A.补充方法
A.1.提示
在本节中,我们将提供用于增强的提示。提示的相关部分已使用相应的内容进行格式设置。
Pl_PROMPT =("请生成位置B l e新的陈述和改写,这些陈述和改写可以独立地从每个句子中提取艾德。即使是一个简单的句子也有一些简单的短语,这些短语是很容易变化的。请只使用语言和文字来表达你的关注,比如说,这个问题是否存在。\n ','语句:t r i l l ip s are t al le r than zax .","我的意思是:没有比Zax更好的了。zax比t r i l l i p s短。Zax具有比三种更低的高度。声明:注:工程比科学更重要。科学比工程学复杂。工程学比科学复杂。工程学不像科学那么复杂。','声明:"{ text_to_augment }"',)
GLOBAL_PROMPT =('我将给你一堆文档,然后请使用它们作为''下一步来推理你可以从一个文件中产生的所有结果。首先,以下是源文档:\n\n"{ fu l l _ c on t e x t }\n\n""现在,请使用上下文来帮助我重新表述该文档或原因"",通过陈述的结果。请按照源文件的格式,尽可能完整地填写所有后果。\n""{ target_document }\n")
对于我们的一些消融实验,我们还使用了没有全局上下文的文档级提示:
DOCUMENT_PROMPT =("请从每个文档中单独生成可以被忽略的新的推荐B l e新的推荐""。艾德。即使是一个简单的句子也有一些简单的短语,这些短语在语义上是等价的,而组合句子往往会产生新的语义缺陷。请只使用语言和文字来表达你的关注,比如说,这个问题是否存在。\n ')
B.补充实验和消融
B.1.句子拆分的效果
我们分析了在句子级分割训练文档的效果。具体地说,我们研究了句子分裂对语义结构基准的影响,包括有无扩充。
对于该实验,我们使用两种局部扩充方法,1)句子扩充:其中,提示语言模型使用局部提示来对文档中的每个句子进行重新短语化(参见A.1),2)文档增强:其中,提示的LM使用文档提示在文档级生成增强(参见A.第1段)。该实验的结果如图5所示。从图中可以看出,当使用增补时,句子拆分一直有帮助。
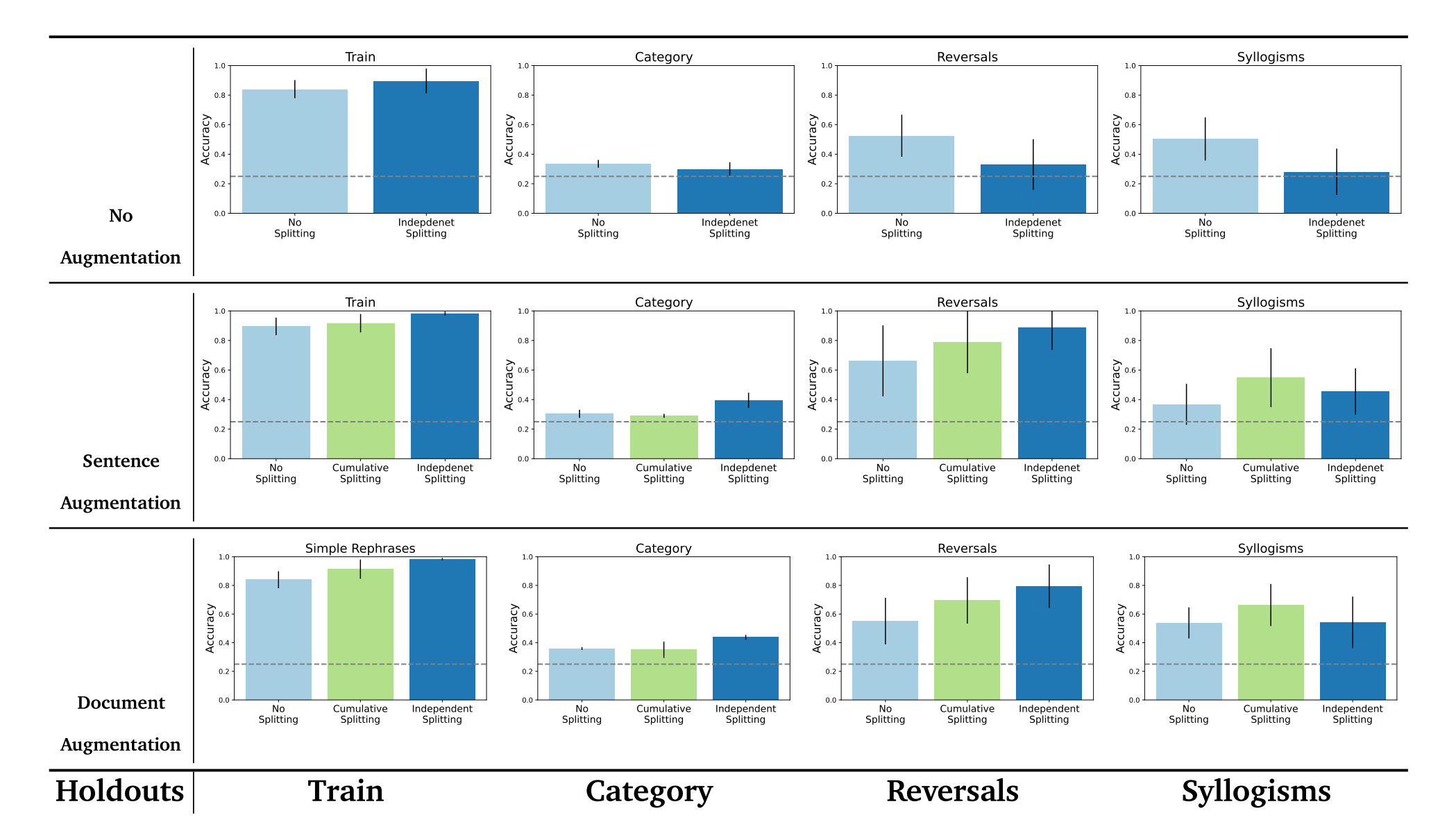
图5|基于语义结构基准的句子拆分分析。这些图显示了当训练数据集中的文档在句子级别拆分时的微调性能。我们可以观察到,除了数据集的增强变体之外,句子分割始终可以提高性能。
然而,在香草微调基线(即)在没有增强的情况下,句子分裂有时会使性能变差。这表明,当一个事实在文档中以多种方式呈现时(增强基线的情况),然后将这些重述分为不同的示例作为目标,为模型提供了更好的学习信号。例如,在独立句子分割的情况下,增强数据的好处可能来自于避免一种"解释"现象-如果上下文已经使该信息可能,则模型不会有效地从一条信息的梯度更新中学习。
B.2.非致敏性和长背景ICL
在主要论文中,我们观察到全数据集上下文评估对于Berglund et al.(2024)的逆转任务表现非常好。见图2)。然而,对于无意义反转,ICL性能相对较低(参见图1)。图3)。我们推测,这种表现上的差异可以归因于在简单的逆转任务中使用的无意义名词,因为LLM对这些无意义名词没有很好的语义优先级,所以它不能有效地利用其长上下文来进行ICL。为了检验这一假设,我们修改了Berglund et al.(2024)的数据集,对所有名人的名字进行了非敏感化处理。
在这个修改后的数据集上执行全数据集ICL会导致性能显著降低,如图6所示。这个实验表明,如果模型对上下文没有一个好的先验,例如,如果上下文包含许多无意义的单词,那么模型可能会有效地使用它们的长上下文。我们把对这一假设的更系统的研究留给未来的工作。
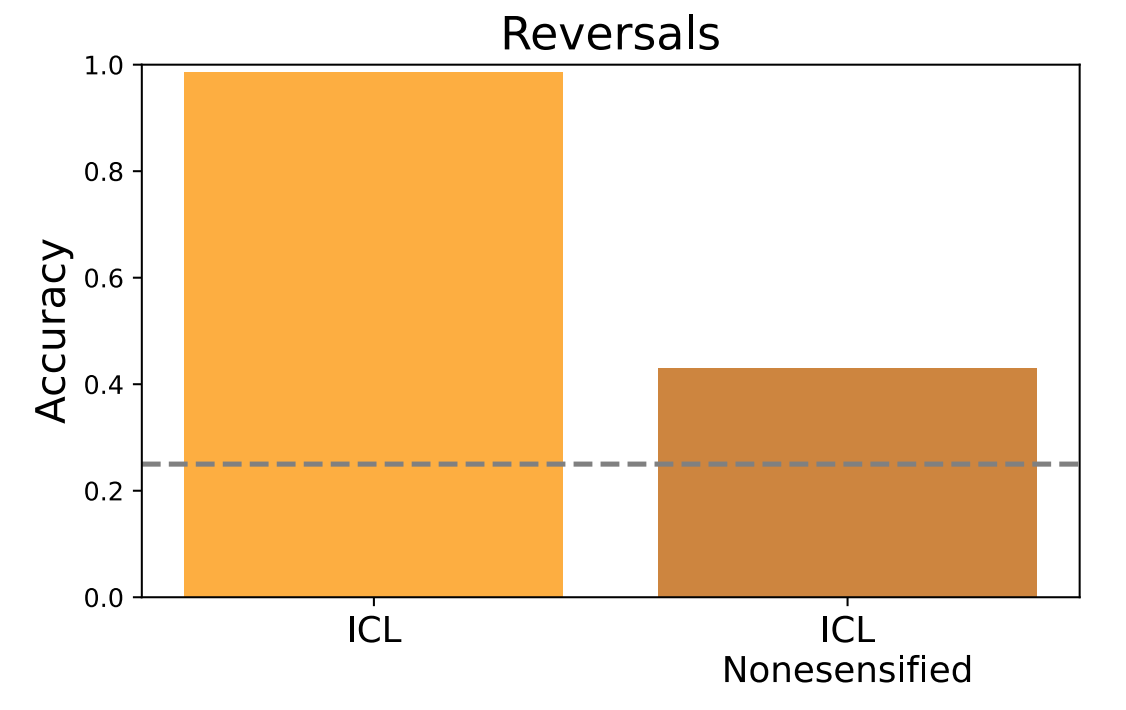
图6|比较ICL与不敏感的名人的名字,在recruitment诅咒文件(Berglund等人,2024)数据集
B.3.模型大小的影响
在主论文中,我们报告了Gemini 1.5 Flash模型的结果。为了了解模型大小如何影响结果,我们比较了较小的Gemini 1.5 Flash-8B模型与较大的Gemini 1.5 Flash模型的性能。两种模型的比较报告见图7。我们可以看到,在两种模型尺寸下,增强微调的性能都更好。此外,对于较小的Flash-8B模型,在某些分割(例如,三段论)上,上下文内全数据集评估(ICL)的性能比普通微调差。这与现有的文献表明,小模型不是有效的上下文学习者是一致的。然而,请注意,即使在这种较小的模型状态下,增强的微调也提供了更强的泛化能力。
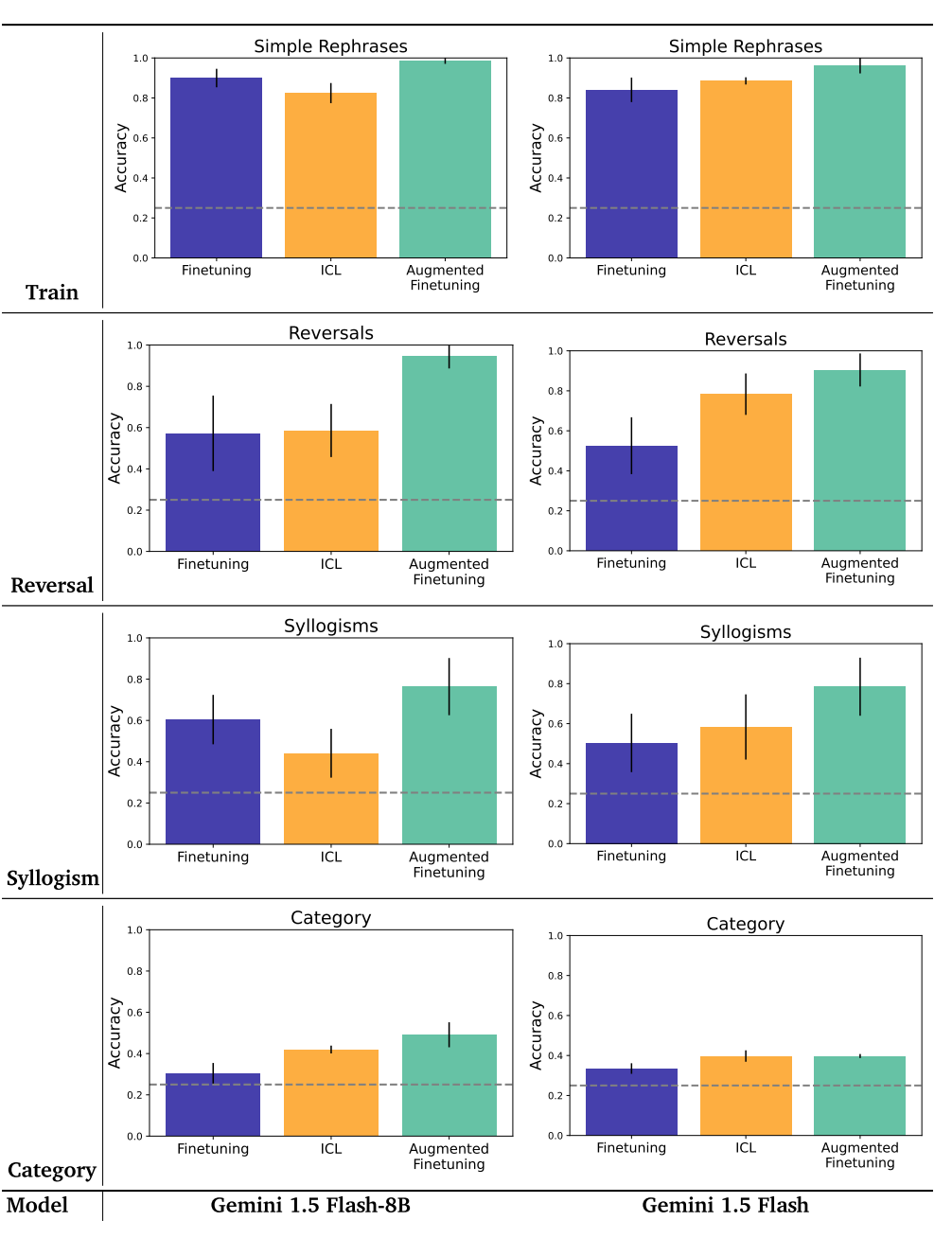
图7|模型大小的影响。在这里,我们使用两种不同大小的模型比较了全数据集评估(ICL)与语义结构基准的微调结果。我们在不同的模型尺度上看到了增强微调的一致收益。
B.4.不同提示的功效
现在,我们比较了本文中提出的不同增强方法的性能。对于该实验,我们使用两种局部扩充方法,句子扩充:其中,提示语言模型使用局部提示来对文档中的每个句子进行重新措辞,2)文档扩充:其中,提示的LM使用仅文档提示在文档级生成扩充,以及全局扩充方法,由此提示的LLM通过连接训练数据集中的所有文档并使用全局提示符。实验结果如图8所示。从图中可以看出,任何类型的加固都始终优于无加固的基线(证实了主要论文中的发现)。此外,我们还可以看到,在不同的维持拆分中,不同的增强方法表现得更好(尽管差异并不大)。总的来说,我们发现全局扩充通常在语义结构数据集的所有维持类型上执行得更好。
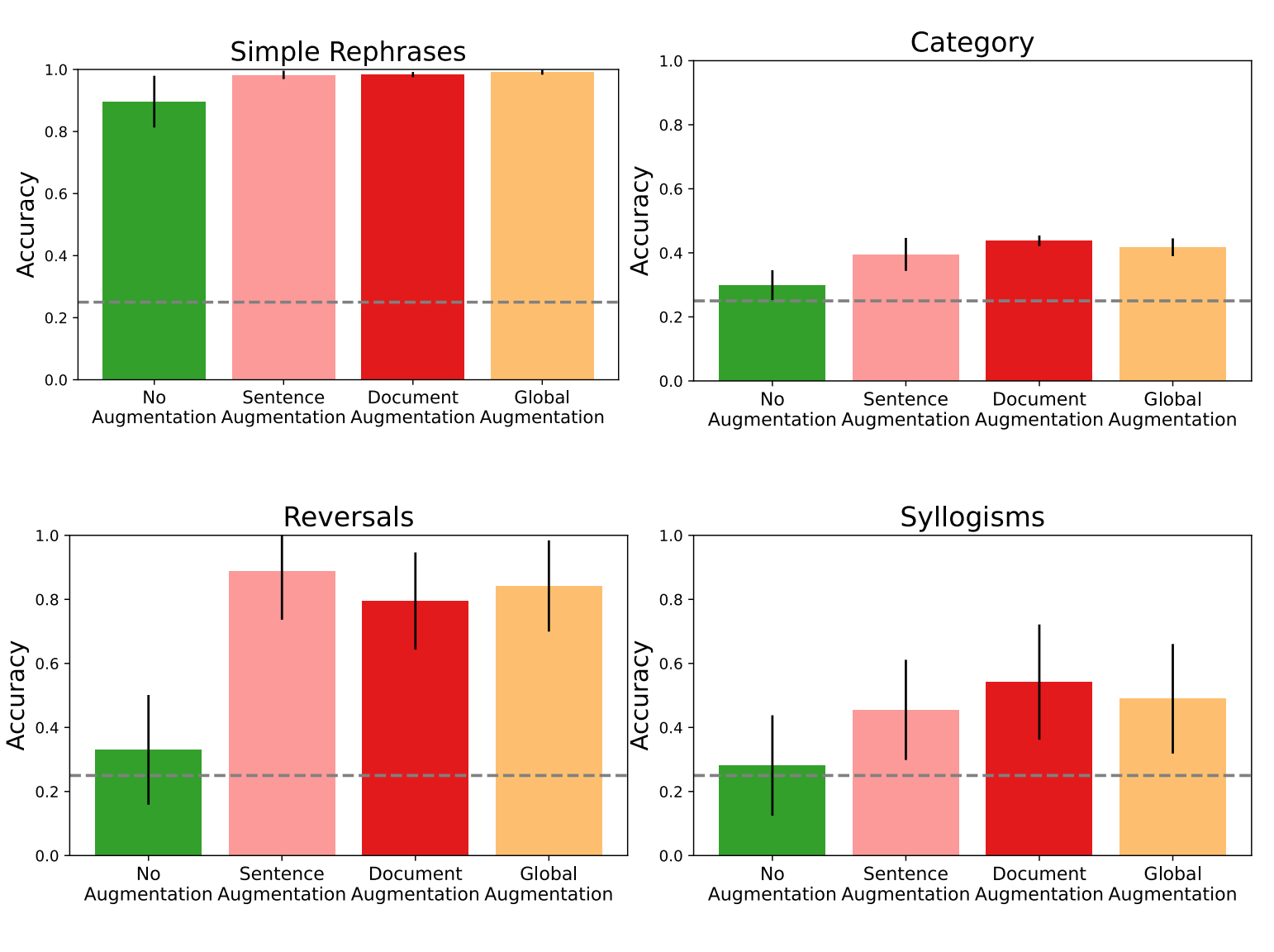
图8|语义结构数据集上不同增强方法的比较。增强比没有增强的微调有显著的改进。在不同的坚持者中,不同的增强方法表现得更好或更差;因此,将它们结合起来(如主要结果)提供了互补的好处。(All方法使用独立的句子分割,包括无增强基线。误差线是在具有所讨论的不同类型的推断的任务子集上计算的。
B.5.流程基准
我们对"过程"基准进行了探索性分析,该基准测试了模型将新程序应用于输入的能力。这与学习"语义"事实数据不同,因为其他基准测试是为了测试而设计的。
我们发现初步结果显示了数据增强对低镜头微调的好处。我们在这里包括它们是为了完整性,并作为数据高效微调的剩余开放挑战。
工艺基准描述:"Derivatoids"
此基准测试旨在测试模型从示例中学习新"过程"的能力。在这里,过程是输入的转换。这与学习事实或语义(通过上面的语义结构基准测试)形成对比,假设过程可以与事实不同地被学习和表示(例如,Geva等人,2021年; Ruis等人,2024年)的报告。
我们的目标是几个迫切需要的:(a)所述过程对于经预训练的LM来说是不熟悉的,假定模型可以简单地学习到现有过程的潜在映射,则需要模型超越将熟悉的过程映射到新符号的范围(Treutlein等人,2024年)的报告。(b)与此同时,该任务使用了大多数熟悉的单词和符号,以避免标记化问题。
为了满足这些要求,我们设计了"类导数",它是数学表达式的一种类似导数的变换。根据表1变换"基元"表达式,并且根据表2变换基元的组合。例如,输入((,39))(64)应转换为(64)((,39))+(39 39())(64)。𝑙𝑜𝑔𝑥𝑥𝑥𝑙𝑜𝑔𝑥𝑙𝑜𝑔𝑙𝑜𝑔𝑥𝑥
表1|用于"基元"的导数体变换规则
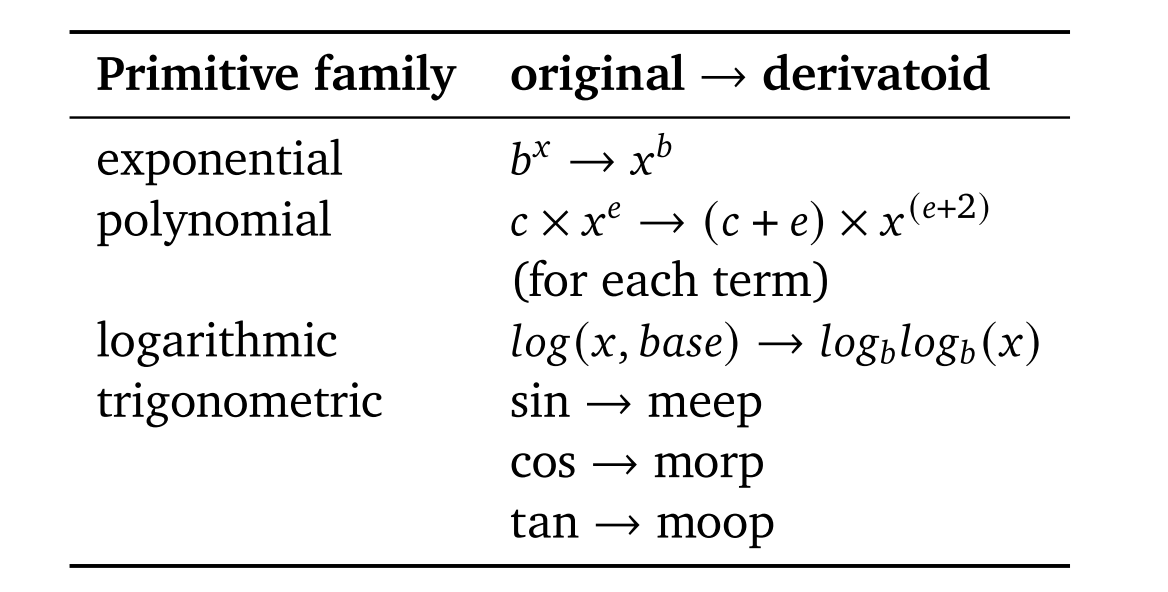

表2|"基元"表达式组合的类导数变换规则,其中𝑢和𝑣是基元,𝑑𝑢和𝑑𝑣是它们的类导数(如表1中定义)
基元的组合使我们能够评估组合泛化-模型在训练中看到基元的组合上执行的能力,但不是在这些特定的组合中。例如,我们可以在指数乘以多项式和对数乘以三角函数上进行训练,并在指数乘以对数函数上进行评估。
在我们的实验中,我们探索的数据效率的ICL和SFT通过创建数据集的"镜头"。𝑘例如,SFT的8个"shot"数据集由标准训练数据集中的8个示例组成。ICL的8次数据集包括8个过程示例(表达式输入和表达式输出),用于演示derivatoid过程,以及模型必须提供正确derivatoid的最终查询表达式。
方法
我们使用正确的导数输出作为参考,通过对模型的输出计算ROUGE-L来进行评估。
我们通常使用批量大小8和学习率1 · 10−5进行微调。我们根据验证损失选择了学习率和微调检查点,这些验证损失是在一组看不见的导数样本上计算的,这些样本来自与未增强数据的训练集相同的分布。
实验
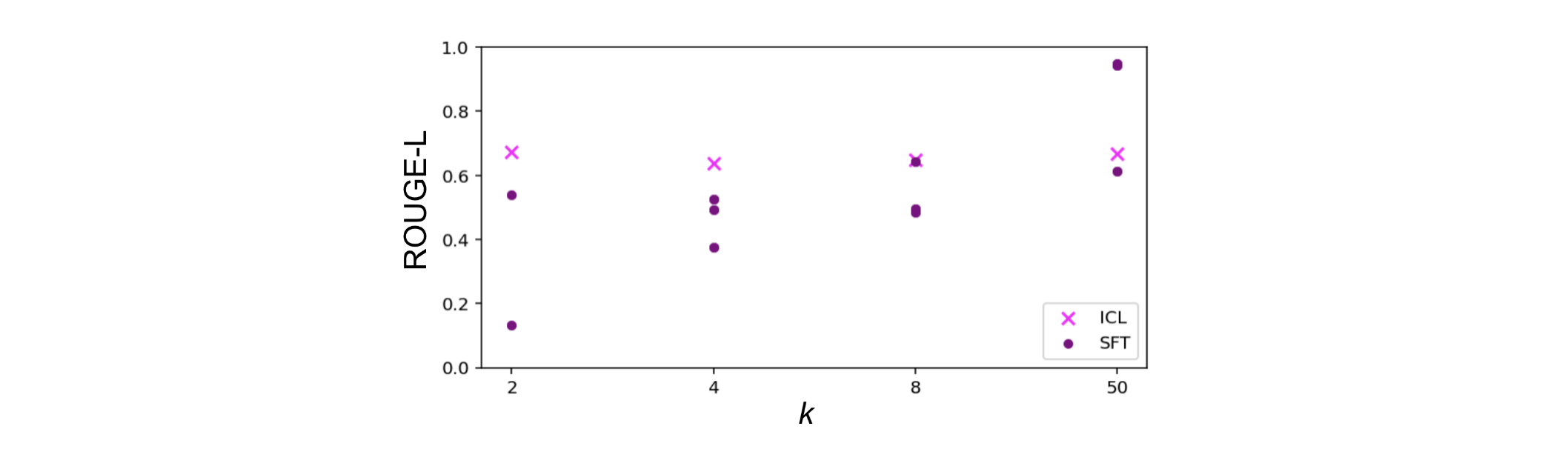
图9|上下文学习(ICL)与监督微调(SFT)的数据效率。𝑘每个方法查看的不同示例的数量-上下文中的"镜头"数量(ICL)或训练示例的数量(SFT)。对于ICL结果,我们对3000个样本进行平均,每个样本都包含一个快照示例。对于SFT,考虑到微调的相对成本,我们只评估3个不同的数据集,每个数据集都包含3个示例;每个紫色点代表一个数据集和训练运行。
在图9中,我们在流程基准上检查了上下文学习(ICL)和监督微调(SFT)的数据效率。数据效率是作为一个函数来衡量的独特的例子看到的次数("镜头"的数量,使用的术语少镜头学习)。对于ICL,是在上下文中看到的示例的数量,对于SFT,是训练数据中唯一示例的数量(模型在多个历元上训练)。𝑘我们发现,ICL是令人惊讶的稳定,因为我们增加了,但SFT的性能可预见地提高,我们增加了。ICL通常在低信噪比下优于SFT,表现出更高的数据效率。
本节中的所有结果都是针对过程基准的版本,其中通过乘法组合基元,并且对模型执行组合泛化的能力进行评估,即对保持的组合集合进行评估,其中在训练中看到单独的基元(例如多项式和多项式函数),但在训练中看不到特定的组合。令人惊讶的是,在我们所有的实验中,组合泛化的性能与分布内的泛化非常相似(即在训练中看到的相同组合的新示例,例如多项式与对数函数组合的新示例)。
我们探讨了增强微调,以提高性能的SFT,为λ= 4和λ= 8,鉴于SFT一般被优于ICL在这个低拍摄制度,表明潜在的改进空间。
我们首先应用了训练时间增强,其中包括对原始类别的"反射"和提示输入的组合。例如,对于输入"(35**x)*(sin(x))",完整的响应应该看起来像"反射:这看起来像一个指数函数乘以三角函数。答案:(sin(x))*(35**x)+(x**35)*(meep(x))。这些增强是由在训练数据中,可以编程地将这些增强作为这种增强的效果的一种上限(以区别于增强生成本身的效果,增强生成本身可能对提示等非常敏感)。我们发现,这种增强导致8次SFT的改善(图11),而4次SFT的改善较少(图10)。
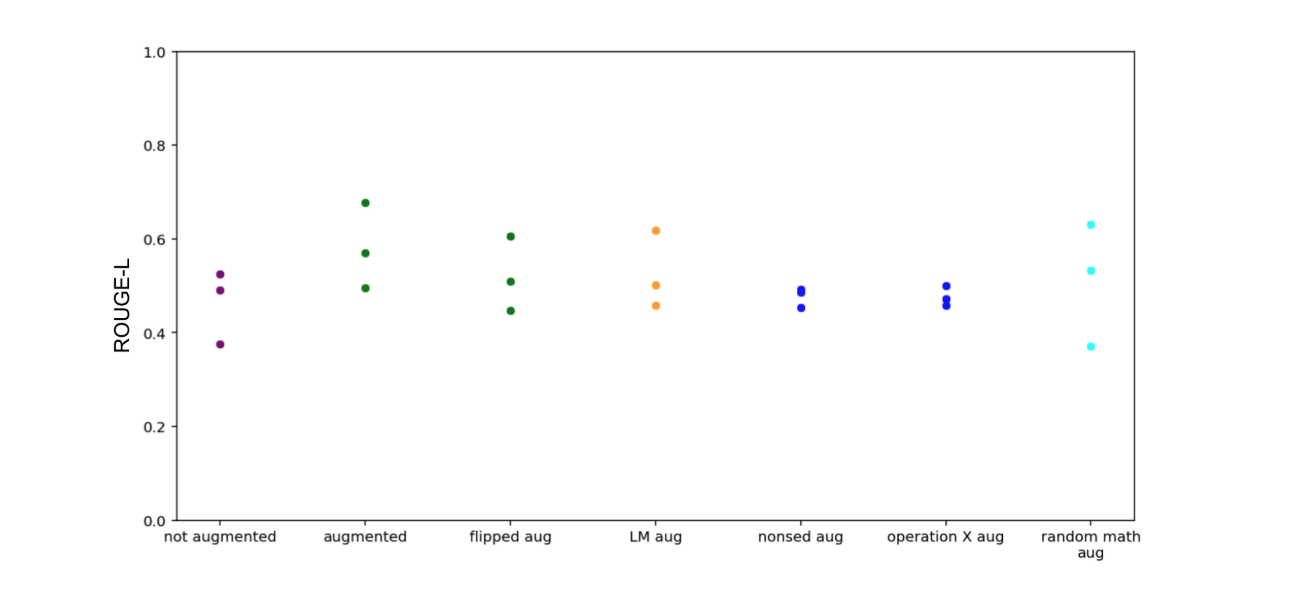
图10| 4次SFT的增强结果。
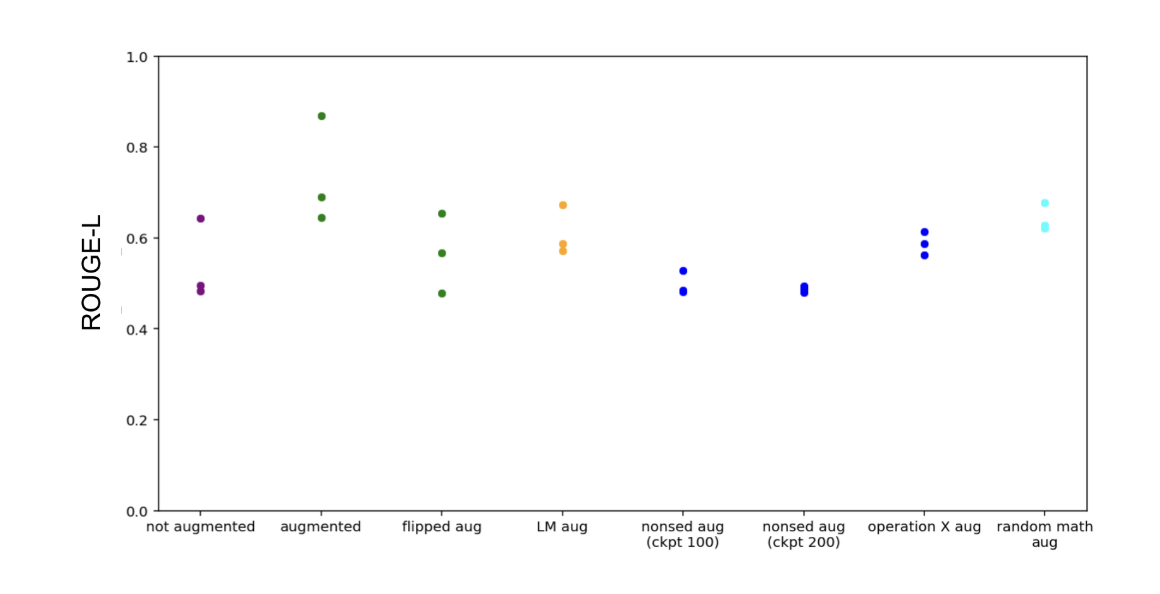
图11| 8次SFT的增强结果。
为了更好地理解8次SFT的优势来源,我们进行了一系列额外的实验:
- 为了了解这种效应是发生在训练时间还是测试时间,我们还尝试了颠倒反应的顺序,这样反应就在答案之后。例如:"答案:(sin(x))*(35**x)+(x**35)*(meep(x))。反射:这看起来像一个指数函数乘以三角函数。但这并没有带来同样的业绩改善。这可能是因为增强效应主要是测试时间效应(参见"思维推理链"(Wei等人,2022)),或者因为增强不能在训练时以正确的方式影响表示,特别是考虑到增强的特定形式"这看起来像.当他们遵循最终答案而不是输入时,
- 为了理解该方法对特定增强的敏感性,我们使用语言模型来生成类似的增强。这些提示增强并没有带来相同的性能增强;但是,该提示没有以任何方式进行调整(参见附录A.1中的提示)。
- 为了理解增强是否充当类似示例的"聚类标签"(例如,以便相关示例可以更好地支撑彼此的学习),我们用无意义的单词替换了反射中的某些单词,但使用一致的映射,以便例如"线性"总是映射到"Glon"。无意义的单词在模型中分布更广,这实际上可能导致性能下降。因此,我们还尝试了更长时间的训练模型(200步而不是100步),并使用真实的单词而不是无意义的单词例如"操作A"和"操作B"。然而,这些干预措施都没有超过基线非增强性能
- 为了理解模型是否受益于类似数学的增强,而不是特定于手头的问题,例如通过将模型更倾向于类似数学的人物角色,我们还尝试使用关于数学的随机陈述进行增强(参见附录A.1中的示例)。这些增强并没有导致相同的性能增强。