服务端高并发分布式结构演进之路
在进行技术学习过程中,由于大部分读者没有经历过一些中大型系统的实际经验,导致无法从全局理解一些概念,所以本文以一个 "电子商务" 应用为例,介绍从一百个到千万级并发情况下服务端的架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让大家对架构的演进有一个整体的认知,方便大家对后续知识做深入学习时有一定的整体视野。
1、认识Redis
Redis是开源的,用于在内存中存储数据的。被很多人使用作为:数据库、缓存、消息中间件。
Redis的初心是最为一个消息中间件(消息队列)使用,相当于分布式系统下的生产者消费者模型。不过当前很少会直接使用Redis作为消息中间件,业界有更多更专业的消息中间件使用。Redis要在分布式系统中才能发挥作用,如果是单机程序,直接通过变量存储数据的方式,是比Redis更优的选择。
MySQL:最大的问题在于访问速度慢,而很多互联网产品对性能要求是很高的。Redis也可以作为数据库使用,由于是在内存中的,所以速度要比MySQL快,但是也有劣势,就是存储的空间是有限的。
那么有没有办法做到又大又快呢?典型的方案:Redis 和 MySQL 结合起来使用。把热点数据存放在Redis中,这样就能大大缓解数据库服务器的压力。
2、服务端高并发分布式结构演进之路
单机架构:只有一台服务器,这个服务器负责所有的工作。
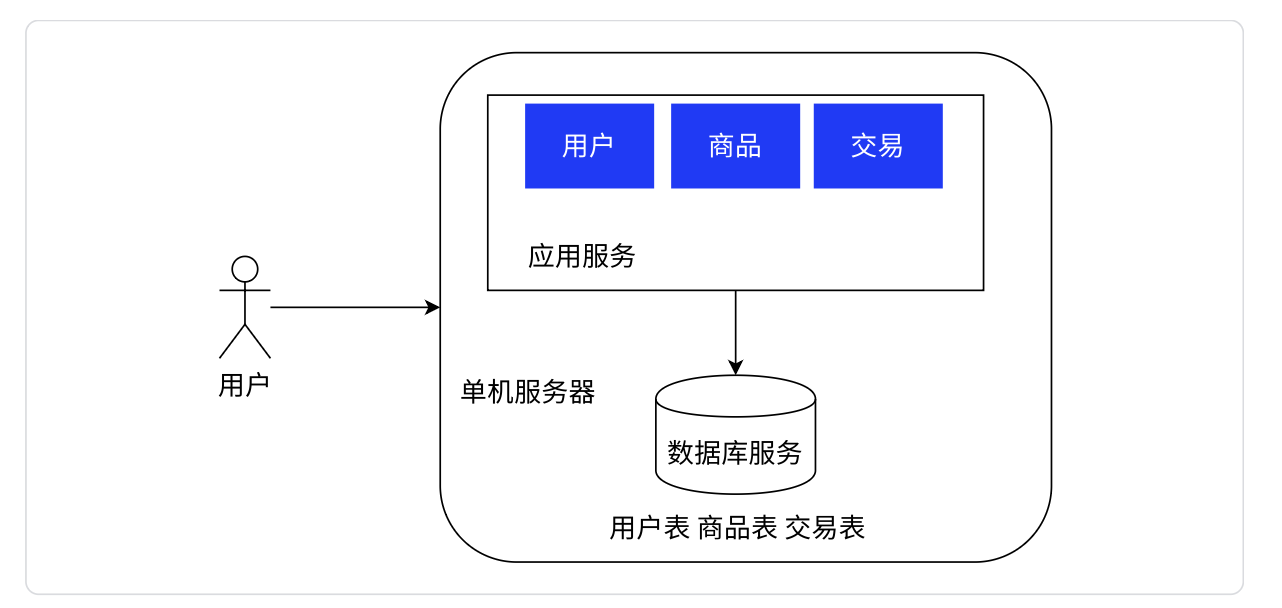
如图:应用服务就是我们所写的C++/Java服务器程序。而数据库服务一般就是指的MySQL。MySQL是一种基于客户端©和服务器(S)的网络服务,这里主要是指MySQL服务器。单机结构中也可以把数据库服务器也去掉,就一个应用服务器既负责业务又负责数据存储,只不过这种方式比较麻烦。
也不要瞧不起上述这种情况,绝大部分公司的产品都是单机架构的,现在的计算机硬件发展速度很快,哪怕只有一台主机,也可以支持比较高的并发和比较大的数据存储。
但如果业务进一步增长,用户量和数据量都水涨船高,一台主机难以应付,此时就需要引入更多的主机,引入更多的硬件资源。一台主机的硬件资源是有上限的,包括但不限于以下这几种:CPU、内存、硬盘、网络。
当遇到服务器资源不够用的场景该怎么办呢?
节流:软件上进行优化。
开源:简单粗暴,直接增加更多的硬件资源。一台主机上所能增加的硬件资源也是有限的,取决于主办的扩展能力。当一台主机扩展到极限了,就只能引入多台主机了。一旦引入了多台主机,咱们的系统就可以称为是 分布式系统 了。引入分布式是万不得已的无奈之举,系统的复杂程度会大大提高~~
应用数据分离架构:应用服务和数据库服务分别在两台主机上工作。
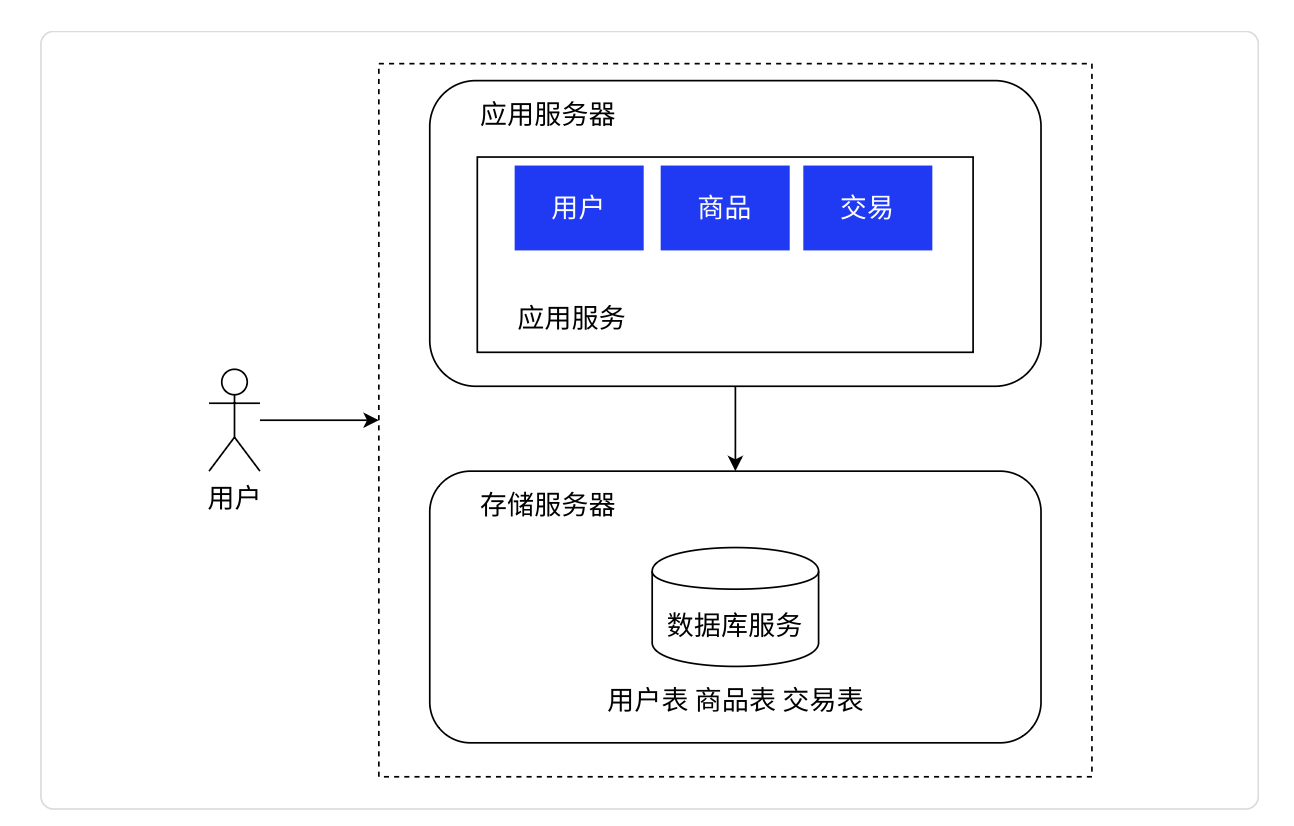
应用服务器:里面可能会包含很多的业务逻辑,会比较吃CPU和内存资源,所以我们可以放到CPU和内存资源更好的服务器上去跑。
数据库服务器:需要更大的硬盘空间,更快的硬盘读写速度,所以我们可以放到配置更大硬盘,甚至是SSD硬盘的机器上。
通过这种方式来实现更高的性价比。但是随着用户量的继续增加,单台的应用服务器也扛不住了,这时候该怎么办呢?有以下两种方式:- 垂直扩展 / 纵向扩展 Scale Up。通过购买性能更优、价格更高的应用服务器来应对更多的流量。这种方案的优势在于完全不需要对系统软件做任何的调整;但劣势也很明显:硬件性能和价格的增长关系是非线性的,意味着选择性能 2 倍的硬件可能需要花费超过 4 倍的价格,其次硬件性能提升是有明显上限的。
- 水平扩展 / 横向扩展 Scale Out。通过调整软件架构,增加应用层硬件,将用户流量分担到不同的应用层服务器上,来提升系统的承载能力。这种方案的优势在于成本相对较低,并且提升的上限空间也很大。但劣势是带给系统更多的复杂性,需要技术团队有更丰富的经验。
应用服务集群架构:引入多台应用服务器和一台负载均衡器,负载均衡器将用户请求打给多台应用服务器。
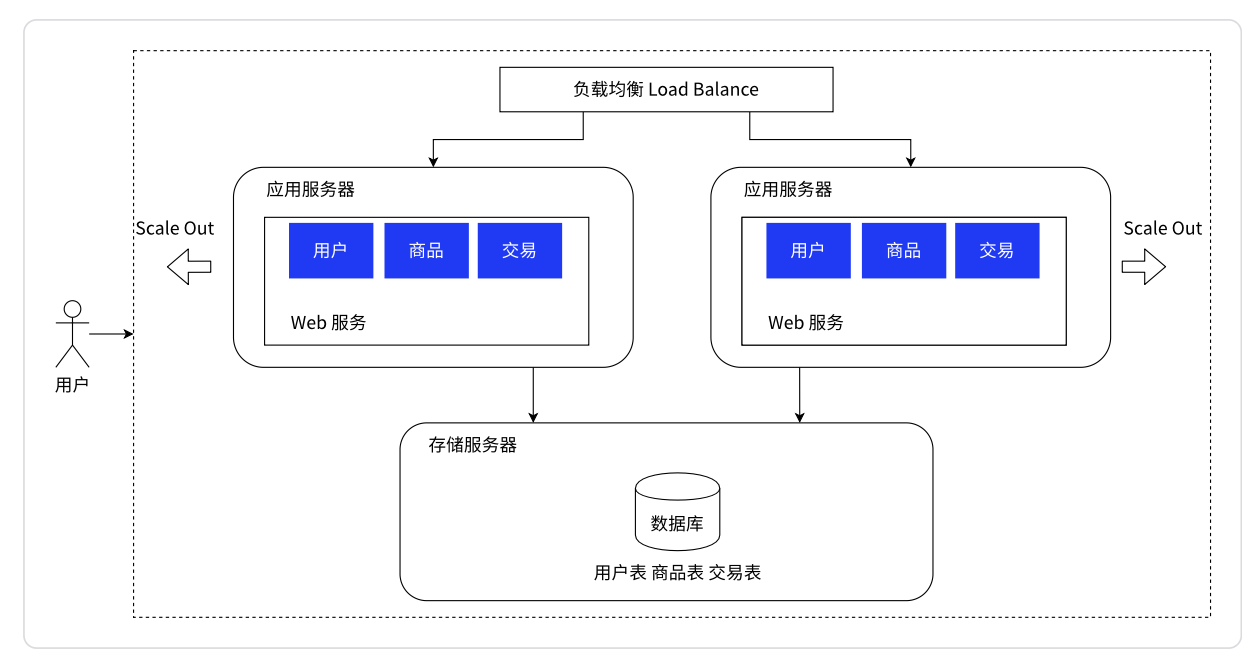
如图:现在引入多台应用服务器,用户请求先打到负载均衡器/网管服务器,这台服务器配置是要更好的,由它接受用户的全部请求,然后再负载均衡的分配给应用服务器。上面虽然只画了两个,但是实际上可能是多个。假设用户请求量是1w,有两个应用服务器,此时通过负载均衡的方式,就可以让每个应用服务器承担5K的访问量,有点类似于多线程。
常见的负载均衡算法有以下几种:
Round-Robin 轮询算法:即非常公平地将请求依次分给不同的应用服务器。
Weight-Round-Robin 轮询算法:为不同的服务器(比如性能不同)赋予不同的权重(weight),能者多劳。
致哈希散列算法:通过计算用户的特征值(比如 IP 地址)得到哈希值,根据哈希结果做分发,优点是确保来自相同用户的请求总是被分给指定的服务器。也就是我们平时遇到的专项客户经理服务。
负载均衡软件:Nginx、HAProxy、LVS、F5等。
那么负载均衡器有没有可能扛不住?一般来说,负载均衡器的承担能力要远超应用服务器。但万一扛不住的话,就需要引入更多的负载均衡器。
虽然增加了应用服务器,可以处理更多的请求,但是随之而来的问题是:存储服务器要承担的请求量也更多了。
读写分离/主从分离架构:将读写数据库分离到不同的服务器上。
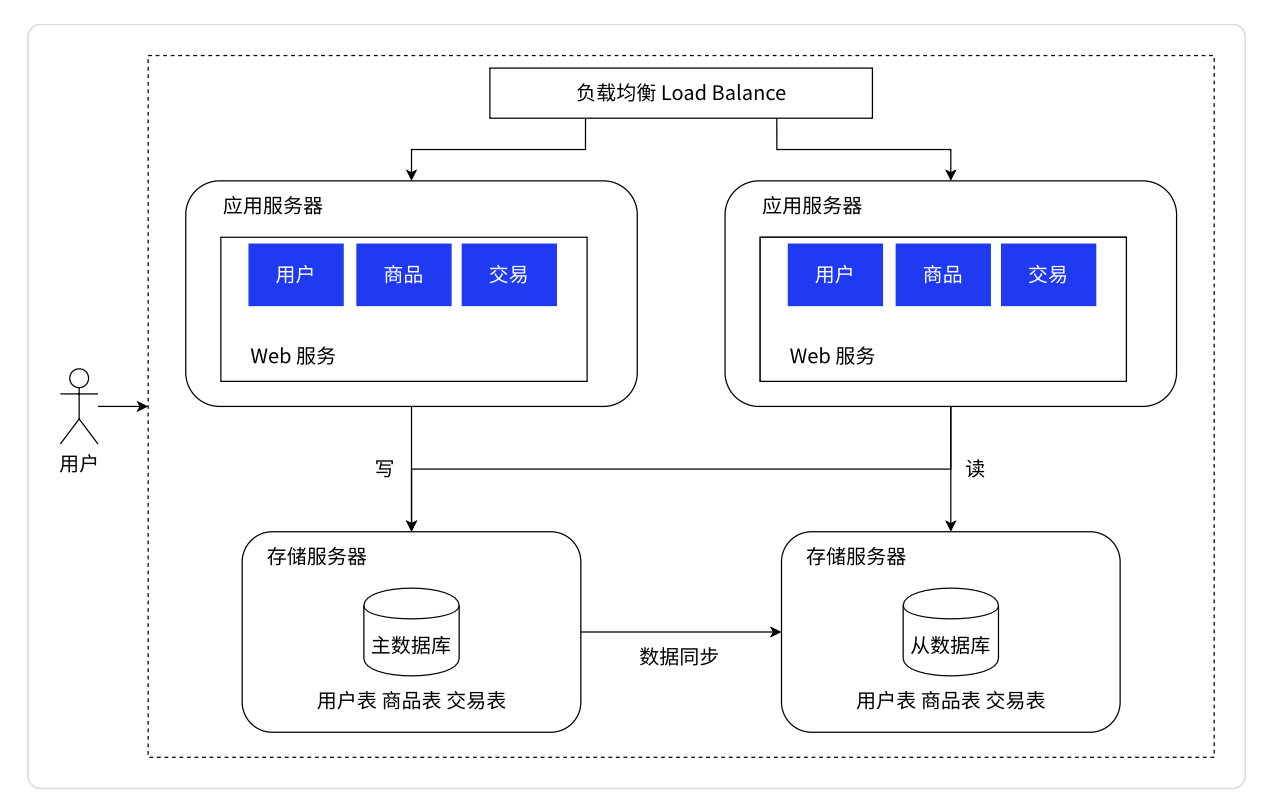
我们把读数据库和写数据库分离到不同的服务器上。写数据库的服务器我们称为主服务器,读数据库的服务器我们称为从服务器。主服务器一般是一个,从服务器可以有多个,一主多从。同时从数据库通过负载均衡的方式让应用服务器访问。因为在实际应用场景中,读的频率比写要来得高。
但是由于可能会写数据库,所以主数据库要定期将数据同步给从数据库。
相关软件:MyCat、TDDL、Amoeba、Cobar 等类似数据库中间件等。
冷热分离架构:将热点数据缓存起来放到内存中,提高读取数据的效率。
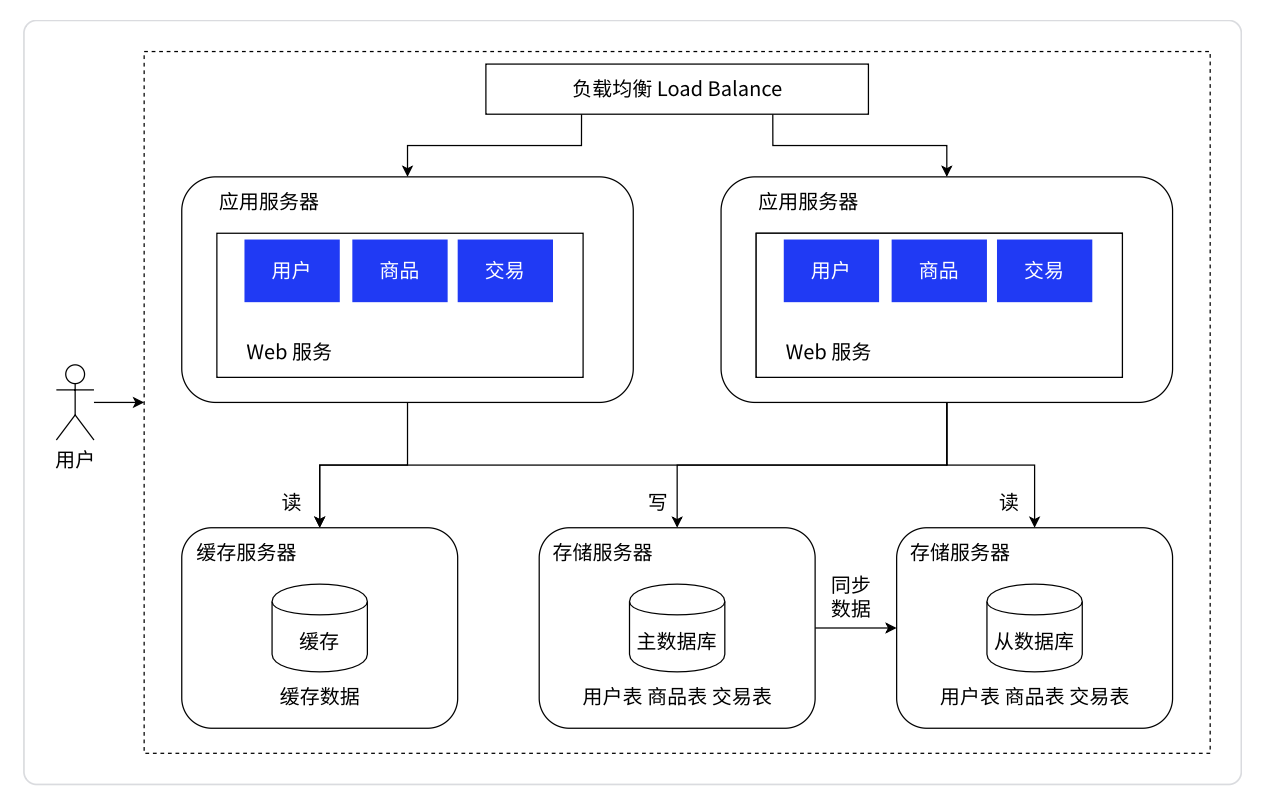
随着访问量继续增加,发现业务中一些数据的读取频率远大于其他数据的读取频率。我们把这部分数据称为热点数据,与之相对应的是冷数据。针对热数据,为了提升其读取的响应时间,可以增加本地缓存,并在外部增加分布式缓存,缓存热门商品信息或热门商品的 html 页面等。通过缓存能把绝大多数请求在读写数据库前拦截掉,大大降低数据库压力。其中涉及的技术包括:使用memcached作为本地缓存,使用 Redis 作为分布式缓存,还会涉及缓存一致性、缓存穿透/击穿、缓存雪崩、热点数据集中失效等问题。
分库分表:单个服务器存储不下所有的数据,引入多台数据库服务器进行分库分表。
随着业务的数据量增大,大量的数据存储在同一个库中已经显得有些力不从心了,所以可以按照业务,将数据分别存储。比如针对评论数据,可按照商品ID进行hash,路由到对应的表中存储;针对支付记录,可按照小时创建表,每个小时表继续拆分为小表,使用用户ID或记录编号来路由数据。只要实时操作的表数据量足够小,请求能够足够均匀的分发到多台服务器上的小表,那数据库就能通过水平扩展的方式来提高性能。其中前面提到的Mycat也支持在大表拆分为小表情况下的访问控制。这种做法显著的增加了数据库运维的难度,对DBA的要求较高。数据库设计到这种结构时,已经可以称为分布式数据库,但是这只是一个逻辑的数据库整体,数据库里不同的组成部分是由不同的组件单独来实现的,如分库分表的管理和请求分发,由Mycat实现,SQL的解析由单机的数据库实现,读写分离可能由网关和消息队列来实现,查询结果的汇总可能由数据库接口层来实现等等,这种架构其实是MPP(大规模并行处理)架构的一类实现。
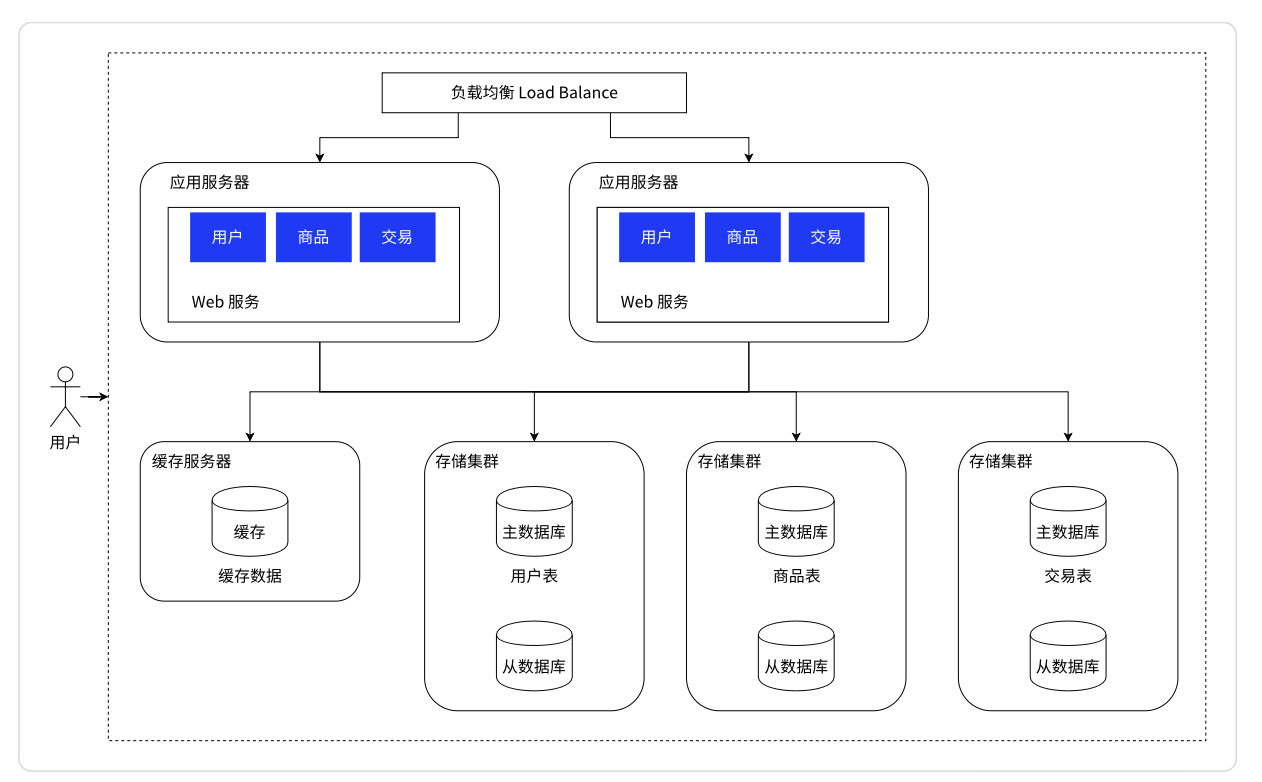
假设数据库存储的是短视频,虽然一台服务器可以存储很大的空间,但是还是可能存不下,这时候就需要针对数据库进一步的拆分:分库分表。
本来一个数据库服务器,这个数据库服务器上有多个数据库database。现在可以引入多个数据库服务器,每个数据库服务器存储一个或者一部分数据,这就是:分库
如果某个表特别大,大到一台主机存不下来,也可以针对表进行拆分,这就是:分表
微服务架构:
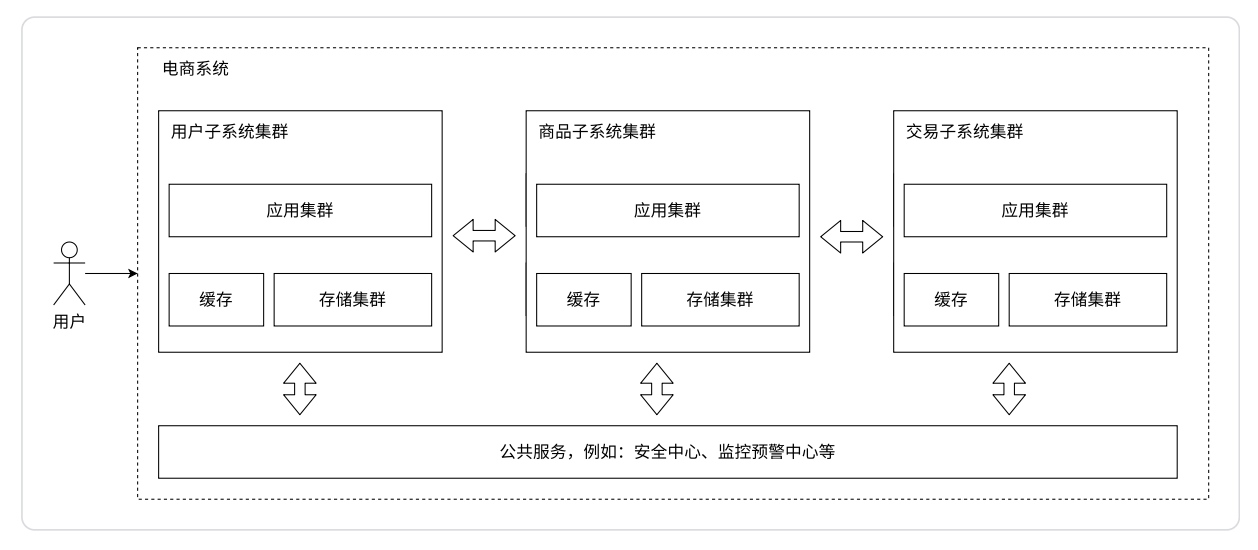
之前的应用服务器,一个服务器程序里面做了很多的业务,这就可能导致服务器的代码变得越来越复杂。为了更方便于代码维护,就可以把这样一个复杂的服务器拆分成更多的,功能更单一,但是更小的服务器。微服务:服务器的种类和数量增加了。
微服务本质上是在解决人的问题,当应用服务器复杂了,势必就需要更多的人来维护。人多了就需要把人管理好,所以就需要划分组织结构,分成多个组,每个组配备领导进行管理。
引入微服务,解决了人的问题,付出的代价?
1. 系统的性能下降,拆分出更多的服务,多个功能之间要依赖网络通信,网络通信的速度可能比硬盘要慢。
2. 系统的复杂程度提高,可用性受到影响。服务器更多了,出问题的概率也就更大,所以需要一系列的手段来保证系统的可用性。
微服务的优势:
1. 解决了人的问题。
2. 使用微服务,可以更方便于功能的复用。
3. 可以给不同的服务进行不同的部署。
3、常见概念
应用(Application)/ 系统(System):一个应用就是一个/组服务器程序。模块(Module)/ 组件(Component):一个应用里面有很多功能,每个独立的功能就可以称为是一个模块 / 组件分布式(Distributed):引入多个主机 / 服务器,协同配合完成一系列工作。物理上的多个主机。集群(Cluster):引入多个主机 / 服务器,协同配合完成一系列工作。逻辑上的多个主机。主(Master)/ 从(Slaver):分布式系统中一种比较典型的结构。多个服务器节点,其中一个是主,另外的是从,从节点的数据要从主节点同步。中间件(Middleware):和业务无关的服务,功能更通用的服务。如:数据库、缓存、消息队列。可用性(Availability):系统整体可用时间 / 总的时间。响应时长(Response Time RT):衡量服务器的性能,越小越好。吞吐(Throughput)vs 并发(Concurrent):吞吐考察单位时间段内,系统可以成功处理的请求的数量。并发指系统同一时刻支持的请求最高量。例如一条辆车道高速公路,一分钟可以通过 20 辆车,则并发是 2,一分钟的吞吐量是 20。实践中,并发量往往无法直接获取,很多时候都是用极短的时间段(比如 1 秒)的吞吐量做代替。我们平时用高并发(Hight Concurrnet)这个非量化目标简要表达系统的追求。