
分享一个视频分割神器 SAM2Long。该项目可以一键抠出视频中的主体,快速输出绿幕视频或者是透明通道视频。SAM2Long是SAM2的优化版本,使得 SAM2Long 在处理遮挡、目标重现等长视频常见问题时表现得更加稳健。
本地部署
部署有两种方式,一种是源码部署,一种是使用我已经制作好的一键包。
源码部署
安装PyTorch环境
python
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128安装本地SAM2代码库
python
pip install -e .下载模型检查点
Linux/macOS使用脚本下载
创建脚本文件:
plain
mkdir -p SAM2Long/checkpoints
nano SAM2Long/checkpoints/download_ckpts.shdownload_ckpts.sh内容
python
#!/bin/bash
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
# Use either wget or curl to download the checkpoints
if command -v wget &> /dev/null; then
CMD="wget"
elif command -v curl &> /dev/null; then
CMD="curl -L -O"
else
echo "Please install wget or curl to download the checkpoints."
exit 1
fi
# Define the URLs for SAM 2 checkpoints
# SAM2_BASE_URL="https://dl.fbaipublicfiles.com/segment_anything_2/072824"
# sam2_hiera_t_url="${SAM2_BASE_URL}/sam2_hiera_tiny.pt"
# sam2_hiera_s_url="${SAM2_BASE_URL}/sam2_hiera_small.pt"
# sam2_hiera_b_plus_url="${SAM2_BASE_URL}/sam2_hiera_base_plus.pt"
# sam2_hiera_l_url="${SAM2_BASE_URL}/sam2_hiera_large.pt"
# Download each of the four checkpoints using wget
# echo "Downloading sam2_hiera_tiny.pt checkpoint..."
# $CMD $sam2_hiera_t_url || { echo "Failed to download checkpoint from $sam2_hiera_t_url"; exit 1; }
# echo "Downloading sam2_hiera_small.pt checkpoint..."
# $CMD $sam2_hiera_s_url || { echo "Failed to download checkpoint from $sam2_hiera_s_url"; exit 1; }
# echo "Downloading sam2_hiera_base_plus.pt checkpoint..."
# $CMD $sam2_hiera_b_plus_url || { echo "Failed to download checkpoint from $sam2_hiera_b_plus_url"; exit 1; }
# echo "Downloading sam2_hiera_large.pt checkpoint..."
# $CMD $sam2_hiera_l_url || { echo "Failed to download checkpoint from $sam2_hiera_l_url"; exit 1; }
# Define the URLs for SAM 2.1 checkpoints
SAM2p1_BASE_URL="https://dl.fbaipublicfiles.com/segment_anything_2/092824"
sam2p1_hiera_t_url="${SAM2p1_BASE_URL}/sam2.1_hiera_tiny.pt"
sam2p1_hiera_s_url="${SAM2p1_BASE_URL}/sam2.1_hiera_small.pt"
sam2p1_hiera_b_plus_url="${SAM2p1_BASE_URL}/sam2.1_hiera_base_plus.pt"
sam2p1_hiera_l_url="${SAM2p1_BASE_URL}/sam2.1_hiera_large.pt"
# SAM 2.1 checkpoints
echo "Downloading sam2.1_hiera_tiny.pt checkpoint..."
$CMD $sam2p1_hiera_t_url || { echo "Failed to download checkpoint from $sam2p1_hiera_t_url"; exit 1; }
echo "Downloading sam2.1_hiera_small.pt checkpoint..."
$CMD $sam2p1_hiera_s_url || { echo "Failed to download checkpoint from $sam2p1_hiera_s_url"; exit 1; }
echo "Downloading sam2.1_hiera_base_plus.pt checkpoint..."
$CMD $sam2p1_hiera_b_plus_url || { echo "Failed to download checkpoint from $sam2p1_hiera_b_plus_url"; exit 1; }
echo "Downloading sam2.1_hiera_large.pt checkpoint..."
$CMD $sam2p1_hiera_l_url || { echo "Failed to download checkpoint from $sam2p1_hiera_l_url"; exit 1; }
echo "All checkpoints are downloaded successfully."添加执行权限:
plain
chmod +x SAM2Long/checkpoints/download_ckpts.sh运行脚本:
plain
cd SAM2Long/checkpoints && ./download_ckpts.shWindows脚本下载
创建批处理文件:
SAM2Long\checkpoints\download_ckpts.bat
bat脚本内容
python
@echo off
rem Copyright (c) Meta Platforms, Inc. and affiliates.
rem All rights reserved.
rem This source code is licensed under the license found in the
rem LICENSE file in the root directory of this source tree.
rem Check for wget or curl
set CMD=""
where wget >nul 2>&1
if %ERRORLEVEL% equ 0 (
set CMD=wget -O
) else (
where curl >nul 2>&1
if %ERRORLEVEL% equ 0 (
set CMD=curl -L -o
) else (
rem 如果既没有wget也没有curl,尝试使用PowerShell的Invoke-WebRequest
echo Neither wget nor curl found. Trying PowerShell Invoke-WebRequest...
set CMD=powershell
)
)
rem Define the URLs for SAM 2.1 checkpoints
set SAM2p1_BASE_URL=https://dl.fbaipublicfiles.com/segment_anything_2/092824
set sam2p1_hiera_t_url=%SAM2p1_BASE_URL%/sam2.1_hiera_tiny.pt
set sam2p1_hiera_s_url=%SAM2p1_BASE_URL%/sam2.1_hiera_small.pt
set sam2p1_hiera_b_plus_url=%SAM2p1_BASE_URL%/sam2.1_hiera_base_plus.pt
set sam2p1_hiera_l_url=%SAM2p1_BASE_URL%/sam2.1_hiera_large.pt
rem SAM 2.1 checkpoints
echo Downloading sam2.1_hiera_tiny.pt checkpoint...
if "%CMD%"=="wget -O" (
wget -O sam2.1_hiera_tiny.pt %sam2p1_hiera_t_url%
) else if "%CMD%"=="curl -L -o" (
curl -L -o sam2.1_hiera_tiny.pt %sam2p1_hiera_t_url%
) else (
powershell -Command "Invoke-WebRequest -Uri '%sam2p1_hiera_t_url%' -OutFile 'sam2.1_hiera_tiny.pt'"
)
if %ERRORLEVEL% neq 0 (
echo Failed to download checkpoint from %sam2p1_hiera_t_url%
exit /b 1
)
echo Downloading sam2.1_hiera_small.pt checkpoint...
if "%CMD%"=="wget -O" (
wget -O sam2.1_hiera_small.pt %sam2p1_hiera_s_url%
) else if "%CMD%"=="curl -L -o" (
curl -L -o sam2.1_hiera_small.pt %sam2p1_hiera_s_url%
) else (
powershell -Command "Invoke-WebRequest -Uri '%sam2p1_hiera_s_url%' -OutFile 'sam2.1_hiera_small.pt'"
)
if %ERRORLEVEL% neq 0 (
echo Failed to download checkpoint from %sam2p1_hiera_s_url%
exit /b 1
)
echo Downloading sam2.1_hiera_base_plus.pt checkpoint...
if "%CMD%"=="wget -O" (
wget -O sam2.1_hiera_base_plus.pt %sam2p1_hiera_b_plus_url%
) else if "%CMD%"=="curl -L -o" (
curl -L -o sam2.1_hiera_base_plus.pt %sam2p1_hiera_b_plus_url%
) else (
powershell -Command "Invoke-WebRequest -Uri '%sam2p1_hiera_b_plus_url%' -OutFile 'sam2.1_hiera_base_plus.pt'"
)
if %ERRORLEVEL% neq 0 (
echo Failed to download checkpoint from %sam2p1_hiera_b_plus_url%
exit /b 1
)
echo Downloading sam2.1_hiera_large.pt checkpoint...
if "%CMD%"=="wget -O" (
wget -O sam2.1_hiera_large.pt %sam2p1_hiera_l_url%
) else if "%CMD%"=="curl -L -o" (
curl -L -o sam2.1_hiera_large.pt %sam2p1_hiera_l_url%
) else (
powershell -Command "Invoke-WebRequest -Uri '%sam2p1_hiera_l_url%' -OutFile 'sam2.1_hiera_large.pt'"
)
if %ERRORLEVEL% neq 0 (
echo Failed to download checkpoint from %sam2p1_hiera_l_url%
exit /b 1
)
echo All checkpoints are downloaded successfully. 创建完成后,双击运行批处理文件。
手动下载
也可以直接访问以下四个链接下载对应模型
Tiny模型
plain
https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_tiny.ptSmall模型
plain
https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_small.ptBase+模型
plain
https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_base_plus.ptLarge模型
plain
https://dl.fbaipublicfiles.com/segment_anything_2/092824/sam2.1_hiera_large.pt模型说明:包含四种大小的预训练模型(Tiny<Small<Base<Large),根据机器配置自行选择。
安装Gradio
python
pip install gradio到这里安装就完成了,关于推理部分的实现,可以参考下方
基础调用(以DAVIS数据集为例)
python
python ./tools/vos_inference.py \
--sam2_cfg configs/sam2.1/sam2.1_hiera_b+.yaml \ # 配置文件
--sam2_checkpoint ./checkpoints/sam2.1_hiera_base_plus.pt \ # 模型文件
--base_video_dir /你的视频文件夹路径 \ # 存放视频的文件夹
--input_mask_dir /你的初始标记路径 \ # 第一帧的物体标记
--output_mask_dir ./预测结果输出 \ # 结果保存位置
--num_pathway 3 \ # 使用3条处理通道(平衡精度和速度)
--iou_thre 0.1 \ # 过滤掉低质量识别(值越小要求越严)
--uncertainty 2 # 识别稳定性设置(1-3之间调整)初次尝试建议num_pathway=1快速测试,正式使用时设为3效果最佳
gradio界面源码:
python
import subprocess
import re
from typing import List, Tuple, Optional
import spaces
# Define the command to be executed
command = ["python", "setup.py", "build_ext", "--inplace"]
# Execute the command
result = subprocess.run(command, capture_output=True, text=True)
css="""
div#component-18, div#component-25, div#component-35, div#component-41{
align-items: stretch!important;
}
"""
# Print the output and error (if any)
print("Output:\n", result.stdout)
print("Errors:\n", result.stderr)
# Check if the command was successful
if result.returncode == 0:
print("Command executed successfully.")
else:
print("Command failed with return code:", result.returncode)
import gradio as gr
from datetime import datetime
import os
os.environ["TORCH_CUDNN_SDPA_ENABLED"] = "1"
import torch
import numpy as np
import cv2
import matplotlib.pyplot as plt
from PIL import Image, ImageFilter
from sam2.build_sam import build_sam2_video_predictor
from moviepy.editor import ImageSequenceClip
def sparse_sampling(jpeg_images, original_fps, target_fps=6):
# Calculate the frame interval for sampling based on the target fps
frame_interval = int(original_fps // target_fps)
# Sparse sample the jpeg_images by selecting every 'frame_interval' frame
sampled_images = [jpeg_images[i] for i in range(0, len(jpeg_images), frame_interval)]
return sampled_images
def get_video_fps(video_path):
# Open the video file
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print("Error: Could not open video.")
return None
# Get the FPS of the video
fps = cap.get(cv2.CAP_PROP_FPS)
return fps
def clear_points(image):
# we clean all
return [
image, # first_frame_path
[], # tracking_points
[], # trackings_input_label
image, # points_map
#gr.State() # stored_inference_state
]
def preprocess_video_in(video_path):
# Generate a unique ID based on the current date and time
unique_id = datetime.now().strftime('%Y%m%d%H%M%S')
# Set directory with this ID to store video frames
extracted_frames_output_dir = f'frames_{unique_id}'
# Create the output directory
os.makedirs(extracted_frames_output_dir, exist_ok=True)
### Process video frames ###
# Open the video file
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print("Error: Could not open video.")
return None
# Get the frames per second (FPS) of the video
fps = cap.get(cv2.CAP_PROP_FPS)
# Calculate the number of frames to process (60 seconds of video)
max_frames = int(fps * 60)
frame_number = 0
first_frame = None
while True:
ret, frame = cap.read()
if not ret or frame_number >= max_frames:
break
if frame_number % 6 == 0:
# Format the frame filename as '00000.jpg'
frame_filename = os.path.join(extracted_frames_output_dir, f'{frame_number:05d}.jpg')
# Save the frame as a JPEG file
cv2.imwrite(frame_filename, frame)
# Store the first frame
if frame_number == 0:
first_frame = frame_filename
frame_number += 1
# Release the video capture object
cap.release()
# scan all the JPEG frame names in this directory
scanned_frames = [
p for p in os.listdir(extracted_frames_output_dir)
if os.path.splitext(p)[-1] in [".jpg", ".jpeg", ".JPG", ".JPEG"]
]
scanned_frames.sort(key=lambda p: int(os.path.splitext(p)[0]))
# print(f"SCANNED_FRAMES: {scanned_frames}")
return [
first_frame, # first_frame_path
[], # tracking_points
[], # trackings_input_label
first_frame, # input_first_frame_image
first_frame, # points_map
extracted_frames_output_dir, # video_frames_dir
scanned_frames, # scanned_frames
None, # stored_inference_state
None, # stored_frame_names
gr.update(open=False) # video_in_drawer
]
def get_point(point_type, tracking_points, trackings_input_label, input_first_frame_image, evt: gr.SelectData):
print(f"You selected {evt.value} at {evt.index} from {evt.target}")
tracking_points.append(evt.index)
# tracking_points.value.append(evt.index)
print(f"TRACKING POINT: {tracking_points}")
if point_type == "include":
trackings_input_label.append(1)
# trackings_input_label.value.append(1)
elif point_type == "exclude":
trackings_input_label.append(0)
# trackings_input_label.value.append(0)
print(f"TRACKING INPUT LABEL: {trackings_input_label}")
# Open the image and get its dimensions
transparent_background = Image.open(input_first_frame_image).convert('RGBA')
w, h = transparent_background.size
# Define the circle radius as a fraction of the smaller dimension
fraction = 0.02 # You can adjust this value as needed
radius = int(fraction * min(w, h))
# Create a transparent layer to draw on
transparent_layer = np.zeros((h, w, 4), dtype=np.uint8)
for index, track in enumerate(tracking_points):
if trackings_input_label[index] == 1:
cv2.circle(transparent_layer, track, radius, (0, 255, 0, 255), -1)
else:
cv2.circle(transparent_layer, track, radius, (255, 0, 0, 255), -1)
# Convert the transparent layer back to an image
transparent_layer = Image.fromarray(transparent_layer, 'RGBA')
selected_point_map = Image.alpha_composite(transparent_background, transparent_layer)
return tracking_points, trackings_input_label, selected_point_map
def show_mask(mask, ax, obj_id=None, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
cmap = plt.get_cmap("tab10")
cmap_idx = 0 if obj_id is None else obj_id
color = np.array([*cmap(cmap_idx)[:3], 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=200):
pos_points = coords[labels==1]
neg_points = coords[labels==0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
def load_model(checkpoint):
# Load model accordingly to user's choice
if checkpoint == "tiny":
sam2_checkpoint = "./checkpoints/sam2.1_hiera_tiny.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_t.yaml"
return [sam2_checkpoint, model_cfg]
elif checkpoint == "samll":
sam2_checkpoint = "./checkpoints/sam2.1_hiera_small.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_s.yaml"
return [sam2_checkpoint, model_cfg]
elif checkpoint == "base-plus":
sam2_checkpoint = "./checkpoints/sam2.1_hiera_base_plus.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_b+.yaml"
return [sam2_checkpoint, model_cfg]
# elif checkpoint == "large":
# sam2_checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
# model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
# return [sam2_checkpoint, model_cfg]
def get_mask_sam_process(
stored_inference_state,
input_first_frame_image,
checkpoint,
tracking_points,
trackings_input_label,
video_frames_dir, # extracted_frames_output_dir defined in 'preprocess_video_in' function
scanned_frames,
working_frame: str = None, # current frame being added points
available_frames_to_check: List[str] = [],
# progress=gr.Progress(track_tqdm=True)
):
# get model and model config paths
print(f"USER CHOSEN CHECKPOINT: {checkpoint}")
sam2_checkpoint, model_cfg = load_model(checkpoint)
print("MODEL LOADED")
# set predictor
predictor = build_sam2_video_predictor(model_cfg, sam2_checkpoint, device='cpu')
print("PREDICTOR READY")
# `video_dir` a directory of JPEG frames with filenames like `<frame_index>.jpg`
# print(f"STATE FRAME OUTPUT DIRECTORY: {video_frames_dir}")
video_dir = video_frames_dir
# scan all the JPEG frame names in this directory
frame_names = scanned_frames
# print(f"STORED INFERENCE STEP: {stored_inference_state}")
if stored_inference_state is None:
# Init SAM2 inference_state
inference_state = predictor.init_state(video_path=video_dir)
inference_state['num_pathway'] = 3
inference_state['iou_thre'] = 0.3
inference_state['uncertainty'] = 2
print("NEW INFERENCE_STATE INITIATED")
else:
inference_state = stored_inference_state
inference_state["device"] = 'cpu'
# segment and track one object
# predictor.reset_state(inference_state) # if any previous tracking, reset
### HANDLING WORKING FRAME
# new_working_frame = None
# Add new point
if working_frame is None:
ann_frame_idx = 0 # the frame index we interact with, 0 if it is the first frame
working_frame = "00000.jpg"
else:
# Use a regular expression to find the integer
match = re.search(r'frame_(\d+)', working_frame)
if match:
# Extract the integer from the match
frame_number = int(match.group(1))
ann_frame_idx = frame_number
print(f"NEW_WORKING_FRAME PATH: {working_frame}")
ann_obj_id = 1 # give a unique id to each object we interact with (it can be any integers)
# Let's add a positive click at (x, y) = (210, 350) to get started
points = np.array(tracking_points, dtype=np.float32)
# for labels, `1` means positive click and `0` means negative click
labels = np.array(trackings_input_label, np.int32)
_, out_obj_ids, out_mask_logits = predictor.add_new_points(
inference_state=inference_state,
frame_idx=ann_frame_idx,
obj_id=ann_obj_id,
points=points,
labels=labels,
)
# Create the plot
plt.figure(figsize=(12, 8))
plt.title(f"frame {ann_frame_idx}")
plt.imshow(Image.open(os.path.join(video_dir, frame_names[ann_frame_idx])))
show_points(points, labels, plt.gca())
show_mask((out_mask_logits[0] > 0.0).cpu().numpy(), plt.gca(), obj_id=out_obj_ids[0])
# Save the plot as a JPG file
first_frame_output_filename = "output_first_frame.jpg"
plt.savefig(first_frame_output_filename, format='jpg')
plt.close()
# torch.cuda.empty_cache()
# Assuming available_frames_to_check.value is a list
if working_frame not in available_frames_to_check:
available_frames_to_check.append(working_frame)
print(available_frames_to_check)
# return gr.update(visible=True), "output_first_frame.jpg", frame_names, predictor, inference_state, gr.update(choices=available_frames_to_check, value=working_frame, visible=True)
return "output_first_frame.jpg", frame_names, predictor, inference_state, gr.update(choices=available_frames_to_check, value=working_frame, visible=False)
@spaces.GPU
def propagate_to_all(video_in, checkpoint, stored_inference_state, stored_frame_names, video_frames_dir, vis_frame_type, available_frames_to_check, working_frame, progress=gr.Progress(track_tqdm=True)):
# use bfloat16 for the entire notebook
torch.autocast(device_type="cuda", dtype=torch.bfloat16).__enter__()
if torch.cuda.get_device_properties(0).major >= 8:
# turn on tfloat32 for Ampere GPUs (https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
#### PROPAGATION ####
sam2_checkpoint, model_cfg = load_model(checkpoint)
# set predictor
inference_state = stored_inference_state
if torch.cuda.is_available():
inference_state["device"] = 'cuda'
predictor = build_sam2_video_predictor(model_cfg, sam2_checkpoint)
else:
inference_state["device"] = 'cpu'
predictor = build_sam2_video_predictor(model_cfg, sam2_checkpoint, device='cpu')
frame_names = stored_frame_names
video_dir = video_frames_dir
# Define a directory to save the JPEG images
frames_output_dir = "frames_output_images"
os.makedirs(frames_output_dir, exist_ok=True)
# Initialize a list to store file paths of saved images
jpeg_images = []
# run propagation throughout the video and collect the results in a dict
video_segments = {} # video_segments contains the per-frame segmentation results
# for out_frame_idx, out_obj_ids, out_mask_logits in predictor.propagate_in_video(inference_state):
# video_segments[out_frame_idx] = {
# out_obj_id: (out_mask_logits[i] > 0.0).cpu().numpy()
# for i, out_obj_id in enumerate(out_obj_ids)
# }
out_obj_ids, out_mask_logits = predictor.propagate_in_video(inference_state, start_frame_idx=0, reverse=False,)
print(out_obj_ids)
for frame_idx in range(0, inference_state['num_frames']):
video_segments[frame_idx] = {out_obj_ids[0]: (out_mask_logits[frame_idx]> 0.0).cpu().numpy()}
# output_scores_per_object[object_id][frame_idx] = out_mask_logits[frame_idx].cpu().numpy()
# render the segmentation results every few frames
if vis_frame_type == "check":
vis_frame_stride = 15
elif vis_frame_type == "render":
vis_frame_stride = 1
plt.close("all")
for out_frame_idx in range(0, len(frame_names), vis_frame_stride):
plt.figure(figsize=(6, 4))
plt.title(f"frame {out_frame_idx}")
plt.imshow(Image.open(os.path.join(video_dir, frame_names[out_frame_idx])))
for out_obj_id, out_mask in video_segments[out_frame_idx].items():
show_mask(out_mask, plt.gca(), obj_id=out_obj_id)
# Define the output filename and save the figure as a JPEG file
output_filename = os.path.join(frames_output_dir, f"frame_{out_frame_idx}.jpg")
plt.savefig(output_filename, format='jpg')
# Close the plot
plt.close()
# Append the file path to the list
jpeg_images.append(output_filename)
if f"frame_{out_frame_idx}.jpg" not in available_frames_to_check:
available_frames_to_check.append(f"frame_{out_frame_idx}.jpg")
torch.cuda.empty_cache()
print(f"JPEG_IMAGES: {jpeg_images}")
if vis_frame_type == "check":
return gr.update(value=jpeg_images), gr.update(value=None), gr.update(choices=available_frames_to_check, value=working_frame, visible=True), available_frames_to_check, gr.update(visible=True)
elif vis_frame_type == "render":
# Create a video clip from the image sequence
original_fps = get_video_fps(video_in)
# sampled_images = sparse_sampling(jpeg_images, original_fps, target_fps=6)
clip = ImageSequenceClip(jpeg_images, fps=original_fps//6)
# clip = ImageSequenceClip(jpeg_images, fps=fps)
# Write the result to a file
final_vid_output_path = "output_video.mp4"
# Write the result to a file
clip.write_videofile(
final_vid_output_path,
codec='libx264'
)
return gr.update(value=None), gr.update(value=final_vid_output_path), working_frame, available_frames_to_check, gr.update(visible=True)
def update_ui(vis_frame_type):
if vis_frame_type == "check":
return gr.update(visible=True), gr.update(visible=False)
elif vis_frame_type == "render":
return gr.update(visible=False), gr.update(visible=True)
def switch_working_frame(working_frame, scanned_frames, video_frames_dir):
new_working_frame = None
if working_frame == None:
new_working_frame = os.path.join(video_frames_dir, scanned_frames[0])
else:
# Use a regular expression to find the integer
match = re.search(r'frame_(\d+)', working_frame)
if match:
# Extract the integer from the match
frame_number = int(match.group(1))
ann_frame_idx = frame_number
new_working_frame = os.path.join(video_frames_dir, scanned_frames[ann_frame_idx])
return gr.State([]), gr.State([]), new_working_frame, new_working_frame
def reset_propagation(first_frame_path, predictor, stored_inference_state):
predictor.reset_state(stored_inference_state)
# print(f"RESET State: {stored_inference_state} ")
return first_frame_path, [], [], gr.update(value=None, visible=False), stored_inference_state, None, ["frame_0.jpg"], first_frame_path, "frame_0.jpg", gr.update(visible=False)
with gr.Blocks(css=css) as demo:
first_frame_path = gr.State()
tracking_points = gr.State([])
trackings_input_label = gr.State([])
video_frames_dir = gr.State()
scanned_frames = gr.State()
loaded_predictor = gr.State()
stored_inference_state = gr.State()
stored_frame_names = gr.State()
available_frames_to_check = gr.State([])
with gr.Column():
gr.Markdown(
"""
<h1 style="text-align: center;">🔥 SAM2Long Demo 🔥</h1>
"""
)
gr.Markdown(
"""
This is a simple demo for video segmentation with [SAM2Long](https://github.com/Mark12Ding/SAM2Long).
"""
)
gr.Markdown(
"""
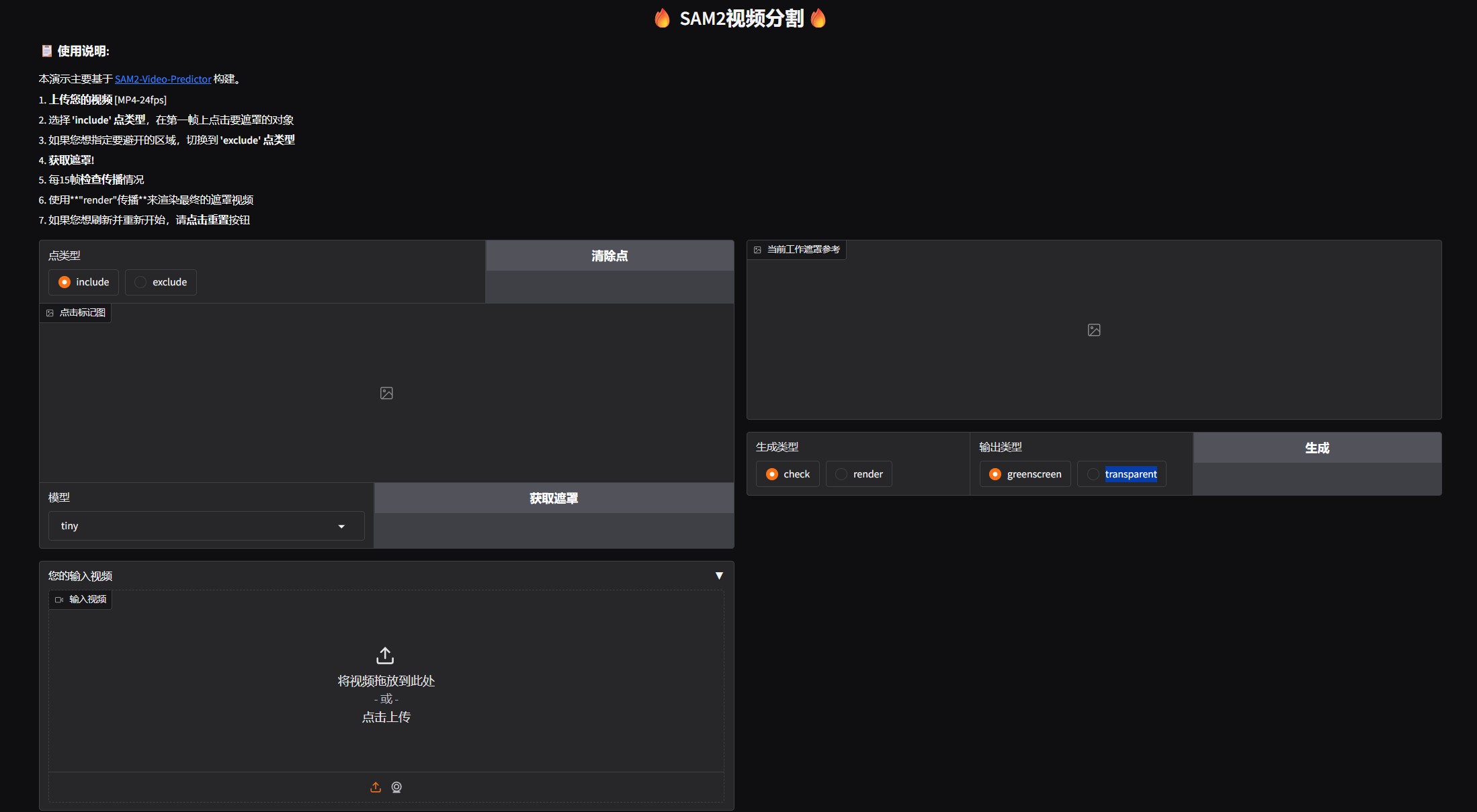
### 📋 Instructions:
It is largely built on the [SAM2-Video-Predictor](https://huggingface.co/spaces/fffiloni/SAM2-Video-Predictor).
1. **Upload your video** [MP4-24fps]
2. With **'include' point type** selected, click on the object to mask on the first frame
3. Switch to **'exclude' point type** if you want to specify an area to avoid
4. **Get Mask!**
5. **Check Propagation** every 15 frames
6. **Propagate with "render"** to render the final masked video
7. **Hit Reset** button if you want to refresh and start again
*Note: Input video will be processed for up to 60 seconds only for demo purposes.*
"""
)
with gr.Row():
with gr.Column():
with gr.Group():
with gr.Group():
with gr.Row():
point_type = gr.Radio(label="point type", choices=["include", "exclude"], value="include", scale=2)
clear_points_btn = gr.Button("Clear Points", scale=1)
input_first_frame_image = gr.Image(label="input image", interactive=False, type="filepath", visible=False)
points_map = gr.Image(
label="Point n Click map",
type="filepath",
interactive=False
)
with gr.Group():
with gr.Row():
checkpoint = gr.Dropdown(label="Checkpoint", choices=["tiny", "small", "base-plus"], value="tiny")
submit_btn = gr.Button("Get Mask", size="lg")
with gr.Accordion("Your video IN", open=True) as video_in_drawer:
video_in = gr.Video(label="Video IN", format="mp4")
gr.HTML("""
<a href="https://huggingface.co/spaces/{os.environ['SPACE_ID']}?duplicate=true">
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/duplicate-this-space-lg-dark.svg" alt="Duplicate this Space" />
</a> to skip queue and avoid OOM errors from heavy public load
""")
with gr.Column():
with gr.Group():
# with gr.Group():
# with gr.Row():
working_frame = gr.Dropdown(label="working frame ID", choices=["frame_0.jpg"], value="frame_0.jpg", visible=False, allow_custom_value=False, interactive=True)
# change_current = gr.Button("change current", visible=False)
# working_frame = []
output_result = gr.Image(label="current working mask ref")
with gr.Group():
with gr.Row():
vis_frame_type = gr.Radio(label="Propagation level", choices=["check", "render"], value="check", scale=2)
propagate_btn = gr.Button("Propagate", scale=2)
reset_prpgt_brn = gr.Button("Reset", visible=False)
output_propagated = gr.Gallery(label="Propagated Mask samples gallery", columns=4, visible=False)
output_video = gr.Video(visible=False)
# output_result_mask = gr.Image()
# When new video is uploaded
video_in.upload(
fn = preprocess_video_in,
inputs = [video_in],
outputs = [
first_frame_path,
tracking_points, # update Tracking Points in the gr.State([]) object
trackings_input_label, # update Tracking Labels in the gr.State([]) object
input_first_frame_image, # hidden component used as ref when clearing points
points_map, # Image component where we add new tracking points
video_frames_dir, # Array where frames from video_in are deep stored
scanned_frames, # Scanned frames by SAM2
stored_inference_state, # Sam2 inference state
stored_frame_names, #
video_in_drawer, # Accordion to hide uploaded video player
],
queue = False
)
# triggered when we click on image to add new points
points_map.select(
fn = get_point,
inputs = [
point_type, # "include" or "exclude"
tracking_points, # get tracking_points values
trackings_input_label, # get tracking label values
input_first_frame_image, # gr.State() first frame path
],
outputs = [
tracking_points, # updated with new points
trackings_input_label, # updated with corresponding labels
points_map, # updated image with points
],
queue = False
)
# Clear every points clicked and added to the map
clear_points_btn.click(
fn = clear_points,
inputs = input_first_frame_image, # we get the untouched hidden image
outputs = [
first_frame_path,
tracking_points,
trackings_input_label,
points_map,
#stored_inference_state,
],
queue=False
)
# change_current.click(
# fn = switch_working_frame,
# inputs = [working_frame, scanned_frames, video_frames_dir],
# outputs = [tracking_points, trackings_input_label, input_first_frame_image, points_map],
# queue=False
# )
submit_btn.click(
fn = get_mask_sam_process,
inputs = [
stored_inference_state,
input_first_frame_image,
checkpoint,
tracking_points,
trackings_input_label,
video_frames_dir,
scanned_frames,
working_frame,
available_frames_to_check,
],
outputs = [
output_result,
stored_frame_names,
loaded_predictor,
stored_inference_state,
working_frame,
],
queue=False
)
reset_prpgt_brn.click(
fn = reset_propagation,
inputs = [first_frame_path, loaded_predictor, stored_inference_state],
outputs = [points_map, tracking_points, trackings_input_label, output_propagated, stored_inference_state, output_result, available_frames_to_check, input_first_frame_image, working_frame, reset_prpgt_brn],
queue=False
)
propagate_btn.click(
fn = update_ui,
inputs = [vis_frame_type],
outputs = [output_propagated, output_video],
queue=False
).then(
fn = propagate_to_all,
inputs = [video_in, checkpoint, stored_inference_state, stored_frame_names, video_frames_dir, vis_frame_type, available_frames_to_check, working_frame],
outputs = [output_propagated, output_video, working_frame, available_frames_to_check, reset_prpgt_brn]
)
demo.launch()使用方法
这里介绍下使用方法(gradio界面版本)
上传需要处理的视频
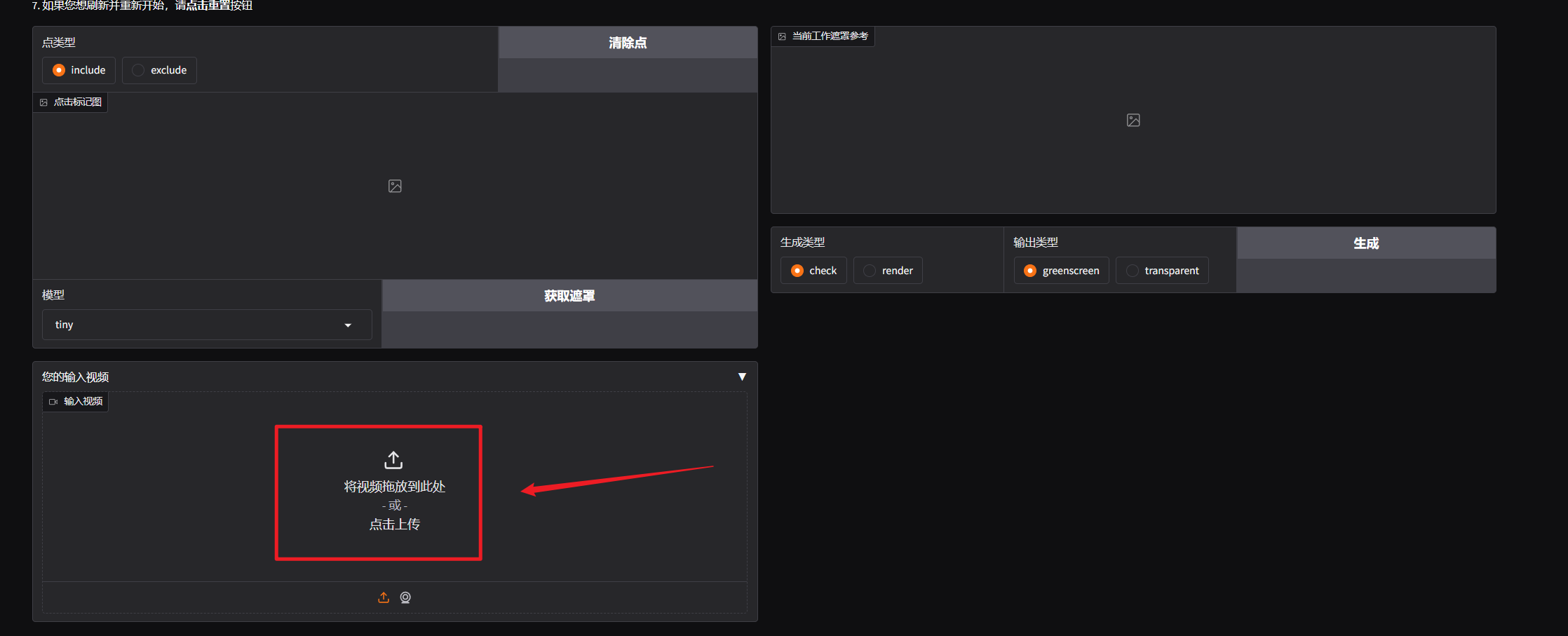
然后在点类型这里选择处理方式。(include保留选中的部分,exclude保留选中以外的部分,一般选择默认的include)
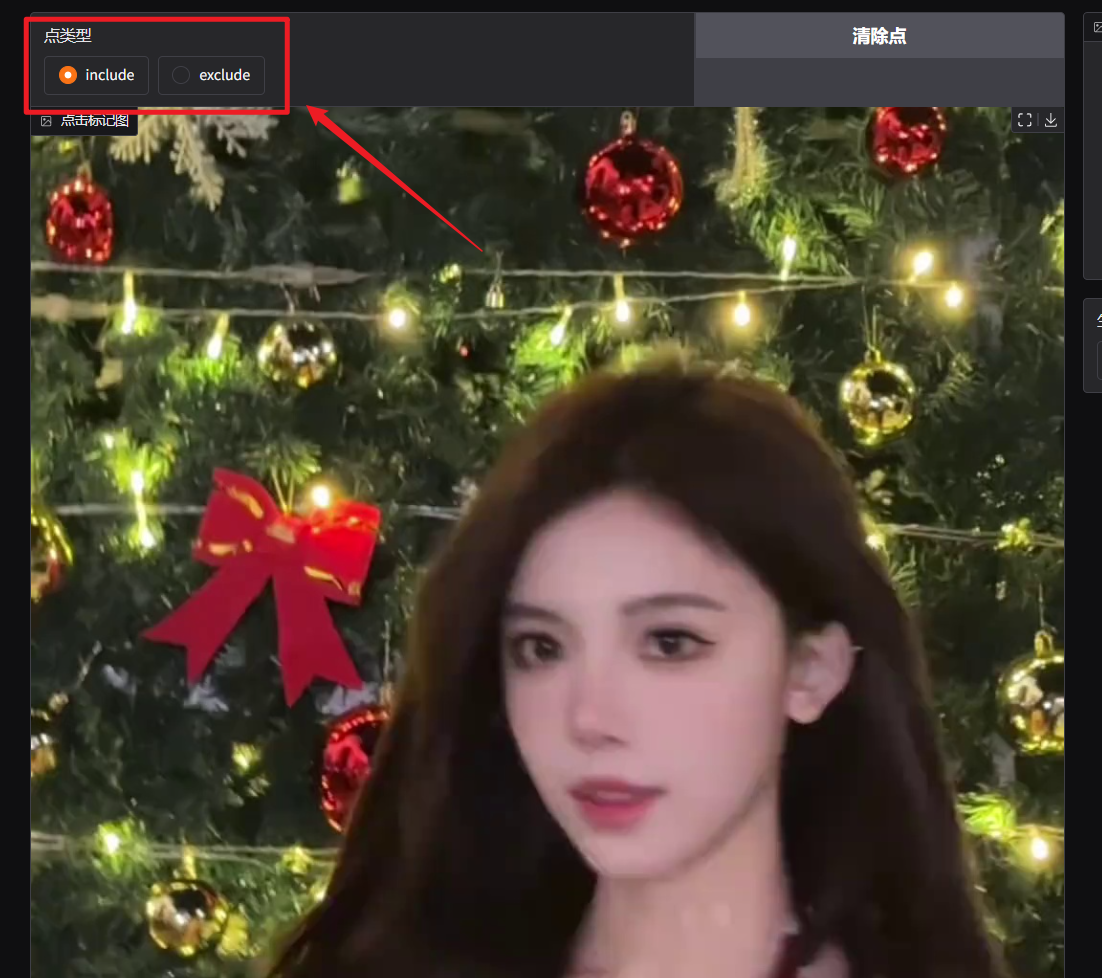
然后增加关键点,点击图片中的部分即可。这里我想将人物抠出来。在人物脸部增加一个关键点

然后点击下方的获取遮罩,我们需要先预览下抠像效果。
可以看到右侧的预览结果,发现人物的衣服和头发并没有包含在内,需要再添加多个点来完善。
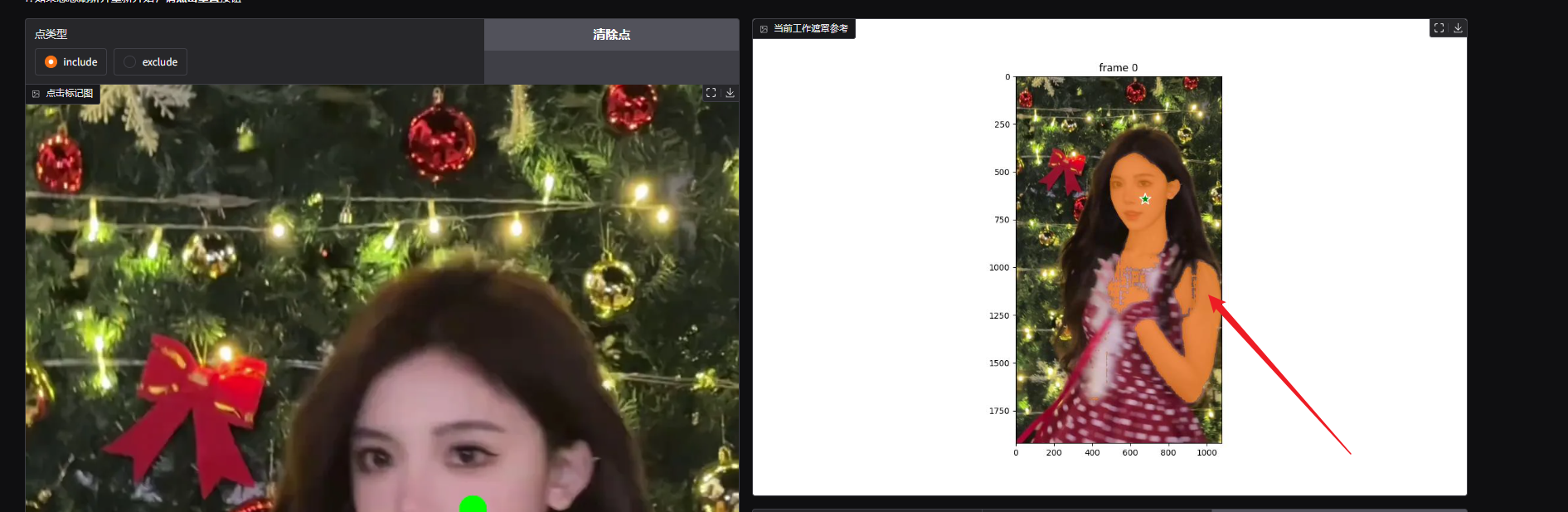
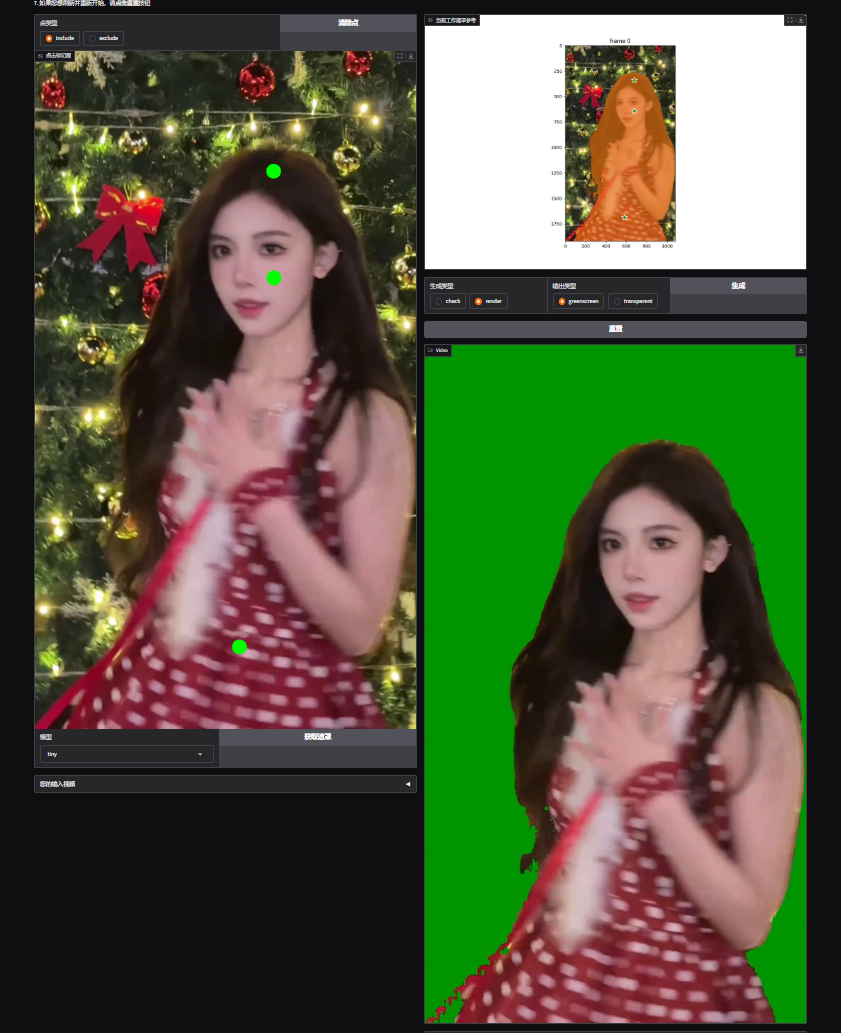
增加了两个点,这次再看下抠像效果。

可以看到这次人物的头发、身体以及衣服都被选中了。

然后在生成类型中选择render。输出类型根据你自己需求选择(greenscreen:输出绿幕视频。transparent:输出包含透明通道的mov视频)

选择完毕后点击生成耐心等待。
配置需求
WIN
WindowsN卡需8G显存
如果运行报错,需要安装cuda12.8
https://developer.nvidia.com/cuda-12-8-0-download-archive
支持50系显卡
MAC
暂不支持
关于速度
11秒视频(每秒24帧),tiny模型,合成绿幕视频
4090完成需要60秒左右。
5090完成需要45秒左右。
整合包获取
👇🏻👇🏻👇🏻下方下方下方👇🏻👇🏻👇🏻
夸夸夸盘:
https://pan.quark.cn/s/97f447f03235
度度度盘:
https://pan.baidu.com/s/1BFVfRCnnCdDOCpwDUTvcbQ?pwd=fbdf
制作不易,如果本文对您有帮助,还请点个免费的赞或在看!感谢您的阅读!