背景
在从服务从mysql迁移达梦数据库的方案中,我们如何快速发现哪些Mapper的中sql需要改写呢?
现有问题分析
当前通过人工检测SQL存在几个痛点:
-
效率低下,人工检查耗时耗力
-
容易遗漏,特别是大型项目中SQL数量众多时
由此我们提出了自动化检测方案。当然现在这种解析的sql方案有一定错误率,待我后续不断进行完善。
自动化检测方案
一、抽取出MyBatis Mapper XML 文件中sql
主要功能
-
扫描Mapper文件 :递归扫描指定目录(
src/main/resources/mapper)下的所有XML文件 -
解析SQL语句 :解析MyBatis的
select、insert、update、delete等SQL语句 -
处理动态SQL :模拟处理MyBatis的动态SQL标签(
if、where、foreach等) -
SQL重写:对提取的SQL进行格式化和方言转换(如MySQL到DM达梦数据库)
-
输出结果 :将所有提取的SQL语句保存到
Runnable_Extracted_SQLs.sql文件中
代码
java
package sql;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.File;
import java.io.PrintWriter;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class RunnableSQLExtractor {
private static final String MAPPER_DIR = "src/main/resources/mapper";
private static final String OUTPUT_FILE = "Runnable_Extracted_SQLs.sql";
public static void main(String[] args) {
System.out.println("🚀 开始提取可执行的SQL...");
try {
RunnableSQLExtractor extractor = new RunnableSQLExtractor();
extractor.extract();
System.out.println("✅ 成功提取SQL并保存到 " + OUTPUT_FILE);
} catch (Exception e) {
System.err.println("❌ 提取过程中发生错误:");
e.printStackTrace();
}
}
public void extract() throws Exception {
List<String> allSqlStatements = new ArrayList<>();
List<File> mapperFiles = getMapperFiles();
System.out.println("🔍 发现 " + mapperFiles.size() + " 个Mapper XML文件。");
for (File file : mapperFiles) {
try {
System.out.println("📄 正在处理: " + file.getName());
List<String> sqls = parseMapperFile(file);
allSqlStatements.addAll(sqls);
} catch (Exception e) {
System.err.println("⚠️ 文件处理失败: " + file.getName() + " - " + e.getMessage());
}
}
try (PrintWriter writer = new PrintWriter(OUTPUT_FILE)) {
for (String sql : allSqlStatements) {
writer.println(sql);
writer.println();
}
}
}
private List<File> getMapperFiles() throws Exception {
try (Stream<Path> paths = Files.walk(Paths.get(MAPPER_DIR))) {
return paths
.filter(Files::isRegularFile)
.filter(path -> path.toString().endsWith(".xml"))
.map(Path::toFile)
.collect(Collectors.toList());
}
}
private List<String> parseMapperFile(File file) throws Exception {
List<String> sqls = new ArrayList<>();
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse(file);
doc.getDocumentElement().normalize();
// 预加载 <sql> 片段
Map<String, Node> sqlFragments = new HashMap<>();
NodeList sqlNodes = doc.getElementsByTagName("sql");
for (int i = 0; i < sqlNodes.getLength(); i++) {
Node node = sqlNodes.item(i);
sqlFragments.put(node.getAttributes().getNamedItem("id").getNodeValue(), node);
}
String[] tags = {"select", "insert", "update", "delete"};
for (String tag : tags) {
NodeList nodes = doc.getElementsByTagName(tag);
for (int i = 0; i < nodes.getLength(); i++) {
Node node = nodes.item(i);
String id = node.getAttributes().getNamedItem("id").getNodeValue();
String header = String.format("-- [文件: %s] [ID: %s] [类型: %s]\n", file.getName(), id, tag);
String sql = buildSqlFromNode(node, sqlFragments);
sql = postProcessSql(sql);
if (!sql.trim().isEmpty()) {
sqls.add(header + rewriteSql(sql) + ";");
}
}
}
return sqls;
}
private String rewriteSql(String originalSql) {
// mysql IFNULL(col1,col2) => NVL(col1,col2) dm
originalSql = originalSql.replaceAll("(?i)GROUP_CONCAT", "WM_CONCAT");
originalSql = originalSql.replaceAll("(?i)!JSON_CONTAINS", " not JSON_CONTAINS ");
originalSql = originalSql.replaceAll("(?i)INSERT\\s+IGNORE\\s+INTO", "INSERT INTO ");
originalSql = convertCastToToChar(originalSql);
// log.debug("OriginalSql: " + originalSql+"\nRewrittenSql: " + originalSql);
return originalSql;
}
public static String convertCastToToChar(String sql) {
// 正则表达式匹配CAST(... AS CHAR)模式
Pattern pattern = Pattern.compile(
"CONVERT\\s*\\(\\s*(.+?)\\s*,\\s*(?:CHAR|VARCHAR|VARCHAR2|TEXT)\\s*(?:\\(\\d+\\))?\\s*\\)",
Pattern.CASE_INSENSITIVE
);
Matcher matcher = pattern.matcher(sql);
StringBuffer result = new StringBuffer();
while (matcher.find()) {
// 获取CAST内部的表达式
String innerExpression = matcher.group(1).trim();
// 替换为TO_CHAR格式
matcher.appendReplacement(result, "TO_CHAR(" + innerExpression + ")");
}
matcher.appendTail(result);
return result.toString();
}
private String buildSqlFromNode(Node node, Map<String, Node> sqlFragments) {
StringBuilder sql = new StringBuilder();
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
switch (child.getNodeType()) {
case Node.TEXT_NODE:
case Node.CDATA_SECTION_NODE:
sql.append(child.getNodeValue());
break;
case Node.ELEMENT_NODE:
sql.append(handleElementNode((Element) child, sqlFragments));
break;
}
}
return sql.toString();
}
private String handleElementNode(Element element, Map<String, Node> sqlFragments) {
String tagName = element.getTagName();
switch (tagName) {
case "if":
// 假设所有if条件都为true
return buildSqlFromNode(element, sqlFragments);
case "where":
return handleWhereTag(element, sqlFragments);
case "set":
return handleSetTag(element, sqlFragments);
case "foreach":
return handleForeachTag(element, sqlFragments);
case "trim":
return handleTrimTag(element, sqlFragments);
case "choose":
return handleChooseTag(element, sqlFragments);
case "include":
return handleIncludeTag(element, sqlFragments);
default:
// 对于未知标签,尝试递归处理其内容
return buildSqlFromNode(element, sqlFragments);
}
}
private String handleWhereTag(Element element, Map<String, Node> sqlFragments) {
String content = buildSqlFromNode(element, sqlFragments).trim();
content = content.replaceAll("^(?i)\\s*(and|or)\\s*", "");
return content.isEmpty() ? "" : "WHERE " + content;
}
private String handleSetTag(Element element, Map<String, Node> sqlFragments) {
String content = buildSqlFromNode(element, sqlFragments).trim();
content = content.replaceAll(",\\s*$", "");
return content.isEmpty() ? "" : "SET " + content;
}
private String handleForeachTag(Element element, Map<String, Node> sqlFragments) {
String open = element.hasAttribute("open") ? element.getAttribute("open") : "";
String close = element.hasAttribute("close") ? element.getAttribute("close") : "";
String separator = element.hasAttribute("separator") ? " " + element.getAttribute("separator") + " " : ", ";
// 生成3个示例值
return open + "1001" + separator + "1001" + separator + "1001" + close;
}
private String handleTrimTag(Element element, Map<String, Node> sqlFragments) {
String content = buildSqlFromNode(element, sqlFragments);
String prefix = element.hasAttribute("prefix") ? element.getAttribute("prefix") : "";
String suffix = element.hasAttribute("suffix") ? element.getAttribute("suffix") : "";
if (element.hasAttribute("prefixOverrides")) {
String overrides = element.getAttribute("prefixOverrides").trim();
content = content.trim();
for(String override : overrides.split("\\|")){
if(content.toLowerCase().startsWith(override.toLowerCase())){
content = content.substring(override.length());
break;
}
}
}
if (element.hasAttribute("suffixOverrides")) {
String overrides = element.getAttribute("suffixOverrides").trim();
content = content.trim();
for(String override : overrides.split("\\|")){
if(content.toLowerCase().endsWith(override.toLowerCase())){
content = content.substring(0, content.length() - override.length());
break;
}
}
}
return prefix + content.trim() + suffix;
}
private String handleChooseTag(Element element, Map<String, Node> sqlFragments) {
NodeList children = element.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
if (child instanceof Element && "when".equals(child.getNodeName())) {
// 只选择第一个when分支
return buildSqlFromNode(child, sqlFragments);
}
}
// 如果没有when,检查otherwise
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
if (child instanceof Element && "otherwise".equals(child.getNodeName())) {
return buildSqlFromNode(child, sqlFragments);
}
}
return "";
}
private String handleIncludeTag(Element element, Map<String, Node> sqlFragments) {
String refid = element.getAttribute("refid");
Node fragment = sqlFragments.get(refid);
if (fragment != null) {
String fragmentSQL = buildSqlFromNode(fragment, sqlFragments);
// 支持在include中传递属性
if(element.hasChildNodes()) {
NodeList properties = element.getElementsByTagName("property");
for(int i = 0; i < properties.getLength(); i++) {
Node prop = properties.item(i);
String name = prop.getAttributes().getNamedItem("name").getNodeValue();
String value = prop.getAttributes().getNamedItem("value").getNodeValue();
fragmentSQL = fragmentSQL.replaceAll("\\$\\{" + name + "\\}", value);
}
}
return fragmentSQL;
}
return "";
}
private String postProcessSql(String sql) {
// 替换MyBatis变量
sql = sql.replaceAll("#\\{([^,)]+?)(,.*?)?\\}", "'sample_value'");
sql = sql.replaceAll("\\$\\{.*?\\}", "sample_column");
// 清理多余的空白
sql = sql.replaceAll("\\s+", " ").trim();
// 修复一些常见模式
sql = sql.replaceAll("(?i)where\\s+and\\s+", "WHERE ");
sql = sql.replaceAll("(?i)where\\s+or\\s+", "WHERE ");
return sql;
}
}二、验证sql
主要功能
-
数据库连接:连接到达梦数据库(DM Database)
-
SQL执行:执行从文件中读取的所有SQL语句
-
事务安全:所有操作在事务中执行,最后会回滚(rollback)以保证数据库不被实际修改
-
报告生成:生成详细的执行报告,包括成功和失败的SQL信息
代码
java
package sql;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.PrintWriter;
import java.sql.*;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.List;
public class MasterSQLRunner {
private static final String DB_URL = "jdbc:dm://ip:5236/xx";
private static final String DB_USER = "xxx";
private static final String DB_PASSWORD = "xxxxx";
private static final String DRIVER_CLASS = "dm.jdbc.driver.DmDriver";
private static final String SQL_FILE = "Runnable_Extracted_SQLs.sql";
private static final String REPORT_FILE = "Master_SQL_Execution_Report.txt";
public static void main(String[] args) {
System.out.println("🚀 终极SQL执行器启动...");
try {
MasterSQLRunner runner = new MasterSQLRunner();
runner.run();
} catch (Exception e) {
System.err.println("❌ 执行器发生严重错误:");
e.printStackTrace();
}
}
public void run() throws Exception {
// 1. 加载驱动
try {
Class.forName(DRIVER_CLASS);
System.out.println("✅ 数据库驱动加载成功。");
} catch (ClassNotFoundException e) {
System.err.println("❌ 数据库驱动未找到!请检查 CLASSPATH。");
throw e;
}
// 2. 解析SQL文件
List<SqlInfo> sqls = parseSqlFile();
System.out.println("📄 成功从 " + SQL_FILE + " 解析 " + sqls.size() + " 条SQL语句。");
List<ExecutionResult> results = new ArrayList<>();
int successCount = 0;
int failureCount = 0;
// 3. 连接数据库并执行
System.out.println("🔄 正在连接数据库并执行SQL...");
try (Connection conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PASSWORD)) {
System.out.println("✅ 数据库连接成功: " + conn.getMetaData().getURL());
conn.setAutoCommit(false); // 开启事务
for (SqlInfo sqlInfo : sqls) {
try (Statement stmt = conn.createStatement()) {
if (sqlInfo.type.equalsIgnoreCase("select")) {
// 对于查询,我们只关心它是否能成功执行
stmt.execute(sqlInfo.sql);
} else {
// 对于DML,我们执行它
stmt.executeUpdate(sqlInfo.sql);
}
results.add(new ExecutionResult(sqlInfo, true, null));
successCount++;
} catch (SQLException e) {
results.add(new ExecutionResult(sqlInfo, false, e.getMessage()));
failureCount++;
}
}
System.out.println("⏪ 正在回滚所有数据库操作...");
conn.rollback();
System.out.println("✅ 所有操作已回滚,数据库未受任何影响。");
} catch (SQLException e) {
System.err.println("❌ 数据库连接或执行期间发生错误!");
throw e;
}
System.out.println("📊 执行完毕。成功: " + successCount + ",失败: " + failureCount);
// 4. 生成报告
System.out.println("✍️ 正在生成执行报告...");
generateReport(results, successCount, failureCount);
System.out.println("✅ 报告已保存到 " + REPORT_FILE);
}
private List<SqlInfo> parseSqlFile() throws Exception {
List<SqlInfo> sqlList = new ArrayList<>();
StringBuilder currentSql = new StringBuilder();
String file = null, id = null, type = null;
try (BufferedReader br = new BufferedReader(new FileReader(SQL_FILE))) {
String line;
while ((line = br.readLine()) != null) {
if (line.startsWith("-- [文件:")) {
// 如果我们有一个待处理的SQL,先保存它
if (currentSql.length() > 0) {
sqlList.add(new SqlInfo(file, id, type, currentSql.toString()));
currentSql.setLength(0);
}
// 解析新的元数据
file = line.split("文件: ")[1].split("]")[0].trim();
id = line.split("ID: ")[1].split("]")[0].trim();
type = line.split("类型: ")[1].split("]")[0].trim();
} else if (!line.trim().isEmpty()) {
currentSql.append(line.trim()).append(" ");
}
}
// 添加最后一个SQL
if (currentSql.length() > 0) {
sqlList.add(new SqlInfo(file, id, type, currentSql.toString()));
}
}
return sqlList;
}
private void generateReport(List<ExecutionResult> results, int success, int failed) throws Exception {
try (PrintWriter writer = new PrintWriter(new File(REPORT_FILE))) {
writer.println("======================================================");
writer.println(" 终极SQL执行报告 (Master SQL Execution Report)");
writer.println("======================================================");
writer.println("报告生成时间: " + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new java.util.Date()));
writer.println("执行的SQL文件: " + SQL_FILE);
writer.println();
// 摘要
writer.println("----------");
writer.println(" 执行摘要");
writer.println("----------");
writer.println("总计SQL数量: " + results.size());
writer.println("✅ 成功: " + success);
writer.println("❌ 失败: " + failed);
writer.printf("成功率: %.2f%%%n", (double) success / results.size() * 100);
writer.println();
// 失败详情
if (failed > 0) {
writer.println("--------------------");
writer.println(" 失败SQL详细信息");
writer.println("--------------------");
for (ExecutionResult result : results) {
if (!result.isSuccess) {
writer.println();
writer.println("---");
writer.printf("[文件: %s] [ID: %s]%n", result.info.file, result.info.id);
writer.println("错误原因:");
writer.println(" " + result.errorMessage);
writer.println("原始SQL:");
writer.println(result.info.sql);
writer.println("---");
}
}
}
// 成功列表
if (success > 0) {
writer.println();
writer.println("--------------------");
writer.println(" 成功执行的SQL列表");
writer.println("--------------------");
for (ExecutionResult result : results) {
if (result.isSuccess) {
writer.printf("- [文件: %s] [ID: %s]%n", result.info.file, result.info.id);
}
}
}
}
}
// 内部类用于存储SQL信息
private static class SqlInfo {
final String file;
final String id;
final String type;
final String sql;
SqlInfo(String file, String id, String type, String sql) {
this.file = file;
this.id = id;
this.type = type;
this.sql = sql;
}
}
// 内部类用于存储执行结果
private static class ExecutionResult {
final SqlInfo info;
final boolean isSuccess;
final String errorMessage;
ExecutionResult(SqlInfo info, boolean isSuccess, String errorMessage) {
this.info = info;
this.isSuccess = isSuccess;
this.errorMessage = errorMessage;
}
}
}执行结果
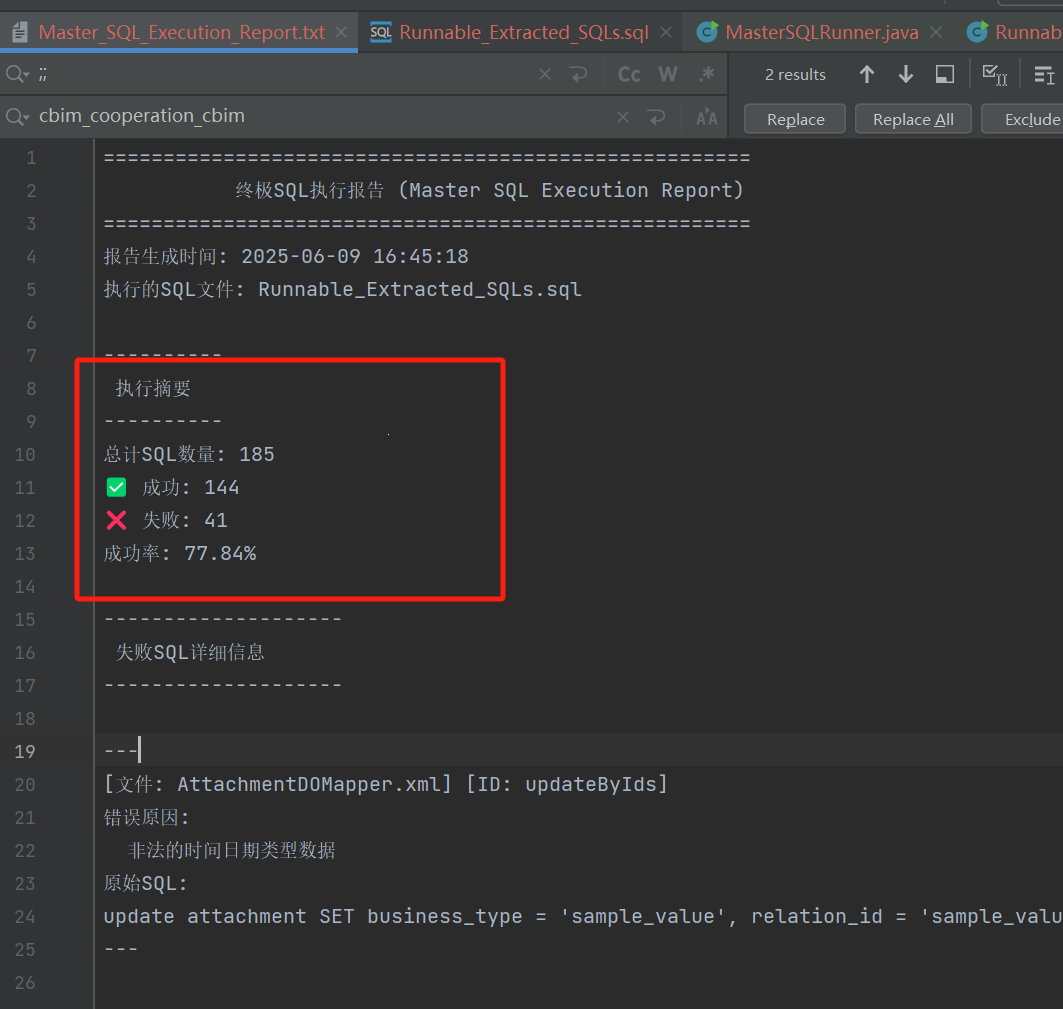
其中报告中有各个sql的执行错误原因及其sql。方便自己在达梦数据库客户端上进行测试和排查。