一、引言
你是否曾遇到过这样的情况:看到一段有用的文本,想要快速复制下来,却只能眼巴巴地盯着屏幕,手动输入?
其实,Java 也可以轻松实现 OCR(光学字符识别)功能,让你轻松识别并提取图片中的文字信息。不需要庞大的外部工具,也不必担心复杂的配置,只需几行代码,Java 就能帮你搞定 OCR!
接下来,我们将带你一步步揭开这项技术的神秘面纱,让你的 Java 项目更加智能、便捷。
二、功能演示
先让我们看看最终效果,再进行实现
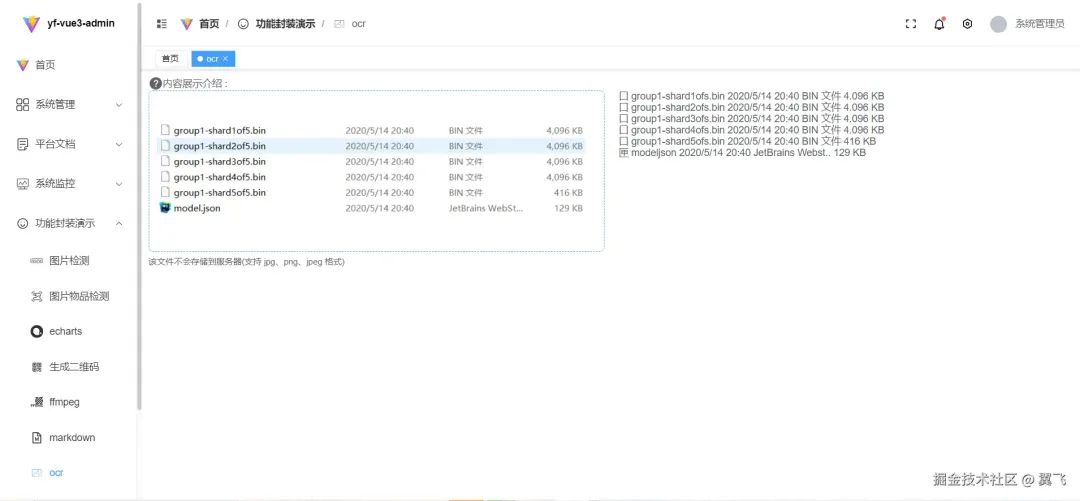
三、功能实现
1. 描述
在这部分,我们将使用 SpringBoot 和 Tess4j 来实现 OCR 功能。Tess4j 是一个基于 Tesseract 的 Java 封装库,它让我们能够轻松地在 Java 应用中使用 OCR 技术。
无论你是在处理扫描的文档、识别图片中的文字,还是自动化读取截图内容,Tess4j 都能派上用场。通过与 SpringBoot 结合,我们可以快速搭建一个轻量级的 RESTful 服务,轻松应对各种 OCR 需求。
2. 编码实现
2.1 引入依赖
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
</dependency>2.2 初始化Tesseract引擎
项目部署:
-
使用
new ClassPathResource("tess_data").getFile().getAbsolutePath()可能在项目打成 Jar 包后无法正常访问。为了解决这个问题,可以参考一些开源项目中的TensorflowUtil工具类,将resource文件进行转存后再加载。 -
在 Linux 环境中,还需要解决 无法初始化
net.sourceforge.tess4j.TessAPI的问题,确保所有必要的依赖库和系统配置正确。
训练数据:
-
不同的训练数据和配置会影响识别结果的精度和速度。可以根据实际需求自行训练适合的数据集。
-
免费的训练数据包括:
-
tessdata_best: 主要针对高精度要求的应用场景,虽然识别速度较慢,但结果更准确。 -
tessdata: 是标准的训练数据集,平衡了识别速度和精度,适合一般的 OCR 应用。 -
tessdata_fast: 适用于需要快速识别的场景,虽然精度略低,但可以显著提升识别速度。/**
-
TesseractOcr 模型加载
-
@author : YiFei
*/
@Slf4j
@Getter
@Component
publicclass TesseractOcrModelService {privatefinal Tesseract tesseract = new Tesseract();
public TesseractOcrModelService() {
try {
// 获取训练模型文件夹 (该方法在打包为jar后会有问题,建议使用项目中TensorflowUtil工具类)
String folderPath = new ClassPathResource("tess_data").getFile().getAbsolutePath();
/*
* OEM_TESSERACT_ONLY = 0:表示仅运行Tesseract OCR引擎,不使用LSTM(Long Short-Term Memory)线识别器。Tesseract是一种传统的OCR引擎,适用于一般的文字识别任务。
* OEM_LSTM_ONLY = 1:表示仅运行LSTM线识别器,不使用Tesseract。LSTM是一种深度学习模型,通常在处理复杂文本或手写文字识别等任务时表现较好。
* OEM_TESSERACT_LSTM_COMBINED = 2:表示同时运行Tesseract和LSTM识别器,并在遇到困难情况时允许回退到Tesseract。这种组合模式可以在不同情况下灵活地选择最适合的识别引擎。
* OEM_DEFAULT = 3:当调用 init_*() 方法时指定此模式,表示可以根据语言特定配置、命令行配置等自动推断使用哪种模式。如果没有明确指定,则默认使用 OEM_TESSERACT_ONLY 模式。
/
tesseract.setPageSegMode(OEM_TESSERACT_LSTM_COMBINED);
// 设置Tesseract OCR引擎的训练数据文件夹路径
/
* chi_sim.traineddata: Chinese Simplified(中文简体)
* chi_sim_vert.traineddata: Chinese Simplified Vertical(中文简体竖排)
* chi_tra.traineddata: Chinese Traditional(中文繁体)
* chi_tra_vert.traineddata: Chinese Traditional Vertical(中文繁体竖排)
*/
tesseract.setDatapath(folderPath);
tesseract.setPageSegMode(6);
// 设置为中文简体
tesseract.setLanguage("chi_sim");
} catch (Exception e) {
thrownew RuntimeException(e);
}
}
}
-
-
2.3 编写 RESTful 接口
/**
* Ocr-控制器
*
* @author : YiFei
*/
@RestController
@RequestMapping("ocr")
@RequiredArgsConstructor
publicclass OcrController {
privatefinal TesseractOcrModelService tesseractOcrModelService;
@PostMapping("/detection")
public Result<String> ocrDetection(MultipartFile file) {
try {
/*
图片调整推荐 :
二值化:将图像转换为黑白,有助于提高对比度。
去噪:去除图像中的噪声。
旋转矫正:确保图像中的文本是水平的。
*/
Tesseract tesseract = tesseractOcrModelService.getTesseract();
return Result.success(tesseract.doOCR(ImageIO.read(file.getInputStream())));
} catch (Exception e) {
thrownew RuntimeException("ImageIO.read(file.getInputStream())) 解析错误");
}
}
}四、源码
注意事项 :
-
平台一人一号,账号可以通过邮箱、第三方平台自动注册。用户名密码方式登录请联系管理员手动添加、手机号不可用。(敏感数据以做信息脱敏)
-
在线聊天功能(消息已做脏词过滤,群发、系统、AI消息不会被平台记录)
五、结束语
Tess4j 在识别身份证号、手机号和英文单词方面表现不错,但在使用免费训练数据时,识别中文的效果相对较差。如果您对识别质量有更高的要求,可以考虑以下几种方案:
-
专项训练: 通过自定义数据集进行专项训练,提升对特定文本类型或语言的识别精度。
-
调用第三方 API: 利用专业的 OCR 服务提供商,如
Google Cloud Vision、Microsoft Azure OCR或Amazon Textract,这些平台通常能提供更高的识别准确性和更多的功能。
此外,Tess4j 也可以应用于其他场景:
-
文档数字化: 将纸质文档转换为可编辑的电子文本。
-
自动数据录入: 自动从扫描的表格、账单等文件中提取数据。
-
车牌识别: 从交通摄像头捕捉的图像中自动识别车牌号码。
-
手写识别: 将手写内容转换为数字文本。
尽管这些方法可能需要额外的成本和设置,但它们能显著提升识别效果,帮助您满足更高的需求。