文章目录
- DeepSeek
- [DeepSeek 私有化部署](#DeepSeek 私有化部署)
- [算例市场: autoDL](#算例市场: autoDL)
- [VllM 使用](#VllM 使用)
- Ollma
- [复习 API 调用deepseek-r1](#复习 API 调用deepseek-r1)
- [Prompt 提示词工程](#Prompt 提示词工程)
- [Prompt 实战](#Prompt 实战)
-
- [设置API Key](#设置API Key)
- [cot 示例](#cot 示例)
- [prompt 优化 prompt](#prompt 优化 prompt)
- note
DeepSeek
Deepseek 的创新
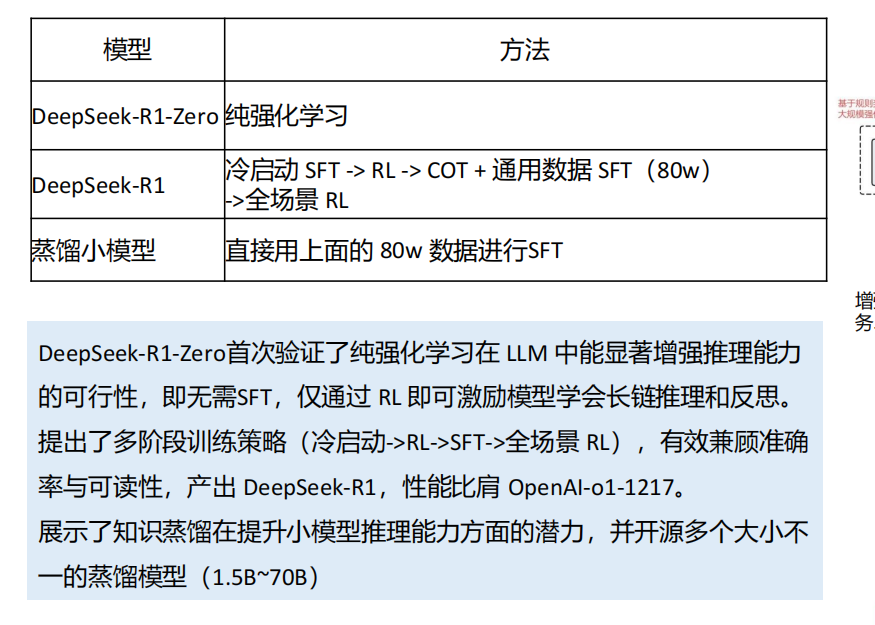
Deepseek-v3的推出是2024年12月,并没有太大波澜Deepseek-R1火出圈,通过新的奖励机制GRPO(group relative policy optimization),并使用规则类验证机制自动对输出进行打分。以v3为基础模型,一个多月内训练出了性能堪比GPT-o1的R1模型,成果非常亮眼。
DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。
DeepSeek-R1 上线 API,对用户开放思维链输出,通过设置 model='deepseek-reasoner' 即可调用。
MLA (低秩近似)
MLA(Multi-Head Latent Attention)在"All you need is attention"的背景下,传统的多头注意力(MHA,Multi-Head Attention)的键值(KV)缓存机制事实上对计算效率形成了较大阻碍。缩小KV缓存(kv Cache)大小,并提高性能,在之前的模型架构中并未很好的解决。
Deepseek引入了ML,一种通过低秩键值联合压缩的注意力机制,在显著减小KV缓存的同时提高计算效率。
低秩近似是快速矩阵计算的常用方法,在MLA之前很少用于大模型计算。
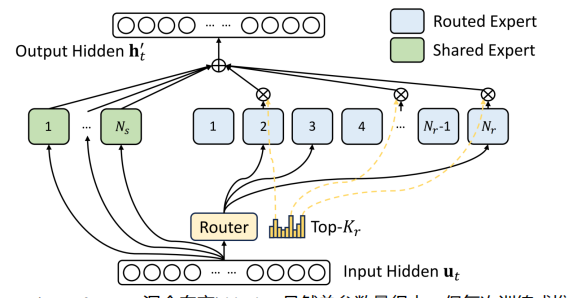
MOE 混合专家
V3使用了61个MoE (Mix of Expert 混合专家) block,虽然总参数量很大,但每次训练或推理时只激活了很少链路,训练成本大大降低,推理速度显著提高。
MoE类比为医院的分诊台,在过去所有病人都要找全科医生,效率很低。但是MoE模型相当于有一个分诊台将病人分配到不同的专科医生那里。Deepseek在这方面也有创新,之前分诊是完全没有医学知识的保安而现在用的是有医学知识的本科生来处理分流任务。
混合精度框架
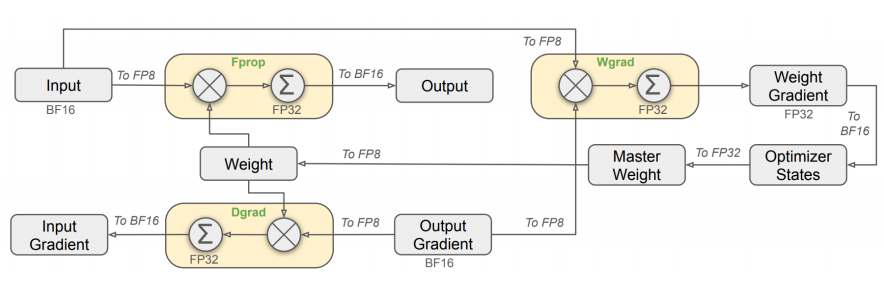
采用了混合精度框架,即在不同的区块里使用不同的精度来存储数据。我们知道精度越高,内存占用越多,运算复杂度越大。Deepseek在一些不需要很高精度的模块,使用很低的精度FP8储存数据,极大的降低了训练计算量。
总结
(1)为什么能实现成本低,计算速度快
- 架构设计方面
DeepSeek MoE架构:在推理时仅激活部分专家,避免了激活所有参数带来的计算资源浪费。
ML架构:MLA通过降秩KV矩阵,减少了显存消耗。 - 训练策略方面
多token预测(MTP)目标:在训练过程中采用多token预测目标,即在每个位置上预测多个未来token,增加了训练信号的密度,提高了数据效率。
混合精度训练框架:在训练中,对于占据大量计算量的通用矩阵乘法(GEMM)操作,采用FP8精度执行。同时,通过细粒度量化策略和高精度累积过程,解决了低精度训练中出现的量化误差问题
(2)为什么DeepSeek-R1的推理能力强大?
**强化学习驱动:**Deepseek-R1通过大规模强化学习技术显著提升了推理能力。在数学、代码和自然语言推理等任务上表现出色,性能与0penAl的o1正式版相当。
长链推理(CoT)技术:Deepseek-R1采用长链推理技术,其思维链长度可达数万字,能够逐步分解复杂问题,通过多步骤的逻辑推理来解决问题
强化学习的作用 :训练大模型,结合少量SFT(监督学习),引入少量高质量监督数据(如数千个CoT示例)进行微调,提升模型初始推理能力,再通过RL进一步优化,最终达到与0penAlo1相当的性能
长链推理CoT :COT让AI模型逐步分解复杂问题,比如在智能客服、市场分析报告、AI辅助编程领域
R1-Zero, AlphaGo-Zero 都是纯强化学习,也就是人没有标注数据,是完全是由机器自我进行学习,掌握的技能
Reward-Model 用于对强化学习的打分
1)对输出的结果正确性进行打分 (因为我们知道真正的Answer)
2)对输出的结构进行打分
1)硬规则
针对结构化标签,
- 结果的评价
首选 answer进行评价,
数据集也会首选 理科类的测试题 => 有标准答案
3)
先给出再给出
reward model 规则是人定的,但是分是机器打的
- AI大模型趋势 :
1)模型越来越大
671B => 旗舰版 (如果要部署满血版,需要16块H800,大约200万-300万)
2)蒸馏小模型超越 OpenAI o1-mini
模型越来越小 => 可以在端侧,可以在手机,可以在个人电脑进行部署 (可以部署的设备非常的广泛)
Qwen3
https://modelscope.cn/models/Qwen/Qwen3-235B-A22B
Qwen3-4B 以及达到了 Qwen2.5-72B的水平
https://modelscope.cn/models/Qwen/Qwen3-4B
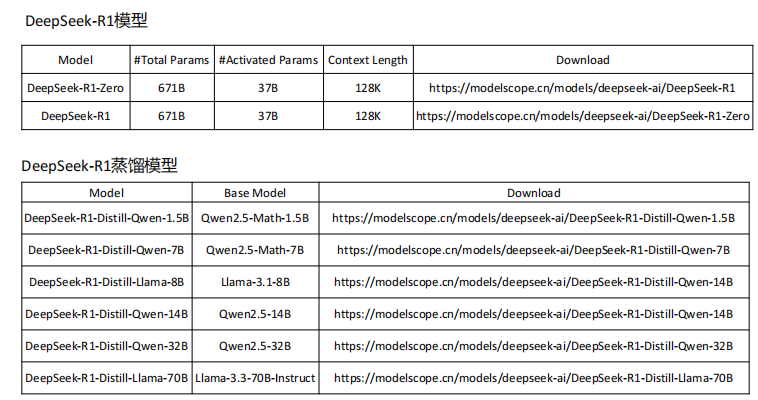
DeepSeek-V3 与 DeepSeek R1
Thinking:当我们写程序的时候,什么时候用 DeepSeek-V3-0324,什么时候用 Deepseek-R1?V3-0324:日常编程、快速开发、前端代码生成、常规脚本任务。R1:数学密集型计算、复杂算法、代码逻辑深度优化、需要推理过程的任务,=>更擅长复杂算法实现,能优化逻辑并减少错误
DeepSeek 私有化部署
Q:如何找到大模型的原文件
https://modelscope.cn/search?search=deepseek
modelscope 类似 huggingface
如果要部署一个RI- 7B的模型,需要 15G的显存
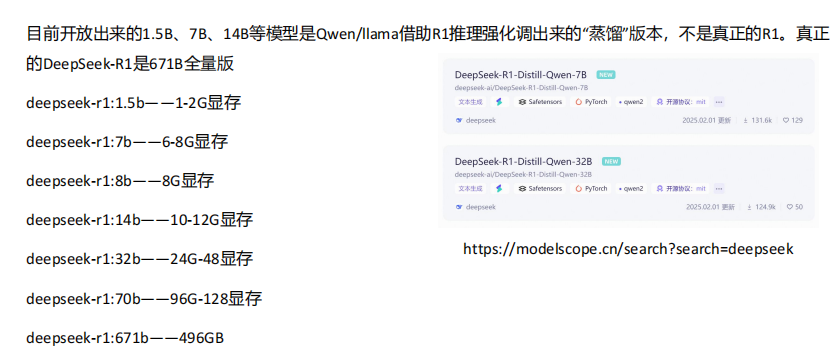
deepseek-r1-32b => 企业级的入门版,不建议个人部署,因为24G的显卡跑不起来,哪怕是int4的版本也跑不起来
算例市场: autoDL
https://www.autodl.com/market/list
Q:关机不扣费,会清除部署的应用和存放的数据吗?
如果放到 autodl-tmp目录下面,数据不会清除
公司建议使用VLLM 部署
个人建议使用 ollm 部署
模型下载:
python
# 模型下载
from modelscope import snapshot_download
snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir="/root/autodl-tmp/models")VllM 使用
Vllm使用:是由伯克利大学 LMSYS 组织开源的LLM高速推理框架,用于提升LLM的吞吐量与内存使用效率。它
通过 PagedAttention 技术高效管理注意力键和值的内存,并结合连续批处理技术优化推理性能。vLLM 支持量化
技术、分布式推理、与 Hugging Face 模型无缝集成等功能
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
• vllm serve,启动 vLLM 推理服务的命令
• deepseek-ai/DeepSeek-R1-Distill-Qwen-32B,Hugging Face 模型库中的模型名称,vLLM 会尝试从 HF 下载模型
• --tensor-parallel-size 2,启用张量并行,在 2 个 GPU 上分布式运行模型(适合 32B 大模型)
• --max-model-len 32768,设置模型的最大上下文长度(32K tokens),确保能处理长文本。
• --enforce-eager,禁用 CUDA Graph 优化(可能在某些环境下更稳定,但性能稍低)
Thinking:如果我在本地的ubuntu下面有 /root/autodl-tmp/models/tclf90/deepseek-r1-distill-qwen-32b-gptq-int4,
如何使用vllm进行推理?
vllm serve /root/autodl-tmp/models/tclf90/deepseek-r1-distill-qwen-32b-gptq-int4 --tensor-parallel-size 1 --maxmodel-len 32768 --enforce-eager --quantization gptq --dtype half
关键改动:指定本地路径:替换 HF 模型名为你的本地路径。
--quantization gptq:显式声明使用 GPTQ 量化。
--dtype:设为 half(FP16)或 auto(自动选择),因为 GPTQ 本身是 4-bit,但计算时需指定中间精度。
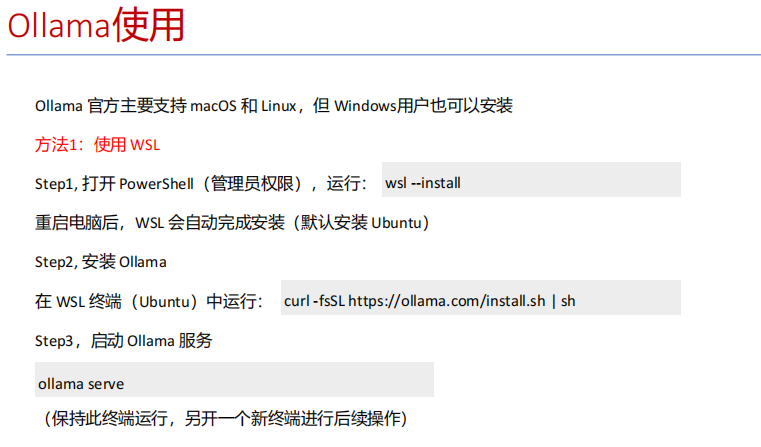
Ollma
适合个人轻量化部署
下载 windows 版本 下载完成后安装
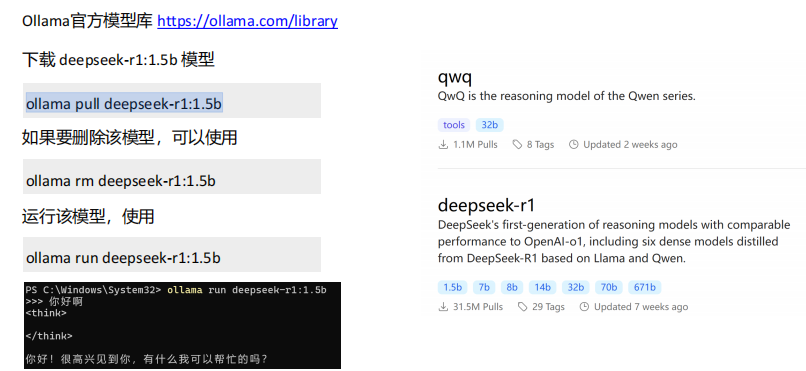
进入 cmd ,通过ollama 下载模型,
ollama pull deepseek-r1:1.5b (ollama pull + 模型id (从ollama 官网看))

复习 API 调用deepseek-r1
大部分情况还是用调用API的方式

python
import dashscope
from dashscope.api_entities.dashscope_response import Role
dashscope.api_key = "sk-你的key"
# 封装模型响应函数
def get_response(messages):
response = dashscope.Generation.call(
model='deepseek-r1', # 使用 deepseek-r1 模型
messages=messages,
result_format='message' # 将输出设置为message形式
)
return response
# 测试对话
messages = [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "你好,你是什么大模型?"}
]
response = get_response(messages)
print(response.output.choices[0].message.content)
# 情感分析
review = '这款音效特别好 给你意想不到的音质。'
messages = [
{"role": "system", "content": "你是一名舆情分析师,帮我判断产品口碑的正负向,回复请用一个词语:正向 或者 负向"},
{"role": "user", "content": review}
]
response = get_response(messages)
print(response.output.choices[0].message.content)Prompt 提示词工程
推理模型和通用模型
文科类的建议用通用模型, 复杂问题建议使用推理模型


cot: chain of thought 思维链
比如:
你是一个数学助手,请根据以下步骤计算用户输入的金额。请将每个金额首先加上1000元,接着减去500元,然后乘以1.2输出计算结果,以','作为分隔符进行返回。
你可以参考以下计算过程来帮助解决:
"""
对于输入:2000, 3000, 4000
计算过程如下:
首先分别对输入的2000, 3000, 4000加上1000,得到:3000, 4000, 5000
然后将3000, 4000, 5000分别减去500,得到:2500, 3500, 4500
然后将2500, 3500, 4500分别乘以1.2,得到:3000, 4200, 5400
答案是:3000, 4200, 5400
"""
输入:1500, 2500, 3500
上述案例涉及 角色 任务 COT 限制输出格式 分隔符 样例
Prompt 实战
设置API Key
使用方便且安全
key 的获取方式: 百炼 dashcope 见上一篇
设置系统变量后,如果运行时报错,找不到key, 可以试试重启IDE
python
# 导入依赖库
import dashscope
import os
# 从环境变量中获取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基于 prompt 生成文本
# 使用 deepseek-v3 模型
def get_completion(prompt, model="deepseek-v3"):
messages = [{"role": "user", "content": prompt}] # 将 prompt 作为用户输入
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message', # 将输出设置为message形式
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.output.choices[0].message.content # 返回模型生成的文本
# 任务描述
instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称,月费价格,月流量。
根据用户输入,识别用户在上述三种属性上的需求是什么。
"""
# 用户输入
input_text = """
办个100G的套餐。
"""
# prompt 模版。instruction 和 input_text 会被替换为上面的内容
prompt = f"""
# 目标
{instruction}
# 用户输入
{input_text}
"""
print("==== Prompt ====")
print(prompt)
print("================")
# 调用大模型
response = get_completion(prompt)
print(response)优化prompt 指定输出结构:
python
# 输出格式
output_format = """
以 JSON 格式输出
"""
# 稍微调整下咒语,加入输出格式
prompt = f"""
# 目标
{instruction}
# 输出格式
{output_format}
# 用户输入
{input_text}
"""
# 调用大模型,指定用 JSON mode 输出
response = get_completion(prompt)
print(response)cot 示例
python
instruction = """
给定一段用户与手机流量套餐客服的对话,。
你的任务是判断客服的回答是否符合下面的规范:
- 必须有礼貌
- 必须用官方口吻,不能使用网络用语
- 介绍套餐时,必须准确提及产品名称、月费价格和月流量总量。上述信息缺失一项或多项,或信息与事实不符,都算信息不准确
- 不可以是话题终结者
已知产品包括:
经济套餐:月费50元,月流量10G
畅游套餐:月费180元,月流量100G
无限套餐:月费300元,月流量1000G
校园套餐:月费150元,月流量200G,限在校学生办理
"""
# 输出描述
output_format = """
如果符合规范,输出:Y
如果不符合规范,输出:N
"""
context = """
用户:你们有什么流量大的套餐
客服:亲,我们现在正在推广无限套餐,每月300元就可以享受1000G流量,您感兴趣吗?
"""
#cot = ""
cot = "请一步一步分析对话"
prompt = f"""
# 目标
{instruction}
{cot}
# 输出格式
{output_format}
# 对话上下文
{context}
"""
response = get_completion(prompt)
print(response)prompt 优化 prompt
python
user_prompt = """
做一个手机流量套餐的客服代表,叫小瓜。可以帮助用户选择最合适的流量套餐产品。可以选择的套餐包括:
经济套餐,月费50元,10G流量;
畅游套餐,月费180元,100G流量;
无限套餐,月费300元,1000G流量;
校园套餐,月费150元,200G流量,仅限在校生。"""
instruction = """
你是一名专业的提示词创作者。你的目标是帮助我根据需求打造更好的提示词。
你将生成以下部分:
提示词:{根据我的需求提供更好的提示词}
优化建议:{用简练段落分析如何改进提示词,需给出严格批判性建议}
问题示例:{提出最多3个问题,以用于和用户更好的交流}
"""
prompt = f"""
# 目标
{instruction}
# 用户提示词
{user_prompt}
"""
response = get_completion(prompt)
print(response)note
Q:带distill的是什么版本呢?
deepseek-r1-7b (qwen2.5-7b-distill)
模型的基座是qwen2.5-7b,不是deepseek
DeepSeek-R1-Distill-Qwen-7B
训练的是Qwen-7B,使用的DeepSeek-R1训练的方式
最终Qwen-7B具备了 的能力