
文章目录
Spark基于Standalone提交任务流程
在Standalone模式下,Spark的任务提交根据Driver程序运行的位置不同,分为client和cluster两种模式。在这两种模式中,Driver负责应用程序的资源申请、任务分发、结果回收以及监控任务执行。以下分别介绍Client和Cluster模式。
一、Standalone-Client模式
1、提交命令
在启动Standalone集群后,可在node4节点上执行以下命令以Client模式提交任务
bash
[root@node4 ~]# cd /software/spark-3.5.5/bin/
#第一种方式
[root@node4 bin]# ./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.13-3.5.5.jar 1000
#第二种方式
[root@node4 bin]# ./spark-submit --master spark://node1:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.13-3.5.5.jar 1000以上命令中注意如下几点:
- "--master"参数指定Applicatin的Master URL,即运行模式;"--deploy-mode"参数指定Driver程序的部署模式,可选Client/Cluster,默认为Client;"--class"参数指定Application的主类。
- 两种提交方式的区别在于是否显式指定--deploy-mode参数,该参数默认为client模式,因此可以省略。
- 任务提交后,可以在客户端看到"SparkSubmit"进程,该进程可以看做为Driver进程;在Standalone集群Worker节点可以看到"CoarseGrainedExecutorBackend"进程,该进程为Executor进程,负责执行Task。
2、任务执行流程
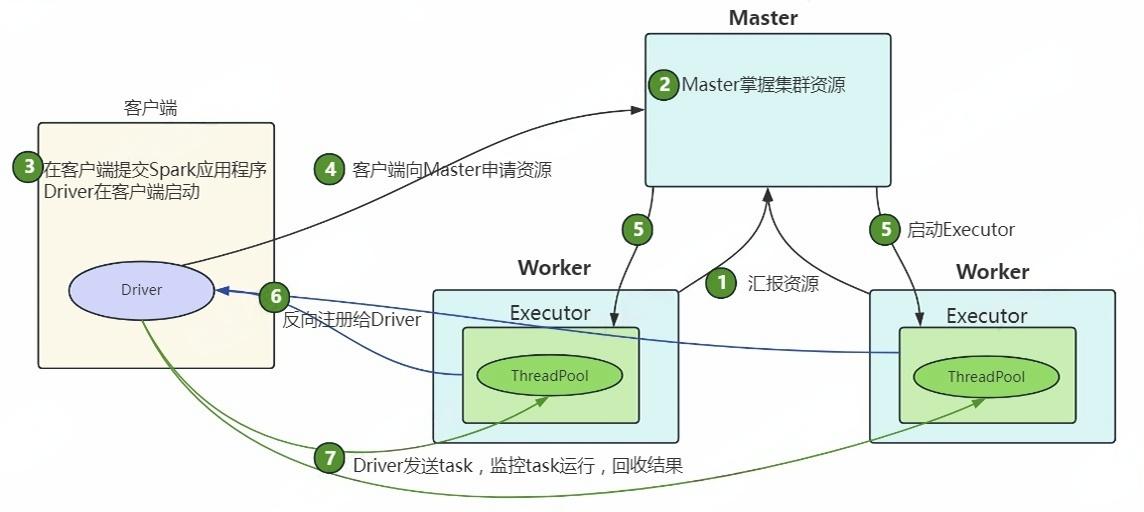
Standalone Client模式提交任务流程如下图所示:
-
Standalone集群启动后,Worker向Master汇报资源,Master掌握集群资源。
-
客户端使用spark-sumbmit提交任务,Driver在客户端启动。
-
Driver向Master申请启动Application所需的资源。
-
Master收到请求之后会在相应的Worker节点上启动Executor进程。
-
Executor启动后,向Driver注册,Driver掌握一批计算资源。
-
Driver将task分发到Executor执行,Executor将task执行结果返回给Driver。
总结:在Standalone-Client模式中,Driver进程在提交Application的客户端节点上启动,客户端可以查看任务的执行情况和结果。此模式适用于测试环境,不建议用于生产环境。原因在于,当客户端提交大量Application时,所有Driver都在客户端启动,Driver与集群之间存在大量通信,可能导致客户端网络流量激增。
二、Standalone-Cluster模式
1、提交命令
在启动Standalone集群后,可在node4节点上执行以下命令以Cluster模式提交任务:
bash
[root@node4 ~]# cd /software/spark-3.5.5/bin/
[root@node4 bin]# ./spark-submit --master spark://node1:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.13-3.5.5.jar 1000需要注意:
- "--master"参数指定Application的Master URL,即运行模式;"--deploy-mode"参数指定Driver程序的部署模式,可选Client或Cluster,默认为Client;"--class"参数指定Application的主类。
- 任务提交后,可以在Worker节点上看到"DriverWrapper"(Driver进程)和"CoarseGrainedExecutorBackend"(Executor进程)。
- 在Standalone-Cluster模式下,任务提交后,客户端无法直接查看任务结果,需要通过Web UI查看Driver的日志以获取结果。
2、任务执行流程
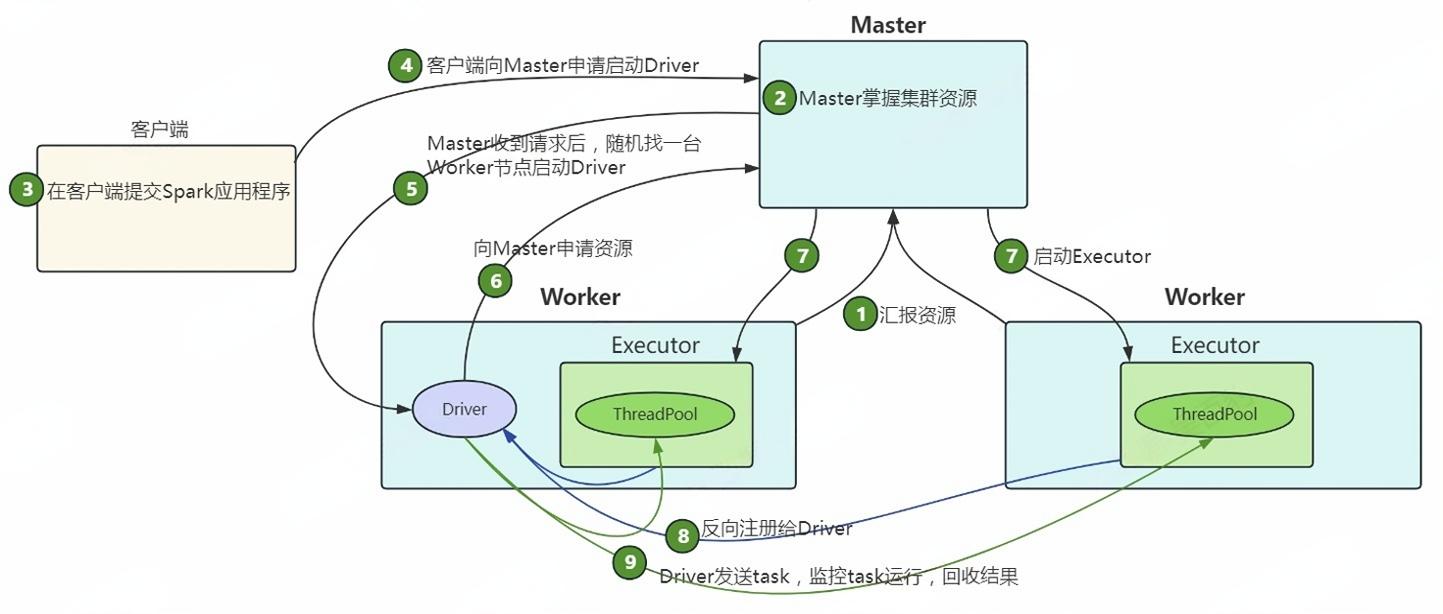
Standalone Cluster模式提交任务流程如下图所示:
-
Standalone集群启动,Worker向Master汇报资源,Master掌握集群资源状况。
-
客户端使用 spark-submit 提交应用程序后,向 Master 请求启动 Driver。
-
Master 接受请求,在集群中的某个 Worker 节点上启动 Driver 进程。
-
Driver 启动后,向Master申请启动Application所需的资源。
-
Master收到请求之后,在相应的Worker节点上启动Executor进程。
-
Executor启动后,向Driver注册,Driver掌握一批计算资源。
-
Driver将task分发到Executor执行,Executor将task执行结果返回给Driver。
总结:在Standalone-Cluster模式中,Driver进程在集群的某个Worker节点上启动,客户端无法直接查看任务的执行结果,需要通过集群的Web UI查看日志获取结果。此模式适用于生产环境,因为每个Application的Driver会随机在集群中的某个Worker上启动,避免了Client模式下客户端网络流量激增的问题。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨