UCF-101(13000多个视频)和 HMDB-51(7000多个视频)数据集过小,提出了 Kinetics 数据集,并且在其之上预训练之后能够迁移到其他小的数据集。
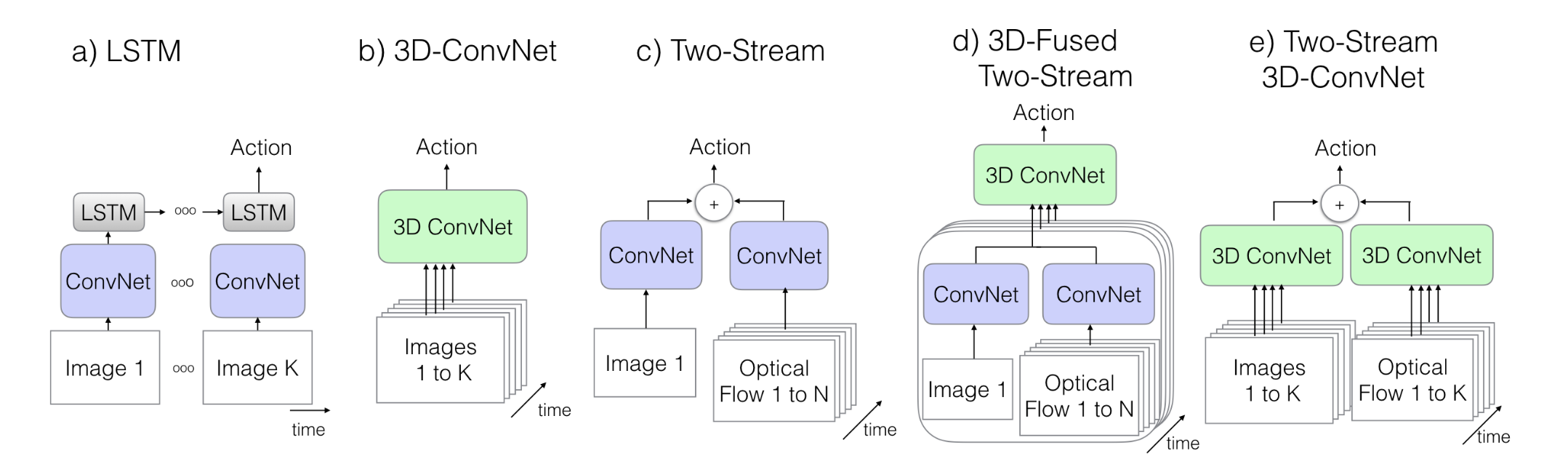
- 2D+LSTM:使用2D CNN的好处是可以直接从 Imagenet 的预训练权重迁移过来,并且使用LSTM提取时序特征。流程是,首先使用2D网络分别提取每一帧图像的特征,然后对于所有特征使用 LSTM 来获取帧之间的时序信息。这种方法的优点 是可以直接使用2D网络的预训练权重;缺点是只有在LSTM的部分才能够基于高维抽象的特征进行运动信息的提取,损失了很多低等级的运动信息,此外 LSTM 训练时需要在每个 step 都进行反向传播。
- 3D CNN:其优点 就是可以同时提取时空信息;缺点也显而易见,即具有更庞大的参数数量从而更难训练,因此一般 3D 网络的深度都较浅,单这样又影响了模型的表达能力,此外,没有办法能够有效的把2D网络的预训练权重迁移到3D网络。
- Two stream:双流网络中一个分支作为 spatial flow,输入RGB图像来提取物体和场景外观特征;另一个分支作为 temporal flow,输入光流来提取运动特征。通常两个网络分开训练,只有在测试时才会平均两个网络的预测。因此,也产生了时空信息在浅层网络中无法有效融合的问题。
Inflate:2D卷积核(和权重)直接复制 N 次得到 3D 卷积核,权重除以 N。
假设我们有一个视频片段,其中的物体移动非常慢,几乎没有运动(比如摄像头拍向一块空地)。我们在这段视频中取一些帧出来,比如取16帧,拼接起来作为3D卷积网络的输入。那么我们可以认为取出来的16帧等价于1帧图像复制16份(视频中几乎没有运动)。
我们来拆分一下 3D 卷积核 h×w×t ,分解成 t 个 h×w 的2D卷积核。这里的 h,w 分别是卷积核的高宽, t 是时间维度的深度,也就是我们把 imagenet 中的1张图像叠加 16 份的 "16"。 h×w 作用在 t=16 上的任意帧时,所提取的空间特征都应该是完全相同的,因为叠加的每一帧都是 1 张图像复制来的。所以把2D卷积核复制N次得到 3D 卷积核,等价于把1张静态图像复制拼接为 boring video ,然后使用 3D 卷积核去预训练是等价的。如果归一化,则改变了下一层卷积的输入特征响应激活值了,所以要对2D卷积核的权重进行归一化, 即除以N。
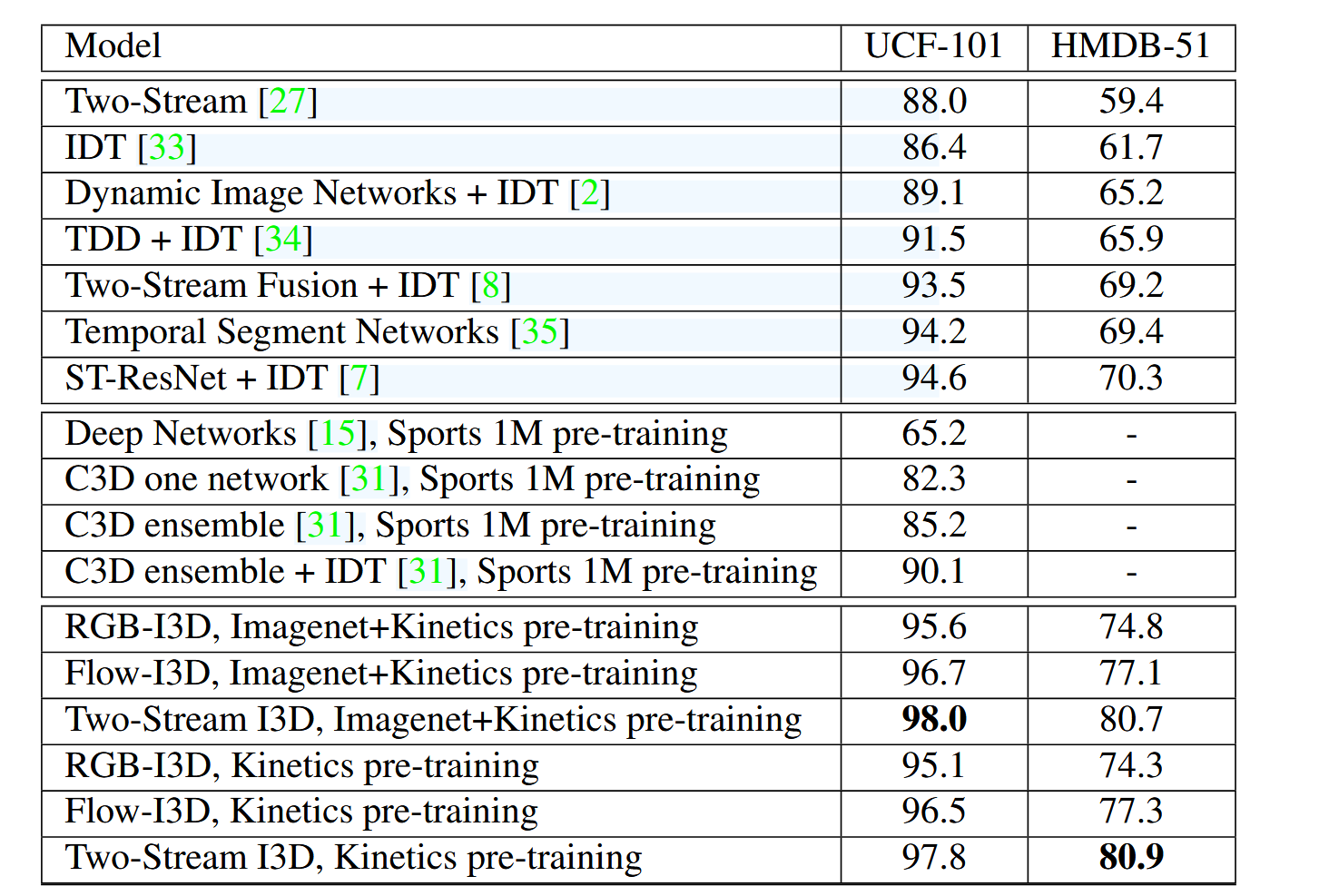
实验结果