在日常的数据采集、文档归档与信息挖掘过程中,PDF格式因其版式固定、内容稳定而被广泛使用。Python 开发者若希望实现 PDF 内容的自动化提取,选择一个易用且功能完善的库至关重要。本文将介绍如何用Python实现 PDF文本读取 、图片提取 以及 文档属性读取 三大核心操作,适用于信息抽取、电子档案处理等场景。
文章目录
本文使用免费的 Free Spire.PDF for Python,pip安装:pip install spire.pdf.free
Python读取PDF文本
在PDF中提取可识别的文字内容,是信息处理的基础需求。Spire.PDF 提供了 PdfTextExtractor 类,可逐页提取文本,并通过参数控制提取方式。
操作说明:
- 创建
PdfDocument实例并加载PDF; - 遍历每一页,构建
PdfTextExtractor; - 设置提取选项,如是否简化布局;
- 累加获取到的文本内容。
代码示例:
python
from spire.pdf import PdfDocument, PdfTextExtractor, PdfTextExtractOptions
# 创建 PdfDocument 实例并加载文档
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
all_text = ""
# 遍历所有页面
for pageIndex in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(pageIndex)
# 创建文本提取器
text_extractor = PdfTextExtractor(page)
# 设置提取选项
options = PdfTextExtractOptions()
options.IsExtractAllText = True
options.IsSimpleExtraction = True
# 提取文本并累加
all_text += text_extractor.ExtractText(options)
# 输出全部文本内容
print(all_text)PDF文档 :

读取的PDF文本 :

Python读取PDF图片
PDF中的图片可能包含插图、图标、水印等重要信息。Spire.PDF 提供了 PdfImageHelper 工具类,可提取页面中嵌入的图像并保存为文件。
操作说明:
- 加载PDF文档并获取页面;
- 使用
PdfImageHelper.GetImagesInfo()获取图片信息; - 遍历并保存提取的图片对象。
代码示例:
python
from spire.pdf import PdfDocument, PdfImageHelper
# 加载PDF文件
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
# 获取第一页
page = pdf.Pages.get_Item(0)
# 创建图片助手
image_helper = PdfImageHelper()
# 获取页面中的图片信息
images_info = image_helper.GetImagesInfo(page)
# 保存图片为本地文件
for i in range(len(images_info)):
images_info[i].Image.Save("output/Images/image" + str(i) + ".png")读取的PDF图片:
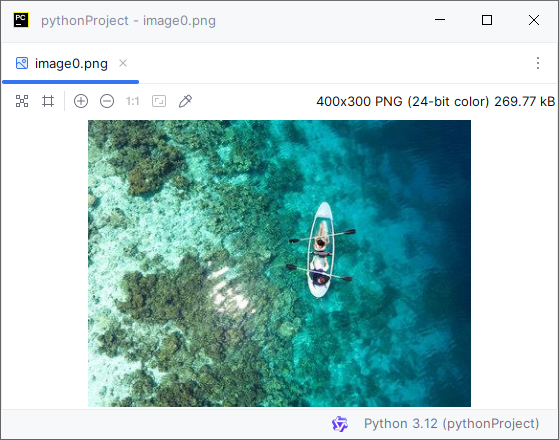
Python读取PDF文档属性
除了内容本身,PDF还可能包含元数据(如标题、作者、关键词等),便于进行文档分类与检索。Spire.PDF 支持直接读取这些信息。
操作说明:
- 加载PDF文件;
- 通过
DocumentInformation属性访问文档元数据; - 打印或记录相关属性值。
代码示例:
python
from spire.pdf import PdfDocument
# 加载PDF文件
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
# 获取文档属性信息
properties = pdf.DocumentInformation
print("标题: " + properties.Title)
print("作者: " + properties.Author)
print("主题: " + properties.Subject)
print("关键词: " + properties.Keywords)读取的PDF文档属性 :
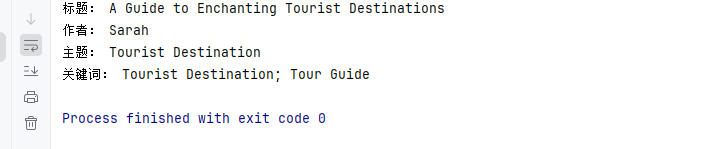
总结
使用 Free Spire.PDF for Python,可以轻松完成以下三类典型的 PDF 信息提取操作:
- 读取PDF文本:逐页提取文字内容,适用于全文分析、搜索系统等;
- 读取PDF图片:提取嵌入图像用于归档、识别或后续处理;
- 读取PDF文档属性:访问标题、作者、关键词等元信息,辅助分类索引。
以上功能均可在本地环境中快速部署,适合构建轻量级 PDF 处理工具或集成至业务系统中。
更多教程请参考:Spire.PDF for Python 教程中心