✅ 3)场景库管理:被严重低估但极具潜力的环节
LLM未来可用于:
- 语义分类与去重;
- 物理一致性检查;
- 合规性审核与标签自动生成;
- 构建结构化数据库索引机制。
📌 目前仍是研究空白区,值得深入探索。
✅ 4)场景筛选:让测试更"接地气"
- 真实度评估:判断仿真轨迹是否合理;
- 合理性打分:生成"鲁棒性指标"筛选挑战性场景。
📌 辅助选出最有"测试价值"的场景。
✅ 5)测试执行:自动化程度再上台阶
- 异常检测:识别感知异常、行为异常;
- 仿真配置生成:快速搭建测试环境;
- 代码修复:自动修正脚本格式与逻辑;
- 闭环优化:结合仿真反馈迭代生成更合理场景。
📌 实现从"生成"到"执行"再到"优化"的自动闭环。
✅ 6)ADS评估:从数值走向"理解与解释"
- 生成评估报告:从仿真输出中提取关键指标并组织成文;
- 智能水平评估:模拟人类评估行为决策合理性;
- 法律责任解释:用于事故法律解释生成。
📌 提供从语言层面上"理解系统行为"的新思路。

三、已有研究的核心要素
我们系统分析了160+篇文献,提炼出以下研究要素:
- 📌 使用的LLM模型(GPT-4、Claude、LLaMA、LLaVA 等)
- 📌 应用策略:Zero-shot、Few-shot、Chain-of-Thought、格式约束等
- 📌 集成平台:CARLA, SUMO, LGSVL等为主流选择
- 📌 工业应用情况:51WORLD、华为、Applied Intuition已有部分探索
👉 整理为可视化表格和数据分析,详见我们搭建的项目仓库:
🔗 GitHub项目地址:https://github.com/ftgTUGraz/LLM4ADSTest****
四、未来的五大挑战
尽管发展迅猛,LLM落地仍有诸多挑战:
1️幻觉与输出不稳定
生成内容可能"编故事"或前后不一致,缺乏可控性。
2️仿真平台集成困难
脚本格式不统一,工具链碎片化,接口适配成本高。
3️缺乏ADS专属模型
通用模型难以理解场景语义或规则,推理能力有限。
4️场景库建设严重缺失
目前研究几乎不涉及"场景怎么存"和"怎么用"。
5️工业界应用仍有限
数据安全、法律责任、模型解释性等仍是痛点。
五、总结
大语言模型为自动驾驶场景测试带来了新的可能。它在数据准备、场景生成、仿真执行、测试评估等多个环节中展现出强大的能力,极大提升测试效率。然而,当前仍面临很多挑战与限制,尤其在工业部署层面。希望本综述能为大家理解"LLM + 场景测试"提供清晰框架。
#这家公司领跑AI数据标注与智能体协同新赛道
获亿元A轮融资加持!
近日,宁波博登智能科技有限公司(以下简称"博登智能")正式宣布完成亿元A轮融资。本轮融资由上海国际集团战略持有机构---国和投资进行独家投资。
国和投资人工智能基金负责人孙逸表示:"国和投资坚定看好人工智能带来的全产业变革中的投资机会,致力于以产业思维进行差异化布局。博登智能以稀缺的非结构化数据处理能力和全栈AI技术壁垒,精准卡位千亿级数据服务赛道。我们相信,博登智能凭借其深厚的技术积累和领先的行业洞察,将乘AI数据革命之风,持续领跑行业增长,为投资人创造长期价值。"
博登智能创始人兼董事长赵捷表示:"衷心感谢国和投资对博登智能技术实力与发展潜力的高度认可。本轮募集的资金将重点投入数据标注平台(BASE)及数据资产管理平台(Blink)的建设加强与新一代智能体平台(BBot)的创新研发上,通过'技术突破+人才驱动'双轮战略,加速博登智能在全球市场的产业布局。"
本融资战略规划
本轮融资标志着博登智能加速成为中国及全球市场的企业级 AI 基础数据服务领军者。资金将用于加速市场拓展、深化产品创新与全球化运营,以应对AI产业的增长需求。
重点方向包括:
- 产品矩阵:BASE数据标注平台、Blink数据资产管理平台、 BBot智能体开发平台的持续创新升级,形成数据产品的闭环。
- 全球市场:强化中国、中东、欧洲与北美市场布局,向全球市场输出AI数据解决方案。
- 人才梯队:扩充顶尖工程师与 AI 算法团队,确保在多模态大模型、语音智能、生成式AI等领域保持技术领先优势。
- 客户拓展:深耕自动驾驶、智慧医疗、大语言模型、具身智能机器人等行业,提供持续的数据解决方案。

博登智能市场布局
乘政策之东风,实现营收与规模双跃升
国家工业和信息化部最新数据显示,我国数据标注产业年产值已突破80亿元,成为数字经济领域的新增长点。这些趋势表明,在技术迭代与政策红利的双重驱动下,数据标注行业不仅将在国内市场形成规模化效应,更将在全球数据治理格局中占据重要席位。(数据标注产业的定义:数据标注产业是对数据进行筛选、清洗、分类、注释、标记和质量检验等加工处理的新型产业。来源:国家发改委)
过去3年来,博登智能年营收平均增长率高达104%,营收规模连续三年持续跃升。公司战略版图持续拓展,在北京、上海、广州、湖南、嘉兴设立子公司,标志着业务体系迈入矩阵化协同发展阶段。凭借在自动驾驶数据服务领域的技术深耕与规模化交付能力,公司入选"2025数据标注企业排行榜TOP5",综合排名及市场份额实现双提升,核心业务指标稳居行业第一梯队,预计2025年内稳居行业头部阵营,持续引领数据标注服务向高价值领域升级。
目前,博登智能已与自动驾驶(Autonomous Driving)、生成式人工智能(Generative AI)、具身智能(Embodied AI)、智慧医疗(Smart Healthcare)等高价值领域国内外超500余家顶级科技企业和科研机构建立了合作关系,是2024年度浙江省人工智能服务商、吉利优秀供应商、广州联通最佳合作伙伴,也是上海、浙江数据交易所挂牌数据服务商。
BASE平台:从"手工模式"到"AI工厂",让标注更精更泛化
在人工智能产业加速迭代的背景下,博登智能自主研发的BASE平台已完成第六代技术迭代。该平台深度整合智能体、多模态大模型和向量数据库等新质生产力,内嵌超100种预标注模型和智能化辅助标注工具,可提供覆盖数据采集、数据清洗、数据标注、数据合成及数据集构建的一站式数据处理服务,将传统"劳动密集型"的标注流程转化为"技术密集型",最高提升700%的标注效率,平均节省40%的成本,技术突破带来的效率提升,直接推动了博登智能在多个垂直领域的市场突破与生态布局。

博登智能全流程数据服务
博登智能依托算法体系构筑智能标注技术制高点,打造行业领先的智能标注技术内核,并在多个AI+高价值领域实现落地。
在非交互式算法领域,深度融合预训练模型库与迁移学习技术,构建高精度初始标注基线;通过弱监督学习、自监督优化与主动学习机制三维联动,构建模型自主进化能力,实现人工标注依赖度降低70%以上。其中,通用属性大模型基于多任务联合表征学习框架,消除跨场景标注冗余;专用分割模型搭载"预测-反馈-再训练"闭环系统,将逐步实现从辅助标注到全自动标注的技术跃迁。
通用大模型标注能力覆盖AI for Science全链条,包含OCR、数学公式解析、化学结构解析、生物数据处理等文件处理服务(数据清洗有效利用率超90%,隐私脱敏交付经验达10TB级),并适配医疗、新零售、遥感等行业的多模态场景(语义分割、目标检测、VQA)。
通过BASE平台智能调度机制,两类模型协同发力------定制模型聚焦垂直领域深度,通用模型强调跨域泛化(生成式AI标注平台准确率突破97%,交付周期缩短至3-5天),结合多任务联合表征与"预测-反馈-再训练"闭环,既保障行业场景的定制化效率,又通过标准化能力降低人工依赖,形成"专精+普适"的技术双轮驱动,全面支撑AI应用的规模化落地。

博登智能智能辅助标注工具下面是博登智能在高价值领域的支持:
1)面向自动驾驶场景(Autonomous Driving):博登智能自主研发的4D标注平台深度融合VLM(视觉语言模型)与VLA(视觉-语言-行动)解决方案,通过多模态对齐标注技术实现图像特征与自然语言描述的语义关联,构建包含交通场景理解、驾驶意图解析及行为决策逻辑的标注体系。
平台支持4D时空轨迹追踪与连续帧行为建模,精准还原复杂场景下"感知-理解-决策-执行"的闭环链路,已为车企L4级自动驾驶系统提供包含BEV+Transformer架构适配、多任务联合训练数据集及场景泛化增强方案的端到端训练框架。目前平台已服务主流汽车厂、Tier1厂商及造车新势力等头部客户,近三年业务量持续高速增长,累计合作金额高达上亿。

博登智能数据标注优势
2)面向生成式人工智能场景(Generative AI):博登智能率先推出的生成式AI标注平台深度融合CoT思维链推理、CUA上下文关联等前沿技术,构建覆盖文生图、文生视频、语音合成(TTS)、语音识别(ASR)的数据标注需求,通过动态增量标注、跨模态一致性校验及智能质量评估机制,为大模型训练提供高精准度数据闭环,已落地智慧医疗、金融保险等复杂领域,助力生成式AI实现认知跃迁与行业赋能。
3)面向智慧医疗场景(Smart Healthcare):医学影像标注平台兼容超声、CT、MRI、X光等主流医学影像格式,内置病灶跟踪及三维重建在内的多种高级功能,为医疗AI模型的高效训练与部署提供了强有力的支持。

博登智能医疗标注
Blink数据资产管理平台,让交付更准更高效
在生成式人工智能(AIGC)蓬勃发展的背景下,为了实现对海量数据的高效管理与精准交付,博登智能推出了集成筛选、标注、清洗、检索与交付功能于一体的数据资产管理平台Blink。
数据资产管理平台Blink现已成功接入超100个数据源,支持客户依据特定训练目标设定一系列复杂筛选条件(如时间区间、语言类别、内容主题、数据模态以及版权状态),并通过系统预设规则自动匹配并提取目标数据集,将平均交付周期压缩至3-5个工作日,准确率高达99%以上。入库数据均经过严格的质量评估与深度优化流程,在语义连贯性、视觉表现力和语音自然度等方面展现出卓越品质,并严格遵循国家法律法规及行业最高标准,确保数据使用的安全合规。
BBot智能体开发平台:让智能化转型更省更快速
随着AIGC技术范式迭代与垂直场景深化,智能体开发平台正成为产业智能化升级的核心基础设施。这类平台不仅需要算法架构的持续创新,更依赖高质量数据闭环体系的深度支撑。博登智能基于在数据采集、清洗、标注、合成领域沉淀的全栈式数据服务能力,通过构建多模态数据处理引擎及数据闭环体系,与智能体开发形成了天然的技术耦合性。

博登智能产品矩阵
作为企业智能化转型的关键载体,BBot构建的多模态交互体系支持文本、语音、图像等全场景交互方式,打造企业智能化沟通中枢。通过结合DocETL文档解析引擎,与流程自动化技术的深度耦合,系统可精准解析复杂业务场景并高效执行标准化流程。借助Workflow工作模块化架构设计、多Agent协作机制与丰富的插件生态,灵活适配金融、制造、医疗等行业特性,提供定制化智能体解决方案,企业可快速构建可用、可演进的智能体系统。

博登智能智能体平台页面
场景化优势应用案例:汽车测试助手与法律助手
- 博登智能助力某汽车研究所突破测试效率瓶颈,针对其研发人员在定位测试中频繁遭遇的技术难题和冗长的资料查阅流程,创新研发了汽车测试智能助手。数据显示,复杂问题平均处理时间较传统模式缩短50%,测试流程推进更为顺畅,使得产能得到了显著提高。

博登智能汽车测试助手页面
- 针对司法实践中证据调取效率低下这一行业痛点,创新研发法律智能助手系统。该系统通过自然语言处理与法律知识图谱的深度耦合,在实测中实现类案证据收集时长从传统8小时压缩至2.5小时,全流程检索耗时较人工模式降低70%。经实测验证,该系统使得单案件检索成本直降56%,成功替代初级律师60%的程式化检索工作,使资深律师专注核心法律判断。
未来已来,锚定AI3.0时代再起航
面向未来,博登智能将以本轮融资为起点,持续挖掘并整合全球顶尖的技术资源,以前沿的研究视角和深厚的技术积淀为依托,推动自身产品的迭代升级,构建"产学研用"战略级生态工程,联合全球顶尖高校及科研机构共建"数据+AI"联合创新实验室,积极参与构建更加高质、高效的人工智能生态系统,助力人工智能行业的繁荣发展。
关于国和投资
上海国和现代服务业股权投资管理有限公司(简称"国和投资")是上海国际集团战略持有机构,聚焦于产业升级和科技创新主题,长期围绕数字化、智能化和绿色化布局投资。系国内首批获得私募基金管理人资格的私募基金管理公司,清科"中国私募股权投资机构100强"、"中国国资投资机构50强",第一财经投融资价值榜"私募股权基金TOP30",连续四年(2020-2023)跻身险资私募股权管理人A类名单。
关于博登智能
宁波博登智能科技有限公司(BODEN AI)专注于为全球AI技术发展提供全栈式数据处理解决方案(Full-stack Data Processing Solutions)。凭借自主研发的BASE平台,为企业打造了一条涵盖数据采集、数据标注、数据脱敏至数据合成的全方位服务链,响应自动驾驶(Autonomous Driving)、生成式人工智能(Generative AI)、具身智能(Embodied AI)、智慧医疗(Smart Healthcare)、数字孪生(Digital Twin)等前沿行业对高质量数据集的需求。
博登智能核心服务涵盖数据标注、定制化数据集构建等环节,广泛适用于图像、视频、文本及传感器数据等多个数据维度。借助BASE平台的强大功能,公司实现了从数据上传至算法预标注的全链路自动化流程,有效加速AI企业的算法迭代进程,构建数据驱动的高效闭环。
迄今,博登智能已与包括英特尔、英伟达、吉利、中国联通、腾讯在内的近500家国内外知名企业建立了长期合作关系。持有数十项核心知识产权,并获ISO 9001、ISO 27001、ISO 14001等国际管理体系认证。
#CogAD
毫末智行CogAD:认知分层引导的端到端自动驾驶
摘要
本文介绍了CogAD:认知分层引导的端到端自动驾驶。尽管端到端自动驾驶已经取得了重大进步,但是主流方法在感知和规划方面仍然与人类认知原则不一致。本文提出了CogAD,这是一种新的端到端自动驾驶模型,它模拟了人类驾驶员的分层认知机制。CogAD实现了双层机制:用于类人感知的全局到局部的上下文处理和用于认知启发规划的意图条件多模态轨迹生成。所提出的方法具有三个主要优势:1)通过分层感知实现全面环境理解;2)通过多级规划实现鲁棒的规划探索;3)通过双层不确定性建模实现多样化但合理的多模态轨迹生成。在nuScenes和Bench2Drive上进行的大量实验表明,CogAD在端到端规划方面实现了最先进的性能,在长尾场景中展现出特别的优势,并且对复杂的现实世界驾驶条件具有鲁棒的泛化能力。
主要贡献
本文的主要贡献为如下三方面:
1)本文提出了一种分层场景实例感知范式,它显著地提高了自车的场景理解能力;
2)本文开发了一种分层意图轨迹规划机制,它同时增强了端到端自动驾驶中的行为多样性和运动合理性;
3)CogAD在开环和闭环评估中均实现了最先进的性能,与先前的方法相比,其在长尾场景中具有特别明显的改进。
论文图片和表格

总结
本文提出了CogAD,这是一种从认知科学的角度受到人类驾驶过程启发的分层端到端规划方法。对于分层感知,CogAD结合了BEV实例交互和跨任务实例交互,这显著提高了自车的场景理解能力。对于分层规划,CogAD利用了意图anchors和轨迹模式来确保生成轨迹的行为多样性和几何精度。大量评估表明,本文方法在开环和闭环基准上均实现了最先进的性能。
局限性:尽管本文方法在大量评估中表现出色,但是现实世界驾驶测试对于进一步验证仍然是必要的。此外,需要进一步研究模型扩展的影响,以潜在地提高CogAD的性能。
#GeoDrive
北大&理想提出:具有精确动作控制的3D几何信息世界模型
近年来,世界模型(world models)彻底改变了动态环境的仿真,使系统能够预见未来状态并评估潜在的操作。在自动驾驶领域,这些能力有助于车辆预判其他道路使用者的行为、进行风险感知规划、加速仿真中的训练,并适应新场景,从而提高安全性与可靠性。目前的方法在保持稳健的3D几何一致性或处理遮挡时存在缺陷,这两点对于可靠的自动驾驶安全评估至关重要。为了解决这些问题,我们提出了GeoDrive,它将稳健的3D几何条件明确地整合到驾驶世界模型中,以增强空间理解和操作可控性。具体来说,我们首先从输入帧中提取3D表示,然后基于用户指定的自车轨迹获得其2D渲染。为了实现动态建模,我们在训练期间提出了一种动态编辑模块,通过编辑车辆的位置来增强渲染效果。广泛的实验表明,我们的方法在动作准确性和3D空间感知方面显著优于现有模型,从而实现了更加真实、灵活和可靠的场景建模,提高了自动驾驶的安全性。此外,我们的模型可以推广到新的轨迹,并提供交互式场景编辑功能,如目标编辑和目标轨迹控制。

驾驶世界模型通过模拟三维动态环境,能够实现一系列关键功能,包括轨迹一致的视角合成、符合物理规律的运动预测以及安全感知的场景重建和生成。特别是,生成视频模型已成为自动驾驶系统中自车运动预测和动态场景重建的有效工具。它们能够合成与轨迹一致的视觉序列,这对于开发能够预见环境交互同时保持物理合理性的自主系统至关重要。
尽管取得了这些进展,大多数现有方法由于依赖二维空间优化,缺乏足够的三维几何感知能力。这种不足导致在新视角下的结构不连贯以及物理上不合理的目标交互,这对密集交通中的防碰撞等安全关键任务尤其有害。此外,现有的方法通常依赖于密集标注(例如高清地图序列和三维边界框轨迹)来实现可控性,仅能重现预定的动作,而无法理解车辆动力学。一种更灵活的方法是从单张(或少量)图像中推断动态先验,同时以期望的自车轨迹为条件。然而,当前基于数值相机参数进行微调的方法缺乏对三维几何的理解,从而影响了其动作可控性和一致性。
一个可靠的驾驶世界模型应满足三个标准:1)静态基础设施和动态智能体之间具有刚性的时空一致性;2)对自车轨迹的三维可控性;3)非自车智能体的运动模式需符合运动学约束。
我们通过一个混合神经-几何框架实现了这些需求,该框架显式地在整个生成序列中强制执行三维几何一致性。首先,我们从单目输入中构建三维结构先验,然后沿着用户指定的相机轨迹进行投影渲染,生成基于几何的条件信号。进一步采用级联视频扩散技术,通过三维注意力去噪来优化这些投影,共同优化光度质量和几何保真度。对于动态目标,我们引入了一个物理引导编辑模块,在显式运动约束下变换目标外观,确保物理合理的交互。
我们的实验表明,GeoDrive显著增强了可控驾驶世界模型的性能。具体而言,我们的方法提高了自车动作的可控性,相比Vista模型,轨迹跟踪误差减少了42%。此外,它在视频质量指标上也取得了显著提升,包括LPIPS、PSNR、SSIM、FID和FVD。此外,我们的模型能够有效地推广到新的视角合成任务,并且在生成视频质量上超越了StreetGaussian。除了轨迹条件,GeoDrive还提供了交互式场景编辑功能,如动态目标插入、替换和运动控制。此外,通过将实时视觉输入与预测建模相结合,我们提升了视觉-语言模型的决策过程,提供了一个交互式仿真环境,使路径规划更加安全和高效。
算法详解
给定一个初始参考图像 和自车轨迹 ,我们的框架合成了遵循输入轨迹的真实感未来帧。我们利用参考图像中的三维几何信息来指导世界建模。首先,我们重建一个三维表示(第3.1节),然后沿着用户指定的轨迹渲染视频序列并处理动态目标。渲染的视频提供了几何引导,以生成遵循输入轨迹且时空一致的视频。图2展示了整个流程。

从参考图像中提取三维表示
为了利用三维信息进行三维一致性生成,我们首先从单个输入图像 中构建三维表示。我们采用 MonST3R,这是一种现成的密集立体模型,可以同时预测三维几何和相机姿态,与我们的训练范式相一致。在推理过程中,我们复制参考图像以满足 MonST3R 的跨视图匹配要求。
给定 RGB 帧 ,MonST3R 通过跨帧特征匹配预测每个像素的三维坐标 和置信度分数 :
其中 表示第 t 个参考帧中像素 在度量空间中的位置, 测量重建的可靠性。通过对 进行阈值处理(通常为 ),第 t 个参考帧的彩色点云为:
为了对抗序列中有效匹配和无效匹配之间的不平衡,置信度图 使用焦点损失进行训练。此外,为了将静态场景几何与移动物体分离,MonST3R 使用基于Transformer的解耦器。该模块处理参考帧的初始特征(通过跨视图上下文丰富化),并将它们分为静态和动态组件。解耦器使用可学习的提示标记来分割注意力图:静态标记关注大型平面区域,动态标记关注紧凑、运动丰富的区域。通过排除动态对应关系,我们获得了一个稳健的相机姿态估计:
其中 表示透视投影算子,并且只使用静态特征匹配。与传统的运动恢复结构相比,这种策略在动态城市场景中减少了38%的姿态误差。得到的点云 成为我们几何支架的基础。
动态编辑下的三维视频渲染
为了实现精确的输入轨迹跟随,我们的模型渲染一个视频作为生成过程的视觉指南。我们将参考点云 通过每个用户提供的相机配置 使用标准的投影几何技术进行投影。每个三维点 经历刚性变换进入相机坐标系 ,然后使用相机的内参矩阵 进行透视投影,得到图像坐标:
我们只考虑深度范围内的有效投影 米,并使用 z 缓冲区处理遮挡,最终生成每个相机位置的渲染视图 。
静态渲染的局限性
由于我们仅使用第一帧的点云,渲染的场景在整个序列中保持静态。这与现实世界的自动驾驶情境存在显著差异,在那里车辆和其他动态物体不断运动。我们的渲染静态性质未能捕捉到区分自动驾驶数据集与传统静态场景的动态本质。
动态编辑
为了解决这一局限性,我们提出动态编辑以生成具有静态背景和移动车辆的渲染 。具体来说,当用户提供场景中移动车辆的一系列二维边界框信息时,我们动态调整其位置以在渲染中创建运动错觉。这种方法不仅在生成过程中引导自车的轨迹,还引导场景中其他车辆的移动。图3提供了这一过程的说明。这样的设计显著减少了静态渲染与动态现实场景之间的差异,同时实现了对其他车辆的灵活控制------这是现有方法如 Vista和 GAIA所无法实现的能力。

双分支控制以确保时空一致性
虽然基于点云的渲染准确地保留了视图之间的几何关系,但它在视觉质量方面存在一些问题。渲染的视图通常包含大量遮挡、因传感器覆盖范围有限而导致的缺失区域,以及与真实相机图像相比降低的视觉保真度。为了提高质量,我们适应了一个潜在视频扩散模型来细化投影视图,同时通过特殊条件保持三维结构保真度。
在此基础上,我们进一步改进了将上下文特征集成到预训练扩散Transformer(DiT)中的方式,借鉴了 VideoPainter引入的方法。然而,我们引入了针对特定需求的关键区别。我们使用动态渲染来捕捉时间和上下文细微差别,为生成过程提供更适应性的表示。设 表示我们修改后的 DiT 主干 在第 i 层的特征输出,其中 表示通过 VAE 编码器 的动态渲染潜变量, 是时间步 t 的噪声潜变量。
这些渲染通过一个轻量级条件编码器进行处理,该编码器提取必要的背景线索而不重复主干架构的大部分部分。将条件编码器的特征整合到冻结的 DiT 中的公式如下:
其中 表示处理噪声潜变量 和渲染潜变量 的连接输入的条件编码器, 表示 DiT 主干中的总层数。 是一个可学习的线性变换,初始化为零,以防止在早期训练中噪声崩溃。提取的特征以结构化的方式选择性地融合到冻结的 DiT 中,确保只有相关的上下文信息引导生成过程。最终的视频序列通过冻结的 VAE 解码器 解码为 。
实验结果








结论
我们提出了 GeoDrive,这是一种用于自动驾驶的视频扩散世界模型,通过显式的米级轨迹控制和直接的视觉条件输入增强了动作可控性和空间准确性。我们的方法重建了三维场景,沿着期望的轨迹进行渲染,并使用视频扩散优化输出。评估表明,我们的模型在视觉真实感和动作一致性方面显著优于现有模型,支持诸如非自车视角生成和场景编辑等应用,从而设定了新的基准。
然而,我们的性能依赖于 MonST3R 对深度和姿态估计的准确性,仅依靠图像和轨迹输入进行世界预测仍具有挑战性。未来的工作将探索结合文本条件和 VLA 理解以进一步提高真实感和一致性。