神经网络类算法
-
前馈神经网络(FFNN):基础结构,信息单向流动,适用于简单任务如手写数字识别 。
-
卷积神经网络(CNN):专为网格数据设计,通过卷积核和池化操作处理图像、音频等数据,广泛应用于图像分类、目标检测 。
-
循环神经网络(RNN):处理序列数据,但存在梯度消失问题,变体如LSTM和GRU改进了长期依赖处理能力 。
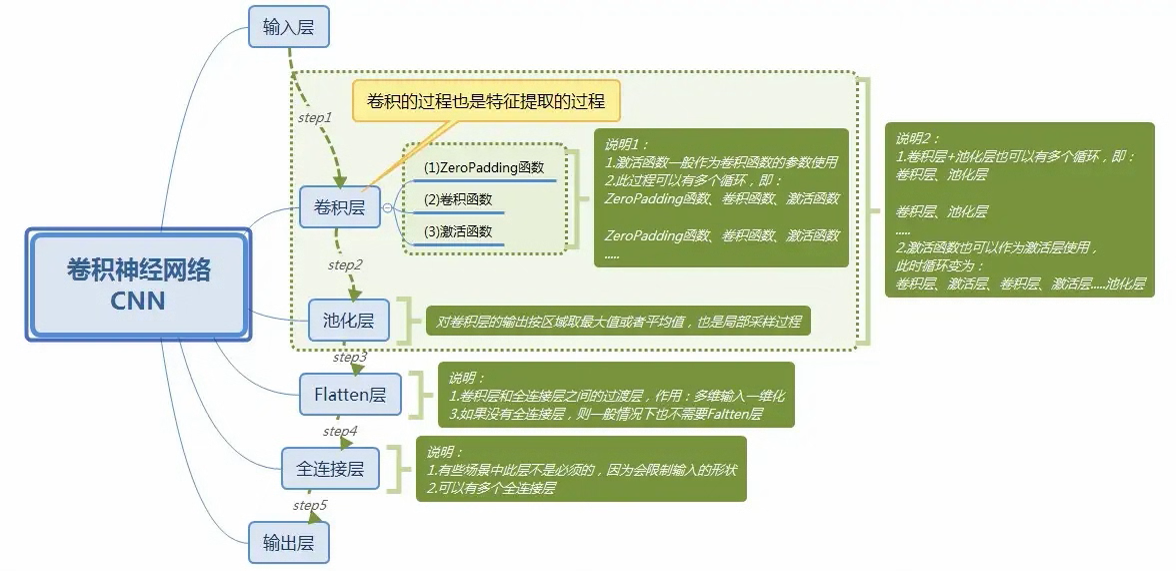
卷积神经网络(CNN)
参考链接:https://cloud.tencent.com/developer/article/2391027
卷积神经网络(Convolutional Neural Network,CNN)是一种专门为处理具有网格结构数据(如图像、音频)而设计的深度学习模型,在计算机视觉领域大放异彩。以图像识别为例,CNN 的局部连接特性使其能够聚焦于图像的局部区域,就像我们观察一幅画时,会先关注画中的某个局部细节,而不是一下子看遍整个画面。它通过卷积核在图像上滑动,对每个局部区域进行特征提取,这样大大减少了需要处理的参数数量,提高了计算效率。它们的设计灵感来自于生物学中的视觉系统,旨在模拟人类视觉处理的方式。在过去的几年中,CNN已经在图像识别、目标检测、图像生成和许多其他领域取得了显著的进展,成为了计算机视觉和深度学习研究的重要组成部分。
传统神经网络原理如下图:
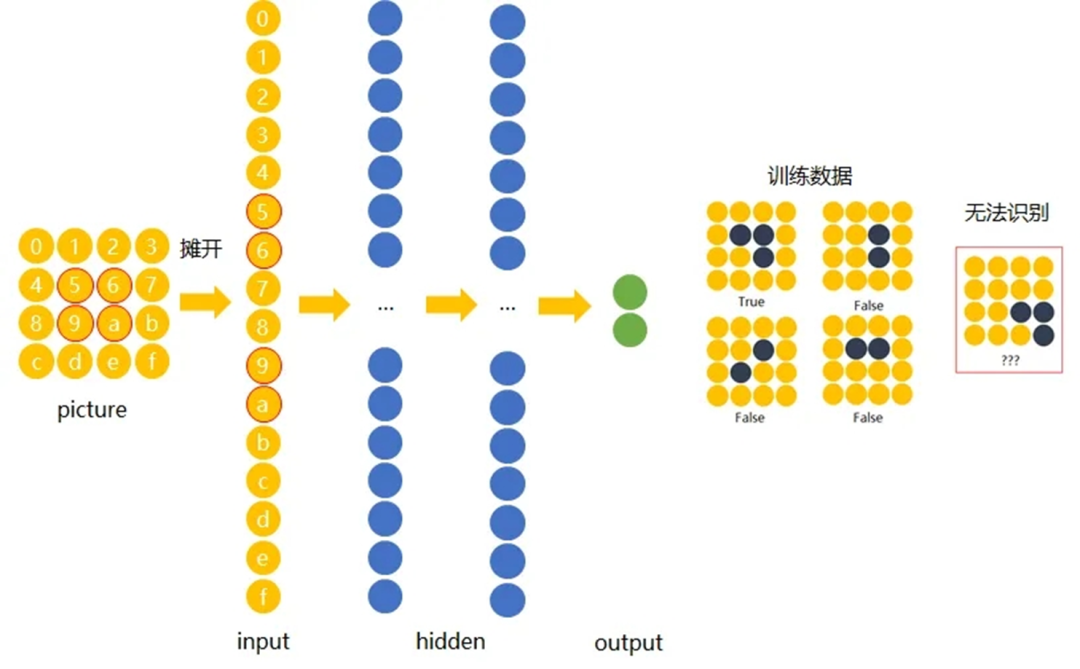
我们希望一个物体不管在画面左侧还是右侧,都会被识别为同一物体,这一特点就是不变性。为了实现平移不变性,卷积神经网络(CNN)等深度学习模型在卷积层中使用了卷积操作,这个操作可以捕捉到图像中的局部特征而不受其位置的影响。
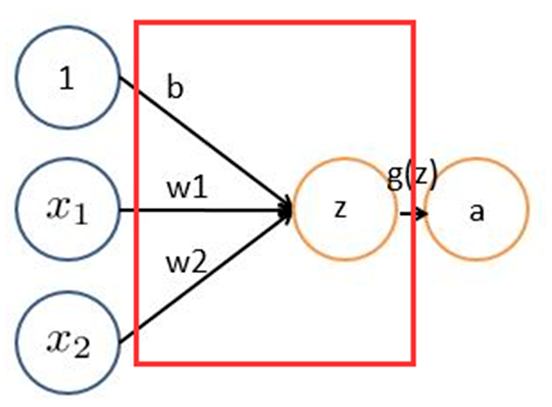
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。CNN一个非常重要的特点就是头重脚轻(越往输入权值越小,越往输出权值越多),呈现出一个倒三角的形态,这就很好地避免了BP神经网络中反向传播的时候梯度损失得太快。
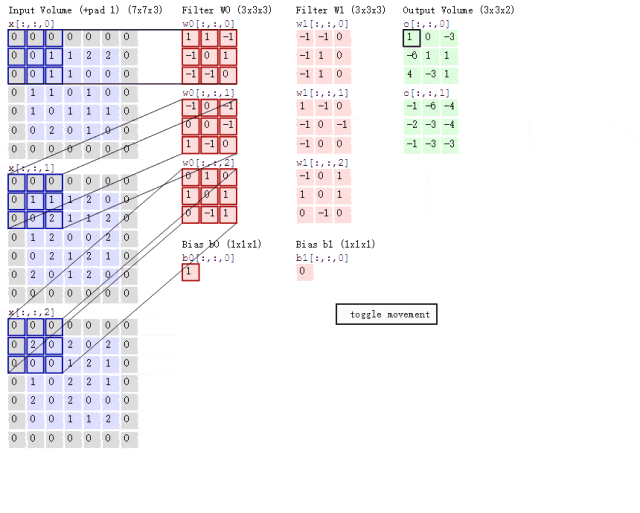
什么是卷积
在卷积神经网络中,卷积操作是指将一个可移动的小窗口(称为数据窗口,如下图绿色矩形)与图像进行逐元素相乘然后相加的操作。这个小窗口其实是一组固定的权重,它可以被看作是一个特定的滤波器(filter)或卷积核。这个操作的名称"卷积",源自于这种元素级相乘和求和的过程。简而言之,卷积操作就是用一个可移动的小窗口来提取图像中的特征,这个小窗口包含了一组特定的权重,通过与图像的不同位置进行卷积操作,网络能够学习并捕捉到不同特征的信息。这张图中蓝色的框就是指一个数据窗口,红色框为卷积核(滤波器),最后得到的绿色方形就是卷积的结果(数据窗口中的数据与卷积核逐个元素相乘再求和)。
卷积神经网络的原理
下面红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层。
1 输入层:输入层接收原始图像数据。图像通常由三个颜色通道(红、绿、蓝)组成,形成一个二维矩阵,表示像素的强度值。
2 卷积和激活:卷积层将输入图像与卷积核进行卷积操作。然后,通过应用激活函数(如ReLU)来引入非线性。这一步使网络能够学习复杂的特征。
3 池化层:池化层通过减小特征图的大小来减少计算复杂性。它通过选择池化窗口内的最大值或平均值来实现。这有助于提取最重要的特征。
4 多层堆叠:CNN通常由多个卷积和池化层的堆叠组成,以逐渐提取更高级别的特征。深层次的特征可以表示更复杂的模式。
5 全连接和输出:最后,全连接层将提取的特征映射转化为网络的最终输出。这可以是一个分类标签、回归值或其他任务的结果。
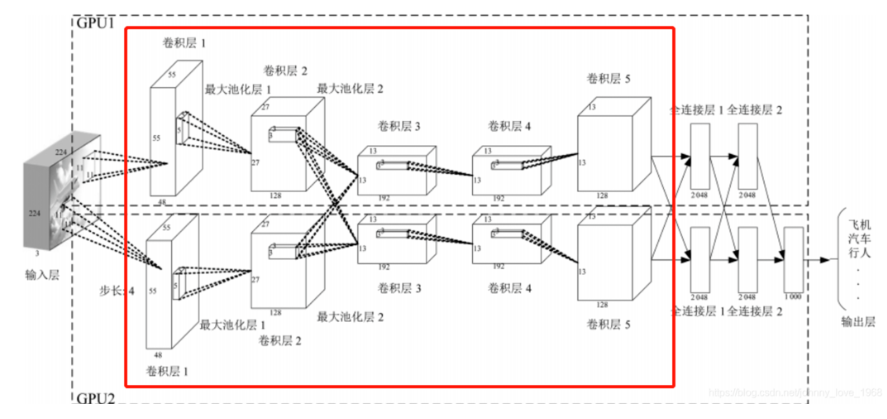
卷积层
卷积层(Convolutional Layer)将输入图像与卷积核进行卷积操作,初步提取特征。然后,通过应用激活函数(如ReLU)来引入非线性。这一步使网络能够学习复杂的特征。
卷积层的作用就是提取图片每个小部分里具有的特征。假定我们有一个尺寸为 6∗6 的图像,每一个像素点里都存储着图像的信息。我们再定义一个卷积核(相当于权重),用来从图像中提取一定的特征。卷积核与数字矩阵对应位相乘再相加,得到卷积层输出结果。
机器一开始并不知道要识别的部分具有哪些特征,是通过与不同的卷积核相作用得到的输出值,相互比较来判断哪一个卷积核最能表现该图片的特征------比如我们要识别图像中的某种特征(比如曲线),也就是说,这个卷积核要对这种曲线有很高的输出值,对其他形状(比如三角形)则输出较低。卷积层输出值越高,就说明匹配程度越高,越能表现该图片的特征。
卷积层的作用其实就是通过不断的改变卷积核,来确定能初步表征图片特征的有用的卷积核是哪些,再得到与相应的卷积核相乘后的输出矩阵。
池化层
池化层(Pooling Layer)池化层的输入就是卷积层输出的原数据与相应的卷积核相乘后的输出矩阵。这有助于提取最重要的特征。
池化层的目的:
- 为了减少训练参数的数量,降低卷积层输出的特征向量的维度
- 减小过拟合现象,只保留最有用的图片信息,减少噪声的传递
最常见的两种池化层的形式: - 最大池化:max-pooling------选取指定区域内最大的一个数来代表整片区域
- 均值池化:mean-pooling------选取指定区域内数值的平均值来代表整片区域(Average Pooling)
举例说明两种池化方式:(池化步长为2,选取过的区域,下一次就不再选取)
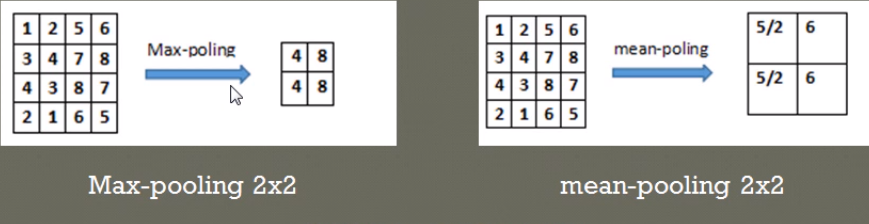
在 4∗4 的数字矩阵里,以步长 2∗2 选取区域,比如上左将区域1,2,3,4中最大的值4池化输出;上右将区域1,2,3,4中平均值5/2池化输出。
全连接层
最后,全连接层(Fully Connected Layer)将各部分特征汇总,将提取的特征映射转化为网络的最终输出。这可以是一个分类标签、回归值或其他任务的结果。例如产生分类器(classifier),进行预测识别。
卷积层和池化层的工作就是提取特征,并减少原始图像带来的参数。然而,为了生成最终的输出,我们需要应用全连接层来生成一个等于我们需要的类的数量的分类器。全连接层的工作原理和之前的神经网络学习很类似,我们需要把池化层输出的张量重新切割成一些向量,乘上权重矩阵,加上偏置值,然后对其使用ReLU激活函数,用梯度下降法优化参数既可。
Python示例
参考链接:https://www.cnblogs.com/haohai9309/p/18211716
使用Keras库构建和训练一个简单神经网络模型来处理鸢尾花(Iris)数据集:
模型的设定
- Sequential:用于创建一个按顺序添加层的神经网络模型。
- Dense:用于创建一个全连接层。
- Activation:用于指定层的激活函数。
有两种方式来设定模型:
方式一:将网络层实例列表直接传递给Sequential构造函数。
方式二:先创建一个Sequential模型,然后使用add()方法依次添加各层。
python
#导入Keras库和相关模块
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.utils import to_categorical
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
#Iris数据集的导入和切分及标准化
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
#load\_iris**:导入鸢尾花数据集,train\_test\_split**:将数据集划分为训练集和测试集,测试集占30%
#StandardScaler:对训练集和测试集进行标准化处理
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
#因变量转换为哑变量
#to\_categorical:将分类标签转换为独热编码(One-Hot Encoding)
y_train = to_categorical(y_train, 3)
y_test = to_categorical(y_test, 3)
#建立神经网络模型三部曲
#建立模型
model = Sequential([
Dense(10, input_shape=(4,)),
Activation('sigmoid'),
Dense(10),
Activation('relu'),
Dense(10),
Activation('tanh'),
Dense(3),
Activation('softmax')
])
# 编译模型
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
#compile:指定损失函数为categorical_crossentropy,优化器为rmsprop,评估标准为accuracy
# 训练模型
history = model.fit(X_train, y_train, epochs=100, batch_size=5, verbose=1)
#fit:使用训练集数据和标签训练模型,指定训练的轮数(epochs)
#模型评价与预测
#evaluate:在测试集上评估模型的性能,打印测试集上的损失函数和预测准确率。
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f'Test loss: {loss:.4f}')
print(f'Test accuracy: {accuracy:.4f}')
#predict:对测试集进行预测,打印预测结果及其形状
predictions = model.predict(X_test)
print(predictions)
print(predictions.shape)
#可视化展示
#使用matplotlib.pyplot绘制训练过程中的准确率和损失函数变化图
plt.plot(history.history['accuracy'])
plt.plot(history.history['loss'])
plt.title('Model accuracy and loss')
plt.xlabel('Epoch')
plt.legend(['Accuracy', 'Loss'], loc='upper left')
plt.show()
ory['loss'])
plt.title('Model accuracy and loss')
plt.xlabel('Epoch')
plt.legend(['Accuracy', 'Loss'], loc='upper left')
plt.show()