我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。
c
@Query("SELECT NEW com.example.qihuangserver.dto.question.QuestionBankDTO(q.id, q.question, q.options) " +
"FROM QuestionBank q " +
"WHERE q.id IN :ids")
List<QuestionBankDTO> findByIds(List<Integer> ids);原顺序是杂乱无章的,符合出题的随机性:
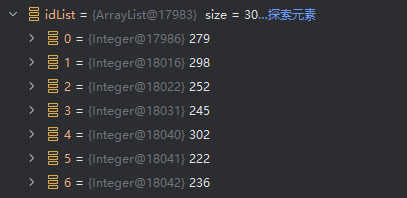
但是查完之后变成了顺序排列:
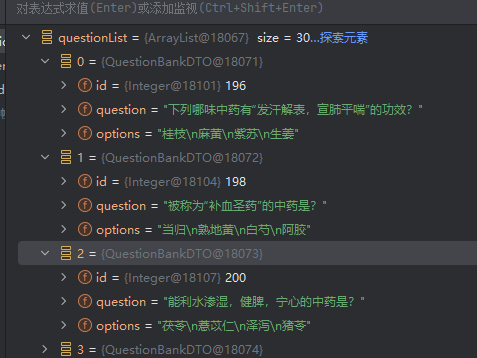
常见原因分析
- IN子句不保证顺序 :
- SQL中的
IN操作符不保证返回结果的顺序与传入ID的顺序一致 - 数据库会按照自己的优化方式返回结果
- SQL中的
- Hibernate/JPA处理问题 :
- 即使你传入了有序列表,Hibernate/JPA可能会重新组织查询
- DTO构造函数问题 :
- 如果DTO构造函数参数顺序与SELECT子句不匹配
解决方案
方案1:手动排序(推荐)
@Query("SELECT NEW com.example.qihuangserver.dto.question.QuestionBankDTO(q.id, q.question, q.options) " +
"FROM QuestionBank q " +
"WHERE q.id IN :ids")
List<QuestionBankDTO> findByIds(@Param("ids") List<Integer> ids);
// 调用时手动排序
public List<QuestionBankDTO> getQuestionsInOrder(List<Integer> ids) {
List<QuestionBankDTO> result = repository.findByIds(ids);
// 创建ID到DTO的映射
Map<Integer, QuestionBankDTO> idToDto = result.stream()
.collect(Collectors.toMap(QuestionBankDTO::getId, Function.identity()));
// 按照原始ID顺序重建列表
return ids.stream()
.map(idToDto::get)
.filter(Objects::nonNull)
.collect(Collectors.toList());
}方案2:使用ORDER BY FIELD(MySQL)
如果是MySQL数据库:
@Query(value = "SELECT NEW com.example.qihuangserver.dto.question.QuestionBankDTO(q.id, q.question, q.options) " +
"FROM QuestionBank q " +
"WHERE q.id IN :ids " +
"ORDER BY FIELD(q.id, :ids)", nativeQuery = true)
List<QuestionBankDTO> findByIdsInOrder(@Param("ids") List<Integer> ids);方案3:使用JPQL CASE表达式(跨数据库)
@Query("SELECT NEW com.example.qihuangserver.dto.question.QuestionBankDTO(q.id, q.question, q.options) " +
"FROM QuestionBank q " +
"WHERE q.id IN :ids " +
"ORDER BY CASE " +
"WHEN q.id = ?1 THEN 1 " +
"WHEN q.id = ?2 THEN 2 " +
// 继续添加更多WHEN条件...
"ELSE 999 END")
List<QuestionBankDTO> findByIdsInOrder(@Param("ids") List<Integer> ids);方案4:使用Spring Data JPA的@OrderBy
public interface QuestionBankRepository extends JpaRepository<QuestionBank, Integer> {
@Query("SELECT q FROM QuestionBank q WHERE q.id IN :ids")
@OrderBy("id ASC") // 但这只能按字段排序,不能按指定顺序
List<QuestionBank> findByIds(@Param("ids") List<Integer> ids);
}最佳实践建议
-
始终在应用层处理排序:
// 服务层方法 public List<QuestionBankDTO> getQuestionsInOrder(List<Integer> orderedIds) { List<QuestionBankDTO> unsorted = repository.findByIds(orderedIds); Map<Integer, QuestionBankDTO> map = unsorted.stream() .collect(Collectors.toMap(QuestionBankDTO::getId, Function.identity())); return orderedIds.stream() .map(map::get) .filter(Objects::nonNull) .collect(Collectors.toList()); } -
添加日志验证:
log.info("Requested IDs order: {}", ids); List<QuestionBankDTO> result = repository.findByIds(ids); log.info("Returned IDs order: {}", result.stream().map(QuestionBankDTO::getId).collect(Collectors.toList())); -
考虑使用批量查询+内存排序:
- 如果列表不大,可以先查询全部再在内存中排序
为什么原有方案不工作
观察到的现象正是因为IN子句不保持顺序。例如:
- 你传入ID顺序:279, 298, 252
- 数据库可能返回:252, 279, 298(按ID升序)
- 或完全不同的顺序(取决于执行计划)
性能考虑
如果ID列表很大:
- 方案1(内存排序)最通用但需要两次遍历
- 数据库特定方案(如MySQL的FIELD)性能更好
- 考虑分页查询避免大结果集
通过以上方法,可以确保返回的题目顺序与传入的ID列表顺序完全一致。