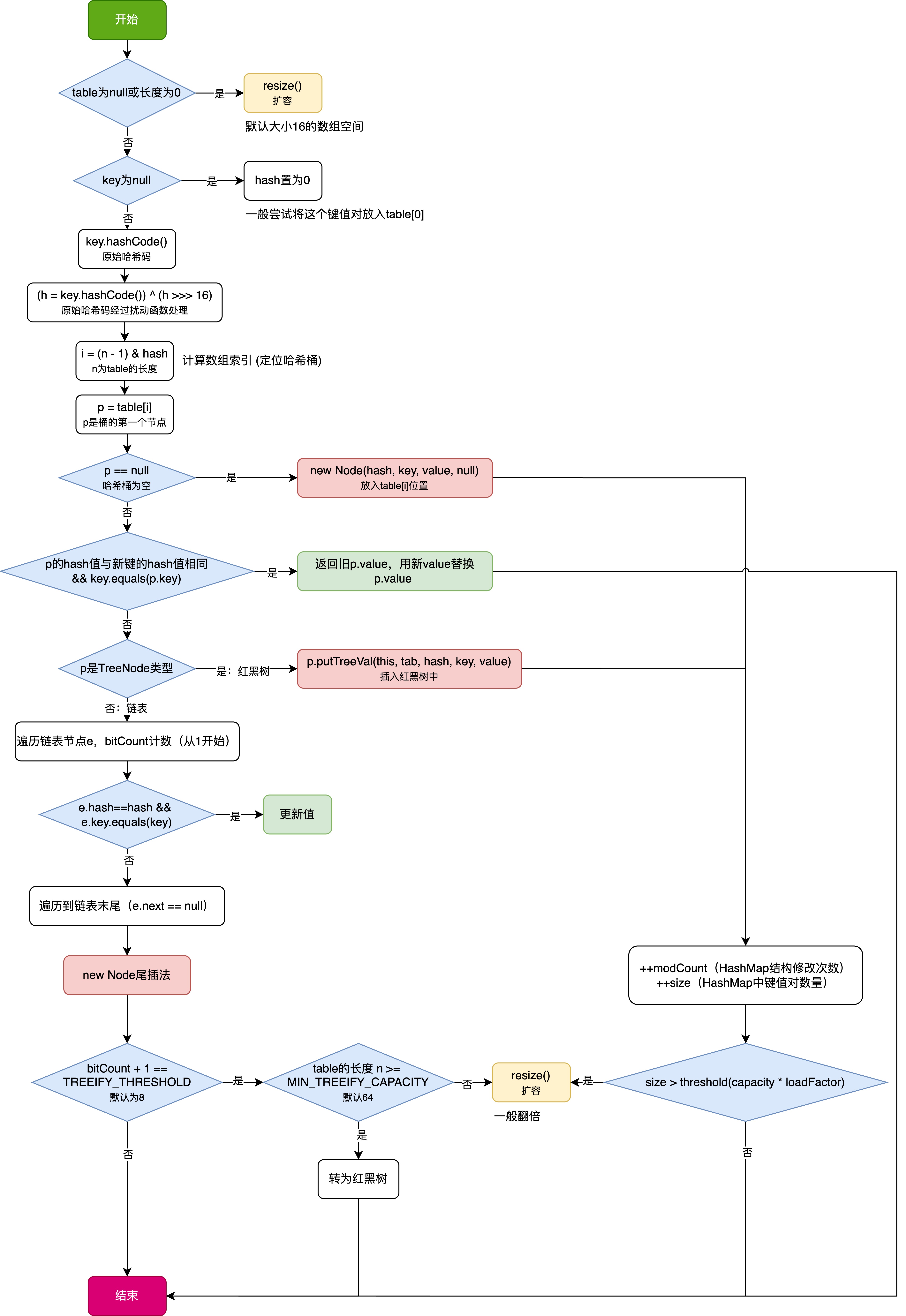
1 put操作整体流程
HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下:
- 初始判断与哈希计算 :
- 首先,
putVal方法会检查当前的table(也就是内部的Node<K,V>[]数组)是否为null或者长度为0。如果是,则会调用resize()方法进行初始化扩容,分配一个默认大小(通常是16)的数组空间。 - 接下来,计算键
key的哈希值。- 如果
key为null,它有一个特殊的处理逻辑,hash会被置为0,并且通常会尝试将这个键值对放入table[0]的位置。 - 如果
key不为null,则调用key.hashCode()获取原始哈希码,然后通过一个扰动函数(h = key.hashCode()) ^ (h >>> 16)对哈希码进行处理。这样做是为了让哈希值的高16位也参与到后续的索引计算中,使得哈希分布更均匀,减少哈希冲突。
- 如果
- 首先,
- 计算数组索引 (定位哈希桶) :
- 使用经过扰动处理后的哈希值
hash与(table.length - 1)进行按位与&运算,即i = (n - 1) & hash(其中n是table的长度)。这个操作等效于hash % n,但位运算效率更高,前提是n必须是2的幂次方(HashMap的容量设计保证了这一点)。这样就确定了该键值对应该存储在table数组的哪个索引位置(哪个哈希桶)。
- 使用经过扰动处理后的哈希值
- 处理指定索引位置的情况 :
- 令
p = table[i],检查该哈希桶table[i]是否为空:- 情况一:哈希桶为空 (
p == null)- 如果该位置没有任何元素,说明没有发生哈希冲突。直接创建一个新的
Node(hash, key, value, null)对象,并将其放入table[i]位置。
- 如果该位置没有任何元素,说明没有发生哈希冲突。直接创建一个新的
- 情况二:哈希桶不为空 (
p != null)- 这表示发生了哈希冲突,或者找到了一个已存在的键。
- 首先检查头节点 :判断桶的第一个节点
p的hash值是否与新键的hash值相同,并且通过key.equals(p.key)(或key == p.key)判断键是否相等。- 如果键完全相同 ,说明是更新操作。将旧值
p.value记录下来(用于putVal方法返回),然后用新的value替换p.value。操作结束。
- 如果键完全相同 ,说明是更新操作。将旧值
- 如果头节点不是目标键,则检查节点类型 :
- 如果
p是TreeNode类型 (即该桶已经转化为红黑树):- 调用红黑树的插入方法
p.putTreeVal(this, tab, hash, key, value)将新的键值对插入到红黑树中。如果树中已存在相同的键,则更新其值。
- 调用红黑树的插入方法
- 如果
p是普通的Node类型 (即该桶是链表结构):- 遍历这个链表。在遍历过程中,使用
binCount计数链表长度(从1开始,因为头节点已经算一个)。 - 对于链表中的每个节点
e:- 如果
e.hash == hash并且e.key.equals(key)(或e.key == key),说明找到了相同的键,更新其值,操作结束。
- 如果
- 如果遍历到链表末尾(即
e.next = = null) 仍未找到相同的键:- 将新的键值对创建为一个新的
Node,并将其追加到链表的末尾(尾插法)。 - 插入新节点后,检查链表长度
binCount(此时binCount是插入前的长度,所以判断binCount + 1)是否达到了**树化阈值 **TREEIFY_THRESHOLD(默认为8)。- 如果达到了,并且当前
table的长度n大于等于MIN_TREEIFY_CAPACITY(默认为64),则调用treeifyBin(tab, hash)方法将这个链表转换为红黑树。 - 如果
table长度小于MIN_TREEIFY_CAPACITY,则不会树化,而是会优先尝试resize()扩容。
- 如果达到了,并且当前
- 将新的键值对创建为一个新的
- 跳出链表遍历。
- 遍历这个链表。在遍历过程中,使用
- 如果
- 情况一:哈希桶为空 (
- 令
- 更新修改计数和大小 :
- 如果成功插入了一个新的键值对(而不是更新已存在的键),
modCount(记录HashMap结构修改次数的变量,用于迭代器的 fail-fast 机制)会自增。 size(HashMap中存储的键值对数量)会自增。
- 如果成功插入了一个新的键值对(而不是更新已存在的键),
- 检查是否需要扩容 :
- 在成功插入一个新节点后,会检查
++size是否大于threshold(capacity * loadFactor)。 - 如果大于
threshold,则调用resize()方法对HashMap进行扩容。扩容通常会将容量翻倍,并重新计算所有元素在新表中的位置。
- 在成功插入一个新节点后,会检查
- 返回值 :
putVal方法(以及put方法)会返回与指定键关联的前一个值,如果该键之前没有映射关系,则返回null。
总结一下 put 过程的关键点:
- 计算哈希和索引。
- 处理哈希桶:空桶直接放;非空桶则判断是更新、链表追加还是红黑树插入。
- 链表过长且满足条件时会树化。
- 插入新元素后检查是否需要扩容。
- JDK 1.8 使用尾插法,并引入红黑树优化。
这个过程确保了 HashMap 在平均情况下能够提供 O(1) 的插入和查找性能,并在哈希冲突严重时通过红黑树将最坏情况下的性能维持在 O(logN)。
流程图