一、缓存加载策略:按需加载与数据库兜底
1. 缓存 Key 设计
java
// 以业务类型+分类ID构建唯一Key(示例:菜品分类ID)
String redisKey = "dish_" + categoryId;- 设计原则 :
- 采用
业务类型_关联ID格式(如dish_1表示分类 ID 为 1 的菜品缓存) - 避免使用模糊 Key(如
dish_*)导致缓存穿透,精确命中目标数据
- 采用
2. 缓存查询逻辑
java
// 优先从Redis获取数据
List<DishVO> cacheData = (List<DishVO>) redisTemplate.opsForValue().get(redisKey);
if (cacheData != null && !cacheData.isEmpty()) {
return Result.success(cacheData); // 命中缓存,直接返回
}- 核心优势 :
- 减少数据库查询压力,提升响应速度(Redis 内存读写速度约为 MySQL 的 1000 倍)
- 适用于读多写少场景(如菜品查询、字典数据)
3. 数据库兜底机制
java
// 缓存未命中时,从数据库查询并加载到缓存
Dish dish = new Dish();
dish.setCategoryId(categoryId);
dish.setStatus(StatusConstant.ENABLE); // 仅查询起售菜品
List<DishVO> dbData = dishService.listWithFlavor(dish);
redisTemplate.opsForValue().set(redisKey, dbData, 30, TimeUnit.MINUTES); // 设置缓存过期时间完整代码
java
//构造redis的KEY
String RedisKey="dish_"+categoryId;
//查询redis内是否有数据
List<DishVO> list= (List<DishVO>) redisTemplate.opsForValue().get(RedisKey);
//缓存中有数据 直接返回即可
if(list!=null && list.size()>0){
return Result.success(list);
}
/**
* 当数据库中发生变化时,就要清理缓存,避免缓存与数据库中的数据不一致
* 当数据库中发生新增、修改、删除、起售,停售的操作时,就要清理缓存
*/
//redis没有数据 从数据库中查询后,加载到redis内
Dish dish = new Dish();
dish.setCategoryId(categoryId);
dish.setStatus(StatusConstant.ENABLE);//查询起售中的菜品
list = dishService.listWithFlavor(dish);
//加载到缓存内(redis)
redisTemplate.opsForValue().set(RedisKey,list);
return Result.success(list);二、缓存一致性维护:数据变更时主动清理缓存
1. 新增数据场景
java
@PostMapping
public Result addDish(@RequestBody DishDTO dishDTO) {
dishService.addDish(dishDTO);
// 新增数据后,删除对应分类的缓存
String key = "dish_" + dishDTO.getCategoryId();
redisTemplate.delete(key);
return Result.success();
}- 逻辑说明 :
新增菜品属于分类数据变更,删除对应分类的缓存(如dish_1),下次查询时自动重新加载最新数据
2. 修改数据场景
java
@PutMapping
public Result modifDish(@RequestBody DishDTO dishDTO) {
dishService.modifDish(dishDTO);
// 修改数据后,删除关联分类的缓存(支持跨分类场景优化)
DeleteDishReids(RedisConstant.ALLDISH_); // 临时方案:先全量清理(待优化为精准删除)
return Result.success();
}- 当前局限与优化方向 :
- 现状 :直接删除所有菜品缓存(
dish_*),适用于简单场景 - 优化 :若修改涉及分类变更,需同时删除原分类和新分类的缓存(如
dish_oldCategoryId和dish_newCategoryId)
- 现状 :直接删除所有菜品缓存(
3. 状态变更场景(启售 / 停售)
java
@PostMapping("status/{status}")
public Result dishHalt(@PathVariable Integer status, Long id) {
dishService.updatedish(status, id);
// 状态变更影响数据有效性,删除所有菜品缓存
DeleteDishReids(RedisConstant.ALLDISH_);
return Result.success();
}- 业务逻辑 :
菜品状态(如停售)变更后,所有相关缓存数据需失效,确保前端获取到最新可用菜品列表
4. 批量删除场景
java
@DeleteMapping
public Result deleDish(@RequestParam List<Long> ids) {
dishService.deleteDish(ids);
// 批量删除时无法精准定位分类,临时全量清理缓存
DeleteDishReids(RedisConstant.ALLDISH_);
// 优化方向:统计删除菜品的分类ID,精准删除对应缓存(如通过SQL查询分类ID列表)
return Result.success();
}优化思路 :
通过数据库查询批量删除菜品的分类 ID 集合,避免全量清理:
java
// 伪代码:从数据库获取删除菜品的分类ID列表
List<Long> categoryIds = dishMapper.getCategoriesByDishIds(ids);
categoryIds.forEach(categoryId -> redisTemplate.delete("dish_" + categoryId));三、缓存清理工具方法:批量删除与 Key 模式匹配
java
private void DeleteDishReids(String keyPrefix) {
// 使用Redis Key模式匹配(如 dish_*)获取所有相关Key
Set<String> keys = redisTemplate.keys(keyPrefix + "*");
if (!keys.isEmpty()) {
redisTemplate.delete(keys); // 批量删除,减少Redis交互次数
}
}- 技术要点 :
- 使用
redisTemplate.keys("prefix*")按前缀模糊匹配 Key - 批量删除(
delete(Set))比单个删除更高效,减少网络 IO 消耗
- 使用
四、缓存策略总结与优化方向
1. 当前策略优势
- 读写分离:读请求优先走缓存,写请求更新数据库后清理缓存,适用于高并发读场景
- 简单可靠:基于同步清理策略(写操作后立即删缓存),避免异步延迟导致的不一致
| 场景 | 现有方案缺陷 | 优化方向 |
|---|---|---|
| 跨分类修改 | 全量清理缓存 | 解析修改后的分类 ID,精准删除对应缓存(需业务层传递新旧分类 ID) |
| 批量删除 | 无法定位具体分类 | 通过数据库查询删除菜品的分类 ID 列表,实现精准删除 |
| 缓存穿透 | 未处理无效 Key 请求 | 添加布隆过滤器(Bloom Filter),提前拦截无效 Key 的查询 |
| 缓存雪崩 | 无过期时间错峰机制 | 为不同 Key 设置随机过期时间(如 30~60 分钟),避免集中失效 |
最佳实践建议
- 敏感数据不缓存:涉及用户隐私或高频变动的数据(如订单状态)不建议缓存
- 监控与告警:通过 Redis 监控工具(如 RedisInsight)实时监测缓存命中率、内存占用等指标
- 灰度发布:新缓存策略上线时,先在测试环境验证一致性和性能影响
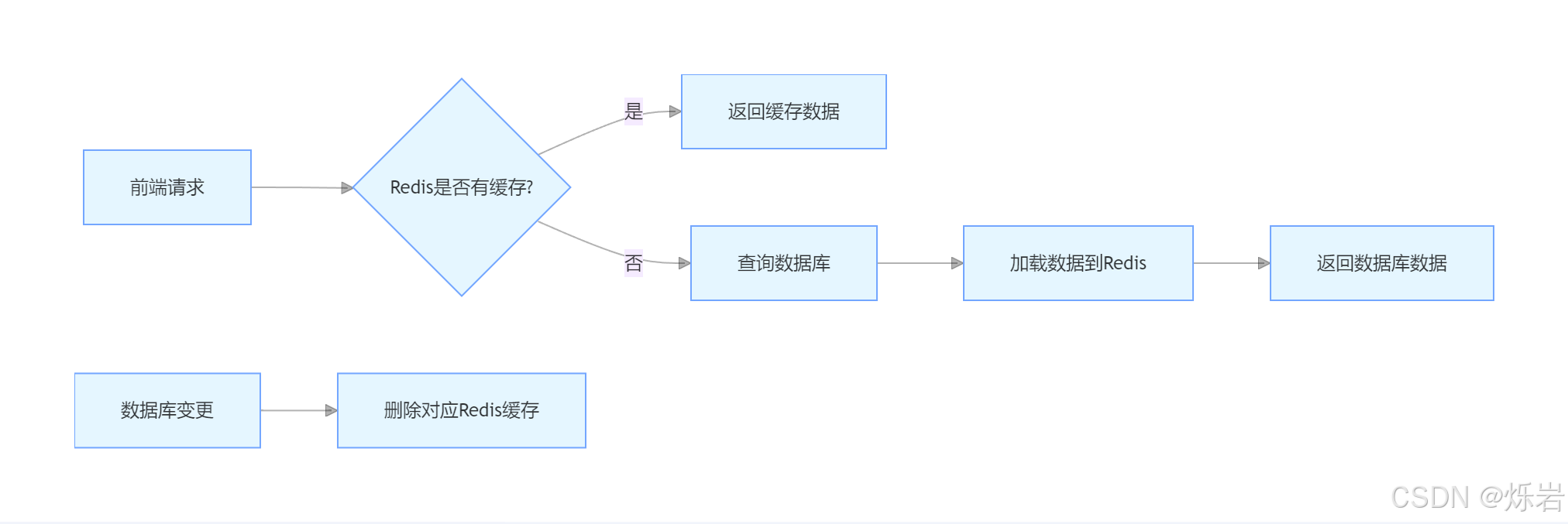
通过上述策略,可在保证数据一致性的前提下,显著提升系统读性能,尤其适用于电商、餐饮等菜品查询频繁的业务场景。