作业:对比不同卷积层热图可视化的结果
一、不同卷积层的特征特性
| 卷积层类型 | 特征类型 | 特征抽象程度 | 对输入的依赖程度 |
|---|---|---|---|
| 低层卷积层(如第 1 - 3 层) | 边缘、纹理、颜色、简单形状等基础特征 | 低 | 高,直接与输入像素关联 |
| 中层卷积层(如第 4 - 6 层) | 组合特征(如纹理组合、简单部件) | 中等 | 中等,基于低层特征进一步组合 |
| 高层卷积层(如第 7 层及以上) | 语义特征(如物体类别、整体结构) | 高 | 低,更关注全局语义而非局部细节 |
二、热图可视化结果对比
(一)低层卷积层:聚焦局部细节
- 可视化特点
- 高分辨率:热图分辨率接近输入图像,能清晰呈现像素级的激活区域。
- 局部响应:激活区域集中在输入图像的边缘、纹理等基础特征所在位置,呈现碎片化分布。
- 多通道差异:不同通道对应不同类型的基础特征(如水平边缘、垂直边缘、特定颜色),热图差异明显。
- 示例(以猫狗图像为例):在低层卷积层热图中,可看到猫的胡须边缘、狗的毛发纹理等局部细节区域显著激活,不同通道分别对应不同方向的边缘或颜色块。
(二)中层卷积层:关注部件组合
- 可视化特点
- 中等分辨率:热图分辨率降低,局部细节被抽象为部件级特征。
- 区域聚合:激活区域从碎片化转向区域性,对应物体的部件(如猫耳、狗眼、车轮等)。
- 语义关联:不同通道开始关联特定语义部件,热图激活区域与物体子结构对应。
- 示例(以车辆图像为例):中层卷积层热图中,汽车的车轮、车窗等部件区域呈现集中激活,不同通道分别对应车轮的圆形结构、车窗的矩形结构等。
(三)高层卷积层:突出全局语义
- 可视化特点
- 低分辨率:热图分辨率进一步降低,呈现为粗糙的语义区域。
- 全局激活:激活区域覆盖物体整体或关键语义区域(如动物身体、车辆主体),体现 "what" 而非 "how"。
- 类别特异性:不同类别图像的高层热图激活区域差异显著,聚焦于类别判别性区域。
- 示例(以动物图像为例):在 "猫" 图像的高层热图中,整个猫的身体区域显著激活;在 "狗" 图像中,狗的身体区域激活,且与猫的激活区域位置和形状相似,但因模型学习到的类别差异,激活强度可能不同。
三、可视化方法对热图的影响
不同可视化方法(如 Grad - CAM、反卷积、引导反向传播等)会使热图呈现不同特点,以下是常见方法在不同卷积层的表现对比:
| 可视化方法 | 低层卷积层热图特点 | 高层卷积层热图特点 |
|---|---|---|
| Grad - CAM | 激活区域定位较模糊,侧重语义相关区域 | 定位准确,清晰标出对分类起关键作用的全局区域 |
| 反卷积(Deconvolution) | 高保真还原低层特征的空间位置,细节丰富 | 语义区域模糊,易受低层噪声干扰 |
| 引导反向传播(Guided Backpropagation) | 边缘和纹理细节突出,噪声较少 | 语义区域碎片化,难以反映高层整体语义 |
四、对比分析的意义
- 理解网络层级功能:通过对比可知,CNN 通过低层到高层的层级结构,逐步从 "看见像素" 过渡到 "理解语义",符合人类认知的层级性。
- 诊断模型缺陷:若某层热图激活异常(如高层热图未覆盖物体主体),可能表明该层特征提取失效,需调整网络结构或训练策略。
- 优化可视化方法:根据分析目标选择合适方法,如分析低层细节用反卷积,定位高层语义用 Grad - CAM。
作业
现在我们引入通道注意力,来观察精度是否有变化,并且进一步可视化。
想要把通道注意力插入到模型中,关键步骤如下:
- 定义注意力模块
- 重写之前的模型定义部分,确定好模块插入的位置
通道注意力的定义
python
# ===================== 新增:通道注意力模块(SE模块) =====================
class ChannelAttention(nn.Module):
"""通道注意力模块(Squeeze-and-Excitation)"""
def __init__(self, in_channels, reduction_ratio=16):
"""
参数:
in_channels: 输入特征图的通道数
reduction_ratio: 降维比例,用于减少参数量
"""
super(ChannelAttention, self).__init__()
# 全局平均池化 - 将空间维度压缩为1x1,保留通道信息
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 全连接层 + 激活函数,用于学习通道间的依赖关系
self.fc = nn.Sequential(
# 降维:压缩通道数,减少计算量
nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),
nn.ReLU(inplace=True),
# 升维:恢复原始通道数
nn.Linear(in_channels // reduction_ratio, in_channels, bias=False),
# Sigmoid将输出值归一化到[0,1],表示通道重要性权重
nn.Sigmoid()
)
def forward(self, x):
"""
参数:
x: 输入特征图,形状为 [batch_size, channels, height, width]
返回:
加权后的特征图,形状不变
"""
batch_size, channels, height, width = x.size()
# 1. 全局平均池化:[batch_size, channels, height, width] → [batch_size, channels, 1, 1]
avg_pool_output = self.avg_pool(x)
# 2. 展平为一维向量:[batch_size, channels, 1, 1] → [batch_size, channels]
avg_pool_output = avg_pool_output.view(batch_size, channels)
# 3. 通过全连接层学习通道权重:[batch_size, channels] → [batch_size, channels]
channel_weights = self.fc(avg_pool_output)
# 4. 重塑为二维张量:[batch_size, channels] → [batch_size, channels, 1, 1]
channel_weights = channel_weights.view(batch_size, channels, 1, 1)
# 5. 将权重应用到原始特征图上(逐通道相乘)
return x * channel_weights # 输出形状:[batch_size, channels, height, width]通道注意力模块的核心原理
- Squeeze(压缩):
- 通过全局平均池化将每个通道的二维特征图(H×W)压缩为一个标量,保留通道的全局信息。
- 物理意义:计算每个通道在整个图像中的 "平均响应强度",例如,"边缘检测通道" 在有物体边缘的图像中响应值会更高。
- Excitation(激发):
- 通过全连接层 + Sigmoid 激活,学习通道间的依赖关系,输出 0-1 之间的权重值。
- 物理意义:让模型自动判断哪些通道更重要(权重接近 1),哪些通道可忽略(权重接近 0)。
- Reweight(重加权):
- 将学习到的通道权重与原始特征图逐通道相乘,增强重要通道,抑制不重要通道。
- 物理意义:类似人类视觉系统聚焦于关键特征(如猫的轮廓),忽略无关特征(如背景颜色)
通道注意力插入后,参数量略微提高,增加了特征提取能力
模型的重新定义(通道注意力的插入)
python
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# ---------------------- 第一个卷积块 ----------------------
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.ReLU()
# 新增:插入通道注意力模块(SE模块)
self.ca1 = ChannelAttention(in_channels=32, reduction_ratio=16)
self.pool1 = nn.MaxPool2d(2, 2)
# ---------------------- 第二个卷积块 ----------------------
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.ReLU()
# 新增:插入通道注意力模块(SE模块)
self.ca2 = ChannelAttention(in_channels=64, reduction_ratio=16)
self.pool2 = nn.MaxPool2d(2)
# ---------------------- 第三个卷积块 ----------------------
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
# 新增:插入通道注意力模块(SE模块)
self.ca3 = ChannelAttention(in_channels=128, reduction_ratio=16)
self.pool3 = nn.MaxPool2d(2)
# ---------------------- 全连接层(分类器) ----------------------
self.fc1 = nn.Linear(128 * 4 * 4, 512)
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
# ---------- 卷积块1处理 ----------
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.ca1(x) # 应用通道注意力
x = self.pool1(x)
# ---------- 卷积块2处理 ----------
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.ca2(x) # 应用通道注意力
x = self.pool2(x)
# ---------- 卷积块3处理 ----------
x = self.conv3(x)
x = self.bn3(x)
x = self.relu3(x)
x = self.ca3(x) # 应用通道注意力
x = self.pool3(x)
# ---------- 展平与全连接层 ----------
x = x.view(-1, 128 * 4 * 4)
x = self.fc1(x)
x = self.relu3(x)
x = self.dropout(x)
x = self.fc2(x)
return x
# 重新初始化模型,包含通道注意力模块
model = CNN()
model = model.to(device) # 将模型移至GPU(如果可用)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器
# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, # 指定要控制的优化器(这里是Adam)
mode='min', # 监测的指标是"最小化"(如损失函数)
patience=3, # 如果连续3个epoch指标没有改善,才降低LR
factor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)# 训练模型(复用原有的train函数)
print("开始训练带通道注意力的CNN模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs=50)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")开始训练带通道注意力的CNN模型...
Epoch: 1/50 | Batch: 100/782 | 单Batch损失: 1.8910 | 累计平均损失: 1.9942
Epoch: 1/50 | Batch: 200/782 | 单Batch损失: 1.6923 | 累计平均损失: 1.8823
Epoch: 1/50 | Batch: 300/782 | 单Batch损失: 1.6001 | 累计平均损失: 1.8048
Epoch: 1/50 | Batch: 400/782 | 单Batch损失: 1.2822 | 累计平均损失: 1.7508
Epoch: 1/50 | Batch: 500/782 | 单Batch损失: 1.5353 | 累计平均损失: 1.7110
Epoch: 1/50 | Batch: 600/782 | 单Batch损失: 1.4252 | 累计平均损失: 1.6772
Epoch: 1/50 | Batch: 700/782 | 单Batch损失: 1.5700 | 累计平均损失: 1.6480
Epoch 1/50 完成 | 训练准确率: 40.15% | 测试准确率: 54.47%
Epoch: 2/50 | Batch: 100/782 | 单Batch损失: 1.1785 | 累计平均损失: 1.3923
Epoch: 2/50 | Batch: 200/782 | 单Batch损失: 1.1950 | 累计平均损失: 1.3703
Epoch: 2/50 | Batch: 300/782 | 单Batch损失: 1.5047 | 累计平均损失: 1.3450
Epoch: 2/50 | Batch: 400/782 | 单Batch损失: 0.9452 | 累计平均损失: 1.3163
Epoch: 2/50 | Batch: 500/782 | 单Batch损失: 1.4187 | 累计平均损失: 1.2955
Epoch: 2/50 | Batch: 600/782 | 单Batch损失: 1.2744 | 累计平均损失: 1.2757
Epoch: 2/50 | Batch: 700/782 | 单Batch损失: 0.8026 | 累计平均损失: 1.2576
Epoch 2/50 完成 | 训练准确率: 55.18% | 测试准确率: 64.94%
Epoch: 3/50 | Batch: 100/782 | 单Batch损失: 1.1973 | 累计平均损失: 1.1252
Epoch: 3/50 | Batch: 200/782 | 单Batch损失: 1.0419 | 累计平均损失: 1.1164
Epoch: 3/50 | Batch: 300/782 | 单Batch损失: 1.1677 | 累计平均损失: 1.1095
Epoch: 3/50 | Batch: 400/782 | 单Batch损失: 0.8185 | 累计平均损失: 1.1021
Epoch: 3/50 | Batch: 500/782 | 单Batch损失: 0.9481 | 累计平均损失: 1.0917
Epoch: 3/50 | Batch: 600/782 | 单Batch损失: 0.9860 | 累计平均损失: 1.0812
Epoch: 3/50 | Batch: 700/782 | 单Batch损失: 1.1787 | 累计平均损失: 1.0746
Epoch 3/50 完成 | 训练准确率: 61.74% | 测试准确率: 68.80%
Epoch: 4/50 | Batch: 100/782 | 单Batch损失: 0.9095 | 累计平均损失: 1.0144
Epoch: 4/50 | Batch: 200/782 | 单Batch损失: 0.8167 | 累计平均损失: 1.0041
Epoch: 4/50 | Batch: 300/782 | 单Batch损失: 0.8562 | 累计平均损失: 1.0046
Epoch: 4/50 | Batch: 400/782 | 单Batch损失: 0.9789 | 累计平均损失: 0.9979
Epoch: 4/50 | Batch: 500/782 | 单Batch损失: 1.1543 | 累计平均损失: 0.9918
Epoch: 4/50 | Batch: 600/782 | 单Batch损失: 0.7725 | 累计平均损失: 0.9879
Epoch: 4/50 | Batch: 700/782 | 单Batch损失: 0.9204 | 累计平均损失: 0.9808
Epoch 4/50 完成 | 训练准确率: 65.42% | 测试准确率: 72.02%
Epoch: 5/50 | Batch: 100/782 | 单Batch损失: 0.8194 | 累计平均损失: 0.9070
Epoch: 5/50 | Batch: 200/782 | 单Batch损失: 0.9422 | 累计平均损失: 0.8977
Epoch: 5/50 | Batch: 300/782 | 单Batch损失: 1.0601 | 累计平均损失: 0.8964
Epoch: 5/50 | Batch: 400/782 | 单Batch损失: 1.1281 | 累计平均损失: 0.9027
Epoch: 5/50 | Batch: 500/782 | 单Batch损失: 0.7543 | 累计平均损失: 0.9074
Epoch: 5/50 | Batch: 600/782 | 单Batch损失: 0.9560 | 累计平均损失: 0.9075
Epoch: 5/50 | Batch: 700/782 | 单Batch损失: 1.1944 | 累计平均损失: 0.9076
Epoch 5/50 完成 | 训练准确率: 67.73% | 测试准确率: 73.46%
Epoch: 6/50 | Batch: 100/782 | 单Batch损失: 1.0541 | 累计平均损失: 0.8482
Epoch: 6/50 | Batch: 200/782 | 单Batch损失: 0.7732 | 累计平均损失: 0.8623
Epoch: 6/50 | Batch: 300/782 | 单Batch损失: 0.6090 | 累计平均损失: 0.8601
Epoch: 6/50 | Batch: 400/782 | 单Batch损失: 0.8097 | 累计平均损失: 0.8651
Epoch: 6/50 | Batch: 500/782 | 单Batch损失: 0.9160 | 累计平均损失: 0.8635
Epoch: 6/50 | Batch: 600/782 | 单Batch损失: 0.8423 | 累计平均损失: 0.8583
Epoch: 6/50 | Batch: 700/782 | 单Batch损失: 0.5550 | 累计平均损失: 0.8572
Epoch 6/50 完成 | 训练准确率: 69.70% | 测试准确率: 73.66%
Epoch: 7/50 | Batch: 100/782 | 单Batch损失: 1.1355 | 累计平均损失: 0.8247
Epoch: 7/50 | Batch: 200/782 | 单Batch损失: 0.9422 | 累计平均损失: 0.8182
Epoch: 7/50 | Batch: 300/782 | 单Batch损失: 0.9666 | 累计平均损失: 0.8241
Epoch: 7/50 | Batch: 400/782 | 单Batch损失: 0.7275 | 累计平均损失: 0.8239
Epoch: 7/50 | Batch: 500/782 | 单Batch损失: 0.7788 | 累计平均损失: 0.8237
Epoch: 7/50 | Batch: 600/782 | 单Batch损失: 0.7764 | 累计平均损失: 0.8223
Epoch: 7/50 | Batch: 700/782 | 单Batch损失: 0.7445 | 累计平均损失: 0.8242
Epoch 7/50 完成 | 训练准确率: 71.07% | 测试准确率: 74.66%
Epoch: 8/50 | Batch: 100/782 | 单Batch损失: 0.7246 | 累计平均损失: 0.7726
Epoch: 8/50 | Batch: 200/782 | 单Batch损失: 0.8171 | 累计平均损失: 0.7776
Epoch: 8/50 | Batch: 300/782 | 单Batch损失: 0.8266 | 累计平均损失: 0.7838
Epoch: 8/50 | Batch: 400/782 | 单Batch损失: 0.7973 | 累计平均损失: 0.7861
Epoch: 8/50 | Batch: 500/782 | 单Batch损失: 1.2108 | 累计平均损失: 0.7865
Epoch: 8/50 | Batch: 600/782 | 单Batch损失: 0.9653 | 累计平均损失: 0.7864
Epoch: 8/50 | Batch: 700/782 | 单Batch损失: 0.4994 | 累计平均损失: 0.7847
Epoch 8/50 完成 | 训练准确率: 72.33% | 测试准确率: 76.28%
Epoch: 9/50 | Batch: 100/782 | 单Batch损失: 0.5965 | 累计平均损失: 0.7670
Epoch: 9/50 | Batch: 200/782 | 单Batch损失: 0.6739 | 累计平均损失: 0.7583
Epoch: 9/50 | Batch: 300/782 | 单Batch损失: 0.8711 | 累计平均损失: 0.7591
Epoch: 9/50 | Batch: 400/782 | 单Batch损失: 0.6418 | 累计平均损失: 0.7630
Epoch: 9/50 | Batch: 500/782 | 单Batch损失: 0.8583 | 累计平均损失: 0.7634
Epoch: 9/50 | Batch: 600/782 | 单Batch损失: 0.6803 | 累计平均损失: 0.7668
Epoch: 9/50 | Batch: 700/782 | 单Batch损失: 0.7970 | 累计平均损失: 0.7632
Epoch 9/50 完成 | 训练准确率: 73.22% | 测试准确率: 77.34%
Epoch: 10/50 | Batch: 100/782 | 单Batch损失: 0.6389 | 累计平均损失: 0.7146
Epoch: 10/50 | Batch: 200/782 | 单Batch损失: 0.9116 | 累计平均损失: 0.7315
Epoch: 10/50 | Batch: 300/782 | 单Batch损失: 0.7333 | 累计平均损失: 0.7330
Epoch: 10/50 | Batch: 400/782 | 单Batch损失: 0.7339 | 累计平均损失: 0.7336
Epoch: 10/50 | Batch: 500/782 | 单Batch损失: 0.6050 | 累计平均损失: 0.7341
Epoch: 10/50 | Batch: 600/782 | 单Batch损失: 0.6220 | 累计平均损失: 0.7345
Epoch: 10/50 | Batch: 700/782 | 单Batch损失: 0.7757 | 累计平均损失: 0.7332
Epoch 10/50 完成 | 训练准确率: 74.16% | 测试准确率: 78.11%
Epoch: 11/50 | Batch: 100/782 | 单Batch损失: 0.7069 | 累计平均损失: 0.7201
Epoch: 11/50 | Batch: 200/782 | 单Batch损失: 1.1344 | 累计平均损失: 0.7279
Epoch: 11/50 | Batch: 300/782 | 单Batch损失: 0.8089 | 累计平均损失: 0.7247
Epoch: 11/50 | Batch: 400/782 | 单Batch损失: 0.5967 | 累计平均损失: 0.7208
Epoch: 11/50 | Batch: 500/782 | 单Batch损失: 0.5873 | 累计平均损失: 0.7237
Epoch: 11/50 | Batch: 600/782 | 单Batch损失: 0.4547 | 累计平均损失: 0.7229
Epoch: 11/50 | Batch: 700/782 | 单Batch损失: 0.8420 | 累计平均损失: 0.7214
Epoch 11/50 完成 | 训练准确率: 74.72% | 测试准确率: 78.84%
Epoch: 12/50 | Batch: 100/782 | 单Batch损失: 0.8635 | 累计平均损失: 0.7254
Epoch: 12/50 | Batch: 200/782 | 单Batch损失: 0.5758 | 累计平均损失: 0.7109
Epoch: 12/50 | Batch: 300/782 | 单Batch损失: 0.8813 | 累计平均损失: 0.7027
Epoch: 12/50 | Batch: 400/782 | 单Batch损失: 0.6096 | 累计平均损失: 0.7045
Epoch: 12/50 | Batch: 500/782 | 单Batch损失: 0.6331 | 累计平均损失: 0.7037
Epoch: 12/50 | Batch: 600/782 | 单Batch损失: 0.5613 | 累计平均损失: 0.7021
Epoch: 12/50 | Batch: 700/782 | 单Batch损失: 0.7367 | 累计平均损失: 0.7000
Epoch 12/50 完成 | 训练准确率: 75.18% | 测试准确率: 78.28%
Epoch: 13/50 | Batch: 100/782 | 单Batch损失: 0.4853 | 累计平均损失: 0.6892
Epoch: 13/50 | Batch: 200/782 | 单Batch损失: 0.6132 | 累计平均损失: 0.6804
Epoch: 13/50 | Batch: 300/782 | 单Batch损失: 0.7773 | 累计平均损失: 0.6795
Epoch: 13/50 | Batch: 400/782 | 单Batch损失: 0.7293 | 累计平均损失: 0.6821
Epoch: 13/50 | Batch: 500/782 | 单Batch损失: 0.7064 | 累计平均损失: 0.6838
Epoch: 13/50 | Batch: 600/782 | 单Batch损失: 0.6225 | 累计平均损失: 0.6825
Epoch: 13/50 | Batch: 700/782 | 单Batch损失: 0.7808 | 累计平均损失: 0.6833
Epoch 13/50 完成 | 训练准确率: 75.94% | 测试准确率: 78.24%
Epoch: 14/50 | Batch: 100/782 | 单Batch损失: 0.6450 | 累计平均损失: 0.6793
Epoch: 14/50 | Batch: 200/782 | 单Batch损失: 0.8774 | 累计平均损失: 0.6634
Epoch: 14/50 | Batch: 300/782 | 单Batch损失: 0.7729 | 累计平均损失: 0.6625
Epoch: 14/50 | Batch: 400/782 | 单Batch损失: 0.7973 | 累计平均损失: 0.6645
Epoch: 14/50 | Batch: 500/782 | 单Batch损失: 0.4674 | 累计平均损失: 0.6614
Epoch: 14/50 | Batch: 600/782 | 单Batch损失: 0.5475 | 累计平均损失: 0.6624
Epoch: 14/50 | Batch: 700/782 | 单Batch损失: 0.8203 | 累计平均损失: 0.6645
Epoch 14/50 完成 | 训练准确率: 76.83% | 测试准确率: 78.92%
Epoch: 15/50 | Batch: 100/782 | 单Batch损失: 0.6754 | 累计平均损失: 0.6515
Epoch: 15/50 | Batch: 200/782 | 单Batch损失: 0.5855 | 累计平均损失: 0.6502
Epoch: 15/50 | Batch: 300/782 | 单Batch损失: 0.6383 | 累计平均损失: 0.6461
Epoch: 15/50 | Batch: 400/782 | 单Batch损失: 0.6179 | 累计平均损失: 0.6429
Epoch: 15/50 | Batch: 500/782 | 单Batch损失: 0.6019 | 累计平均损失: 0.6467
Epoch: 15/50 | Batch: 600/782 | 单Batch损失: 0.6988 | 累计平均损失: 0.6459
Epoch: 15/50 | Batch: 700/782 | 单Batch损失: 0.7184 | 累计平均损失: 0.6496
Epoch 15/50 完成 | 训练准确率: 77.02% | 测试准确率: 79.01%
Epoch: 16/50 | Batch: 100/782 | 单Batch损失: 0.6067 | 累计平均损失: 0.6246
Epoch: 16/50 | Batch: 200/782 | 单Batch损失: 0.6392 | 累计平均损失: 0.6408
Epoch: 16/50 | Batch: 300/782 | 单Batch损失: 0.6083 | 累计平均损失: 0.6367
Epoch: 16/50 | Batch: 400/782 | 单Batch损失: 0.6707 | 累计平均损失: 0.6327
Epoch: 16/50 | Batch: 500/782 | 单Batch损失: 0.6953 | 累计平均损失: 0.6293
Epoch: 16/50 | Batch: 600/782 | 单Batch损失: 0.4582 | 累计平均损失: 0.6342
Epoch: 16/50 | Batch: 700/782 | 单Batch损失: 0.9490 | 累计平均损失: 0.6377
Epoch 16/50 完成 | 训练准确率: 77.72% | 测试准确率: 79.28%
Epoch: 17/50 | Batch: 100/782 | 单Batch损失: 0.6170 | 累计平均损失: 0.6355
Epoch: 17/50 | Batch: 200/782 | 单Batch损失: 0.6250 | 累计平均损失: 0.6314
Epoch: 17/50 | Batch: 300/782 | 单Batch损失: 0.5300 | 累计平均损失: 0.6285
Epoch: 17/50 | Batch: 400/782 | 单Batch损失: 0.6244 | 累计平均损失: 0.6328
Epoch: 17/50 | Batch: 500/782 | 单Batch损失: 0.6127 | 累计平均损失: 0.6353
Epoch: 17/50 | Batch: 600/782 | 单Batch损失: 0.5944 | 累计平均损失: 0.6352
Epoch: 17/50 | Batch: 700/782 | 单Batch损失: 0.6465 | 累计平均损失: 0.6353
Epoch 17/50 完成 | 训练准确率: 77.89% | 测试准确率: 80.43%
Epoch: 18/50 | Batch: 100/782 | 单Batch损失: 0.5609 | 累计平均损失: 0.6032
Epoch: 18/50 | Batch: 200/782 | 单Batch损失: 0.6771 | 累计平均损失: 0.6216
Epoch: 18/50 | Batch: 300/782 | 单Batch损失: 0.6366 | 累计平均损失: 0.6288
Epoch: 18/50 | Batch: 400/782 | 单Batch损失: 0.5645 | 累计平均损失: 0.6291
Epoch: 18/50 | Batch: 500/782 | 单Batch损失: 0.8008 | 累计平均损失: 0.6278
Epoch: 18/50 | Batch: 600/782 | 单Batch损失: 0.6849 | 累计平均损失: 0.6272
Epoch: 18/50 | Batch: 700/782 | 单Batch损失: 0.7924 | 累计平均损失: 0.6269
Epoch 18/50 完成 | 训练准确率: 77.96% | 测试准确率: 80.82%
Epoch: 19/50 | Batch: 100/782 | 单Batch损失: 0.5558 | 累计平均损失: 0.6171
Epoch: 19/50 | Batch: 200/782 | 单Batch损失: 0.5985 | 累计平均损失: 0.6068
Epoch: 19/50 | Batch: 300/782 | 单Batch损失: 0.6577 | 累计平均损失: 0.6134
Epoch: 19/50 | Batch: 400/782 | 单Batch损失: 0.5516 | 累计平均损失: 0.6165
Epoch: 19/50 | Batch: 500/782 | 单Batch损失: 0.7816 | 累计平均损失: 0.6170
Epoch: 19/50 | Batch: 600/782 | 单Batch损失: 0.5580 | 累计平均损失: 0.6183
Epoch: 19/50 | Batch: 700/782 | 单Batch损失: 0.5850 | 累计平均损失: 0.6176
Epoch 19/50 完成 | 训练准确率: 78.33% | 测试准确率: 81.22%
Epoch: 20/50 | Batch: 100/782 | 单Batch损失: 0.6917 | 累计平均损失: 0.5775
Epoch: 20/50 | Batch: 200/782 | 单Batch损失: 0.4631 | 累计平均损失: 0.5914
Epoch: 20/50 | Batch: 300/782 | 单Batch损失: 0.5342 | 累计平均损失: 0.5921
Epoch: 20/50 | Batch: 400/782 | 单Batch损失: 0.6903 | 累计平均损失: 0.5977
Epoch: 20/50 | Batch: 500/782 | 单Batch损失: 0.6729 | 累计平均损失: 0.6048
Epoch: 20/50 | Batch: 600/782 | 单Batch损失: 0.5450 | 累计平均损失: 0.6074
Epoch: 20/50 | Batch: 700/782 | 单Batch损失: 0.4961 | 累计平均损失: 0.6058
Epoch 20/50 完成 | 训练准确率: 78.70% | 测试准确率: 81.15%
Epoch: 21/50 | Batch: 100/782 | 单Batch损失: 0.7660 | 累计平均损失: 0.5994
Epoch: 21/50 | Batch: 200/782 | 单Batch损失: 0.5768 | 累计平均损失: 0.5965
Epoch: 21/50 | Batch: 300/782 | 单Batch损失: 0.5978 | 累计平均损失: 0.5945
Epoch: 21/50 | Batch: 400/782 | 单Batch损失: 0.5098 | 累计平均损失: 0.5890
Epoch: 21/50 | Batch: 500/782 | 单Batch损失: 0.7482 | 累计平均损失: 0.5885
Epoch: 21/50 | Batch: 600/782 | 单Batch损失: 0.5658 | 累计平均损失: 0.5898
Epoch: 21/50 | Batch: 700/782 | 单Batch损失: 0.4952 | 累计平均损失: 0.5899
Epoch 21/50 完成 | 训练准确率: 79.21% | 测试准确率: 80.35%
Epoch: 22/50 | Batch: 100/782 | 单Batch损失: 0.5834 | 累计平均损失: 0.6001
Epoch: 22/50 | Batch: 200/782 | 单Batch损失: 0.4394 | 累计平均损失: 0.5847
Epoch: 22/50 | Batch: 300/782 | 单Batch损失: 0.4991 | 累计平均损失: 0.5856
Epoch: 22/50 | Batch: 400/782 | 单Batch损失: 0.7057 | 累计平均损失: 0.5855
Epoch: 22/50 | Batch: 500/782 | 单Batch损失: 0.5274 | 累计平均损失: 0.5857
Epoch: 22/50 | Batch: 600/782 | 单Batch损失: 0.6782 | 累计平均损失: 0.5872
Epoch: 22/50 | Batch: 700/782 | 单Batch损失: 0.5026 | 累计平均损失: 0.5895
Epoch 22/50 完成 | 训练准确率: 79.22% | 测试准确率: 80.70%
Epoch: 23/50 | Batch: 100/782 | 单Batch损失: 0.6250 | 累计平均损失: 0.5777
Epoch: 23/50 | Batch: 200/782 | 单Batch损失: 0.4429 | 累计平均损失: 0.5752
Epoch: 23/50 | Batch: 300/782 | 单Batch损失: 0.4288 | 累计平均损失: 0.5800
Epoch: 23/50 | Batch: 400/782 | 单Batch损失: 0.5530 | 累计平均损失: 0.5794
Epoch: 23/50 | Batch: 500/782 | 单Batch损失: 0.5810 | 累计平均损失: 0.5814
Epoch: 23/50 | Batch: 600/782 | 单Batch损失: 0.6042 | 累计平均损失: 0.5815
Epoch: 23/50 | Batch: 700/782 | 单Batch损失: 0.7897 | 累计平均损失: 0.5783
Epoch 23/50 完成 | 训练准确率: 79.80% | 测试准确率: 82.05%
Epoch: 24/50 | Batch: 100/782 | 单Batch损失: 0.5486 | 累计平均损失: 0.5543
Epoch: 24/50 | Batch: 200/782 | 单Batch损失: 0.6512 | 累计平均损失: 0.5688
Epoch: 24/50 | Batch: 300/782 | 单Batch损失: 0.6041 | 累计平均损失: 0.5664
Epoch: 24/50 | Batch: 400/782 | 单Batch损失: 0.4824 | 累计平均损失: 0.5691
Epoch: 24/50 | Batch: 500/782 | 单Batch损失: 0.5739 | 累计平均损失: 0.5696
Epoch: 24/50 | Batch: 600/782 | 单Batch损失: 0.7306 | 累计平均损失: 0.5713
Epoch: 24/50 | Batch: 700/782 | 单Batch损失: 0.3697 | 累计平均损失: 0.5693
Epoch 24/50 完成 | 训练准确率: 80.08% | 测试准确率: 82.09%
Epoch: 25/50 | Batch: 100/782 | 单Batch损失: 0.4554 | 累计平均损失: 0.5543
Epoch: 25/50 | Batch: 200/782 | 单Batch损失: 0.3852 | 累计平均损失: 0.5500
Epoch: 25/50 | Batch: 300/782 | 单Batch损失: 0.6902 | 累计平均损失: 0.5556
Epoch: 25/50 | Batch: 400/782 | 单Batch损失: 0.3672 | 累计平均损失: 0.5564
Epoch: 25/50 | Batch: 500/782 | 单Batch损失: 0.6507 | 累计平均损失: 0.5590
Epoch: 25/50 | Batch: 600/782 | 单Batch损失: 0.4924 | 累计平均损失: 0.5613
Epoch: 25/50 | Batch: 700/782 | 单Batch损失: 0.8046 | 累计平均损失: 0.5637
Epoch 25/50 完成 | 训练准确率: 80.18% | 测试准确率: 80.45%
Epoch: 26/50 | Batch: 100/782 | 单Batch损失: 0.6297 | 累计平均损失: 0.5688
Epoch: 26/50 | Batch: 200/782 | 单Batch损失: 0.5689 | 累计平均损失: 0.5668
Epoch: 26/50 | Batch: 300/782 | 单Batch损失: 0.4731 | 累计平均损失: 0.5631
Epoch: 26/50 | Batch: 400/782 | 单Batch损失: 0.4124 | 累计平均损失: 0.5606
Epoch: 26/50 | Batch: 500/782 | 单Batch损失: 0.4638 | 累计平均损失: 0.5567
Epoch: 26/50 | Batch: 600/782 | 单Batch损失: 0.5766 | 累计平均损失: 0.5597
Epoch: 26/50 | Batch: 700/782 | 单Batch损失: 0.6235 | 累计平均损失: 0.5574
Epoch 26/50 完成 | 训练准确率: 80.50% | 测试准确率: 81.66%
Epoch: 27/50 | Batch: 100/782 | 单Batch损失: 0.4954 | 累计平均损失: 0.5411
Epoch: 27/50 | Batch: 200/782 | 单Batch损失: 0.4585 | 累计平均损失: 0.5459
Epoch: 27/50 | Batch: 300/782 | 单Batch损失: 0.5495 | 累计平均损失: 0.5480
Epoch: 27/50 | Batch: 400/782 | 单Batch损失: 0.4660 | 累计平均损失: 0.5501
Epoch: 27/50 | Batch: 500/782 | 单Batch损失: 0.7180 | 累计平均损失: 0.5506
Epoch: 27/50 | Batch: 600/782 | 单Batch损失: 0.5334 | 累计平均损失: 0.5512
Epoch: 27/50 | Batch: 700/782 | 单Batch损失: 0.9151 | 累计平均损失: 0.5503
Epoch 27/50 完成 | 训练准确率: 80.69% | 测试准确率: 82.66%
Epoch: 28/50 | Batch: 100/782 | 单Batch损失: 0.5780 | 累计平均损失: 0.5544
Epoch: 28/50 | Batch: 200/782 | 单Batch损失: 0.6886 | 累计平均损失: 0.5520
Epoch: 28/50 | Batch: 300/782 | 单Batch损失: 0.6571 | 累计平均损失: 0.5505
Epoch: 28/50 | Batch: 400/782 | 单Batch损失: 0.6173 | 累计平均损失: 0.5508
Epoch: 28/50 | Batch: 500/782 | 单Batch损失: 0.4593 | 累计平均损失: 0.5539
Epoch: 28/50 | Batch: 600/782 | 单Batch损失: 0.2833 | 累计平均损失: 0.5520
Epoch: 28/50 | Batch: 700/782 | 单Batch损失: 0.6721 | 累计平均损失: 0.5491
Epoch 28/50 完成 | 训练准确率: 80.87% | 测试准确率: 81.96%
Epoch: 29/50 | Batch: 100/782 | 单Batch损失: 0.5877 | 累计平均损失: 0.5381
Epoch: 29/50 | Batch: 200/782 | 单Batch损失: 0.5812 | 累计平均损失: 0.5396
Epoch: 29/50 | Batch: 300/782 | 单Batch损失: 0.4271 | 累计平均损失: 0.5419
Epoch: 29/50 | Batch: 400/782 | 单Batch损失: 0.5118 | 累计平均损失: 0.5393
Epoch: 29/50 | Batch: 500/782 | 单Batch损失: 0.6373 | 累计平均损失: 0.5377
Epoch: 29/50 | Batch: 600/782 | 单Batch损失: 0.5544 | 累计平均损失: 0.5408
Epoch: 29/50 | Batch: 700/782 | 单Batch损失: 0.7512 | 累计平均损失: 0.5428
Epoch 29/50 完成 | 训练准确率: 80.99% | 测试准确率: 81.47%
Epoch: 30/50 | Batch: 100/782 | 单Batch损失: 0.4670 | 累计平均损失: 0.5293
Epoch: 30/50 | Batch: 200/782 | 单Batch损失: 0.3581 | 累计平均损失: 0.5368
Epoch: 30/50 | Batch: 300/782 | 单Batch损失: 0.4213 | 累计平均损失: 0.5372
Epoch: 30/50 | Batch: 400/782 | 单Batch损失: 0.3971 | 累计平均损失: 0.5353
Epoch: 30/50 | Batch: 500/782 | 单Batch损失: 0.5780 | 累计平均损失: 0.5336
Epoch: 30/50 | Batch: 600/782 | 单Batch损失: 0.6527 | 累计平均损失: 0.5295
Epoch: 30/50 | Batch: 700/782 | 单Batch损失: 0.4783 | 累计平均损失: 0.5303
Epoch 30/50 完成 | 训练准确率: 81.26% | 测试准确率: 81.89%
Epoch: 31/50 | Batch: 100/782 | 单Batch损失: 0.3568 | 累计平均损失: 0.5350
Epoch: 31/50 | Batch: 200/782 | 单Batch损失: 0.4978 | 累计平均损失: 0.5356
Epoch: 31/50 | Batch: 300/782 | 单Batch损失: 0.5088 | 累计平均损失: 0.5327
Epoch: 31/50 | Batch: 400/782 | 单Batch损失: 0.5637 | 累计平均损失: 0.5310
Epoch: 31/50 | Batch: 500/782 | 单Batch损失: 0.6395 | 累计平均损失: 0.5266
Epoch: 31/50 | Batch: 600/782 | 单Batch损失: 0.4701 | 累计平均损失: 0.5279
Epoch: 31/50 | Batch: 700/782 | 单Batch损失: 0.6192 | 累计平均损失: 0.5296
Epoch 31/50 完成 | 训练准确率: 81.46% | 测试准确率: 81.23%
Epoch: 32/50 | Batch: 100/782 | 单Batch损失: 0.4148 | 累计平均损失: 0.4952
Epoch: 32/50 | Batch: 200/782 | 单Batch损失: 0.4242 | 累计平均损失: 0.4808
Epoch: 32/50 | Batch: 300/782 | 单Batch损失: 0.5075 | 累计平均损失: 0.4801
Epoch: 32/50 | Batch: 400/782 | 单Batch损失: 0.7260 | 累计平均损失: 0.4798
Epoch: 32/50 | Batch: 500/782 | 单Batch损失: 0.7650 | 累计平均损失: 0.4804
Epoch: 32/50 | Batch: 600/782 | 单Batch损失: 0.4746 | 累计平均损失: 0.4819
Epoch: 32/50 | Batch: 700/782 | 单Batch损失: 0.3565 | 累计平均损失: 0.4804
Epoch 32/50 完成 | 训练准确率: 83.17% | 测试准确率: 83.49%
Epoch: 33/50 | Batch: 100/782 | 单Batch损失: 0.4010 | 累计平均损失: 0.4820
Epoch: 33/50 | Batch: 200/782 | 单Batch损失: 0.8172 | 累计平均损失: 0.4776
Epoch: 33/50 | Batch: 300/782 | 单Batch损失: 0.3856 | 累计平均损失: 0.4793
Epoch: 33/50 | Batch: 400/782 | 单Batch损失: 0.4422 | 累计平均损失: 0.4741
Epoch: 33/50 | Batch: 500/782 | 单Batch损失: 0.5063 | 累计平均损失: 0.4714
Epoch: 33/50 | Batch: 600/782 | 单Batch损失: 0.6978 | 累计平均损失: 0.4745
Epoch: 33/50 | Batch: 700/782 | 单Batch损失: 0.2665 | 累计平均损失: 0.4708
Epoch 33/50 完成 | 训练准确率: 83.48% | 测试准确率: 83.61%
Epoch: 34/50 | Batch: 100/782 | 单Batch损失: 0.7424 | 累计平均损失: 0.4434
Epoch: 34/50 | Batch: 200/782 | 单Batch损失: 0.2732 | 累计平均损失: 0.4603
Epoch: 34/50 | Batch: 300/782 | 单Batch损失: 0.3624 | 累计平均损失: 0.4581
Epoch: 34/50 | Batch: 400/782 | 单Batch损失: 0.2882 | 累计平均损失: 0.4574
Epoch: 34/50 | Batch: 500/782 | 单Batch损失: 0.3933 | 累计平均损失: 0.4552
Epoch: 34/50 | Batch: 600/782 | 单Batch损失: 0.4164 | 累计平均损失: 0.4577
Epoch: 34/50 | Batch: 700/782 | 单Batch损失: 0.4240 | 累计平均损失: 0.4589
Epoch 34/50 完成 | 训练准确率: 83.84% | 测试准确率: 83.52%
Epoch: 35/50 | Batch: 100/782 | 单Batch损失: 0.5984 | 累计平均损失: 0.4505
Epoch: 35/50 | Batch: 200/782 | 单Batch损失: 0.3762 | 累计平均损失: 0.4503
Epoch: 35/50 | Batch: 300/782 | 单Batch损失: 0.6179 | 累计平均损失: 0.4561
Epoch: 35/50 | Batch: 400/782 | 单Batch损失: 0.4294 | 累计平均损失: 0.4586
Epoch: 35/50 | Batch: 500/782 | 单Batch损失: 0.5536 | 累计平均损失: 0.4597
Epoch: 35/50 | Batch: 600/782 | 单Batch损失: 0.7695 | 累计平均损失: 0.4597
Epoch: 35/50 | Batch: 700/782 | 单Batch损失: 0.6179 | 累计平均损失: 0.4614
Epoch 35/50 完成 | 训练准确率: 83.76% | 测试准确率: 84.31%
Epoch: 36/50 | Batch: 100/782 | 单Batch损失: 0.5466 | 累计平均损失: 0.4394
Epoch: 36/50 | Batch: 200/782 | 单Batch损失: 0.3466 | 累计平均损失: 0.4396
Epoch: 36/50 | Batch: 300/782 | 单Batch损失: 0.2771 | 累计平均损失: 0.4353
Epoch: 36/50 | Batch: 400/782 | 单Batch损失: 0.2139 | 累计平均损失: 0.4399
Epoch: 36/50 | Batch: 500/782 | 单Batch损失: 0.3482 | 累计平均损失: 0.4439
Epoch: 36/50 | Batch: 600/782 | 单Batch损失: 0.4815 | 累计平均损失: 0.4465
Epoch: 36/50 | Batch: 700/782 | 单Batch损失: 0.4194 | 累计平均损失: 0.4478
Epoch 36/50 完成 | 训练准确率: 84.29% | 测试准确率: 83.60%
Epoch: 37/50 | Batch: 100/782 | 单Batch损失: 0.5648 | 累计平均损失: 0.4479
Epoch: 37/50 | Batch: 200/782 | 单Batch损失: 0.4379 | 累计平均损失: 0.4410
Epoch: 37/50 | Batch: 300/782 | 单Batch损失: 0.4254 | 累计平均损失: 0.4399
Epoch: 37/50 | Batch: 400/782 | 单Batch损失: 0.2895 | 累计平均损失: 0.4428
Epoch: 37/50 | Batch: 500/782 | 单Batch损失: 0.3518 | 累计平均损失: 0.4439
Epoch: 37/50 | Batch: 600/782 | 单Batch损失: 0.4451 | 累计平均损失: 0.4441
Epoch: 37/50 | Batch: 700/782 | 单Batch损失: 0.4058 | 累计平均损失: 0.4459
Epoch 37/50 完成 | 训练准确率: 84.40% | 测试准确率: 84.51%
Epoch: 38/50 | Batch: 100/782 | 单Batch损失: 0.4155 | 累计平均损失: 0.4501
Epoch: 38/50 | Batch: 200/782 | 单Batch损失: 0.4825 | 累计平均损失: 0.4511
Epoch: 38/50 | Batch: 300/782 | 单Batch损失: 0.5833 | 累计平均损失: 0.4510
Epoch: 38/50 | Batch: 400/782 | 单Batch损失: 0.4195 | 累计平均损失: 0.4445
Epoch: 38/50 | Batch: 500/782 | 单Batch损失: 0.3762 | 累计平均损失: 0.4443
Epoch: 38/50 | Batch: 600/782 | 单Batch损失: 0.5810 | 累计平均损失: 0.4440
Epoch: 38/50 | Batch: 700/782 | 单Batch损失: 0.3335 | 累计平均损失: 0.4436
Epoch 38/50 完成 | 训练准确率: 84.35% | 测试准确率: 84.04%
Epoch: 39/50 | Batch: 100/782 | 单Batch损失: 0.5044 | 累计平均损失: 0.4341
Epoch: 39/50 | Batch: 200/782 | 单Batch损失: 0.4293 | 累计平均损失: 0.4381
Epoch: 39/50 | Batch: 300/782 | 单Batch损失: 0.4864 | 累计平均损失: 0.4369
Epoch: 39/50 | Batch: 400/782 | 单Batch损失: 0.4687 | 累计平均损失: 0.4348
Epoch: 39/50 | Batch: 500/782 | 单Batch损失: 0.3985 | 累计平均损失: 0.4358
Epoch: 39/50 | Batch: 600/782 | 单Batch损失: 0.4243 | 累计平均损失: 0.4366
Epoch: 39/50 | Batch: 700/782 | 单Batch损失: 0.4411 | 累计平均损失: 0.4386
Epoch 39/50 完成 | 训练准确率: 84.35% | 测试准确率: 84.25%
Epoch: 40/50 | Batch: 100/782 | 单Batch损失: 0.4993 | 累计平均损失: 0.4010
Epoch: 40/50 | Batch: 200/782 | 单Batch损失: 0.4146 | 累计平均损失: 0.4082
Epoch: 40/50 | Batch: 300/782 | 单Batch损失: 0.6128 | 累计平均损失: 0.4061
Epoch: 40/50 | Batch: 400/782 | 单Batch损失: 0.6048 | 累计平均损失: 0.4039
Epoch: 40/50 | Batch: 500/782 | 单Batch损失: 0.2145 | 累计平均损失: 0.4085
Epoch: 40/50 | Batch: 600/782 | 单Batch损失: 0.3212 | 累计平均损失: 0.4110
Epoch: 40/50 | Batch: 700/782 | 单Batch损失: 0.4806 | 累计平均损失: 0.4105
Epoch 40/50 完成 | 训练准确率: 85.56% | 测试准确率: 84.92%
Epoch: 41/50 | Batch: 100/782 | 单Batch损失: 0.5425 | 累计平均损失: 0.4034
Epoch: 41/50 | Batch: 200/782 | 单Batch损失: 0.5033 | 累计平均损失: 0.4010
Epoch: 41/50 | Batch: 300/782 | 单Batch损失: 0.5131 | 累计平均损失: 0.4055
Epoch: 41/50 | Batch: 400/782 | 单Batch损失: 0.3179 | 累计平均损失: 0.4026
Epoch: 41/50 | Batch: 500/782 | 单Batch损失: 0.3293 | 累计平均损失: 0.4049
Epoch: 41/50 | Batch: 600/782 | 单Batch损失: 0.3221 | 累计平均损失: 0.4047
Epoch: 41/50 | Batch: 700/782 | 单Batch损失: 0.4158 | 累计平均损失: 0.4048
Epoch 41/50 完成 | 训练准确率: 85.64% | 测试准确率: 84.80%
Epoch: 42/50 | Batch: 100/782 | 单Batch损失: 0.4801 | 累计平均损失: 0.4149
Epoch: 42/50 | Batch: 200/782 | 单Batch损失: 0.2000 | 累计平均损失: 0.4105
Epoch: 42/50 | Batch: 300/782 | 单Batch损失: 0.3847 | 累计平均损失: 0.4088
Epoch: 42/50 | Batch: 400/782 | 单Batch损失: 0.2396 | 累计平均损失: 0.4104
Epoch: 42/50 | Batch: 500/782 | 单Batch损失: 0.5950 | 累计平均损失: 0.4109
Epoch: 42/50 | Batch: 600/782 | 单Batch损失: 0.5241 | 累计平均损失: 0.4117
Epoch: 42/50 | Batch: 700/782 | 单Batch损失: 0.3273 | 累计平均损失: 0.4104
Epoch 42/50 完成 | 训练准确率: 85.52% | 测试准确率: 84.93%
Epoch: 43/50 | Batch: 100/782 | 单Batch损失: 0.3661 | 累计平均损失: 0.4097
Epoch: 43/50 | Batch: 200/782 | 单Batch损失: 0.5192 | 累计平均损失: 0.3928
Epoch: 43/50 | Batch: 300/782 | 单Batch损失: 0.4022 | 累计平均损失: 0.3967
Epoch: 43/50 | Batch: 400/782 | 单Batch损失: 0.3866 | 累计平均损失: 0.3963
Epoch: 43/50 | Batch: 500/782 | 单Batch损失: 0.6058 | 累计平均损失: 0.3987
Epoch: 43/50 | Batch: 600/782 | 单Batch损失: 0.4382 | 累计平均损失: 0.3997
Epoch: 43/50 | Batch: 700/782 | 单Batch损失: 0.5409 | 累计平均损失: 0.4021
Epoch 43/50 完成 | 训练准确率: 85.85% | 测试准确率: 84.88%
Epoch: 44/50 | Batch: 100/782 | 单Batch损失: 0.4297 | 累计平均损失: 0.3890
Epoch: 44/50 | Batch: 200/782 | 单Batch损失: 0.3757 | 累计平均损失: 0.3827
Epoch: 44/50 | Batch: 300/782 | 单Batch损失: 0.4636 | 累计平均损失: 0.3889
Epoch: 44/50 | Batch: 400/782 | 单Batch损失: 0.3794 | 累计平均损失: 0.3926
Epoch: 44/50 | Batch: 500/782 | 单Batch损失: 0.4853 | 累计平均损失: 0.3931
Epoch: 44/50 | Batch: 600/782 | 单Batch损失: 0.3573 | 累计平均损失: 0.3960
Epoch: 44/50 | Batch: 700/782 | 单Batch损失: 0.3538 | 累计平均损失: 0.3981
Epoch 44/50 完成 | 训练准确率: 85.90% | 测试准确率: 84.82%
Epoch: 45/50 | Batch: 100/782 | 单Batch损失: 0.5312 | 累计平均损失: 0.3968
Epoch: 45/50 | Batch: 200/782 | 单Batch损失: 0.4579 | 累计平均损失: 0.3912
Epoch: 45/50 | Batch: 300/782 | 单Batch损失: 0.2741 | 累计平均损失: 0.3939
Epoch: 45/50 | Batch: 400/782 | 单Batch损失: 0.4357 | 累计平均损失: 0.3942
Epoch: 45/50 | Batch: 500/782 | 单Batch损失: 0.2150 | 累计平均损失: 0.3940
Epoch: 45/50 | Batch: 600/782 | 单Batch损失: 0.3173 | 累计平均损失: 0.3926
Epoch: 45/50 | Batch: 700/782 | 单Batch损失: 0.2830 | 累计平均损失: 0.3935
Epoch 45/50 完成 | 训练准确率: 86.12% | 测试准确率: 85.01%
Epoch: 46/50 | Batch: 100/782 | 单Batch损失: 0.2203 | 累计平均损失: 0.3814
Epoch: 46/50 | Batch: 200/782 | 单Batch损失: 0.2126 | 累计平均损失: 0.3861
Epoch: 46/50 | Batch: 300/782 | 单Batch损失: 0.3392 | 累计平均损失: 0.3904
Epoch: 46/50 | Batch: 400/782 | 单Batch损失: 0.4534 | 累计平均损失: 0.3941
Epoch: 46/50 | Batch: 500/782 | 单Batch损失: 0.5200 | 累计平均损失: 0.3928
Epoch: 46/50 | Batch: 600/782 | 单Batch损失: 0.4988 | 累计平均损失: 0.3919
Epoch: 46/50 | Batch: 700/782 | 单Batch损失: 0.3091 | 累计平均损失: 0.3936
Epoch 46/50 完成 | 训练准确率: 86.10% | 测试准确率: 84.89%
Epoch: 47/50 | Batch: 100/782 | 单Batch损失: 0.4145 | 累计平均损失: 0.3821
Epoch: 47/50 | Batch: 200/782 | 单Batch损失: 0.2262 | 累计平均损失: 0.3902
Epoch: 47/50 | Batch: 300/782 | 单Batch损失: 0.4841 | 累计平均损失: 0.3933
Epoch: 47/50 | Batch: 400/782 | 单Batch损失: 0.2731 | 累计平均损失: 0.3920
Epoch: 47/50 | Batch: 500/782 | 单Batch损失: 0.2827 | 累计平均损失: 0.3898
Epoch: 47/50 | Batch: 600/782 | 单Batch损失: 0.2895 | 累计平均损失: 0.3881
Epoch: 47/50 | Batch: 700/782 | 单Batch损失: 0.6257 | 累计平均损失: 0.3906
Epoch 47/50 完成 | 训练准确率: 86.19% | 测试准确率: 85.16%
Epoch: 48/50 | Batch: 100/782 | 单Batch损失: 0.3067 | 累计平均损失: 0.3838
Epoch: 48/50 | Batch: 200/782 | 单Batch损失: 0.4014 | 累计平均损失: 0.3908
Epoch: 48/50 | Batch: 300/782 | 单Batch损失: 0.4236 | 累计平均损失: 0.3943
Epoch: 48/50 | Batch: 400/782 | 单Batch损失: 0.3618 | 累计平均损失: 0.3938
Epoch: 48/50 | Batch: 500/782 | 单Batch损失: 0.4159 | 累计平均损失: 0.3892
Epoch: 48/50 | Batch: 600/782 | 单Batch损失: 0.3298 | 累计平均损失: 0.3905
Epoch: 48/50 | Batch: 700/782 | 单Batch损失: 0.3324 | 累计平均损失: 0.3892
Epoch 48/50 完成 | 训练准确率: 86.16% | 测试准确率: 85.32%
Epoch: 49/50 | Batch: 100/782 | 单Batch损失: 0.3237 | 累计平均损失: 0.3801
Epoch: 49/50 | Batch: 200/782 | 单Batch损失: 0.3632 | 累计平均损失: 0.3872
Epoch: 49/50 | Batch: 300/782 | 单Batch损失: 0.2550 | 累计平均损失: 0.3838
Epoch: 49/50 | Batch: 400/782 | 单Batch损失: 0.2802 | 累计平均损失: 0.3859
Epoch: 49/50 | Batch: 500/782 | 单Batch损失: 0.4700 | 累计平均损失: 0.3872
Epoch: 49/50 | Batch: 600/782 | 单Batch损失: 0.4471 | 累计平均损失: 0.3875
Epoch: 49/50 | Batch: 700/782 | 单Batch损失: 0.4551 | 累计平均损失: 0.3873
Epoch 49/50 完成 | 训练准确率: 86.12% | 测试准确率: 85.16%
Epoch: 50/50 | Batch: 100/782 | 单Batch损失: 0.3697 | 累计平均损失: 0.3955
Epoch: 50/50 | Batch: 200/782 | 单Batch损失: 0.2297 | 累计平均损失: 0.3878
Epoch: 50/50 | Batch: 300/782 | 单Batch损失: 0.5298 | 累计平均损失: 0.3907
Epoch: 50/50 | Batch: 400/782 | 单Batch损失: 0.3974 | 累计平均损失: 0.3869
Epoch: 50/50 | Batch: 500/782 | 单Batch损失: 0.3202 | 累计平均损失: 0.3893
Epoch: 50/50 | Batch: 600/782 | 单Batch损失: 0.4020 | 累计平均损失: 0.3885
Epoch: 50/50 | Batch: 700/782 | 单Batch损失: 0.4807 | 累计平均损失: 0.3894
Epoch 50/50 完成 | 训练准确率: 86.14% | 测试准确率: 85.38%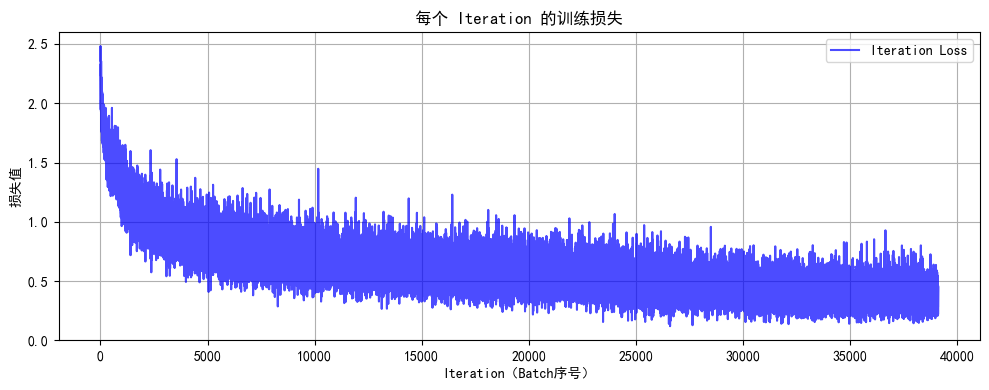
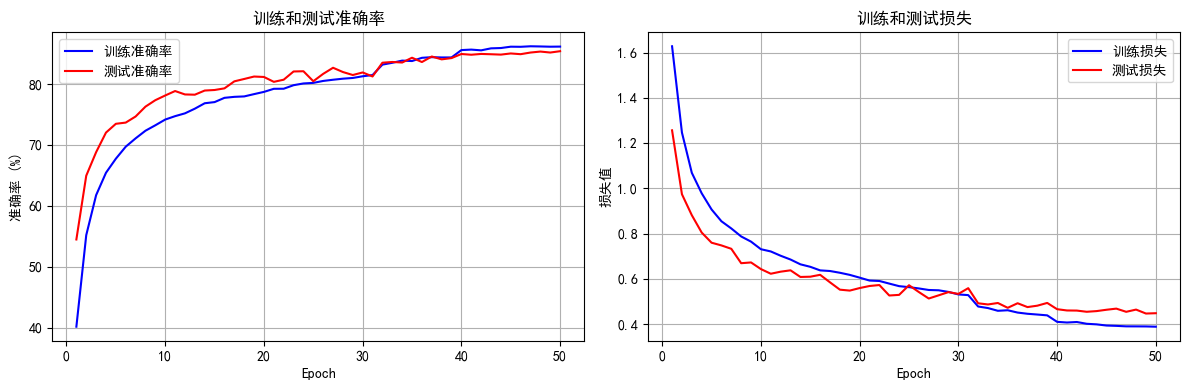
训练完成!最终测试准确率: 85.38%在同样50个epoch后精度略有提升
我们关注的不只是精度的差异,还包含了同精度下训练时长的差异等,在大规模数据集上推理时长、训练时长都非常重要。因为资源是有限的。
可视化部分同理,在训练完成后通过钩子函数取出权重or梯度,即可进行特征图的可视化、Grad-CAM可视化、注意力热图可视化
python
# 可视化空间注意力热力图(显示模型关注的图像区域)
def visualize_attention_map(model, test_loader, device, class_names, num_samples=3):
"""可视化模型的注意力热力图,展示模型关注的图像区域"""
model.eval() # 设置为评估模式
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
if i >= num_samples: # 只可视化前几个样本
break
images, labels = images.to(device), labels.to(device)
# 创建一个钩子,捕获中间特征图
activation_maps = []
def hook(module, input, output):
activation_maps.append(output.cpu())
# 为最后一个卷积层注册钩子(获取特征图)
hook_handle = model.conv3.register_forward_hook(hook)
# 前向传播,触发钩子
outputs = model(images)
# 移除钩子
hook_handle.remove()
# 获取预测结果
_, predicted = torch.max(outputs, 1)
# 获取原始图像
img = images[0].cpu().permute(1, 2, 0).numpy()
# 反标准化处理
img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)
img = np.clip(img, 0, 1)
# 获取激活图(最后一个卷积层的输出)
feature_map = activation_maps[0][0].cpu() # 取第一个样本
# 计算通道注意力权重(使用SE模块的全局平均池化)
channel_weights = torch.mean(feature_map, dim=(1, 2)) # [C]
# 按权重对通道排序
sorted_indices = torch.argsort(channel_weights, descending=True)
# 创建子图
fig, axes = plt.subplots(1, 4, figsize=(16, 4))
# 显示原始图像
axes[0].imshow(img)
axes[0].set_title(f'原始图像\n真实: {class_names[labels[0]]}\n预测: {class_names[predicted[0]]}')
axes[0].axis('off')
# 显示前3个最活跃通道的热力图
for j in range(3):
channel_idx = sorted_indices[j]
# 获取对应通道的特征图
channel_map = feature_map[channel_idx].numpy()
# 归一化到[0,1]
channel_map = (channel_map - channel_map.min()) / (channel_map.max() - channel_map.min() + 1e-8)
# 调整热力图大小以匹配原始图像
from scipy.ndimage import zoom
heatmap = zoom(channel_map, (32/feature_map.shape[1], 32/feature_map.shape[2]))
# 显示热力图
axes[j+1].imshow(img)
axes[j+1].imshow(heatmap, alpha=0.5, cmap='jet')
axes[j+1].set_title(f'注意力热力图 - 通道 {channel_idx}')
axes[j+1].axis('off')
plt.tight_layout()
plt.show()
# 调用可视化函数
visualize_attention_map(model, test_loader, device, class_names, num_samples=3)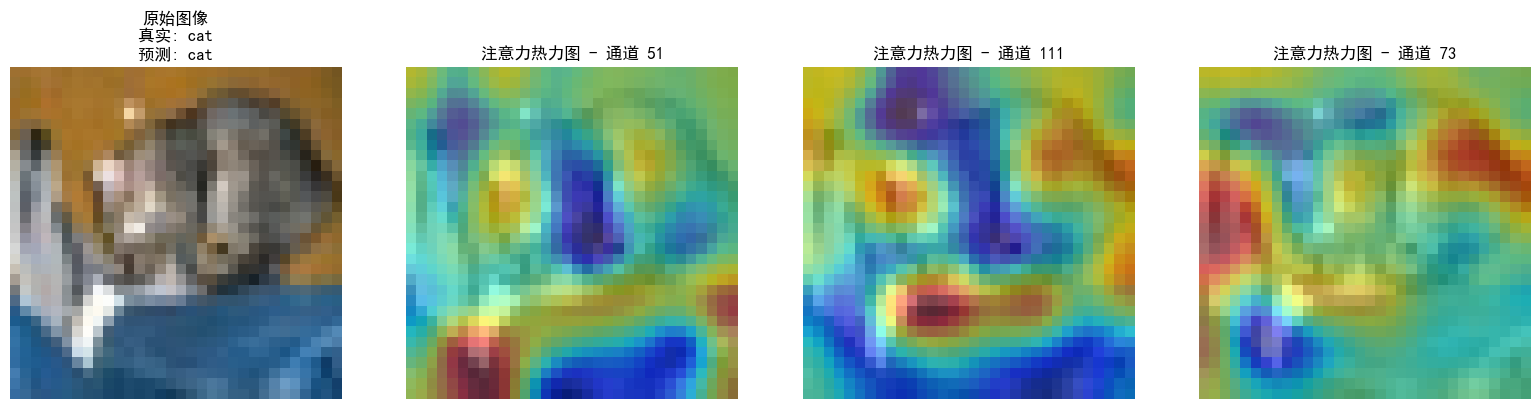
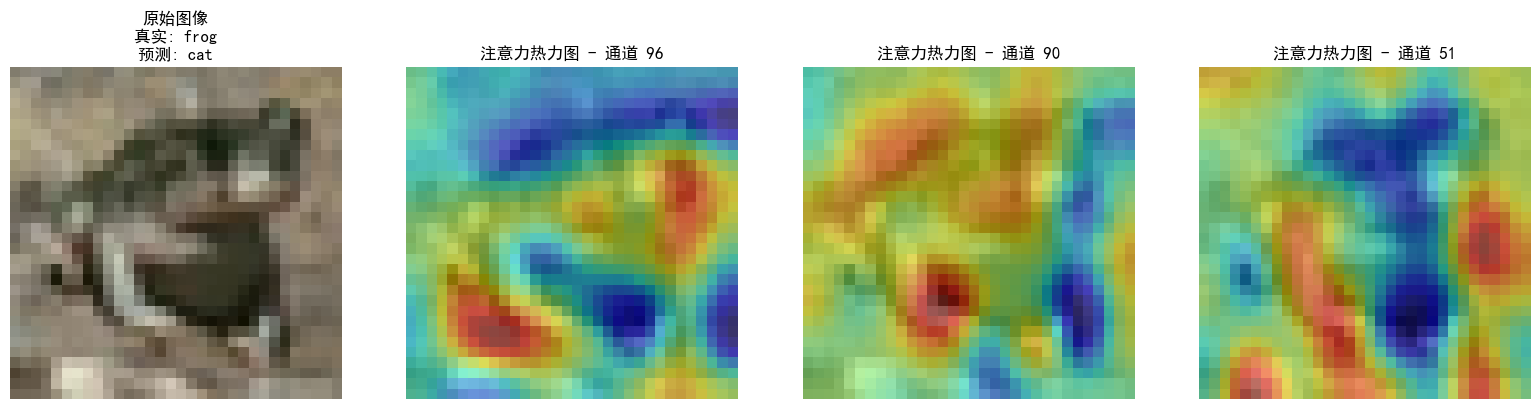
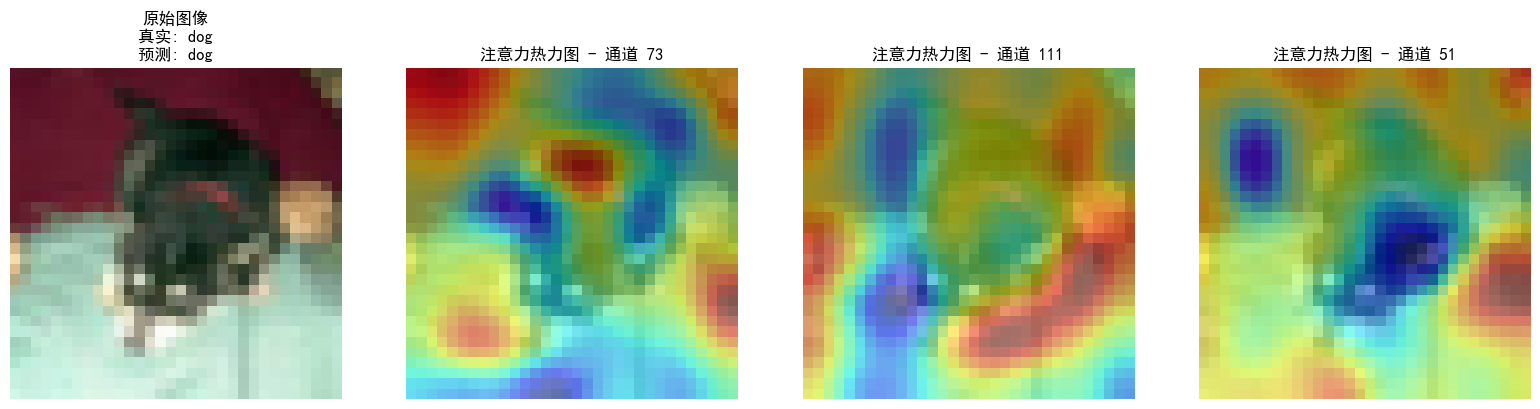
这个注意力热图是通过构子机制: register_forward_hook 捕获最后一个卷积层(conv3)的输出特征图。
- 通道权重计算:对特征图的每个通道进行全局平均池化,得到通道重要性权重。
- 热力图生成:将高权重通道的特征图缩放至原始图像尺寸,与原图叠加显示。
热力图(红色表示高关注,蓝色表示低关注)半透明覆盖在原图上。主要从以下方面理解:
- 高关注区域 (红色):模型认为对分类最重要的区域。
例如:- 在识别"狗"时,热力图可能聚焦狗的面部、身体轮廓或特征性纹理。
- 若热力图错误聚焦背景(如红色区域在无关物体上),可能表示模型过拟合或训练不足。
多通道对比
- 不同通道关注不同特征 :
例如:- 通道1可能关注整体轮廓,通道2关注纹理细节,通道3关注颜色分布。
- 结合多个通道的热力图,可全面理解模型的决策逻辑。
可以帮助解释
- 检查模型是否关注正确区域(如识别狗时,是否聚焦狗而非背景)。
- 发现数据标注问题(如标签错误、图像噪声)。
- 向非技术人员解释模型决策依据(如"模型认为这是狗,因为关注了眼睛和嘴巴")。