SELECT
(SELECT COUNT(*) FROM imdb.title_basics) AS titles,
(SELECT COUNT(*) FROM imdb.name_basics) AS names,
(SELECT COUNT(*) FROM imdb.title_principals) AS principals;
!\[2_1查询数据入库结果.png]
表结构说明
1️⃣ 作品表(title_basics)
sql复制代码
\d imdb.title_basics;
重点字段解释:
字段
含义
tconst
作品唯一 ID(tt 开头)
titleType
movie / tvSeries / short
primaryTitle
常用标题
startYear
上映年份
runtimeMinutes
时长
genres
逗号分隔
2️⃣ 人物表(name_basics)
复制代码
\d imdb.name_basics;
字段
含义
nconst
人物唯一 ID(nm 开头)
primaryName
人名
birthYear
出生年
primaryProfession
actor, director 等
3️⃣ 关系表(title_principals)
复制代码
\d imdb.title_principals;
这是最关键的一张表,也是图模型的核心。
字段
含义
tconst
作品 ID
nconst
人物 ID
category
actor / actress / director
characters
饰演角色
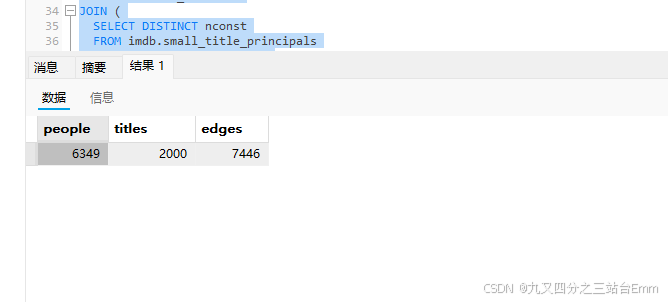
2. 准备小量数据
sql复制代码
DROP TABLE IF EXISTS imdb.small_name_basics;
DROP TABLE IF EXISTS imdb.small_title_basics;
DROP TABLE IF EXISTS imdb.small_title_principals;
CREATE TABLE imdb.small_title_basics AS
SELECT *
FROM imdb.title_basics
WHERE startyear BETWEEN 2015 AND 2018
AND isadult = 0
AND titletype IN ('movie','tvSeries','tvMiniSeries')
ORDER BY tconst
LIMIT 2000; -- ⭐ 控制规模
ALTER TABLE imdb.small_title_basics
ADD PRIMARY KEY (tconst);
CREATE TABLE imdb.small_title_principals AS
SELECT p.*
FROM imdb.title_principals p
JOIN imdb.small_title_basics t
ON t.tconst = p.tconst
WHERE p.category IN ('actor','actress');
CREATE INDEX ON imdb.small_title_principals(tconst);
CREATE INDEX ON imdb.small_title_principals(nconst);
CREATE INDEX ON imdb.small_title_principals(category);
CREATE TABLE imdb.small_name_basics AS
SELECT n.*
FROM imdb.name_basics n
JOIN (
SELECT DISTINCT nconst
FROM imdb.small_title_principals
) x ON x.nconst = n.nconst;
ALTER TABLE imdb.small_name_basics
ADD PRIMARY KEY (nconst);
SELECT
(SELECT count(*) FROM imdb.small_name_basics) AS people,
(SELECT count(*) FROM imdb.small_title_basics) AS titles,
(SELECT count(*) FROM imdb.small_title_principals) AS edges;
3. 效率比对
3.1. 两人是否合作过
3.1.1. Cypher
sql复制代码
EXPLAIN (ANALYZE, BUFFERS)
SELECT *
FROM cypher('imdb_graph', $$
MATCH (a:Person {primaryname:'Melissa Peters'})
-[:WORKED_ON]->(t:Title)<-[:WORKED_ON]-
(b:Person {primaryname:'Jason Hopley'})
RETURN count(DISTINCT t) AS co_titles
$$) AS (co_titles agtype);
sql复制代码
Aggregate (cost=304.13..304.14 rows=1 width=32) (actual time=1.353..1.355 rows=1.00 loops=1)
Buffers: shared hit=297
-> Sort (cost=304.11..304.12 rows=1 width=246) (actual time=1.349..1.350 rows=1.00 loops=1)
Sort Key: (_agtype_build_vertex(t.id, _label_name('25188'::oid, t.id), t.properties))
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=297
-> Nested Loop (cost=1.14..304.10 rows=1 width=246) (actual time=1.206..1.346 rows=1.00 loops=1)
Buffers: shared hit=297
-> Nested Loop (cost=0.84..302.61 rows=2 width=254) (actual time=1.197..1.314 rows=32.00 loops=1)
Buffers: shared hit=264
-> Nested Loop (cost=0.56..302.05 rows=1 width=262) (actual time=1.193..1.296 rows=7.00 loops=1)
Buffers: shared hit=241
-> Nested Loop (cost=0.28..301.67 rows=1 width=16) (actual time=1.189..1.285 rows=7.00 loops=1)
Buffers: shared hit=220
-> Seq Scan on "Person" a (cost=0.00..293.36 rows=1 width=8) (actual time=1.180..1.272 rows=1.00 loops=1)
Filter: (properties @> '{"primaryname": "Melissa Peters"}'::agtype)
Rows Removed by Filter: 6348
Buffers: shared hit=214
-> Index Scan using "WORKED_ON_start_id_idx" on "WORKED_ON" _age_default_alias_0 (cost=0.28..8.30 rows=1 width=24) (actual time=0.007..0.010 rows=7.00 loops=1)
Index Cond: (start_id = a.id)
Index Searches: 1
Buffers: shared hit=6
-> Index Scan using "Title_pkey" on "Title" t (cost=0.28..0.38 rows=1 width=246) (actual time=0.001..0.001 rows=1.00 loops=7)
Index Cond: (id = _age_default_alias_0.end_id)
Index Searches: 7
Buffers: shared hit=21
-> Index Scan using "WORKED_ON_end_id_idx" on "WORKED_ON" _age_default_alias_1 (cost=0.28..0.54 rows=2 width=24) (actual time=0.001..0.002 rows=4.57 loops=7)
Index Cond: (end_id = _age_default_alias_0.end_id)
Filter: _ag_enforce_edge_uniqueness2(_age_default_alias_0.id, id)
Rows Removed by Filter: 1
Index Searches: 7
Buffers: shared hit=23
-> Memoize (cost=0.29..0.73 rows=1 width=8) (actual time=0.001..0.001 rows=0.03 loops=32)
Cache Key: _age_default_alias_1.start_id
Cache Mode: logical
Hits: 21 Misses: 11 Evictions: 0 Overflows: 0 Memory Usage: 1kB
Buffers: shared hit=33
-> Index Scan using "Person_pkey" on "Person" b (cost=0.28..0.72 rows=1 width=8) (actual time=0.002..0.002 rows=0.09 loops=11)
Index Cond: (id = _age_default_alias_1.start_id)
Filter: (properties @> '{"primaryname": "Jason Hopley"}'::agtype)
Rows Removed by Filter: 1
Index Searches: 11
Buffers: shared hit=33
Planning:
Buffers: shared hit=60
Planning Time: 0.535 ms
Execution Time: 1.388 ms
3.1.2. SQL
sql复制代码
EXPLAIN (ANALYZE, BUFFERS)
WITH
a AS (SELECT nconst FROM imdb.small_name_basics WHERE primaryname='Melissa Peters' LIMIT 1),
b AS (SELECT nconst FROM imdb.small_name_basics WHERE primaryname='Jason Hopley' LIMIT 1)
SELECT count(DISTINCT p1.tconst) AS co_titles
FROM imdb.small_title_principals p1
JOIN a ON a.nconst = p1.nconst
JOIN imdb.small_title_principals p2 ON p2.tconst = p1.tconst
JOIN b ON b.nconst = p2.nconst;
EXPLAIN (ANALYZE, BUFFERS)
SELECT *
FROM cypher('imdb_graph', $$
MATCH (a:Person {primaryname:'Melissa Peters'})
-[:WORKED_ON]->(t:Title)<-[:WORKED_ON]-
(b:Person {primaryname:'Daniel F.K. Fernandes'})
RETURN DISTINCT
t.primarytitle AS title,
t.startyear AS year,
t.titletype AS type
ORDER BY year
$$) AS (title agtype, year agtype, type agtype);
sql复制代码
Unique (cost=304.14..304.15 rows=1 width=96) (actual time=1.391..1.396 rows=6.00 loops=1)
Buffers: shared hit=297
-> Sort (cost=304.14..304.14 rows=1 width=96) (actual time=1.390..1.392 rows=11.00 loops=1)
Sort Key: (agtype_access_operator(VARIADIC ARRAY[_agtype_build_vertex(t.id, _label_name('25188'::oid, t.id), t.properties), '"startyear"'::agtype])), (agtype_access_operator(VARIADIC ARRAY[_agtype_build_vertex(t.id, _label_name('25188'::oid, t.id), t.properties), '"primarytitle"'::agtype])), (agtype_access_operator(VARIADIC ARRAY[_agtype_build_vertex(t.id, _label_name('25188'::oid, t.id), t.properties), '"titletype"'::agtype]))
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=297
-> Nested Loop (cost=1.14..304.13 rows=1 width=96) (actual time=1.214..1.374 rows=11.00 loops=1)
Buffers: shared hit=297
-> Nested Loop (cost=0.84..302.61 rows=2 width=254) (actual time=1.177..1.301 rows=32.00 loops=1)
Buffers: shared hit=264
-> Nested Loop (cost=0.56..302.05 rows=1 width=262) (actual time=1.171..1.282 rows=7.00 loops=1)
Buffers: shared hit=241
-> Nested Loop (cost=0.28..301.67 rows=1 width=16) (actual time=1.163..1.268 rows=7.00 loops=1)
Buffers: shared hit=220
-> Seq Scan on "Person" a (cost=0.00..293.36 rows=1 width=8) (actual time=1.094..1.194 rows=1.00 loops=1)
Filter: (properties @> '{"primaryname": "Melissa Peters"}'::agtype)
Rows Removed by Filter: 6348
Buffers: shared hit=214
-> Index Scan using "WORKED_ON_start_id_idx" on "WORKED_ON" _age_default_alias_0 (cost=0.28..8.30 rows=1 width=24) (actual time=0.065..0.069 rows=7.00 loops=1)
Index Cond: (start_id = a.id)
Index Searches: 1
Buffers: shared hit=6
-> Index Scan using "Title_pkey" on "Title" t (cost=0.28..0.38 rows=1 width=246) (actual time=0.002..0.002 rows=1.00 loops=7)
Index Cond: (id = _age_default_alias_0.end_id)
Index Searches: 7
Buffers: shared hit=21
-> Index Scan using "WORKED_ON_end_id_idx" on "WORKED_ON" _age_default_alias_1 (cost=0.28..0.54 rows=2 width=24) (actual time=0.001..0.002 rows=4.57 loops=7)
Index Cond: (end_id = _age_default_alias_0.end_id)
Filter: _ag_enforce_edge_uniqueness2(_age_default_alias_0.id, id)
Rows Removed by Filter: 1
Index Searches: 7
Buffers: shared hit=23
-> Memoize (cost=0.29..0.73 rows=1 width=8) (actual time=0.001..0.001 rows=0.34 loops=32)
Cache Key: _age_default_alias_1.start_id
Cache Mode: logical
Hits: 21 Misses: 11 Evictions: 0 Overflows: 0 Memory Usage: 1kB
Buffers: shared hit=33
-> Index Scan using "Person_pkey" on "Person" b (cost=0.28..0.72 rows=1 width=8) (actual time=0.002..0.002 rows=0.09 loops=11)
Index Cond: (id = _age_default_alias_1.start_id)
Filter: (properties @> '{"primaryname": "Daniel F.K. Fernandes"}'::agtype)
Rows Removed by Filter: 1
Index Searches: 11
Buffers: shared hit=33
Planning:
Buffers: shared hit=60
Planning Time: 0.515 ms
Execution Time: 1.426 ms
3.2.2. SQL
sql复制代码
EXPLAIN (ANALYZE, BUFFERS)
WITH
a AS (SELECT nconst FROM imdb.small_name_basics WHERE primaryname='Melissa Peters' LIMIT 1),
b AS (SELECT nconst FROM imdb.small_name_basics WHERE primaryname='Daniel F.K. Fernandes' LIMIT 1)
SELECT DISTINCT
t.primarytitle AS title,
t.startyear AS year,
t.titletype AS type
FROM imdb.small_title_principals p1
JOIN a ON a.nconst = p1.nconst
JOIN imdb.small_title_principals p2 ON p2.tconst = p1.tconst
JOIN b ON b.nconst = p2.nconst
JOIN imdb.small_title_basics t ON t.tconst = p1.tconst
ORDER BY year;
sql复制代码
Unique (cost=25.82..25.83 rows=1 width=30) (actual time=0.527..0.531 rows=6.00 loops=1)
Buffers: shared hit=63 read=1
-> Sort (cost=25.82..25.82 rows=1 width=30) (actual time=0.527..0.528 rows=11.00 loops=1)
Sort Key: t.startyear, t.primarytitle, t.titletype
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=63 read=1
-> Nested Loop (cost=1.41..25.81 rows=1 width=30) (actual time=0.459..0.505 rows=11.00 loops=1)
Buffers: shared hit=63 read=1
-> Nested Loop (cost=1.13..25.49 rows=1 width=20) (actual time=0.453..0.479 rows=11.00 loops=1)
Join Filter: (p2.nconst = small_name_basics.nconst)
Rows Removed by Join Filter: 28
Buffers: shared hit=30 read=1
-> Limit (cost=0.28..8.30 rows=1 width=10) (actual time=0.431..0.431 rows=1.00 loops=1)
Buffers: shared hit=2 read=1
-> Index Scan using idx_small_name_primaryname on small_name_basics (cost=0.28..8.30 rows=1 width=10) (actual time=0.430..0.430 rows=1.00 loops=1)
Index Cond: (primaryname = 'Daniel F.K. Fernandes'::text)
Index Searches: 1
Buffers: shared hit=2 read=1
-> Nested Loop (cost=0.85..17.10 rows=7 width=30) (actual time=0.018..0.043 rows=39.00 loops=1)
Buffers: shared hit=28
-> Nested Loop (cost=0.56..16.61 rows=1 width=10) (actual time=0.013..0.017 rows=7.00 loops=1)
Buffers: shared hit=7
-> Limit (cost=0.28..8.30 rows=1 width=10) (actual time=0.007..0.007 rows=1.00 loops=1)
Buffers: shared hit=3
-> Index Scan using idx_small_name_primaryname on small_name_basics small_name_basics_1 (cost=0.28..8.30 rows=1 width=10) (actual time=0.007..0.007 rows=1.00 loops=1)
Index Cond: (primaryname = 'Melissa Peters'::text)
Index Searches: 1
Buffers: shared hit=3
-> Index Scan using idx_small_prin_nconst on small_title_principals p1 (cost=0.28..8.30 rows=1 width=20) (actual time=0.005..0.008 rows=7.00 loops=1)
Index Cond: (nconst = small_name_basics_1.nconst)
Index Searches: 1
Buffers: shared hit=4
-> Index Scan using idx_small_prin_tconst on small_title_principals p2 (cost=0.28..0.43 rows=6 width=20) (actual time=0.002..0.003 rows=5.57 loops=7)
Index Cond: (tconst = p1.tconst)
Index Searches: 7
Buffers: shared hit=21
-> Index Scan using small_title_basics_pkey on small_title_basics t (cost=0.28..0.32 rows=1 width=40) (actual time=0.002..0.002 rows=1.00 loops=11)
Index Cond: (tconst = p2.tconst)
Index Searches: 11
Buffers: shared hit=33
Planning:
Buffers: shared hit=48
Planning Time: 0.727 ms
Execution Time: 0.556 ms
3.3. 某演员合作次数最多的搭档 Top10
3.3.1. Cypher
sql复制代码
EXPLAIN (ANALYZE, BUFFERS)
SELECT *
FROM cypher('imdb_graph', $$
MATCH (a:Person {primaryname:'Melissa Peters'})
-[:WORKED_ON]->(t:Title)<-[:WORKED_ON]-(b:Person)
WHERE a <> b
WITH b, count(DISTINCT t) AS co_titles
RETURN b.primaryname AS partner, co_titles
ORDER BY co_titles DESC
LIMIT 10
$$) AS (partner agtype, co_titles agtype);
sql复制代码
Limit (cost=304.19..304.20 rows=2 width=64) (actual time=1.600..1.603 rows=10.00 loops=1)
Buffers: shared hit=360
-> Sort (cost=304.19..304.20 rows=2 width=64) (actual time=1.599..1.601 rows=10.00 loops=1)
Sort Key: _age_default_alias_previous_cypher_clause.co_titles DESC
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=360
-> Subquery Scan on _age_default_alias_previous_cypher_clause (cost=304.12..304.18 rows=2 width=64) (actual time=1.548..1.593 rows=10.00 loops=1)
Buffers: shared hit=360
-> GroupAggregate (cost=304.12..304.18 rows=2 width=64) (actual time=1.544..1.584 rows=10.00 loops=1)
Group Key: (_agtype_build_vertex(b.id, _label_name('25188'::oid, b.id), b.properties))
Buffers: shared hit=360
-> Sort (cost=304.12..304.12 rows=2 width=278) (actual time=1.535..1.537 rows=30.00 loops=1)
Sort Key: (_agtype_build_vertex(b.id, _label_name('25188'::oid, b.id), b.properties)), (_agtype_build_vertex(t.id, _label_name('25188'::oid, t.id), t.properties))
Sort Method: quicksort Memory: 49kB
Buffers: shared hit=360
-> Nested Loop (cost=1.12..304.11 rows=2 width=278) (actual time=1.055..1.349 rows=30.00 loops=1)
Join Filter: (_agtype_build_vertex(a.id, _label_name('25188'::oid, a.id), a.properties) <> _agtype_build_vertex(b.id, _label_name('25188'::oid, b.id), b.properties))
Rows Removed by Join Filter: 2
Buffers: shared hit=360
-> Nested Loop (cost=0.84..302.61 rows=2 width=429) (actual time=1.042..1.254 rows=32.00 loops=1)
Buffers: shared hit=264
-> Nested Loop (cost=0.56..302.05 rows=1 width=437) (actual time=1.037..1.236 rows=7.00 loops=1)
Buffers: shared hit=241
-> Nested Loop (cost=0.28..301.67 rows=1 width=191) (actual time=1.032..1.225 rows=7.00 loops=1)
Buffers: shared hit=220
-> Seq Scan on "Person" a (cost=0.00..293.36 rows=1 width=175) (actual time=1.023..1.212 rows=1.00 loops=1)
Filter: (properties @> '{"primaryname": "Melissa Peters"}'::agtype)
Rows Removed by Filter: 6348
Buffers: shared hit=214
-> Index Scan using "WORKED_ON_start_id_idx" on "WORKED_ON" _age_default_alias_0 (cost=0.28..8.30 rows=1 width=24) (actual time=0.006..0.009 rows=7.00 loops=1)
Index Cond: (start_id = a.id)
Index Searches: 1
Buffers: shared hit=6
-> Index Scan using "Title_pkey" on "Title" t (cost=0.28..0.38 rows=1 width=246) (actual time=0.001..0.001 rows=1.00 loops=7)
Index Cond: (id = _age_default_alias_0.end_id)
Index Searches: 7
Buffers: shared hit=21
-> Index Scan using "WORKED_ON_end_id_idx" on "WORKED_ON" _age_default_alias_1 (cost=0.28..0.54 rows=2 width=24) (actual time=0.001..0.002 rows=4.57 loops=7)
Index Cond: (end_id = _age_default_alias_0.end_id)
Filter: _ag_enforce_edge_uniqueness2(_age_default_alias_0.id, id)
Rows Removed by Filter: 1
Index Searches: 7
Buffers: shared hit=23
-> Index Scan using "Person_pkey" on "Person" b (cost=0.28..0.72 rows=1 width=175) (actual time=0.001..0.001 rows=1.00 loops=32)
Index Cond: (id = _age_default_alias_1.start_id)
Index Searches: 32
Buffers: shared hit=96
Planning:
Buffers: shared hit=60
Planning Time: 0.978 ms
Execution Time: 1.694 ms
3.3.2. SQL
sql复制代码
EXPLAIN (ANALYZE, BUFFERS)
WITH a AS (
SELECT nconst FROM imdb.small_name_basics
WHERE primaryname='Melissa Peters' LIMIT 1
),
pairs AS (
SELECT p2.nconst AS partner_nconst, p1.tconst
FROM imdb.small_title_principals p1
JOIN a ON a.nconst = p1.nconst
JOIN imdb.small_title_principals p2 ON p2.tconst = p1.tconst
WHERE p2.nconst <> a.nconst
)
SELECT nb.primaryname AS partner,
count(DISTINCT tconst) AS co_titles
FROM pairs
JOIN imdb.small_name_basics nb ON nb.nconst = pairs.partner_nconst
GROUP BY nb.primaryname
ORDER BY co_titles DESC
LIMIT 10;
EXPLAIN (ANALYZE, BUFFERS)
SELECT *
FROM cypher('imdb_graph', $$
MATCH (a:Person)-[:WORKED_ON]->(t:Title)<-[:WORKED_ON]-(b:Person)
WHERE a.nconst < b.nconst
WITH a, b, count(DISTINCT t) AS co_titles
RETURN a.primaryname AS actor1,
b.primaryname AS actor2,
co_titles
ORDER BY co_titles DESC
LIMIT 20
$$) AS (actor1 agtype, actor2 agtype, co_titles agtype);
EXPLAIN (ANALYZE, BUFFERS)
WITH pair_titles AS (
SELECT
LEAST(p1.nconst, p2.nconst) AS n1,
GREATEST(p1.nconst, p2.nconst) AS n2,
p1.tconst
FROM imdb.small_title_principals p1
JOIN imdb.small_title_principals p2
ON p2.tconst = p1.tconst
AND p2.nconst <> p1.nconst
WHERE p1.category IN ('actor','actress')
AND p2.category IN ('actor','actress')
),
pair_counts AS (
SELECT n1, n2, count(DISTINCT tconst) AS co_titles
FROM pair_titles
GROUP BY n1, n2
)
SELECT
n1_name.primaryname AS actor1,
n2_name.primaryname AS actor2,
pc.co_titles
FROM pair_counts pc
JOIN imdb.small_name_basics n1_name ON n1_name.nconst = pc.n1
JOIN imdb.small_name_basics n2_name ON n2_name.nconst = pc.n2
ORDER BY pc.co_titles DESC
LIMIT 20;