目录
写在前面
DeepSeek今天(12月1日)同步推出两款正式版本AI模型DeepSeek-V3.2和DeepSeek-V3.2-Speciale,前者主打日常应用场景,后者在多项国际竞赛中获得金牌。这标志着开源模型与闭源商业模型的性能差距进一步缩小。
而给我印象最深的,是**思考模式与工具调用机制无缝融合!**在此之前,即便是具备思考模式的模型(如 o1),在推理过程中也无法主动调用外部工具,而 V3.2 打破了这一长期存在的限制,使推理链路更加完整、灵活且具备更强的实用价值。
下面我们就来看看V3.2有哪些新东西。
技术文档地址: https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2/resolve/master/assets/paper.pdf
一、技术突破的三个层面就像搭积木
1.效率革命:稀疏注意力是真正的"智能筛选器"
想象一下,你要在1000页的文档里找特定信息,传统方法是逐页翻阅,而DSA就像有个智能助手帮你快速定位关键页。这个"闪电索引器"能实时判断哪些信息值得关注,哪些可以忽略,让长文本处理速度大幅提升。
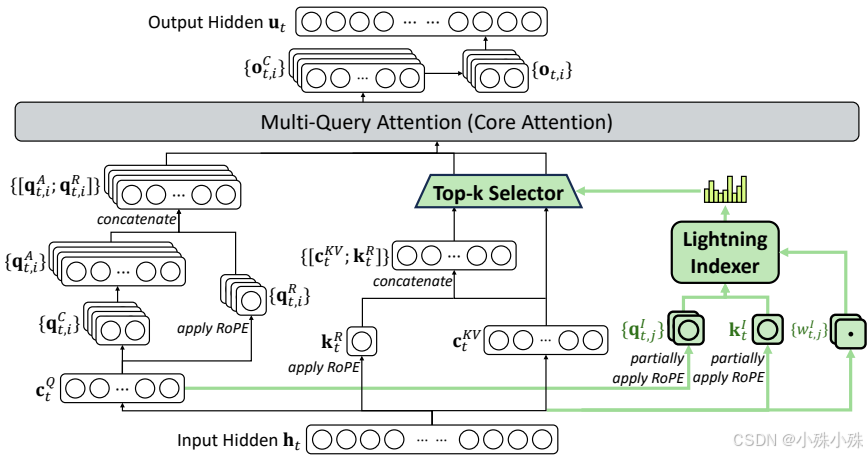
具体来说,它通过两个步骤工作:先快速扫描所有信息给出重要性评分,然后只挑选得分最高的2048个关键点进行深度处理。这种"先粗选后精加工"的模式,既保证了质量又提升了效率。
2.训练升级:强化学习投入堪比"重金培养"
研究人员在后期训练阶段投入了巨额计算资源,超过预训练成本的10%。这就像不仅给孩子打好基础教育,还额外请了顶级专家进行专项特训。特别是DeepSeek-V3.2-Speciale版本,就像奥运选手的强化训练营,通过减少输出长度限制,让模型能够进行更深入的思考推理。
3.实践能力:智能体训练如同"实战演习"
通过构建1800多个虚拟环境和8.5万个复杂任务,模型就像在模拟现实中接受全方位训练。从代码调试到旅行规划,从数据分析到问题解决,这种大规模、多场景的训练让模型具备了真正的工具使用能力。
二、性能表现堪称"全能选手"
在具体测试中,DeepSeek-V3.2展现出了令人印象深刻的全面能力:
在学术能力方面,它在MMLU-Pro、GPQA等专业考试中与顶尖模型旗鼓相当;在编程领域,Codeforces评分达到2386,具备解决复杂算法问题的能力;在数学竞赛中,AIME 2025得分率93.1%,HMMT数学竞赛更是达到90%以上的准确率。
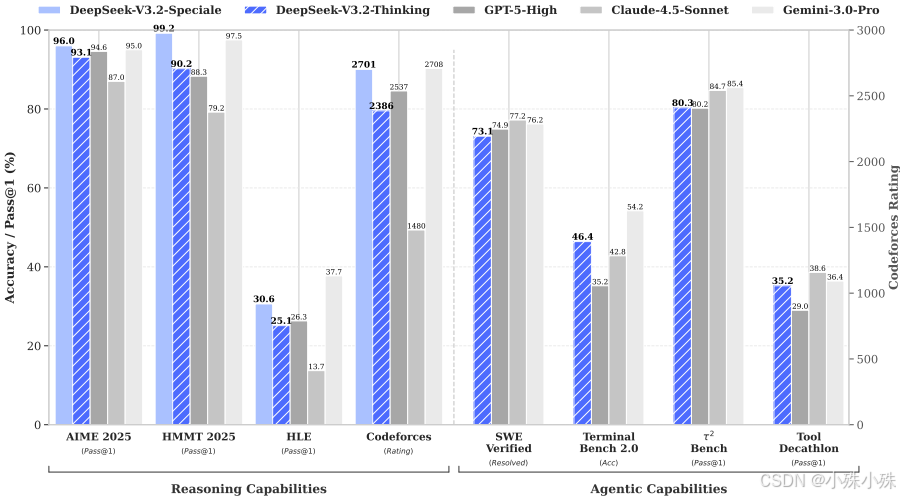
特别值得一提的是其特别版在顶级竞赛中的表现:在IOI 2025中获得492/600分(金牌级别),在ICPC世界总决赛中解决10/12道难题,在IMO国际数学奥林匹克中获得35/42分,充分证明了其在复杂推理方面的顶尖实力。
三、实用价值体现在"性价比优势"
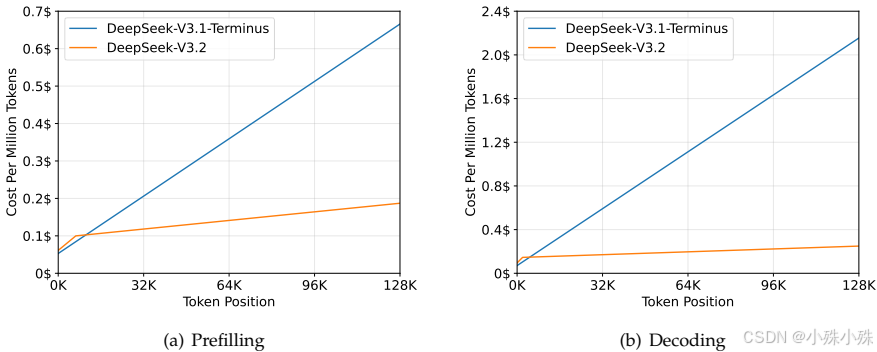
1.成本控制有妙招
通过稀疏注意力机制,在长文本处理时的推理成本显著降低。从图表可以看出,随着序列长度增加,V3.2的成本增长远低于前代版本。
2.上下文管理智能
当处理超长文档时,模型会智能地总结或丢弃部分历史信息,确保思考过程的连续性。这种"断点续传"能力让它在浏览任务中表现尤为出色。
3.工具使用自然流畅
模型学会了在思考过程中自然调用工具,比如在解决数学问题时使用Python验证思路,在规划旅行时智能查询信息,这种"边想边做"的模式更接近人类的解决问题方式。
四、开源生态的重要意义
DeepSeek-V3.2的成功最大的意义在于证明了开源模型同样可以达到商用顶尖水平。它缩小了开源与闭源模型之间的性能差距,为整个AI社区提供了高质量的基础模型,这将加速人工智能技术的普及和创新。
总的来说,DeepSeek-V3.2不仅在技术指标上表现出色,更重要的是它找到了一条高效、实用、可扩展的发展路径,为未来大模型的发展指明了方向。
关注不迷路(*^▽^*),暴富入口==》 https://bbs.csdn.net/topics/619691583