温馨提示:
本篇文章已同步至"AI专题精讲 " 量化大型语言模型的评估
摘要
后训练量化(PTQ)作为一种有前景的技术,能够有效降低大型语言模型(LLMs)的计算成本。具体来说,PTQ可以显著减少LLMs的内存消耗和计算开销。为了在多样化场景下兼顾高效性和性能,全面评估量化后的LLMs显得尤为重要,以指导量化方法的选择。本文通过对11个模型家族(包括OPT、LLaMA2、Falcon、Bloomz、Mistral、ChatGLM、Vicuna、LongChat、StableLM、Gemma和Mamba,参数规模从1.25亿到1800亿)中权重、激活和KV缓存量化效果的系统评估,涵盖基础自然语言处理、突现能力、可信度、对话和长上下文任务五类任务。此外,本文还评测了当前最先进的量化方法以验证其适用性。基于大量实验,我们系统总结了量化的影响,给出了量化技术的应用建议,并指出了未来研究方向。代码开源于:https://github.com/thu-nics/qllm-eval。
1. 引言
如今,大型语言模型(LLMs)在自然语言理解与生成等多种任务中展现了卓越性能。尤其是,LLMs的出现催生了许多有趣且有价值的应用,如ChatGPT(OpenAI,2023)和Copilot(GitHub,2023)。然而,由于LLMs庞大的内存需求和计算开销,高效部署仍是一大挑战。
LLM推理过程包含预填充阶段和解码阶段。预填充阶段主要受计算限制,而解码阶段由于批量较小,通常受内存限制。此外,在处理长文本或大批量任务时,Key-Value缓存(KV Cache)的内存开销甚至超过了权重部分。
后训练量化(PTQ)(Wan等,2023;Zhou等,2024)是一种有效的解决方案。PTQ通过使用低精度的数值替代高精度数值,帮助降低权重、激活和KV缓存的内存消耗。具体来说:(1) 权重量化在解码阶段加速内存受限的通用矩阵向量乘法(GEMV)操作(Lin等,2023;Park等,2023;Frantar等,2023;Kim等,2023;Lee等,2023);(2) 权重-激活量化使GPU中的低精度Tensor核得以利用,从而缓解预填充阶段计算受限的通用矩阵乘法(GEMM)操作(Xiao等,2023;Wei等,2022;Dettmers等,2022;Yao等,2022;Yuan等,2023);(3) KV缓存量化有助于缓解处理长文本或大批量时的内存压力(Sheng等,2023)。
如上所述,为适应不同模型规模、批量大小、文本长度和硬件环境下的效率需求,量化设计方案必须多样化。由于量化是一种有损压缩技术,不同设计选择对任务性能的影响各异。尤其当前LLMs作为广泛任务的通用求解器,深入理解量化选择对任务性能的影响成为量化技术应用中的关键问题。
为此,近期Yao等(2023)研究了量化对权重和激活在语言建模任务中的影响,但未考虑KV缓存量化。Liu等(2023b)仅关注量化LLMs的三种突现能力,未涵盖可信度、对话和长上下文等重要任务。这些工作虽有价值,但尚未全面阐明不同量化方法能否广泛适用于多种模型并在多样任务中保持性能。
本文对量化后的大型语言模型(LLMs)进行了全面评估,揭示了当前量化研究的现状,涵盖以下四个维度:
(1)量化对各类自然语言处理任务的影响:现有量化方法主要评估量化模型在零样本理解任务和语言建模任务上的表现,但量化后的LLMs在对话、长上下文处理及可信度等关键任务上的性能表现仍未明确。
(2)量化对不同LLM模型的影响:不同模型家族和不同规模的LLMs在量化后是否存在一致的性能下降趋势?
(3)对不同张量类型进行量化的影响:权重(Weight)、激活(Activation)和键值缓存(KV Cache)三类张量的量化对模型性能有何不同影响?目前大多数方法聚焦于权重和激活的量化,而KV缓存量化的性能评估较为缺乏。
(4)不同量化方法的效果:诸如AWQ(Lin等,2023)和SmoothQuant(Xiao等,2023)等当前主流的先进量化方法,能否有效弥补量化带来的性能损失?
具体而言,本文评估了包括OPT、LLaMA2、Falcon、Bloomz、Mistral、ChatGLM、Vicuna、LongChat、StableLM、Gemma和Mamba等11个模型家族,模型规模涵盖从1.25亿到1800亿参数。为了扩大评估基准的覆盖面,我们关注LLMs的五类能力:基础自然语言处理能力、突现能力、可信度、对话能力以及长上下文处理能力。针对不同张量类型的量化影响,我们分别评估了仅权重量化、权重-激活联合量化及KV缓存量化。
我们在表1中总结了关键发现。值得注意的是,我们总结了许多跨不同LLMs普遍存在的定性趋势和失败案例,这些结论具有一定的普适性,但推荐的量化位宽可能无法直接推广到其他模型或任务。
2. 预备知识
2.1. 量化
本文聚焦于最常用的均匀量化格式(Krishnamoorthi, 2018;Nagel 等, 2021),其量化过程可以表示为:
X I N T = X F P 16 − Z S ( 1 ) { \bf X } _ { \mathrm { I N T } } = \left \\frac { { \\bf X } _ { \\mathrm { F P 1 6 } } - Z } { S } \\right\quad(1) XINT=SXFP16−Z(1)
S = max ( X F P 16 ) − min ( X F P 16 ) 2 N − 1 − 1 ( 2 ) S = \frac { \operatorname* { m a x } ( \mathbf { X } _ { \mathrm { F P 1 6 } } ) - \operatorname* { m i n } ( \mathbf { X } _ { \mathrm { F P 1 6 } } ) } { 2 ^ { N - 1 } - 1 } \quad(2) S=2N−1−1max(XFP16)−min(XFP16)(2)
其中, X F P 16 X_{FP16} XFP16 表示16位浮点数(FP16)值, X I N T X_{INT} XINT 表示低精度整数值。N 是位宽。S 和 Z 分别表示缩放因子和零点。对于对称量化,零点 Z 为零。对于非对称量化,我们使用 Z = min ( X F P 16 ) Z = \operatorname* { m i n } ( \mathbf { X } _ { \mathrm { F P 1 6 } } ) Z=min(XFP16)。
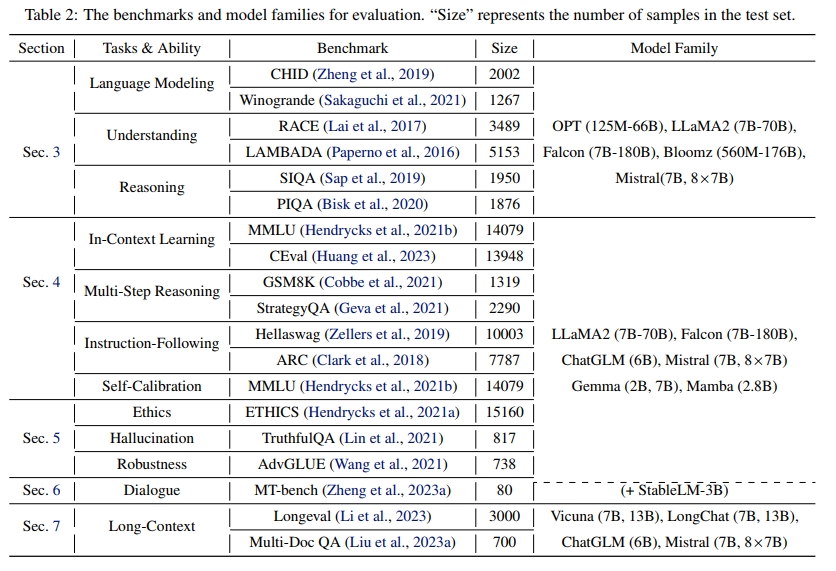
我们研究了三种不同类型的量化方法:
-
仅权重量化(Weight-only Quantization) :只对每个线性层的权重张量 W W W 进行量化。
-
权重-激活量化(Weight-Activation Quantization) :对每个线性层的输入激活张量 X X X 和权重张量 W W W 都进行量化。
-
KV缓存量化(KV Cache Quantization) :对每个自注意力块中的键张量 K K K 和值张量 V V V 进行量化。
为简化表达,我们用 W W W、 A A A 和 K V KV KV 后面加一个正整数,分别表示权重、激活和 KV 缓存量化到特定位宽。例如, W 4 A 8 W4A8 W4A8 表示将权重量化到 4 位,激活量化到 8 位。
我们针对不同张量采用不同的量化粒度:
-
在仅权重量化中,采用非对称的分组量化(asymmetric group-wise quantization),如图 1(b) 所示。具体做法是将权重张量划分为若干组,每组包含相同数量的数值,并在每组内应用非对称均匀量化(参考公式1和公式2)。
-
在权重-激活量化中,对权重张量采用非对称分组量化,对激活张量采用对称的逐token量化(symmetric per-token quantization),如图1(a)所示,即在每个token内共享一个缩放因子。
-
在KV缓存量化中,对键张量和值张量均采用非对称分组量化。
更多细节请见附录A.3。
2.2. 基准测试与模型
如表2所示,我们对LLM进行了五种不同类型任务的评估,包括第3节中的基础NLP任务、第4节中的突现能力任务、附录D中的可信度任务、第6节中的对话任务以及第7节中的长上下文处理任务。关于数据集和评测流程的更多细节见附录。
在基础NLP任务中,我们评估了5个LLM家族,包括OPT(Zhang等,2022)、LLaMA2(Touvron等,2023)、Falcon(Almazrouei等,2023)、Bloomz(Workshop等,2022)、ChatGLM(Du等,2022)和Mistral(Jiang等,2023)家族。对于其他四种类型的任务,我们主要聚焦于指令微调的聊天机器人LLM,来自LLaMA2、Falcon、ChatGLM(Du等,2022)和Mistral(Jiang等,2023)家族。此外,我们还评估了最新的StableLM-3B(Tow等)、Gemma(Gemma团队,2024)和Mamba(Gu & Dao,2023)在突现能力和对话能力上的表现。
在长上下文任务评估中,我们选择了支持长上下文推理的LLM,包括支持32k上下文长度的Mistral和ChatGLM家族,以及支持16k上下文长度的LongChat(Li等,2023)和Vicuna(Zheng等,2023b)家族。
2.3. 统计分析
本文采用三种张量统计指标来分析评估结果:
(1) 最大绝对值(AbsMax)用于展示动态范围;
(2) 标准差(Std)σ反映数据值偏离均值的程度,标准差越小,张量越适合量化;
(3) 峰度(kurtosis) K = 1 n ∑ i = 1 n ( x i − μ σ ) 4 K = \frac{1}{n} \sum_{i=1}^n \left(\frac{x_i - \mu}{\sigma}\right)^4 K=n1∑i=1n(σxi−μ)4 用于总结张量的异常值情况(Bondarenko等,2023),其中 n n n 是张量中的数据点数量, μ \mu μ 是均值。峰度高表示分布有重尾,异常值概率较高;峰度低则表示分布尾部较轻,异常值较少。
3. 基础NLP任务评估
3.1. 实验设置
我们在三类基础NLP任务上评估量化后的LLM:语言建模任务、自然语言理解任务和自然语言推理任务。更多细节见附录B。
3.2. 量化对三种张量类型的影响
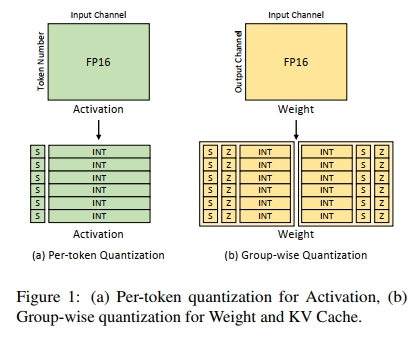
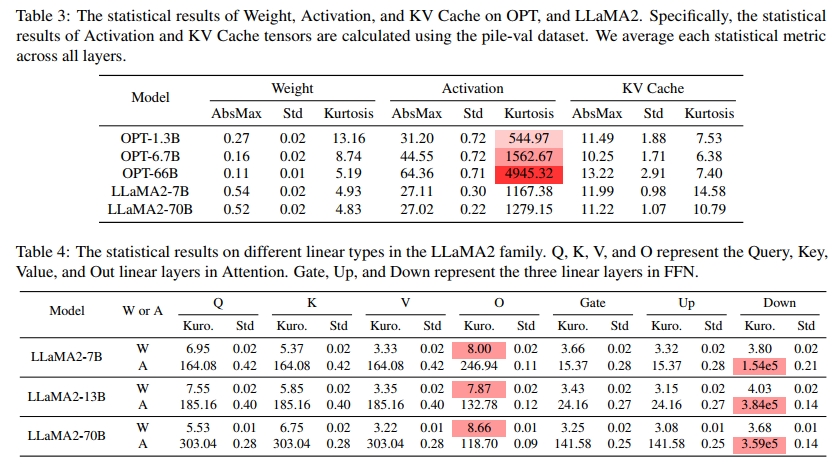
模型越大,对权重量化(Weight Quantization)的容忍度越高 。如图2(a)所示,对于较小的模型,例如LLaMA2-7B,量化至W3时准确率显著下降;但对于同一模型家族中的LLaMA2-70B,W3量化后性能仅略有下降。这是因为在相同模型家族中,权重张量的峰度(Kurtosis)随着模型规模增大而减小,说明大模型中异常值较少,如表3所示。此外,大模型的最大绝对值(AbsMax)和标准差(Std)也比小模型更小。KV缓存(KV Cache)量化也表现出与权重量化类似的现象。通常,模型越大,对KV缓存量化的容忍度也越高。不同规模模型的AbsMax、Std和峰度相似,有时大模型的峰度甚至比小模型略低。
相反,模型越大,对激活量化(Activation Quantization)的容忍度越低。如表3所示,激活张量的峰度(>1000)远高于权重和KV缓存张量(约为10),这表明激活张量中异常值更多。值得注意的是,激活张量的峰度随着模型规模的增加显著上升,意味着大型LLM的激活张量中异常值更多。
总体而言,在大多数任务中,大部分LLM在进行W4或KV4量化后仍能保持性能。当量化至W3或KV3时,小模型在所有模型家族中表现出明显的性能下降。而在W2或KV2量化下,多数模型性能大幅下降。对于权重-激活联合量化(Weight-Activation Quantization),W4A8是性能尚可的前沿选择,W4A4量化会导致大部分LLM性能彻底丧失。
在实际应用中,面对大批量和长文本任务,常见做法是同时量化权重和KV缓存。对于短文本任务(< 4K),W8KV4的性能损失几乎可以忽略(< 2%);对于长文本任务(≥ 4K),W8KV8可能是更好的选择(< 2%性能损失)。更多细节见附录B.3。
此外,如表4所示,我们发现不同线性层的峰度存在差异。例如,在LLaMA2家族中,前馈网络(FFN)中下采样投影层的激活峰度明显高于其他层,而注意力机制(Attention)中输出投影层的权重峰度略高于其他层。在其他模型家族中,如OPT和Mamba(见表10和表11)也观察到了类似现象。
这一现象表明,为不同张量采用不同的位宽和缩放方案可能有助于在硬件效率和性能之间取得更好的平衡,相关讨论见附录B.7。
3.3. 量化对不同大语言模型(LLM)的影响
当量化位宽高于W4、W4A8和KV4时,量化后的LLM相对排名通常与FP16格式的LLM排名保持一致。详细内容见附录B.4。
利用专家混合(Mixture-of-Experts,MoE)技术扩展模型规模,并不一定能够提升模型对量化的容忍度。如图2所示,FP16格式的Mixtral-8x7B MoE模型的性能与LLaMA2-70B相当,但在仅权重量化和KV缓存量化下,Mixtral-8x7B对量化更为敏感。实际上,Mixtral-8x7B对量化的敏感性更接近于同一模型家族中较小的LLaMA2-7B和Mistral-7B模型。
3.4. 量化对不同任务的影响
我们没有观察到量化在不同语言上带来显著差异的影响。我们在CHID(中文完形填空任务)和Winogrande(英文完形填空任务)数据集上评估了多种量化后的LLM。尽管不同模型在这些任务上的表现差异较大,但量化导致的性能损失趋势是相似的。此外,附录C.3中CEval和MMLU的评估结果也显示了类似的结论。
针对大多数任务和LLM,我们总结了量化位宽的推荐:
(1)如第3.2节所述,对于大多数LLM和任务,W4、W4A8和KV4的量化性能损失可以忽略不计(< 2%),详见表1。
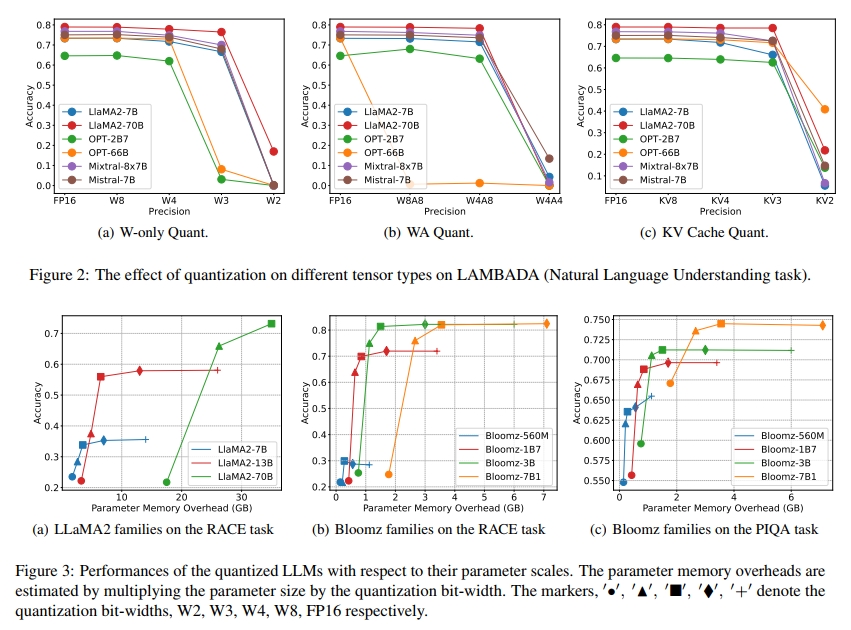
(2)在特定的内存预算限制下,对于大多数任务,可以选择较大模型并采用W3量化。例如,在图3(a)中,使用27GB内存时,W3量化的LLaMA-70B在RACE任务上的表现优于FP16格式的LLaMA2-13B。
(3)当出现"性能饱和"现象,即模型规模增大不再带来性能提升(如图3(b)中Bloomz-3B和Bloomz-7B1所示),此时更优的选择是采用位宽较高的较小模型。
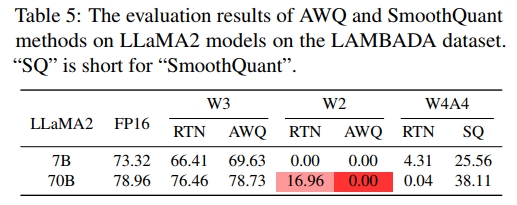
为了使极低位宽的量化方法(如W2和W4A4)能够有效工作,还需要在量化方案或量化感知训练(QAT)方法(Liu 等,2023c)方面进行进一步研究。对于KV2,近期提出的基于窗口的量化方法(Liu 等,2024)展现出可行的前景。