**前言:**你是否遇到过这样的情况?项目需要接入多个AI模型,结果发现每个模型都要单独注册账号、申请API密钥、学习不同的SDK、写一大堆适配代码。OpenAI、DeepSeek、Claude、Qwen......光是维护这些平台的账号和代码就让人头大,更别提频繁切换测试时的效率损失了。
正在我犹豫如何开始时,GMI Cloud 推理引擎平台进入了我的视野。它可以用一个账号、一个API密钥、一套代码,调用市面上所有主流AI模型,无论是文本生成、视频创作还是图像生成,全部统一搞定。
两周体验下来,体验远超预期:底层采用H200芯片,集成了36个顶级LLM模型(DeepSeek、GPT、Qwen、Kimi等)和31个视频生成模型(Sora 2、Veo 3.1、Kling V2.5等),统一的OpenAI兼容API让切换模型只需调整一行代码,Token透明计费避免超支更好管理。
以下内容是我这两周完整的使用经验,从注册到线上体验再到实战部署,手把手教你玩转GMI Cloud。
一、登录GMI Cloud
1.登录方法
首先我们打开官网,在右上角有注册按钮。可以直接用邮箱注册,也支持 Google 或 GitHub 账号登录。我用的是 GitHub 授权,基本秒进。
2.领取体验额度
新用户可以兑换一个优惠码,获得免费额度,对于测试和小规模使用来说,已经够用很久了: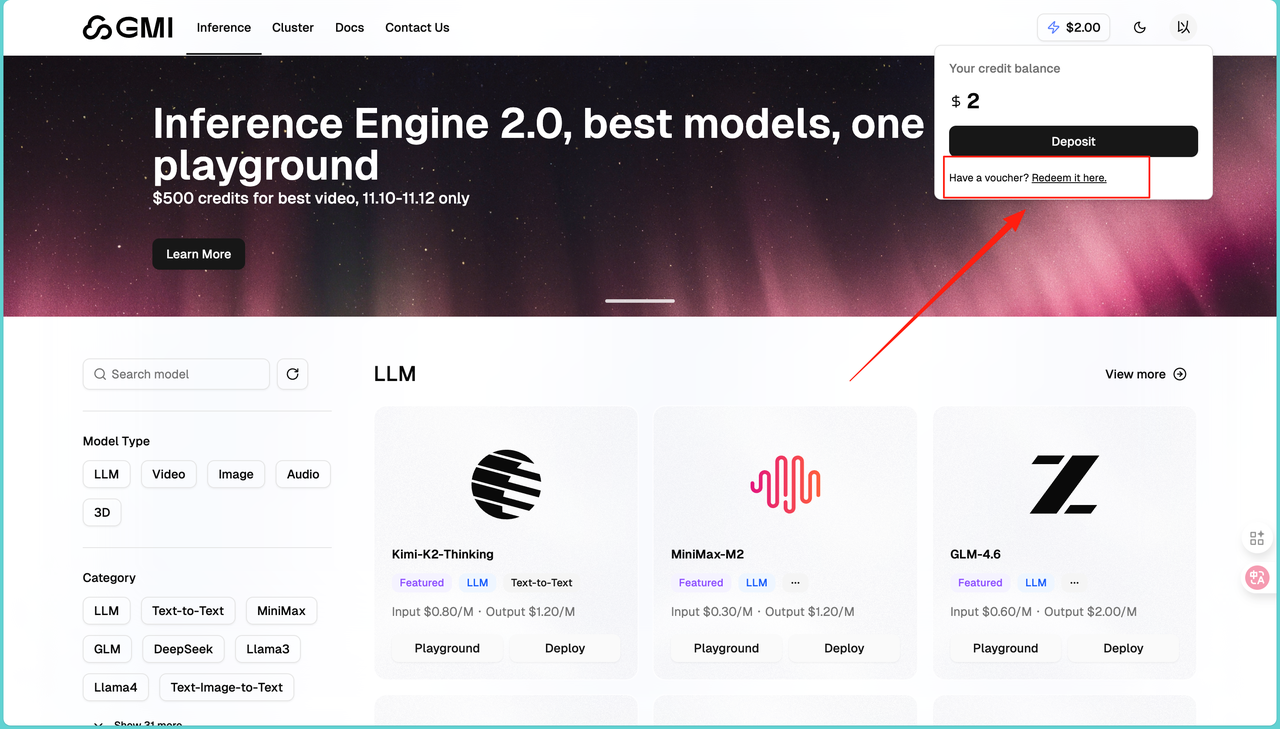
登录后先看左侧菜单,确认选中了"Mass"这个选项。这是主控制台的默认视图。然后点击右上角显示"0 USD"的余额区域,会弹出一个账户信息窗口。在弹出的窗口里找到"Redeem it here"这个链接,点进去。输入优惠码:**ACC2025BJ,**点击"Apply"按钮完成兑换。刷新页面后,余额就会变成 2.00 USD。这个钱可以用在所有集成的模型上,没有限制。
二、GMI Cloud介绍
1.模型丰富
正如我们看到的一样,模型的数量非常多,随便点开一个LLM就有36个,而Video模型更是有31个之多,包括最新的Hailuo模型等,让人看起来眼花缭乱十分兴奋。
这里能找到几乎所有主流的大语言模型。从国产的 DeepSeek、Qwen、GLM,到国外的 GPT、Claude、Gemini,再到最新的 Kimi-K2-Thinking,应有尽有。每个模型都标注了上下文长度、支持的功能(比如是否支持函数调用)、价格等信息。这样选择起来很方便,不用再去各个官网查资料。
31 个视频生成模型确实震撼。除了大家熟知的 Sora 2、Veo 3.1,还有很多国产优秀模型,比如 Kling V2.5、Wan 2.5、Minimax-Hailuo 2.3。有些模型支持文本生成视频(Text to Video),有些支持图片生成视频(Image to Video),还有些两者都支持。界面上都有清楚标注,选择起来很直观。
图像生成模型相对少一些,但质量都不错。Flux 系列、Seedream 系列、Seededit 系列基本覆盖了各种需求。有些适合从零生成,有些适合修改现有图片。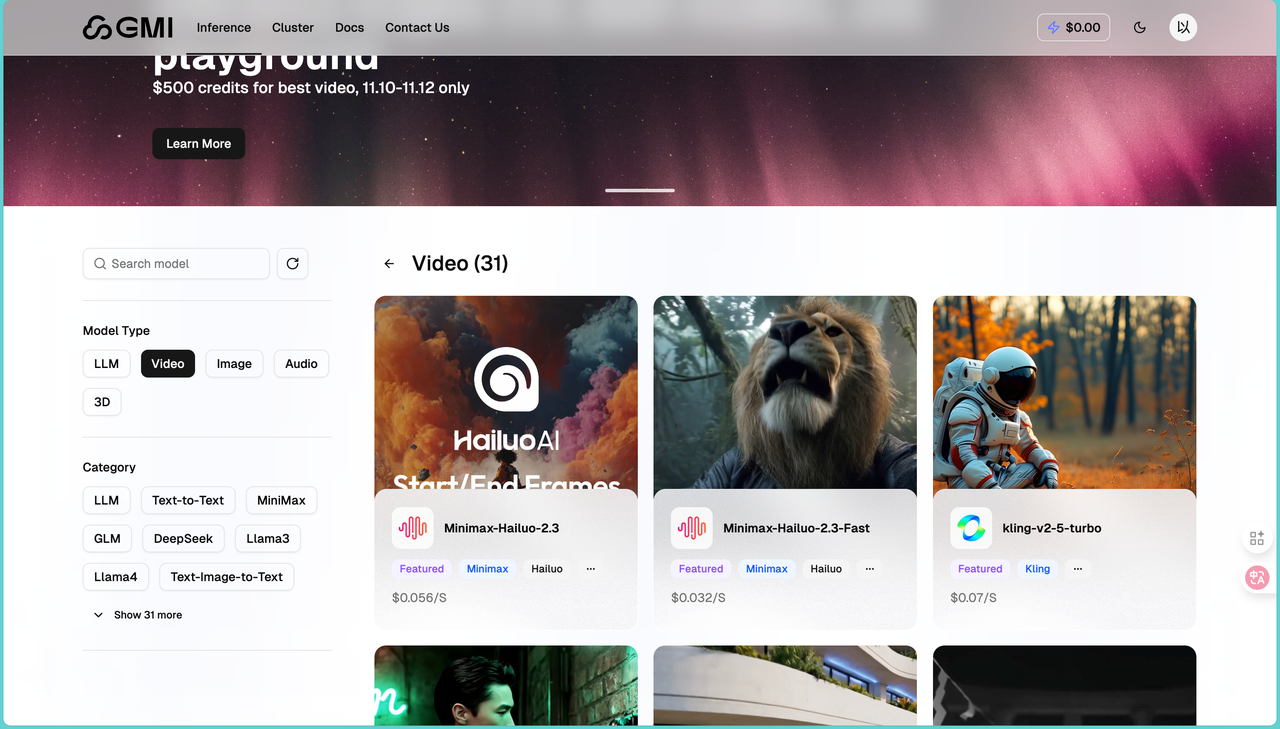
2.GMI Cloud优势
用了一段时间后,我总结了几个核心优势,首先就是GMI Cloud 的技术底子很扎实,底层靠 H100/H200 芯片支撑,还集成了近百个前沿模型,覆盖视频生成、大语言、图像生成等多个类别。更省心的是所有模型共用一套 API 体系,不用切换平台反复适配代码,以前对接新模型要注册、申密钥、啃文档、写适配代码的麻烦全没了,学会一个就能套用所有,代码复用率高,维护起来也省事。
最让人惊喜的是它的模型更新速度,像 Minimax Hailuo 2.3、Kimi-K2-Thinking 这些新模型,基本都是刚发布没几天就能用上,追新技术的项目完全不用等。成本方面也透明可控,按 Token 计费,后台能看到每次调用的详细消耗,还能设预算提醒,避免意外超支。而且背景很靠谱,是 Google X AI 专家和硅谷团队创立的,还是 NVIDIA 全球六大参考平台云合作伙伴,优先拿最新 GPU 资源,服务稳定性有保障,全球分布的数据中心让 API 响应基本在 1-3 秒,视频生成 1-3 分钟,符合使用预期。
三、在线使用模型
GMI Cloud 提供了 Playground 功能,可以直接在浏览器里测试模型,不用写一行代码。这个功能特别适合快速体验和对比不同模型的效果。
1.生成 Keys密钥
在使用模型之前首先需要我们生成自己的API,进入控制台,找到左侧菜单的Keys:
点击"Create New API Key"按钮。给密钥起个名字,同时可以设置权限范围,比如只允许调用文本模型,或者只读不写。点击生成后,密钥会显示在页面上,这里要注意这个密钥只显示一次,一定要立刻复制保存,不要问我为什么,因为我就因为没记住又回来重新操作了一遍!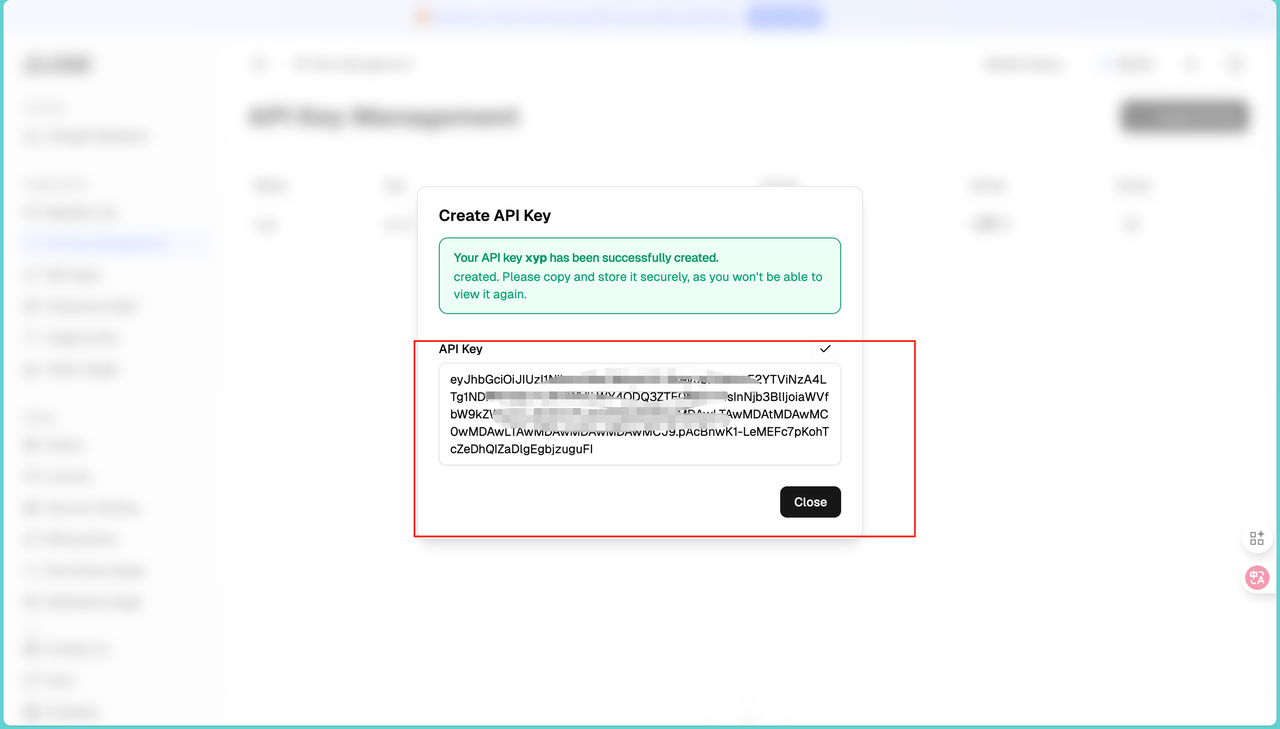
2.测试大语言模型
在左侧菜单选择"LLM"分类,找到想测试的模型,比如Kimi-K2-Thinking: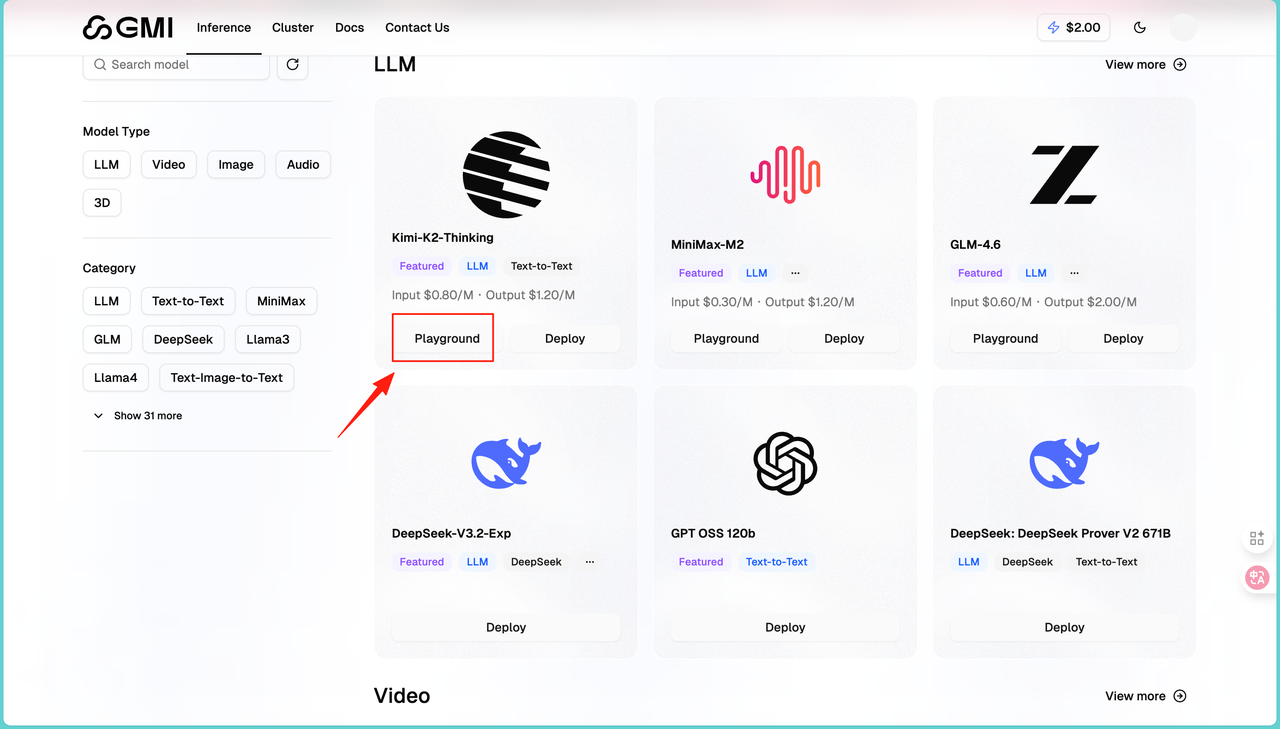
点击模型卡片,进入详情页后,点击顶部的"Playground"标签。
进入之后我们会发现页面分为左右两部分。左边是参数设置区,右边是对话区: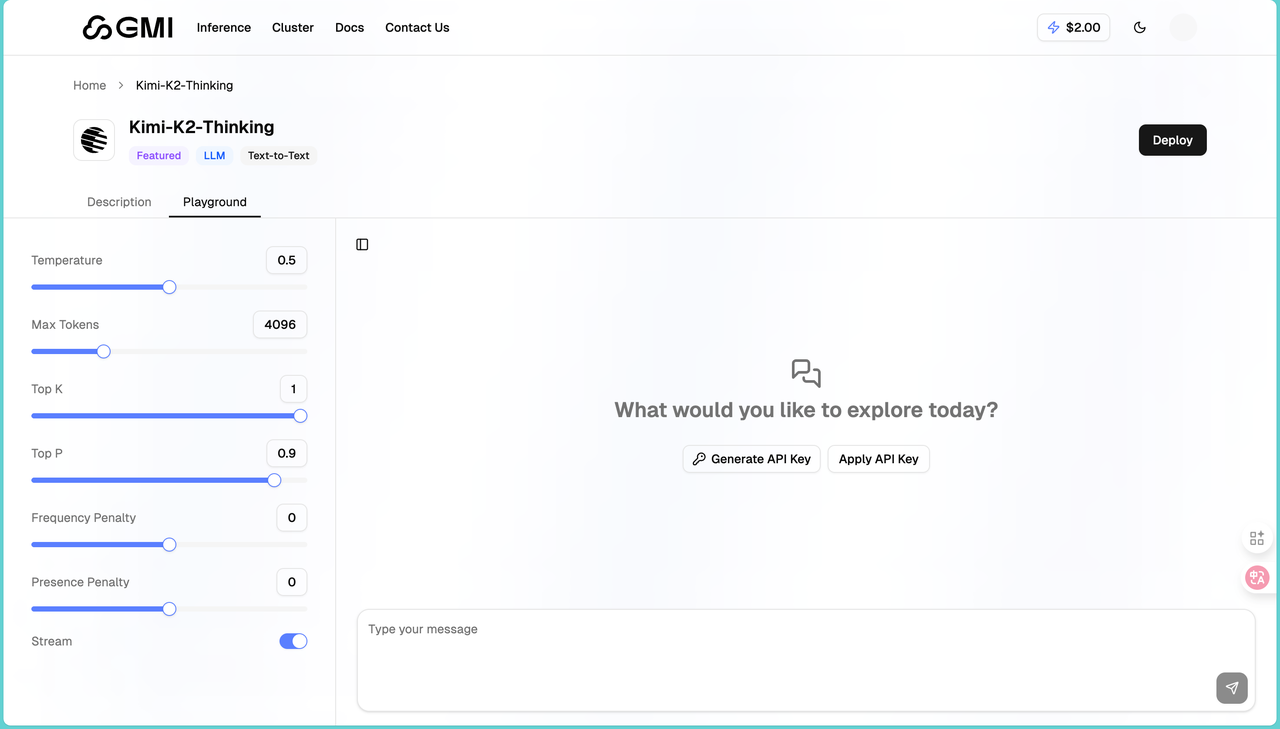
然后在右侧的地方点击Apply API,将我们刚才复制的API输入进去,然后就可以使用模型了: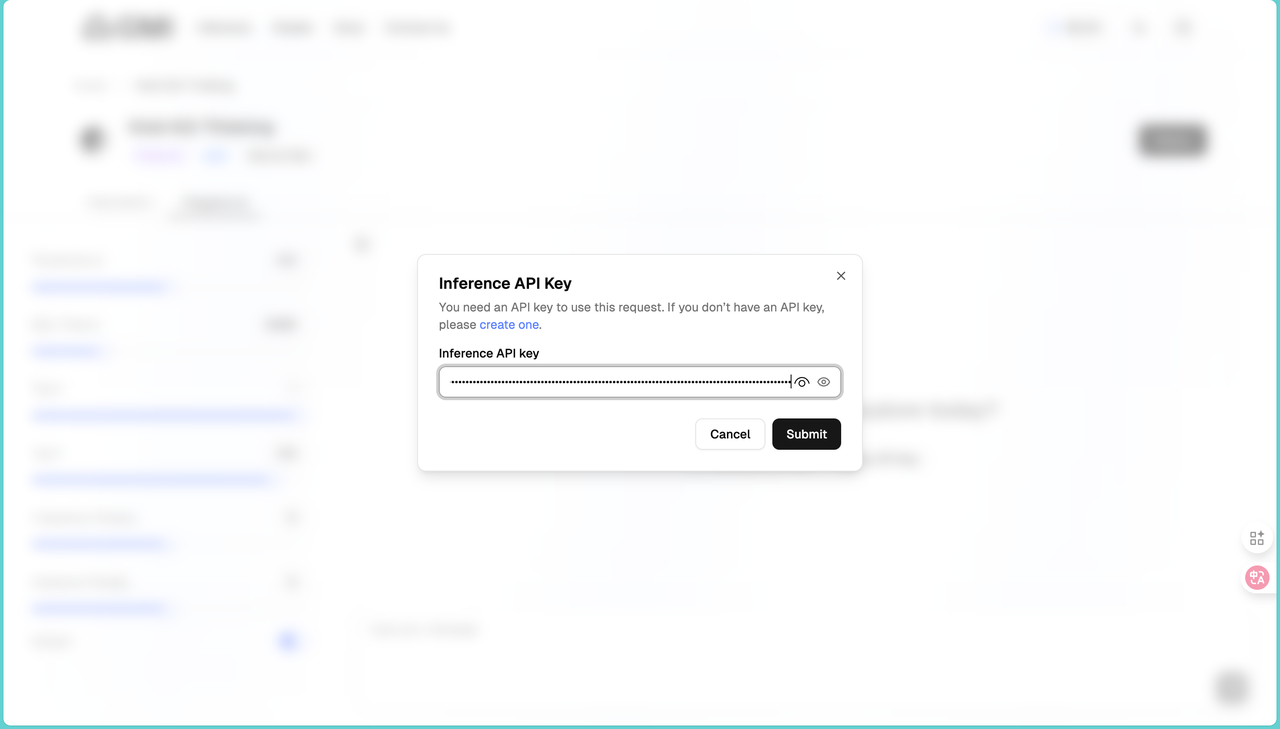
在对话框输入我们的问题,比如"请用 Python 写一个快速排序算法"。点击发送按钮或按 Enter 键,等几秒钟就能看到回复: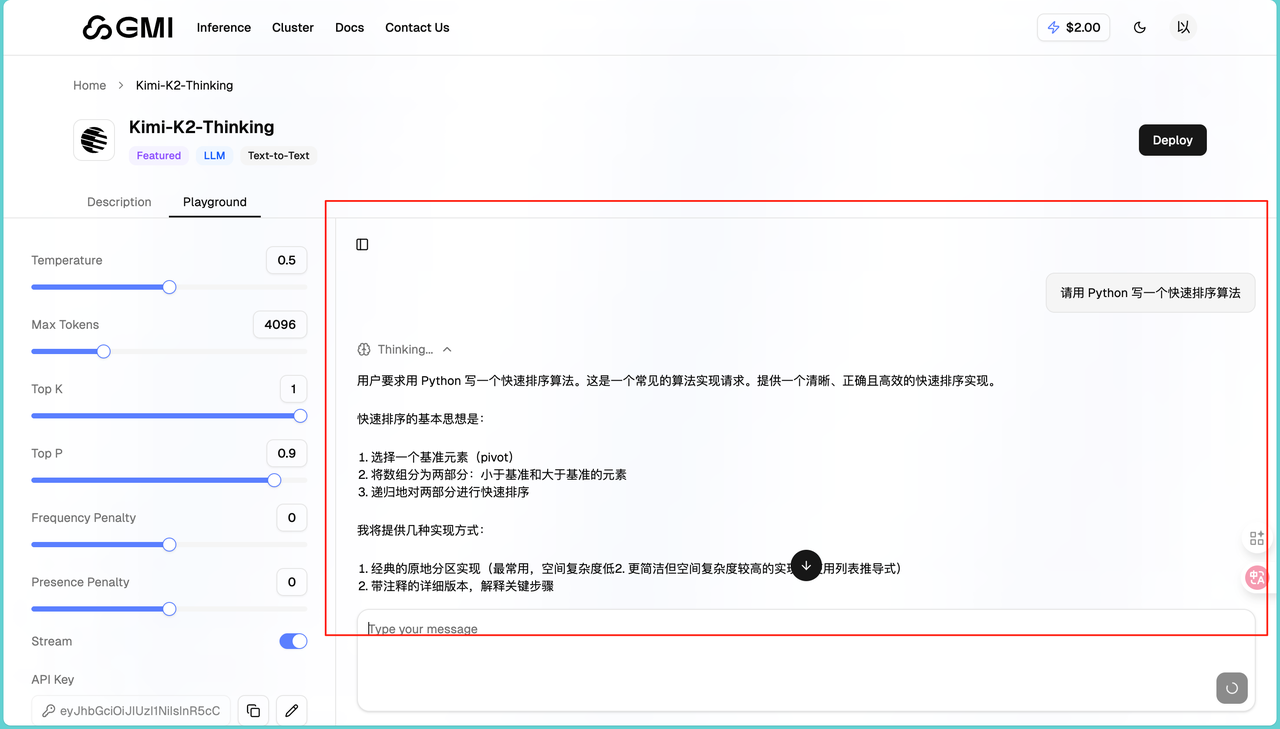
回复的非常准确,同时左侧有几个重要参数可以调整,可以控制回复的随机性以及限制回复长度等。同Playground 最大的好处是可以快速切换模型对比。同样的问题,分别用 DeepSeek、Kimi、Qwen 测试,看哪个回答更好。通过我的大量测试,我发现DeepSeek 性价比高,适合大量调用;Kimi-K2 推理能力强,适合复杂问题;GLM-4.6 中文理解好,适合中文内容生成。
3.生成 AI 视频
在左侧菜单选择"Video"分类,能看到 31 个模型。每个模型都标注了价格。我一般会先用便宜的模型测试,效果满意后再用高端模型生成最终版本。这里我们首先选择的是:Minimax-Hailuo-2.3。
点击进入模型页面,我们可以根据描述你想生成的视频内容。提示词写得越详细,效果越好,也可以上传一张图片作为首帧或参考,如果想让视频从特定画面开始,可以用这个功能。同时其提供了Duration和Resolution 供我们选择,也就是说我们可以自主选择时长和分辨率。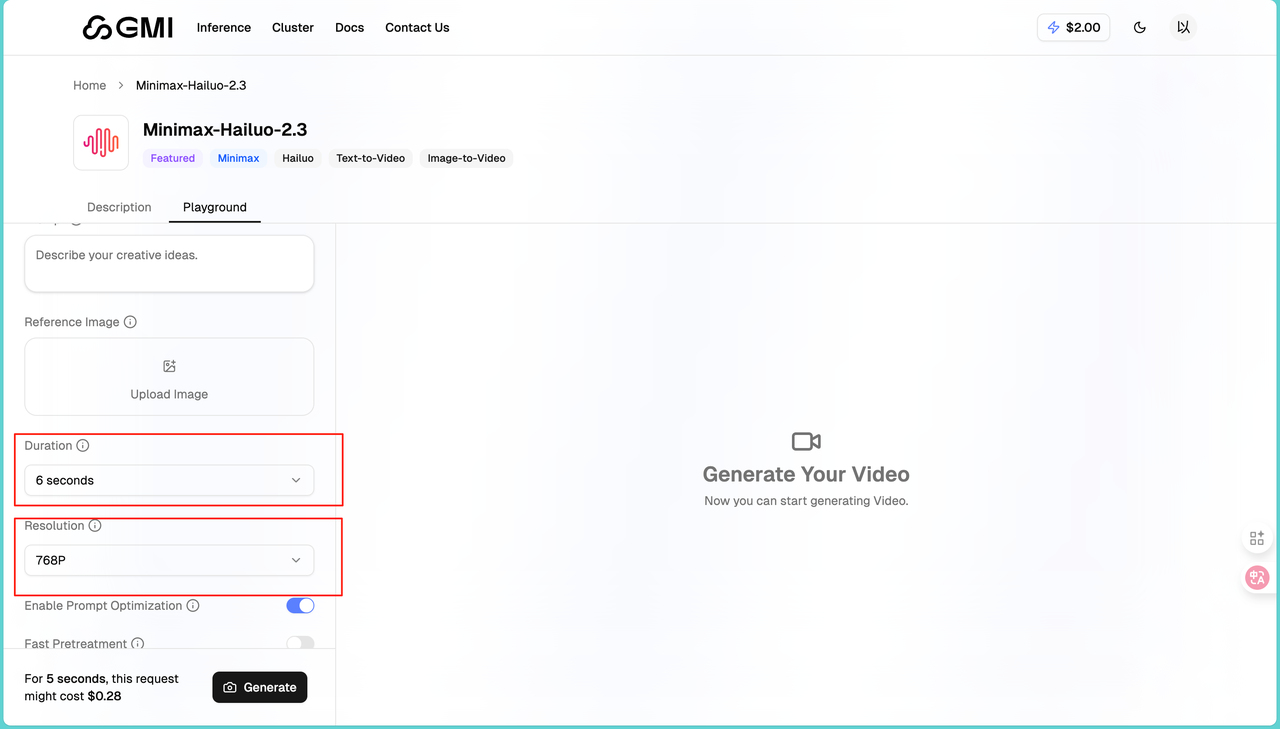
参数设置好后,点击"Generate"按钮,视频生成时间大概一分钟就好了。这里我上传了一张我家猫猫的照片:
我输入的提示词是"让这只小猫可爱的笑起来",看看效果咋样:
我们可以看到生成的十分好,简直跟真的一模一样,生成速度快,画面流畅,适合日常使用。生成的视频会保存在你的账户里,但建议下载到本地,平台可能会定期清理旧文件。其余的模型我就不再详细介绍了,大家感兴趣就自己来体验呀。
四、一键调用API 模型
1.如何调用
首先我们打开之前用过的Kimi-K2-Thinking模型,点击Description,这里为我们提供了很多然后我们可以选择使用终端Shell或者Python去调用,这里我们选择用Python去调用,首先输入其给我们提供的代码:
python
import requests
import json
url = "https://api.gmi-serving.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer *************"
}
payload = {
"model": "moonshotai/Kimi-K2-Thinking",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": "List 3 countries and their capitals."}
],
"temperature": 0,
"max_tokens": 500
}
response = requests.post(url, headers=headers, json=payload)
print(json.dumps(response.json(), indent=2))这里要注意Bearer *************后面的内容是需要我们输入自己的Key,输入完毕之后点击运行,我们会看到返回的JSON输出内容,结构清晰、通用性强,能够轻松被各种编程语言和系统解析处理。这就代表我们已经调用API成功了: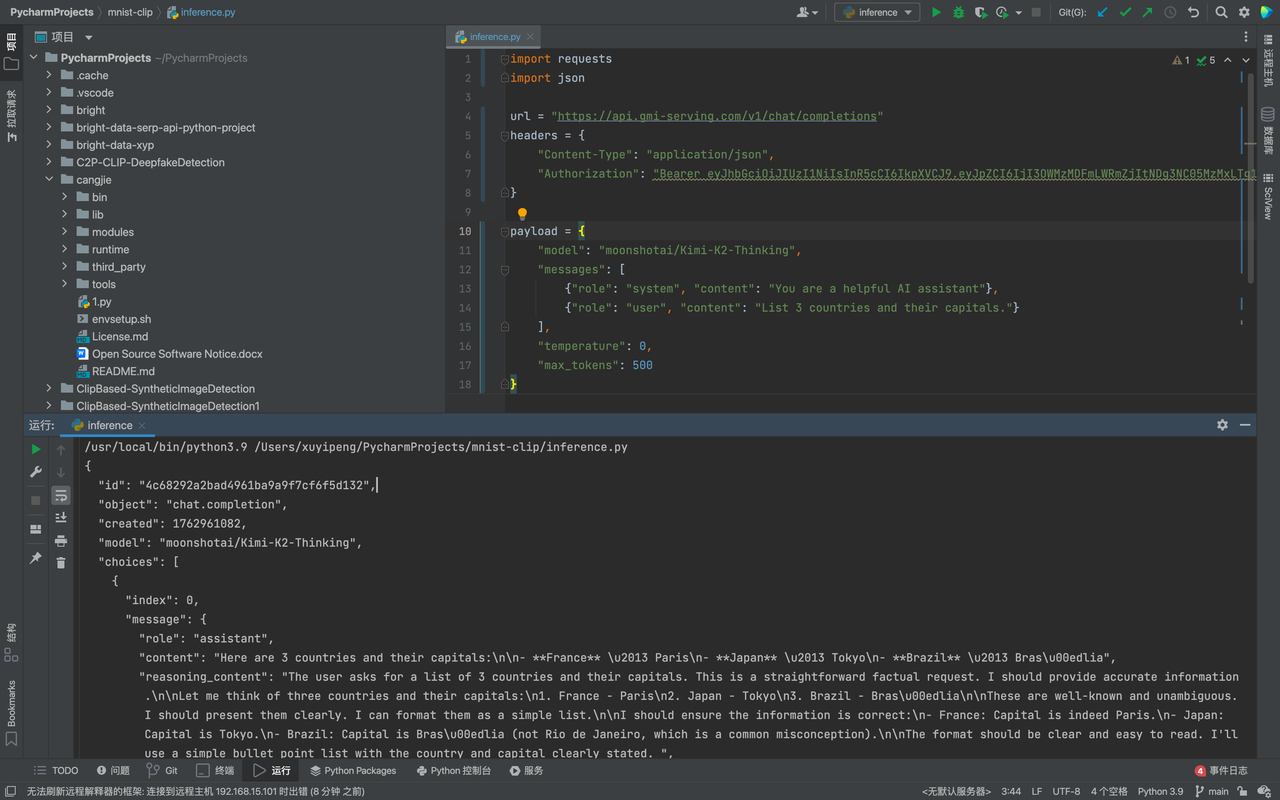
仅需要一步就能完成接入,直接没有技术门槛,任何人都可以很快的开发。
2.本地部署LLM模型
为了后续能方便地引用自己的提问,也避免每次修改问题都要在复杂的我先把原本直接写在 messages 中的提问内容单独抽离出来。我定义了一个 user_question 变量,这样一来,后续要更换提问时,只需要修改 user_question 这一行代码,不用改动整个 结构,代码的灵活性和可维护性都提升了不少。
原来的代码只会打印 API 返回的完整 JSON 数据,看起来杂乱且看不到自己的原始提问,输出结果不够直观。我们可以先从响应数据中提取出 AI 的核心回答, 通过回复定位到 AI 回复的内容并存储在变量中。接着用格式化输出的方式,先明确打印出 "你的问题:" 和对应的提问内容,再换行打印 "AI 的回答:" 以及提取出的回复,让提问和回答一一对应,整个输出结果清晰明了,也更符合我查看结果的需求,具体代码如下:
python
import requests
import json
url = "https://api.gmi-serving.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer ........"
}
# 提问内容
user_question = "怎么去写作"
payload = {
"model": "moonshotai/Kimi-K2-Thinking",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": user_question} # 引用提问内容
],
"temperature": 0,
"max_tokens": 500
}
response = requests.post(url, headers=headers, json=payload)
response_data = response.json()
# 提取 AI 的回答
ai_answer = response_data['choices'][0]['message']['content']
# 同时打印问题和回答
print(f"你的问题:{user_question}")
print("\nAI 的回答:")
print(ai_answer)这里我的问题是怎么去写作,我们可以看到Kimi-K2-Thinking模型回答的十分快速也非常详细: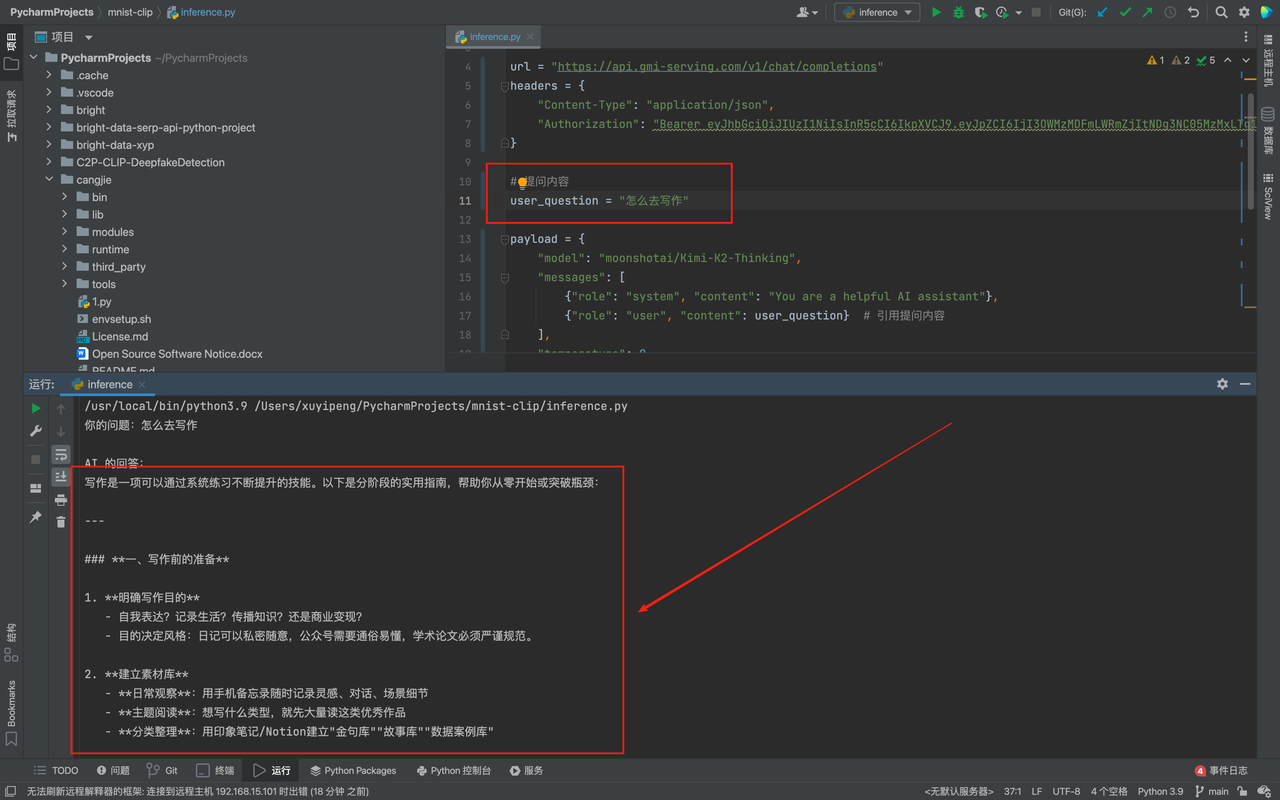
每个模型的详细调用方式可以在模型页面找到,大家可以根据自己的需要去调用,下面给大家展示如何调用视频模型。
3.本地部署视频模型
与 LLM 模型类似,我们可以将视频生成的 API 调用逻辑进行封装,使其更易于在本地项目中复用和维护。我写了一个更结构化的封装示例,大家可以直接在本地项目中使用,这里我选择调用的模型是Minimax-Hailuo-2.3-Fast:
python
import requests
import json
import os
API_KEY = os.getenv("GMI_API_KEY", "。。。。。。")
# 视频生成 API 的基础 URL 和 Endpoint
BASE_URL = "https://console.gmicloud.ai"
ENDPOINT = "/api/v1/ie/requestqueue/apikey/requests"
FULL_URL = f"{BASE_URL}{ENDPOINT}"
HEADERS = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
VIDEO_MODEL_NAME = "Minimax-Hailuo-2.3-Fast"
PROMPT = "A serene ocean scene with waves under a pink sunset"
DURATION = 6 # 视频时长(秒)
RESOLUTION = "768P" # 分辨率,可选值如 "768P", "1080P" 等
PROMPT_OPTIMIZER = True # 是否开启提示词优化
FAST_PRETRATMENT = False # 是否开启快速预处理
payload = {
"model": VIDEO_MODEL_NAME,
"payload": {
"prompt": PROMPT,
"duration": DURATION,
"resolution": RESOLUTION,
"prompt_optimizer": PROMPT_OPTIMIZER,
"fast_pretreatment": FAST_PRETRATMENT
}
}
def main():
print(f"--- 开始调用视频模型: {VIDEO_MODEL_NAME} ---")
print(f"提示词: {PROMPT}")
try:
# 发送 POST 请求
response = requests.post(FULL_URL, headers=HEADERS, json=payload)
# 检查响应状态码
response.raise_for_status()
# 解析 JSON 响应
response_data = response.json()
print("\n请求成功!")
print("完整响应:")
print(json.dumps(response_data, indent=2))
if "data" in response_data and "task_id" in response_data["data"]:
task_id = response_data["data"]["task_id"]
print(f"\n任务 ID: {task_id}")
print("请保存此 Task ID,用于后续查询视频生成状态。")
except requests.exceptions.RequestException as e:
print(f"\n调用 API 时发生错误: {e}")
if response:
print("错误响应内容:")
print(response.text)
if __name__ == "__main__":
if API_KEY == "你的API" and not os.getenv("GMI_API_KEY"):
print("警告: 请设置 GMI_API_KEY 环境变量或在代码中替换 '你的API密钥'。")
main()这里我使用的提示词是:A serene ocean scene with waves under a pink sunset。英文是会更加准确的,建议大家在后期使用的时候也要多使用英文的提示词,点击run会发现其已经在我们本地成功运行: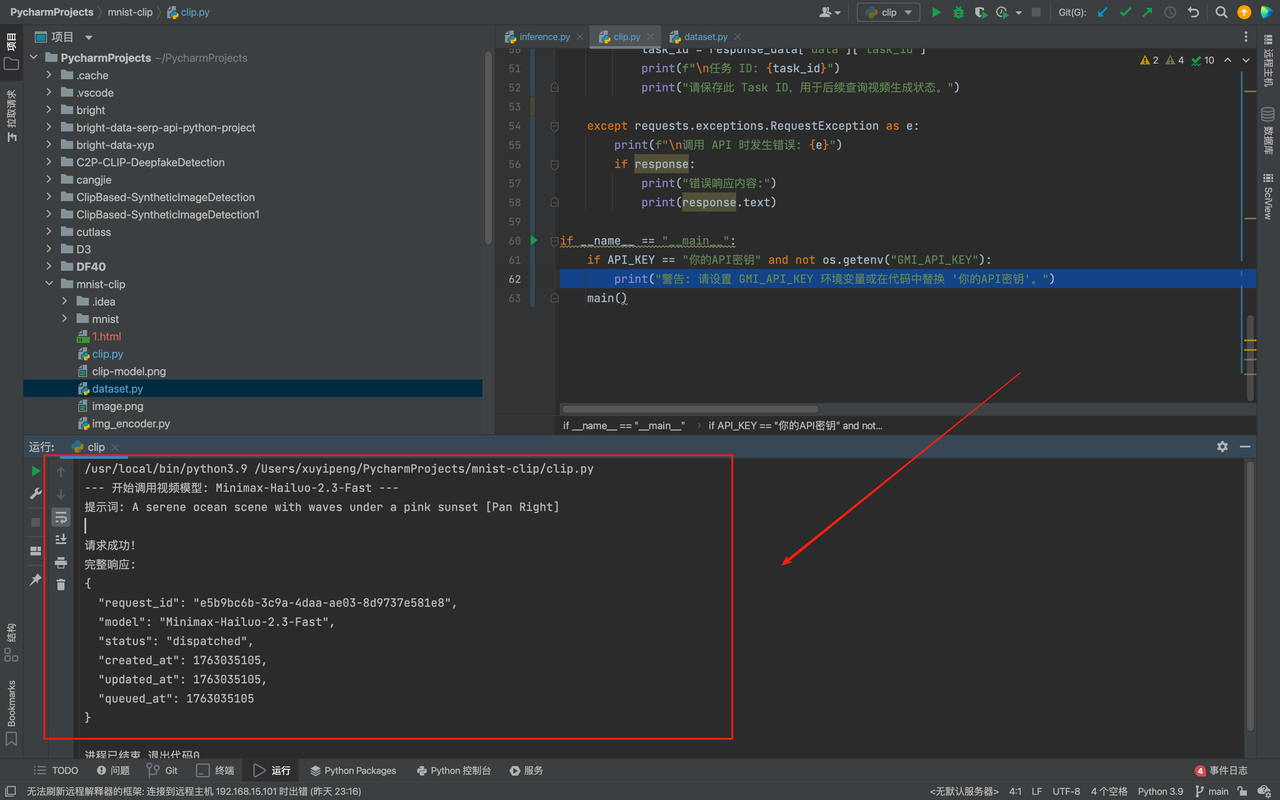
同时我们会看到在后端输出了我们的视频,非常的逼真:
五、模型对比与 Agent 集成
在实际开发中,我们经常会遇到两个核心痛点:一是多模型效果对比繁琐 (尤其是 LLM 代码能力这种需要反复测试的场景),二是Agent 集成多模态模型时配置混乱。而 GMI Cloud 的统一 API 体系,恰好完美解决了这两个问题。
1.传统LLM厂家需要单独调用
现在各家 LLM 都在卷代码生成、调试、优化能力,但如果想对比不同模型的表现,传统方式简直是 "折磨":要给 OpenAI、DeepSeek、Anthropic、Qwen 等每家平台单独注册账号、充值、申请 API 密钥。
除此之外每家的 SDK 和接口格式都不同,OpenAI 用openai.ChatCompletion.create,DeepSeek 要改model参数和请求地址,Anthropic 的max_tokens命名可能都有差异;测试时要写多套适配代码,切换模型时还要改密钥、调参数,效率极低。
2.GMI Cloud一秒调用所有模型
但用 GMI Cloud,这一切都简化到 "改一个参数":因为所有模型都遵循统一的 OpenAI 兼容接口,你只需要写一套代码,想测试哪个模型,直接修改model字段即可,其他逻辑完全不变。
这里我想直接对比DeepSeek-V3.1、Kimi-K2-Thinking、gpt-oss-120b的代码生成能力,让其用 Python 写一个斐波那契数列生成器,如果按照传统方式的话
传统方式需要:配置 OpenAI 的 API 密钥和 SDK,写调用代码;切换到 DeepSeek 的平台,改 SDK 和密钥,调整代码;再切换到 Anthropic,重复适配工作,最后再去测试,非常的麻烦不方便。
但是用了GMI Cloud,代码只需要写一次,就可以完成我们所有任务啦,这里我们将 API_KEY、HEADERS、MODEL_NAMES 等配置项集中放在代码开头,把要测试的模型名称放在 MODEL_NAMES 列表中,想要去修改模型只需修改这个列表,具体代码如下:
python
import requests
import json
import os
from typing import List, Dict
API_KEY = os.getenv("GMI_API_KEY", "。。。。。。。"
HEADERS = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
# 定义你想要测试的模型列表
MODEL_NAMES = [
"deepseek-ai/DeepSeek-V3.1",
"moonshotai/Kimi-K2-Thinking",
"openai/gpt-oss-120b",
]
# 定义统一的请求参数
PROMPT = "用 Python 写一个带缓存的斐波那契数列生成器"
SYSTEM_PROMPT = "You are a helpful AI assistant."
TEMPERATURE = 0
MAX_TOKENS = 500
def call_single_model(model_name: str, prompt: str) -> Dict:
payload = {
"model": model_name,
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt}
],
"temperature": TEMPERATURE,
"max_tokens": MAX_TOKENS
}
try:
response = requests.post(BASE_URL, headers=HEADERS, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"调用模型 {model_name} 时发生错误: {e}")
return None
def main():
print(f"问题: {PROMPT}\n")
print("--- 开始批量调用模型 ---")
for model in MODEL_NAMES:
print(f"\n===== 正在调用模型: {model} =====")
# 调用模型
response_data = call_single_model(model, PROMPT)
if response_data and "choices" in response_data:
# 提取并打印回答
answer = response_data['choices'][0]['message']['content'].strip()
print(f"回答:\n{answer}")
else:
print("未能获取有效响应。")
if __name__ == "__main__":
if API_KEY == "你的API密钥" and not os.getenv("GMI_API_KEY"):
print("警告: 请设置 GMI_API_KEY 环境变量或在代码中替换 '你的API密钥'。")
main()结果如下: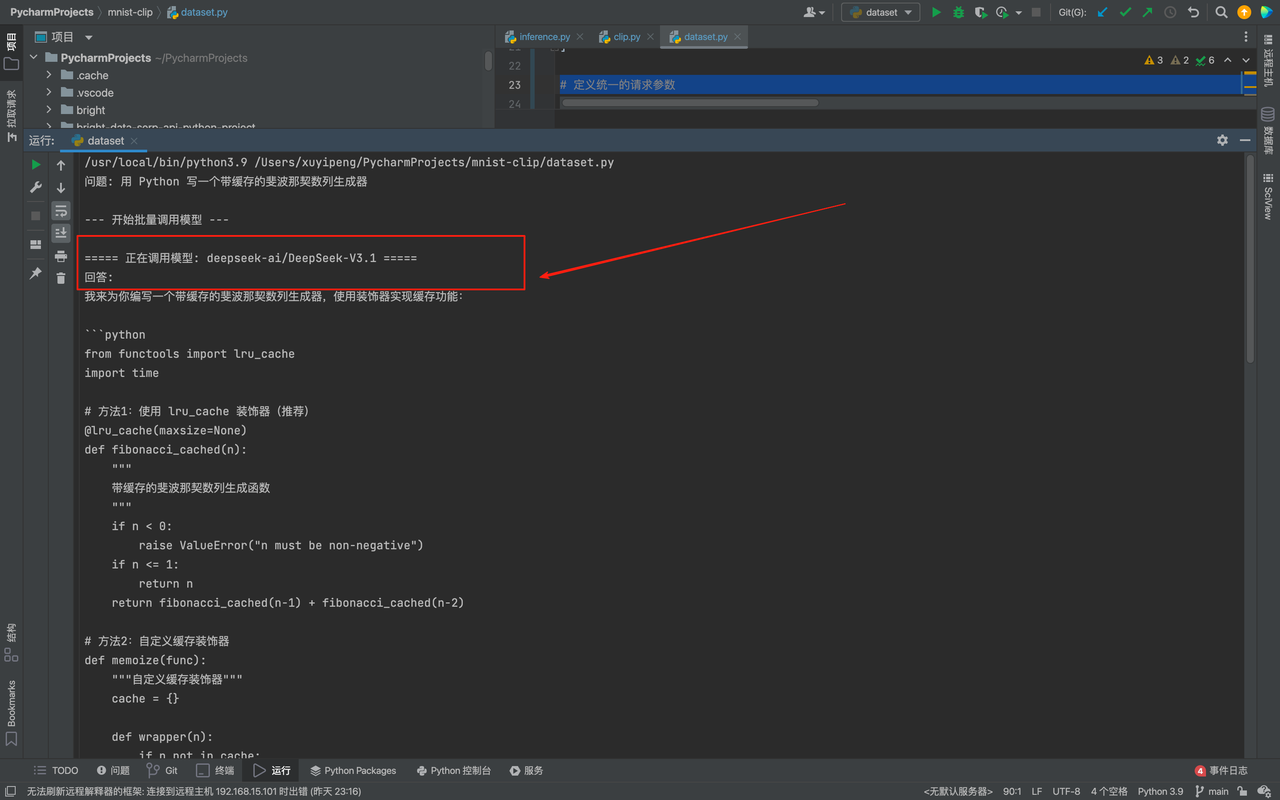
我们可以看其首先给我们调用了deepseek-ai/DeepSeek-V3.1模型,然后给我们调用moonshotai/Kimi-K2-Thinking以及openai/gpt-oss-120b: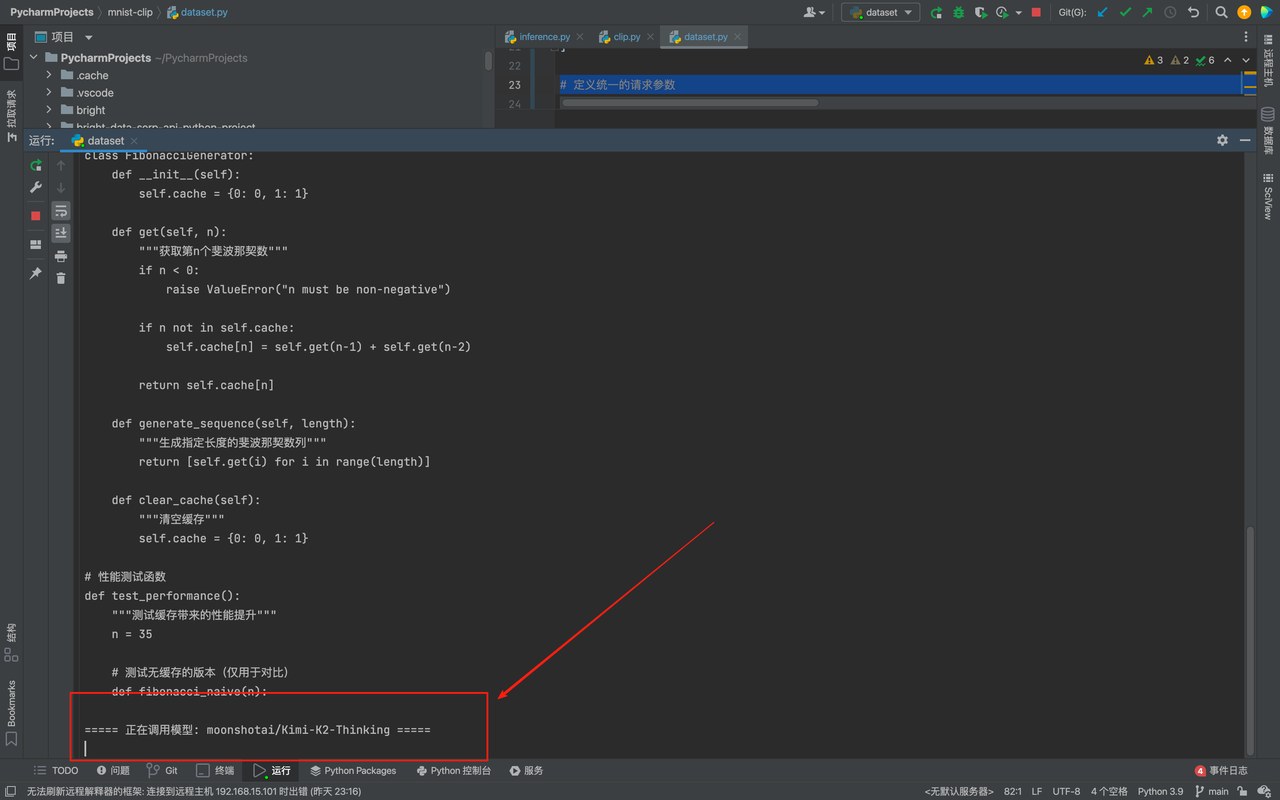
这样一来,我不需要给任何一家单独充值,也不用学不同的 SDK,1s即可已完成3 个主流模型的代码能力对比 ,而且测试结果直观,能快速判断哪个模型更适合我的代码场景,这里我发现DeepSeek 对中文注释更友好,Kimi 的缓存逻辑更严谨,GPT-4o 的代码更简洁。
六、总结
用了两周 GMI Cloud,整体感受还是很满意的。最大的优势是省心。 以前接入一个新模型,要注册平台、看文档、写适配代码,折腾半天。现在一个账号、一个密钥,所有模型都能调。代码写一次,换模型只需要改个模型名称。
36 个文本模型、31 个视频模型,基本覆盖了所有主流选择。而且更新很快,新模型发布后很快就能在平台上用到。同时 按 Token 计费,每次消耗都能看到。不同模型价格有差异,但都在合理范围。欢迎大家前去使用体验: