一、grep(文本查找)
grep,globally search a regular expression and print
文本搜索工具(类似于windows中的查找功能?),支持正则表达式,常用于以下场景:
1. 在ls的输出结果中过滤指定文件名或后缀的文件
 root家目录下过滤包含temp的文件
root家目录下过滤包含temp的文件
2. 在文本文件中匹配特定内容
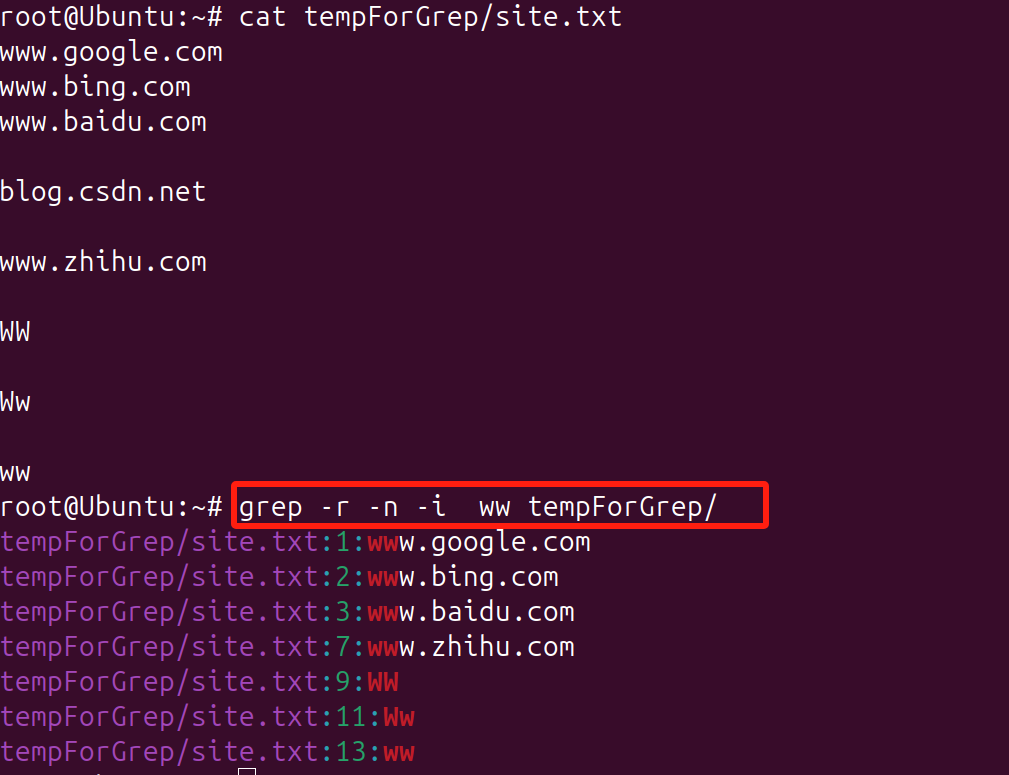 tempForGrep目录下的文档site.txt,记录若干网址和字符
tempForGrep目录下的文档site.txt,记录若干网址和字符
-r 递归查询当前目录下子文件的内容
-n 标记查找内容的行号
-i 忽略大小写
3. 结合正则表达式匹配邮箱或ip
4. 递归查找子目录(忽略文件/文件夹)
grep -r **--exclude-dir=**temp2 com ./ ,在当前目录下递归查找文件,--exclude-dir=temp2,可以忽略子目录temp2下的site2.txt文件,该功能常用来排除不需要查阅的代码库文件。
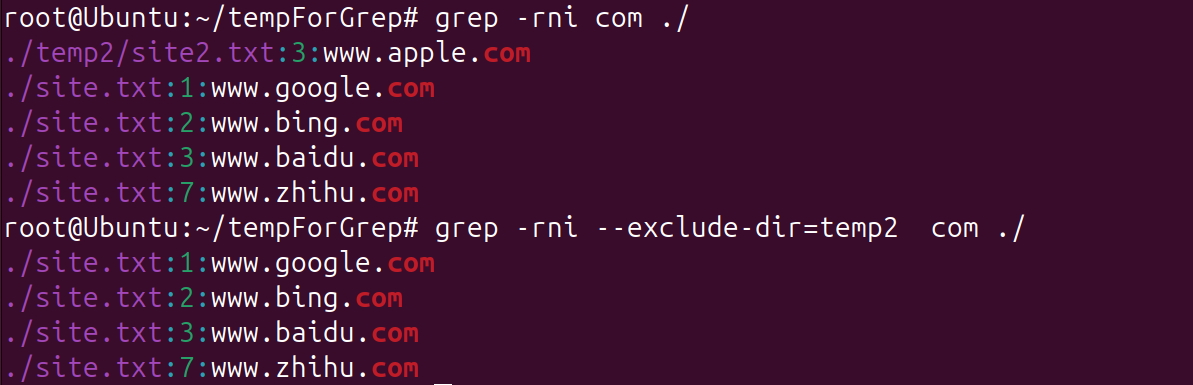 --exclude-dir= 忽略目录
--exclude-dir= 忽略目录
参考链接:grep时排除指定的文件和目录 - dolinux - 博客园
 grep简介
grep简介
 windows,office中的查找功能
windows,office中的查找功能
 grep支持的正则表达式符号
grep支持的正则表达式符号
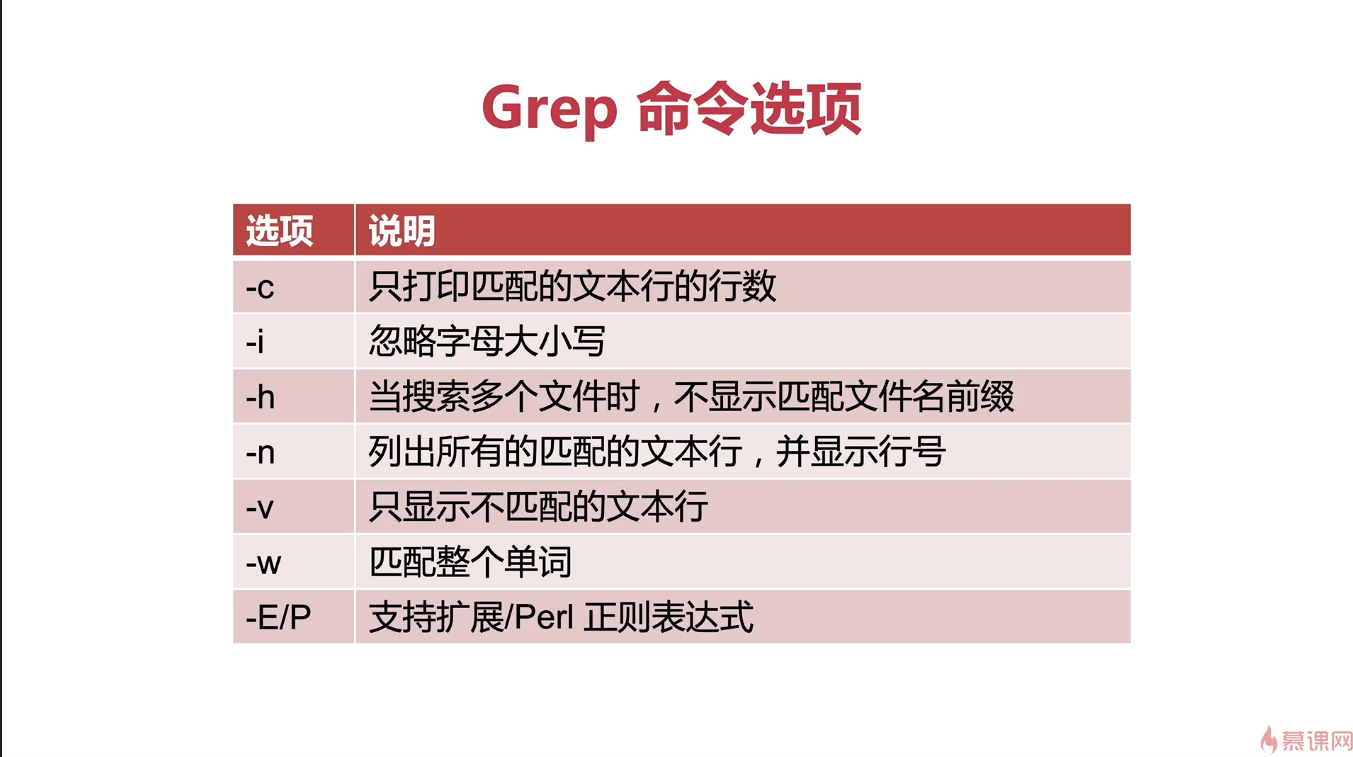 grep 命令参数
grep 命令参数


二、awk(文本样式扫描与处理)
awk是三个创始人名字的缩写(Alfred Aho,Peter Weinberger,Brian Kernighan),具有不同的版本AWK、NAWK、GAWK。
 awk简介
awk简介
awk 工具使用时,需要包含BEGIN、BODY、END三个代码块,对应如下功能:
BEGIN块,程序初始化,变量定义及赋值,可以省略。
body块,逐行读取文档每一行,并执行处理。
END块,用于程序结束后的简单输出,可以省略。
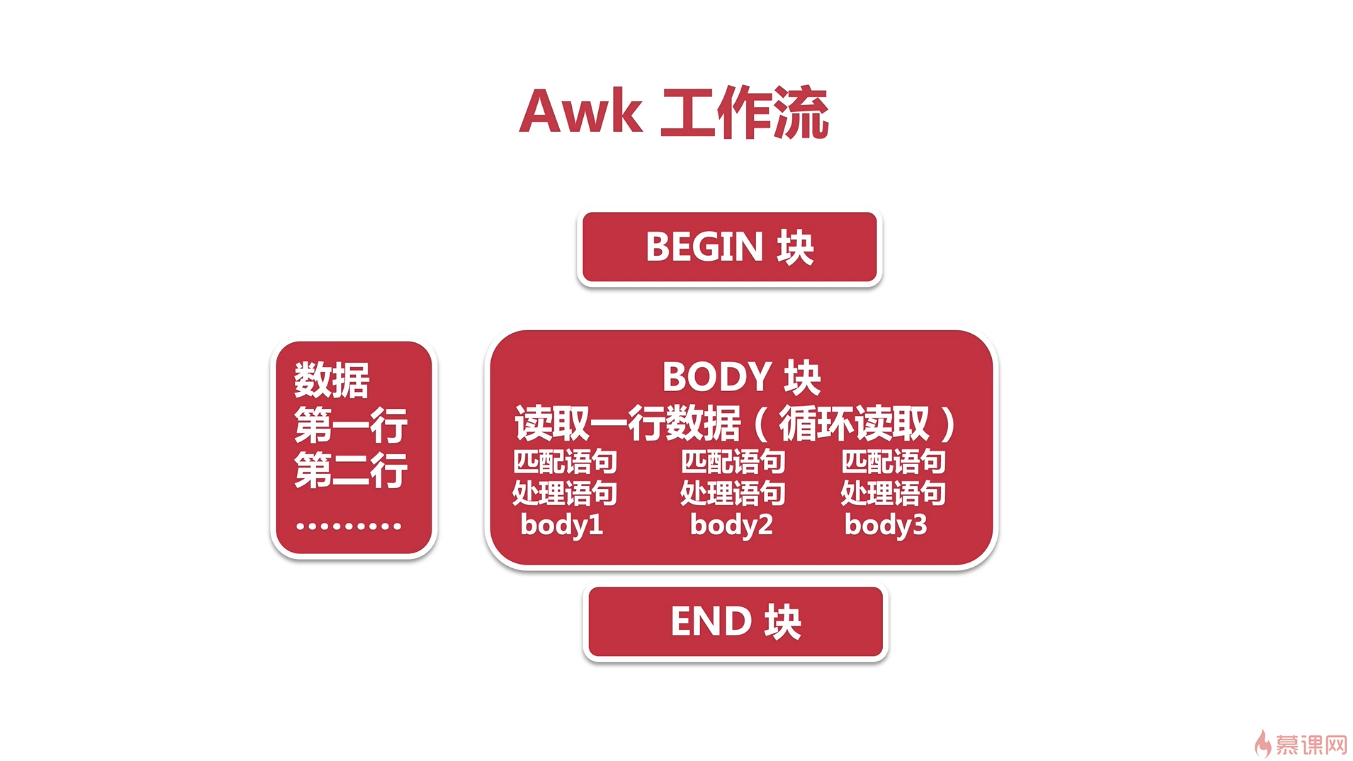 awk工作示意图
awk工作示意图
 代码块功能
代码块功能
内置变量 中,最常用的就是NR ,从0计数,每读取一行文件自加一,当有多个文件的时候,连续计数不中断;FNR表示,从0计数,每当awk打开一个新文件的第一行,FNR从0开始自加一。NR==FNR表示处理第一份文件,BR>FNR表示处理第二份文件。
FS,域分隔符/列分隔符,也可以用awk -F " : "参数指定域分隔符,系统默认的域分隔符是空格。
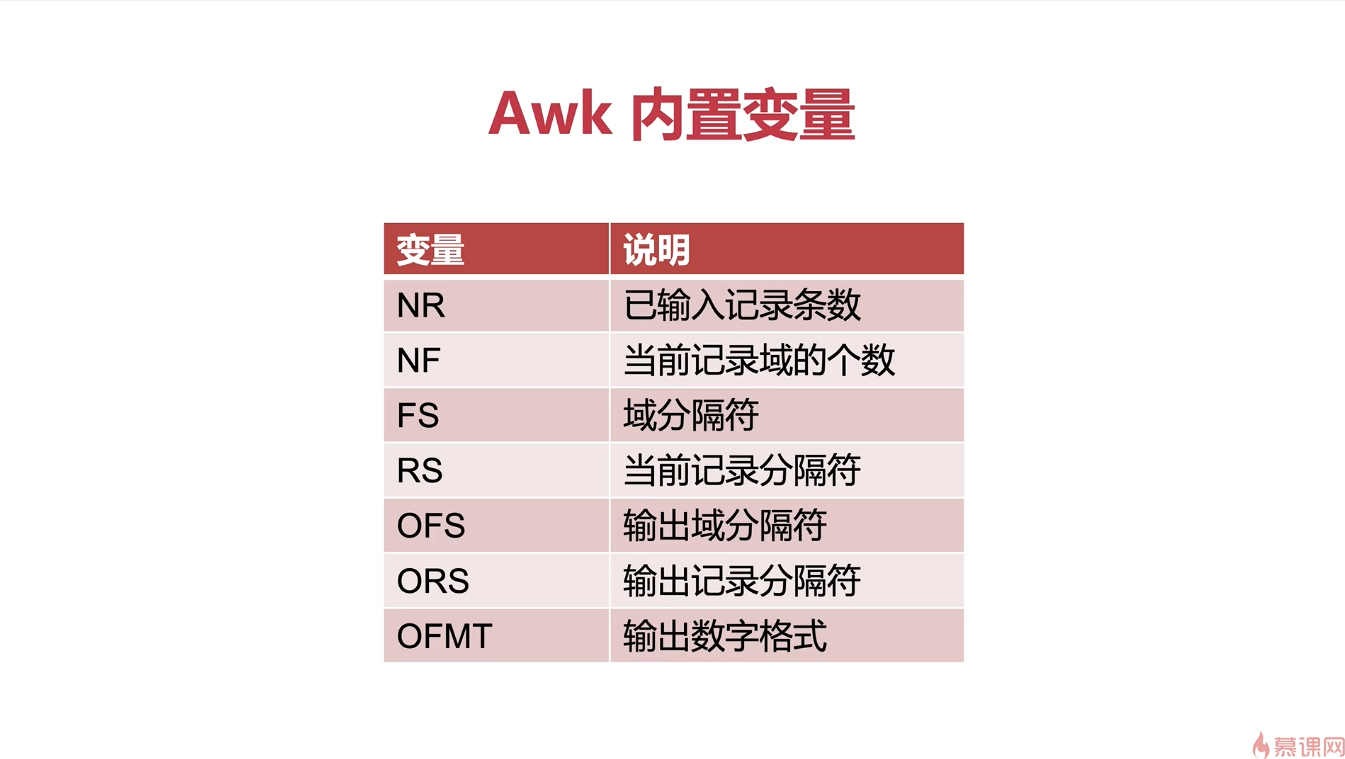 awk内置变量
awk内置变量
awk的主要使用场景:

- 过滤指定列的数据:
$1表示第一列,-F ":"和BEGIN{FS=":"}都表示指定分隔符
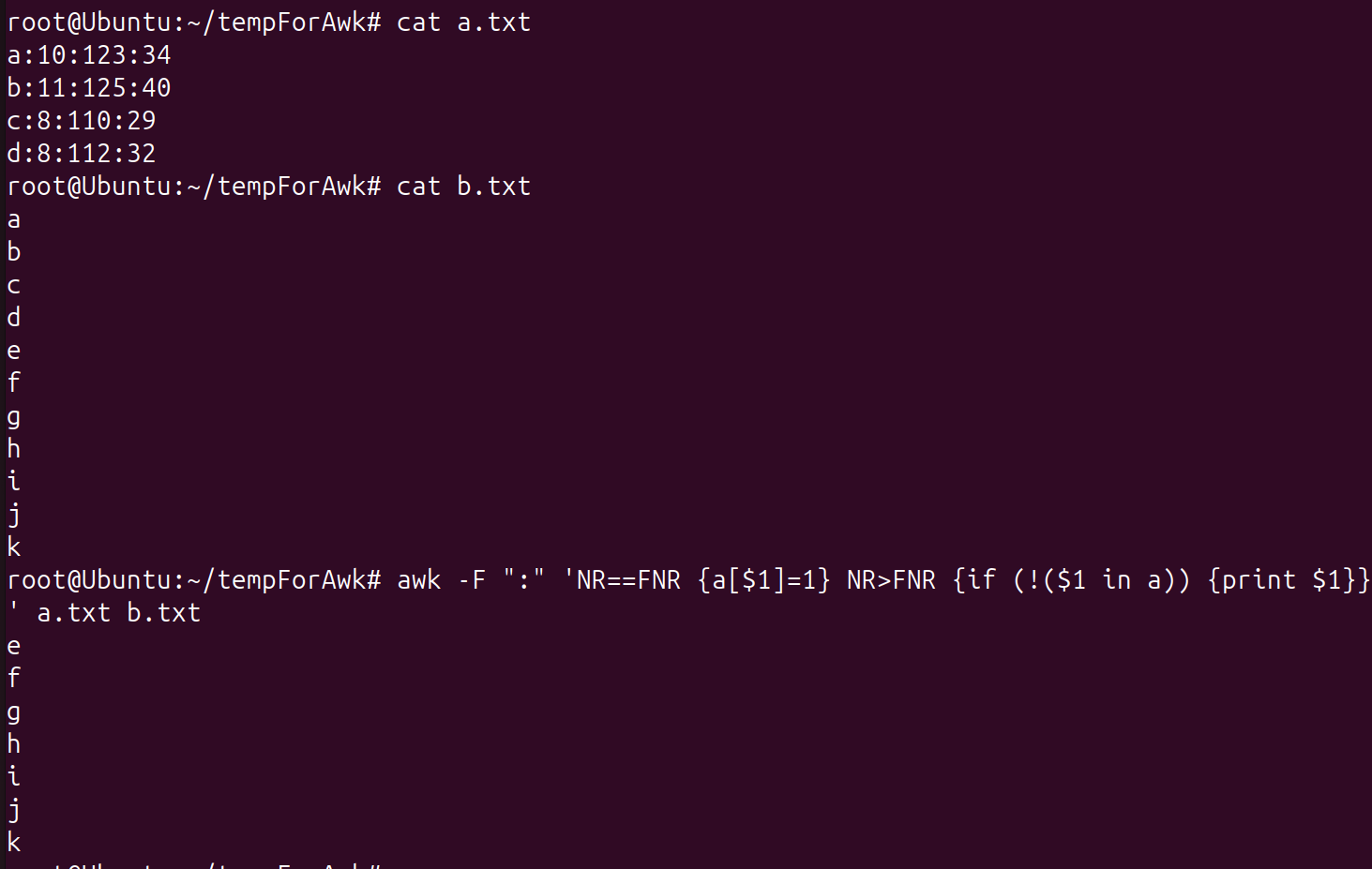 awk输出两份文件的差别项
awk输出两份文件的差别项
- 比较两份文件,输出第一份文件没有第二份文件有的数据
例:b.txt表示学生姓名,a.txt表示学生信息,通过awk可以比较输出未处理b.txt中未处理的学生姓名。
NR==FNR表示正在处理第一份文件,即a.txt。利用awk内置的一维数组结构,对a.txt中以处理的第一列数据打标。NR>FNR表示第二份文件,即b.txt,判断当前元素是否位于数组,对于不在数组中的元素,输出显示。
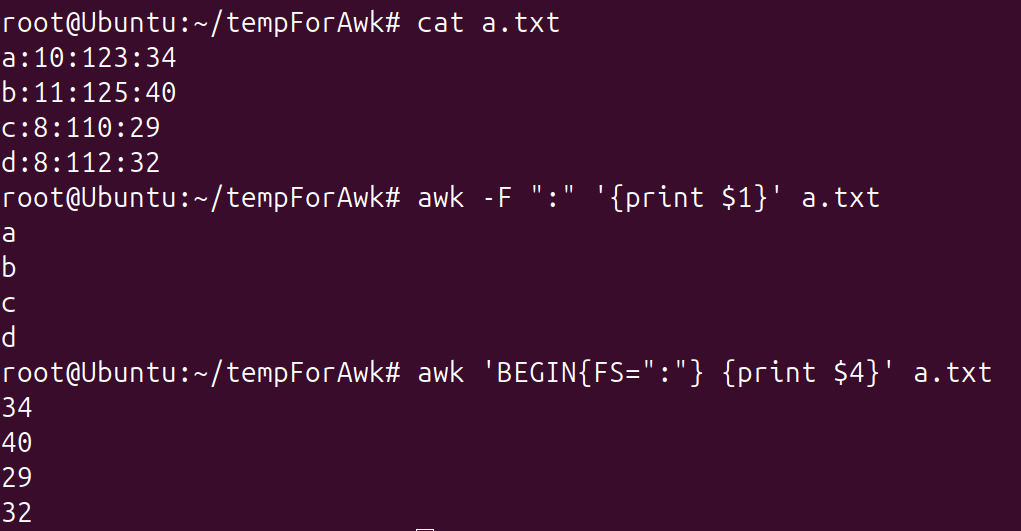 awk过滤指定列的数据
awk过滤指定列的数据
三、sed(流编辑器)

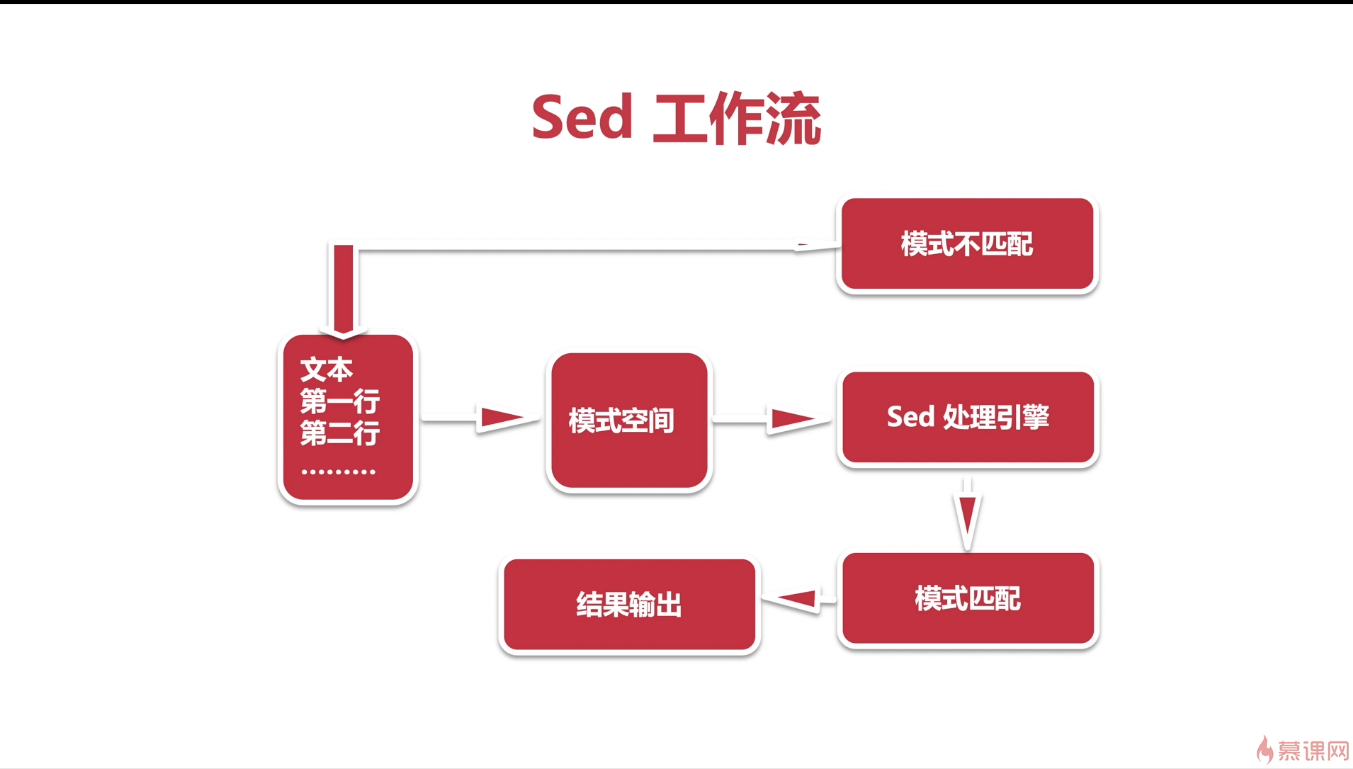

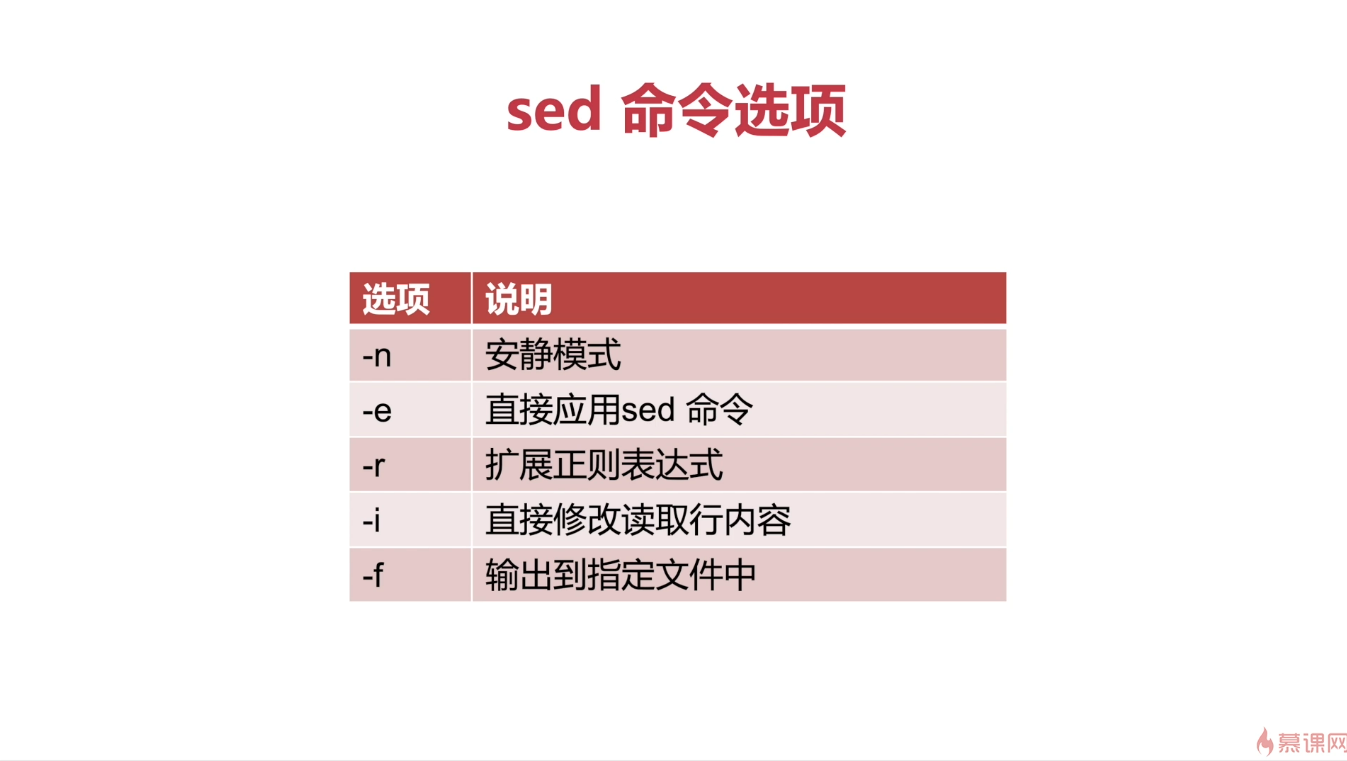


逐行读取做模式匹配,默认只处理不修改源文件的内容。
- 字符替换
bash
sed 's/old/new/' file.txt- 字符插入
bash
# 在第2行前插入a2
sed '2i\a2' file.txt
# 在第2行后插入b2
sed '2a\b2' file.txt- 删除行
bash
# 删除第2~4行,并写入源文件
sed -i '2,4d' 2.txt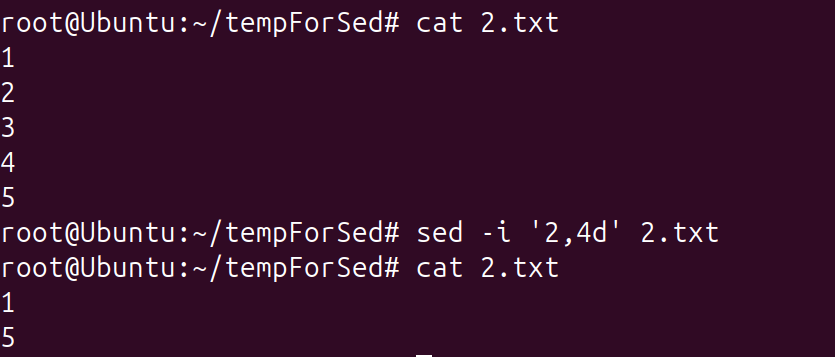
四、文档增删改查的综合练习
-
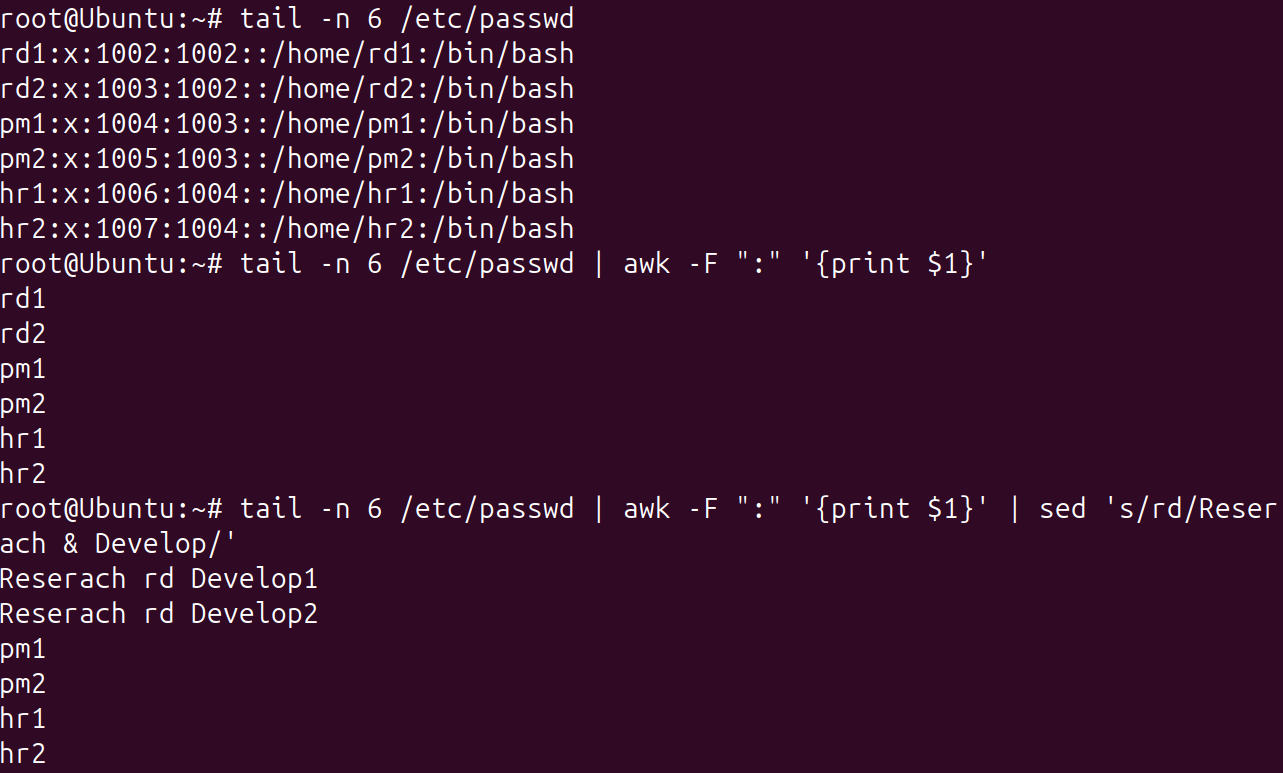
使用tail查看新增用户信息,新增用户在/etc/passwd的末尾,使用tail命令查看文档倒数n行
-
使用awk对数据分列,域分隔符为":",输出第一列用户名
-
使用sed对用户名中的rd替换成Research & Develop
至此,可以实现对文档的增删改查操作。
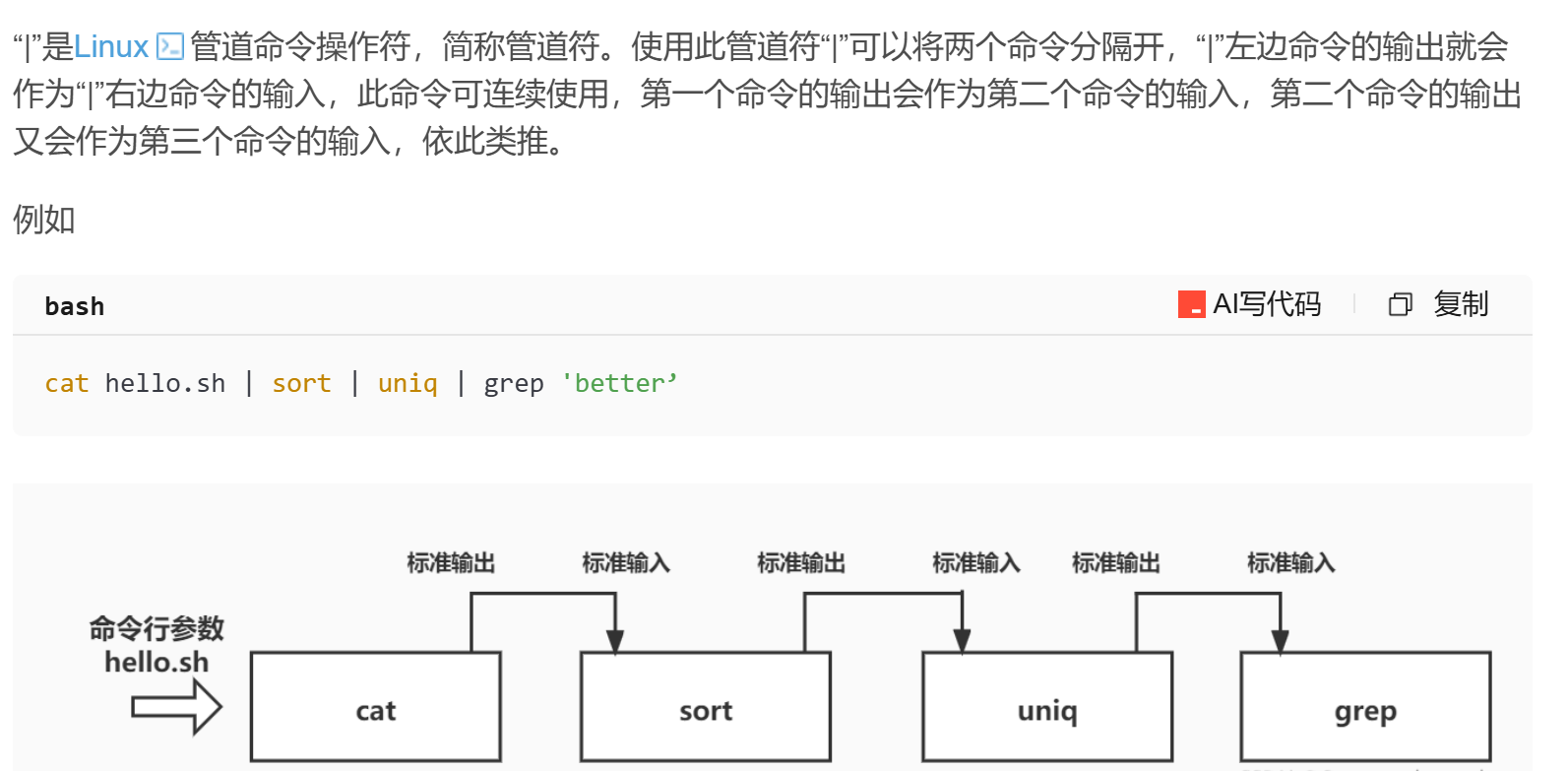 管道符使用说明
管道符使用说明
参考链接: