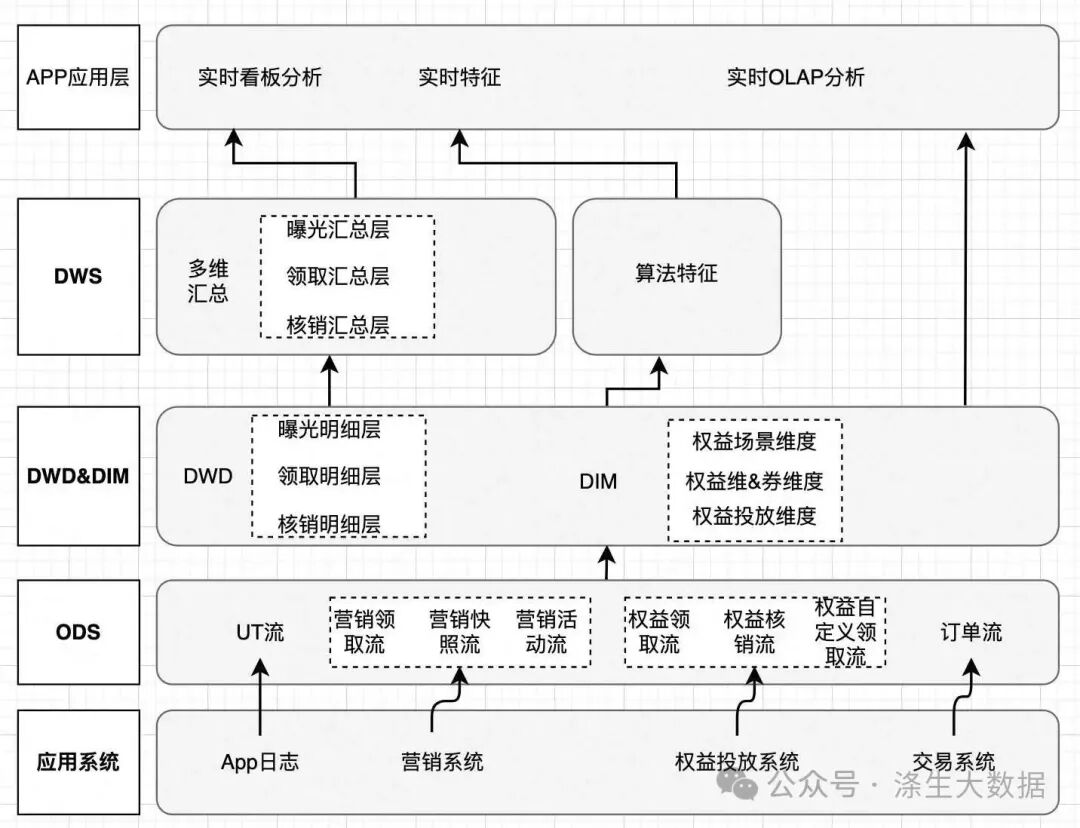
Flink CDC 的重要性:打通实时数据入湖的最后一公里
对数据的实时性要求越来越高。传统的离线数仓(T+1)已无法满足业务对秒级响应的需求,而实时数仓和数据湖(Data Lake)架构正成为主流。然而,如何将业务数据库中的变更数据(Insert/Update/Delete)低延迟、高可靠、无侵入地同步到下游系统,一直是构建实时链路的关键挑战。
CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。
又细分为基于直连查询的 CDC 和基于Binlog的 CDC。

以下是之前的mysql binlog日志处理流程,例如canal监听binlog把日志写入到kafka中。 Flink实时消费Kakfa的数据实现mysql数据的同步,整体上可以分为以下几个阶段。
-
mysql开启binlog
-
canal同步binlog数据写入到kafka
-
flink读取kakfa中的binlog数据进行相关的业务处理。
整体的处理链路较长,需要用到的组件也比较多。
Apache Flink CDC可以直接从数据库获取到binlog供下游进行业务计算分析。

也就是说数据不再通过canal与kafka进行同步,而flink直接进行处理mysql的数据。节省了canal与kafka的过程。
Flink CDC(Change Data Capture)应运而生,它基于 Apache Flink 构建,能够直接从数据库的事务日志(如 MySQL 的 binlog、Oracle 的 Redo Log)中捕获数据变更,并以流式方式输出到 Kafka、Pulsar、Iceberg、Hudi 或直接写入实时计算引擎。其核心价值体现在:
-
无侵入性:无需修改业务代码或添加触发器,仅通过读取数据库日志即可捕获变更。
-
端到端 Exactly-Once 语义:结合 Flink Checkpoint 机制,保障数据不丢不重。
-
统一处理模型:CDC 数据以流的形式进入 Flink,可无缝对接窗口计算、维表关联、状态管理等高级功能。
-
入湖桥梁:作为连接 OLTP 系统与数据湖(如 Iceberg、Delta Lake)的关键组件,实现"实时入湖"(Real-time Lakehouse)。
因此,Flink CDC 堪称是"实时数据入湖的第一公里",是构建现代实时数据架构不可或缺的一环。
Flink CDC 原理与实践
核心原理
Flink CDC 的底层依赖于 Debezium(开源 CDC 引擎),通过封装 Debezium 的 Source Connector,将其集成到 Flink 的 SourceFunction 中。其工作流程如下:
-
启动时全量快照(Snapshot)
-
切换至增量日志(Binlog/Redo Log)
-
统一事件格式输出:所有记录(包括快照和增量)都以统一的 RowData 或 JSON 格式输出,包含操作类型(INSERT/UPDATE/DELETE)、时间戳、前后镜像等信息
-
Checkpoint 保障一致性:
注:Flink CDC 2.0+ 引入了 "无锁快照" 和 "并行读取" 机制,大幅提升大表初始化性能。
接入常见数据库实践
✅ MySQL 通过 Flink 接入
编写一个 Flink CDC 应用程序,以将 MySQL 表更改推送到 Kafka Topic 中。可以使用 Flink 的 flink-connector-jdbc 库和 flink-connector-kafka 库来实现此目的。
核心代码:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test-group");
JdbcSource<RowData> source = JdbcSource.<RowData>builder()
.setDrivername("com.mysql.jdbc.Driver")
.setDBUrl("jdbc:mysql://localhost:3306/test_db")
.setUsername("flink_cdc_user")
.setPassword("password")
.setQuery("SELECT id, name, age, email FROM test_table")
.setRowTypeInfo(Types.ROW(Types.INT, Types.STRING, Types.INT, Types.STRING))
.setFetchSize(1000)
.build();
DataStream<RowData> stream = env.addSource(source);前提条件:
-
开启 binlog:binlog_format=ROW,binlog_row_image=FULL
-
用户需有 REPLICATION SLAVE, REPLICATION CLIENT, SELECT 权限
一个简单的示例运行及结果:
$ bin/flink run -c com.example.MyCDCJob ./my-cdc-job.jar --database.server=mysql.example.com --database.port=3306 --database.name=mydb --database.username=myuser --database.password=mypassword --table.name=mytable --debezium.plugin.name=mysql --debezium.plugin.property.version=1.3.1.Final可以看到,当有数据变更时,Flink CDC Job 会输出变更的表名、记录的主键以及变更的数据。例如,在这个示例中,有一行记录的年龄字段从25变成了27。
[INFO] Starting CDC process for table: mytable.
[INFO] Initializing CDC source...
[INFO] CDC source successfully initialized.
[INFO] Starting CDC source...
[INFO] CDC source successfully started.
[INFO] Adding CDC source to Flink job topology...
[INFO] CDC source successfully added to Flink job topology.
[INFO] Starting Flink job...
[INFO] Flink job started successfully.
[INFO] Change data for table: mytable.
[INFO] Record key: {"id": 1}, record value: {"id": 1, "name": "Alice", "age": 25}.
[INFO] Record key: {"id": 2}, record value: {"id": 2, "name": "Bob", "age": 30}.
[INFO] Record key: {"id": 3}, record value: {"id": 3, "name": "Charlie", "age": 35}.
[INFO] Change data for table: mytable.
[INFO] Record key: {"id": 1}, record value: {"id": 1, "name": "Alice", "age": 27}.✅ MySQL 通过 Flink SQL 接入 CDC
示例:创建 CDC 源表并写入控制台
-- 创建 MySQL CDC 源表
CREATE TABLE mysql_users (
id INT PRIMARY KEY NOT ENFORCED,
name STRING,
email STRING,
update_time TIMESTAMP(3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'flinkuser',
'password' = 'flinkpw',
'database-name' = 'test_db',
'table-name' = 'users'
);
-- 查询并输出
SELECT * FROM mysql_users;使用中的常见问题
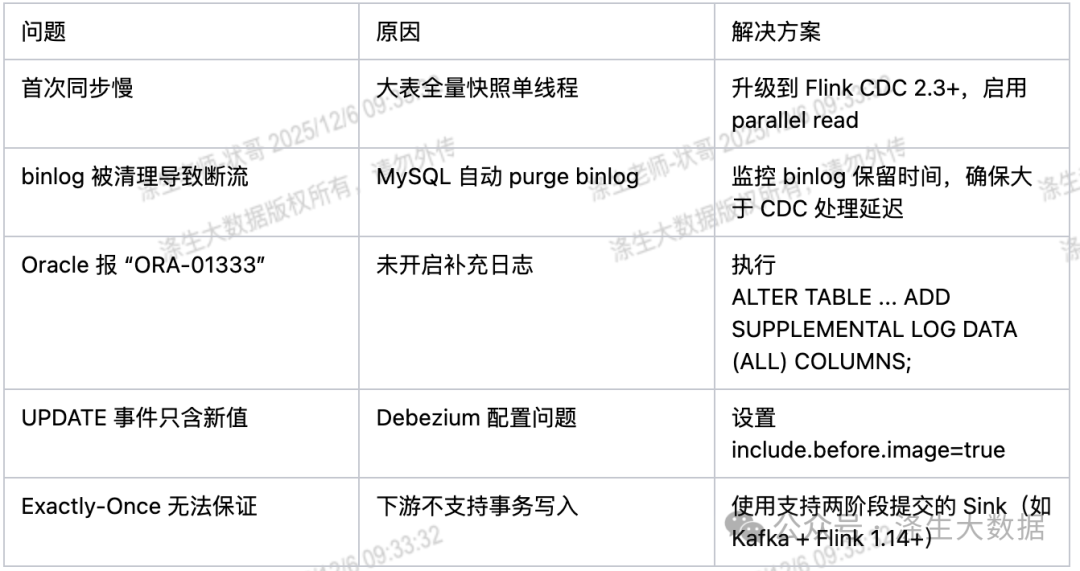
Flink CDC 高频面试题
Q1:Flink CDC 和传统 Canal / Maxwell 有什么区别?
-
集成度:Flink CDC 深度集成 Flink,可直接参与流计算;Canal/Maxwell 通常作为独立服务,需额外接入 Flink。
-
语义保障:Flink CDC 原生支持 Checkpoint 和 Exactly-Once;Canal 需自行实现位点管理。
-
全量+增量一体化:Flink CDC 自动切换快照与增量;Canal 仅支持增量。
Q2:Flink CDC 如何实现无锁快照?
Flink CDC 2.0 引入 Chunk-based Snapshot 机制:
-
将表按主键分片(chunk)
-
每个 chunk 独立读取,并记录高低水位
-
读取过程中允许并发写入,通过 binlog 补偿中间变更
-
最终合并快照与增量,保证一致性
Q3:如何处理 DDL 变更(如加列)?
-
当前限制:Flink CDC 默认不支持动态 DDL 同步(会报错或忽略)
-
解决方案:
-
手动重启作业(适用于低频变更)
-
使用 Schema Registry + 动态反序列化(如 Avro)
-
结合 Flink 1.17+ 的 Dynamic Table Options 实现 schema evolution(实验性)
-
Q4:Flink CDC 能否捕获 DELETE 操作?
可以。DELETE 事件会以 op='d' 形式输出,并包含删除前的完整行数据(前提是数据库日志包含 before image,如 MySQL ROW 格式)。
Q5:如何优化大表 CDC 的性能?
-
升级到 Flink CDC 2.3+,启用 parallelism 参数
-
增加 source 并行度(需主键分布均匀)
-
调整 checkpoint 间隔(避免过频繁影响吞吐)
结语
Flink CDC 正在成为实时数据管道的事实标准。它不仅简化了从数据库到数据湖的同步链路,还为实时分析、实时风控、实时推荐等场景提供了高质量的数据源。随着 Flink 社区对 CDC 的持续投入(如支持更多数据库、增强 schema evolution、提升性能),其在实时数仓架构中的地位将愈发不可替代。
建议学习和实践路径:从 MySQL CDC 入手 → 接入 Kafka → 写入 Iceberg/Hudi /Paimon→ 构建端到端实时入湖 pipeline。