锁的分类
1.乐观锁和悲观锁
**乐观锁:**预测接下来锁冲突的概率不大,就少做一些工作。
**悲观锁:**预测接下来锁冲突的概率很大,就多做一些工作。
2.重量级锁和轻量级锁
**重量级锁:**锁的开销比较大(和悲观锁有关联,但乐观锁时预测,并非实际开销)
**轻量级锁:**锁的开销比较小(和乐观锁有关联)
3.自旋锁和挂起等待锁
**自旋锁:**轻量级锁的实现
当一个线程尝试获取自旋锁,但发现锁已经被其他线程持有(即锁被"占用了")时,它不会立即进入休眠或阻塞状态。相反,它会持续地循环(while)检查锁是否被释放。这个循环检查的过程就是"自旋"。线程会不断地占用 CPU,直到锁被释放为止。
使用自旋锁的前提是预期锁冲突概率不大,只要其他线程释放了锁,它就能第一时间加锁成功;
但如果有很多线程要加锁,就不要使用自旋锁,因为会浪费cpu资源。
**挂起等待锁:**重量级锁的实现
当一个线程尝试获取等待挂起锁,但发现锁已经被其他线程持有时,它会立即被挂起(阻塞)。被挂起的线程会放弃 CPU,进入"等待"或"休眠"状态,不再消耗 CPU 资源。只有当持有锁的线程释放锁后,操作系统或调度器才会将等待队列中的一个线程唤醒,使其重新竞争锁。
阻塞状态和运行状态的切换需要开销
4.可重入锁和不可重入锁
**可重入锁:**如synchronized,加锁一段代码,锁里面可以再进行一次加锁,锁里面可以嵌套多个锁,里面是用计数器这种方式对加锁的数量进行计数,并判断是否解锁,是可重入锁。
**不可重入锁:**系统自带的锁,不能连续加锁两次。
5.普通互斥锁和读写锁
普通互斥锁: 像 synchronized 关键字或 ReentrantLock 这样的传统互斥锁(也称为排他锁),在任何时刻都只允许一个线程访问被保护的共享资源。
**读写锁:**这里加锁的情况分为两种:给读加锁,给写加锁
读锁(共享锁) :当一个线程持有读锁时,其他线程也可以同时获取读锁。这意味着多个读线程可以同时并发地访问共享资源,只要没有线程持有写锁。读锁之间是共享的,互不阻塞。
写锁(排他锁) :当一个线程持有写锁时,任何其他线程(无论是读线程还是写线程)都不能获取读锁或写锁。写锁是排他的,它会阻塞所有其他读写操作,确保在数据修改时数据的一致性。
为啥要引入读写锁?
- 提高读并发性:允许多个读线程同时访问共享资源,显著提高了读操作的吞吐量和性能。
- 保证数据一致性:在写操作发生时,通过写锁保证了数据的独占访问,防止了数据在修改过程中被其他线程读取或修改,维护了数据的一致性和完整性。
- 优化性能 :在读操作远多于写操作的场景下,读写锁能够显著优于传统的互斥锁,因为它减少了不必要的线程阻塞和上下文切换。
6.公平锁和非公平锁
此处的公平定义为:先来后到原则
场景:很多线程去尝试加一把锁时,一个线程拿到锁,其它线程等待;
当这把锁被释放时,哪个线程能够拿到锁?
**公平锁:**先来后到顺序
**非公平锁:**按照"均等"概率(随即调度),竞争锁
系统加锁api默认为非公平,需要引入队列,来实现公平锁。
java中的synchronized属于哪种锁?
:synchronized具有自适应
当前锁冲突的激烈程度不大,它就处于乐观锁、轻量级锁、自旋锁;
当前锁冲突的激烈程度很大,它就处于悲观锁、重量级锁、等待挂起锁
synchronized不是读写锁,是可重入锁,是非公平锁
synchronized几个重要机制
1.锁升级
-
偏向锁 (Bias Lock)
- 思想:懒汉模式,能不加锁就不加锁。
- 特点:当只有一个线程反复访问同步代码时,它就"偏向"这个线程。锁只是在对象头做个标记,几乎没有开销。该线程下次再来,直接通过标记就能进入,无需同步操作。
- 作用 :在无竞争情况下,大幅提高效率。
- 升级 :一旦有第二个线程来竞争,偏向锁就会被撤销,升级为轻量级锁。
-
轻量级锁 (Lightweight Lock)
- 思想 :通过自旋(线程忙等循环尝试获取锁)实现。
- 特点 :适用于少量竞争(线程交替进入)的场景。当锁被释放时,自旋的线程能快速获取锁。
- 优点:避免了线程阻塞和唤醒的开销(上下文切换)。
- 缺点:如果竞争激烈或持有锁的时间长,自旋会白白消耗大量 CPU 资源。
- 升级:当竞争变得非常激烈,自旋无法快速获取锁时,会升级为重量级锁。
-
重量级锁 (Heavyweight Lock)
- 思想 :通过挂起等待实现。
- 特点 :适用于大量竞争的场景。获取不到锁的线程会被阻塞(挂起),放弃 CPU 资源,进入等待队列。等锁被释放后,再被唤醒去竞争。
- 优点:线程阻塞让出 CPU,节省了 CPU 资源,可以被其他任务利用。
- 缺点:涉及线程上下文切换,开销最大。
- 注意 :在当前 JVM 版本中,
synchronized锁一旦升级到重量级锁,通常不会再降级。

2.锁消除
锁消除是 JVM 的一种智能优化。
工作原理 :如果 JVM 发现某段 synchronized 代码在任何情况下都不可能发生多线程竞争 (比如同步的是一个局部变量),它就会直接把这个锁完全移除,节省开销。
与偏向锁的区别:
锁消除 :JVM 提前判断 (编译时),觉得没必要加锁,直接删除。
偏向锁 :JVM 运行时观察 ,发现当前只有一个线程在用,就给它一个"专属标记",下次这个线程来了就直接进。有竞争时才会升级。
3.锁粗化
锁粗化是 JVM 的一种性能优化。
频繁的加锁解锁(涉及到锁竞争),肯定会消耗更多的硬件资源,但是如果能把一段代码的多个加锁、解锁操作,优化成只有一次加锁、解锁,这样也能提高效率。
CAS(Compare-And-Swap)
CAS 是一种 无锁的原子操作 ,全称是 比较并交换,它的作用是:
-
比较内存中的某个值和期望值是否相等,
-
如果相等,就将内存中的值更新为新值,
-
如果不相等,说明被别的线程改过,就不做修改。
这个过程是原子性的,不会被线程调度打断。
CAS 的三个操作数
-
内存地址(V):需要更新的变量的地址
-
期望值(A):当前线程期望内存中变量的值
-
新值(B):希望更新成的新值
CAS 的工作过程
-
线程读取内存地址 V 中的值
-
比较该值是否等于期望值 A
-
如果相等,将 V 更新为新值 B,操作成功
-
如果不相等,说明其他线程已修改,操作失败,通常会重试
CAS 优点
-
无锁,避免了加锁带来的上下文切换和阻塞,提高性能
-
实现原子操作,保证线程安全
CAS 缺点
-
ABA 问题:值可能从 A 变成 B 又变回 A,导致 CAS 误判成功
-
循环时间长:如果竞争激烈,CAS 重试次数多,性能下降
-
只能保证一个变量的原子操作,不适合复杂操作
CAS 在 Java 中的应用
Java 的 java.util.concurrent.atomic 包中大量用到了 CAS,比如 AtomicInteger 的 incrementAndGet(),底层就是 CAS 实现。
什么是 ABA 问题?
ABA问题描述的是在使用CAS操作时,比较的值从A变成了B,又变回了A,这种情况下CAS操作会误以为数据没有被修改过,从而导致错误。
举个简单的例子
假设某个变量初始值是A:
-
线程1执行CAS时,期望值是A。
-
在这期间,线程2把变量从A改成了B,然后又改回了A。
-
线程1执行CAS比较时,发现变量还是A(和期望值相同),CAS成功。
-
但实际上变量经历了变化,线程1却没有察觉。
这在某些场景下会带来严重错误,尤其是在基于CAS实现的锁或者内存管理时。
为什么ABA会导致问题?
CAS只关心值是不是和期望值相等,不关心中间是否有变化。
如果值变成别的东西再变回来了,CAS操作会误以为值一直没变过。
如何解决ABA问题?
1. 使用版本号(带标记的引用)
-
将值和版本号绑定成一个整体(如结构体或对象),每次修改时,版本号增加。
-
CAS比较时不仅比较值,还比较版本号,避免ABA问题。
Java中的AtomicStampedReference就是基于这种思路。
2. 使用带有时间戳的对象引用
- 每次更新值时附带时间戳或版本号,保证唯一性。
Java中的解决方案
-
AtomicStampedReference<V>:提供了带"版本号"的原子引用。 -
AtomicMarkableReference<V>:提供了带"标记位"的原子引用,能解决类似问题。
JUC并发包
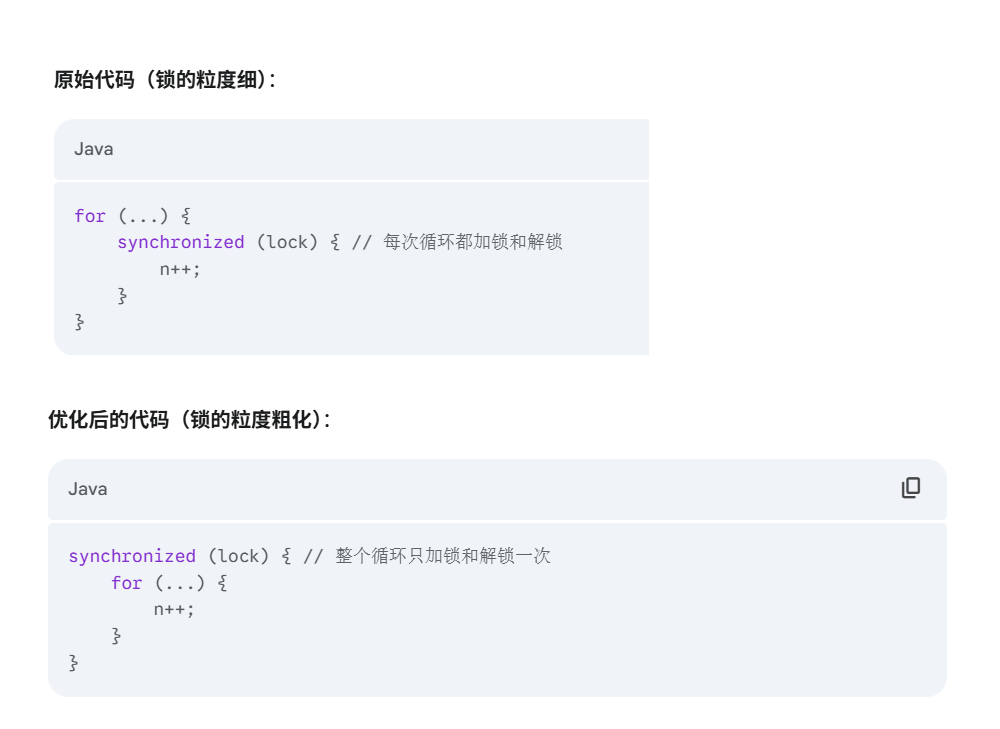
1.Callable接口
创建线程的一种方式,要返回结果。(Runnable不返回结果)
因为Thread没有关于Callable的构造函数,所有用FutureTask。

由此可以复习一下线程的创建方式:
1.继承Thread,重写run(创建单独类,也可匿名内部类)
2.实现Runnable,重写run(创建单独类,也可匿名内部类)
3.实现Callable,重写run(创建单独类,也可匿名内部类)
4.使用lambda表达式
5.ThreadFactory工厂
6.线程池
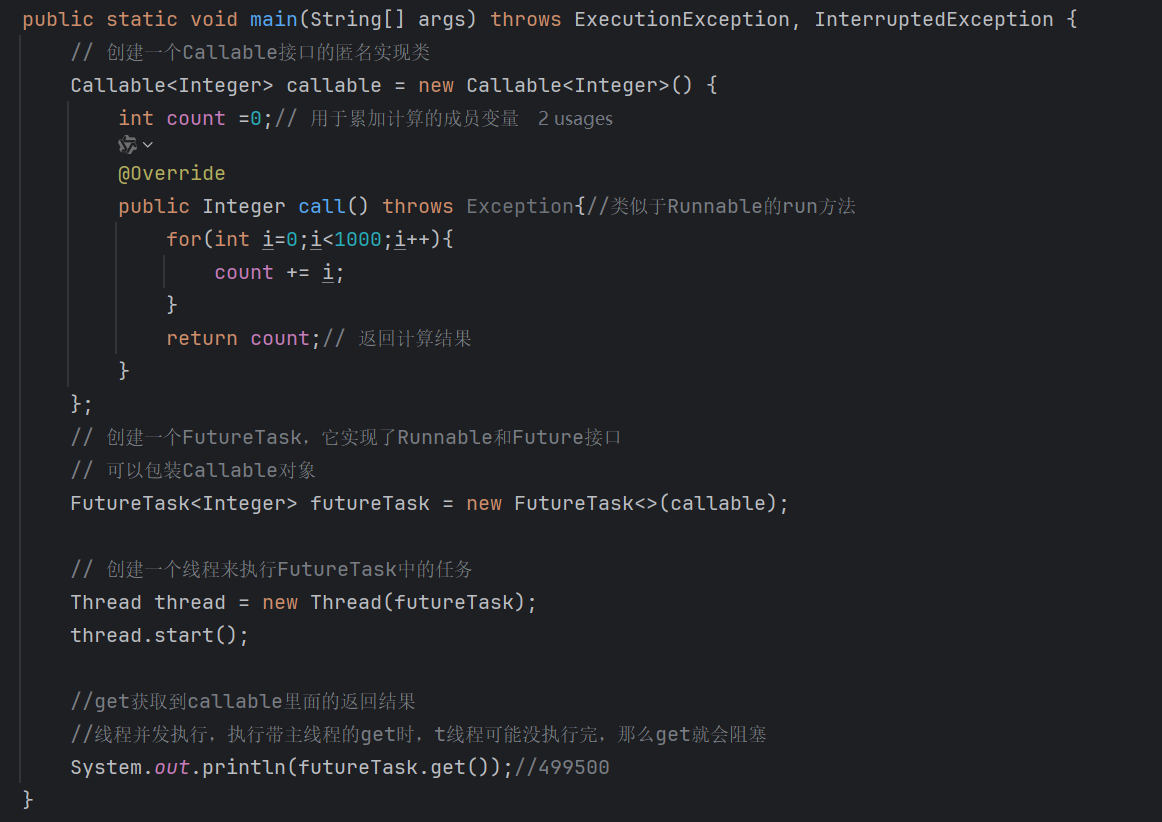
2.ReentrantLock
特性:
1.在加锁的时候有两种方式:lock和tryLock,更多操作空间
2.提供了公平锁的实现(默认非公平锁)
3.提供更强大的等待通知机制(搭配Condition类,实现等待通知)。
4.可重入
synchronized和ReentrantLock之间的区别:
1.synchronized自动加锁解锁,ReentrantLock需要手动加锁解锁(容易忘记解锁)。
2.synchronized是非公平锁,ReentrantLock默认非公平,但可实现公平锁。
3.synchronized不能响应中断,ReentrantLock可以响应中断,解决死锁问题。
4.synchronized时JVM层面通过监视器实现的;ReentrantLock基于AQS实现。
ReentrantLock 可以结合 Condition 实现类似 wait/notify 的线程通信,但更灵活
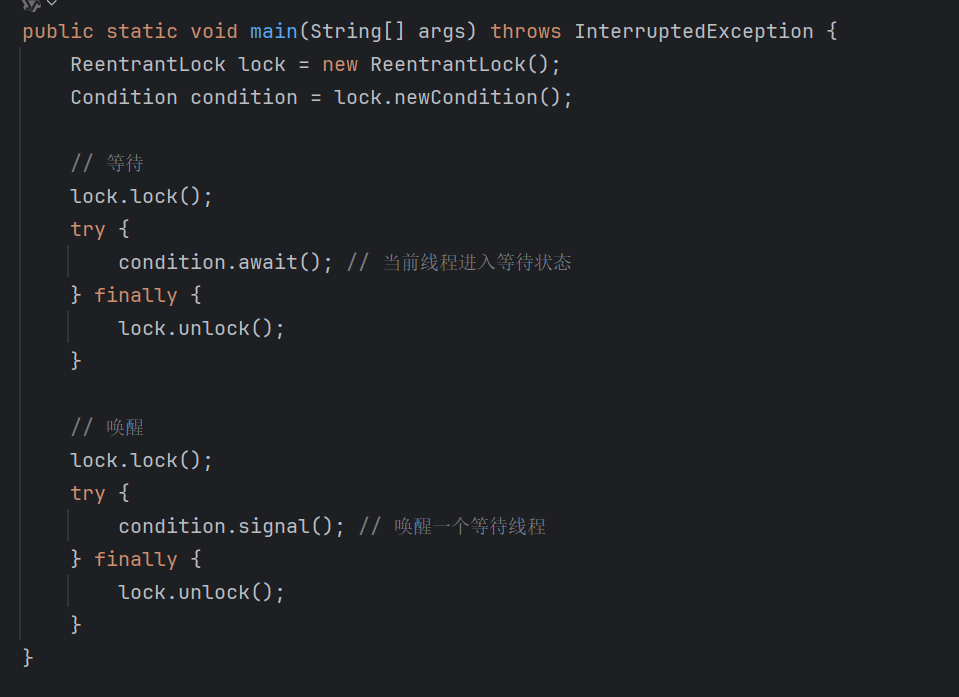
3.Semaphore(信号量)
Semaphore 是 JUC(java.util.concurrent)包中提供的一个并发工具类,它通过控制许可数量,来限制同时访问某个资源的线程数量。
线程在访问资源前必须先获取许可证,使用完毕后释放。
可以将它比作一个"车位计数器",比如有 3 个车位,最多同时容纳 3 辆车,多的就得排队等位。
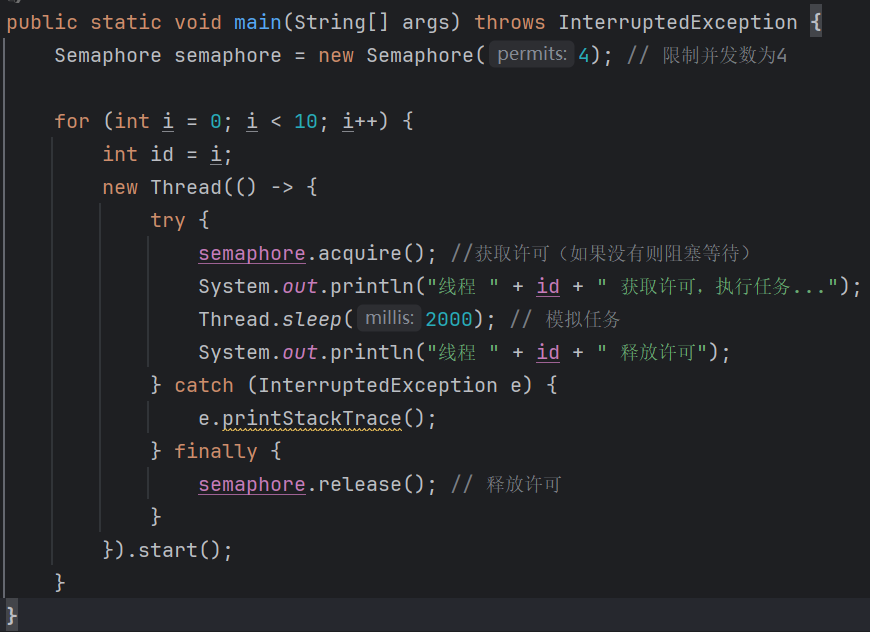
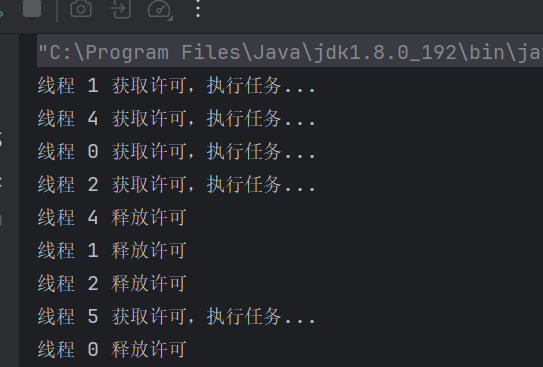
Semaphore 的原理
Semaphore 内部基于 AQS(AbstractQueuedSynchronizer) 实现,其核心是:
-
每次
acquire()会尝试将许可数减 1; -
若许可数不足,则线程进入等待队列;
-
每次
release()会将许可数加 1,并唤醒等待线程
4.CountDownLatch
CountDownLatch 是 JUC 包中提供的一个 同步辅助工具类 ,用于控制一个或多个线程 等待其他线程完成操作
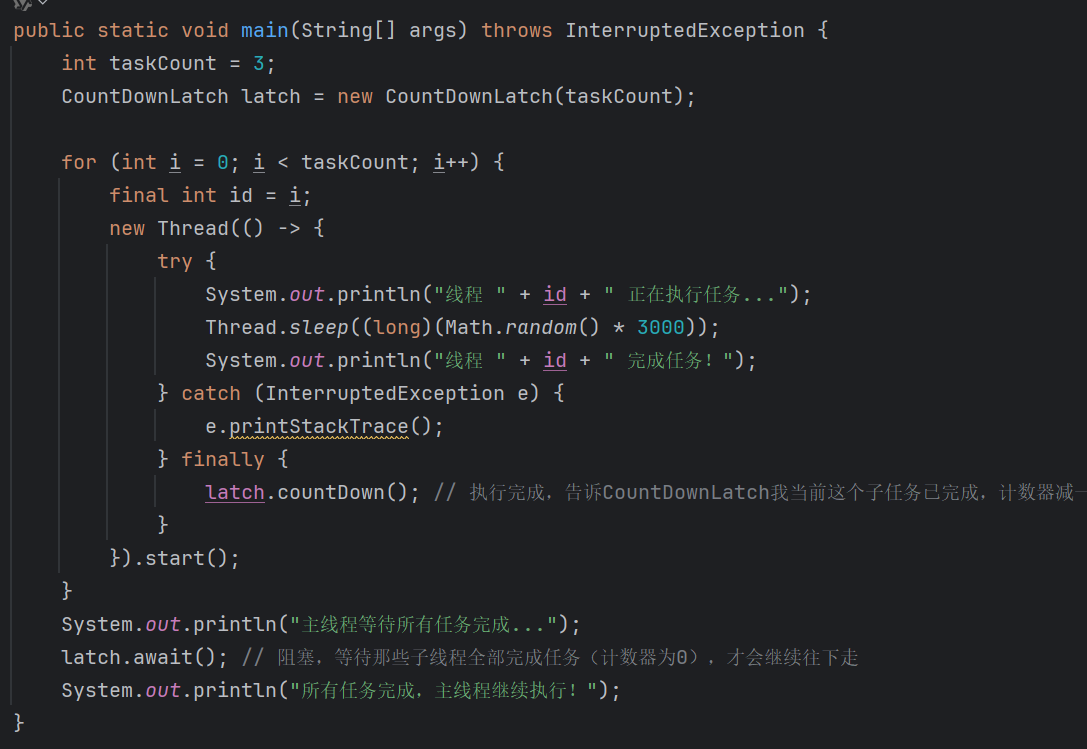
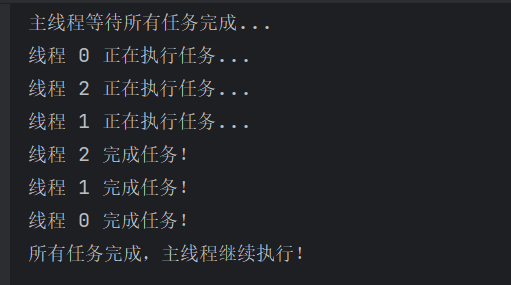
CountDownLatch的原理
-
CountDownLatch内部使用 AQS(AbstractQueuedSynchronizer) 实现; -
初始时维护一个状态值(count);
-
countDown()将状态减一; -
await()阻塞,直到状态为 0。
注意:一次性使用,count=0之后不可重置
应用:
多个任务并发执行,主线程等待结果;主线程等待多个子线程加载完毕
线程安全的集合类
一、早期线程安全集合(不推荐)
-
Vector、Stack、Hashtable 等类是 Java 早期引入的集合类,它们通过
synchronized保证线程安全。 -
它们的方法都是加锁的,例如:
get()、put()都是同步方法。 -
缺点:
-
性能差:粗粒度锁,全部方法加锁,效率低。
-
不灵活:很少适应现代并发编程的高性能要求。
-
-
结论 :现在已经不推荐使用,可能在未来被移除。
二、对非线程安全集合加锁(较推荐)
-
示例
Collections.synchronizedList(new ArrayList<>()); -
本质是对普通集合加一层同步包装,返回一个线程安全的集合。
-
特点:
-
底层依然是
ArrayList等。 -
多线程访问时线程安全,但 遍历时仍需手动加锁。
-
类似"临时解决方案",适合简单场景。
-
三、现代推荐:并发容器类
1. CopyOnWriteArrayList(适合读多写少)
-
写时复制思想(Copy on Write):
-
修改时会复制一份副本,在副本上修改。
-
修改完成后替换原数据(往往是一个引用)。
-
-
优点:
-
读写分离:读操作不加锁,效率高。
-
适用于读多写少的场景(如系统配置的更新,配置文件不大,一个线程修改之后,重新加载)。
-
-
缺点:
-
当前操作的ArrayList不能太大,不然拷贝成本高,修改代价大(需要复制数组)。
-
不适合频繁修改的情况,适合一个线程去修改,而不是多个线程同时修改。
-
2.HashTable和ConcurrentHashMap
1.HashTable
只是简单把关键方法 加上synchronized关键字;
只要两个线程操作同一个Hashtable会出现锁竞争
2.ConcurrentHashMap
ConcurrentHashMap 是 Java 并发集合框架 (java.util.concurrent) 中的一个高性能线程安全的 HashMap 实现,适用于高并发场景。
它通过分段锁(JDK 7)和 CAS + synchronized(JDK 8) 实现线程安全
JDK7:分段锁(Segment)
将数据分成多个Segment(默认16个),每个Segment都是一个独立的HashEntry数组。
写操作只锁对应的Segment,不影响其它Segement的读写。
缺点:并发度受Segment数量限制。
JDK8:CAS+synchronized
改用Node数组+链表/红黑树(类似HashMap)
读操作:完全无锁(volatile保证内存可见性)
写操作:
使用CAS(Compare-And-Swap)尝试无锁修改(比如使用变量记录hash表中的元素个数);
如果CAS失败,则用synchronized锁住单个头节点Node;
扩容:支持多线程协同扩容(helpTransfer)
ConcurrentHashMap扩容机制详解:
1.触发扩容的条件:
a.元素数量超过阈值:
当元素数量超过capacity*loadFactor时,触发扩容(默认负载因子为0.75)
b.链表过长
当链表长度达到8且数组长度小于64时,优先扩容而非转为红黑树
c.协助扩容
当一个线程发现其它线程正在扩容时,会协助进行扩容(Help Transfer机制)
对扩容进行优化:
Hashtable和HashMap扩容时需要把所有元素拷贝一遍,耗时;
ConcurrentHashMap做出了优化,需要扩容时,并非一次完成,每次搬运一部分数据。



面试题:
ConcurrentHashMap 不允许 null 是为了避免在多线程下歧义,比如返回 null 是表示键不存在,还是值就是 null?

ConcurrentHashMap扩容时如何保证线程安全?

ConcurrentHashMap为啥不允许为null?

请你讲讲 ConcurrentHashMap 的读操作和写操作是如何协同工作以实现高并发的?

ConcurrentHashMap 和 CopyOnWriteArrayList 比较
