开篇:为什么你的 SQL Agent 总是在关键时刻"掉链子"?
你有没有遇到过这样的场景:辛辛苦苦搭了个 SQL Agent,满心欢喜地测试"研发部的平均薪资是多少?",结果它自信满满地返回了一个错误答案,或者干脆报错罢工?
更让人崩溃的是,当你想要debug的时候,发现整个流程就像个"黑盒"------你只知道输入和输出,但中间到底发生了什么,LLM 是怎么想的,为什么会选错表,为什么生成的 SQL 有语法错误,完全无从知晓。
今天我们就来解决这个问题。我们会搭建一个具备自我诊断能力的 SQL Agent ,让它不仅能工作,还能在出现问题时告诉我们为什么,就像给 AI 装上了"X 光片"。
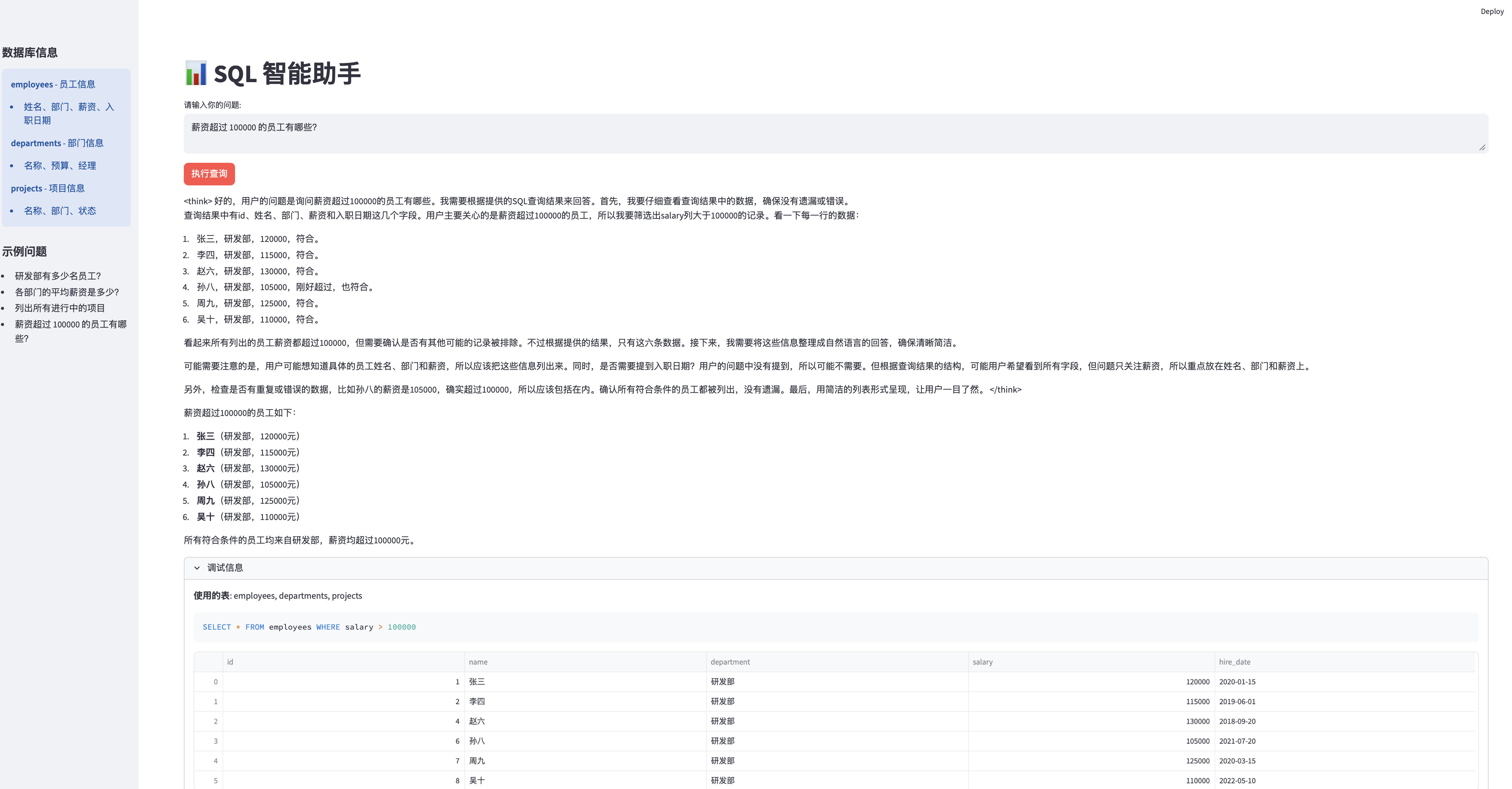
系统界面展示
问答界面
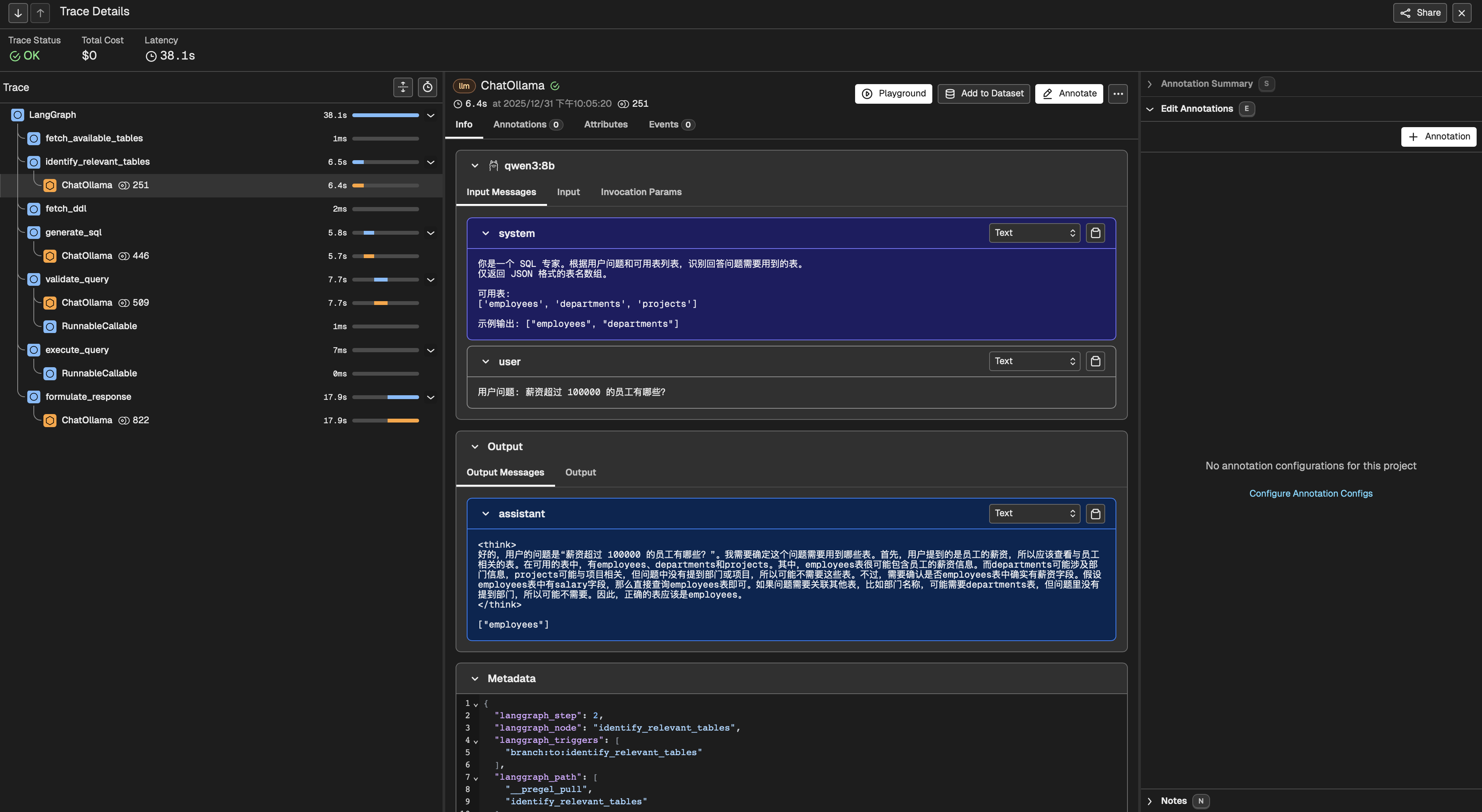
Arize Phoenix观测界面
第一章:系统架构------为什么选择 LangGraph 而不是简单的 Chain?
1.1 从"单行道"到"立交桥":架构思维转变
想象一下,如果你的 SQL Agent 是一辆车,传统的 Chain 模式就像单行道------一旦走错了路,就得重新开始。而 LangGraph 给我们提供了"立交桥"系统,可以根据不同情况选择不同的路线。
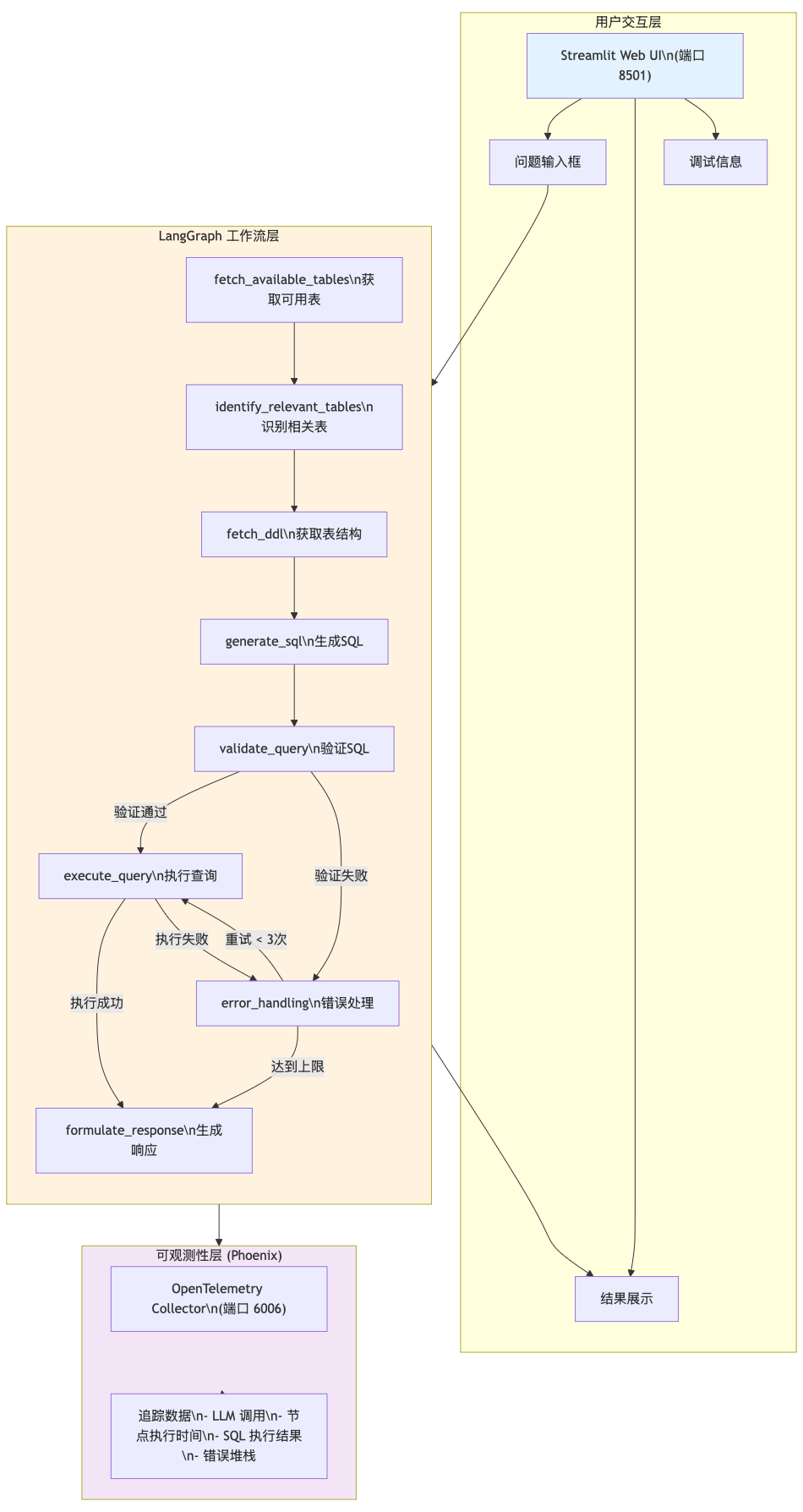
这个架构图告诉我们三个核心思想:
- 分层设计:像搭积木一样,每个节点职责单一
- 状态驱动:数据在节点间流动,就像血液在血管里循环
- 循环纠错:出错不可怕,可怕的是不知道错在哪里
1.2 技术栈的深层考量
| 组件 | 技术选型 | 为什么要选它? |
|---|---|---|
| 前端界面 | Streamlit | 就像给专家配了个助手,能快速看到结果和调试信息 |
| 工作流编排 | LangGraph 1.0 | 不只是执行流程,更是状态管理和错误处理的核心 |
| LLM 框架 | LangChain | 统一的接口,可以轻松切换 OpenAI/Ollama |
| 数据库 | SQLite | 轻量级,适合演示,生产环境可替换为 PostgreSQL/MySQL |
| 可观测性 | Arize Phoenix + OpenTelemetry | 标准化的监控方案,未来可以无缝迁移 |
第二章:8 个节点的深度拆解------Agent 是如何"思考"的?
2.1 状态定义:给 Agent 装上"记忆芯片"
想象一下,如果人类没有记忆,每次对话都得从零开始,那该有多可怕?SQL Agent 也是一样,我们需要给它装上"记忆芯片"。
python
class SQLAgentState(TypedDict):
"""SQL Agent 工作流状态------Agent 的记忆芯片"""
# 用户输入
question: str
# 数据库信息
available_tables: list[str] # 有哪些表可用
relevant_tables: list[str] # 哪些表与当前问题相关
table_schemas: dict[str, str] # 表的详细结构信息
# 查询生成过程
generated_sql: str # 第一次生成的 SQL
validated_sql: str # 验证/修正后的 SQL
# 执行结果
query_result: Any # 查询结果
query_error: str | None # 错误信息
retry_count: int # 重试次数,防止无限循环
# 最终响应
response: str # 给用户的最终回答这个状态就像 Agent 的"短期记忆",它记录了从问题输入到结果输出的整个思考过程。
2.2 工作流程图
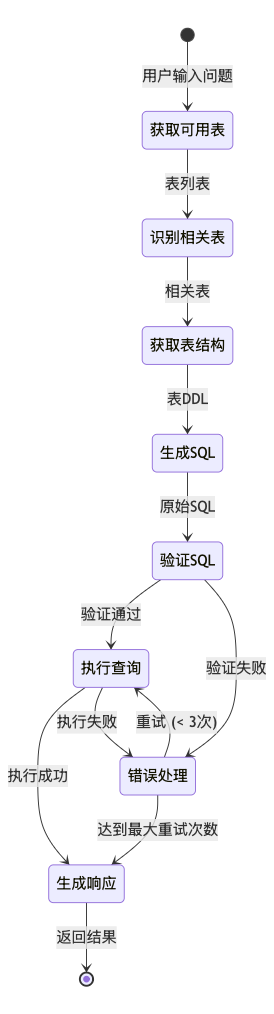
2.3 节点的"专业分工"
第一阶段:信息检索与上下文压缩(节点 1-3)
这就像是一个"过滤器",先把海量信息筛选出最相关的部分。
节点 1:获取可用表列表
python
def fetch_available_tables(state):
"""从数据库获取所有可用表------看看家里有什么菜"""
db = DatabaseManager(state.get("database_path"))
return {"available_tables": list(db.get_all_schemas().keys())}节点 2:智能识别相关表
python
def identify_relevant_tables(state):
"""根据问题识别需要哪些表------点菜环节"""
llm = create_llm()
prompt = """数据库中有这些表:{available_tables}
用户要问:{question}
请只返回相关的表名列表,用 JSON 格式。"""
# LLM 会告诉我们需要哪些表
return {"relevant_tables": relevant_tables}节点 3:获取详细表结构
python
def fetch_ddl(state):
"""获取选中表的 DDL------看菜谱"""
db = DatabaseManager(state.get("database_path"))
all_schemas = db.get_all_schemas()
table_schemas = {t: all_schemas[t] for t in state["relevant_tables"]}
return {"table_schemas": table_schemas}第二阶段:生成与预校验(节点 4-5)
这是 Agent 的"创作"阶段,我们引入双保险机制。
节点 4:生成 SQL
python
def generate_sql(state):
"""根据问题和表结构生成 SQL------炒菜环节"""
system_prompt = """你是 SQLite 专家。严格按照以下规则:
1. 只返回 SQL 语句,不要任何解释
2. 不要使用 markdown 代码块
3. 只能使用表中明确存在的字段名"""
response = llm.invoke([SystemMessage(content=system_prompt),
HumanMessage(content=state["question"])])
# 清洗 SQL(移除 LLM 的思考标签等噪声)
sql = sanitize_sql(response.content)
return {"generated_sql": sql}节点 5:验证 SQL
python
def validate_query(state):
"""验证生成的 SQL------试吃环节"""
prompt = """请检查以下 SQLite 查询是否有错误:
1. 是否引用了不存在的列?
2. JOIN 条件是否正确?
3. 语法是否正确?
如果完全正确,请回复 'VALID'。
如果有误,请直接返回修正后的 SQL。"""
response = llm.invoke([...])
result = sanitize_sql(response.content)
if result == "VALID":
return {"validated_sql": state["generated_sql"]}
else:
return {"validated_sql": result} # 返回修正后的 SQL第三阶段:执行与闭环纠错(节点 6-7)
这是 Agent 具备"生命力"的关键环节。
节点 6:执行查询
python
def execute_query(state):
"""执行验证后的 SQL 查询------上菜环节"""
db = DatabaseManager(state.get("database_path"))
success, result = db.execute_query(state["validated_sql"])
if success:
return {"query_result": result}
else:
# 执行失败,增加重试计数,进入错误处理
return {"query_error": result,
"retry_count": state.get("retry_count", 0) + 1}节点 7:错误处理与重试
python
def error_handling(state):
"""处理查询执行错误------发现问题并改进"""
if state.get("retry_count", 0) >= 3:
# 达到最大重试次数,返回错误响应
return {"response": f"尝试多次后仍无法执行查询。错误: {state['query_error']}"}
# 使用 LLM 根据错误信息修正 SQL
prompt = f"""以下 SQL 执行失败:
SQL: {state['validated_sql']}
错误: {state['query_error']}
请仔细检查表结构:{state['table_schemas']}
修正后重新输出 SQL。"""
response = llm.invoke([...])
corrected_sql = sanitize_sql(response.content)
return {"validated_sql": corrected_sql, "query_error": None}第四阶段:语义化响应(节点 8)
节点 8:生成自然语言回答
python
def form_response(state):
"""将查询结果转化为自然语言------服务员解释菜品"""
if state.get("query_error"):
return {"response": f"抱歉,无法回答。错误: {state['query_error']}"}
# 格式化查询结果
df = pd.DataFrame(state["query_result"]["rows"],
columns=state["query_result"]["columns"])
prompt = """根据用户问题和 SQL 查询结果,提供清晰回答。
问题: {state['question']}
结果: {df.to_string(index=False)}"""
response = llm.invoke([SystemMessage(content=prompt)])
return {"response": response.content}第三章:可观测性实战------让 AI 的每一步都有迹可循
3.1 为什么传统的日志不够用?
想象一下,你去医院看病,医生只告诉你"你有病",但不告诉你哪里不舒服、为什么不舒服、该怎么治疗,你会有什么感受?
传统的日志就像是这个"不负责任的医生",它只告诉你"出错了",但不会告诉你:
- 当时发送给 LLM 的具体提示词是什么?
- LLM 到底是怎么理解的?
- 哪个环节最耗时?
- Token 消耗情况如何?
3.2 Phoenix 的集成艺术
只需几行代码,就能给你的 Agent 装上"X 光机":
python
# 在应用启动时初始化
try:
from phoenix.otel import register
# 注册 OpenTelemetry 追踪
tracer_provider = register(
project_name="sql-agent-phoenix", # 项目名称
endpoint=f"http://127.0.0.1:6006/v1/traces",
auto_instrument=True, # 自动插桩 LangChain/LangGraph
batch=False, # 开发环境立即发送
)
except Exception as e:
logger.warning(f"初始化 Phoenix 失败: {e}")3.3 追踪原理图解
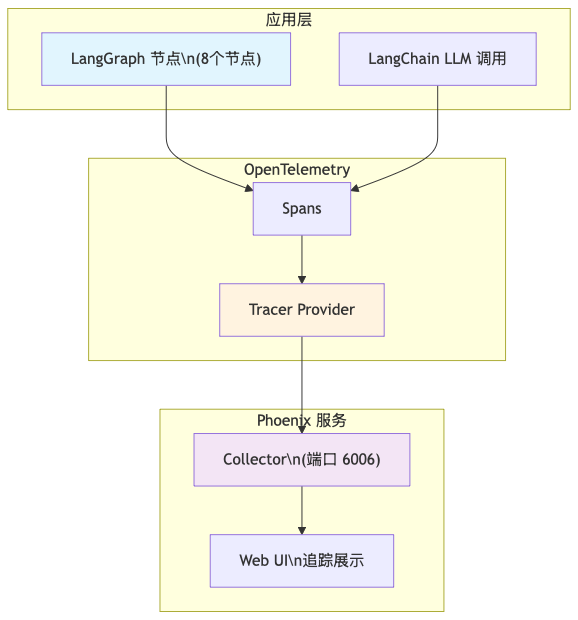
3.4 使用 Phoenix 诊断问题
| 问题场景 | 查看内容 |
|---|---|
| SQL 生成错误 | generate_sql span → LLM 输入输出 |
| SQL 执行失败 | execute_query span → 错误堆栈 |
| LLM 响应异常 | 对应节点 span → 完整对话历史 |
| 性能问题 | 各 span 执行时间 → 找出瓶颈 |
第四章:Prompt 优化实战------如何约束 LLM 的"想象力"?
4.1 识别节点:防止"信息过载"
在 identify_relevant_tables 节点中,我们要防止 LLM 被太多表名搞混。
优化策略:JSON 强约束
你是一个专业的数据库管理员。
数据库表名:{available_tables}
用户问题:{question}
任务:
1. 仅识别回答问题必需的表名
2. 如果无法回答,返回空数组
3. 严格要求:只返回 JSON 数组,不要任何解释4.2 生成节点:Schema 锚定与方言适配
在 generate_sql 中,我们要给 LLM 明确的"菜谱"。
优化策略:SQLite 专家模式
你是 SQLite 专家。请根据以下表结构生成查询:
{table_schemas}
规则:
* 使用 LIMIT 限制结果条数
* 优先使用显式 JOIN 语法
* 处理日期使用 SQLite 的 date() 函数
* 仅输出 SQL 语句4.3 验证节点:引入"批判性思维"
validate_query 要扮演"挑刺的审查员"。
优化策略:代码审查专家
你是代码审查专家。请检查以下 SQL:
1. 是否引用了不存在的列?
2. JOIN 条件是否可能导致笛卡尔积?
3. 是否存在语法错误?
如果完全正确,回复 'VALID'
如果有误,直接返回修正后的 SQL4.4 纠错节点:基于反馈的修复
当 SQL 执行失败时,error_handling 要善于"知错就改"。
优化策略:错误溯源
你生成的 SQL 执行失败了:
SQL: {validated_sql}
错误: {query_error}
请分析报错原因,并重新生成修正后的 SQL。
注意:只能使用表中明确存在的字段名。第五章:实战演练------一次完整的"破案"过程
场景重现:Agent 返回了错误答案
用户问:"Engineering 部门的平均薪资是多少?"但程序返回了错误。
第一步:在 Phoenix 中观察"案发现场"
- 定位红色节点 :发现
execute_query节点的 Span 状态为 Error - 查看报错详情 :数据库错误
no such column: salary - 检查生成的 SQL :看到
SELECT AVG(salary) FROM employees WHERE department_id = 1;
第二步:溯源分析------为什么 LLM 会写错?
- 向上追溯 :点击
fetch_ddl的 Span - 查看输入上下文 :发现真实 DDL 是
CREATE TABLE employees (id INTEGER, name TEXT, pay_rate REAL, ...) - 发现病灶 :数据库里真实的列名是
pay_rate,而 LLM 幻觉出了salary
第三步:针对性优化------给 Agent 穿上"防弹衣"
1. 优化 generate_sql 的 Prompt
警告:只能使用 DDL 中明确列出的字段名。
严禁使用 salary、emp_id 等猜测性的名称。
如果不确定,请重新检查表结构。2. 增强 error_handling 的反馈能力
python
def error_handling(state):
correction_prompt = f"""
你生成的 SQL 执行失败了:{state['validated_sql']}
报错信息:{state['query_error']}
请仔细核对表结构:{state['table_schemas']}
注意:报错提示列名不存在,说明你写错了字段名。
"""
# 再次调用 LLM 进行修正第四步:验证闭环------观察"康复过程"
- 第一次尝试 :LLM 可能还是写了
salary - 触发循环 :
execute_query报错 -> 进入error_handling - 自我修复 :第二次
execute_query中,SQL 变成了SELECT AVG(pay_rate) FROM employees ... - 成功标志 :Trace 变绿,
formulate_response生成了正确答案
第六章:数据库结构------我们的"厨房"长什么样?
为了让读者更好地理解,我们设计了一个简单的演示数据库,包含三个主要表:
6.1 employees 员工表
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INTEGER | 主键 |
| name | TEXT | 员工姓名 |
| department_id | INTEGER | 外键,关联 departments |
| pay_rate | REAL | 薪资(注意:不是 salary!) |
| hire_date | TEXT | 入职日期 |
6.2 departments 部门表
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INTEGER | 主键 |
| name | TEXT | 部门名称 |
| budget | REAL | 部门预算 |
| manager_id | INTEGER | 外键,关联 employees |
6.3 projects 项目表
| 字段 | 类型 | 说明 |
|---|---|---|
| id | INTEGER | 主键 |
| name | TEXT | 项目名称 |
| department_id | INTEGER | 外键,关联 departments |
| status | TEXT | 状态 (active/inactive) |
第七章:高级优化技巧------让你的 Agent 更"聪明"
7.1 Schema 剪枝:减少上下文污染
python
def fetch_ddl(state):
# 根据 relevant_tables,仅提取核心字段的 DDL
table_schemas = {t: db.get_simplified_schema(t) for t in state["relevant_tables"]}
return {"table_schemas": table_schemas}7.2 动态元数据增强
python
def fetch_available_tables(state):
db = DatabaseManager(state.get("database_path"))
all_schemas = db.get_all_schemas()
# 添加表注释信息,帮助 LLM 更好理解
table_metadata = {}
for table, schema in all_schemas.items():
if table == "employees":
table_metadata[table] = "包含员工基础信息和薪资"
elif table == "departments":
table_metadata[table] = "包含部门信息和预算"
# ...
return {"available_tables": list(table_metadata.keys())}7.3 性能监控与优化
在 Phoenix 中观察:
- Span 耗时:哪个节点最慢?
- Input/Output 对比:输入给 LLM 的信息是否准确?
- 重试路径:是否频繁触发错误处理?
第八章:扩展与部署------让 Agent 走向"生产线"
8.1 生产环境适配
- 多数据库支持:PostgreSQL、MySQL 的 DDL 获取逻辑
- 认证机制:企业级数据库的安全认证
- 并发处理:多用户同时使用的性能保障
8.2 功能扩展方向
- 对话历史管理:支持多轮对话
- Chain of Thought:复杂查询的推理过程
- 结果可视化:直接生成图表和报告
8.3 部署最佳实践
- 容器化部署:Docker 容器打包
- 监控告警:生产环境的健康检查
- 版本控制:Prompt 和代码的版本管理
结语:从"黑盒"到"全透明"的进化之路
通过这套基于 LangGraph + Phoenix 的 SQL Agent 方案,我们实现了:
✅ 流程优于模型:即使模型稍弱,通过良好的工作流设计也能超越单次调用的最强模型
✅ 观测先于优化:在配置追踪工具前,不要盲目调优 Prompt,因为根本不知道病灶在哪
✅ 错误即数据:每次失败都是 Agent 进化的燃料
✅ 状态驱动设计:让 Agent 具备记忆和思考能力
这套方案不仅仅是技术实现,更是一种思维方式------让 AI 从"黑盒"变成"透明盒",从"可能出错"变成"可以诊断和修复"。
记住,好的 Agent 不是不会出错,而是知道什么时候出错了,并且知道怎么修正。这就是可观测性的真正价值。
项目源代码
完整的项目代码和更详细的实现,请访问我的知识星球( https://t.zsxq.com/CCi0k ),获取完整系统项目源代码。