基于pca的人脸识别
引言:pca
1.pca是什么
pca是一种统计方法,它可以通过正交变换将一组可能相关的变量转换成一组线性不相关的变量,这组新的变量被称为主成分。PCA常用于高维数据的降维,通过保留最重要的几个主成分来简化数据集,同时尽可能保留原始数据的信息。
2.PCA算法的基本步骤
- 数据标准化:对原始数据进行预处理,使得每个特征的均值为0,标准差为1。这一步是为了消除不同量纲对数据分析的影响。
- 构建协方差矩阵:计算数据的协方差矩阵,协方差矩阵能够反映不同特征之间的相关性。
- 计算协方差矩阵的特征值和特征向量:特征值和特征向量能够揭示数据的内在结构。特征值越大,对应的特征向量在数据集中的重要性越高。
- 选择主成分:根据特征值的大小,选择前k个最大的特征值对应的特征向量作为主成分。通常会选择累计贡献率达到一定比例(如85%)的特征向量。
- 形成特征向量矩阵:将选定的特征向量组成一个矩阵,这个矩阵将用于将原始数据转换到新的特征空间。
- 数据转换:使用特征向量矩阵将原始数据转换到新的特征空间,得到降维后的数据。
实例:人脸识别
1.实验目的
- 理解PCA原理:通过实践掌握主成分分析(PCA)算法的核心思想及其在降维中的应用
- 应用PCA处理图像数据:学习如何将PCA应用于高维图像数据,特别是人脸识别领域
- 探索特征提取:了解PCA如何提取图像的主要特征(特征脸)及其在人脸表示中的作用
- 评估降维效果:通过图像重建实验,直观理解不同数量主成分对图像质量的影响
2.实现步骤
- 数据准备
• 加载ORL人脸数据集(包含40个人的400张人脸图像)
• 将每张112×92像素的灰度图像转换为10304维的向量
• 构建数据矩阵(每行代表一张图像) - 数据预处理
• 计算并减去平均脸(数据集中所有图像的平均)
• 中心化数据(使数据均值为0) - PCA分析
• 使用sklearn的PCA进行主成分分析
• 提取前50个主成分
• 可视化前5个特征脸(主成分) - 方差分析
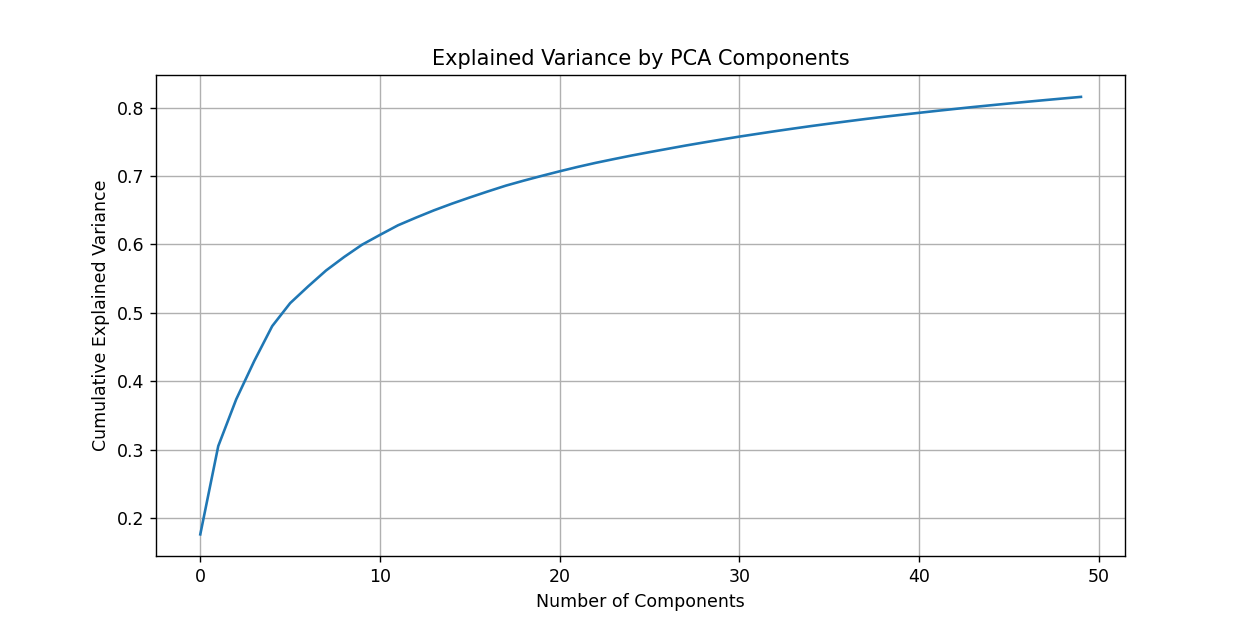
• 绘制累计解释方差图
• 观察不同数量主成分对数据方差的解释程度 - 图像重建
• 选择样本图像进行重建
• 分别使用10、30、50个主成分重建图像
• 对比重建图像与原始图像的质量差异 - 结果分析
• 观察特征脸的特点
• 分析主成分数量对重建质量的影响
• 评估PCA在图像压缩和特征提取中的效果
3.代码实现
python
import os
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 1. 加载ORL人脸数据集
def load_orl_faces(data_path, num_persons=40, num_images=10, img_size=(112, 92)):
"""
加载ORL人脸数据集
参数:
data_path: 数据集路径
num_persons: 人数(默认40)
num_images: 每人图像数(默认10)
img_size: 图像尺寸(默认112×92)
返回:
X: 图像矩阵(每行一个图像)
image_shape: 图像原始形状
"""
total_images = num_persons * num_images
X = np.zeros((total_images, img_size[0] * img_size[1]))
image_count = 0
for person in range(1, num_persons + 1):
person_dir = os.path.join(data_path, f's{person}')
for img_num in range(1, num_images + 1):
img_path = os.path.join(person_dir, f'{img_num}.pgm')
if os.path.exists(img_path):
try:
img = Image.open(img_path).convert('L')
img_array = np.array(img).flatten()
X[image_count] = img_array
image_count += 1
except Exception as e:
print(f"处理文件 {img_path} 时出错: {str(e)}")
else:
print(f"警告: 未找到文件 {img_path}")
# 只保留成功加载的图像
X = X[:image_count]
return X, img_size
# 2. PCA降维与可视化
def pca_analysis(X, image_shape, n_components=50):
"""
PCA分析与人脸重建
参数:
X: 图像矩阵
image_shape: 图像原始形状
n_components: 保留的主成分数量
"""
# 数据标准化
mean_face = np.mean(X, axis=0)
X_centered = X - mean_face
# 使用sklearn的PCA
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X_centered)
# 可视化前几个特征脸
plt.figure(figsize=(15, 5))
for i in range(5):
eigenface = pca.components_[i].reshape(image_shape)
plt.subplot(1, 5, i+1)
plt.imshow(eigenface, cmap='gray')
plt.title(f'Eigenface {i+1}')
plt.axis('off')
plt.suptitle('Top 5 Eigenfaces')
plt.show()
# 显示方差解释率
plt.figure(figsize=(10, 5))
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('Number of Components')
plt.ylabel('Cumulative Explained Variance')
plt.title('Explained Variance by PCA Components')
plt.grid()
plt.show()
return pca, mean_face, X_pca
# 3. 图像重建与对比
def reconstruct_and_compare(pca, mean_face, X_pca, image_shape, sample_indices=[0, 10, 20]):
"""
重建图像并与原始图像对比
参数:
pca: PCA模型
mean_face: 平均脸
X_pca: PCA降维后的数据
image_shape: 图像形状
sample_indices: 要显示的样本索引
"""
plt.figure(figsize=(15, 5 * len(sample_indices)))
for i, idx in enumerate(sample_indices):
# 原始图像
original_img = mean_face + X_pca[idx] @ pca.components_
# 使用不同数量的主成分重建
plt.subplot(len(sample_indices), 4, i*4 + 1)
plt.imshow(original_img.reshape(image_shape), cmap='gray')
plt.title(f'Original Image {idx}')
plt.axis('off')
for j, n in enumerate([10, 30, 50]):
# 使用前n个主成分重建
reconstructed = mean_face + X_pca[idx, :n] @ pca.components_[:n]
plt.subplot(len(sample_indices), 4, i*4 + j + 2)
plt.imshow(reconstructed.reshape(image_shape), cmap='gray')
plt.title(f'{n} Components')
plt.axis('off')
plt.suptitle('Image Reconstruction with Different Numbers of PCA Components')
plt.tight_layout()
plt.show()
# 主程序
def main():
# 数据集路径 - 替换为你的实际路径
dataset_path = r'C:\Users\62755\Downloads\ORL_Faces'
# 1. 加载数据
X, image_shape = load_orl_faces(dataset_path)
print(f"成功加载 {X.shape[0]} 张人脸图像,每张图像维度 {X.shape[1]}")
# 2. PCA分析
pca, mean_face, X_pca = pca_analysis(X, image_shape, n_components=50)
# 3. 重建与对比
reconstruct_and_compare(pca, mean_face, X_pca, image_shape)
if __name__ == "__main__":
main()4.实验结果
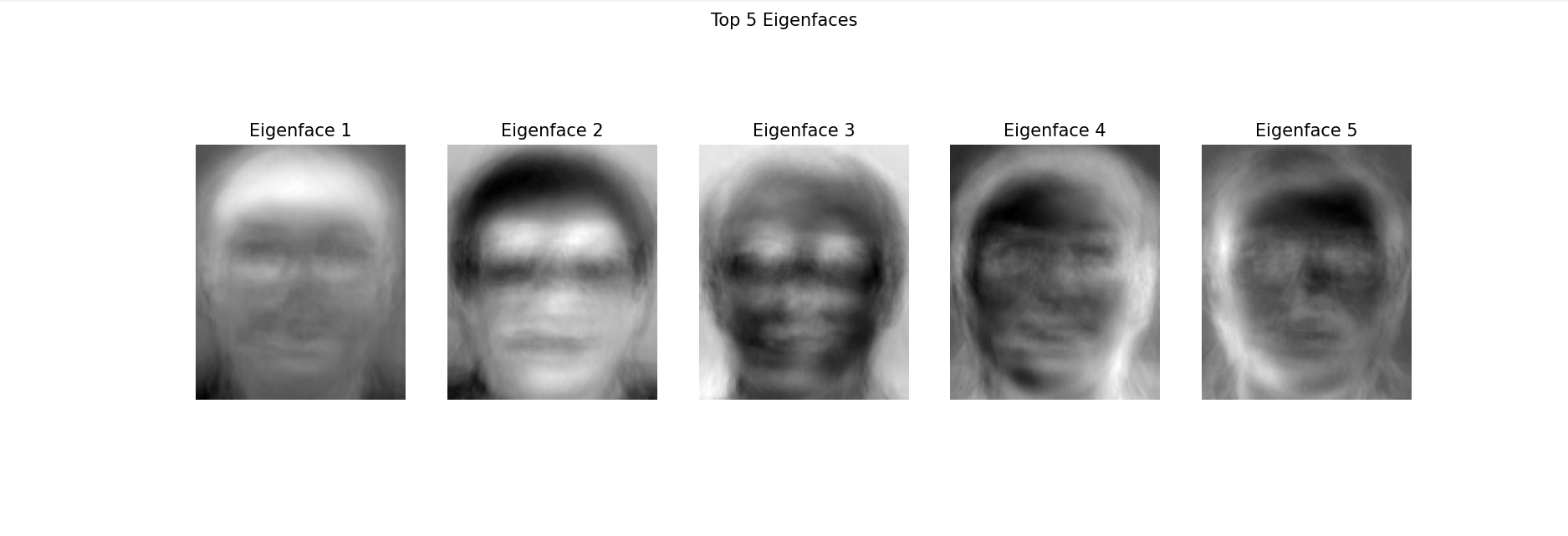
图像重建对比图:

累计解释方差图:
5.实验总结
通过本次基于PCA的人脸识别实验,我深入理解了主成分分析的核心原理及其在实际问题中的应用价值。实验过程中,我不仅掌握了如何将高维图像数据转化为适合PCA处理的矩阵形式,还学会了数据标准化和中心化的预处理方法。通过可视化特征脸,我直观认识到PCA如何自动提取数据的主要变化模式,这些特征脸实际上构成了人脸图像的基础成分。