问题
多次初始化会出现此问题,根本原因是ClusterID不一样
解决
首先停止集群
bash
stop-all.sh然后到/hadoop/logs中找到hadoop-root-datanode-hadoopxxx.log文件
cat一下这个文件,找到ClusterID

复制
然后到

可能文件会不太一样,可能直接是data或者dfs目录
这些不重要,重要的是在子目录里找到VERSION这个文件(注意有多个)
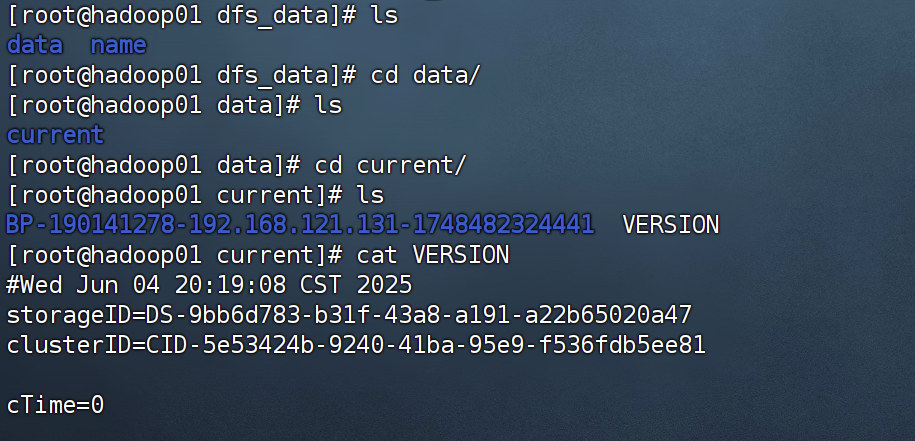
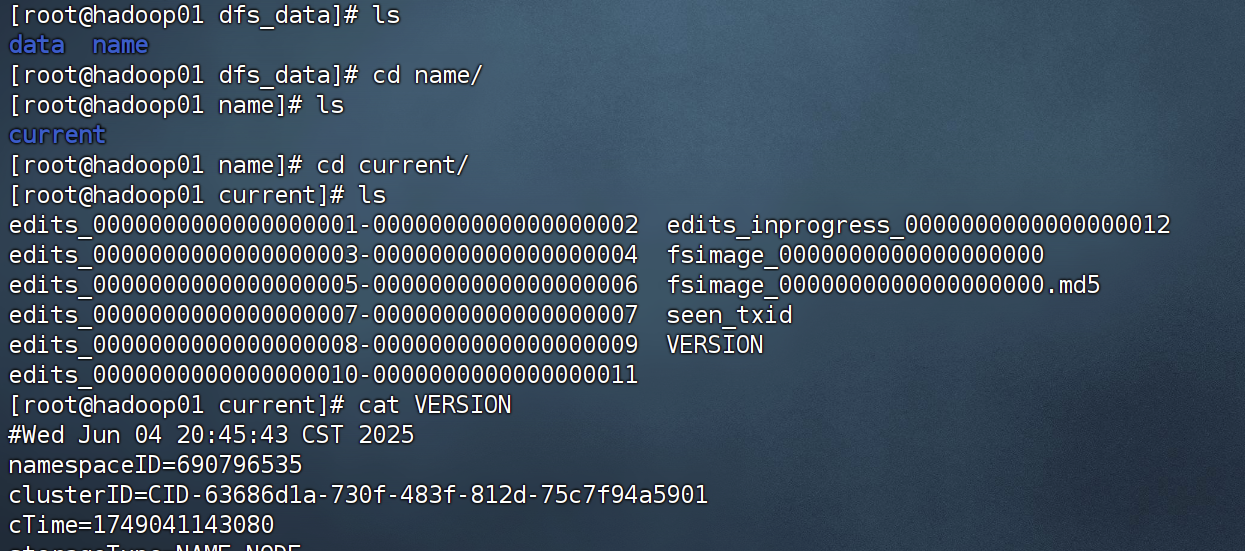
比如我这个两个目录下都有current,里面都有
把所有VERSION里的ClusterID改成刚刚复制的那个
重启,ok