文章目录
-
-
- [A 论文出处](#A 论文出处)
- [B 背景](#B 背景)
-
- [B.1 背景介绍](#B.1 背景介绍)
- [B.2 问题提出](#B.2 问题提出)
- [B.3 创新点](#B.3 创新点)
- [C 模型结构](#C 模型结构)
-
- [C.1 数据生成](#C.1 数据生成)
- [C.2 LLM训练](#C.2 LLM训练)
- [D 实验设计](#D 实验设计)
- [E 个人总结](#E 个人总结)
-
A 论文出处
- 论文题目:Disentangling Memory and Reasoning Ability in Large Language Models
- 发表情况:2025-ACL
B 背景
B.1 背景介绍
当前提升大语言模型(LLM)推理能力的研究方法主要可划分为两类:
(1)基于记忆增强 的方法。该方法聚焦于优化模型对外部世界知识的检索与利用机制 ,尤其针对未内化于模型参数的知识体系,例如检索增强生成(Retrieval-Augmented Generation, RAG),通过动态接入外部知识库强化信息召回能力。
(2)基于推理优化 的方法。该方法旨在改进模型自身的逻辑推演 过程,例如引入思维链 (Chain-of-Thought, CoT)技术引导多步推理,或在训练阶段植入结构化引导标记(如planning tokens)以提升推理路径的规划性。
尽管上述方法在特定场景下展现出性能增益,其仍存在显著局限:当面对需深度融合多源记忆与复杂逻辑链的综合性问题时(如跨领域知识关联、长程因果推断等),现有技术的效能仍显不足。这类任务要求模型协同调度记忆检索与知识推理能力,而当前方案尚未有效弥合两类机制间的协同鸿沟。
B.2 问题提出
尽管大语言模型(LLMs)在依赖外部知识与复杂推理的任务中展现出显著效能,现有推理框架存在根本性局限:这种框架并未实现知识检索(knowledge retrieval)与逻辑推演(logical reasoning)的模块化隔离。这种耦合架构导致两个关键缺陷:
(1)可追溯性缺失:无法明确辨识模型调用的具体知识源及其在推理路径中的效用机制;
(2)认知风险加剧:面对高复杂度问题时,未显式关联推理步骤与支撑知识,容易引发知识连续性中断(如关键信息遗漏)及事实性幻觉(factual hallucination)。
B.3 创新点
本文提出推理解耦 框架,将LLM推理解构为记忆-推理双阶段,对问答数据集所有应答句进行记忆/推理分类,并添加可学习的控制标记<memory>或<reason>。这种机制强制模型显式执行知识检索(记忆阶段)与逻辑推演(推理阶段),通过结构化引导规避混合处理导致的知识遗忘与幻觉风险。
C 模型结构
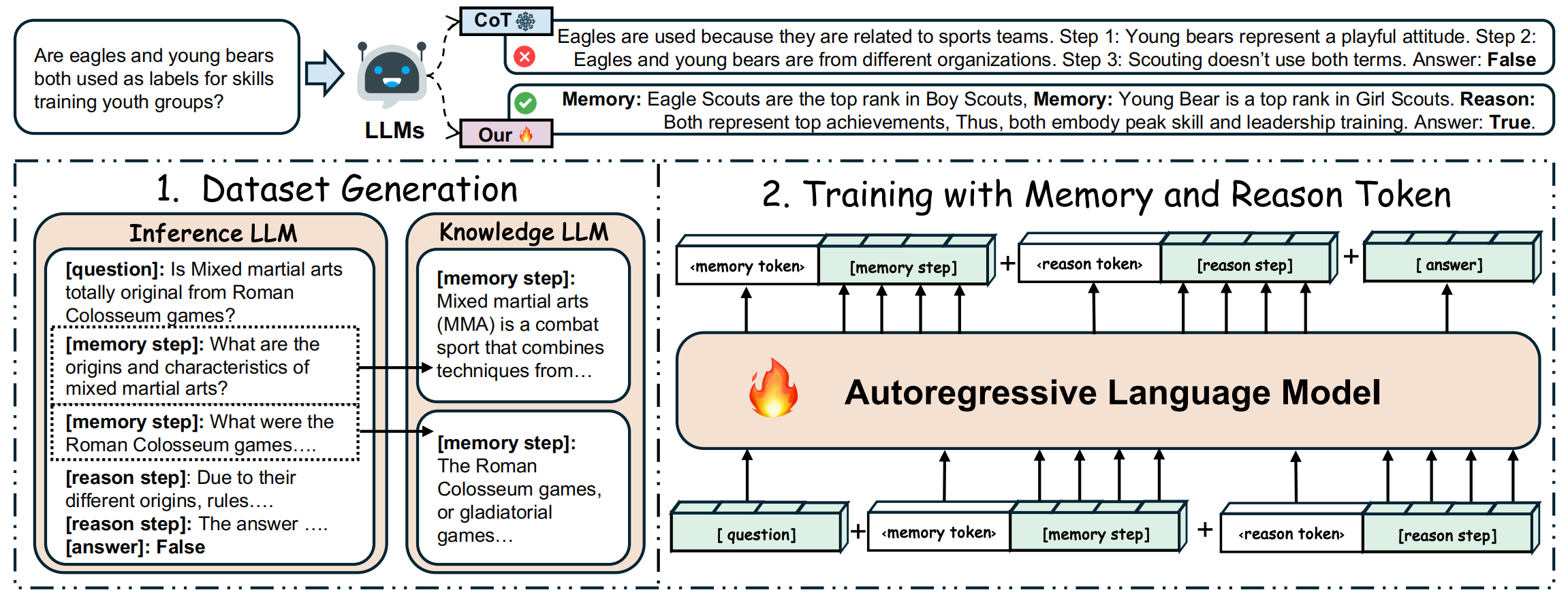
C.1 数据生成
针对所选 QA 基准数据集的训练集,首先使用 inference LLM (gpt4o) 生成 CoT 推理步骤,将那些需要事实信息的步骤前放置 rag 作为 memory 的标记,将那些需要推理的步骤前放置 reason 作为 reason 的标记,需要注意的是,prompt 中指定如果是 memory 部分,则输出能够用于检索的知识的 question 文本。然后使用 Knowledge LLM 回答上一步中的 question,并将其回答内容用于替换 question。
C.2 LLM训练
通过LoRA进行微调,每条数据 T 包含如下组成部分:
- 问题 。 Q = q 1 , q 2 , ⋯ , q n Q Q={q_1,q_2,⋯,q_{n_Q}} Q=q1,q2,⋯,qnQ,其中每个 q i q_i qi 表示问题的每个 token, n Q n_Q nQ 则是问题 prompt 中 token 的个数;
- 思考过程 。包含一系列 memory 和 reason 的过程,其中 memory 的形式为 { ⟨ m e m o r y ⟩ , k 1 , k 2 , ⋯ , k n K } \{⟨memory⟩,k_1,k_2,⋯,k_{n_K}\} {⟨memory⟩,k1,k2,⋯,knK} ,reason 的形式为 { ⟨ r e a s o n ⟩ , s 1 , s 2 , ⋯ , s n S } \{⟨reason⟩,s_1,s_2,⋯,s_{n_S}\} {⟨reason⟩,s1,s2,⋯,snS} ;
- 答案。对于 StrategyQA 则为 true 或者 false,commonsenseQA 以及 truthfulQA 则为单项选择题。
D 实验设计
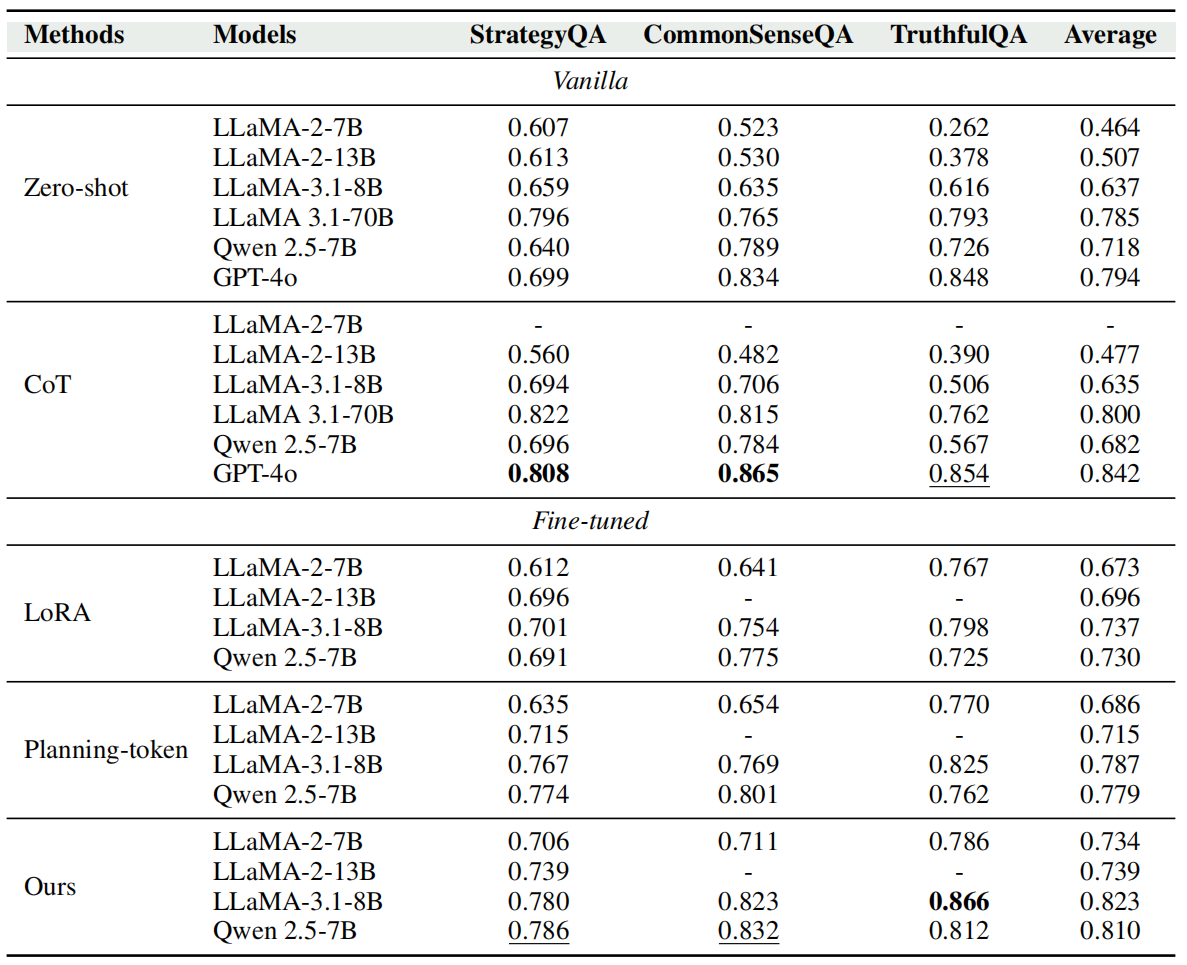
(1)使用相同的数据,分别通过Zero-shot、CoT、LoRA、Planning-token和本文的方法对大模型进行训练,实验对比如下。
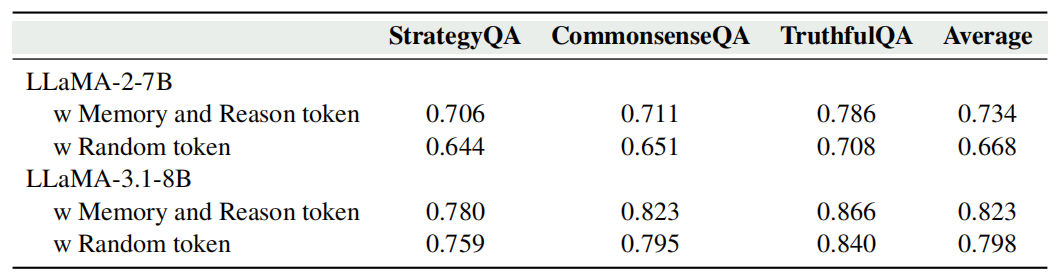
(2)消融实验,本文提出的memory和reason标记的有效性
E 个人总结
(1)本文通过强制模型分阶段执行知识检索(<memory>)与逻辑推演(<reason>),显著降低记忆偏差对推理链的干扰。同时标记化机制使知识调用路径透明化,支持溯源分析;
(2)但当前单轮QA的验证框架尚未证明其在多轮对话中维持知识连贯性的能力,跨轮次知识调度机制需进一步探索。