目录
[1. 什么是消息队列](#1. 什么是消息队列)
[2. 消息队列的特征](#2. 消息队列的特征)
[3. 为什么需要消息队列](#3. 为什么需要消息队列)
[二、Kafka 基础与入门](#二、Kafka 基础与入门)
[1. Kafka 基本概念](#1. Kafka 基本概念)
[2. Kafka 相关术语](#2. Kafka 相关术语)
[3. Kafka 拓扑架构](#3. Kafka 拓扑架构)
[4. Topic 与 partition](#4. Topic 与 partition)
[5. Producer 生产机制](#5. Producer 生产机制)
[6. Consumer 消费机制](#6. Consumer 消费机制)
[三、Zookeeper 介绍](#三、Zookeeper 介绍)
[0. zookeeper 概述](#0. zookeeper 概述)
[1. zookeeper 应用举例](#1. zookeeper 应用举例)
[2. zookeeper 的工作原理是什么?](#2. zookeeper 的工作原理是什么?)
[3. zookeeper 集群架构](#3. zookeeper 集群架构)
[4. zookeeper 的工作流程](#4. zookeeper 的工作流程)
[四、Zookeeper 在 Kafka 中的作用](#四、Zookeeper 在 Kafka 中的作用)
[1. Broker 注册](#1. Broker 注册)
[2. Topic 注册](#2. Topic 注册)
[3. 生产者负载均衡](#3. 生产者负载均衡)
[4. 消费者负载均衡](#4. 消费者负载均衡)
[5. 记录消息分区与消费者的关系](#5. 记录消息分区与消费者的关系)
[6. 消息消费进度 Offset 记录](#6. 消息消费进度 Offset 记录)
[7. 消费者注册](#7. 消费者注册)
[五、 单节点部署 Kafka](#五、 单节点部署 Kafka)
一、消息队列
1. 什么是消息队列
核心定义 :
消息队列(Message Queue)是一种异步通信中间件 ,允许应用通过发送/接收消息 解耦系统组件。采用生产者-消费者模型解耦系统。生产者发送消息到队列,消费者异步拉取处理,典型组件如 Kafka、RabbitMQ。其工作模型如下
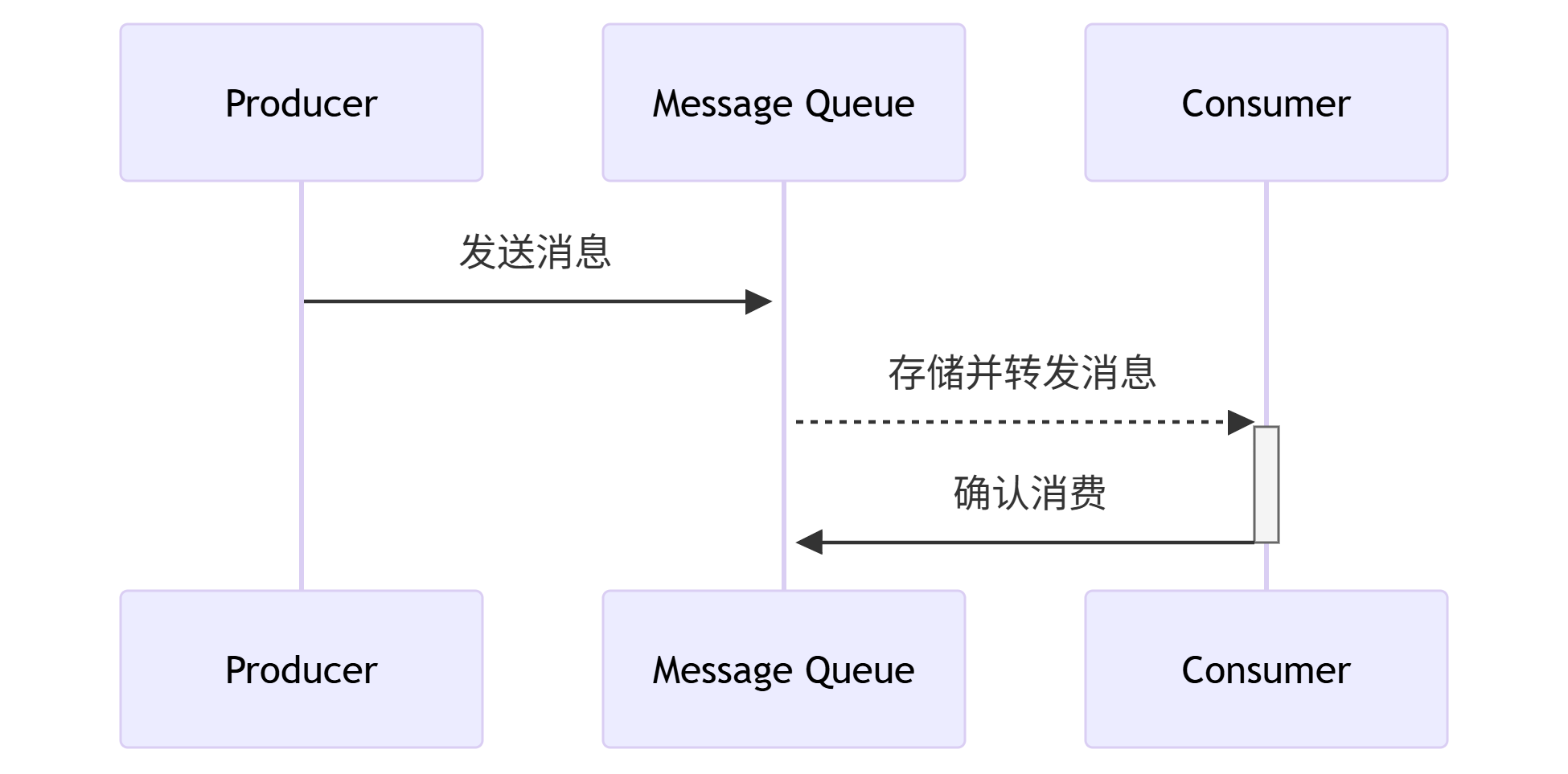
2. 消息队列的特征
| 特征 | 核心机制 | 关键价值 |
|---|---|---|
| 解耦 | 服务间无直接调用 | 独立演进,减少依赖 |
| 冗余 | 多副本持久化存储 | 防数据丢失,高可用 |
| 缓冲 | 积压突发流量 | 平滑后端压力,防系统崩溃 |
| 顺序保证 | 分区内消息有序 | 保障业务逻辑一致性 |
| 可恢复性 | 故障自动转移+重试机制 | 服务自愈,业务连续性 |
| 异步通信 | 生产者发送即返回 | 提升吞吐,降低延迟 |
| 削峰填谷 | 流量整形+匀速消费 | 资源利用率最大化 |
| 可靠性 | ACK确认+副本同步+持久化 | 消息必达,零丢失 |
| 扩展性 | 水平扩容分区/消费者/Broker | 线性提升吞吐能力 |
3. 为什么需要消息队列
-
解决场景:秒杀系统(流量削峰)、订单处理(异步扣库存)、日志收集(非阻塞传输)
-
价值:提升系统可用性、降低延迟敏感度、保证最终一致性
二、Kafka 基础与入门
1. Kafka 基本概念
-
分布式流平台:高吞吐、持久化日志存储
-
核心角色:Producer(生产者)、Broker(服务节点)、Consumer(消费者)、ZooKeeper(元数据管理,Kafka 3.0+ 逐步替代为KRaft)
-
定位 :分布式、高吞吐、持久化的发布-订阅消息系统,适用于实时流数据处理。
-
核心优势:
-
高吞吐:单机每秒百万级消息(SSD 磁盘 + 零拷贝技术)。
-
持久存储:消息保留策略可配置(默认 7天)。
-
水平扩展:无缝扩容 Broker 和 Partition。
-
2. Kafka 相关术语
| 术语 | 说明 | 类比 |
|---|---|---|
| Producer | 消息生产者(如订单系统) | 快递寄件人 |
| Consumer | 消息消费者(如库存系统) | 快递收件人 |
| Topic | 消息类别(如 order_events) |
快递柜编号 |
| Partition | Topic 的分区,并行处理单位 | 快递柜中的格子 |
| Broker | Kafka 服务节点 | 快递柜 |
| Offset | 消息在 Partition 内的唯一位置标识 | 快递单号 |
| Consumer Group | 一组协同消费的 Consumer,共享 Topic 消息 | 合租收件小组 |
3. Kafka 拓扑架构
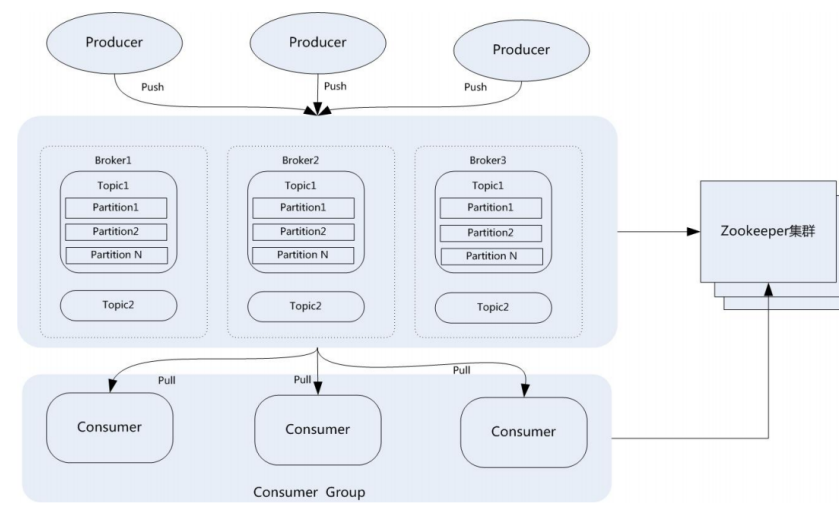
-
生产者(Producer) :
多个生产者通过 Push(推送) 操作将消息发送到 Broker(代理服务器),实现消息的生产。
-
Broker 集群:
- 包含多个 Broker(如 Broker1、Broker2、Broker3),每个 Broker 存储 主题(Topic) 的 分区(Partition)(如 Topic1 的多个 Partition 分布在不同 Broker 上,实现数据分片与分布式存储,提升吞吐量和容错性)。
- 支持多主题(如 Topic1、Topic2),每个主题的分区在集群中分布式存储,确保高可用和并行处理。
-
消费者组(Consumer Group):
- 多个消费者(Consumer)组成一组,通过 Pull(拉取) 从 Broker 获取消息。
- 消费者组内的消费者 负载均衡 消费不同的 Partition(同一 Partition 只能被组内一个消费者消费),实现消费能力的水平扩展。
-
Zookeeper 集群 :
负责 集群元数据管理,包括 Broker 状态、消费者消费位置(Offset)、主题分区的分布等,协调集群各组件的运行(如 Broker 注册、消费者组的协调)。
4. Topic 与 partition
-
Partition 的核心作用:
-
并行处理:每个 Partition 可被独立消费,提升吞吐量。
-
消息顺序性:同一 Partition 内消息有序,不同 Partition 无序。
-
-
分区目的:
-
并行处理(不同分区可被不同消费者同时消费)
-
水平扩展(单Topic可跨多Broker存储)
-
-
分区策略:
-
Producer指定Key时:
hash(key) % 分区数 -
无Key时:轮询分配
-
5. Producer 生产机制
-
写入流程:
-
消息发送至指定Topic
-
根据分区策略选择目标Partition
-
批量压缩后发送至Leader副本
-
-
关键配置:
-
acks=0/1/all(消息持久化保证级别) -
retries(发送失败重试次数)
-
6. Consumer 消费机制
-
消费模式:
-
Pull模型:消费者主动拉取消息(避免Broker压垮消费者)
-
位移提交 :消费者定期提交Offset(
enable.auto.commit=true或手动提交)
-
-
重平衡(Rebalance):
-
触发条件:消费者加入/离开组、分区数变更
-
影响:暂停消费,重新分配分区(可能造成短暂不可用)
-
三、Zookeeper 介绍
0. zookeeper 概述
分布式协调服务 ,为分布式系统提供一致性数据管理 、节点监听 和集群选举能力
核心特性:
-
树形命名空间(类似文件系统路径,如
/kafka/config) -
数据节点 ZNode (分持久节点
PERSISTENT和临时节点EPHEMERAL) -
监听机制 Watch(实时感知节点变化)
-
强一致性(基于 Zab 协议保证数据一致)
1. zookeeper 应用举例
| 场景 | 实现方式 |
|---|---|
| 分布式配置中心 | 将配置写入 ZNode(如 /app/config),服务监听节点变化实时更新配置 |
| 分布式锁 | 创建临时顺序节点,最小序号节点获得锁(如 /lock/task_00000001) |
| 服务注册发现 | 服务启动注册临时节点(如 /services/user-service/192.168.1.1:8080) |
| HDFS 高可用 | 主 NameNode 注册临时节点,备节点监听其状态,宕机时触发切换 |
2. zookeeper 的工作原理是什么?
-
写请求流程:
-
Client 向 Leader 发送写请求
-
Leader 生成事务提案(ZXID)并广播给所有 Follower
-
过半 Follower 确认后提交事务
-
通知所有节点更新数据
-
-
读请求:由任意节点直接响应(可能读到旧数据,最终一致)
-
Watch 机制:Client 对 ZNode 设置监听,节点变更时触发回调(一次性触发)
3. zookeeper 集群架构
| 角色 | 职责 | 关键特性 |
|---|---|---|
| Leader | 处理所有写请求,发起事务提案 | 选举产生,唯一有效 |
| Follower | 同步 Leader 数据,处理读请求;参与选举 | 可参与写投票(过半确认) |
| Observer | 同步数据并处理读请求,不参与选举和写投票 | 扩展集群读性能 |
-
选举条件:
-
节点启动时
-
Leader 宕机时
-
-
选举规则 :基于
zxid(最新事务ID)和myid(服务器ID)的 FastLeaderElection 算法
4. zookeeper 的工作流程
-
启动选举:
-
节点启动后进入 LOOKING 状态
-
交换投票信息,选举
(zxid, myid)最大的节点为 Leader
-
-
数据同步:
-
Follower/Observer 连接 Leader
-
通过 DIFF(差异同步) 或 SNAP(全量快照) 同步数据
-
-
请求处理:
-
写请求:转发给 Leader 执行 Zab 协议
-
读请求:当前节点直接响应
-
-
故障恢复:
- Leader 宕机 → 剩余节点重新选举 → 新 Leader 同步数据至最新状态
四、Zookeeper 在 Kafka 中的作用
1. Broker 注册
-
路径 :
/brokers/ids/<broker.id> -
数据类型 :临时节点(Ephemeral Node)
-
数据内容 :
{"host":"broker1","port":9092,"rack":"dc1"} -
作用:Broker 上线时自动注册,宕机时节点消失(触发 Controller 重分配分区)
2. Topic 注册
-
路径 :
/brokers/topics/<topic_name> -
{
"partitions": {
"0": [1, 2], // 分区0:Leader=Broker1,ISR=[Broker1, Broker2]
"1": [2, 3] // 分区1:Leader=Broker2,ISR=[Broker2, Broker3]
}
}
3. 生产者负载均衡
-
流程:
-
生产者从 ZK 拉取 Topic 的分区分布信息
-
根据
partitioner.class(如hash(key)%分区数)计算目标 Partition
-
4. 消费者负载均衡
-
关键路径:
-
消费者组注册:
/consumers/<group_id>/ids/<consumer_id> -
分区分配结果:
/consumers/<group_id>/owners/<topic>/<partition_id>
-
-
触发重平衡(Rebalance):
-
消费者加入/退出 → ZNode 子节点变化 → 触发 Watch
-
消费者组内选举 Leader → 计算新分配方案 → 写入 ZK
-
5. 记录消息分区与消费者的关系
-
路径 :
/consumers/<group_id>/owners/<topic>/<partition_id> -
数据 :
consumer_id(如consumer1) -
作用:标记分区被哪个消费者占用(避免重复消费)
6. 消息消费进度 Offset 记录
-
路径 :
/consumers/<group_id>/offsets/<topic>/<partition_id> -
数据 :
offset_value(如1532) -
新版改进 :Offset 存储至 Kafka 内置 Topic
__consumer_offsets(ZK 仅协调重平衡)
7. 消费者注册
-
路径 :
/consumers/<group_id>/ids/<consumer_id> -
数据 :
{"subscription":{"topics":["topicA"]},"pattern":"static"} -
特性 :临时节点,消费者下线时自动删除 → 触发组内重平衡
五、 单节点部署 Kafka
bash
--基础环境
dnf -y install java
--解压二进制包安装zookeeper
tar zxvf apache-zookeeper
mv apa.. /etc/zookeeper
cd /etc/zookeeper
ls
cd conf/
ls
--拷贝配置模板
cp zoo_sample.cfg zoo.cfg
vim /etc/zookeeper/conf/zoo.cfg
dataDir=/etc/zookeeper/zookeeper-data
--创建指定的文件
mkdir zookeeper-data
cd bin
--启动zookeeper
./zkServer.sh start
--Kafka安装
tar zxvf kafka
mv kafka /etc/kafka
--修改配置文件
cd /etc/kafka/config/
vim kafka.conf
log.dirs=/etc/kafka/kafka-logs #60行
--启动Kafka
mkdir /etc/kafka/kafka-logs
cd .../bin
./kafka-server-start.sh ../config/server.properties &
--查看启动
netstat -anpt | grep java
--topic
cd .../bin
./kafka-topics.sh --list --zookeeper 127.0.0.1:2181
--生产消息
./kafka-console-producer.sh --broker-list 127.0.0.1:9092 -topic test0001
--消费消息 (另一个终端进行,一边生产,一边查看)
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test0001六、多节点集群部署
bash
101,102,103
--修改hosts文件,地址映射
vim /etc/hosts
192.168.10.101 kafka1
192.168.10.102 kafka2
192.168.10.103 kafka3
--改主机名
101:
hostnamectl set-hostname kafka1
102:
hostnamectl set-hostname kafka2
103:
hostnamectl set-hostname kafka3
bash
--关闭防火墙
systemctl stop firewalld
setenforce 0
--安装Java
dnf -y install java
--安装Zookeeper
tar zxvf apache-zookeeper
mv apa.. /etc/zookeeper
cd /etc/zookeeper
cd conf/
cp zoo_sample.cfg zoo.cfg
--配置文件
vim /etc/zookeeper/conf/zoo.cfg
dataDir=/etc/zookeeper/zookeeper-data //存放目录
clientPort=2181
server.1=192.168.10.101:2888:3888
server.2=192.168.10.102:2888:3888
server.3=192.168.10.103:2888:3888
ls
--创建文件
mkdir /etc/zookeeper/zookeeper-data
101:
echo "1">/etc/zookeeper/zookeeper-data/myid
102:
echo "2">/etc/zookeeper/zookeeper-data/myid
103:
echo "3">/etc/zookeeper/zookeeper-data/myid
--启动zookeeper(bin目录)
cd /etc/zookeeper/bin/
./zkServer.sh start
--测试启动
netstat -anpt |grep java
--安装kafka
tar zxvf kafka
mv kafka /etc/kafka
--修改配置文件
cd /etc/kafka/config/
vim server.properties
log.dirs=/etc/kafka/kafka-logs
broker.id=1/2/3 #要不同,3台主机不能一样
--监听
31行(3台不同注意IP)
listeners=PLAINTEXT://192.168.10.101:9092 //监听是要监听自己
65行
num.partitions=1 //分区的配置
123行(相同)
zookeeper.connect=192.168.10.101:2181,192.168.10.102:2181,192.168.10.103:2181
--创建日志文件
mkdir kafka-logs
--启动Kafka
cd /etc/kafka/bin
./kafka-server-start.sh ../config/server.properties &
测试:=========
101:
--创建主题(在bin目录下)
./kafka-topics.sh --create --zookeeper kafka1:2181 --replication-factor 1 --partitions 1 --topic test
--生成消息
./kafka-console-producer.sh --broker-list kafkal:9092 --topic test
102.103
--消费
./kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic test
--删除
./kafka-topics.sh --delete --zookeeper kafkal:2181 --topic test