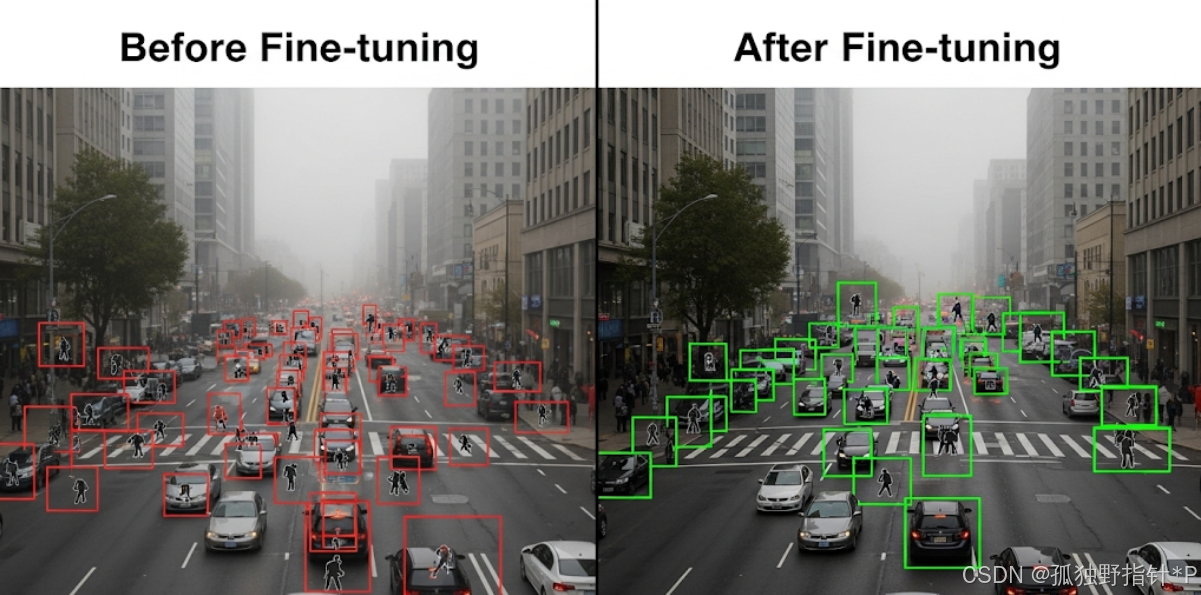
引言
在计算机视觉领域,目标检测是一项至关重要的任务,它不仅要识别出图像中存在哪些物体,还要精确地定位它们的位置。从自动驾驶汽车识别行人与车辆,到医疗影像辅助诊断病灶,再到智能安防监控异常事件,目标检测技术无处不在。
像YOLO、SSD、Faster R-CNN等经典的深度学习目标检测模型,通常在如COCO、ImageNet等大规模、通用性的公开数据集上进行预训练。这些预训练模型已经学习到了丰富的图像特征,能够识别数百种常见物体,展现了强大的泛化能力。
然而,当我们尝试将这些通用模型直接应用于某些特定且复杂的场景时,常常会遇到"水土不服"的问题。例如:
- 在光线条件多变的工业流水线上检测微小瑕疵。
- 在特定角度、有遮挡的监控视频中识别人脸。
- 在雾天或雨天等恶劣天气条件下识别交通标志。
在这些场景下,通用模型可能会出现较高的误识别率或漏检率,因为预训练数据集中可能缺乏这类特定场景的样本,或者场景中的某些固定元素对模型造成了干扰。

那么,如何让这些强大的通用模型更好地服务于我们的特定需求呢?答案就是------微调 (Fine-tuning)。
什么是微调 (Fine-tuning)?------ 原理揭秘
微调,顾名思义,就是对一个已经训练好的模型进行"微小调整",使其更适应新的、特定的任务或数据。它是迁移学习 (Transfer Learning) 的一种重要策略。
1. 预训练 (Pre-training) 的基石:
在进行微调之前,我们首先需要一个预训练模型。这个模型通常是在一个非常大的数据集(如ImageNet包含数百万张图片,COCO包含数十万张图片和物体实例)上花费大量时间和计算资源训练得到的。通过这个过程,模型(尤其是其底层的卷积层)学习到了如何提取图像的通用特征,如边缘、角点、纹理、颜色、基本形状等。这些特征对于理解各种视觉信息都是有用的。
2. 迁移学习的核心思想:
迁移学习的核心思想是将从一个任务(源任务,Source Task)中学到的知识应用到另一个不同但相关的任务(目标任务,Target Task)上。在目标检测的微调中:
- 源任务: 在大规模通用数据集上进行物体检测或图像分类。
- 目标任务: 在我们特定的、通常数据量较小的数据集上进行物体检测。
3. 微调的流程:
微调的过程通常包括以下步骤:
- 选择预训练模型: 根据您的需求(如速度、精度、模型大小),选择一个合适的预训练模型(例如YOLOv5, Faster R-CNN with ResNet backbone等)。
- 准备特定数据集: 收集并标注您特定场景下的图像数据。这个数据集通常比预训练数据集小得多,但必须能够代表您目标应用的实际情况。正如您之前提到的,"将固定复杂场景的数据标注后放入重新训练"。
- 调整模型结构(可选):
- 输出层修改: 如果您的特定任务需要检测的物体类别数量与预训练模型不同,您需要修改模型的最后一层(分类层)以匹配新的类别数量。
- 冻结部分层: 通常,预训练模型的底层网络学习到的是非常通用的特征(如边缘、纹理)。这些特征对于新任务也很有用,因此可以选择"冻结"这些层的权重,使其在微调过程中不更新。这样可以减少需要训练的参数数量,防止在小数据集上过拟合,并加快训练速度。通常,我们会冻结靠近输入层的卷积层,而微调靠近输出层的、更具任务特异性的层。
- 设置学习率: 微调时通常使用比从头训练时更小的学习率。这是因为我们不希望大幅度改变已经学习到的有用特征,只是想对其进行"微调"。
- 进行再训练: 使用您准备好的特定数据集和调整后的学习率,在预训练模型的基础上继续训练。模型会逐渐适应新的数据分布和任务需求,例如学会忽略您场景中特定的"固定区域干扰"。
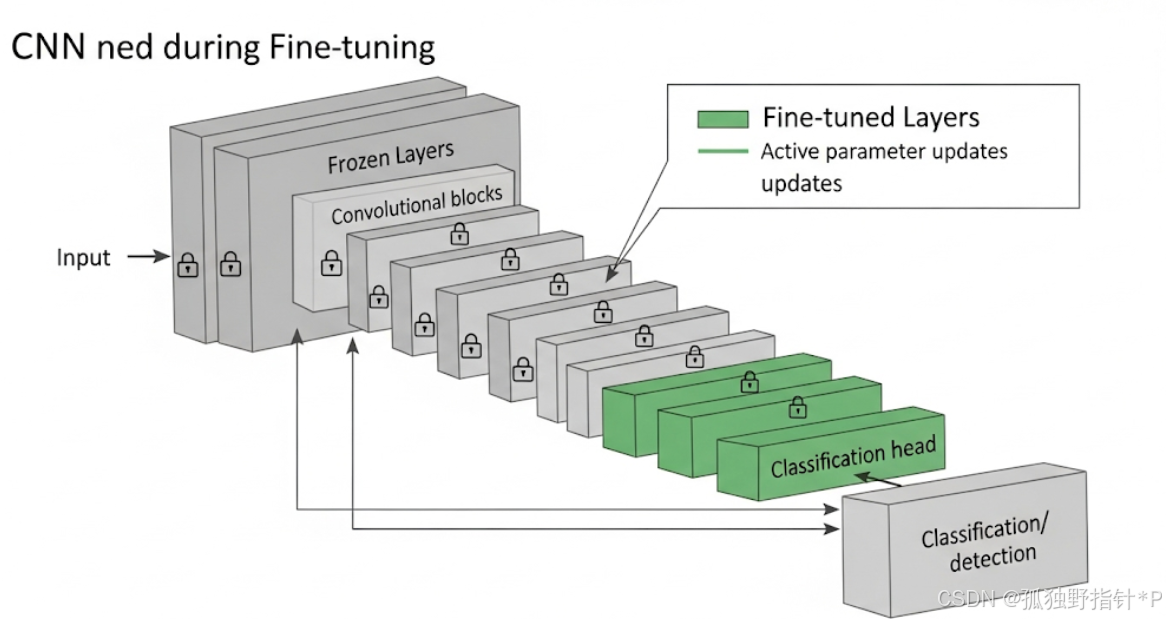
4. 为什么微调有效?
- 节省时间和资源: 从零开始训练一个深度学习模型需要大量的标注数据和强大的计算能力。微调利用了预训练模型的知识,大大减少了所需的数据量和训练时间。
- 提高性能: 对于数据量有限的特定任务,从头训练的模型可能难以学习到鲁棒的特征,容易过拟合。而微调能够利用预训练模型学到的通用特征,在此基础上针对性优化,往往能取得更好的性能。
- 适应特定分布: 微调使得模型能够更好地理解和适应特定场景的数据分布和噪声模式,从而提高在这些场景下的准确性和鲁棒性。
微调的应用场景
目标检测模型的微调应用非常广泛,几乎涵盖了所有需要定制化目标检测能力的领域:
-
特定场景下的性能提升(如您所提):
- 工业制造: 检测特定生产线上的特定零件、缺陷、产品计数等。微调可以帮助模型适应工厂独特的光照、背景和产品外观。
- 智慧城市: 针对特定路口的交通流量分析、违章停车检测、特定类型车辆识别等。
- 零售业: 货架商品识别、空置区域检测、顾客行为分析等。
- 农业: 特定作物的成熟度识别、病虫害检测、牲畜计数等。
-
新类别的检测: 假设一个通用模型能识别100种物体,但您的应用需要识别一种它之前没见过的全新物体(例如一种特殊的本地水果)。您可以通过收集少量该水果的图像数据,对现有模型进行微调,使其具备识别这种新水果的能力,而无需重新训练整个模型。
-
领域自适应 (Domain Adaptation): 当训练数据(源域)和测试数据(目标域)的分布存在显著差异时,模型性能会下降。例如,一个在白天清晰照片上训练的行人检测模型,在夜间低光照或红外图像中可能效果不佳。通过收集目标域(如夜间图像)的数据进行微调,可以帮助模型适应新的数据特征。
-
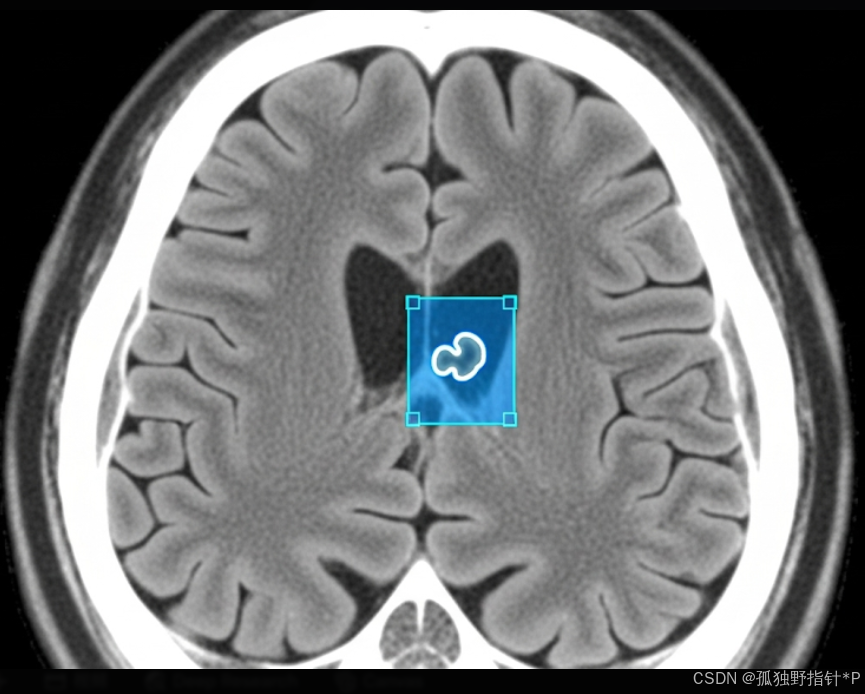
医疗影像分析: 在X光片、CT扫描、MRI图像中检测特定的肿瘤、病变或其他异常结构。通用模型可能不包含这些医学特征,通过微调,可以训练模型专注于识别这些特定的医学指标。
-
遥感图像分析: 从卫星或无人机图像中检测特定类型的建筑物、船舶、农作物或自然灾害迹象。
微调成功的关键点与其他考量
虽然微调非常强大,但要取得良好效果,还需要注意以下几点:
-
高质量的特定数据集是核心:
- 相关性: 微调数据集必须与您的目标应用场景高度相关,能够覆盖实际应用中可能遇到的各种情况(光照、角度、遮挡等)。
- 标注准确性: 即使数据量不大,标注的质量也至关重要。错误的标注会误导模型的学习。
- 数据量: 虽然微调不需要像预训练那样海量的数据,但数据量也不能过少,否则容易导致过拟合。具体数量取决于任务的复杂性和与预训练任务的相似性。
-
学习率的选择: 如前所述,微调时通常选择较小的学习率(例如预训练时的1/10或1/100)。可以从一个较小的值开始,然后根据训练过程中的验证集表现进行调整。
-
冻结与解冻策略:
- 数据量小或任务相似: 如果您的特定数据集很小,或者新任务与预训练任务非常相似,可以考虑冻结更多底层网络(特征提取器),只微调顶部的分类/回归层,甚至只替换分类头后训练分类头。
- 数据量较大或任务差异大: 如果数据量相对充足,或者新任务与预训练任务差异较大,可以考虑解冻更多层,甚至微调整个网络,但依然使用较小的学习率。
- 分阶段微调: 一种常见的策略是先冻结所有层,只训练新添加的分类头;然后解冻一部分顶层网络进行微调;最后,如果数据充足,可以解冻更多层甚至整个网络,用更小的学习率进行整体微调。
-
过拟合的防治: 由于微调数据集通常较小,模型很容易在训练数据上表现很好,但在未见过的数据上表现差(即过拟合)。
- 数据增强 (Data Augmentation): 通过旋转、裁剪、调整亮度和对比度、加噪声等手段人为增加训练样本的多样性。
- 正则化 (Regularization): 如L1/L2正则化、Dropout等。
- 早停 (Early Stopping): 在验证集上监控模型性能,当验证集性能不再提升甚至开始下降时,停止训练。
-
评估指标的正确选择: 根据您的具体应用场景,选择合适的评估指标(如mAP, Precision, Recall, F1-score等)来衡量模型性能。
-
迭代与实验: 微调往往是一个需要多次实验和迭代的过程。不同的预训练模型、不同的冻结策略、不同的超参数(学习率、批大小等)都可能带来不同的结果。耐心尝试,并记录实验结果,是找到最优方案的关键。
总结与展望
目标检测模型的微调技术,是连接通用人工智能与特定领域应用的桥梁。它使得我们能够站在巨人的肩膀上,利用强大的预训练模型,快速、高效地解决现实世界中各种复杂场景下的目标检测问题。通过精心准备特定场景数据,并采用合适的微调策略,我们可以显著提升模型在目标任务上的性能,真正实现AI技术的落地应用。
未来,随着自监督学习、少样本学习等技术的发展,我们期望能够用更少、甚至无需人工标注的数据来进行更高效的微调,进一步降低AI应用的门槛,拓展其应用边界。
希望这篇博客能帮助您更好地理解和应用目标检测模型的微调技术!