目录
[一、Redis 集群方式](#一、Redis 集群方式)
[1. 主从模式](#1. 主从模式)
[2. 哨兵模式](#2. 哨兵模式)
[3. 集群模式](#3. 集群模式)
[1. 客户端分片](#1. 客户端分片)
[2. 代理分片](#2. 代理分片)
[(2)Twemproxy 代理分片机制](#(2)Twemproxy 代理分片机制)
[(3)Codis 代理分片机制](#(3)Codis 代理分片机制)
[3. 服务器端分片](#3. 服务器端分片)
[1. 故障转移](#1. 故障转移)
[2. 多 slave 选举](#2. 多 slave 选举)
[六、Redis 群集部署](#六、Redis 群集部署)
[1. 部署基础环境](#1. 部署基础环境)
[2. 安装 redis (每个节点都要安装)](#2. 安装 redis (每个节点都要安装))
[3. 修改配置文件](#3. 修改配置文件)
[4. 重启服务并查看状态](#4. 重启服务并查看状态)
[5. 创建 redis 群集](#5. 创建 redis 群集)
[6. 测试群集](#6. 测试群集)
[7. 集群信息查看](#7. 集群信息查看)
[8. 添加节点](#8. 添加节点)
[9. 修改新节点为其他节点的从节点](#9. 修改新节点为其他节点的从节点)
[10. 重新分配槽位](#10. 重新分配槽位)
[11. 删除节点](#11. 删除节点)
一、Redis 集群方式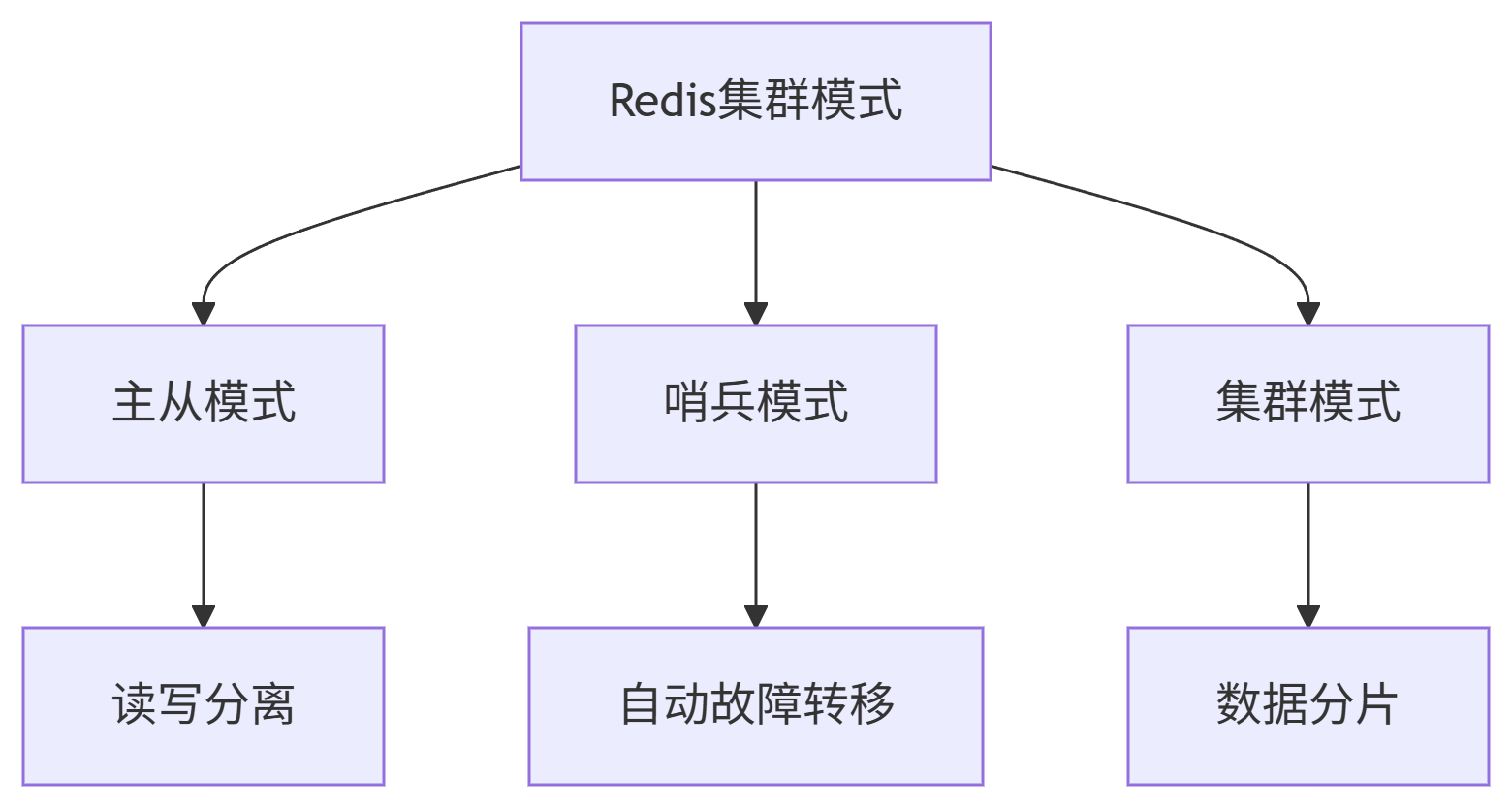
1. 主从模式
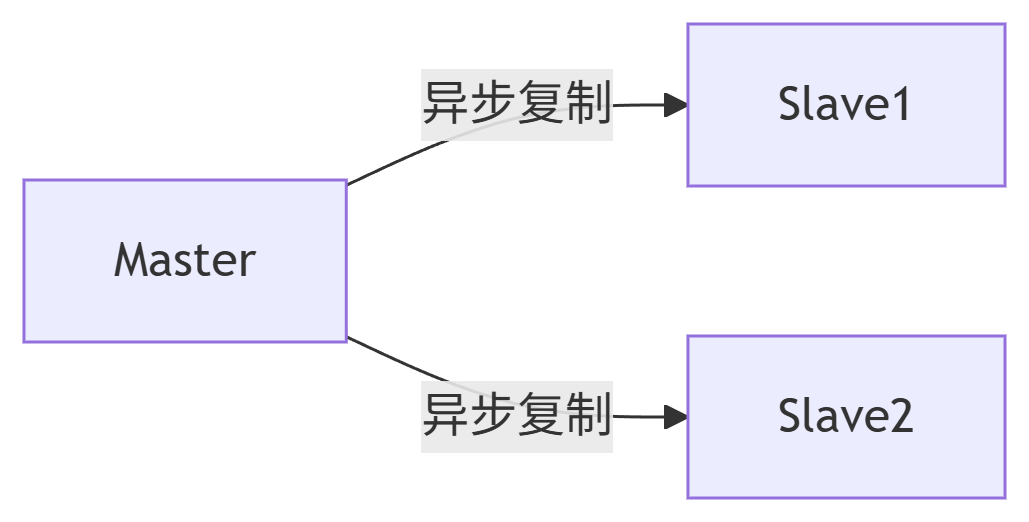
核心概念:
- 单主节点负责读写,从节点被动复制主节点数据,实现数据备份和读写分离。
- 基于
replicaof命令实现主从关系,从节点只读,主节点可读可写。核心能力:
读写分离:写请求到 Master,读请求到 Slave
数据冗余:Slave 全量复制 Master 数据
手动故障切换:需人工干预主节点故障
局限:
单点写入瓶颈
无自动故障转移
2. 哨兵模式
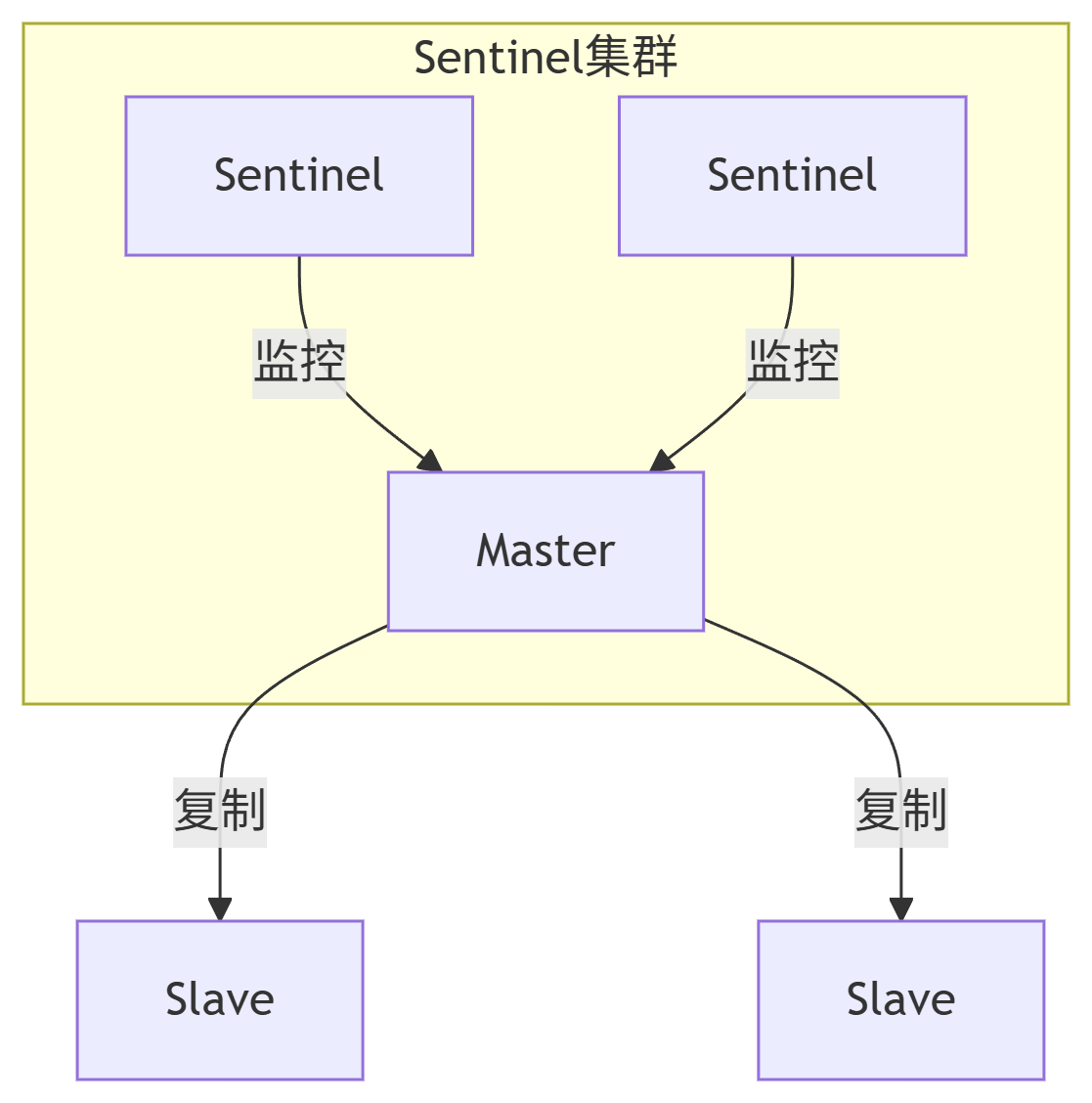
核心概念:
- 在主从模式基础上引入 哨兵节点(Sentinel),形成监控集群。
- 哨兵负责:
- 监控主从节点状态(心跳检测)。
- 自动故障转移(主节点宕机时,选举从节点成为新主)。
- 通知客户端节点拓扑变化。
核心能力:
自动故障转移:Master 宕机时选举新主
配置中心:客户端自动获取拓扑信息
集群监控:实时检测节点健康
局限:
未解决数据分片问题
写性能受单节点限制
3. 集群模式
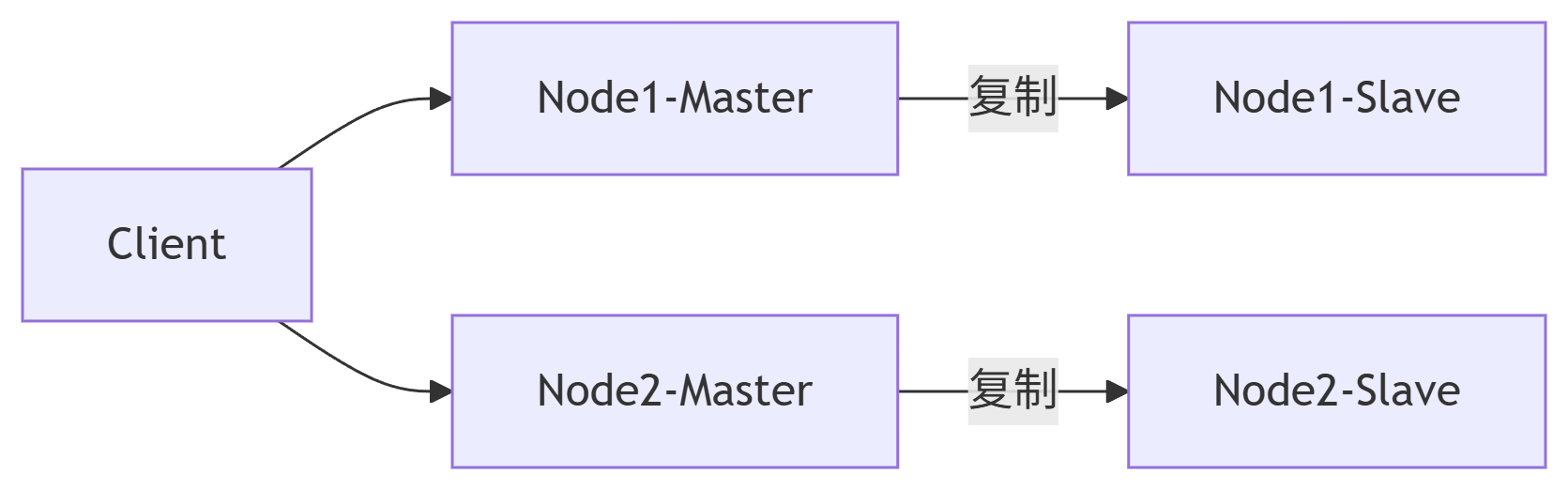
核心概念:
- 分布式集群架构,数据通过 分片(Sharding) 分布在多个节点,支持横向扩展。
- 每个节点既是主节点(负责数据)也是集群成员(通过 Gossip 协议通信)。
- 引入 哈希槽(Hash Slot) 机制:将数据键映射到
0~16383共16384个槽中,每个主节点负责一部分槽。核心能力:
数据分片:16384 个槽位分散到多节点
自动路由:客户端直连正确节点
高可用:主从切换 + 多副本存储
适用场景:
数据量 > 单机内存
要求高并发写入
二、集群模式简介
1. 架构设计
- 节点角色 :分为 主节点(Master) (处理读写、维护集群元数据)和 从节点(Slave)(备份主节点数据,主故障时可晋升为新主)。
- 无中心节点:通过 Gossip 协议实现节点间拓扑信息同步,客户端可连接任意节点。
2. 容错与部署
- 投票容错 :需 超过半数节点投票 判定某节点故障(如 3 主节点时,2 票即可标记故障),避免 "误判"。
- 最小部署 :
- 主节点至少
3 个(满足投票机制的 "多数决" 条件); - 若为每个主节点搭配 1 个从节点,需
3 主 + 3 从 = 6 节点(提升高可用,应对主节点故障)。所有节点开启集群模式:cluster-enabled yes
- 主节点至少
3. 核心能力
-
自动分片 :通过 哈希槽(16384 个) 分配数据,支持水平扩展(官方理论支持上万节点,实际推荐 ≤1000 节点)。
-
自主高可用:内置故障转移能力(无需 Sentinel 哨兵),主节点故障时,从节点自动选举新主。
-
核心特性:
| 特性 | 说明 |
| 去中心化 | 无代理层,节点间 Gossip 协议通信 |
| 数据分片 | 基于哈希槽(Slot)分布数据 |
| 跨节点操作 | 支持MGET/MSET等跨槽命令 |迁移透明 槽迁移期间自动重定向请求
4. 适用场景与优势
- 场景 :面向 海量数据、高并发、高可用 需求(如电商缓存、社交平台实时数据)。
- 优势:性能、扩展性和高可用性均优于哨兵模式,且部署配置更简单。
三、数据分片方式
1. 客户端分片
- 概念 :
应用层实现分片逻辑,直接连接不同 Redis 节点,根据键计算目标节点。 - 实现方式 :
- 哈希取模:
node = hash(key) % N(N 为节点数)。 - 一致性哈希:减少节点增减时的数据迁移量。
- 哈希取模:
- 优缺点 :
- ✅ 无中间层,性能高。
- ❌ 客户端复杂度高(需维护节点列表),动态扩缩容需重启应用。
- 典型工具 :
Jedis Cluster(Redis 官方客户端)、Redisson。
2. 代理分片
通过中间代理层处理分片逻辑,客户端仅需连接代理。
(1)概述
- 优点:客户端无感知,适配传统单节点客户端。
- 缺点:代理可能成为性能瓶颈或单点,需部署多实例(如主从 / 集群)。
(2)Twemproxy 代理分片机制
- 机制 :
- 静态分片:代理启动时通过配置文件指定节点与槽的映射,不支持动态调整。
- 请求转发:代理解析键,根据配置路由到目标节点。
- 局限性:扩缩容需重启代理,适合静态架构。
(3)Codis 代理分片机制
优势:
动态扩容:槽迁移无需停机
Web 管理界面:可视化操作
多语言 SDK:兼容原生 Redis 协议
机制:
- 动态分片:通过管理节点(Codis Dashboard)监控节点状态,支持在线添加 / 删除节点。
- 数据迁移:自动将槽从旧节点迁移到新节点,客户端无感知。
组件:
Codis Proxy:负责请求转发和协议转换。Codis Server:基于 Redis 改造的节点,支持动态槽管理。- 应用场景:传统架构迁移到分布式 Redis 的过渡方案。
3. 服务器端分片
路由原理 :
-
客户端计算键哈希值:CRC16(key) % 16384
-
连接任意节点
-
若数据不在该节点,返回 MOVED 重定向
-
客户端缓存槽位映射表
机制:
- 节点自管理:通过 Gossip 协议同步槽分配信息,节点间互相感知拓扑。
- 客户端重定向:当请求键所在槽不在当前节点时,返回
MOVED命令,指引客户端连接正确节点。核心命令:
CLUSTER ADDSLOTS <slot...>:分配槽到当前节点。CLUSTER MIGRATE <target-node> <key> 0 <timeout>:迁移数据到目标节点。
四、负载均衡的实现
客户端路由
Redis Cluster 中,客户端依据键名哈希值,通过 哈希槽(hash slot) 定位数据所属节点,将请求发往对应节点,实现负载均衡。哈希槽划分数据并映射到节点,客户端通过键哈希匹配槽对应的节点。
自动迁移
节点加入 / 离开集群时,系统自动重分配 哈希槽 以均衡数据:
- 节点加入:从其他节点迁移部分哈希槽到新节点;
- 节点离开 :将该节点的哈希槽分配给其他节点。
通过槽迁移,动态调整数据分布,保障负载均衡。
故障检测与恢复
- 检测:节点间互监健康状态,判定故障节点;
- 恢复:标记故障节点为下线,重分配其哈希槽;节点恢复后,重新加入集群并迁移数据,保证一致性。
五、故障的处理
1. 故障转移
(1)哨兵模式 vs. 集群模式
| 维度 | 哨兵模式 | 集群模式 |
|---|---|---|
| 触发者 | 哨兵节点 | 集群内节点(通过 Gossip 协议) |
| 选举算法 | Raft 协议 | Raft 协议(用于从节点选举) |
| 数据迁移 | 无(单分片) | 自动迁移槽(扩缩容时) |
(2)故障转移流程(以集群模式为例)
-
故障检测:
- 节点通过心跳包(PING/PONG)检测邻居状态,若主节点在
cluster-node-timeout内未响应,标记为 疑似下线(PFAIL)。 - 当半数以上主节点认为某主节点 PFAIL 时,标记为 已下线(FAIL),触发故障转移。
- 节点通过心跳包(PING/PONG)检测邻居状态,若主节点在
-
从节点选举:
- 主节点的从节点竞争成为新主,选举依据:
- 优先级(
slave-priority) :值越小优先级越高(默认100,设为0则不参与选举)。 - 复制偏移量:复制进度越新(偏移量越大),数据越完整,优先选举。
- 运行 ID:优先级和偏移量相同时,取较小的运行 ID(避免脑裂)。
- 优先级(
- 主节点的从节点竞争成为新主,选举依据:
-
角色切换:
- 选举胜出的从节点晋升为主节点,其他从节点改为复制新主。
- 集群更新槽分配信息,通知客户端新拓扑。
2. 多 slave 选举
- 配置多个从节点:提高故障转移成功率,避免单从节点故障导致主节点无法恢复。
- 权重选举 :通过
slave-priority为不同从节点设置优先级(如 SSD 节点优先级更高)。 - 延迟故障转移 :通过
min-slaves-to-write和min-slaves-max-lag配置,确保主节点至少有 N 个从节点复制延迟低于 M 秒时才允许故障转移,减少数据丢失。
六、Redis 群集部署
1. 部署基础环境
安装gcc
dnf -y install gcc
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 02. 安装 redis (每个节点都要安装)
bash
解压redis
tar zxvf redis-5.0.14.tar.gz
make
make PREFIX=/usr/local/redis install
做软链接
ln -s /usr/local/redis/bin* /usr/local/bin
启动
cd /redis/utils
./install_server.sh3. 修改配置文件
bash
vim /etc/redis/6379.conf
bind 0.0.0.0
appendonly yes
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
cluster-require-full-coverage no参数解释:
"appendonly yes" 表示开启 AOF(Append Only File)持久化模式,Redis 会将写操作追加到 AOF 文件中,用于数据恢复。
"cluster-enabled yes" 意思是启用 Redis 集群模式,使 Redis 支持分布式集群部署。
"cluster-config-file nodes-6379.conf" 指定了集群配置文件为 nodes-6379.conf ,用于存储集群节点的相关配置信息。
"cluster-node-timeout 15000" 设置了集群节点的超时时间为 15000 毫秒,若在该时间内未收到节点的响应,则判定该节点超时。
"cluster-require-full-coverage no" 表示不要求集群必须覆盖所有槽位,即使部分槽位未分配,集群仍可正常运行。
4. 重启服务并查看状态
bash
/etc/init.d/redis_6379 restart
netstat -anpt | grep 63795. 创建 redis 群集
bash
--创建集群(3主3从,自动分配主从)
101
redis-cli --cluster create --cluster-replicas 1 192.168.10.101:6379 192.168.10.102:6379 192.168.10.103:6379 192.168.10.104:6379 192.168.10.105:6379 192.168.10.106:6379redis-cli:Redis 命令行界面工具,用于与 Redis 服务器进行交互。--cluster create:表示要创建一个 Redis 集群。--cluster-replicas 1:指定每个主节点配备 1 个从节点,即设置集群的副本数量为 1。
6. 测试群集
bash
#以集群方式登录到
redis-cli -h 192.168.10.105 -p 6379 -c
set name zhangsan
redis-cli -h 192.168.10.103 -p 6379 -c
get centos7. 集群信息查看
bash
> cluster nodes8. 添加节点
bash
--添加节点(会成为master,但没有槽,数据不会写入到这里)
1.
redis-cli -c -p 6379 cluster meet 192.168.10.107 6379
2.
另一种方式添加(指定当前集群的任意一个节点,结果和上面一样)
redis-cli --cluster add-node 192.168.10.108:6379 192.168.10.107:63799. 修改新节点为其他节点的从节点
bash
redis-cli -h 192.168.10.108 -p 6379
> cluster replicate 107ID10. 重新分配槽位
bash
redis-cli --cluster rebalance --cluster-threshold 1 --cluster-use-empty-masters 192.168.10.101:6379命令核心参数解析
| 参数 | 作用 | 示例值 | 说明 |
|---|---|---|---|
--cluster rebalance |
启动集群自动负载均衡 | 必选 | 自动重新分配哈希槽,使各节点负载趋于平衡 |
--cluster-threshold |
触发均衡的最小不平衡度 | 1 | 当节点间槽数量差异 >=1 时触发迁移(默认值为 1) |
--cluster-use-empty-masters |
允许使用空主节点接收槽 | 无参数值 | 若集群中有新加入的空主节点,会优先分配槽给它们 |
192.168.10.101:6379 |
集群中任意节点的地址 | 集群内节点 IP: 端口 | 用于连接集群并获取拓 |
11. 删除节点
bash
清理节点
flushall
cluster reset
删除
redis-cli del-node 192.168.10.108:6379 108ID