终极数据结构详解:从理论到实践
我将从 底层原理 、时间复杂度 、空间优化 、实际应用 和 代码实现 五个维度,彻底解析数据结构。内容涵盖:
- 线性结构(数组、链表、栈、队列)
- 非线性结构(树、图)
- 高级结构(哈希表、堆、跳表、并查集等)
- 各语言标准库实现对比
- 工业级优化技巧
一、线性数据结构深度解析
1. 数组(Array)
底层实现
- 内存模型 :连续内存块,通过
基地址 + 偏移量直接访问(arr[i] = *(arr + i * sizeof(type)))。 - 动态扩容 :
- Python
list:超额分配(over-allocation),扩容公式new_size = (old_size >> 3) + (old_size < 9 ? 3 : 6)。 - C++
vector:2倍扩容(均摊O(1)),但可能因内存碎片导致性能抖动。
- Python
时间复杂度
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 随机访问 | O(1) | 直接计算内存地址 |
| 头部插入 | O(n) | 需移动所有元素 |
| 尾部插入 | O(1) 均摊 | 考虑扩容成本 |
| 删除中间 | O(n) | 需移动后续元素 |
实战技巧
python
# Python 动态数组优化
arr = [None] * 1000 # 预分配避免频繁扩容
arr.append(1) # 均摊O(1)2. 链表(Linked List)
内存布局对比
| 类型 | 每个节点内存消耗 | 适用场景 |
|---|---|---|
| 单链表 | data + 1指针 (8字节) |
单向遍历(如LRU缓存) |
| 双链表 | data + 2指针 (16字节) |
需要反向操作(如Linux内核) |
| XOR链表 | data + 1指针 (8字节) |
内存敏感场景(嵌入式系统) |
核心算法
- 快慢指针找中点(用于归并排序):
python
def find_middle(head):
slow = fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
return slow各语言实现差异
| 语言 | 标准库实现 | 特点 |
|---|---|---|
| C++ | std::list |
双链表,支持O(1) splice |
| Java | LinkedList |
双链表,线程不安全 |
| Python | 无内置,用deque |
deque实为双向循环链表 |
二、非线性结构深度剖析
1. 树(Tree)
红黑树 vs AVL树
| 特性 | 红黑树 | AVL树 |
|---|---|---|
| 平衡标准 | 黑色高度平衡 | 严格左右子树高度差≤1 |
| 插入/删除 | O(1)旋转(均摊) | O(log n)旋转 |
| 查找效率 | 稍慢(近似平衡) | 更快(严格平衡) |
| 应用场景 | C++ map/set, Java TreeMap | 数据库索引 |
B树/B+树
- B树:每个节点存储键值,用于文件系统(如NTFS)。
- B+树:非叶子节点仅存键,叶子节点链表连接,用于MySQL索引。
2. 图(Graph)
存储方案对比
| 方法 | 空间复杂度 | 适用场景 |
|---|---|---|
| 邻接矩阵 | O(V²) | 稠密图,快速判边存在 |
| 邻接表 | O(V+E) | 稀疏图,节省空间 |
| 边列表 | O(E) | Kruskal算法 |
关键算法优化
- Dijkstra算法 :
- 普通实现:
O(V²) - 二叉堆优化:
O(E + V log V) - Fibonacci堆优化:
O(E + V log V)(理论最优)
- 普通实现:
python
# 邻接表表示图
graph = {
0: {1: 4, 2: 1},
1: {3: 1},
2: {1: 2, 3: 5},
3: {}
}三、高级数据结构实战
1. 哈希表(Hash Table)
冲突解决方案对比
| 方法 | 实现方式 | 优缺点 |
|---|---|---|
| 链地址法 | 数组+链表/红黑树 | 简单,但指针消耗内存 |
| 开放寻址法 | 线性探测/二次探测 | 缓存友好,但易聚集 |
| 布谷鸟哈希 | 双哈希函数+踢出策略 | 高负载因子(>90%) |
Java HashMap优化
java
// Java 8后的优化:链表转红黑树
if (binCount >= TREEIFY_THRESHOLD - 1)
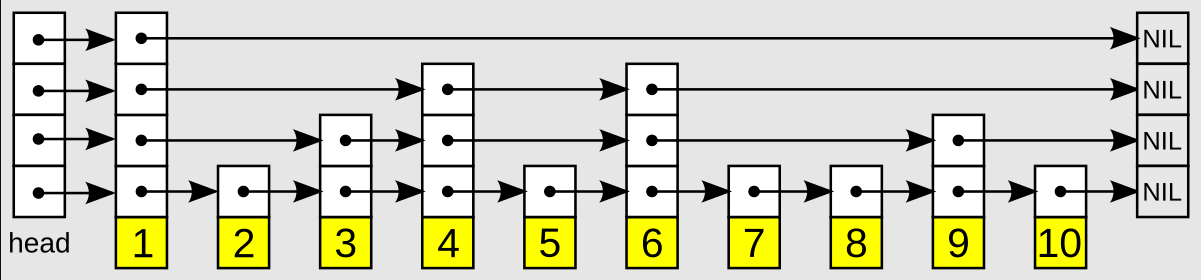
treeifyBin(tab, hash);2. 跳表(Skip List)
层级概率控制
- Redis的
zset实现:- 层高概率:
1/4(相比经典跳表的1/2),减少内存占用。 - 最大层数:
32(支持亿级数据)。
- 层高概率:
四、工业级优化技巧
-
CPU缓存友好设计:
- 数组 vs 链表:数组顺序访问触发预加载(prefetching)。
- 结构体对齐:
__attribute__((packed))(C/C++)。
-
内存池技术:
- C++
std::allocator自定义内存分配。 - Python
__slots__减少对象内存开销。
- C++
-
并发安全:
- Java
ConcurrentHashMap:分段锁+CAS。 - Go
sync.Map:读写分离+原子操作。
- Java
五、各语言标准库对比
| 数据结构 | C++ | Python | Java |
|---|---|---|---|
| 动态数组 | vector |
list |
ArrayList |
| 哈希表 | unordered_map |
dict |
HashMap |
| 红黑树 | map/set |
无内置 | TreeMap/TreeSet |
| 优先队列 | priority_queue |
heapq |
PriorityQueue |
六、终极选择指南
是 是 否 否 是 否 需要快速查找? 是否需要有序? 红黑树/TreeMap 哈希表 频繁插入删除? 链表 数组
Ai收集的,后面慢慢优化吧