我自己的原文哦~https://blog.51cto.com/whaosoft/13956141
#Foveated Instance Segmentation
解决XR算力瓶颈,FovealSeg框架实现毫秒级IOI分割
本文共同第一作者为纽约大学研究生 Hongyi Zeng 和Wenxuan Liu。合作作者为 Tianhua Xia、Jinhui Chen、Ziyun Li。通讯作者为纽约大学电子工程系和计算机系教授 Sai Qian Zhang,研究方向为高效人工智能,硬件加速和增强现实。
在 XR 正逐步从概念走向落地的今天,如何实现 "按用户所视,智能计算" 的精准理解,一直是视觉计算领域的核心挑战之一。
最近,一项来自纽约大学和 Meta Reality Labs 的联合研究引发了行业关注:Foveated Instance Segmentation ------ 一种结合眼动追踪信息进行实例分割的新方法,已被 CVPR 2025 正式接收。
代码连接:https://github.com/SAI-Lab-NYU/Foveated-Instance-Segmentation
论文连接:https://arxiv.org/pdf/2503.21854
- 从算力瓶颈谈起
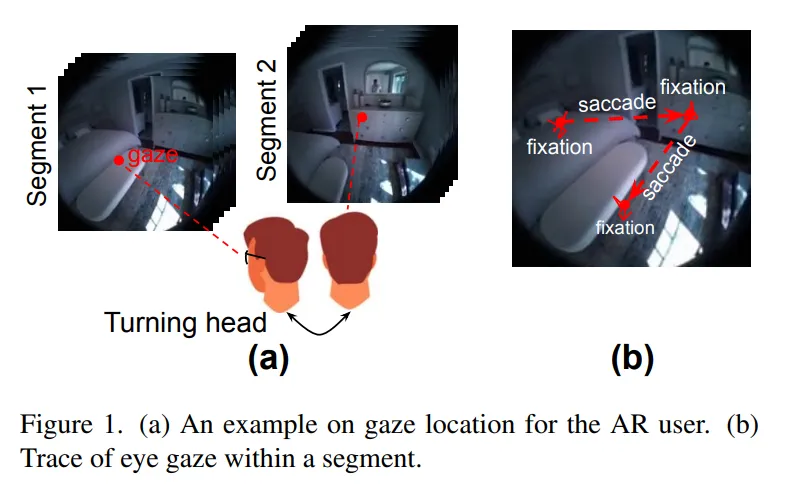
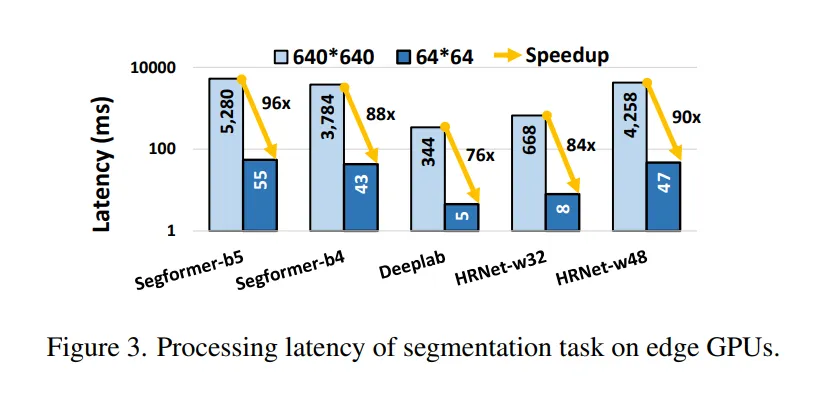
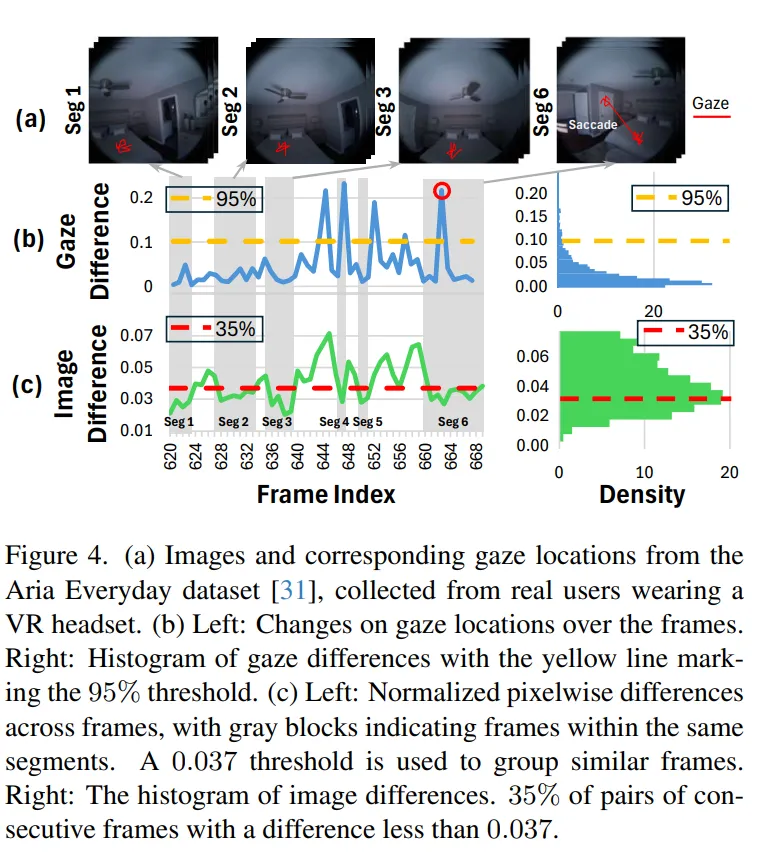
在当下主流的 AR / VR 头显中,内置相机往往具备 720 P、1080 P 乃至 1440 P 的拍摄能力,但要想在如此高分辨率的画面上做实例分割,推理延迟常常飙升至数百毫秒甚至秒级,远超人眼在交互中对时延(50--100 ms)所能接受的舒适阈值。论文 Foveated Instance Segmentation 便是从 "为什么一定要整幅图都分割" 这一疑问切入,指出绝大多数计算其实浪费在用户根本不关注的区域上。Figure 1 里的卧室示例就说明,用户目光仅停留在床或衣柜等极小区域,而 Figure 3 则量化了分辨率与延迟的关系:当输入从 640 × 640 缩到 64 × 64 时,延迟能从 300 ms 量级骤降到十毫秒级。
- 人眼注视模式带来的灵感
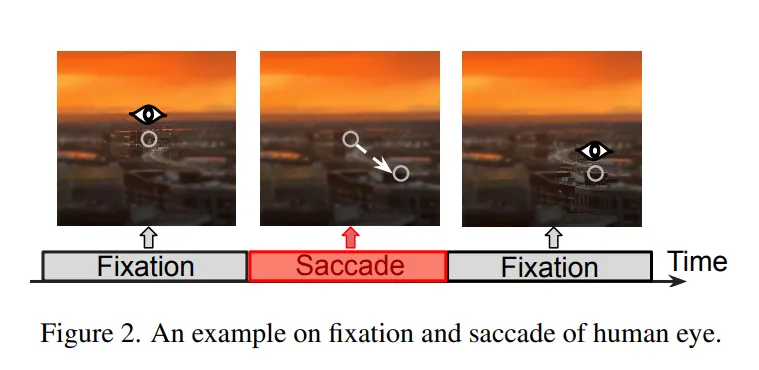
与桌面视觉任务不同,XR 用户的视线呈 "凝视 --- 扫视" 交替:每秒 1--3 次扫视,每次 20--200 ms;扫视期间视觉输入被大脑抑制,凝视期间只有注视点周围拥有高视觉敏锐度。Figure 2 直观展示了凝视 / 扫视节奏,而作者在 Aria Everyday Activities 数据集上的统计进一步揭示:只需像素差分即可将视频切成 "视段",段内帧间差异极小;若注视点位移低于 0.1 的阈值,上一帧的分割结果即可直接复用(Figure 4)。这为跨帧掩码复用和区域限定分割奠定了扎实的人因与统计基础。
- 系统总览:FovealSeg 框架
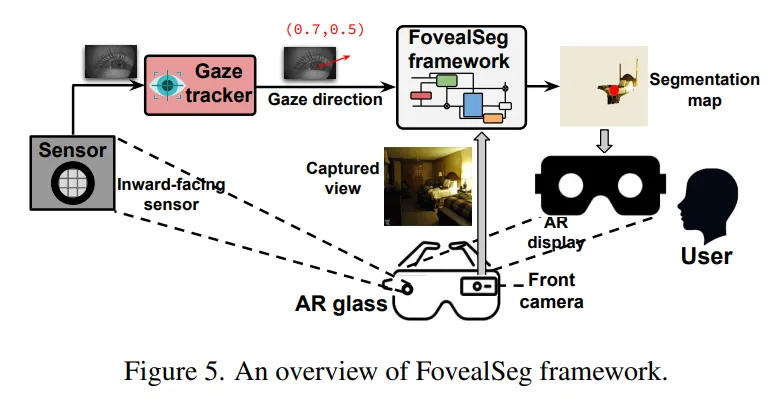
作者据此提出 FovealSeg:内向摄像头以 120 Hz 捕获眼部图像,经眼动追踪 5--10 ms 就能得出注视坐标;外向摄像头同步采集前向高分辨率画面。框架首先检测是否发生扫视(阈值 α),再判断场景是否突变(阈值 β),若两者皆否,就把分割任务限制在当前 gaze 坐标附近的 IOI 区域,并复用历史掩码。流程图见 Figure 5。
- 算法核心:FSNet
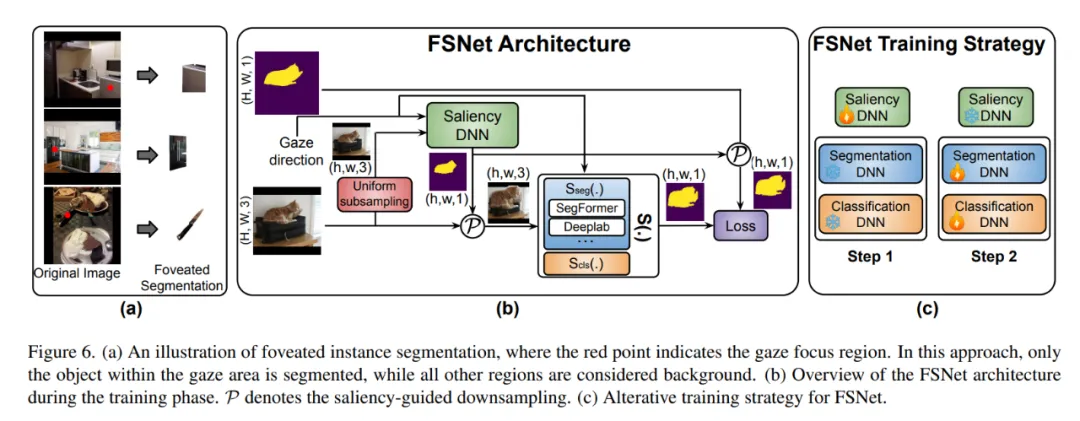
FovealSeg 的核心网络模块是 FSNet:
-
显著性自适应下采样 ------ 把 gaze 坐标编码成距离图,与原图拼成四通道张量;Saliency DNN 依据距离图按需放大 IOI、压缩背景。
-
分割 / 分类双分支 ------ 前支路输出二值 IOI 掩码,后支路输出类别向量,二者外积得最终掩码。
-
阶段式训练 ------ 先固定分割网训练 Saliency DNN,再反向微调分割 / 分类分支;Dice Loss + 面积加权 Focal Loss 解决小目标易被背景淹没的顽疾。
Figure 6 依次展示了 IOI 局部放大策略的可视化示意、网络结构图和交替训练流程。
- 效果验证:速度与精度双赢
在 ADE20K、LVIS、Cityscapes 等数据集上,作者用 Jetson Orin NX 做测试:
- FSNet 将输入缩到 64 × 64 仍能把 IoU 提到 0.36 以上,比统一下采样基线高 ≥ 0.14;
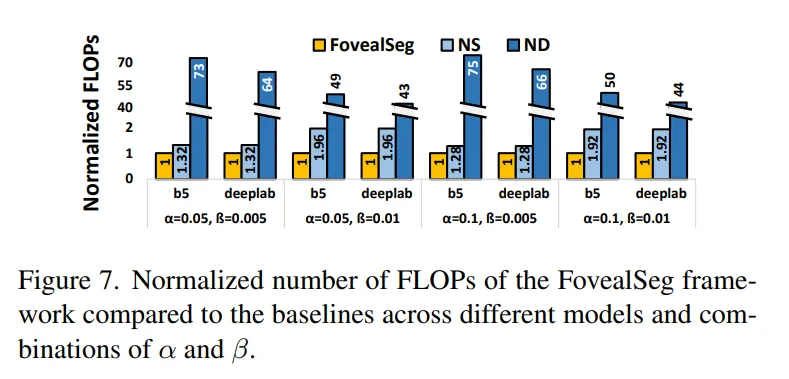
- FovealSeg 进一步利用跨帧重用,在 α=0.1、β=0.01 设置下把 FLOPs 降到 ND(无下采样 baseline)基线的 1⁄75,比 NS(无帧复用 baseline)进一步降低近两倍。
Figure 7 的柱状图直观呈现了不同 α、β 组合下三种方案的 FLOPs 差距,端到端延迟仅 84 ms,重回实时交互红线。
- 消融与讨论
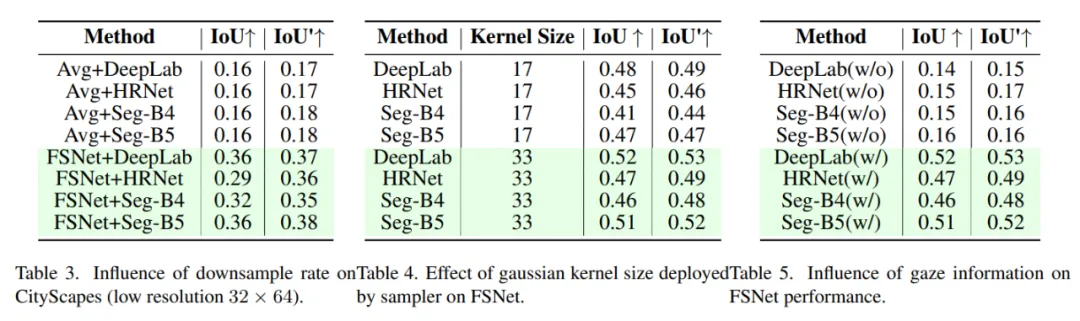
论文还就下采样倍率、Gaussian Kernel 大小、gaze 输入等因素做了消融:
- 下采样过猛虽降精度,但 FSNet 依旧显著优于平均池化基线;
- Kernel 越大,显著区域权重越高,精度随之提升。
- 将 gaze 坐标替换成随机噪声,IoU 至少掉 0.3,说明注视信息是方法立足之本。
这些对比虽以表格呈现(Table 3--5),但也佐证了 "人因驱动 + 统计约束" 在模型设计中的必要性。
- 小结与展望
FovealSeg 以人眼生理特征为钥匙,把'中央精细处理、周边压缩简化'的 foveated 思想真正落到实例分割上:
- FSNet 巧用显著性采样,把计算集中在 IOI,兼顾分割和分类;
- FovealSeg 又用扫视检测与帧间复用,把冗余推理压到极致。
在当前 XR 终端算力有限的背景下,它为 "毫秒级 IOI 分割" 提供了切实可落地的方案;随着更高精度、低延迟的眼动传感器普及,以及多 IOI 并行、多任务融合的需求升温,foveated 视觉计算或将成为 XR 生态里的 "默认范式",也为更多实时计算密集型任务(如场景理解、三维重建)提供新的能效平衡思路。
#姚顺雨提到的「AI下半场」
产品评估仍被误解
前段时间,OpenAI 研究员姚顺雨发表了一篇主题为「AI 下半场」的博客。其中提到,「接下来,AI 的重点将从解决问题转向定义问题。在这个新时代,评估的重要性将超过训练。我们需要重新思考如何训练 AI 以及如何衡量进展,这可能需要更接近产品经理的思维方式。」(参见《清华学霸、OpenAI 姚顺雨:AI 下半场开战,评估将比训练重要》)
由于观点非常有见地,这篇博客吸引了大量从业者围观。
有意思的是,亚马逊首席应用科学家 Eugene Yan 最近也发表了一篇博客,专门介绍 AI 产品的评估,可以说是对姚顺雨博客的有力补充。
这篇博客同样得到了诸多好评。
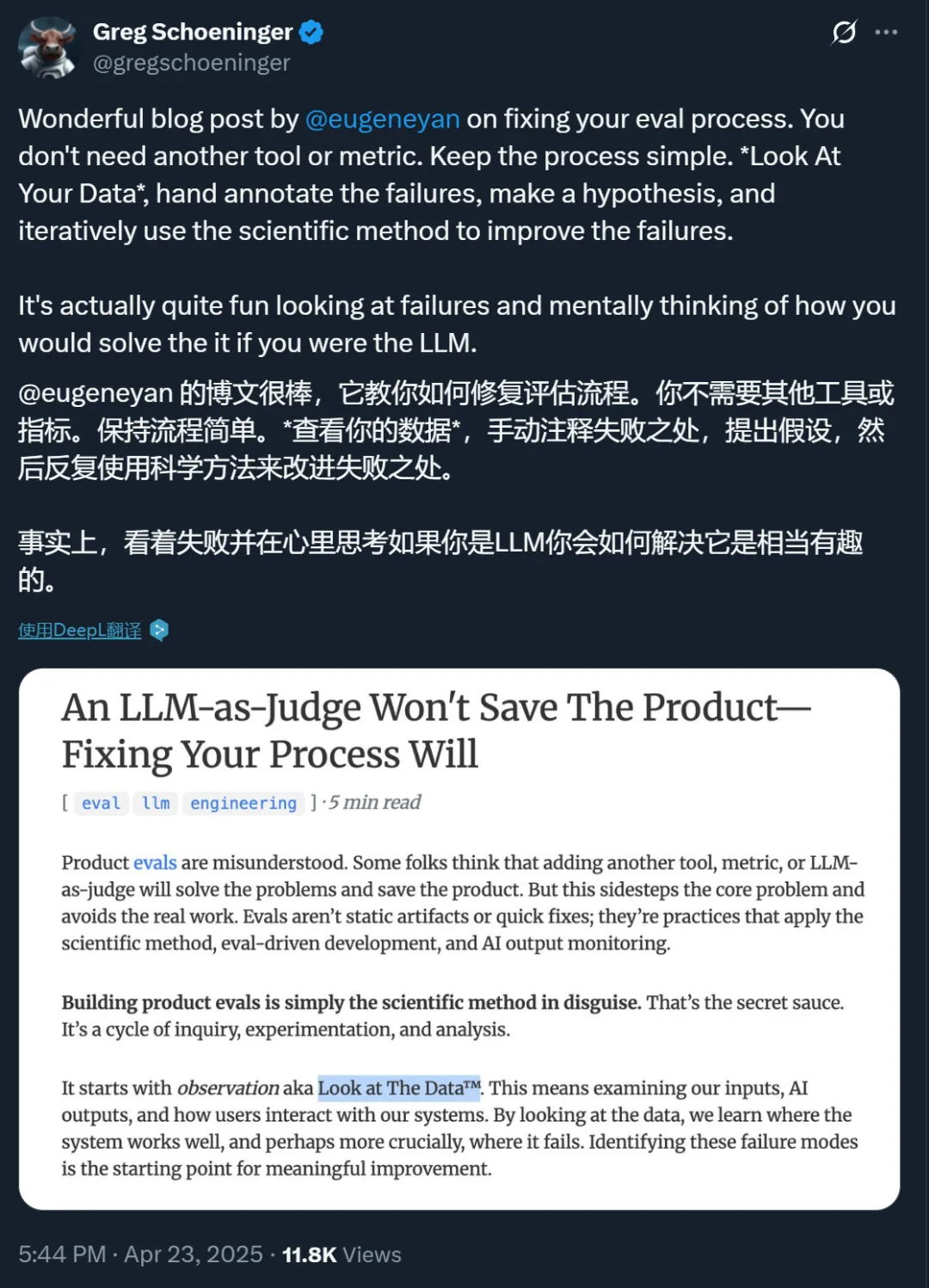
以下是博客原文。
自动化评估救不了你的产品
你得修复你的流程
产品评估这件事,很多人根本没搞懂。总有人以为再加个工具、添个指标,或者让大语言模型当裁判(LLM-as-judge),就能解决问题拯救产品。这根本是在回避核心问题,逃避真正该做的工作。评估并非一劳永逸,也不是什么快速起效的方法 ------ 它是运用科学方法的持续实践,是评估驱动开发,是 AI 输出的持续监测。
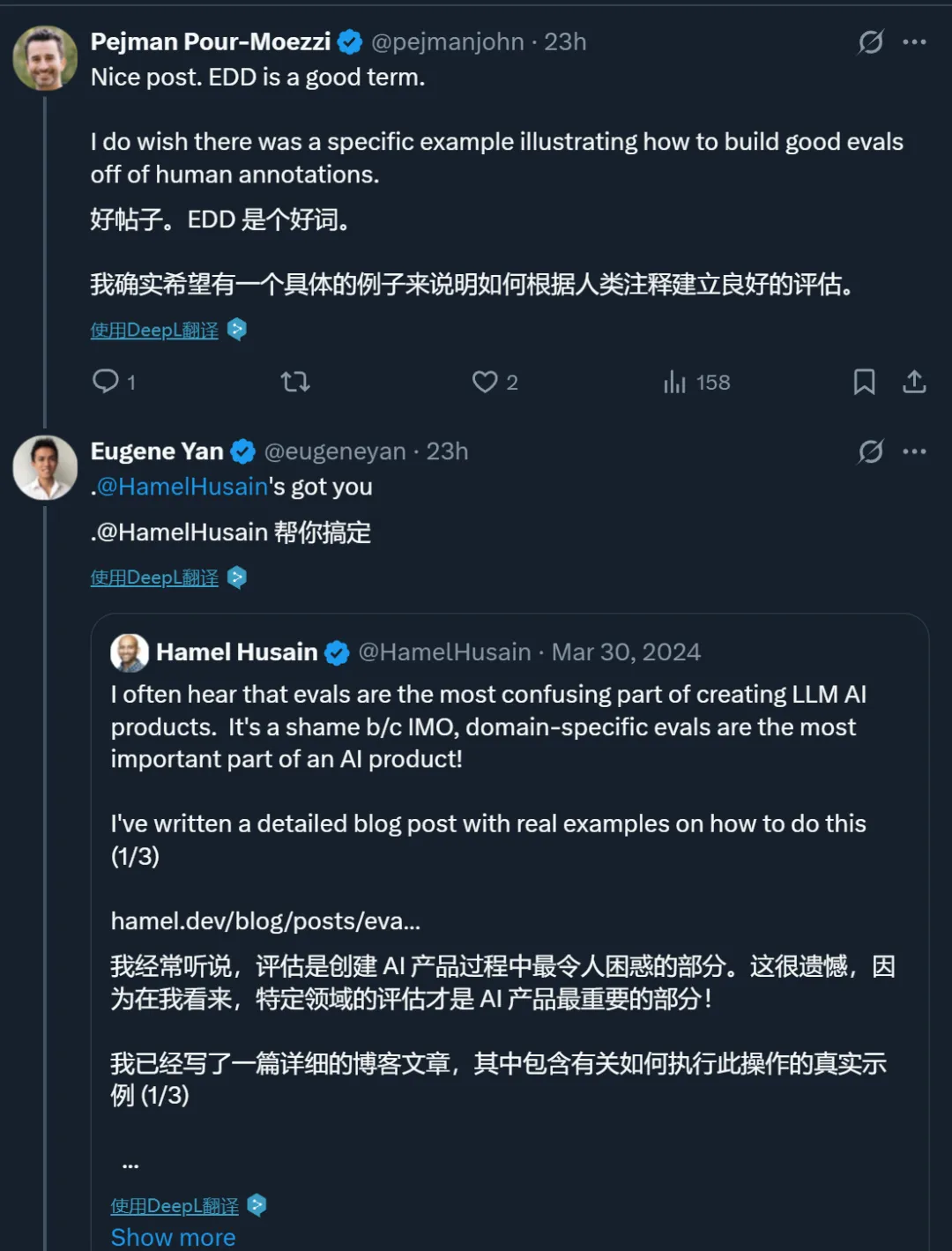
构建产品评估体系,本质上就是在践行科学方法。这才是真正的秘诀。它是一个不断提问、实验和分析的循环。
首先从观察开始,也就是「看数据」。我们要审视输入内容、AI 输出结果,以及用户与系统的交互情况。数据会告诉我们系统哪里运转良好,更重要的是,哪里会出问题。发现这些故障模式才是有效改进的起点。
接着我们标注数据,优先处理问题输出。这意味着要对成功和失败的样本进行标记,建立平衡且有代表性的数据集。理想情况下,正负样本应该五五开,并覆盖各类输入场景。这个数据集将成为针对性评估的基础,帮我们追踪已发现问题的改进情况。
然后,我们提出假设:为什么会出现这个错误?可能是 RAG 检索没返回相关上下文,也可能是模型处理复杂(有时自相矛盾)的指令时力不从心。通过分析检索文档、推理轨迹和错误输出等数据,我们能确定要优先修复的问题以及要验证的假设。
紧接着设计实验验证假设。比如重写提示词、更新检索组件或切换不同模型。好的实验要能明确验证假设是否成立,最好还设置基线对照组进行比较。
结果测量和错误分析往往是最难的环节。这不同于随意的感觉判断,必须量化实验改动是否真有效果:准确率提升了吗?缺陷减少了吗?新版本在对比测试中表现更优吗?无法量化的改进根本不算改进。
实验成功就应用更新,失败就深挖错误原因,修正假设再来一次。就在这个循环中,产品评估成了推动产品进步、减少缺陷、赢得用户信任的数据飞轮。
将科学方法应用于 AI 产品开发。
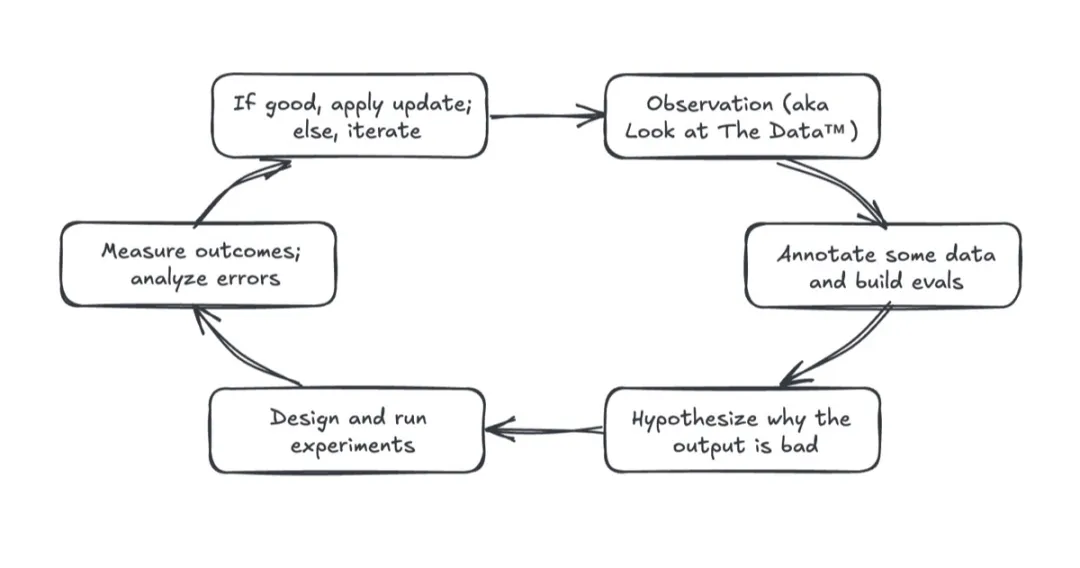
评估驱动的开发(Eval-driven development,EDD)能帮我们打造更好的 AI 产品。这类似于测试驱动的开发 ------ 先写测试用例,再实现能通过测试的代码。EDD 秉持相同理念:开发 AI 功能前,先通过产品评估定义成功标准,确保从第一天就有明确目标和可衡量的指标。说个秘密:机器学习团队几十年来都在这么做,我们始终根据验证集和测试集来构建模型系统,只是说法不同而已。
在 EDD 中,评估指引开发方向。我们先评估基线(比如简单提示词)获取基准数据。之后每个提示词调整、系统更新和迭代都要评估:简化提示词提升了准确性吗?检索更新增加了相关文档召回率吗?还是反而让效果变差了?
EDD 提供即时客观的反馈,让我们看清哪些改进有效。这个「写评估 - 做改动 - 跑评估 - 整合改进」的循环确保了可衡量的进步。我们建立的不是模糊的直觉判断,而是扎根于软件工程实践的反馈闭环。
先写评估标准,再构建能通过评估的系统。
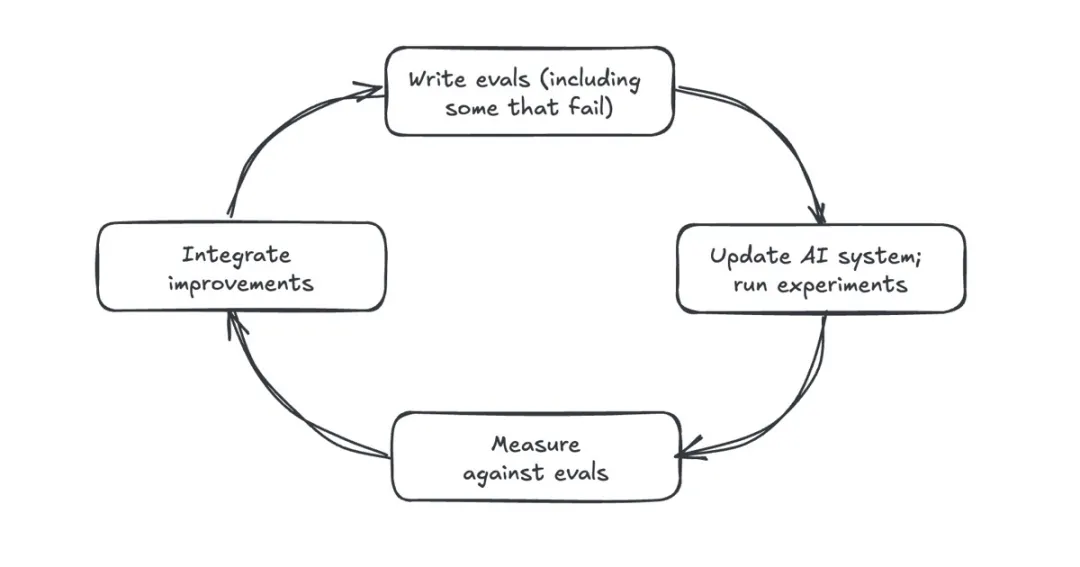
自动化评估工具(LLM-as-judge)也离不开人工监督。虽然自动化评估能扩大监测范围,但无法弥补人为疏忽。如果我们不主动审查 AI 输出和用户反馈,再多自动评估工具也救不了产品。
要评估和监测 AI 产品,通常需要采样输出并标注质量缺陷。有了足够多高质量标注数据,我们就能校准自动评估工具,使其与人类判断一致。这可能涉及测量二元标签的召回率 / 准确率,或通过两两比较决定输出之间的相关性。校准后的评估工具能有效扩展 AI 系统的持续监测能力。
但自动评估工具不能取代人工监督。我们仍需要定期采样、标注数据,分析用户反馈。理想情况下,我们应该设计能够通过用户交互获取隐式反馈的产品。不过,显式反馈虽然不那么频繁,偶尔也会有偏见,但也很有价值。
另外,自动评估工具虽扩展性强,但也不完美。不过人类标注员同样会犯错。只要持续收集更高质量的标注数据,我们就能更好地校准这些工具。保持「数据采样 - 输出标注 - 工具优化」的反馈循环,需要严格的组织纪律。
自动化评估工具本质上是人工标注与反馈流程的放大器。
虽然使用 AI 构建产品感觉很神奇,但仍然需要耗费大量精力。如果团队不应用科学的方法,实践评估驱动的开发,并监控系统的输出,那么购买或构建另一个评估工具将无法挽救产品。
原文链接:https://eugeneyan.com/writing/eval-process/
#Chain-of-Model Learning for Language Model
微软等提出「模型链」新范式,与Transformer性能相当,扩展性灵活性更好
随着大语言模型 (LLM) 的出现,扩展 Transformer 架构已被视为彻底改变现有 AI 格局并在众多不同任务中取得最佳性能的有利途径。因此,无论是在工业界还是学术界,探索如何扩展 Transformer 模型日益成为一种趋势。
在此背景下,LLM 的参数规模呈指数级增长,从数十亿级增长到数万亿级。因此,其爆炸式增长的参数规模也给训练带来了极其昂贵的负担,并且无法针对不同的部署环境提供不同的推理用途。
鉴于这种日益增长的扩展律,如何开发和有效利用 LLM 来处理各种场景中的用户指令,已成为整个社区面临的一个开放且关键的挑战。
目前,扩展 LLM 架构存在以下问题:
与人类智能能够渐进式获取新知识不同,现有的扩展策略无法保留已有知识规模,总是需要从头开始训练,导致效率低下。
现有 LLM 架构(如密集模型或 MoE)始终激活固定规模的参数,缺乏动态适应问题解决能力的机制。
本文,来自微软、复旦大学、浙江大学以及上海科技大学的研究者提出了一个新的概念,CoR(Chain-of-Representation,表征链),它将表征范式的范畴泛化到更广泛的范围。
- 论文标题:Chain-of-Model Learning for Language Model
- 论文地址:https://arxiv.org/pdf/2505.11820
具体而言,本文观察到任何表征总是可以看作是隐藏维度上多个子表征的组合。因此,本文将这种组合定义为表征链,每个子表征对应一条链。基于此定义,通过使用不同数量的前导链(preceding chains),其对应的特征可以用来编码不同的知识(称之为 scale),如图 1 所示。
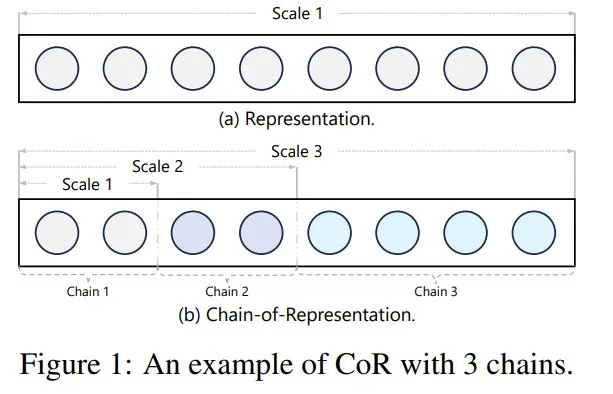
因此,如何在 CoR 特征之间建立连接以确保跨尺度的特征转换是非常关键的。
为了实现这一目标,本文接着提出了一种名为模型链(Chain-of-Model,CoM)的新型学习范式,用于建模 CoR 特征。
其核心思想是在不同尺度之间引入因果依赖关系,确保每个尺度只能使用其前面尺度的信息。为此,本文提出了链式层(Chain-of-Layer,CoL),以基于 CoR 特征重新构建当前的网络层。
在 CoM 框架的基础上,本文将 CoL 的思想应用于 Transformer 的每一层,重新构建了语言模型架构,并将其命名为语言模型链(CoLM)。
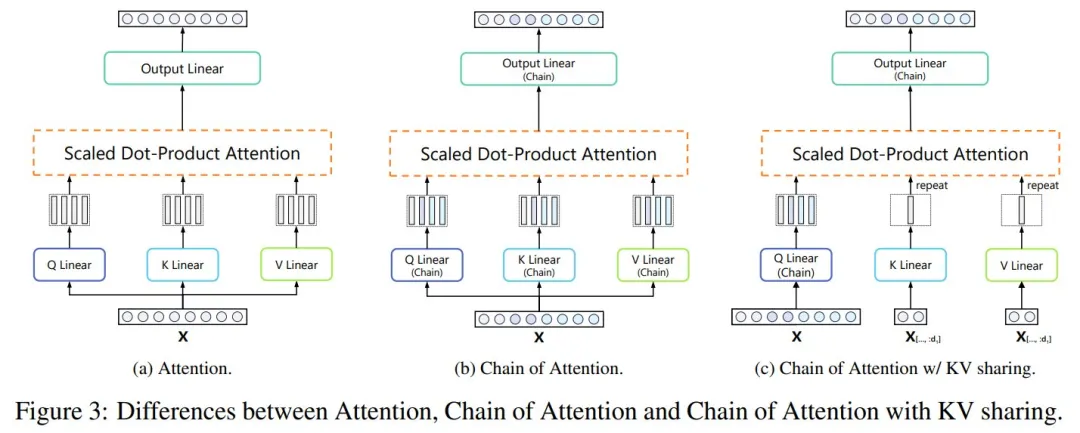
此外,基于 CoL 准则,本文在注意力模块中进一步引入了键值共享机制,该机制要求所有键和值都在第一个链中进行计算,并将其命名为 CoLM-Air。基于此机制,CoLM-Air 提供了更高的可扩展性和灵活性。
多个基准测试实验结果表明,CoLM 系列模型能够达到相当的性能,同时展现出更好的可扩展性和灵活性。
方法介绍
首先是表征链的定义:

据定义 1,每个链对应于 CoR 中的每个子表征,通过激活前几个链,CoR 可以用来编码尺度。因此,CoR 允许在单一表示中编码 n 个不同的尺度。如果 n=1,CoR 与原始表示相同。图 1 展示了 CoR 的概念。
基于上述定义,现在面临的一个挑战是如何设计层来建立 CoR 输入和 CoR 输出之间的连接,从而实现多尺度特征转换,同时又能保持输出特征符合定义 1 中 CoR 的标准。
这就需要保证每个尺度只能利用其所有前一个尺度的信息,并同时引入 Chain-of-Layer 将因果关系融入 CoR 的隐藏状态中,如下所示:
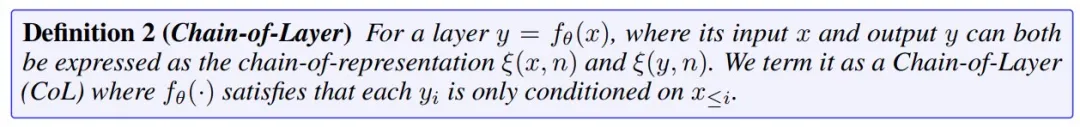
其中,CoL 具有三个基本属性 ------ 普遍性、因果性和组合性。
最重要的是,CoL 支持组合性,这意味着堆叠多个 CoL 层也能保留 CoL 的特性。这一特性能够将 CoL 的范围从层级推广到模型级。
接着本文又给出了第三个定义

根据定义 3,如果一个模型满足了 CoM 的标准,那么它也继承了 CoL 的所有属性,例如通用性和因果关系。换句话说,任何模型都可以被视为一种 CoM(即 n = 1)。 CoM 可以将不同规模的多个子模型集成到一个模型中,能够在现有模型的基础上进行扩展。这种能力直接赋予了基础模型更好的可扩展性和灵活性。
接着,文章详细描述了如何将 CoM 应用于语言模型,包括 Linear、Transformer 中的每个模块(例如,嵌入、自注意力、前馈、归一化)以及目标函数,并将其称为 CoLM(Chain-of-Language-Model)。此外,本文进一步引入了一种基于 CoLM 框架的键值共享机制,并将其称为 CoLM-Air,它提供了更好的灵活性。
图 2 描述了线性层和 Chain-of-Linear 层的比较。
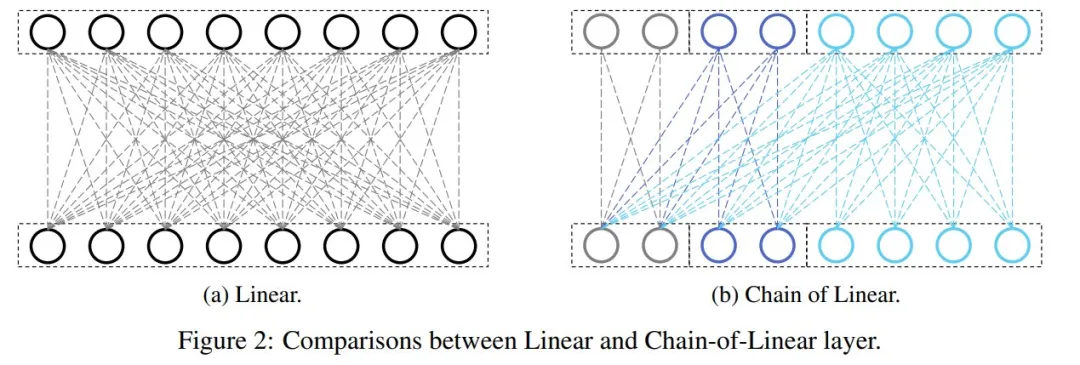
图 3 说明了注意力和注意力链的区别:
对这部分内容感兴趣的读者,可以参考原论文了解更多内容。
实验结果
表 1 结果表明,CoLM 取得了与基线相当的结果,同时提供了更快的预填充速度和更高的灵活性。
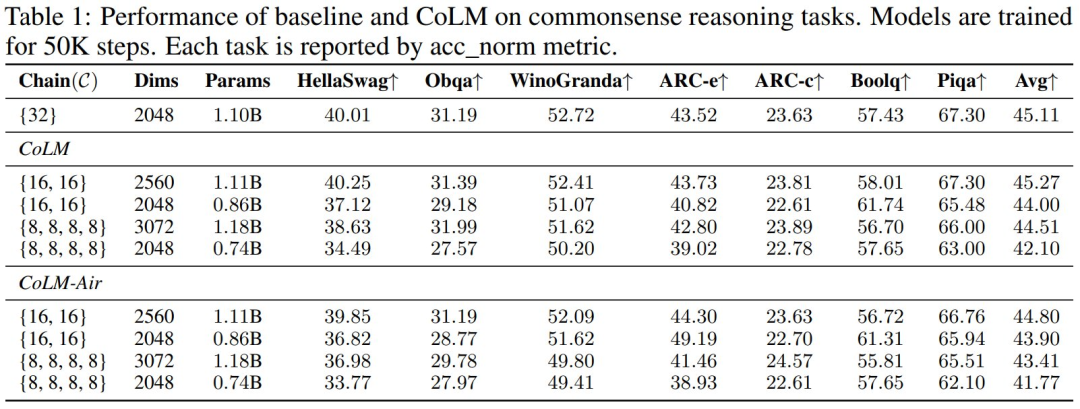
考虑到 CoM 的通用性与因果性,任何模型在链数为 1 时均可视为 CoM 的特例,并可扩展至多链结构。因此,本文提出链式扩展(Chain Expansion)方法:以训练完备的模型作为初始链,通过新增链进行扩展。
为验证这一观点,本文选择了两个 LLaMA 变体(即 TinyLLaMA-v1.1 和 LLaMA-3.21B)作为扩展的初始链。
表 2 结果表明,与 TinyLLaMA-v1.1 和 LLaMA-3.2-1B 相比,本文分别实现了 0.92 和 0.14 的提升。由于 LLaMa-3.2-1B 是更强的基线,因此需要更多计算才能获得显著提升,但本文方法在有限的计算量下仍然可以对其进行改进。总体而言,这些结果也表明,即使在资源受限的情况下,本文方法在改进基线方面仍然有效。
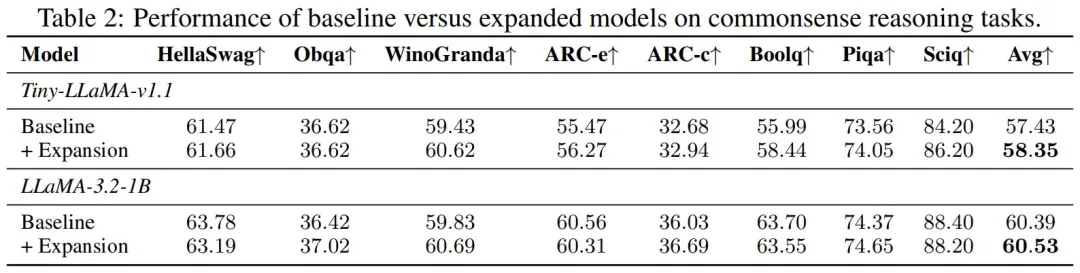
弹性推理旨在提供动态推理能力以满足不同部署场景的需求。表 3 结果进一步凸显了 CoLM 在实现弹性推理方面的潜力。

从图 5 可以看出,在参数量相近的情况下,CoLM-Air 相比 LLaMa 实现了更快的预填充速度。随着序列长度的增加,CoLM-Air 在预填充阶段能获得更显著的速度提升。这充分证明了 CoLM-Air 能有效加速预填充过程。
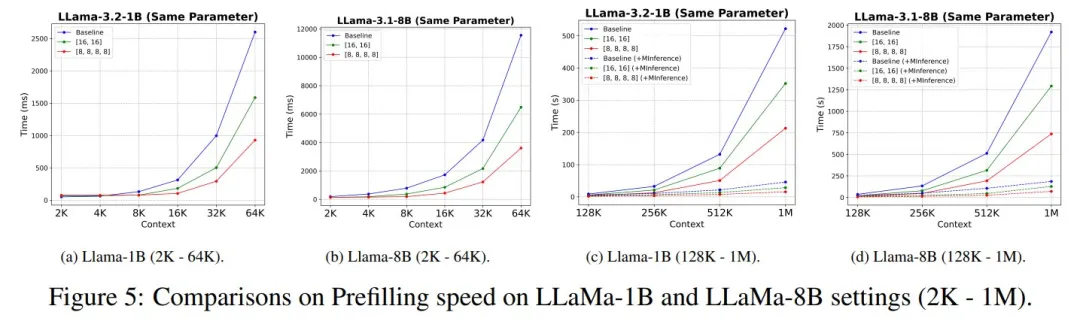
得益于 CoM 架构的因果特性,CoLM 由多个链式模块组成,其中每个链都能继承前序链的能力。基于这一特性,本文提出链式调优(Chain Tuning)方法 ------ 在冻结前几个链的同时仅对后续链进行微调。该方法通过保留初始链参数,既能降低约 42% 的调优成本,又可有效缓解灾难性遗忘问题。
此外,当采用 CoLM-Air 配置并冻结首链时,经微调模型产生的键值对可无缝迁移至原始模型,无需额外计算。实验表明,链式调优仅需微调约 42% 的模型参数即可提升性能,且能与 LoRA 等参数高效微调方法兼容。

#LSTM之父22年前构想将成真?
一周内AI「自我进化」论文集中发布,新趋势涌现?
让 AI 实现自我进化是人类一直以来的梦想。
早在 2003 年,AI 先驱、LSTM 之父 Jürgen Schmidhuber 就提出过一种名为「哥德尔机(Gödel Machine)」的构想------它使用一种递归的自我改进协议,如果能够证明新代码的策略较佳,就会重写自己的代码。但这终究只是一个假想。
近年来,关于模型自我学习、进化的研究逐渐多了起来,很多研究者的目标在逐渐从单纯的「训练模型」向「让模型学会自我学习和自我进化」转变,谷歌最近发布的 AlphaEvolve 就是其中的重要代表。
在过去的一周,这一方向的进展尤其丰富。有人发现,几篇关于「让 LLM(或智能体)学会自我训练」的论文在 arXiv 上集中出现,其中甚至包括受「哥德尔机」构想启发而提出的「达尔文哥德尔机」。或许,AI 模型的自我进化能力正在加速提升。

在这篇文章中,我们将详细介绍最近的几篇论文,它们分别是:
Sakana AI 与不列颠哥伦比亚大学等机构合作的「达尔文哥德尔机(DGM)」:DGM 利用基础模型和开放式算法来创建和评估新的 AI 智能体,并能够读取和修改自身的 Python 代码库以进行自我改进,还通过评估在编码基准上的性能来判断更改是否有效。实验表明,DGM 可以持续自我改进,并能在不同模型和编程语言之间实现迁移。
- CMU 的「自我奖励训练(SRT)」:提出了一种名为「自我奖励训练」的在线自我训练强化学习算法,旨在让大型语言模型通过自身的判断信号进行自我监督和训练,从而在没有外部标签的情况下提升性能。
- 上海交通大学等机构提出的多模态大模型的持续自我改进框架「MM-UPT」:在完全无监督场景下,通过强化学习框架 GRPO 实现多模态大模型的持续自我改进。他们提出了一种简洁而高效的框架:MM-UPT(Multi-Modal Unsupervised Post-Training),并在多个图文数学推理 benchmarks 上验证了其有效性。
- 香港中文大学联合 vivo 等机构的自改进框架「UI-Genie」:旨在解决 GUI 智能体中的两大核心挑战:一是轨迹结果的验证十分困难,二是高质量训练数据的规模化获取不易。针对这两个挑战,研究团队分别提出了一种奖励模型和一个自改进流水线。
达尔文哥德尔机:让 AI 通过重写自己的代码实现自我改进
- 论文标题:Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents
- 论文链接:https://arxiv.org/abs/2505.22954
- 博客:https://sakana.ai/dgm/
人工智能研究的一个长期目标是创造能够持续学习的 AI 系统。实现这一目标的一条诱人路径是让 AI 通过重写自身代码(包括负责学习的代码)来实现自我改进。这一由 Jürgen Schmidhuber 数十年前提出的构想被称为「哥德尔机」,是一种假想中的自我改进型 AI。当它在数学上证明存在更优策略时,它会通过递归地重写自身代码来优化问题解决方案,因此成为元学习(即「学会学习」)领域的核心概念。
虽然理论上的哥德尔机能确保可证明的良性自我修改,但其实现依赖于一个不切实际的假设:AI 必须能在数学上证明代码修改会带来净效益才会实施变更。
针对此问题,Sakana AI 与不列颠哥伦比亚大学 Jeff Clune 实验室合作,提出了一种更可行的方案:利用达尔文进化等开放式算法的原理,通过实证检验来寻找能提升性能的改进方法。
他们将这一成果命名为「达尔文哥德尔机(DGM)」。DGM 系统利用基础模型提出代码改进方案,并采用开放式算法的最新创新来搜索不断增长的多样化优质 AI 智能体库。实验表明,DGM 获得的算力越多,自我改进效果就越显著。鉴于依赖学习的 AI 系统终将超越人工设计系统这一明确趋势,DGM 很可能在短期内超越人工设计的 AI 系统。
第一个 DGM 是一个编码智能体,它能够:
- 读取并修改自己的代码;
- 评估修改是否提高了性能;
- 开放式地探索 AI 设计空间。

达尔文哥德尔机是一种通过重写自身代码来提升编程任务性能的自我改进型编程智能体。它能实现多种自我改进,包括:增加补丁验证步骤、优化文件查看功能、增强编辑工具、生成并排序多个解决方案以选择最优选项,以及在实施新修改时记录历史尝试记录(包括失败原因)。
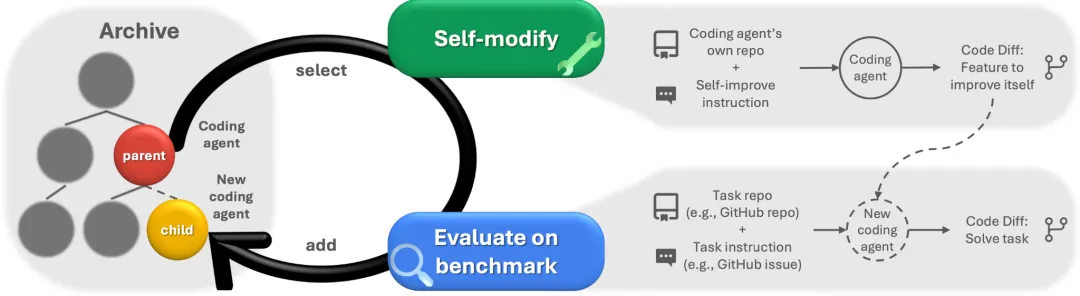
达尔文哥德尔机通过运用开放式探索原则,逐步构建起一个不断扩增的智能体库。该系统通过交替执行自我修改与下游任务评估的方式,持续创建新智能体并对其进行评分。
在 sw-bench 上,DGM 自动将其性能从 20.0% 提高到 50.0%。在 Polyglot 上,DGM 的表现从最初的 14.2% 跃升至 30.7%,远远超过了 Aider 手工设计的代表性智能体。这些可观的收益证明了 DGM 发现并实现对其自身代码的有益更改的能力。
模型的自我奖励训练:潜力、崩溃与缓解策略
- 论文标题:Can Large Reasoning Models Self-Train?
- 论文链接:https://arxiv.org/abs/2505.21444
- 项目地址:https://self-rewarding-llm-training.github.io/
- 代码地址:https://github.com/tajwarfahim/srt
- 数据集:https://huggingface.co/collections/ftajwar/self-rewarding-llm-training-6835218091832c3664176553
通过可验证奖励进行的强化学习显著增强了大语言模型的推理能力,尤其是在数学和编码方面。然而,这种方法依赖于人工创建的真实标签验证器,这使得为每个问题生成奖励信号的成本高昂且受到限制。在这项工作中,研究团队提出以下问题:
- 推理模型能否仅使用自身的反馈进行自我训练,而无需访问真实标签?
- 自我训练的性能能否达到基于真实标签的强化学习训练的水平?
- 自我训练能否无限期持续?其改进最终是否会受到限制?
- 哪些策略可以有效地维持模型的自我训练?
自我奖励培训(SRT)
受先前基于一致性自我提升研究的启发,研究团队引入了一种简单而有效的自我训练强化学习方法论,称为自我奖励训练(Self-Rewarded Training,SRT)。该方法在强化学习训练期间,通过模型生成的多个解决方案之间的一致性来评估正确性,从而在没有标注数据的情况下提供自监督信号。
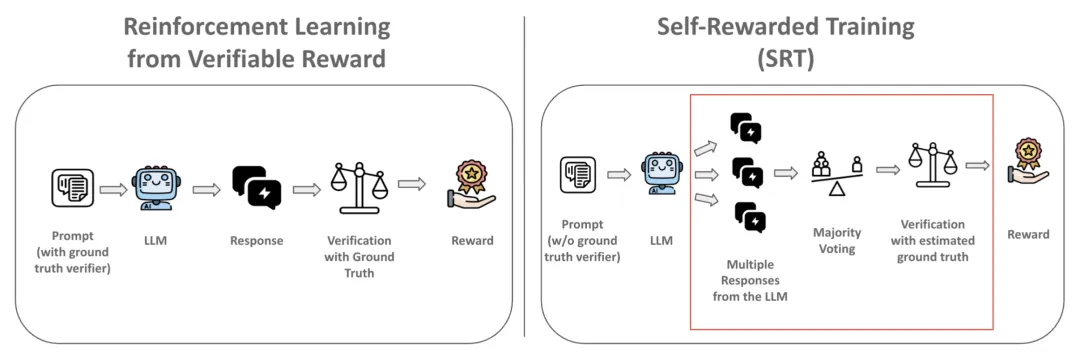
SRT 概览。在 RLVR 方法中,系统通过真实验证器生成用于强化学习训练的奖励信号。与之相反,SRT 方法并不依赖真实验证器,而是通过模型自身生成结果的多数投票机制来估算真实值,并利用这一替代性奖励信号来训练模型。
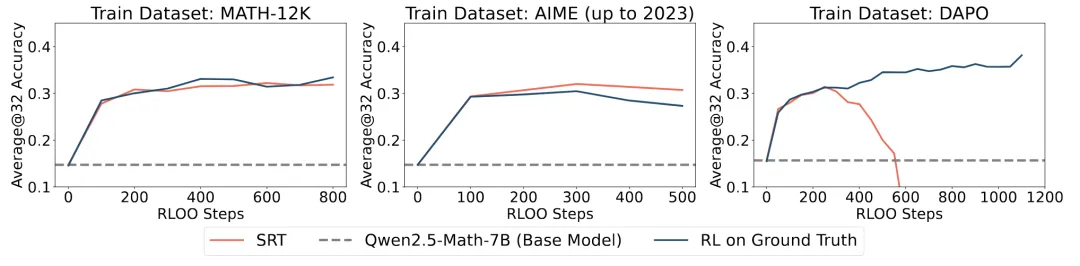
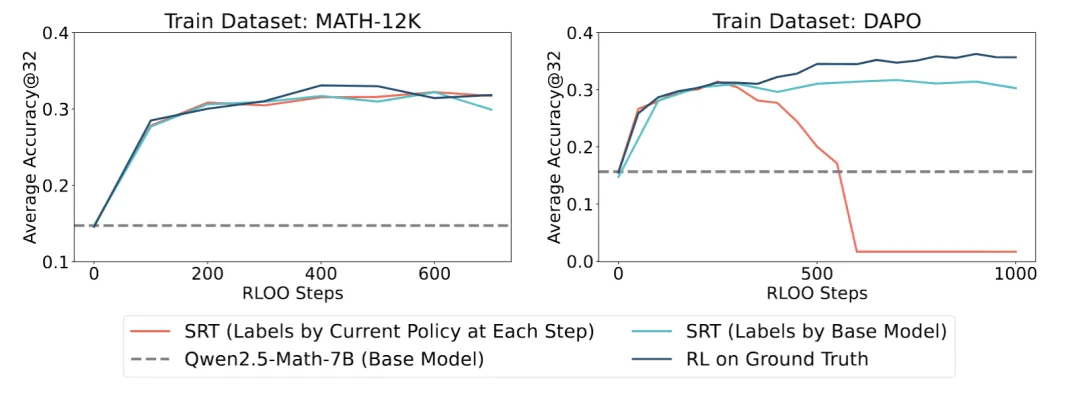
SRT 与早期训练阶段的 RL 性能相匹配
研究团队通过经验证明,在早期训练阶段,SRT 能够达到与那些在黄金标准答案上进行显式训练的标准强化学习方法相媲美的性能。测试数据集包括:AMC、AIME24、AIME25。 然而,研究团队发现其性能最终会崩溃,例如在最右图中展示的 DAPO 数据集上的训练情况。
自我训练必然会崩溃
研究团队分析了 SRT 在具有挑战性的 DAPO 数据集上训练时的训练动态。
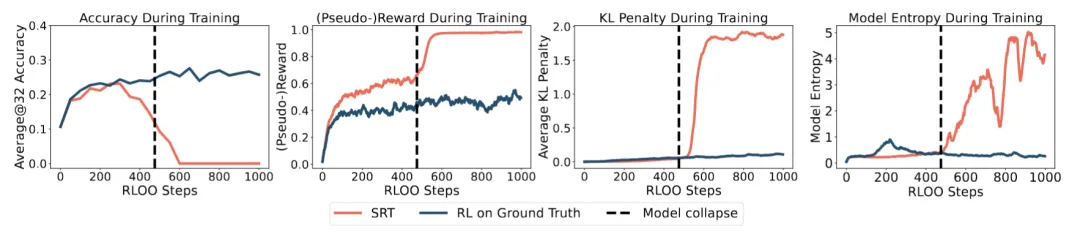
这些发现表明,模型通过产生一致(见上方第二个图)但错误(见上方最左图)的答案来学习最大化自我分配的奖励。人工检查证实了这一点:在崩溃之后,模型的输出会退化为随机的词元序列,并带有一个固定的、与提示无关的答案(例如,「答案是 1」)。这种行为有一个简单而精确的理论依据:

由 SRT 目标定义的强化学习优化问题明确鼓励输出之间的一致性,而不考虑其正确性。因此,在该目标下的最优策略会退化为无论输入如何都产生相同的答案,从而人为地最大化奖励。在这种代理 (proxy) 目标上持续进行自我训练,自然会驱动模型朝向这种平凡解 (trivial solution) 发展,特别是当这种解比解决实际任务更简单时。
缓解策略可能是有效的
研究团队提出了一些策略来缓解奖励作弊 (reward hacking),为未来维持模型持续改进的有效方法奠定基础。
(i)早停(Early Stopping):一个小的验证集可以可靠地检测到模型的最佳性能点,并防止在自我训练过程中发生崩溃。对于所有的留出集(heldout sets),最佳性能点几乎出现在同一位置,因此使用任何一个留出集进行早停都是有效的。
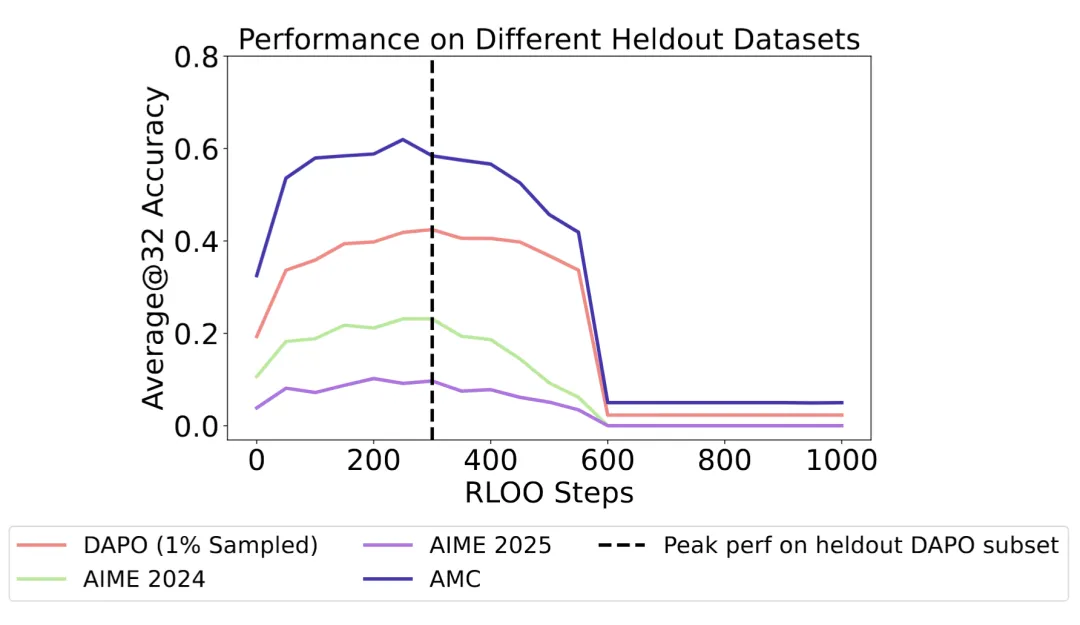
(ii)使用离线生成的标签进行自我训练:一种有效的方法是从一个稳定的、先前固定的检查点生成伪标签,而不是利用来自演进中的策略的标签。这样做可以稳定训练,同时达到与 SRT 相当的性能。
(iii)结合课程学习的自我训练:研究团队假设,在更具挑战性的数据集上训练时,模型崩溃会发生得更快,这一推测与研究团队的经验性发现一致。其直觉是,在更具挑战性的数据集上,模型更容易放弃其预训练知识,转而优化自我一致性,而不是真正学习解决潜在的任务。研究团队利用这一假设,通过根据(a)通过率和(b)多数投票的频率来识别 DAPO 数据集中「最简单」的子集,从而实施一种课程学习策略(更多细节请参见论文)。
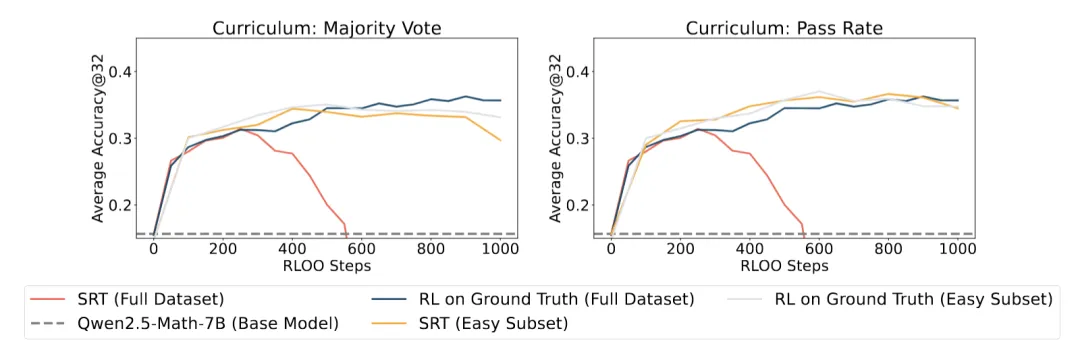
在这些课程子集上的性能达到了与在整个 DAPO 数据集上使用真实标签进行标准强化学习训练相当的水平。这些富有前景的结果表明,课程学习策略可能会进一步扩展 SRT 的益处,为未来的研究开辟了激动人心的途径。
MM-UPT:多模态大模型的持续自我进化
- 论文标题:Unsupervised Post-Training for Multi-Modal LLM Reasoning via GRPO
- 论文链接:https://arxiv.org/abs/2505.22453
- 项目代码:https://github.com/waltonfuture/MM-UPT
近年来,多模态大语言模型在视觉问答、图文推理等任务上取得了显著进展。然而,要在这些强大的基础模型之上进一步提升性能,往往需要依赖高质量人工标注数据进行监督微调或强化学习,这在成本与可扩展性上面临严峻挑战。过往研究虽然探索了无监督后训练方法,但大多流程复杂、难以迭代、数据利用率低。

在这篇论文中,作者首次探索了在完全无监督场景下,通过强化学习框架 GRPO 实现多模态大模型的持续自我改进。他们提出了一种简洁而高效的框架:MM-UPT(Multi-Modal Unsupervised Post-Training),并在多个图文数学推理 benchmarks 上验证了其有效性。
MM-UPT 的核心思想主要为以下两个关键点:
- 强化学习中的 GRPO 提供了稳定高效的在线策略优化能力;
- 多数投票可以在无标签数据上为模型输出生成伪标签,驱动自我优化。
整个流程如下:
- 给定一张图片和一个问题,模型生成多个候选回答;
- 使用多数投票选出出现频率最高的回答,作为当前输入的「伪标签」;
- 使用这个「伪标签」来计算 reward,引导模型根据 GRPO 策略更新;
这整个过程无需任何外部监督信号或真实答案,使得模型可以基于自身的「共识」行为进行强化学习,从而实现持续的性能提升。
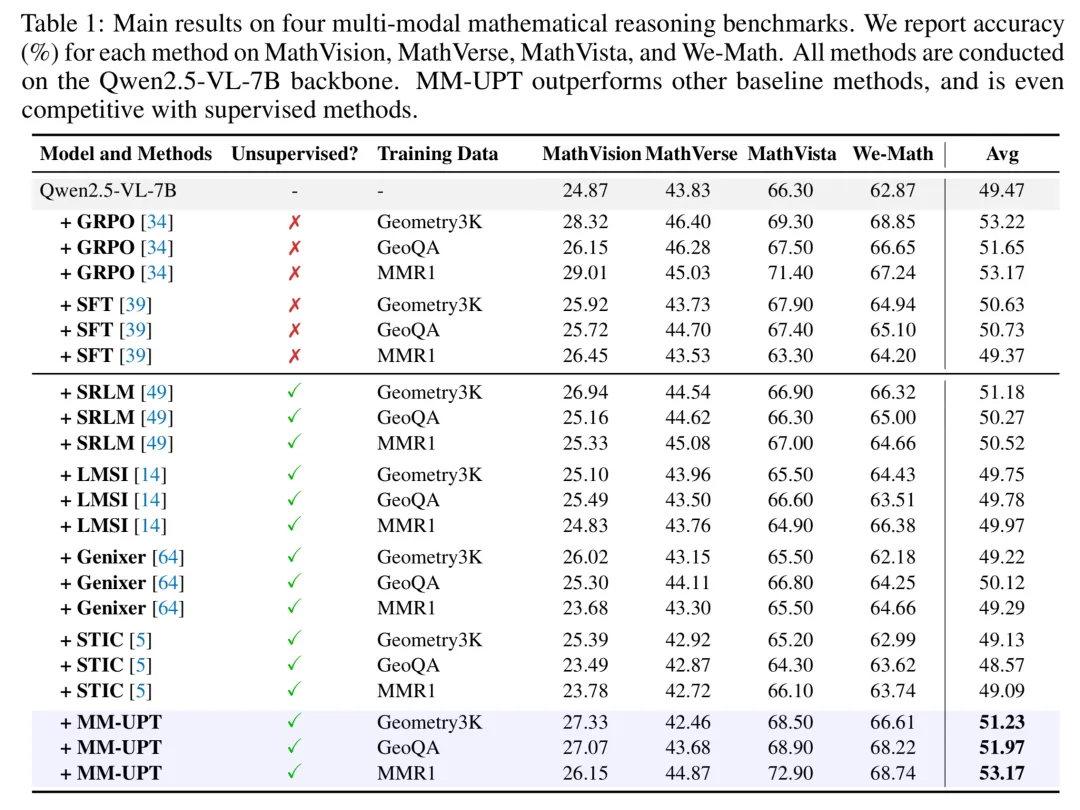
作者在四个多模态数学推理基准测试集(MathVisioan、MathVista、We-Math、MathVerse)上进行了广泛实验。表格 1 的结果显示:
- 在使用标准的训练集但不使用任何人工标注答案的情况下,MM-UPT 可以使 Qwen2.5-VL-7B 的准确率从 66.3% 提升至 72.9%(MathVista);
- 超过之前的无监督自我改进方法(如 Genixer、STIC、SRLM 等);
- 表现甚至媲美有监督的 GRPO;
在标准数据集上遮盖答案进行无监督训练后,作者进一步探究了一个更具挑战的问题:模型能否通过自己生成训练数据来实现自我提升?为此,MM-UPT 引入了两种简单的合成数据生成策略:
In-Context Synthesizing(上下文引导生成)
模型在给定图像、原问题和原答案的前提下生成一个新的问题。生成的问题与原问题在结构上相近,相当于进行语义改写或条件替换来进行数据增强。
Direct Synthesizing(直接生成)
仅提供图像输入,模型完全基于图片内容生成问题。这种方法生成的问题更加多样,但也存在一定概率的幻觉。 无论使用哪种方式生成问题,MM-UPT 都采用多数投票生成伪标签,驱动模型进行强化学习更新。
表格 2 中的结果显示:即便训练数据完全由模型自己生成,MM-UPT 仍然能显著提升多模态推理能力,甚至在部分任务上超越使用原始问题的数据。这表明,多模态大模型具备一定的「自我提问 + 自我优化」的潜力,为未来依靠 AI 自行生成训练语料进行自我进化的范式提供了坚实基础。
MM-UPT 为什么有效?作者用一个简单的例子解释了其有效性。假设模型对某个二分类问题,模型每次预测正确的概率较高,
。从该模型独立采样
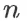
个回答

,多数投票选出出现频率最高的答案作为伪标签。定义随机变量
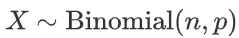
表示预测正确的次数,则多数投票正确的概率为:
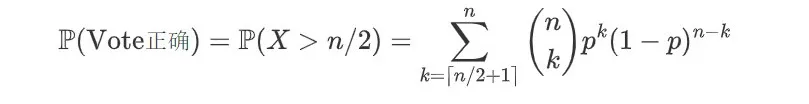
由于
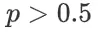
,有:
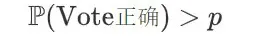
即:多数投票比单次预测更可靠。这就是 MM-UPT 中用多数投票作为伪标签的合理性所在 ------ 它可以构造一个有效的自监督奖励信号。但作者也指出了边界条件:当模型对任务缺乏先验时(如在 ThinkLite-11K 这种困难的数据集上),多数投票会反而强化错误预测,导致性能下降。
总的来说,MM-UPT 为多模态大模型的后训练阶段提供了一种无需人工标注、无需外部奖励模型的自我提升方式,展现了强化学习在无监督场景下的潜力。后续可以探索结合更强的自我评估机制(如 LLM-as-a-Judge)、复杂 reward 设计等,进一步拓展 MM-UPT 框架的能力边界。
UI-Genie:赋能 GUI 智能体高效自改进的新框架
- 论文标题:UI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
- 论文链接:https://arxiv.org/abs/2505.21496
- 项目地址:https://github.com/Euphoria16/UI-Genie
在这篇论文中,研究团队介绍了一种名为 UI-Genie 的自改进框架,旨在解决 GUI 智能体中的两大核心挑战:一是轨迹结果的验证十分困难,二是高质量训练数据的规模化获取不易。针对这两个挑战,研究团队分别提出了一种奖励模型和一个自改进流水线。
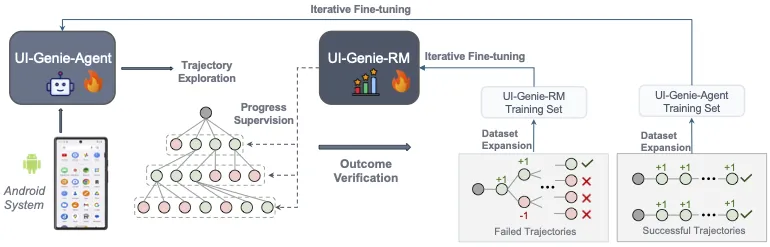
该奖励模型,即 UI-Genie-RM,采用了一种图文交错的架构,能够高效处理历史上下文信息,并统一了动作级别和任务级别的奖励:
- 通过迭代式合成轨迹生成,消除人工标注
- 通过自改进循环,共同演进智能体和奖励模型
- 无需人工干预即可生成高质量数据集
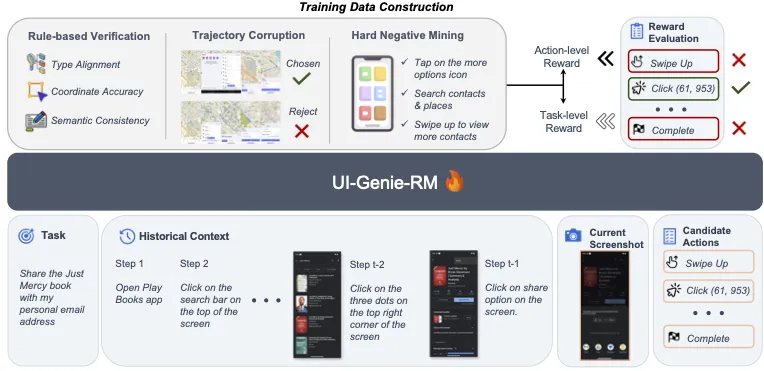
为了支持 UI-Genie-RM 的训练,研究团队开发了精心设计的数据生成策略,包括基于规则的验证、受控的轨迹损坏以及难负例挖掘。
为应对第二个挑战,研究团队设计了一个自改进流水线,通过在动态环境中进行奖励引导的探索和结果验证,逐步增强智能体和奖励模型的能力,从而扩展可解决的复杂 GUI 任务范围。
在模型训练方面,研究团队生成了 UI-Genie-RM-517k 和 UI-Genie-Agent-16k 数据集,这不仅是首个针对 GUI 智能体的奖励专用数据集,同时也展示了无需人工标注即可生成高质量合成轨迹的能力。
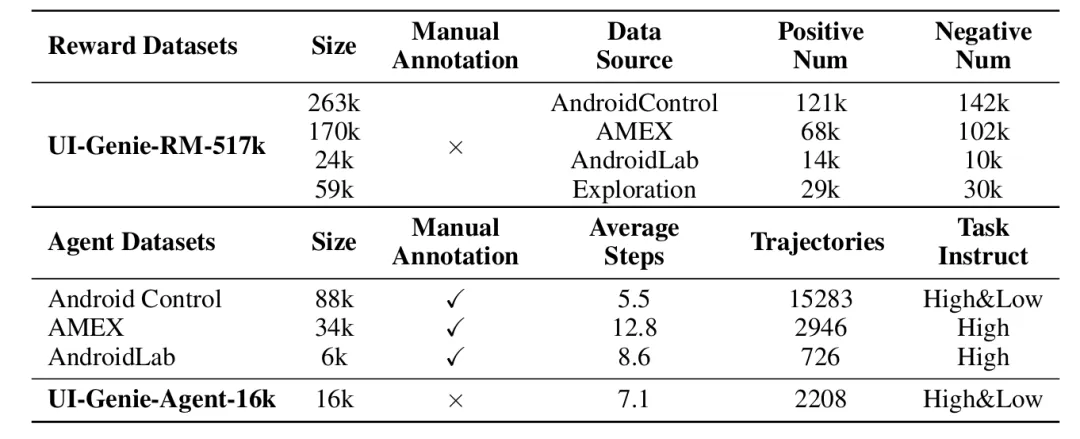
UI-Genie 数据集统计信息。UI-Genie-RM-517k 是首个专用于 GUI 智能体的奖励数据集,而 UI-Genie-Agent-16k 则包含了无需人工标注的合成轨迹。
实验结果表明,经过三代数据与模型的自改进迭代,UI-Genie 在多个 GUI 智能体基准测试中均达到了业界领先水平。研究团队已将完整的框架实现和生成的数据集开源,以促进该领域的进一步研究。
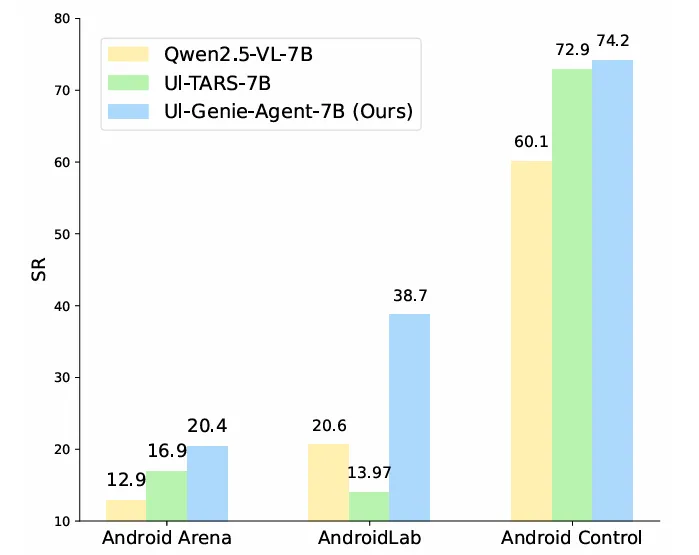
UI-Genie、Qwen2.5-VL 和 UI-TARS 在三个基准上的性能比较。
关于模型自我改进的论文还有很多,如果你也在做相关研究,欢迎在评论区留言推荐自己的工作。
#Video-XL-2
万帧?单卡!智源研究院开源轻量级超长视频理解模型
长视频理解是多模态大模型关键能力之一。尽管 OpenAI GPT-4o、Google Gemini 等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。
近日,智源研究院联合上海交通大学等机构,正式发布新一代超长视频理解模型:Video-XL-2。相较于上一版本的 Video-XL,该模型在多个维度全面优化了多模态大模型对长视频内容的理解能力:
效果更佳:Video-XL-2 在长视频理解任务中表现出色,在 MLVU、Video-MME、LVBench 等主流评测基准上达到了同参数规模开源模型的领先水平。
长度更长:新模型显著扩展了可处理视频的时长,支持在单张显卡上高效处理长达万帧的视频输入。
速度更快:Video-XL-2 大幅提升了处理效率,编码 2048 帧视频仅需 12 秒,显著加速长视频理解流程。
目前,Video-XL-2 的模型权重已全面向社区开放。未来,该模型有望在影视内容分析、异常行为监测等多个实际场景中展现重要应用价值。
- 项目主页:https://unabletousegit.github.io/video-xl2.github.io/
- 模型 hf 链接:https://huggingface.co/BAAI/Video-XL-2
- 仓库链接:https://github.com/VectorSpaceLab/Video-XL
技术简介
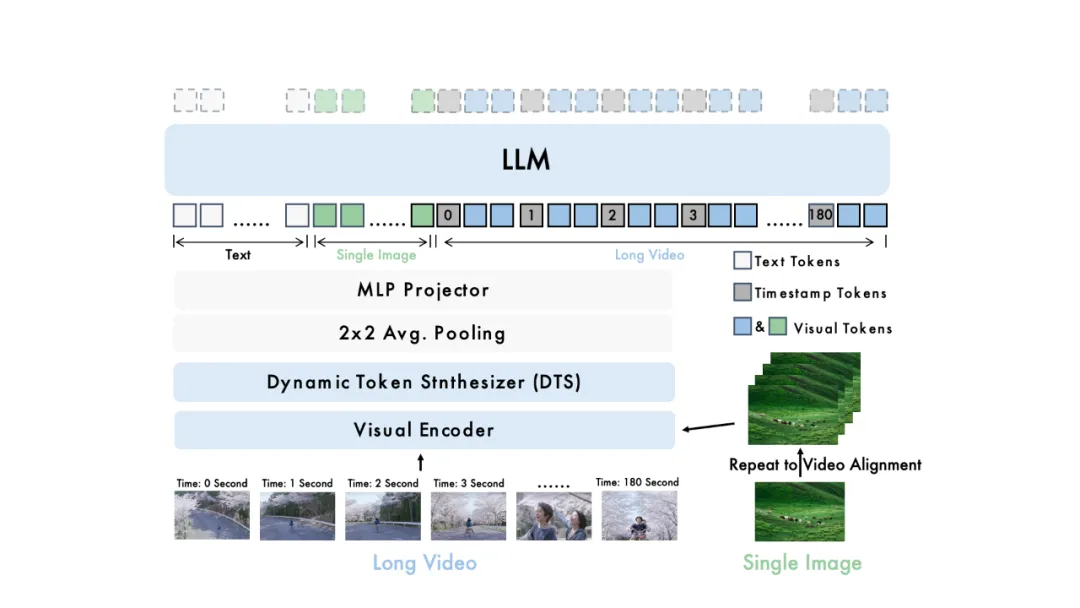
图 1:Video-XL-2 的模型架构示意图
在模型架构设计上,Video-XL-2 主要由三个核心组件构成:视觉编码器(Visual Encoder)、动态 Token 合成模块(Dynamic Token Synthesis, DTS)以及大语言模型(LLM)。
具体而言,Video-XL-2 采用 SigLIP-SO400M 作为视觉编码器,对输入视频进行逐帧处理,将每一帧编码为高维视觉特征。随后,DTS 模块对这些视觉特征进行融合压缩,并建模其时序关系,以提取更具语义的动态信息。处理后的视觉表征通过平均池化与多层感知机(MLP)进一步映射到文本嵌入空间,实现模态对齐。最终,对齐后的视觉信息输入至 Qwen2.5-Instruct,以实现对视觉内容的理解与推理,并完成相应的下游任务。

图 2:Video-XL-2 的训练阶段示意图
在训练策略上,Video-XL-2 采用了四阶段渐进式训练的设计 ,逐步构建其强大的长视频理解能力。前两个阶段主要利用图像 / 视频 - 文本对,完成 DTS 模块的初始化与跨模态对齐;第三阶段则引入更大规模,更高质量的图像与视频描述数据,初步奠定模型对视觉内容的理解能力;第四阶段,在大规模、高质量且多样化的图像与视频指令数据上进行微调,使 Video-XL-2 的视觉理解能力得到进一步提升与强化,从而能够更准确地理解和响应复杂的视觉指令。
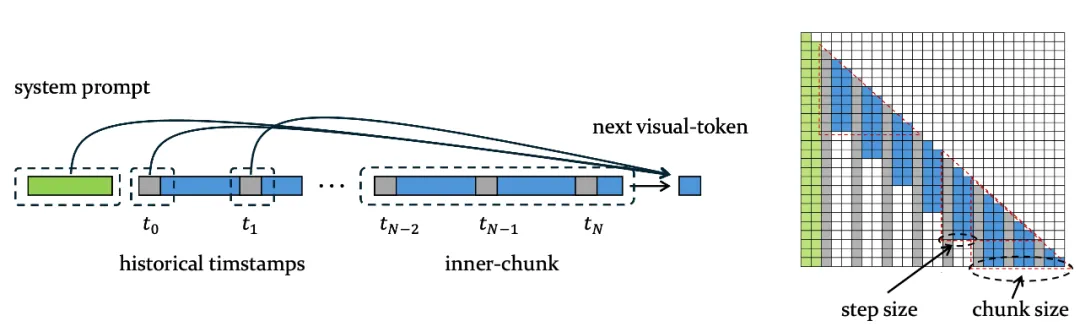
图 3. Chunk-based Prefilling
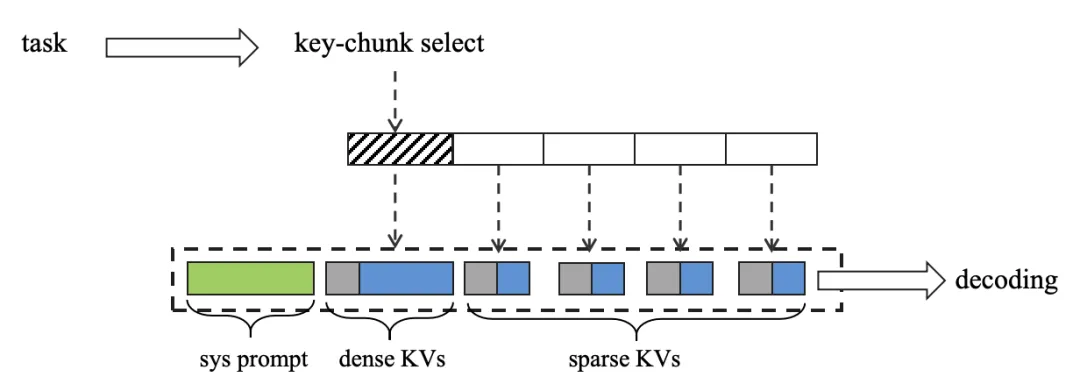
图 4. Bi-granularity KV Decoding
此外,Video-XL-2 还系统性设计了效率优化策略。首先,Video-XL-2 引入了分段式的预装填策略(Chunk-based Prefilling,如图 3 所示):将超长视频划分为若干连续的片段(chunk),在每个 chunk 内部使用稠密注意力机制进行编码,而不同 chunk 之间则通过时间戳传递上下文信息。该设计显著降低了预装填阶段的计算成本与显存开销。
其次,Video-XL-2 还设计了基于双粒度 KV 的解码机制(Bi-granularity KV Decoding,如图 4 所示):在推理过程中,模型会根据任务需求,选择性地对关键片段加载完整的 KVs(dense KVs),而对其他次要片段仅加载降采样后的稀疏的 KVs(sparse KVs)。这一机制有效缩短了推理窗口长度,从而大幅提升解码效率。得益于上述策略的协同优化,Video-XL-2 实现了在单张显卡上对万帧级视频的高效推理,显著增强了其在实际应用场景中的实用性。
实验效果
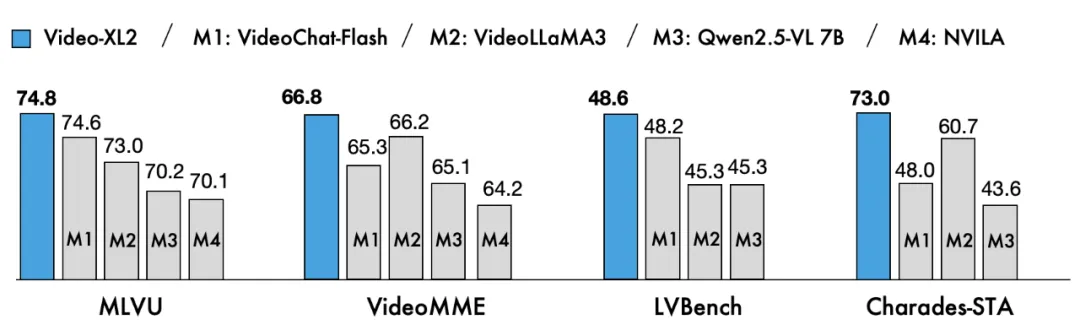
图 5:Video-XL-2 的主要对比结果
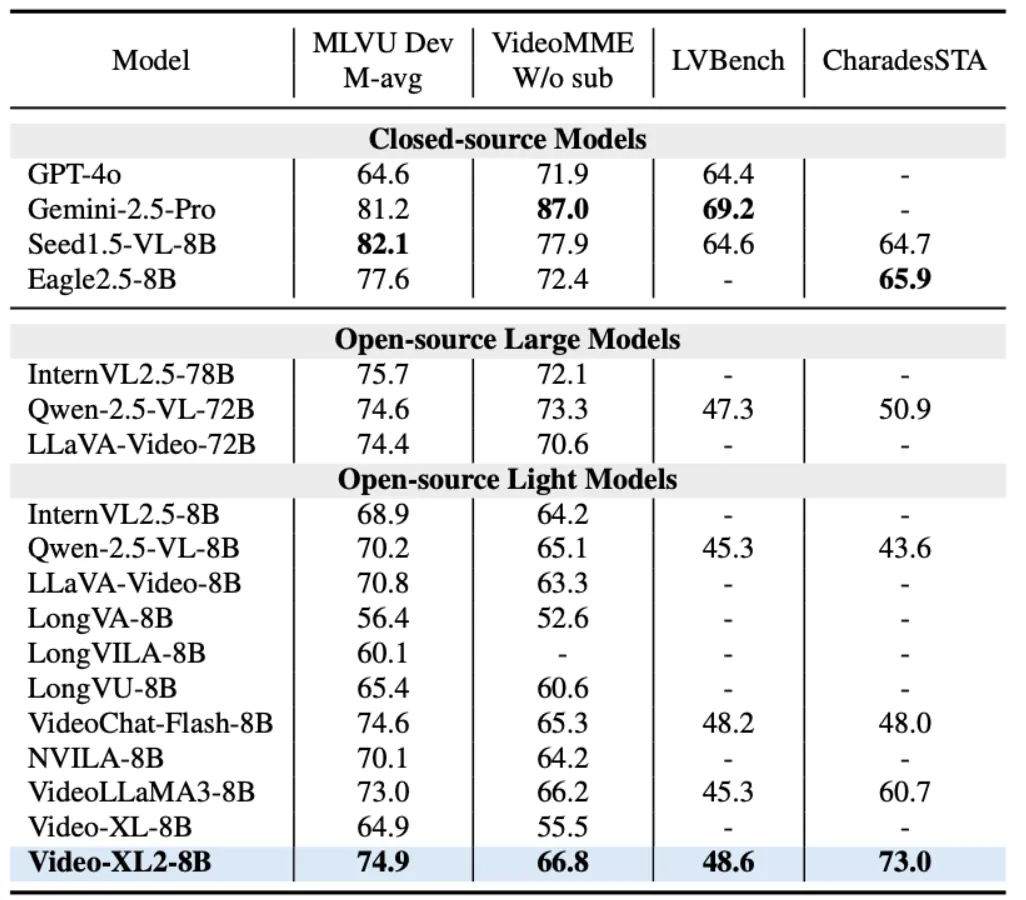
表 1:Video-XL-2 的全面对比结果
在模型具体表现方面,Video-XL-2 在 MLVU、VideoMME 和 LVBench 等主流长视频评测基准上全面超越现有所有轻量级开源模型,达成当前最先进性能(SOTA),相较第一代 Video-XL 实现了显著提升。尤其值得关注的是,在 MLVU 和 LVBench 上,Video-XL-2 的性能已接近甚至超越了如 Qwen2.5-VL-72B 和 LLaVA-Video-72B 等参数规模高达 720 亿的大模型。
此外,在时序定位(Temporal Grounding)任务中,Video-XL-2 也表现出色,在 Charades-STA 数据集上取得了领先的结果,进一步验证了其在多模态视频理解场景中的广泛适用性与实际价值。
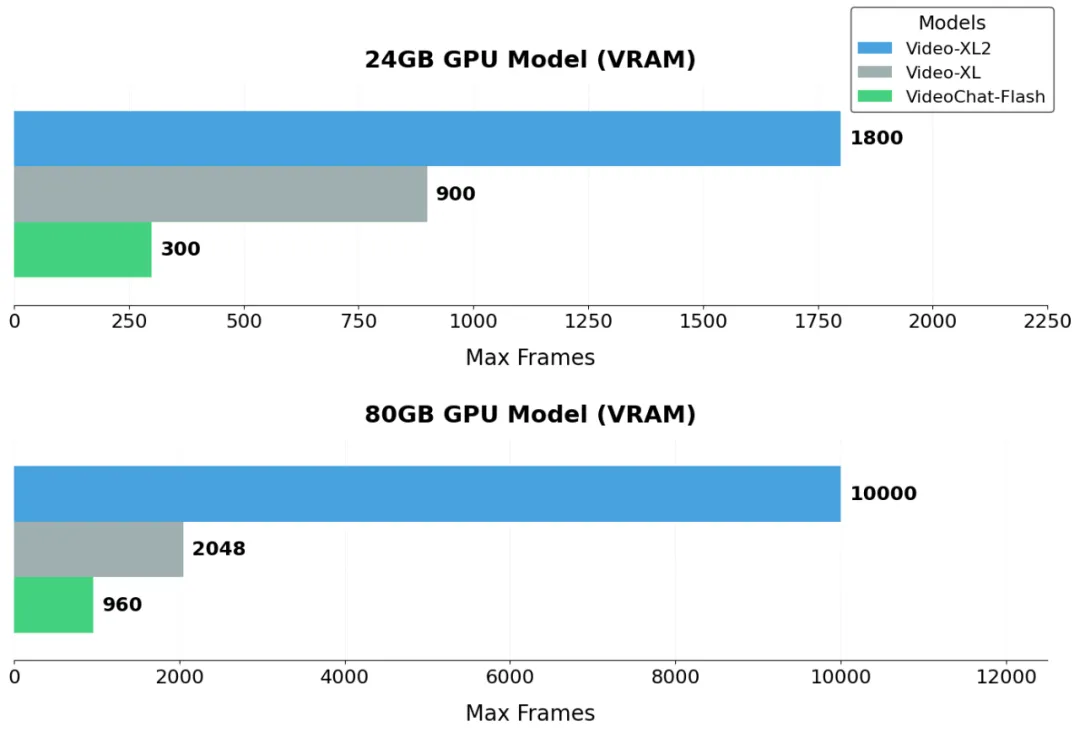
图 6:Video-XL-2 输入长度的对比展示
除了效果上的提升,Video-XL-2 在视频长度方面也展现出显著优势。如图 6 所示,在单张 24GB 消费级显卡(如 RTX 3090 / 4090)上,Video-XL-2 可处理长达千帧的视频;而在单张 80GB 高性能显卡(如 A100 / H100)上,模型更支持万帧级视频输入,远超现有主流开源模型。相较于 VideoChat-Flash 和初代 Video-XL,Video-XL-2 显著拓展了视频理解的长度并有效降低了资源需求,为处理复杂的视频任务提供了有力的支撑。

图 7:Video-XL-2 Prefilling 速度的对比展示
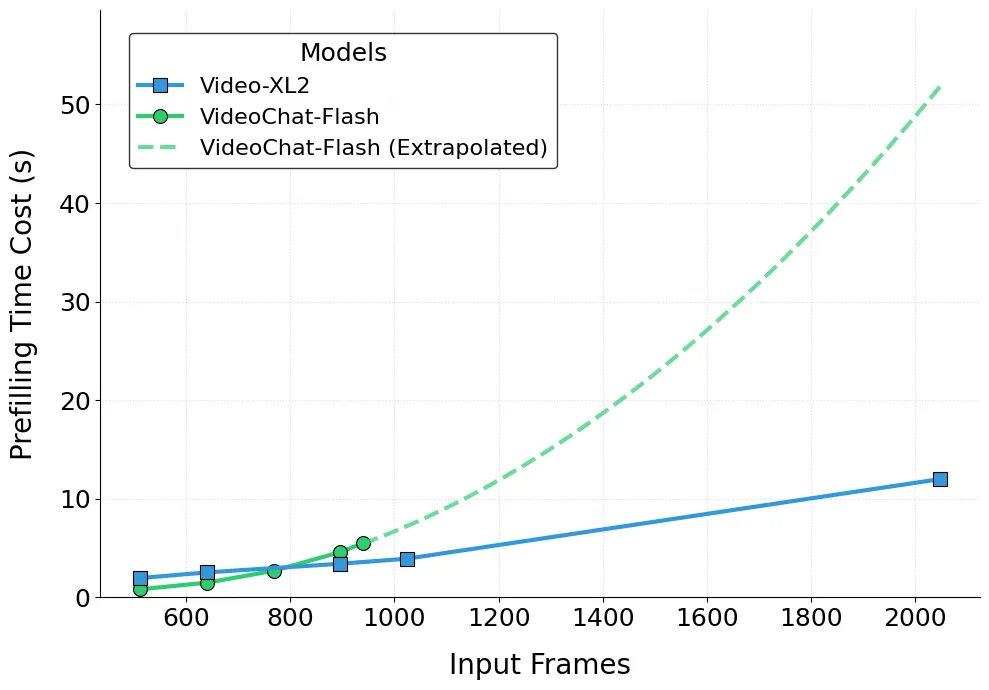
图 8:Video-XL-2 Prefilling 速度和输入帧数的关系图
最后,Video-XL-2 在速度上也展现出卓越性能。如上图所示,Video-XL-2 仅需 12 秒即可完成 2048 帧视频的预填充。更重要的是,其预填充时间与输入帧数之间呈现出近似线性增长,体现了其出色的可扩展性。相比之下,Video-XL 与 VideoChat-Flash 在输入长视频条件下的工作效率明显落后于 Video-XL-2。
应用潜力
以下是一些具体的例子,将展示 Video-XL-2 在实际应用中的巨大潜力:
Example 1 电影情节问答:

Question: A bald man wearing a green coat is speaking on the phone. What color is the phone?
Answer: The phone's color is red
Example 2 监控异常检测:

Question: Is there any unexpected event happening in this surveillance footage?
Answer: There is physical altercation between the customers and the store employees
Example 3: 影视作品内容总结
Example4:游戏直播内容总结
得益于出色的视频理解能力与对超长视频的高效处理性能,Video-XL-2 在多种实际应用场景中展现出很高的应用潜力。例如,它可广泛应用于影视内容分析、剧情理解、监控视频中的异常行为检测与安全预警等任务,为现实世界中的复杂视频理解需求提供高效、精准的技术支撑。
#Neural Incompatibility
传统符号语言传递知识太低效?探索LLM高效参数迁移可行性
论文第一作者谭宇乔来自中国科学院自动化研究所的自然语言处理和知识工程研究组,导师为何世柱老师。目前研究方向主要在利用大语言模型参数知识增强大模型能力。
1 跨规模参数知识迁移 PKT 的全面分析
人类的思维是非透明的,没有继承的记忆,因此需要通过语言交流的环境来学习。人类的知识传递长期依赖符号语言:从文字、数学公式到编程代码,我们通过符号系统将知识编码、解码。但这种方式存在天然瓶颈,比如信息冗余、效率低下等。
现如今,大语言模型(LLM)就主要模仿这一套范式来学习和传递知识。然而,与人脑不可知和不透明的特性不同,开源 LLM 的可访问参数和信息流则像一个透明的大脑,直接编码了事实知识,已有的研究对其进行了系统分析、精确定位和有效转移。因此研究人员提出疑问:大模型能否像《阿凡达》中的人类和纳威人之间建立传递知识的练习?其中在天然存在的较大 LLM 和较小 LLM 对之间展开,将参数知识作为媒介。
最近,中国科学院自动化所提出对 Parametric Knowledge Transfer (PKT,参数知识迁移) 的全面分析。一句话总结:跨规模大模型之间的表现相似和参数结构相似度都极低,这对实现有效的 PKT 提出了极大的挑战。
论文标题:Neural Incompatibility: The Unbridgeable Gap of Cross-Scale Parametric Knowledge Transfer in Large Language Models
论文地址:https://arxiv.org/abs/2505.14436
Github 地址:https://github.com/Trae1ounG/Neural_Incompatibility
2 新的 Pre-Align PKT 范式:定位后对齐 LaTen
论文首先通过简单的前置实验,挖掘出参数空间的对齐是实现参数知识迁移的必要条件。现有的参数对齐方法 Seeking 通过梯度定位部分较大 LLM 参数以适配较小 LLM 张量形状,将其初始化为 LoRA 矩阵通过后续微调实现迁移,称之为后对齐参数迁移方法(Post-Align PKT)。论文为了更全面探索 PKT 是否可行,根据对齐时机提出先对齐知识迁移(Pre-Align PKT)新范式,采用定位后对齐(Locate-then-Align,LaTen)方法实现参数对齐。
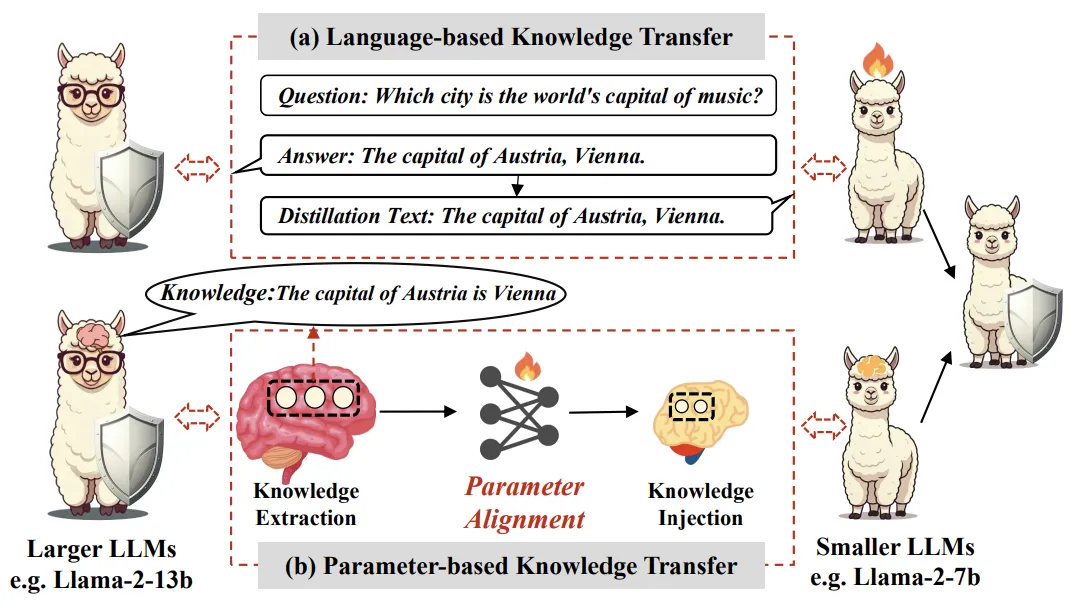
图表 1:展示了基于语言的知识迁移和基于参数的知识迁移范式的差异
该方法的核心理念是首先通过神经元级别的归因分析,识别出与特定任务相关的参数,然后利用训练得当的超网络,将较大 LLM 的知识映射到较小 LLM 上。
具体而言,LaTen 方法分为两个阶段:
- 知识提取:通过分析大模型的参数,识别出与目标任务相关的知识。这一过程利用静态神经元归因方法,计算出每个神经元在任务中的重要性,从而选择出最具信息量的参数进行迁移。
- 参数对齐:一旦确定了重要参数,接下来通过轻量级的超网络进行对齐,确保这些参数能够有效整合到小型模型中。
- 参数注入:这一过程强调在对齐后直接注入参数,减少了后续训练所需的资源和时间。
通过上述流程,就可以将较大模型中的参数知识转换为在较小模型中可受用的知识进而进行注入,以避免参数空间的差异性导致的性能丢失。
3 对齐实验分析
在实验部分,研究者针对多个基准数据集,涵盖世界知识(MMLU),数学推理(GSM8K)和代码能力(HumanEval 和 MBPP)进行了详细评估。
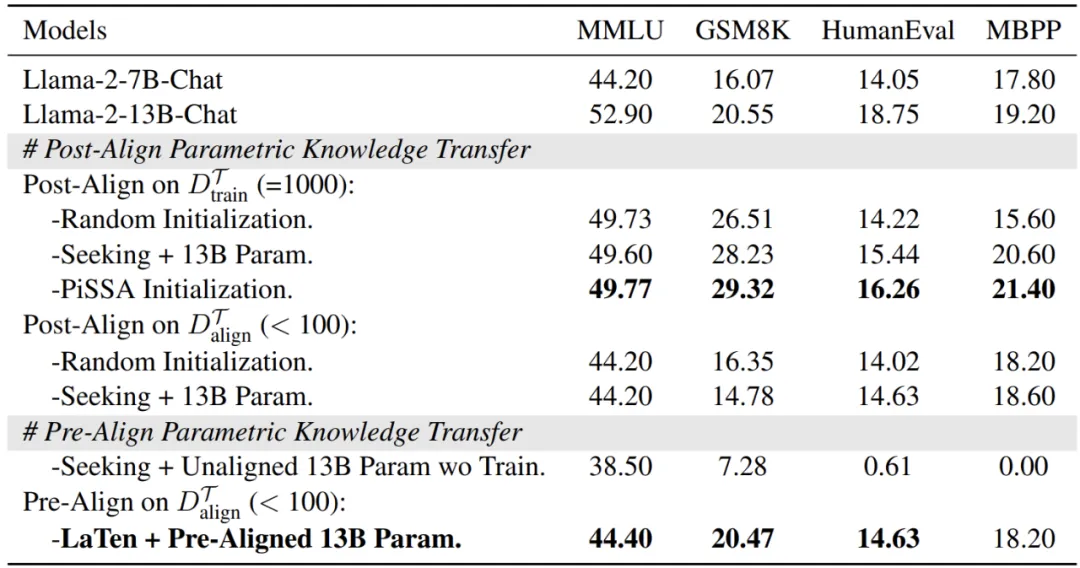
图表 2:展示 Post-Align PKT 和 Pre-Align PKT 在不同数据集上的性能表现
实验结论:
- 对于 Post-Align PKT,论文将其同利用 SVD 从模型自身获取 LoRA 的 PiSSA 方法对比,结果发现 PiSSA 在相同设置下优于 Seeking,证明从较大模型抽取的参数知识不如利用模型自身知识作为 LoRA 初始化,进一步怀疑其可行性。
- 对于 Pre-Align PKT,结果显示,只需要极少的训练步数和数据开销,LaTen 能有效取得性能提升。但是 Pre-Align PKT 通过训练实现参数对齐的方式受到极大限制,无法超越较大 LLM 的能力上界,同时训练不太稳定,没有明显收敛。
此外,论文从另一个方面来验证目前阶段的 PKT 是否有效。既然假设迁移的参数知识中包含了有用的特定任务的知识,那么在特定任务上表现更好的模型,理应在迁移后能让小模型的性能更好。因此,研究者在代码任务上开展了这一探索实验:
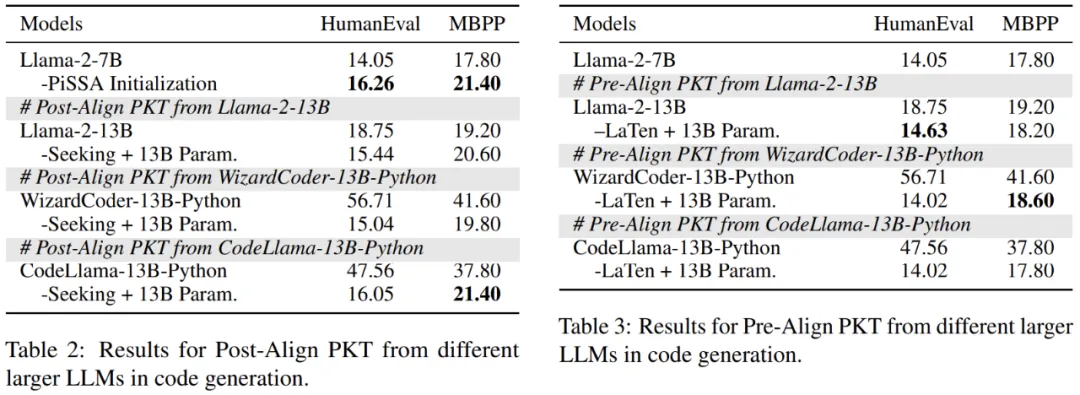
图表 3:基于更强的较大 LLM 向较小 LLM 传递知识,左图为 Post-Aligh PKT 实验结果,右图为 Pre-Align PKT 实验结果
实验结果证明了两种 PKT 在这种设置下的失败,让人疑惑为什么跨规模 PKT 无法有效实现?
4 为什么跨规模 PKT 失败?
PKT 的核心任务在于对齐(Align),不管是通过后续训练还是提前通过超网络实现,是否能有效实现对齐是 PKT 成功的关键。从现有实验结果来看,PKT 并没有有效实现对齐,那么阻碍的关键在哪?
论文从表现相似度(representation similarity)和参数相似度(parametric similarity)出发,分析跨规模大模型在行为方式和内部参数结构的相似度是否会导致跨规模 PKT 的失败,称为神经不兼容性(Neuron Incompatibility)。
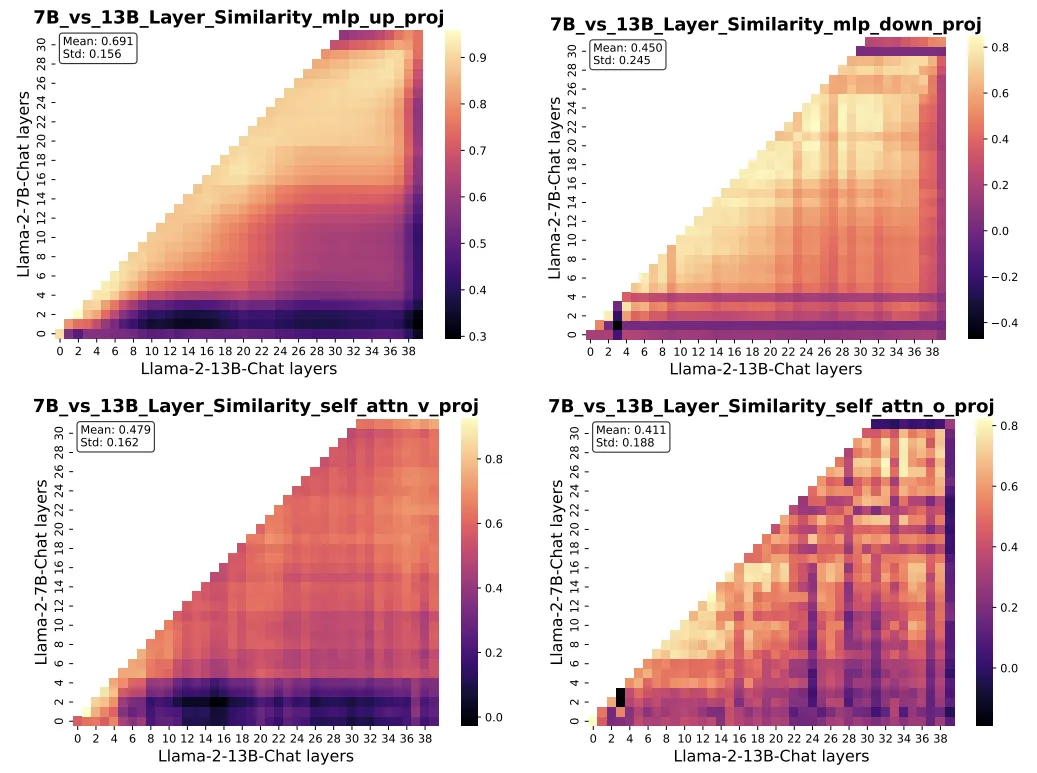
图表 4:跨规模大模型之间的表现相似度分析
对于表现相似度的分析,论文采用了中心核对齐(Centered Kernel Alignment, CKA)方法,该方法基于 Hilbert-Schmidt 独立性准则(HSIC),用于计算神经网络中特征表示的相似性。该指标评估了两个模型之间行为的相似性,可以视为大语言模型的行为相似性。
如图 4 所示,Llama2-7B 和 13B 之间的相似性较低,尤其是在多头自注意力(MHSA)模块中,该模块在信息整合中扮演着至关重要的角色。有趣的是,上投影层的相似性较高,这可能是因为它们作为关键记忆,捕捉特定的输入模式,而这些模式通常在不同模型间是一致的。跨规模大模型之间的低相似性也解释了为何从同一模型衍生的 LoRA 表现更好,因为它与模型的内在行为更为贴合。证明跨规模大语言模型之间的表示相似性较弱是导致神经不兼容性的关键因素之一,这使得理想的参数知识转移成功变得困难。
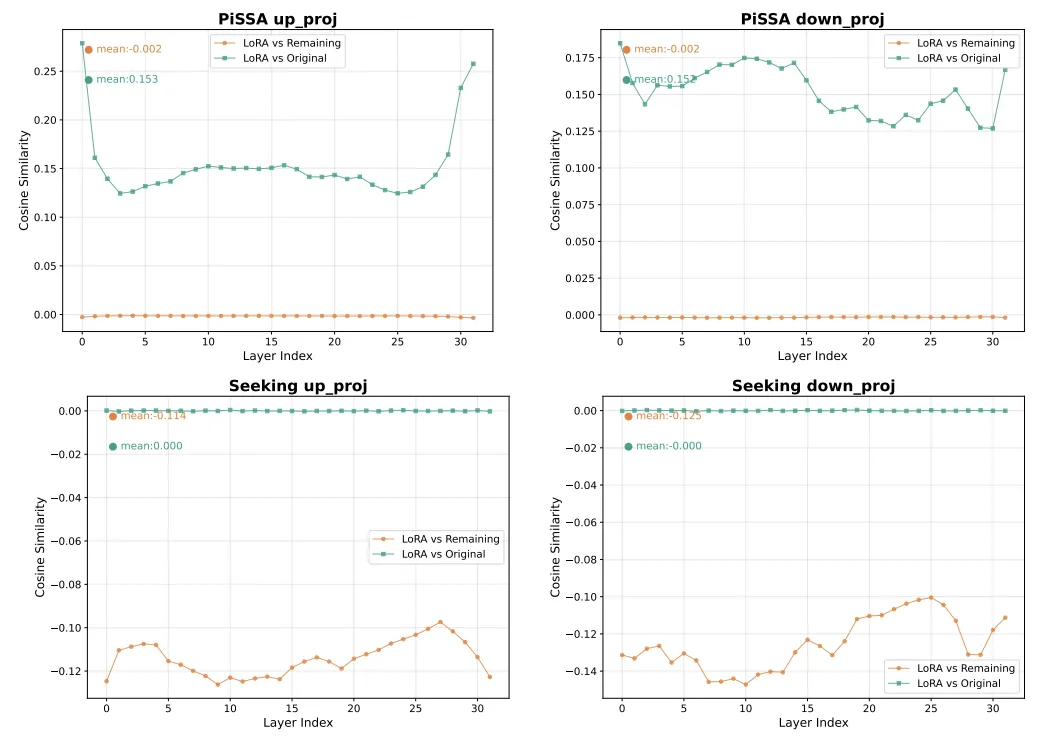
对于参数结构相似度的分析,论文进一步基于参数结构相似性进行深入分析,以了解其对性能的影响。如图 5 所示,比较了
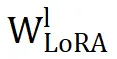
(即第 l 层的 LoRA 参数)与
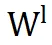
和
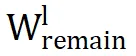
(即
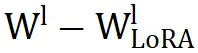
)在上投影和下投影模块中的表现。
首先,Seeking 和 PiSSA 的结果模式完全相反。在 Seeking 中,
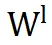
和
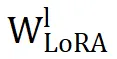
之间的平均相似度降至 0,表明
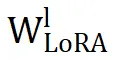
没有保留任何来自
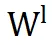
的有意义信息。这一缺陷导致了次优性能。
相比之下,PiSSA 利用奇异值分解(SVD)捕捉 LoRA 的重要参数,与原始权重保持更高的相似性,并与
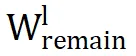
建立了正交关系,从而在学习新技能时更为有效。研究表明,参数结构相似性在进一步微调中扮演着关键角色。具体来说,
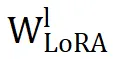
与
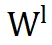
之间的相似度显著影响模型适应新任务和执行参数对齐的能力。低参数相似度成为导致神经不兼容性的重要因素。在多头自注意力模块中同样观察到了相同的模式。
5 总结与展望:理想的 PKT 尚待实现
人类从牙牙学语到学贯古今,通过语言和文字在历史长河中不断汲取知识,通过吸收和迭代实现知识的传承。
然而,我常幻想能实现,类似科幻小说中三体人直接通过脑电波传递所有知识,或利用一张链接床就能把人类的意识输入到纳威人体内,这是一种更理想的知识传递方式,而开放的大模型参数正有可能实现这一点。
通过将 PKT 根据 Align 进行划分,我们完成了对现有阶段 PKT 的全面研究,找出了实验结果欠佳的背后是不同规模大模型之间参数知识本质上的行为和结构的差异。
但仍期望,在未来大模型之间的交流不再局限于语言这种有损的压缩方式,而去尝试更高效直接的迁移方法。
语言,或许是人类知识的起点,但不一定是大模型的终点。
#VRAG-RL
视觉感知驱动的多模态推理,阿里通义提出VRAG,定义下一代检索增强生成
在数字化时代,视觉信息在知识传递和决策支持中的重要性日益凸显。然而,传统的检索增强型生成(RAG)方法在处理视觉丰富信息时面临着诸多挑战。一方面,传统的基于文本的方法无法处理视觉相关数据;另一方面,现有的视觉 RAG 方法受限于定义的固定流程,难以有效激活模型的推理能力。
来自阿里巴巴通义实验室的最新研究成果 ------VRAG-RL(Empower Vision-Perception-Based RAG for Visually Rich Information Understanding via Iterative Reasoning with Reinforcement Learning),将强化学习算法引入多模态智能体训练,借助迭代推理和视觉感知空间,全方位提升视觉语言模型(VLMs)在检索、推理和理解视觉信息方面的能力,为纯视觉检索增强生成任务提供有效解决方案,代码、模型全面开源!
Paper 地址:arxiv.org/pdf/2505.22019
Github 地址:https://github.com/Alibaba-NLP/VRAG
为了解决现有 RAG 方法在处理视觉丰富文档时面临的挑战,尤其是生成阶段推理能力不足的问题,我们推出了 VRAG-RL,该框架引入强化学习,专为视觉丰富信息复杂推理量身定制。VRAG-RL 通过定义视觉感知动作空间,使模型能够从粗到细地逐步聚焦信息密集区域,精准提取关键视觉信息,从而全方位提升视觉语言模型(VLMs)在检索、推理和理解视觉信息方面的能力。

与此同时,我们注意到现有的方法在将用户查询转化为搜索引擎可理解的检索请求时,常常因无法精准表达需求而难以检索到相关信息,往往存在语义偏差或信息缺失的问题。这不仅影响了检索结果的相关性,还限制了模型在后续生成阶段的推理能力。为了解决这一问题,VRAG-RL 引入了一种创新的检索机制,通过结合视觉感知动作和强化学习,使模型能够更有效地与搜索引擎进行交互。这种机制不仅能够帮助模型更精准地表达检索需求,还能够在检索过程中动态调整检索策略,从而显著提升检索效率和结果的相关性。
重定义感知行动空间
视觉仿生思考新范式
传统 RAG 方法在处理视觉信息时,往往采用固定的检索 - 生成流程,即先通过搜索引擎检索相关信息,然后直接生成答案。这种固定流程忽略了视觉信息的独特性,无法充分利用视觉数据中的丰富细节,导致推理能力受限。
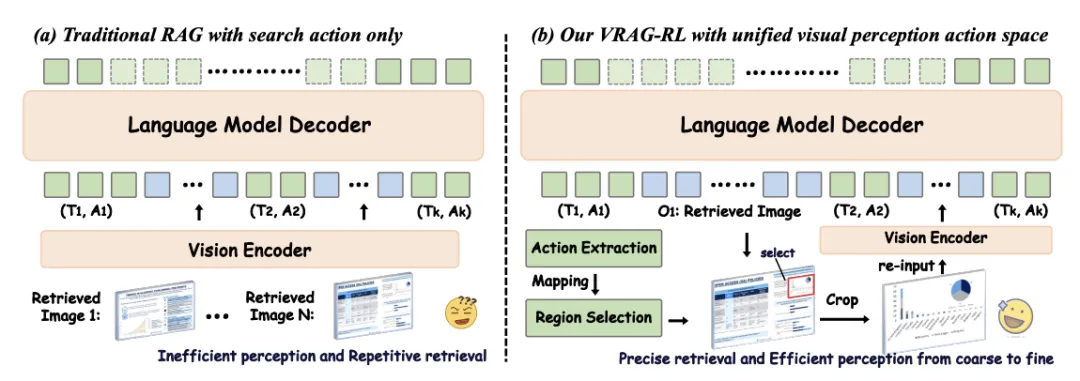
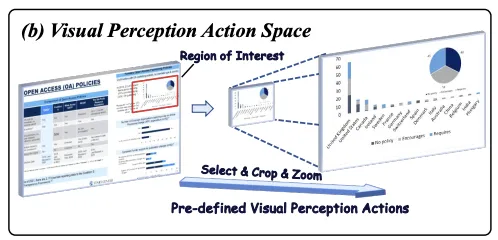
相比之下,VRAG-RL 彻底革新了传统的检索生成范式,引入了多样化的视觉感知动作,其中包含了多种视觉感知动作,如区域选择、裁剪、缩放等。这些动作使 VLMs 能够从粗粒度到细粒度逐步聚焦信息密集区域,精准提取关键视觉信息。例如,在处理复杂的图表或布局时,模型可以先从整体图像中提取大致信息,然后逐步聚焦到信息密集的区域,通过裁剪和缩放操作,获取更清晰、更详细的视觉信息。这种从粗粒度到细粒度的感知方式,不仅提高了模型对视觉信息的理解能力,还显著提升了检索效率,使模型能够更快速地定位到与问题相关的图像内容。
VRAG-RL 采用了多专家采样策略构建训练数据,大规模模型负责确定整体的推理路径,而专家模型则在大规模模型的指导下,对图像中的关键区域进行精确标注,结合大规模模型的推理能力和专家模型的精确标注能力,模型能够在训练过程中学习到更有效的视觉感知策略,显著提升了模型在实际应用中的表现。
检索与推理协同优化
效率与深度双重提升
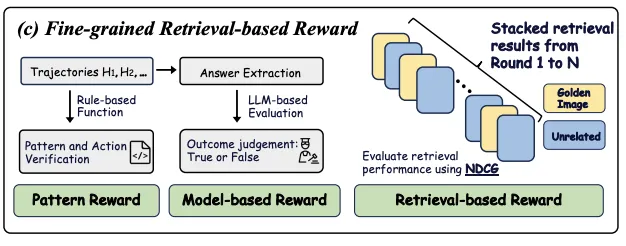
VRAG-RL 的细粒度奖励机制将检索效率、模式一致性与生成质量三方面因素融合,引导模型在与搜索引擎的交互中不断优化其检索与推理路径。
- 检索效率奖励 :借鉴信息检索领域广泛使用的 NDCG(Normalized Discounted Cumulative Gain)指标,激励模型优先检索相关度高的图像内容,快速构建高质量上下文;
- 模式一致性奖励 :确保模型遵循预设的推理逻辑路径,避免因模式偏差导致生成结果偏离任务目标;
- 生成质量奖励 :通过评估模型对生成答案的质量打分,引导模型输出更准确、连贯的答案。
这种多维度奖励机制实现了检索与推理的双向驱动------高效的检索为深入推理提供支撑,而推理反馈又进一步指导模型优化检索策略,形成闭环优化。
强化学习赋能多模态智能体训练
VRAG-RL 基于强化学习的训练策略,引入业界领先的 GRPO 算法,让视觉语言模型(VLMs)在与搜索引擎的多轮交互中,持续优化检索与推理能力。同时,通过本地部署搜索引擎模拟真实世界应用场景,实现搜索引擎调用零成本,模型训练更加高效。这种训练方式,不仅提升了模型的泛化能力,使其在不同领域、不同类型的视觉任务中都能表现出色,为多模态智能体的训练提供全新的解决方案。

实验分析
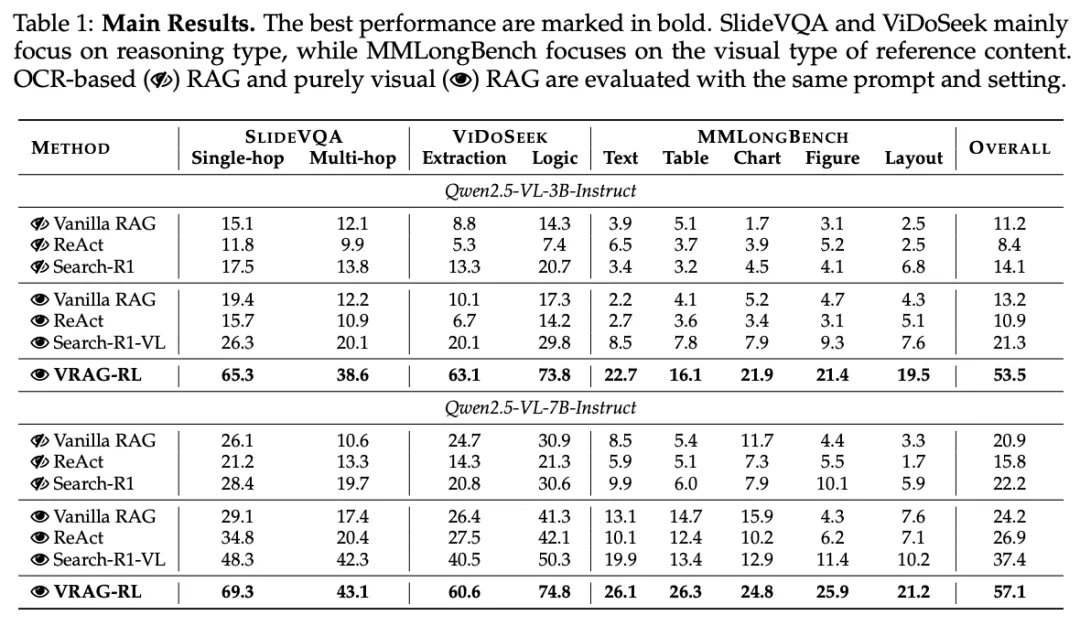
VRAG-RL 在各个基准数据集上均取得了显著优于现有方法的性能,涵盖了从单跳到多跳推理、从文本到图表和布局等多种复杂的视觉和语言任务类型。实验结果表明,VRAG-RL 在处理视觉丰富信息时具有显著的优势,能够更有效地进行检索、推理和生成高质量的答案。无论是在传统的 prompt-based 方法(如 Vanilla RAG 和 ReAct RAG)还是在基于强化学习的方法(如 Search-R1)上,VRAG-RL 都展现出了显著的性能提升。
在传统的 RAG 方法中,模型通常在进行一次或多次检索后直接生成答案。然而,在处理复杂的视觉任务时,这种方法往往表现不佳,因为它缺乏对视觉信息的深入理解和多轮推理能力。
相比之下,我们的 VRAG-RL 方法支持多轮交互。具体来说,通过定义视觉感知动作空间,VRAG-RL 能够在推理阶段逐步聚焦于信息密集区域,从而实现从粗到细的信息获取。同时,该方法通过优化检索效率和推理路径,在保持高效率的同时,显著提升了模型在视觉任务上的性能。

未来展望
开启视觉感知驱动多模态推理的新时代
VRAG-RL 为视觉丰富信息的检索增强生成任务开辟了新的道路。未来,研究团队计划进一步拓展模型的能力,引入更多模仿人类处理复杂信息的动作,使模型能够更深入地进行思考。同时,团队还将致力于减少模型的幻觉现象,通过引入更先进的模型架构和训练方法,进一步提高框架的准确性和可靠性,推动视觉语言模型在更多实际应用场景中的落地与发展。
#The Resurrection of the ReLU
经典ReLU回归!重大缺陷「死亡ReLU问题」已被解决
不用换模型、不用堆参数,靠 SUGAR 模型性能大增!
在深度学习领域中,对激活函数的探讨已成为一个独立的研究方向。例如 GELU、SELU 和 SiLU 等函数凭借其平滑梯度与卓越的收敛特性,已成为热门选择。
尽管这一趋势盛行,经典 ReLU 函数仍因其简洁性、固有稀疏性及其他优势拓扑特性而广受青睐。
然而 ReLU 单元易陷入所谓的「死亡 ReLU 问题」, 一旦某个神经元在训练中输出恒为 0,其梯度也为 0,无法再恢复。 这一现象最终制约了其整体效能,也是 ReLU 网络的重大缺陷。
正是死亡 ReLU 问题催生了大量改进的线性单元函数,包括但不限于:LeakyReLU、PReLU、GELU、SELU、SiLU/Swish 以及 ELU。这些函数通过为负预激活值引入非零激活,提供了不同的权衡。
本文,来自德国吕贝克大学等机构的研究者引入了一种新颖的方法:SUGAR(Surrogate Gradient for ReLU),在不牺牲 ReLU 优势的情况下解决了 ReLU 的局限性。即前向传播仍使用标准 ReLU(保持其稀疏性和简单性),反向传播时替换 ReLU 的导数为一个非零、连续的替代梯度函数(surrogate gradient)。
这样可以让 ReLU 在保持原始前向行为的同时,避免梯度为零的问题,从而复活死神经元。
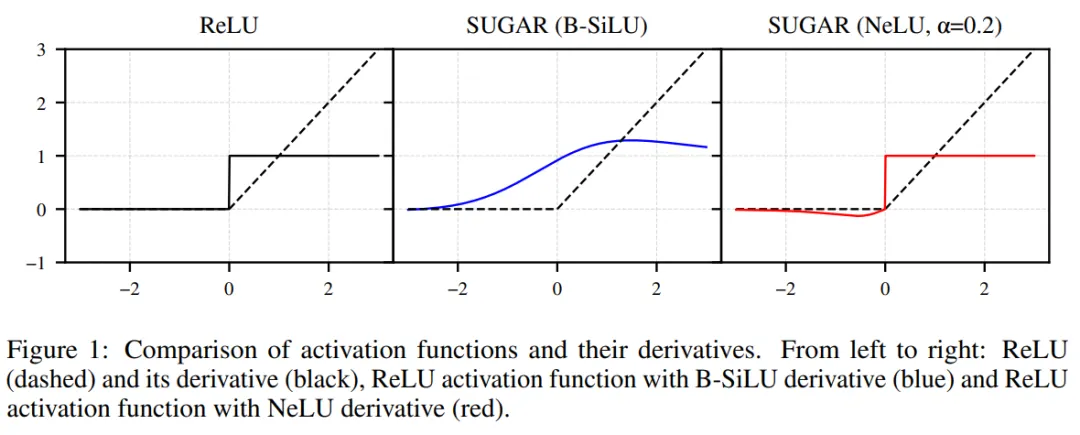
基于此,本文还设计了两种新型替代梯度函数:B-SiLU(Bounded SiLU)、 NeLU(Negative slope Linear Unit),可以无缝集成到各种模型中。
本研究的进一步贡献如下:
本文对 VGG-16 和 ResNet-18 进行了全面的实验,表明 SUGAR 显著增强了这两种架构的泛化能力。
本文在 Swin Transformer 和 Conv2NeXt 等现代架构上对 SUGAR 进行了评估,展示了其适应性和有效性。
对 VGG-16 层激活的深入分析表明,当应用 SUGAR 时,激活分布发生了明显的变化,为其在缓解消亡 ReLU 问题中的作用提供了直观证据,同时促进了更稀疏的表示。
SUGAR 方法易于实现,并在前向传播中始终采用 ReLU 激活函数。与所提出的 B-SiLU 替代函数结合使用时,VGG-16 在 CIFAR-10 和 CIFAR-100 数据集上的测试准确率分别提升了 10 个百分点和 16 个百分点,而 ResNet-18 与未使用 SUGAR 的最佳模型相比,分别提升了 9 个百分点和 7 个百分点。
- 论文标题: The Resurrection of the ReLU
- 论文链接:https://arxiv.org/pdf/2505.22074
SUGAR 介绍
本文提出的方法将 FGI ( Forward gradient injection )应用于具有平滑替代函数的 ReLU 网络中。在 SUGAR 框架下, FGI 可以表示为:
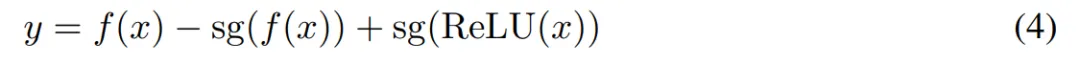
该公式实现了梯度注入,并确保即使对于负激活也能进行梯度传播。具体来说,利用 34 中的乘法技巧,替代梯度函数的直接注入如下:
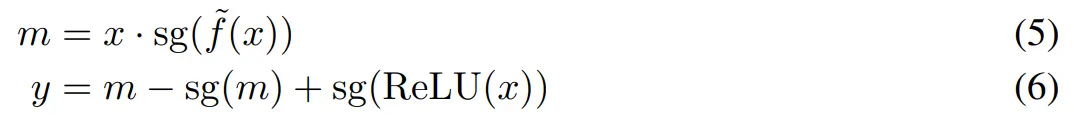
替代函数的选择具有灵活性,可兼容当前最先进的各类激活函数,例如 ELU、GELU、SiLU、SELU 以及 Leaky ReLU(见图 8)。
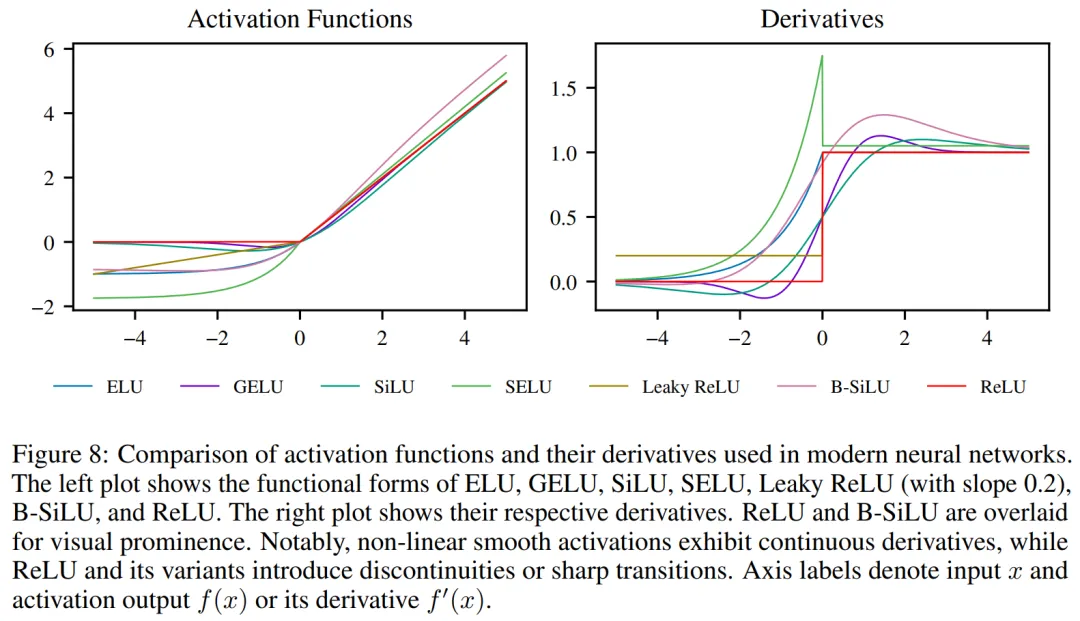
关键区别在于,与 ReLU 不同,这些候选替代函数均具有一个共同特征:对负输入(x < 0)能产生非零梯度。虽然这些函数为负激活提供了梯度流通路径,但前向传播及后续损失计算仍严格依赖 x > 0 时的激活输出。
在初步研究中,本文意识到需要调整当前的激活函数以适应 SUGAR 的特定用途。因此,接下来本文提出了两个与这些设置良好匹配的新替代函数。
B-SiLU:引入了一种名为 B-SiLU(Bounded Sigmoid Linear Unit) 的新型激活函数,它结合了自门控特性和可调下限参数。从数学上讲,该函数可以表示为:
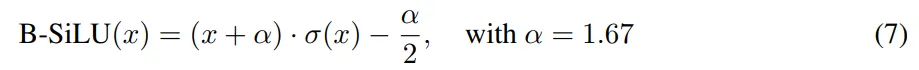
B-SiLU 激活函数的导数为:
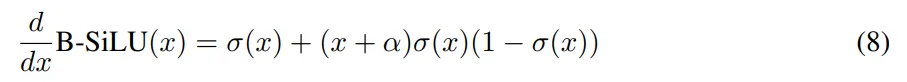
图 8 中可视化了 B-SiLU 及其导数。
NeLU:本文进一步引入了 NeLU(Negative slope Linear Unit),作为 ReLU 的平滑导数替代品。
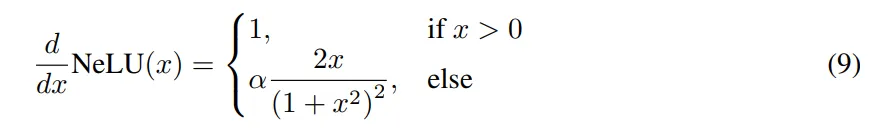
最终的梯度如图 1 所示。
实验
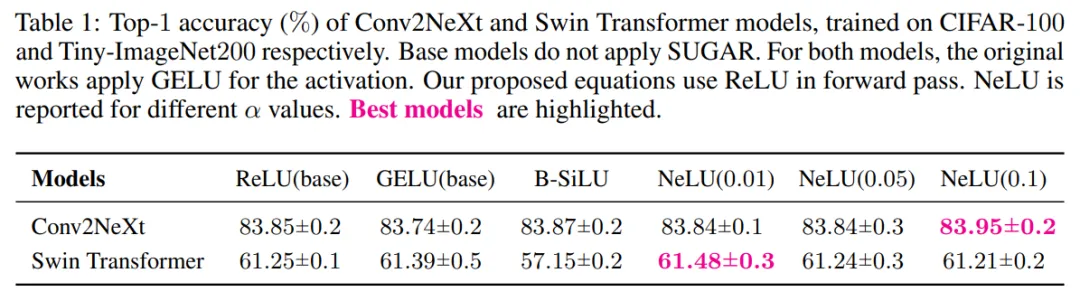
总体而言,与 ReLU 基线相比,SUGAR 结合 ELU、SELU 以及特别是 B-SiLU 获得了最大的提升,而 LeakyReLU 和 NeLU 则始终表现不佳(见图 2)。在 CIFAR-10 数据集上使用 ResNet-18 作为骨干网络时,B-SiLU 的性能从 76.76% 提升到 86.42%,得益于 SUGAR。VGG-16 也表现出类似的效果:B-SiLU 将测试精度提高了近 10 个百分点(从 78.50% 提升到 88.35%)。
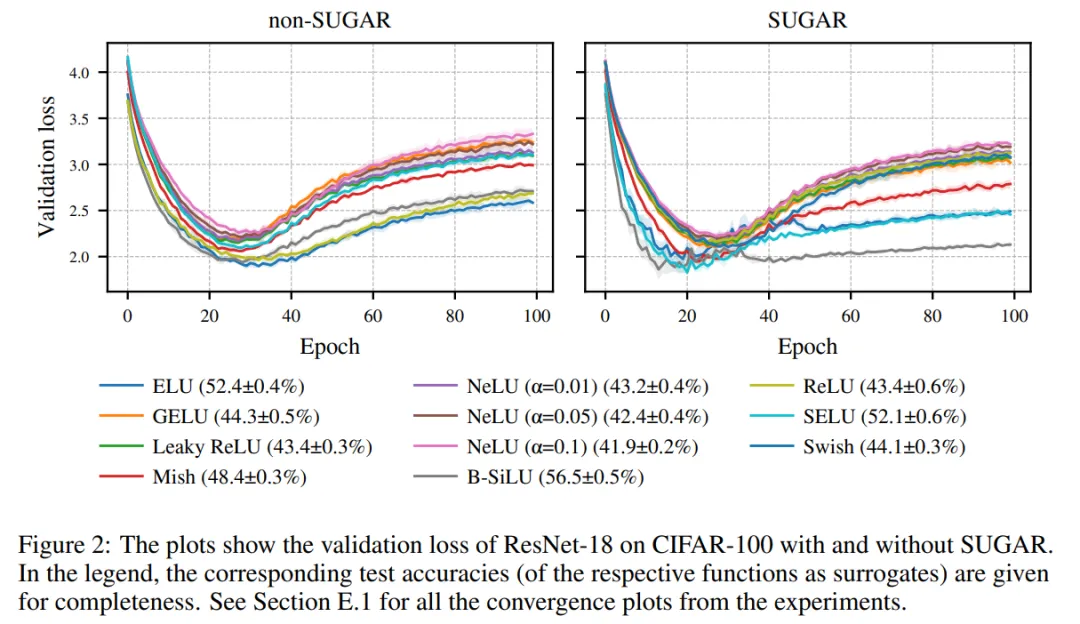
在 CIFAR-100 数据集上,SUGAR 结合 B-SiLU 的优势更加明显:ResNet-18 的准确率从 48.99% 跃升至 56.51%,VGG-16 的准确率从 48.73% 提升至 64.47%(见图 3)。同样,Leaky ReLU 和 NeLU 仅显示出微小的甚至是负的提升(例如 ResNet-18 上的 43.67% → 43.41%)。
总的来说,B-SiLU 在不同架构和数据集上均优于其他替代激活函数,ELU 和 SELU 能够提供可靠的改进,而在这种设置下,SUGAR 从 Leaky ReLU 和 NeLU 中并未获得有意义的益处。

当应用于 Conv2NeXt 时,如表 1 所示,SUGAR 在前向和反向传播过程中均始终优于使用 GELU 的基础模型。
了解更多内容,请参考原论文。
#CoT-Bridge
思维链也会「跳帧」?浙大团队提出,显著提升数学推理性能
本文的共同第一作者是徐皓雷和颜聿辰。徐皓雷是浙江大学的一年级硕士生,主要研究兴趣集中在大模型推理和可解释性研究;颜聿辰是浙江大学博士三年级研究生,主要研究兴趣集中在大模型推理和智能体。本文通讯作者是浙江大学鲁伟明教授和沈永亮研究员。
在大语言模型(LLM)飞速发展的今天,Chain-of-Thought(CoT)技术逐渐成为提升复杂推理能力的关键范式,尤其是在数学、逻辑等结构化任务中表现亮眼。
但你是否注意到:即使是精心构建的 CoT 数据,也可能存在 "跳跃式" 推理,缺失关键中间步骤。对人类专家来说这些步骤或许 "理所当然",但对模型而言,却可能是无法逾越的鸿沟。
为了解决这一问题,浙江大学联合微软亚洲研究院、香港中文大学提出了 Thought Leap Bridge 任务,并开发了思维链修复方法:CoT-Bridge。实验显示,该方法显著提升了多个数学与逻辑任务中的推理准确率,并能作为 "即插即用" 的模块嵌入到知识蒸馏、强化学习等流程中。
论文链接:https://arxiv.org/abs/2505.14684
项目主页:https://zju-real.github.io/CoT-Bridge/
代码仓库:https://github.com/ZJU-REAL/Mind-the-Gap
CoT 不等于 Coherent-of-Thought
思维跳跃是如何破坏推理链的?
CoT 的设计初衷是让大模型像人一样 "按步骤思考",然而研究团队发现,许多公开 CoT 数据中存在一种被严重低估的问题:Thought Leap。
Thought Leap 指的是 CoT 推理链中,前后步骤之间存在中间推理内容的省略,导致逻辑跳跃,破坏推理的连贯性。
这种现象往往源于专家在书写推理过程时的 "经验性省略"------ 由于熟练掌握相关问题,他们倾向于跳过自认为显而易见的步骤。然而,模型并不具备这种人类专家式的 "思维粒度":它需要更细致、逐步的推理过程来建立完整的逻辑链条。
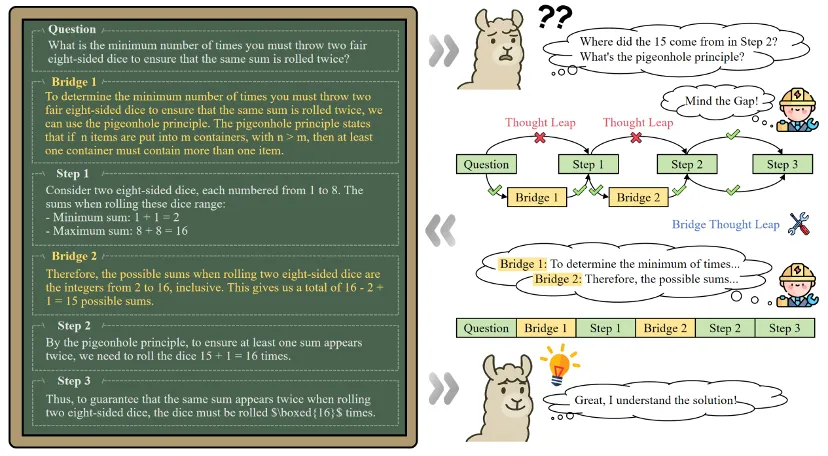
论文中给出了一个典型例子:
对于问题 "两颗八面骰子最少要投多少次,才能确保出现重复的和?"
原始 CoT 中跳过了两个关键推理环节:15 种是怎么来的?为什么要使用鸽巢原理?
这种 "缺口" 虽然对人类来说轻松跨越,对模型而言却是理解失败的高风险点。
团队通过实验证明,这种结构性不完整对模型训练带来显著负面影响:
- 训练效果降低:严重的思维跳跃可造成 27.83% 的性能损失
- 学习效率变低:模型在训练过程中的收敛速度显著变慢
CoT-Bridge:为模型补上思维跳跃的 "桥梁"
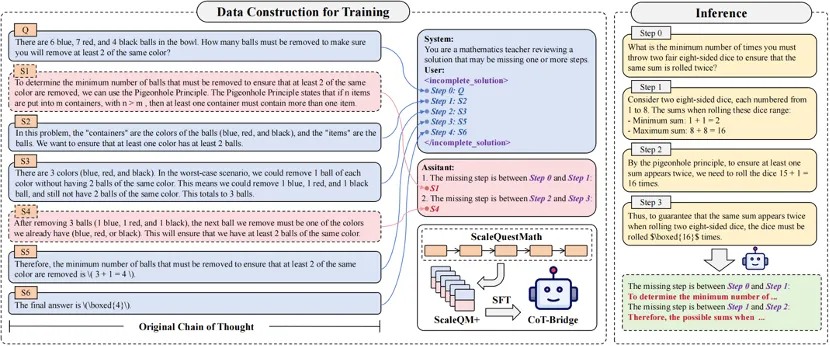
为解决数学推理任务中推理链不连贯的问题,研究团队提出了 Thought Leap Bridge Task,目标是自动检测推理链中的结构性缺失,并补全相应的中间推理步骤,以恢复其逻辑完整性。
该任务包含两个关键子问题:
-
Leap 检测:识别推理链中相邻步骤之间是否存在逻辑跳跃,即是否缺失必要的过渡性推理。
-
步骤补全:对于检测到的跳跃位置,生成满足推理连贯性的中间步骤。
团队将 ScaleQuestMath 作为 "理想" CoT 数据集,并基于其构建了专用训练数据集 ScaleQM+。研究团队通过有控制地删除原始推理链中的若干中间步骤,构造出含有 Thought Leap 的 "不完整推理链",并与被删除的步骤配对,作为训练样本。这一设计使得模型能够学习到如何识别不连贯结构,并生成适当的推理补全内容。
随后,团队基于 Qwen2.5-Math-7B 对模型进行指令微调,训练出 CoT-Bridge 模型。该模型能够作为独立组件,接收可能存在缺口的推理链输入,自动输出所需的中间步骤补全,从而生成结构完整的推理过程。
实验结果
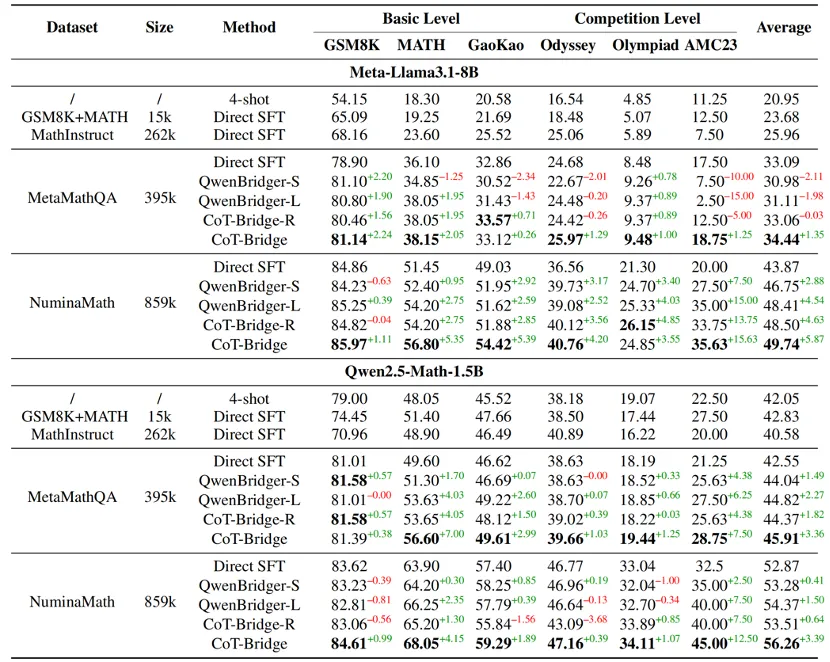
补全后的数据集显著提升 SFT 效果
研究团队在两个数学推理数据集 MetaMathQA 和 NuminaMath 上,分别使用补全前后的数据进行监督微调(SFT)对比实验。结果显示,使用 CoT-Bridge 补全 Thought Leap 后的数据在多个数学基准任务上均带来了显著的性能提升,其带来的最大增益达到 + 5.87%。这表明:思维链的连贯性,正是限制模型进一步提升的瓶颈之一,修复这些 "跳跃",能够让模型真正学会 "怎么思考"。
即插即用,增强蒸馏与强化学习流程中的训练效果
在主实验基础上,研究进一步评估了 CoT-Bridge 在更广泛训练流程中的适配性,包括知识蒸馏与强化学习两个典型场景。
蒸馏数据增强:使用大模型生成数学题解是当前训练数据的来源之一。团队将 CoT-Bridge 应用于使用 Qwen2.5-Instruct-72B 蒸馏得到的数据。实验结果表明,补全后的蒸馏数据带来 + 3.02% 的准确率提升。该结果说明,即便原始生成内容已具备较高质量,推理过程的结构优化仍能带来额外增益。
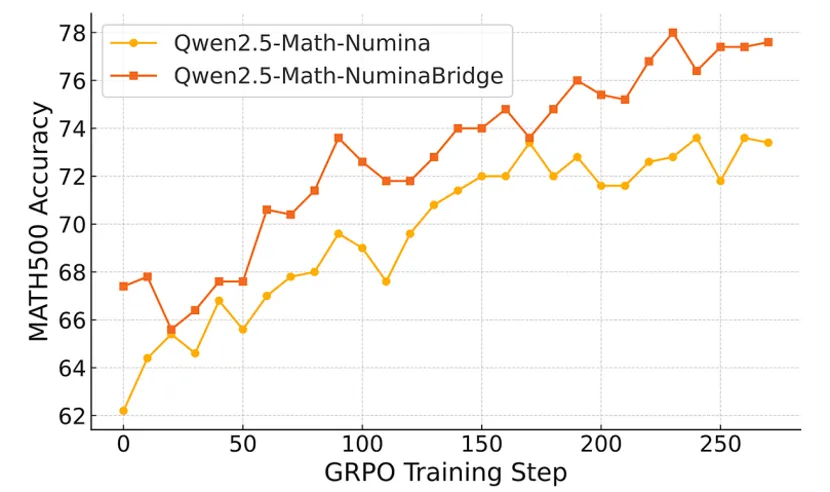
强化学习冷启动优化:在强化学习范式中,初始监督微调模型对最终性能具有重要影响。研究团队将使用 CoT-Bridge 生成的数据用于 SFT,并在此基础上继续训练。对比实验显示,该方案可作为更优的 "冷启动模型",在训练初期即具备更高起点,并最终获得更好的收敛性能。在 NuminaMath 数据集上,基于补全后数据训练的模型在 RL 阶段最终准确率较原始方案提升约 +3.1%。
泛化能力提升,改善 OOD 推理表现
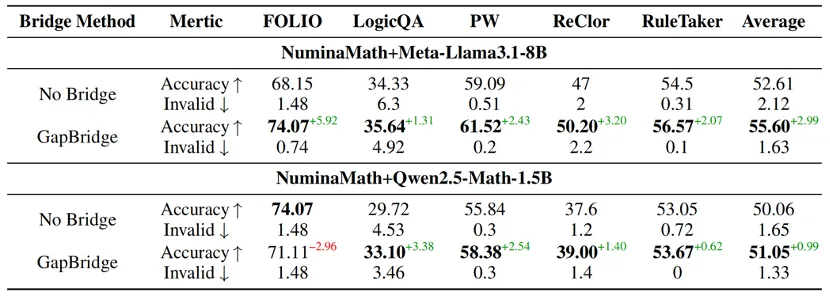
为了验证 CoT-Bridge 是否具备跨任务迁移能力,研究将逻辑推理类任务作为模型在 OOD 场景下的评估基准,包括 FOLIO、LogicQA、ProofWriter、ReClor 和 RuleTaker 等。
实验结果表明,使用补全数据训练的模型在大多数逻辑任务中准确率有不同程度提升,Meta-Llama3.1-8B 平均提升为 +2.99%,Qwen2.5-Math-1.5B 提升约 +0.99%。此外,模型生成无效输出的比例有所下降,说明其在结构控制和推理一致性方面表现更为稳健。这意味着,补全思维链条不仅提升了数学能力,也让模型更擅长 "解释自己是怎么推理出来的",从而在广义逻辑任务中具备更强鲁棒性。