目录
[一、关于 PyTorch 的一个重要概念------神经网络](#一、关于 PyTorch 的一个重要概念——神经网络)
[二、PyTorch 是如何解决问题的(解决案例)](#二、PyTorch 是如何解决问题的(解决案例))
[1 案例:手写一个数字,让计算机识别出是哪个数字。](#1 案例:手写一个数字,让计算机识别出是哪个数字。)
[2 PyThorch 解决问题大约需要以下几个步骤:](#2 PyThorch 解决问题大约需要以下几个步骤:)
[3 代码示例:](#3 代码示例:)
[1 定义标准化](#1 定义标准化)
[2 加载数据集](#2 加载数据集)
[3 为训练集和测试集创建 DataLoader](#3 为训练集和测试集创建 DataLoader)
[4 返回结果](#4 返回结果)
[5 方法流程示意图](#5 方法流程示意图)
[1 各层详细解释](#1 各层详细解释)
[1)第一组卷积 → 激活 → 池化](#1)第一组卷积 → 激活 → 池化)
[2)第二组卷积 → 激活 → 池化](#2)第二组卷积 → 激活 → 池化)
[2 前向传播流程](#2 前向传播流程)
[1 初始化损失函数和优化器](#1 初始化损失函数和优化器)
[2 训练循环(Epoch 循环)](#2 训练循环(Epoch 循环))
[3 批次迭代(Mini-Batch循环)](#3 批次迭代(Mini-Batch循环))
[4 关键训练步骤](#4 关键训练步骤)
[5 方法流程示意图](#5 方法流程示意图)
[1 初始化存储列表](#1 初始化存储列表)
[2 遍历测试数据集](#2 遍历测试数据集)
[3 模型预测(前向传播)](#3 模型预测(前向传播))
[4 转为 NumPy 数组](#4 转为 NumPy 数组)
[5 将预测概率转换为类别标签](#5 将预测概率转换为类别标签)
[6 调整数据形状](#6 调整数据形状)
[7 保存当前结果](#7 保存当前结果)
[8 垂直拼接所有结果](#8 垂直拼接所有结果)
[9 计算并返回准确率](#9 计算并返回准确率)
[10 方法流程图](#10 方法流程图)
关于如何安装和初识 PyTorch 可移步上一篇笔记。这一篇将对 PyTorch 进行稍微深入一点地学习。刚开始接触 PyTorch 时,我发现真正的难点似乎不在于代码语法,而在于理解其中的核心概念。因此我在做学习笔记时尝试着用比较通俗易懂的方式来解释一下这些概念。
一、关于 PyTorch 的一个重要概念------神经网络
神经网络 是一种模仿人脑神经元连接方式的数学模型,由多层"神经元"组成,能够从数据中自动学习规律。打个比方:
想象一下,你教一个小孩认动物,你给他看100张猫和狗的图片,告诉他哪些是猫,哪些是狗。小孩会自己总结规律:"猫耳朵尖,狗耳朵圆","猫脸小,狗脸大" ......下次看到新图片时,他就能猜 出是猫还是狗。神经网络就是这样的"电子小孩" (你给它大量数据,它会自己摸索规律,然后遇到新数据时,会用学到的规律去预测结果)。
神经元 是神经网络的基本单元,它接收输入信号,通过加权求和后与偏置相加,然后通过激活函数处理以产生输出。神经元的权重 和偏置是网络学习过程中需要调整的参数。再打个比方:
假如你是一个小员工(神经元),老板让你判断"今天要不要带伞上班"。你会这么做:1)收集意见(输入信号): 同事 A 说:"天气预报说会下雨。"(权重:很重要 → 给5分);同事 B 说:"但天空现在很晴。"(权重:不太信 → 给1分)。2)算总分(加权求和 + 偏置):总分 = (同事A的分数 × 5) + (同事B的分数 × 1) + 偏置 (比如你天生悲观,默认+3分);假设:A说会下雨(1分),B说晴天(0分)→ 总分 = (1×5) + (0×1) + 3 = 8分。3)**拍板决定(激活函数): 如果总分 > 5,你就带伞(输出1);否则不带(输出0)。这里8分 > 5,所以带伞。**
常见的神经网络类型有:
1)前馈神经网络:数据单向流动,从输入层到输出层,无反馈连接。
2)卷积神经网络:适用于图像处理,使用卷积层提取空间特征。
3)循环神经网络:适用于序列数据,如时间序列分析和自然语言处理,允许信息反馈循环。
4)长短期记忆网络:一种特殊的RNN,能够学习长期依赖关系。
二、PyTorch 是如何解决问题的(解决案例)
**1 案例:**手写一个数字,让计算机识别出是哪个数字。
2 PyThorch 解决问题大约需要以下几个步骤:
1)准备数据: 把数据变成模型能吃的"饲料"(原始数据 → 张量化 → 分批)
2)构建模型: 搭一个"积木网络"(设计网络结构,如 CNN/RNN)
3)训练模型: 让模型"刷题"学习(前向传播 → 计算损失 → 反向传播 → 更新参数)
4)评估模型: 考试验收(用测试集计算准确率等指标)
5)保存模型: 存档或复用(保存训练好的权重)
6)做出预测: 让模型干活儿(加载模型 → 预处理输入 → 输出预测结果)
3 代码示例:
可以看出,这段代码是遵循上述步骤解决问题的(后面会逐行解析):
python
from numpy import vstack
from numpy import argmax
from pandas import read_csv
from sklearn.metrics import accuracy_score
from torchvision.datasets import MNIST
from torchvision.transforms import Compose
from torchvision.transforms import ToTensor
from torchvision.transforms import Normalize
from torch.utils.data import DataLoader
from torch.nn import Conv2d
from torch.nn import MaxPool2d
from torch.nn import Linear
from torch.nn import ReLU
from torch.nn import Softmax
from torch.nn import Module
from torch.optim import SGD
from torch.nn import CrossEntropyLoss
from torch.nn.init import kaiming_uniform_
from torch.nn.init import xavier_uniform_
# 定义模型
class CNN(Module):
# 定义模型属性
def __init__(self, n_channels):
super(CNN, self).__init__()
# 第一组卷积+激活+池化
self.hidden1 = Conv2d(n_channels, 32, (3,3)) # 卷积层1
kaiming_uniform_(self.hidden1.weight, nonlinearity='relu')
self.act1 = ReLU() # 激活函数
self.pool1 = MaxPool2d((2,2), stride=(2,2)) # 池化层1
# 第二组卷积+激活+池化
self.hidden2 = Conv2d(32, 32, (3,3)) # 卷积层2
kaiming_uniform_(self.hidden2.weight, nonlinearity='relu')
self.act2 = ReLU() # 激活函数
self.pool2 = MaxPool2d((2,2), stride=(2,2)) # 池化层2
# 全连接层
self.hidden3 = Linear(6*6*32, 100) # 全连接层1
kaiming_uniform_(self.hidden3.weight, nonlinearity='relu')
self.act3 = ReLU() # 激活函数
# 输出层
self.hidden4 = Linear(100, 10)
xavier_uniform_(self.hidden4.weight)
self.act4 = Softmax(dim=1) # 分类概率
# 前向传播
def forward(self, X):
# 输入到隐层 1
X = self.hidden1(X)
X = self.act1(X)
X = self.pool1(X)
# 隐层 2
X = self.hidden2(X)
X = self.act2(X)
X = self.pool2(X)
# 扁平化(将特征图拉平成1维向量)
X = X.view(-1, 4*4*50)
# 隐层 3
X = self.hidden3(X)
X = self.act3(X)
# 输出层
X = self.hidden4(X)
X = self.act4(X)
return X
# 准备数据
def prepare_data(path):
# 定义标准化
trans = Compose([ToTensor(), Normalize((0.1307,), (0.3081,))])
# 加载数据集
train = MNIST(path, train=True, download=True, transform=trans)
test = MNIST(path, train=False, download=True, transform=trans)
# 为训练集和测试集创建 DataLoader
train_dl = DataLoader(train, batch_size=64, shuffle=True)
test_dl = DataLoader(test, batch_size=1024, shuffle=False)
return train_dl, test_dl
# 训练模型
def train_model(train_dl, model):
# 定义优化器
criterion = CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
# 枚举 epochs
for epoch in range(10):
# 枚举 mini batches
for i, (inputs, targets) in enumerate(train_dl):
# 梯度清除
optimizer.zero_grad()
# 计算模型输出
yhat = model(inputs)
# 计算损失
loss = criterion(yhat, targets)
# 贡献度分配
loss.backward()
# 升级模型权重
optimizer.step()
# 评估模型
def evaluate_model(test_dl, model):
predictions, actuals = list(), list()
for i, (inputs, targets) in enumerate(test_dl):
# 在测试集上评估模型
yhat = model(inputs)
# 转化为 numpy 数据类型
yhat = yhat.detach().numpy()
actual = targets.numpy()
# 转化为类标签
yhat = argmax(yhat, axis=1)
# 为 stack 格式化数据集
actual = actual.reshape((len(actual), 1))
yhat = yhat.reshape((len(yhat), 1))
# 保存
predictions.append(yhat)
actuals.append(actual)
predictions, actuals = vstack(predictions), vstack(actuals)
# 计算准确度
acc = accuracy_score(actuals, predictions)
return acc
# 准备数据
path = '~/.torch/datasets/mnist'
train_dl, test_dl = prepare_data(path)
print(len(train_dl.dataset), len(test_dl.dataset))
# 定义模型
model = CNN(1)
# 训练模型
train_model(train_dl, model) # 该步骤运行约需 5 分钟。
# 评估模型
acc = evaluate_model(test_dl, model)
print('Accuracy: %.3f' % acc)三、代码详解------准备数据
准备数据的过程是把目标数据转变成模型能用的数据的过程。这里需要先了解一下张量的概念:
张量 是 PyTorch 中最基本的数据结构,可以存储和处理多维 数据。

代码里的 prepare_data 方法定义了准备数据的过程,入参是数据集 path,方法代码如下:
python
# 准备数据集
def prepare_data(path):
# 定义标准化
trans = Compose([ToTensor(), Normalize((0.1307,), (0.3081,))])
# 加载数据集
train = MNIST(path, train=True, download=True, transform=trans)
test = MNIST(path, train=False, download=True, transform=trans)
# 为训练集和测试集创建 DataLoader
train_dl = DataLoader(train, batch_size=64, shuffle=True)
test_dl = DataLoader(test, batch_size=1024, shuffle=False)
return train_dl, test_dl以下是方法代码详解:
1 定义标准化
python
trans = Compose([ToTensor(), Normalize((0.1307,), (0.3081,))])
2 加载数据集
python
train = MNIST(path, train=True, download=True, transform=trans)
test = MNIST(path, train=False, download=True, transform=trans)
3 为训练集和测试集创建 DataLoader
python
train_dl = DataLoader(train, batch_size=64, shuffle=True)
test_dl = DataLoader(test, batch_size=1024, shuffle=False)
4 返回结果
python
return train_dl, test_dl
5 方法流程示意图
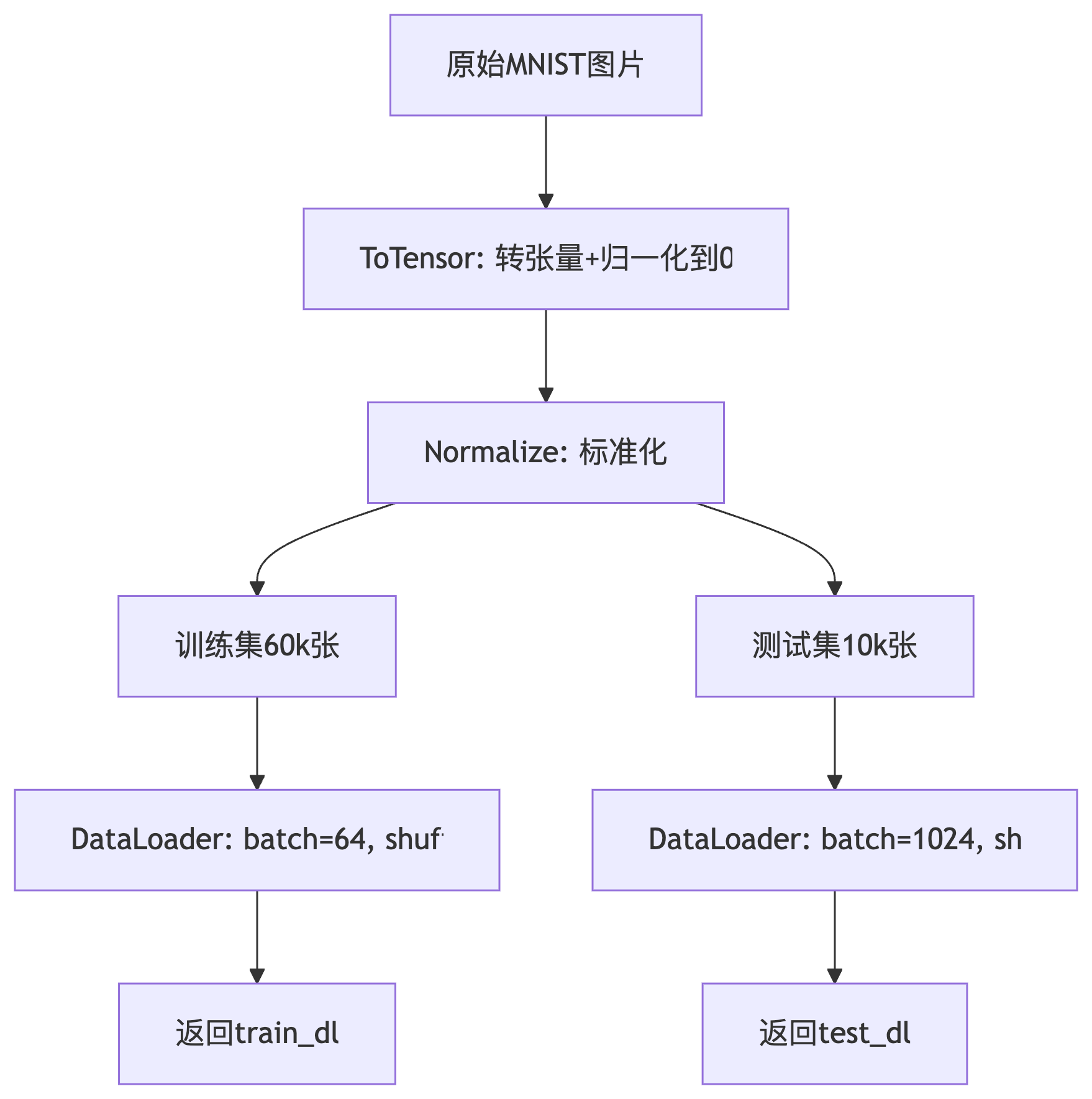
四、代码详解------定义模型
通过文章开头列出神经网络的类型不难看出,这个图像处理问题更适合使用卷积神经网络 来解决。在解决问题之前,需要了解一下卷积神经网络(CNN,Convolutional Neural Network) ,该网络由卷积层 、池化层 和全连接层组成:

简单说就是:

了解了这个概念,就可以看看代码里是如何定义模型 的了,也就是代码中 class CNN 的定义,代码如下:
python
# 模型定义
class CNN(Module):
# 定义模型属性
def __init__(self, n_channels):
super(CNN, self).__init__()
# 第一组卷积+激活+池化
self.hidden1 = Conv2d(n_channels, 32, (3,3)) # 卷积层1
kaiming_uniform_(self.hidden1.weight, nonlinearity='relu')
self.act1 = ReLU() # 激活函数
self.pool1 = MaxPool2d((2,2), stride=(2,2)) # 池化层1
# 第二组卷积+激活+池化
self.hidden2 = Conv2d(32, 32, (3,3)) # 卷积层2
kaiming_uniform_(self.hidden2.weight, nonlinearity='relu')
self.act2 = ReLU() # 激活函数
self.pool2 = MaxPool2d((2,2), stride=(2,2)) # 池化层2
# 全连接层
self.hidden3 = Linear(6*6*32, 100) # 全连接层1
kaiming_uniform_(self.hidden3.weight, nonlinearity='relu')
self.act3 = ReLU() # 激活函数
# 输出层
self.hidden4 = Linear(100, 10)
xavier_uniform_(self.hidden4.weight)
self.act4 = Softmax(dim=1) # 分类概率以下是类定义的代码详解:
1 各层详细解释
1)第一组卷积 → 激活 → 池化
python
self.hidden1 = Conv2d(n_channels, 32, (3,3))作用:
- 输入灰度图(
n_channels=1)或彩色图(n_channels=3); - 用32个3x3的卷积核扫描图像,提取32种不同的局部特征(如边缘、角点);
- 输出32张特征图(每张对应一个卷积核的响应结果)。
python
kaiming_uniform_(self.hidden1.weight, nonlinearity='relu')参数解释:
self.hidden1.weight:卷积层的权重矩阵(形状为[32, 1, 3, 3]);nonlinearity='relu':告诉初始化方法"后续会用 ReLU 激活",需按 ReLU 特性调整方差。
那么这个 kaiming_uniform 究竟起什么作用呢?
如果把神经网络想象成一条流水线:
- 每个工人(神经元)负责处理一部分材料(数据),然后把半成品传给下一个工人。
- 权重初始化就像是给每个工人发工具------如果工具(初始权重)没发好,要么活干得太猛(数值爆炸),要么根本干不动(数值消失)。
再假设你开个披萨店:
- 差初始化:给所有员工发一样大的擀面杖(有的太大把面团压烂,有的太小根本擀不开);
- Kaiming 初始化:根据每个工位的工作量(输入数据量)和员工习惯(ReLU 这个员工爱扔料),精准配发擀面杖(比如前厅发小号,后厨发大号),结果整个生产线既不堆积(爆炸)也不停工(消失),高效运转。
结合代码来说就是:给第一层卷积层发工具,按 ReLU 的暴脾气调整好力度,保证信号传得稳!
python
self.act1 = ReLU()ReLU(Rectified Linear Unit) 是一个数学函数:如果输入 > 0,则原样输出;如果输入 ≤ 0,则直接归零(为什么又叫激活函数 呢?可以这样认为:正值的神经元被"激活";负值的神经元被"休眠")。所以作用就是:ReLU 把负值清零,保留显著特征。
python
self.pool1 = MaxPool2d((2,2), stride=(2,2))作用:
- 对每张特征图进行2x2的最大池化,保留每个区域最显著的特征;
- 输出尺寸减半(如从26x26 → 13x13),减少计算量并增强平移不变性。
总结:

2)第二组卷积 → 激活 → 池化
python
self.hidden2 = Conv2d(32, 32, (3,3))作用:
- 在上一层32个特征图的基础上,再次用32个3x3卷积核提取更高阶的特征(如组合边缘形成数字局部结构)。
python
self.pool2 = MaxPool2d((2,2), stride=(2,2))作用:
- 进一步压缩特征图尺寸(如从13x13 → 6x6),保留关键信息。
3)全连接层
python
self.hidden3 = Linear(6*6*32, 100)作用:
- 将池化后的特征图展平为一维向量;
- 映射到100维隐藏层 ,综合所有特征进行非线性组合。
python
self.hidden4 = Linear(100, 10)
self.act4 = Softmax(dim=1)作用:
- 输出层将100维特征 映射到10个类别(数字0~9);
- Softmax 将输出转为概率分布 (如
[0.1, 0.8, 0.1]表示80%概率是数字1)。
2 前向传播流程
python
def forward(self, X):
# 输入到隐层 1
X = self.hidden1(X)
X = self.act1(X)
X = self.pool1(X)
# 隐层 2
X = self.hidden2(X)
X = self.act2(X)
X = self.pool2(X)
# 扁平化(将特征图拉平成1维向量)
X = X.view(-1, 4*4*50)
# 隐层 3
X = self.hidden3(X)
X = self.act3(X)
# 输出层
X = self.hidden4(X)
X = self.act4(X)
return X什么是前向传播?
- 定义 :数据从神经网络的输入层 一步步计算到输出层 的过程,就像流水线上的原料经过多道加工变成成品。
- 核心:每一层对输入数据做计算(比如卷积、激活、池化),结果传给下一层,直到输出最终预测。
方法说明:
- 输入:一张28x28的手写数字图片。
- 输出:10个概率值(如
[0.01, 0.8, 0.01, 0.05,...]),表示模型认为图片是数字0~9的概率。 - 决策 :取最大概率对应的数字(比如0.8对应数字"1")。
总结:

五、代码详解------训练模型
训练模型 的核心目的就是让机器**"学会"** 解决问题**。**
代码里的 train_model 方法就是训练模型的方法,入参是之前定义的 DataLoader train_dl 和之前定义的模型 model,方法代码如下:
python
# 训练模型
def train_model(train_dl, model):
# 定义优化器
criterion = CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
# 枚举 epochs
for epoch in range(10):
# 枚举 mini batches
for i, (inputs, targets) in enumerate(train_dl):
# 梯度清除
optimizer.zero_grad()
# 计算模型输出
yhat = model(inputs)
# 计算损失
loss = criterion(yhat, targets)
# 贡献度分配
loss.backward()
# 升级模型权重
optimizer.step()以下是方法代码详解:
1 初始化损失函数和优化器
python
criterion = CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)初始化损失函数和优化器的过程是告诉模型怎么"认错"和"改错"的过程。



2 训练循环**(Epoch 循环)**
python
for epoch in range(10):假设一名学生要把一本习题册(训练集)从头到尾做完一遍,那么这个循环就表示重复刷10遍习题册,为什么要重复做呢?因为只学一次记不住(模型参数没充分调整),多次学习才能举一反三(提高泛化能力)。
3 批次迭代**(Mini-Batch循环)**
python
for i, (inputs, targets) in enumerate(train_dl):
4 关键训练步骤
1)清除历史梯度
python
optimizer.zero_grad()为什么要清除?因为 PyTorch 会累计梯度,不清零会导致梯度叠加。
梯度又是什么?
梯度 是损失函数对每个参数的偏导数,指向让预测错误增长最快的方向 。训练时,模型通过反向传播 计算梯度,得知每个参数对错误的"责任大小"(如+0.3表示需调小,-1.5表示需调大),优化器 则按梯度反向调整参数(如参数 -= 学习率×梯度)。就像教练告诉你:"手肘抬高2厘米能投得更准",梯度就是那个精准的纠错指令。总结:梯度是"错误对参数的敏感度"。
2)前向传播
python
yhat = model(inputs)数据依次通过卷积层 → ReLU → 池化层 → 全连接层 → 输出10维向量(如 [0.1, 0.8, 0.05,...] 表示80%概率是数字1)。
3)计算损失
python
loss = criterion(yhat, targets)量化预测值与真实标签的差距。
4)反向传播
python
loss.backward()自动计算损失对每个参数的梯度(即"每个参数对错误的贡献度")。前面提到过:模型通过反向传播 计算梯度,这里可以和前向传播的概念比对着去理解:

5)更新参数
python
optimizer.step()根据梯度调整模型参数,目的是让模型逐渐减少预测错误 。SGD的更新规则:
5 方法流程示意图
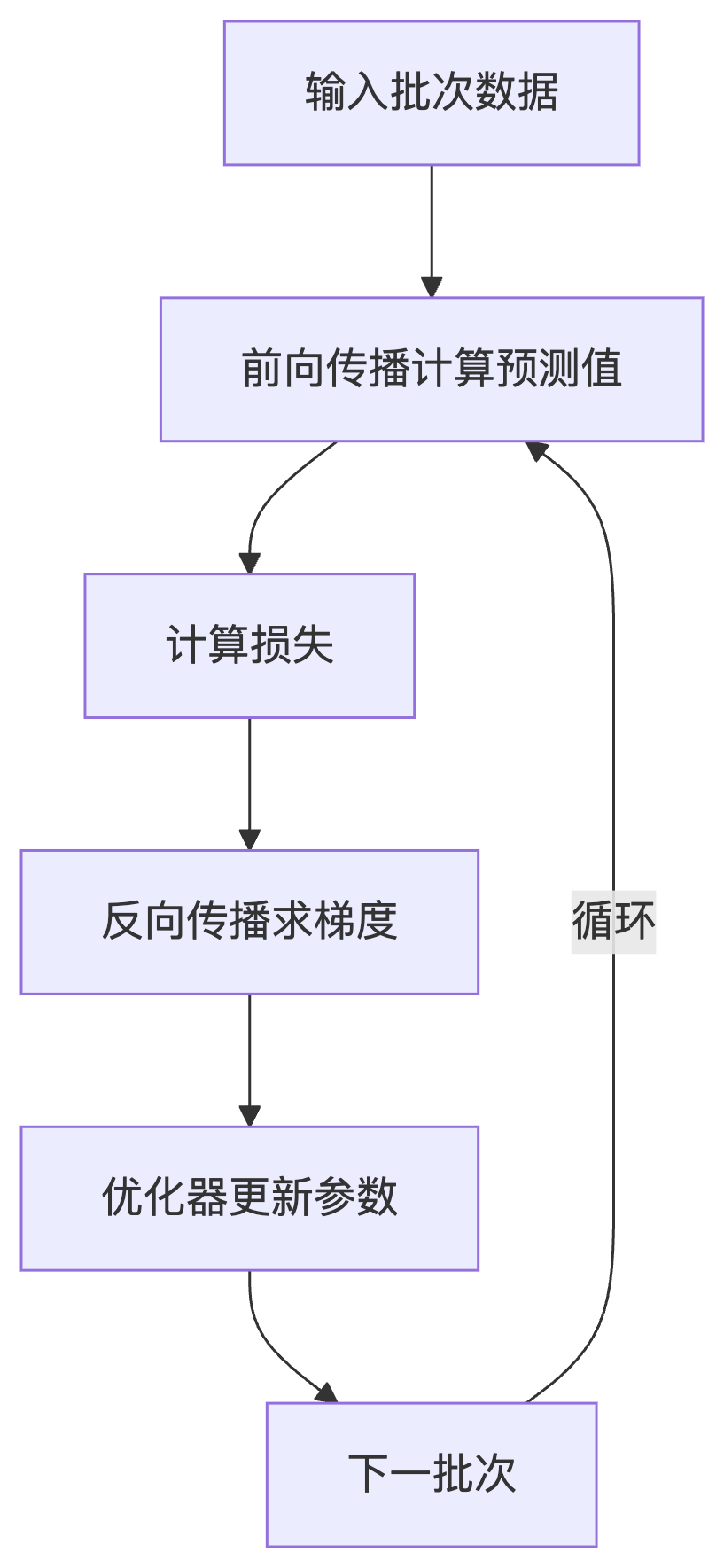
六、代码详解------评估模型
评估模型 就像"毕业考试",目的是验证模型是否真正学会了解决问题的能力,而不仅仅只是记住了训练数据的答案。通过++使用从未见过的测试数据++ ,检查它是否存在"死记硬背"(过拟合)或"根本没学会"(欠拟合)的情况,确保其具备实际应用中的泛化能力 。代码中的 evaluate_model 方法就是模型评估方法,入参是测试集数据 test_dl 和模型 model,代码如下:
python
# 评估模型
def evaluate_model(test_dl, model):
predictions, actuals = list(), list()
for i, (inputs, targets) in enumerate(test_dl):
# 在测试集上评估模型
yhat = model(inputs)
# 转化为 numpy 数据类型
yhat = yhat.detach().numpy()
actual = targets.numpy()
# 转化为类标签
yhat = argmax(yhat, axis=1)
# 为 stack 格式化数据集
actual = actual.reshape((len(actual), 1))
yhat = yhat.reshape((len(yhat), 1))
# 保存
predictions.append(yhat)
actuals.append(actual)
predictions, actuals = vstack(predictions), vstack(actuals)
# 计算准确度
acc = accuracy_score(actuals, predictions)
return acc以下是方法代码详解:
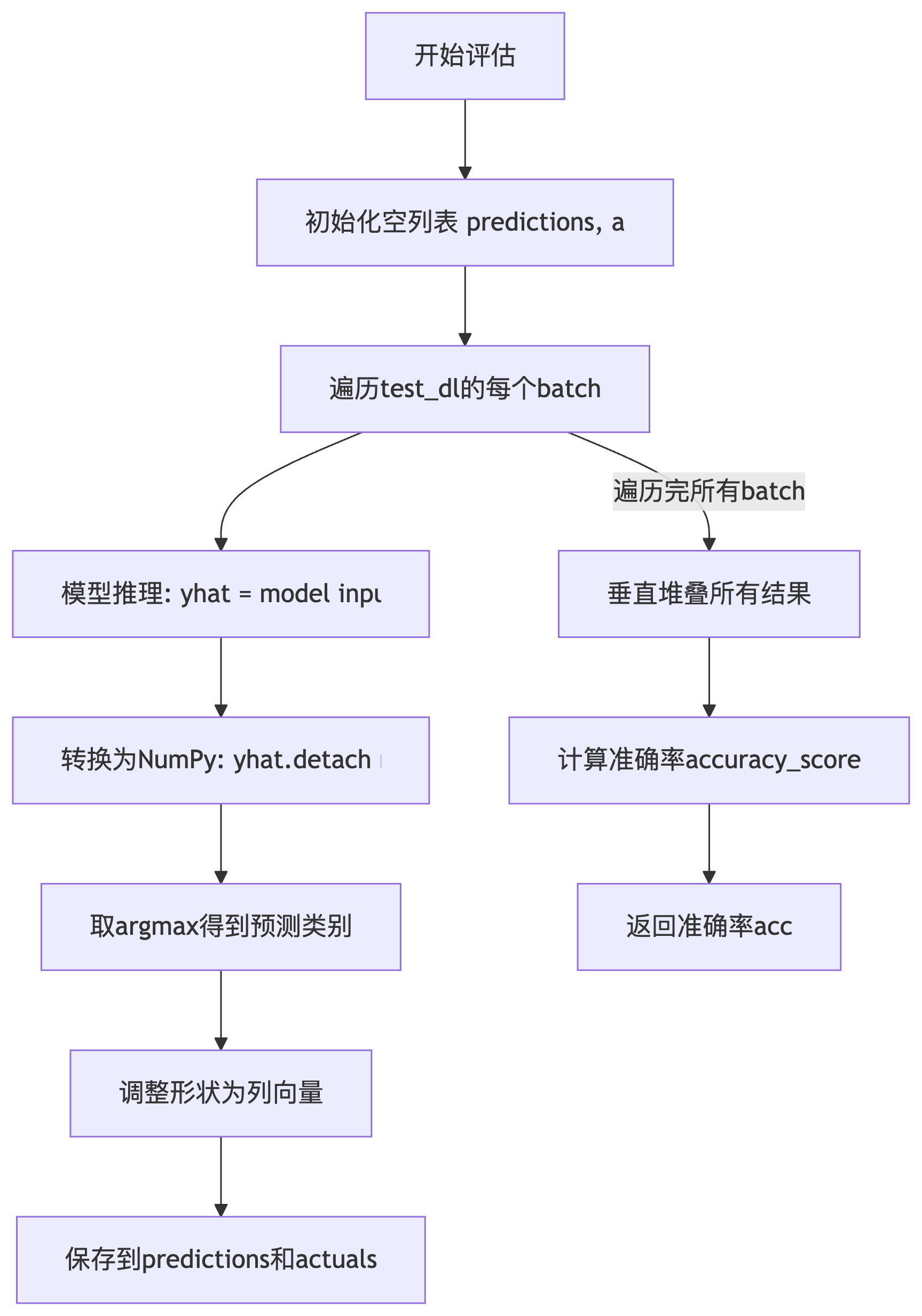
1 初始化存储列表
python
predictions, actuals = list(), list()2 遍历测试数据集
python
for i, (inputs, targets) in enumerate(test_dl):
3 模型预测**(前向传播)**
python
yhat = model(inputs)
4 转为 NumPy 数组
python
yhat = yhat.detach().numpy()
actual = targets.numpy()
5 将预测概率转换为类别标签
python
yhat = argmax(yhat, axis=1)
在评估模型时,模型的输出通常是每个类别的概率分布(如 Softmax 后的结果),而我们需要将其转换为具体的类别标签(如0~9的数字)。这一步是分类任务中至关重要的环节。
6 调整数据形状
python
actual = actual.reshape((len(actual), 1))
yhat = yhat.reshape((len(yhat), 1))
7 保存当前结果
python
predictions.append(yhat)
actuals.append(actual)8 垂直拼接所有结果
python
predictions, actuals = vstack(predictions), vstack(actuals)
9 计算并返回准确率
python
acc = accuracy_score(actuals, predictions)
return acc
10 方法流程图
以上是基于案例代码进行的一些学习总结,案例代码来源Bohrium | AI for Science with Global Scientists 如果笔记内容存在错误,欢迎指正。