Cilium动手实验室: 精通之旅---19.Golden Signals with Hubble and Grafana
- [1. Lab 环境](#1. Lab 环境)
- [2. 部署测试应用](#2. 部署测试应用)
-
- [2.1 7层可见性的网络](#2.1 7层可见性的网络)
-
- [2.1.1 允许所有命名空间](#2.1.1 允许所有命名空间)
- [2.1.2 DNS 可见性](#2.1.2 DNS 可见性)
- [2.1.3 L7-egress-visibility](#2.1.3 L7-egress-visibility)
- [2.2 检查 Deployments](#2.2 检查 Deployments)
- [2.3 在 Hubble UI 中查看](#2.3 在 Hubble UI 中查看)
- [3. Grafana 选项卡](#3. Grafana 选项卡)
-
- [3.1 Grafana 中的 Hubble L7 HTTP 指标](#3.1 Grafana 中的 Hubble L7 HTTP 指标)
- [3.2 L7 Hubble 仪表板](#3.2 L7 Hubble 仪表板)
- [4. 吞吐量](#4. 吞吐量)
-
- [4.1 提高请求速率](#4.1 提高请求速率)
- [5. 增加错误率](#5. 增加错误率)
- [6. 延迟](#6. 延迟)
-
- [6.1 增加请求持续时间](#6.1 增加请求持续时间)
- [7. 跟踪集成](#7. 跟踪集成)
-
- [7.1 介绍](#7.1 介绍)
- [7.2 Grafana 中的痕迹](#7.2 Grafana 中的痕迹)
- [7.3 访问 Tempo](#7.3 访问 Tempo)
- [8. 最终实验](#8. 最终实验)
-
- [8.1 题目](#8.1 题目)
- [8.2 解题](#8.2 解题)
-
- [8.2.1 图形化界面确认问题](#8.2.1 图形化界面确认问题)
- [8.2.2 命令行下确认问题](#8.2.2 命令行下确认问题)
1. Lab 环境
LAB访问地址
url
https://isovalent.com/labs/hubble-grafana-golden-signals/在本实验中,我们部署了:
- 启用 Hubble 和度量标准的 Cilium 1.17.1
- Kube Prometheus Stack Helm 图表(包括 Prometheus 和 Grafana)
特别是,使用了以下 Cilium Helm 参数(完整的值文件位于 /tmp/helm/cilium-values.yaml):
yaml
root@server:~# yq /tmp/helm/cilium-values.yaml
kubeProxyReplacement: true
k8sServiceHost: kind-control-plane
k8sServicePort: 6443
operator:
# only 1 replica needed on a single node setup
replicas: 1
prometheus:
enabled: true
serviceMonitor:
enabled: true
hubble:
relay:
# enable relay in 02
# enabled: true
service:
type: NodePort
prometheus:
enabled: true
serviceMonitor:
enabled: true
metrics:
serviceMonitor:
enabled: true
enableOpenMetrics: true
enabled:
- dns
- drop
- tcp
- icmp
- "flow:sourceContext=workload-name|reserved-identity;destinationContext=workload-name|reserved-identity"
- "kafka:labelsContext=source_namespace,source_workload,destination_namespace,destination_workload,traffic_direction;sourceContext=workload-name|reserved-identity;destinationContext=workload-name|reserved-identity"
- "httpV2:exemplars=true;labelsContext=source_ip,source_namespace,source_workload,destination_ip,destination_namespace,destination_workload,traffic_direction;sourceContext=workload-name|reserved-identity;destinationContext=workload-name|reserved-identity"
dashboards:
enabled: true
namespace: monitoring
annotations:
grafana_folder: "Hubble"
ui:
# enable UI in 02
# enabled: true
service:
type: NodePort
prometheus:
enabled: true
serviceMonitor:
enabled: true在本实验中,我们将使用 Cilium 的 Hubble 子系统生成的 Prometheus 指标来监控 HTTP 黄金信号。
具体而言,我们使用以下命令启用了 httpv2 Hubble 指标:
bash
httpV2:exemplars=true;labelsContext=source_ip,source_namespace,source_workload,destination_ip,destination_namespace,destination_workload,traffic_direction;sourceContext=workload-name|reserved-identity;destinationContext=workload-name|reserved-identity这是一条相当长的队伍。让我们拆分选项以了解它们的作用:
examplars=true将允许我们将应用程序跟踪中的 OpenTelemetry 跟踪点显示为 Grafana 图形上的叠加层labelsContext设置为向指标添加额外的标签,包括源/目标 IP、源/目标命名空间、源/目标工作负载以及流量方向(入口或出口)sourceContext设置源标签的构建方式,在这种情况下,尽可能使用工作负载名称,否则使用保留身份(例如world)destinationContext对目标执行相同的作
检查 Cilium 是否已正确安装并准备就绪
bash
root@server:~# cilium status --wait
/¯¯\
/¯¯\__/¯¯\ Cilium: OK
\__/¯¯\__/ Operator: OK
/¯¯\__/¯¯\ Envoy DaemonSet: OK
\__/¯¯\__/ Hubble Relay: disabled
\__/ ClusterMesh: disabled
DaemonSet cilium Desired: 3, Ready: 3/3, Available: 3/3
DaemonSet cilium-envoy Desired: 3, Ready: 3/3, Available: 3/3
Deployment cilium-operator Desired: 1, Ready: 1/1, Available: 1/1
Containers: cilium Running: 3
cilium-envoy Running: 3
cilium-operator Running: 1
clustermesh-apiserver
hubble-relay
Cluster Pods: 8/8 managed by Cilium
Helm chart version: 1.17.1
Image versions cilium quay.io/cilium/cilium:v1.17.1@sha256:8969bfd9c87cbea91e40665f8ebe327268c99d844ca26d7d12165de07f702866: 3
cilium-envoy quay.io/cilium/cilium-envoy:v1.31.5-1739264036-958bef243c6c66fcfd73ca319f2eb49fff1eb2ae@sha256:fc708bd36973d306412b2e50c924cd8333de67e0167802c9b48506f9d772f521: 3
cilium-operator quay.io/cilium/operator-generic:v1.17.1@sha256:628becaeb3e4742a1c36c4897721092375891b58bae2bfcae48bbf4420aaee97: 12. 部署测试应用
我们在后台部署了 jobs-app demo 工作负载应用程序,以生成将要分析的 HTTP 流量。
2.1 7层可见性的网络
jobs-app 应用程序附带一组 Cilium 网络策略资源,这些资源使用 Cilium 的 Envoy 代理实现第 7 层可见性。
List them with: 列出它们:
bash
root@server:~# kubectl -n tenant-jobs get cnp
NAME AGE VALID
allow-all-within-namespace 3m30s True
dns-visibility 3m30s False
l7-egress-visibility 3m30s True
l7-ingress-visibility 3m30s True2.1.1 允许所有命名空间
使用以下命令检查策略:
bash
root@server:~# kubectl -n tenant-jobs get cnp allow-all-within-namespace -o yaml
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
annotations:
meta.helm.sh/release-name: jobs-app
meta.helm.sh/release-namespace: tenant-jobs
creationTimestamp: "2025-06-03T09:02:53Z"
generation: 1
labels:
app.kubernetes.io/managed-by: Helm
name: allow-all-within-namespace
namespace: tenant-jobs
resourceVersion: "4789"
uid: 9de56664-8f96-4eb2-a842-09f215f7685f
spec:
description: Allow all within namespace
egress:
- toEndpoints:
- {}
endpointSelector: {}
ingress:
- fromEndpoints:
- {}
status:
conditions:
- lastTransitionTime: "2025-06-03T09:02:53Z"
message: Policy validation succeeded
status: "True"
type: Valid此策略可确保默认情况下允许所有流量。虽然从安全角度来看,这不是最佳实践,但它使本练习的设置更加容易。查看 Zero Trust Visibility 实验室,了解有关保护命名空间的最佳方法的更多信息。
2.1.2 DNS 可见性
使用以下命令检查策略:
bash
root@server:~# kubectl -n tenant-jobs get cnp dns-visibility -o yaml
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
annotations:
meta.helm.sh/release-name: jobs-app
meta.helm.sh/release-namespace: tenant-jobs
creationTimestamp: "2025-06-03T09:02:53Z"
generation: 1
labels:
app.kubernetes.io/managed-by: Helm
name: dns-visibility
namespace: tenant-jobs
resourceVersion: "4819"
uid: c2739fed-3c39-451d-85bc-a2481eef3446
spec:
egress:
- toEndpoints:
- matchLabels:
k8s:io.kubernetes.pod.namespace: kube-system
k8s:k8s-app: kube-dns
toPorts:
- ports:
- port: "53"
protocol: ANY
rules:
dns:
- matchPattern: '*'
- toFQDNs:
- matchPattern: '*'
- toEntities:
- all
endpointSelector:
matchLabels: {}
status:
conditions:
- lastTransitionTime: "2025-06-03T09:02:53Z"
message: FQDN regex compilation LRU not yet initialized
status: "False"
type: Valid此策略允许命名空间中的 Pod 访问 Kube DNS 服务。它还添加了一个 DNS 规则,用于通过 Cilium 的 DNS 代理获取 DNS 流量,这使得解析 Hubble 流中的 DNS 名称成为可能。
2.1.3 L7-egress-visibility
使用以下命令检查策略:
bash
root@server:~# kubectl -n tenant-jobs get cnp l7-ingress-visibility -o yaml
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
annotations:
meta.helm.sh/release-name: jobs-app
meta.helm.sh/release-namespace: tenant-jobs
creationTimestamp: "2025-06-03T09:02:53Z"
generation: 1
labels:
app.kubernetes.io/managed-by: Helm
name: l7-ingress-visibility
namespace: tenant-jobs
resourceVersion: "4829"
uid: 0a049efb-6bd8-475f-a607-adbfebaccc5f
spec:
description: L7 policy
endpointSelector: {}
ingress:
- toPorts:
- ports:
- port: "9080"
protocol: TCP
- port: "50051"
protocol: TCP
- port: "9200"
protocol: TCP
rules:
http:
- {}
status:
conditions:
- lastTransitionTime: "2025-06-03T09:02:53Z"
message: Policy validation succeeded
status: "True"
type: Valid最后一个策略允许从命名空间中的所有 Pod 到 TCP 中的端口 9080、50051 和 9200 的入口流量。它强制这些流量通过 Cilium 的 Envoy 代理来实现第 7 层可见性。
2.2 检查 Deployments
让我们等到一切准备就绪。这可能需要几分钟时间才能部署所有组件:
bash
kubectl rollout -n tenant-jobs status deployment/coreapi
kubectl rollout -n tenant-jobs status deployment/crawler
kubectl rollout -n tenant-jobs status deployment/jobposting
kubectl rollout -n tenant-jobs status deployment/loader
kubectl rollout -n tenant-jobs status deployment/recruiter
kubectl rollout -n tenant-jobs status deployment/resumes2.3 在 Hubble UI 中查看
检查 Hubble UI 是否已正确部署:
bash
root@server:~# cilium status --wait
/¯¯\
/¯¯\__/¯¯\ Cilium: OK
\__/¯¯\__/ Operator: OK
/¯¯\__/¯¯\ Envoy DaemonSet: OK
\__/¯¯\__/ Hubble Relay: OK
\__/ ClusterMesh: disabled
DaemonSet cilium Desired: 3, Ready: 3/3, Available: 3/3
DaemonSet cilium-envoy Desired: 3, Ready: 3/3, Available: 3/3
Deployment cilium-operator Desired: 1, Ready: 1/1, Available: 1/1
Deployment hubble-relay Desired: 1, Ready: 1/1, Available: 1/1
Deployment hubble-ui Desired: 1, Ready: 1/1, Available: 1/1
Containers: cilium Running: 3
cilium-envoy Running: 3
cilium-operator Running: 1
clustermesh-apiserver
hubble-relay Running: 1
hubble-ui Running: 1
Cluster Pods: 21/21 managed by Cilium
Helm chart version: 1.17.1
Image versions cilium quay.io/cilium/cilium:v1.17.1@sha256:8969bfd9c87cbea91e40665f8ebe327268c99d844ca26d7d12165de07f702866: 3
cilium-envoy quay.io/cilium/cilium-envoy:v1.31.5-1739264036-958bef243c6c66fcfd73ca319f2eb49fff1eb2ae@sha256:fc708bd36973d306412b2e50c924cd8333de67e0167802c9b48506f9d772f521: 3
cilium-operator quay.io/cilium/operator-generic:v1.17.1@sha256:628becaeb3e4742a1c36c4897721092375891b58bae2bfcae48bbf4420aaee97: 1
hubble-relay quay.io/cilium/hubble-relay:v1.17.1@sha256:397e8fbb188157f744390a7b272a1dec31234e605bcbe22d8919a166d202a3dc: 1
hubble-ui quay.io/cilium/hubble-ui-backend:v0.13.1@sha256:0e0eed917653441fded4e7cdb096b7be6a3bddded5a2dd10812a27b1fc6ed95b: 1
hubble-ui quay.io/cilium/hubble-ui:v0.13.1@sha256:e2e9313eb7caf64b0061d9da0efbdad59c6c461f6ca1752768942bfeda0796c6: 1选择 tenant-jobs 命名空间以可视化应用程序组件以及它们如何相互通信。
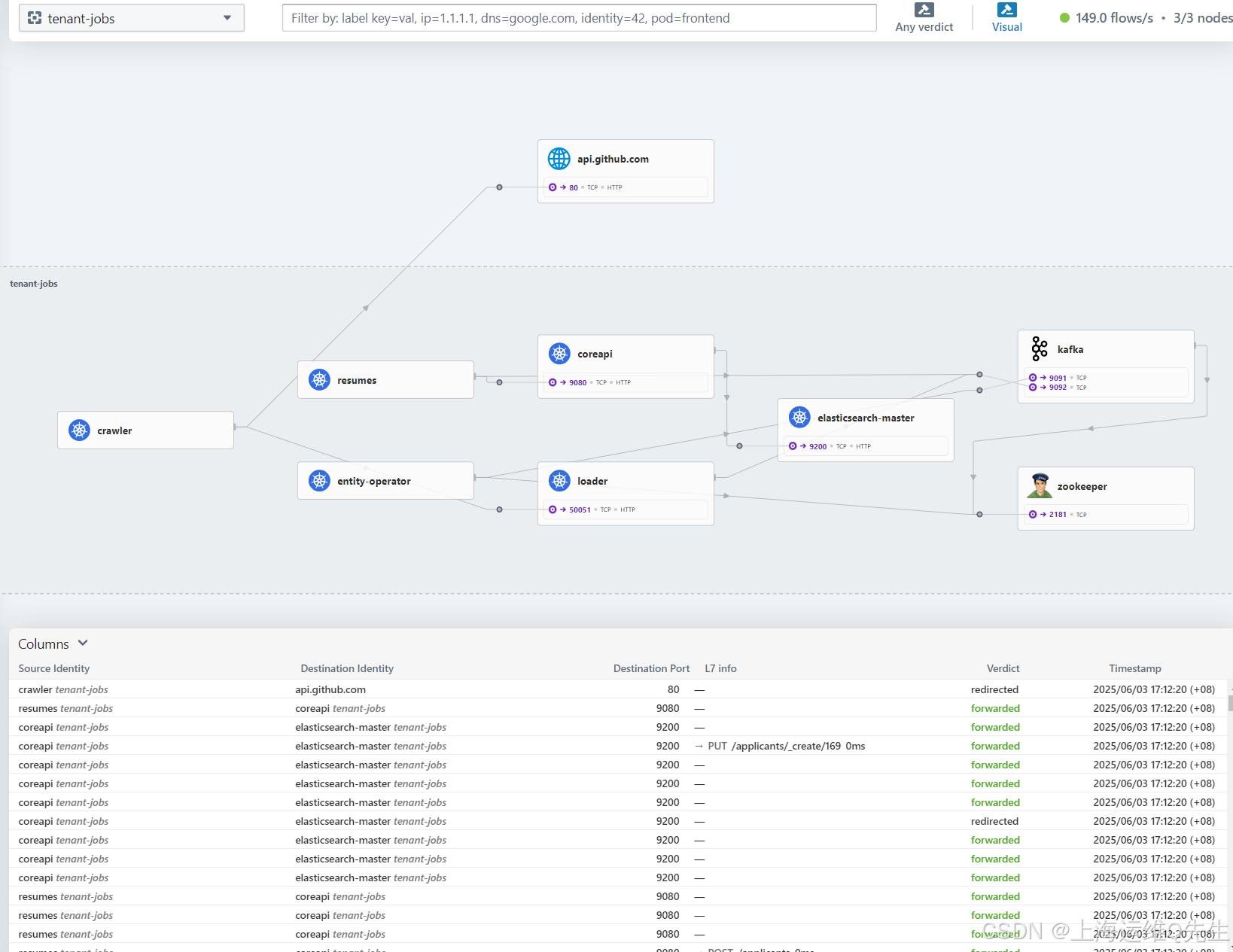
组件在相互通信时出现,因为 Hubble 显示服务之间的实时流。
请注意,某些块(例如 zookeeper)具有端口号,后跟 TCP,而其他块则具有额外的 HTTP 标签。这是因为该流量通过 Cilium 的 Envoy Proxy 进行重定向,用于第 7 层解析,从而提供应用层可观察性。
例如,单击 coreapi 块。您将看到使用 HTTP 协议从 resumes 组件到端口 9080/TCP 的通信。该块实际上显示 /applications 路径上的 resumes 应用程序正在使用 POST 方法访问该服务:
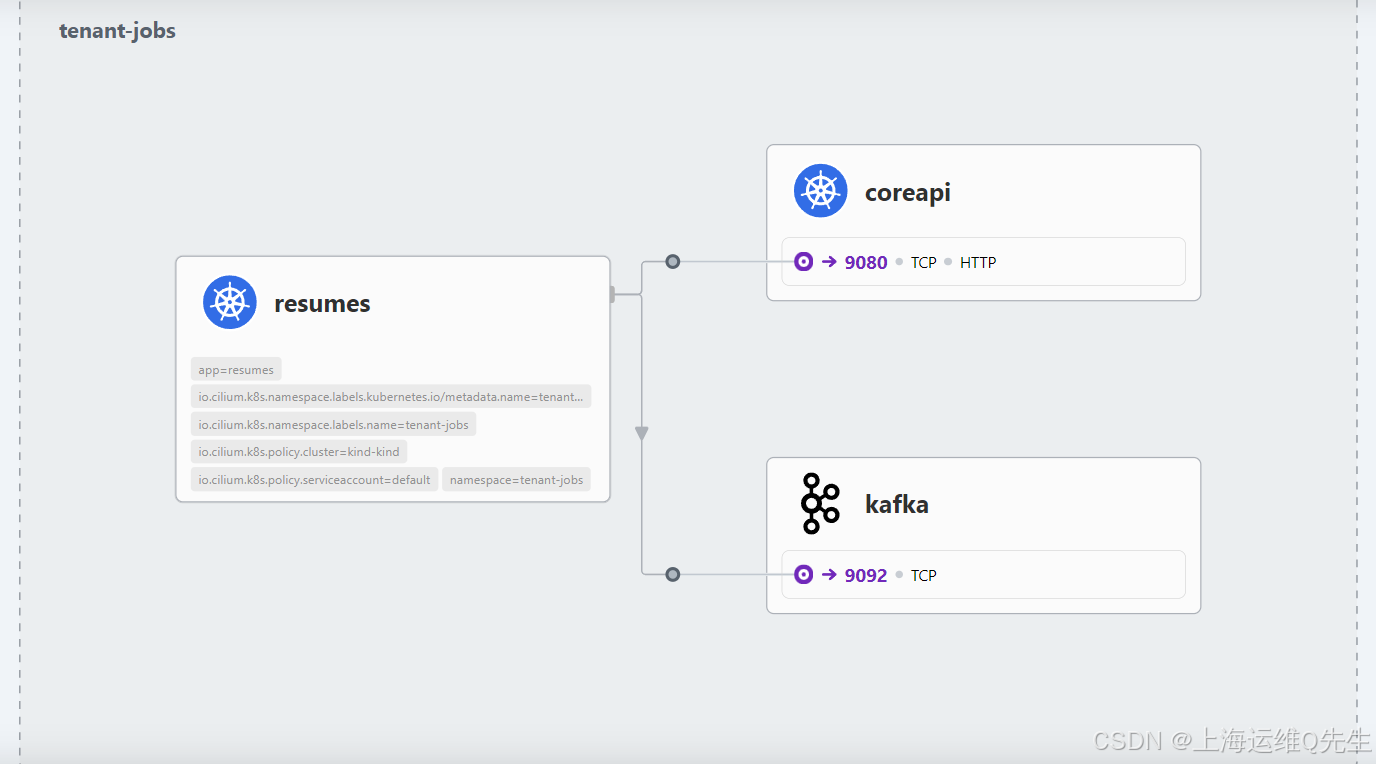
我们之前描述的 l7-ingress-visibility Cilium 网络策略强制通过 Envoy 代理在端口 9080/TCP 上传输入口流量,从而允许 Hubble 提供这些额外的数据。
3. Grafana 选项卡
3.1 Grafana 中的 Hubble L7 HTTP 指标
在本实验中,我们设置了一个 Grafana 服务器,其数据源指向 Prometheus,并导入了 L7 HTTP 指标控制面板以可视化 Hubble 相关指标。
控制面板中的所有内容都使用 Hubble HTTP 指标,应用程序不需要任何插桩,也不需要向应用程序注入任何内容。
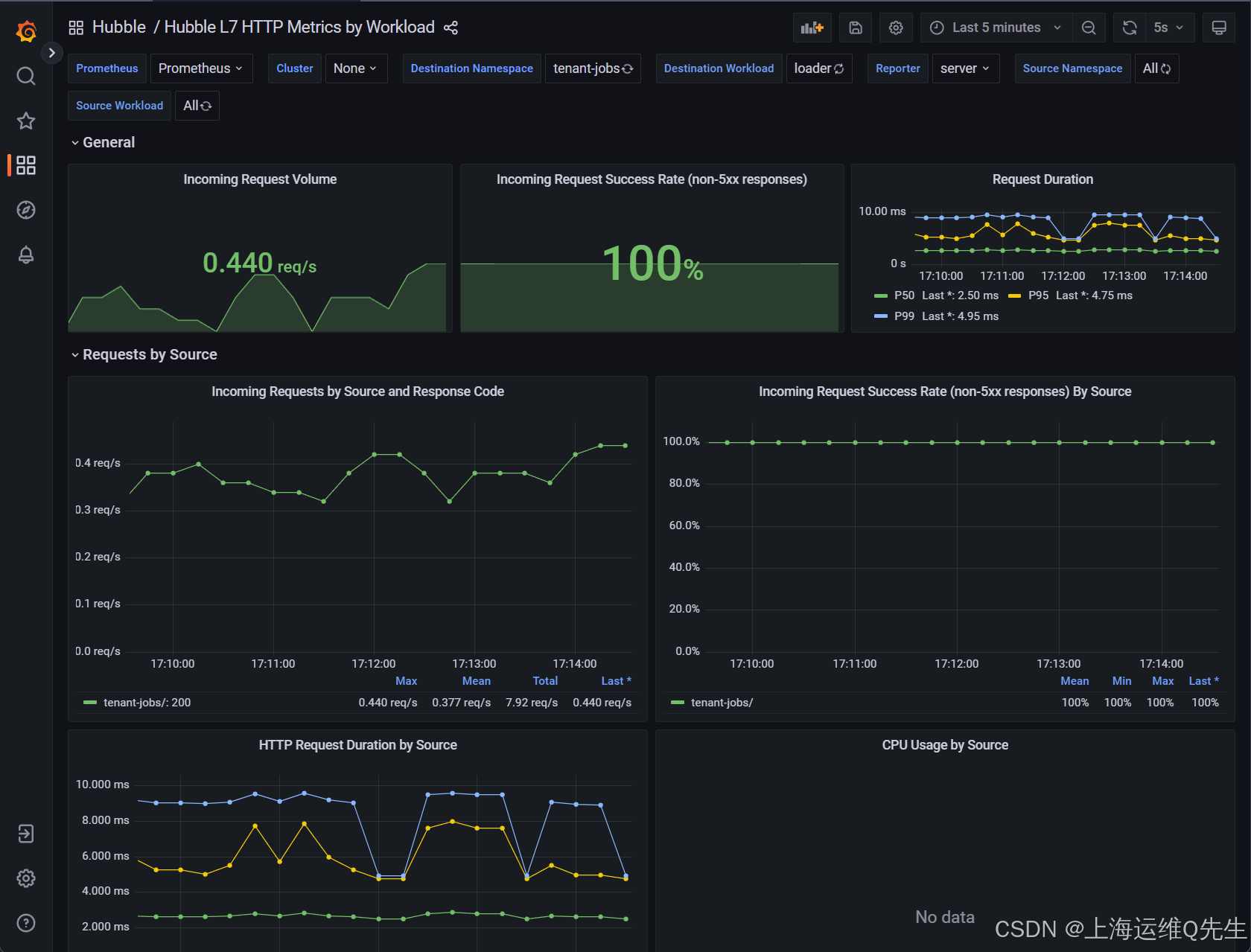
Incoming Requests by Source and Response Code 图表应在 0.3 到 0.4 req/s 之间变化。
3.2 L7 Hubble 仪表板
导航仪表板。
请注意您现在如何访问各种 HTTP 指标:
- Incoming Request Volume
- Incoming Request Success Rate
- Request Duration
- Requests by Response Code
请注意如何按源查看指标(第二部分, 按来源划分的请求 ,带有三个面板)或按目标(第三部分, 按目标划分的请求 ,具有三个面板)。这将使您能够找到异常所在的位置。
在 Requests by Source 部分中,检查 HTTP Request Duration by Source。请注意,有几个可用的统计数据:P50、P95 和 P99。我们通常用第 99 个百分位或 P99 来描述延迟。
如果我们基于 HTTP 的 Web 应用程序的 P99 延迟小于或等于 2 毫秒,则意味着 99% 的 Web 调用的响应时间低于 2 毫秒。相反,只有 1% 的调用获得超过 2 毫秒的延迟响应。
4. 吞吐量
4.1 提高请求速率
找到页面顶部的 Destination Workload 变量,并确保已选择 loader。
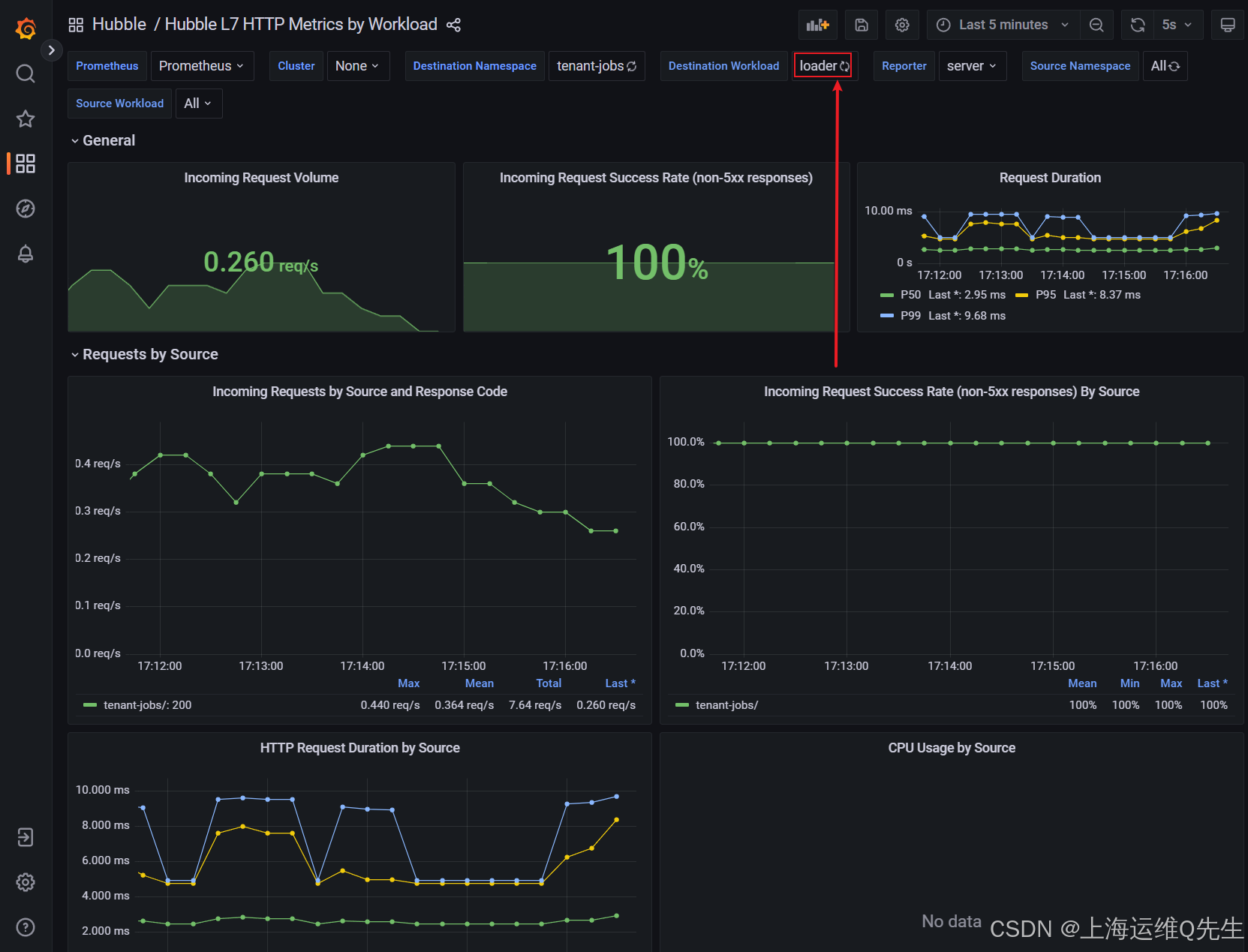
接下来,通过配置crawler以生成更多简历,并运行crawler和resumes的更多副本来增加请求量 部署。
运行:
bash
helm upgrade jobs-app ./helm/jobs-app.tgz \
--namespace tenant-jobs \
--reuse-values \
--set crawler.replicas=3 \
--set crawler.crawlFrequencyLowerBound=0.2 \
--set crawler.crawlFrequencyUpperBound=0.5 \
--set resumes.replicas=2观察 Incoming Requests by Source and Response Code 面板。当爬网程序向加载程序提交简历时,您应该会看到请求速率增加,因为爬网程序的简历生成速率增加。速率应稳定在 3 req/s 左右。
现在,选择 coreapi 作为页面顶部的 Destination Workload 变量。
在 Incoming Requests by Source and Response Code 视图中,您还应该看到 coreapi 的请求速率增加。速率应稳定在 6 req/s 左右。
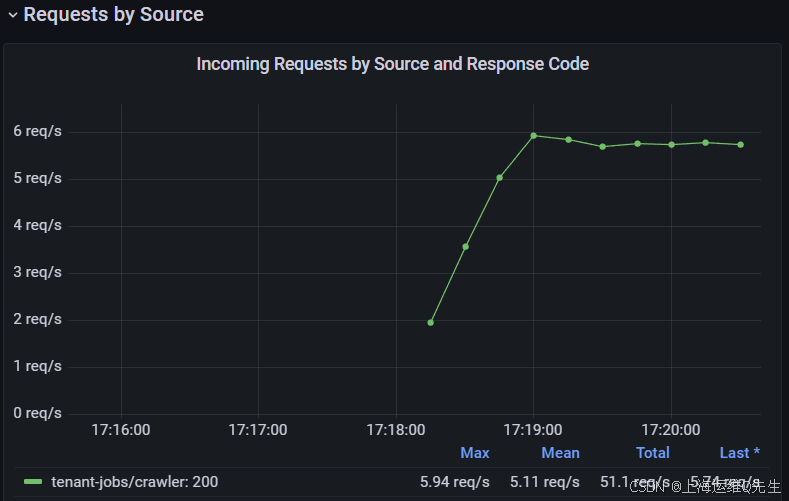
5. 增加错误率
让我们部署一个新的 jobs-app 配置,并使用我们的指标来查看请求错误率的变化。
bash
helm upgrade jobs-app ./helm/jobs-app.tgz \
--namespace tenant-jobs \
--reuse-values \
--set coreapi.errorRate=0.5 \
--set coreapi.sleepRate=0.01确保选择 coreapi 作为 Destination Workload。
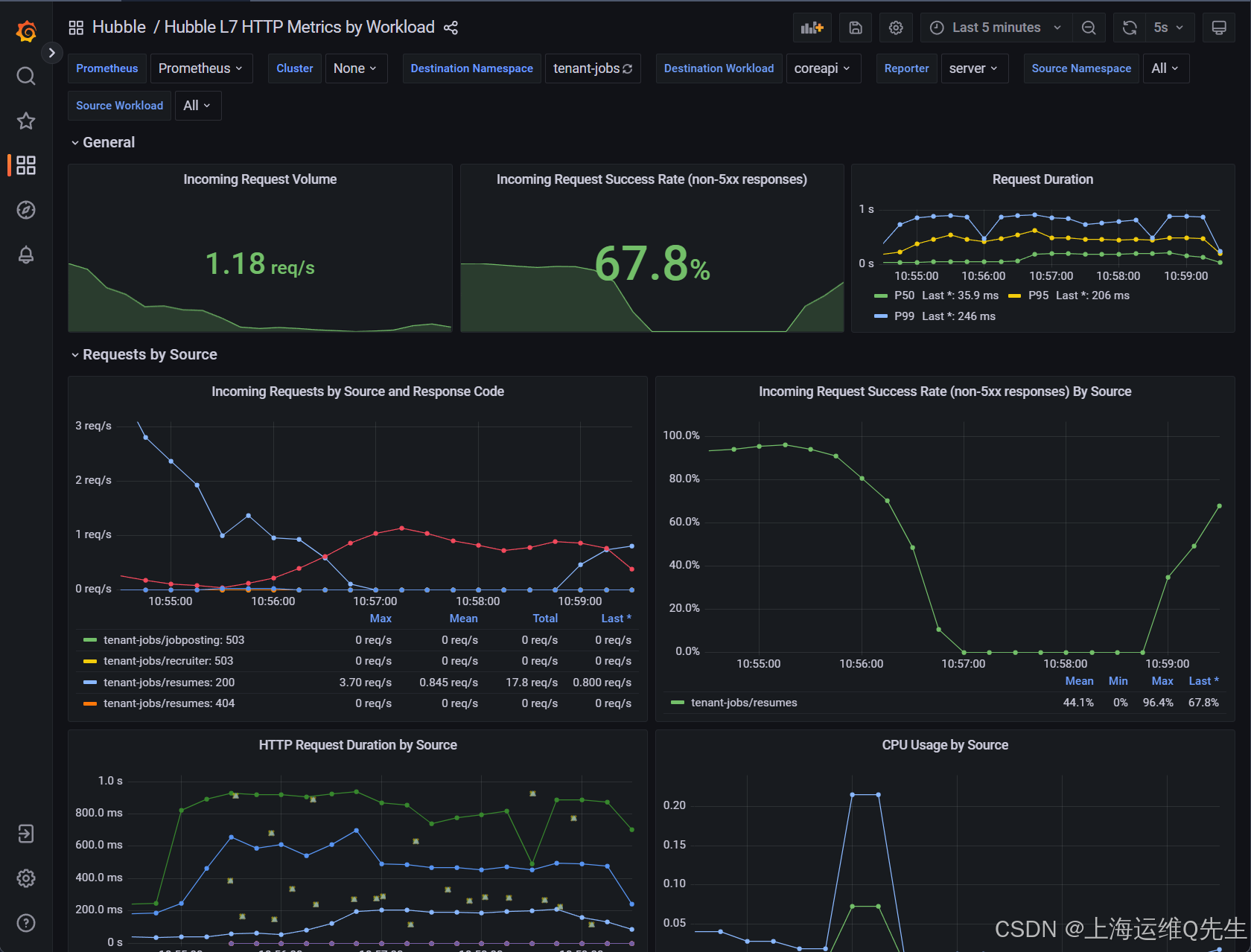
大约一分钟后,您将看到 Incoming Request Success Rate (non-5xx responses) By Source (按源) 图表开始下降。
最后,Incoming Request Success Rate (non-5xx responses) 面板应稳定在 93% 左右。
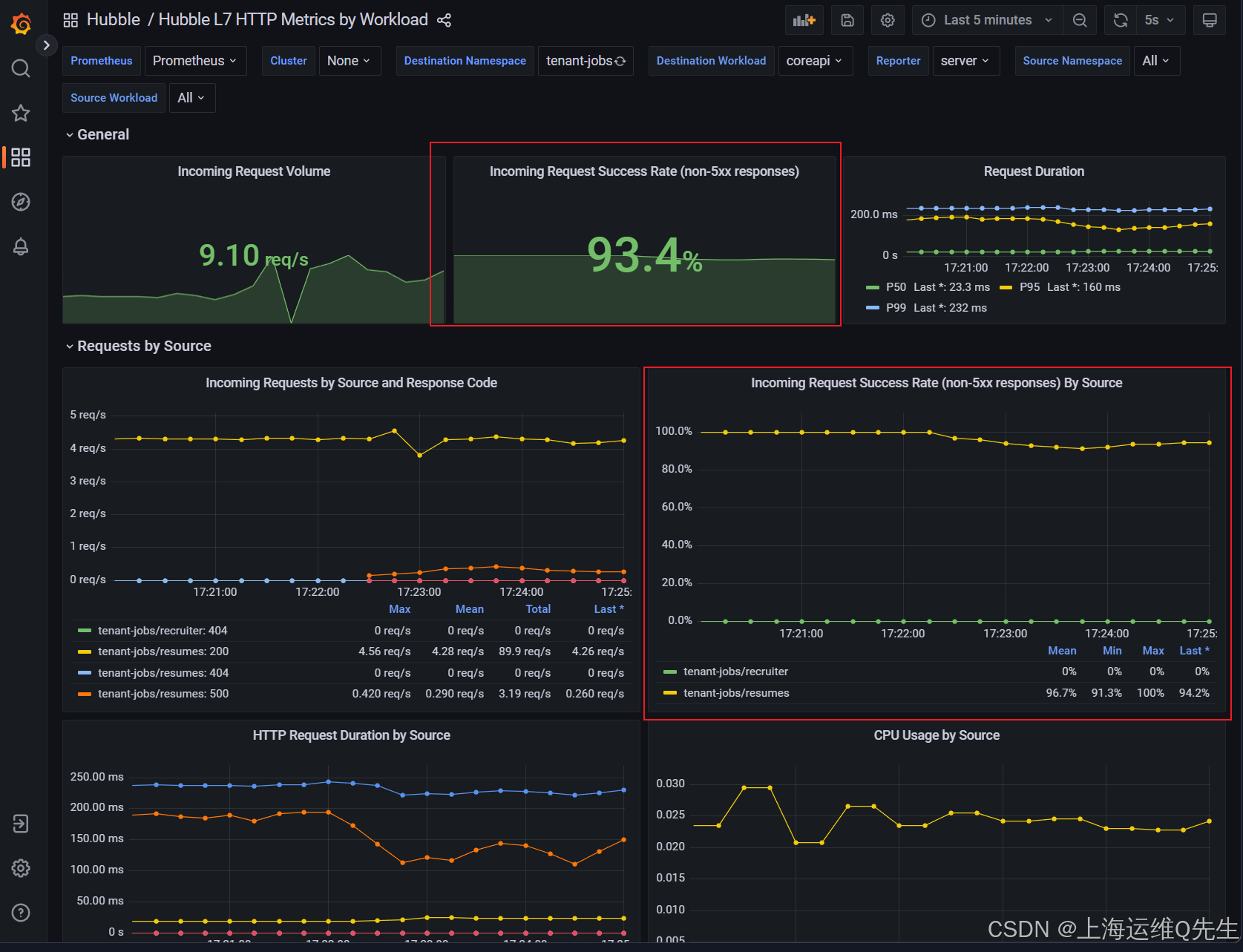
6. 延迟
6.1 增加请求持续时间
接下来,我们将升级 jobs-app 设置以增加响应之间的睡眠时间,从而延长请求持续时间。
运行:
bash
helm upgrade jobs-app ./helm/jobs-app.tgz \
--namespace tenant-jobs \
--reuse-values \
--set coreapi.sleepRate=0.2 \
--set coreapi.sleepLowerBound=0.5 \
--set coreapi.sleepUpperBound=5.0并选择 coreapi 作为 Destination Workload。
大约一分钟后,您将看到 HTTP Request Duration by Source (按源划分的 HTTP 请求持续时间 ) 图表中的值增加到 800 毫秒左右。
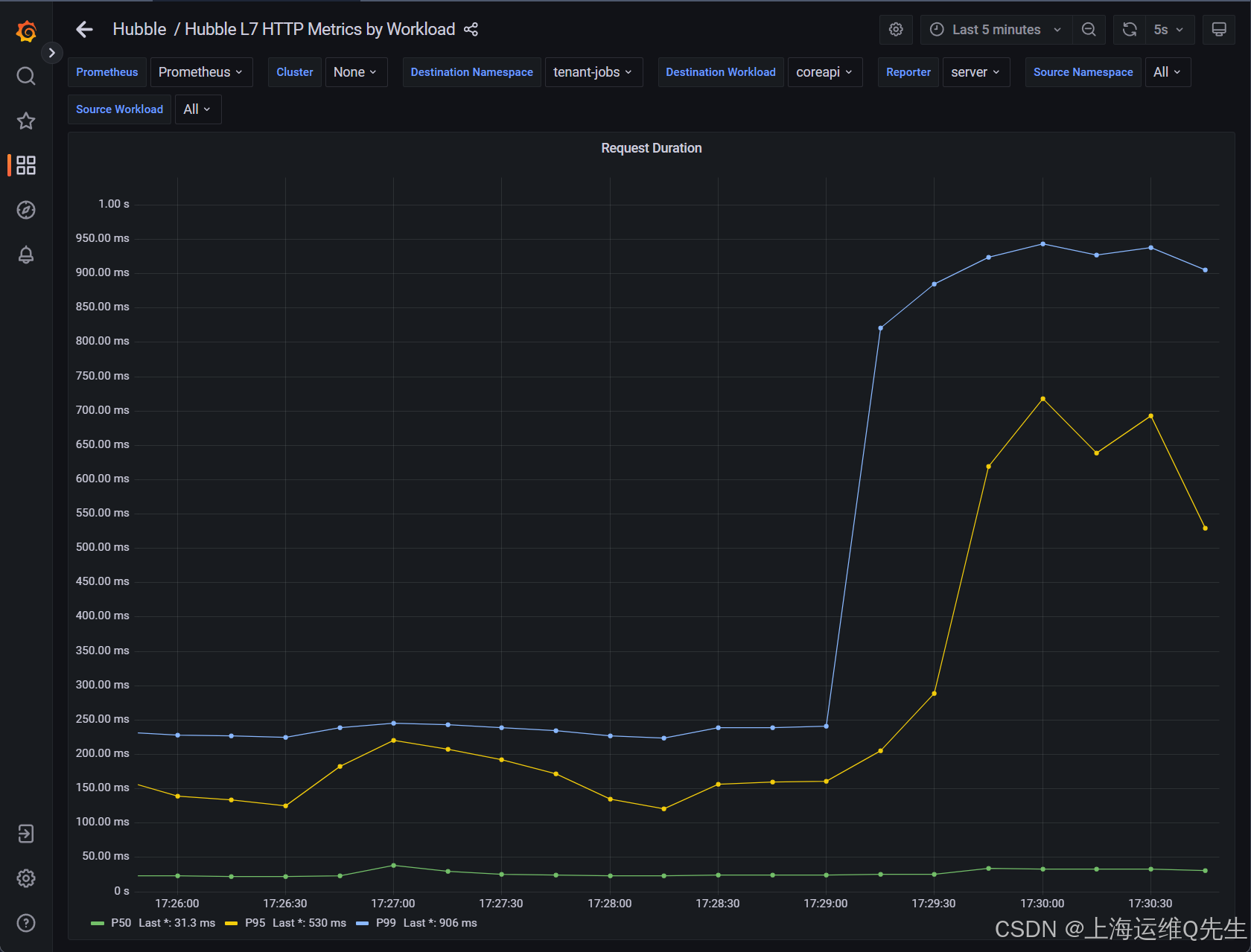
请注意,P50、P95 和 P99 的三条曲线具有截然不同的值。这意味着延迟会增加,但仅限于一小部分请求。
例如,上面的屏幕截图显示,虽然 99% 的请求的延迟低于 ~1 秒(P99 曲线),但其中 95% 的请求延迟低于 600 毫秒(P95 曲线),其中 50% 的请求速度要快得多(P50 曲线)。
单击图形下的 tenant-jobs/resumes P50 标签,仅查看以下值:
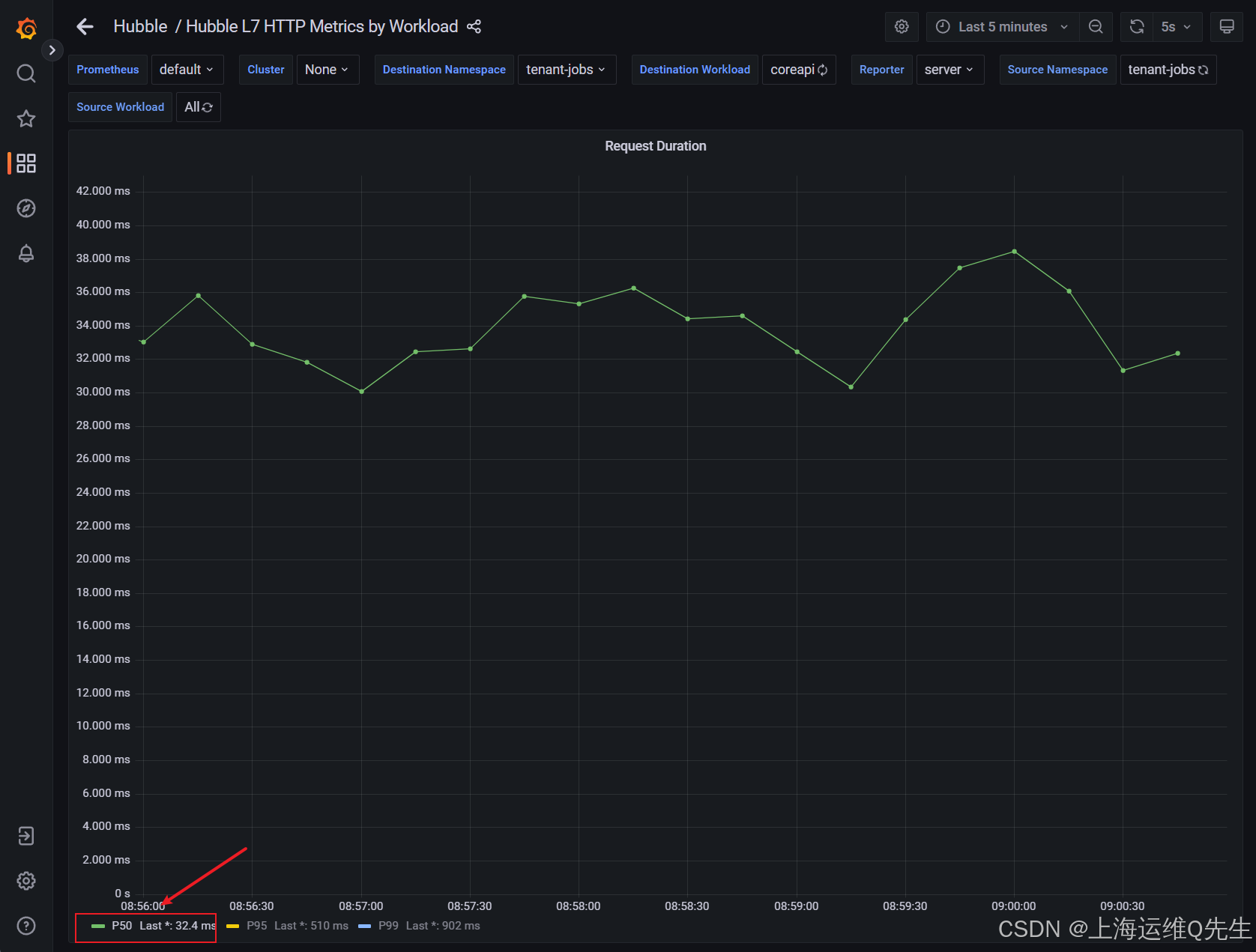
您可以看到 50% 的请求实际上需要 ~30 毫秒才能得到处理。
检查图表图例中每个序列的最小值、最大值和平均值。这对于识别延迟问题非常有用。
7. 跟踪集成
7.1 介绍
Grafana Tempo 以及 OpenTelemetry Operator 和 Collector 已添加到集群中。
升级 jobs-app 设置以启用 OpenTelemetry 跟踪。
运行:
bash
helm upgrade jobs-app ./helm/jobs-app.tgz \
--namespace tenant-jobs \
--reuse-values \
--set tracing.enabled=true这将使应用程序生成 OpenTelemetry 跟踪。
当 Cilium 的 Envoy 代理处理第 7 层数据时,Hubble 将能够从 HTTP 标头中提取 Trace ID,并将它们与 Hubble 的数据相关联,以丰富 Grafana 仪表板。
7.2 Grafana 中的痕迹
选择 coreapi 作为 Destination Workload(目标工作负载 )。
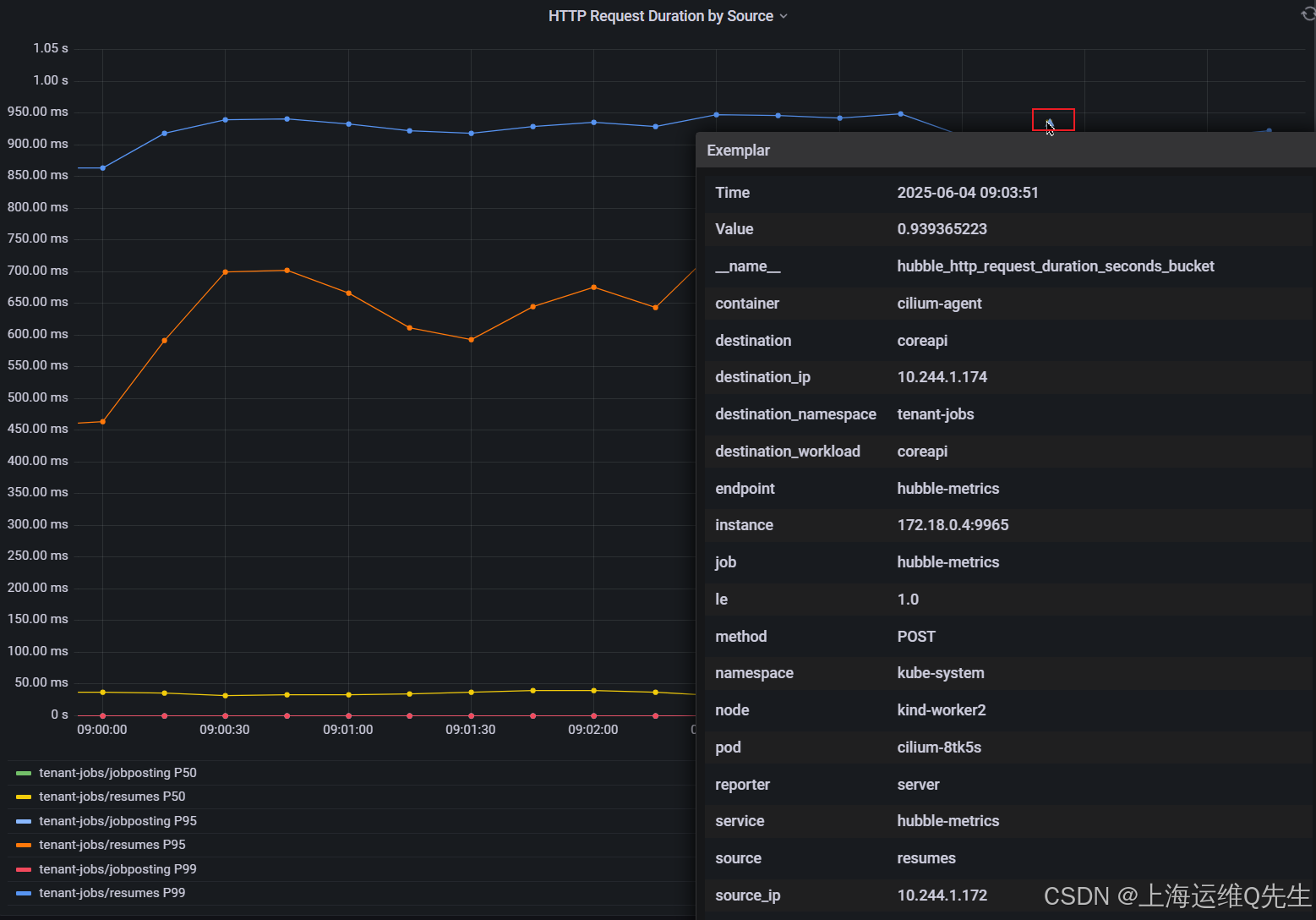
在 HTTP Request Duration by Source/Destination 面板中,您应该开始看到示例显示为点,并位于折线图可视化图表旁边。
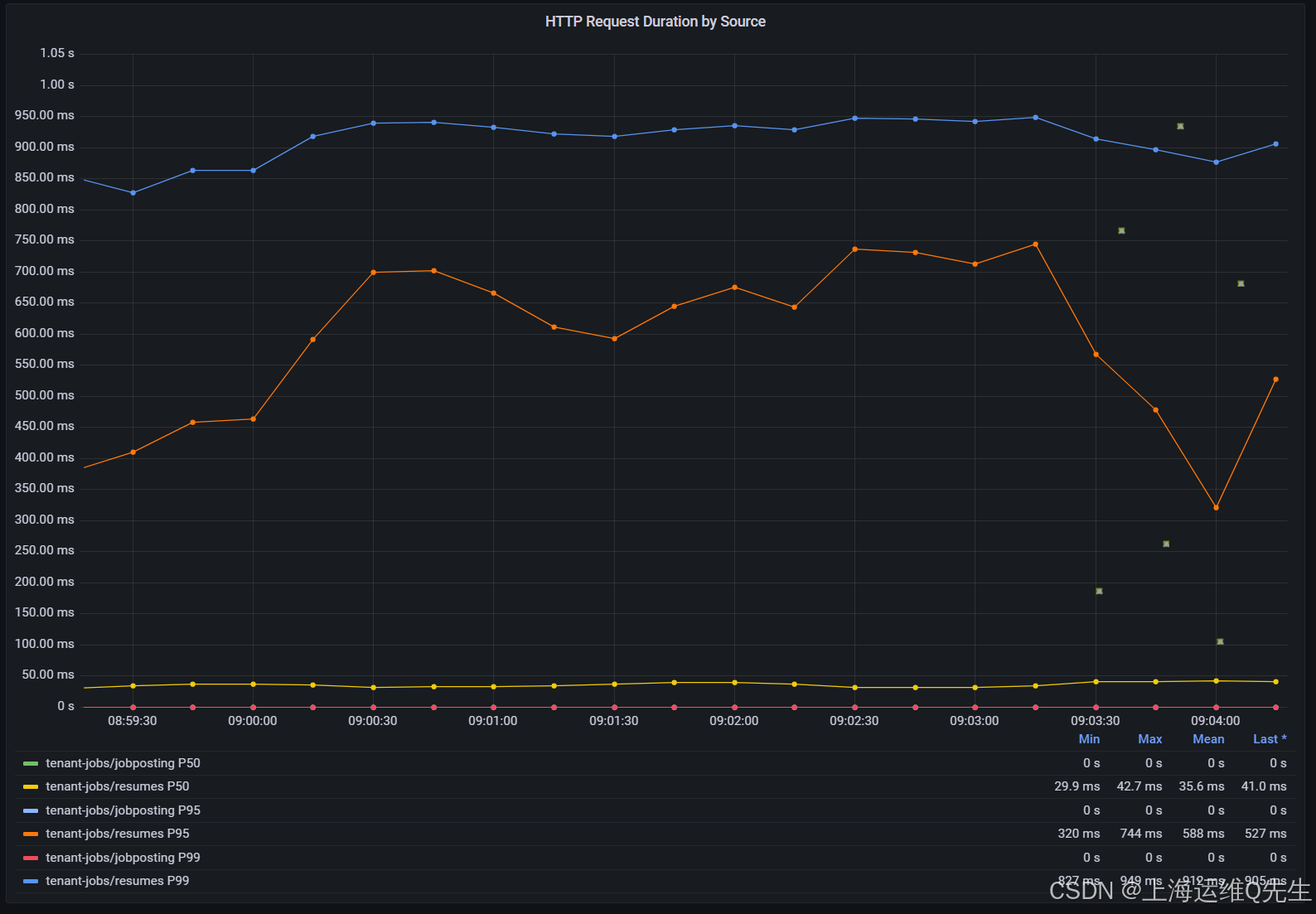
这些示例中的每个示例都表示单个请求的持续时间,并链接到跟踪 ID。
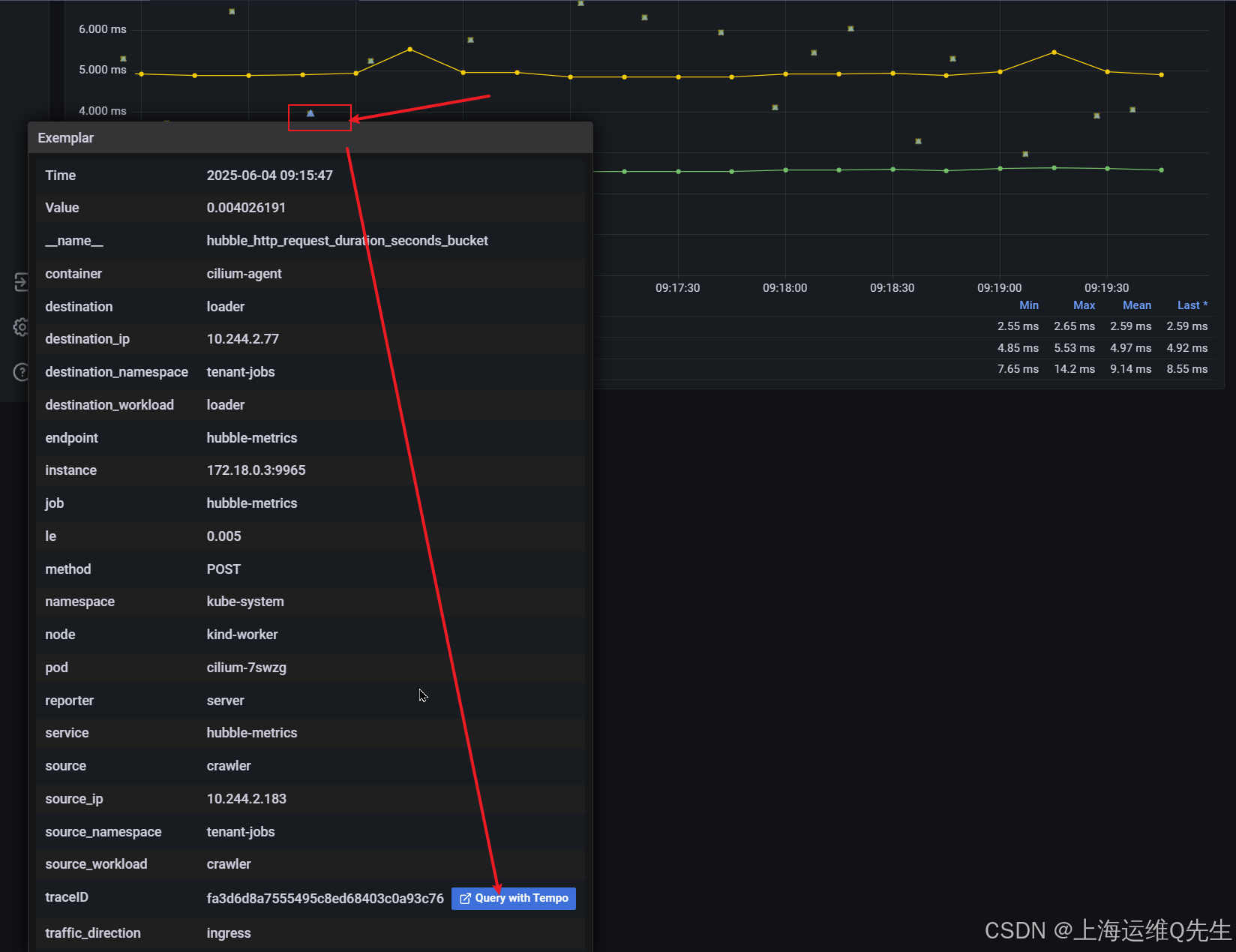
您可以通过将鼠标悬停在点上来查看跟踪详细信息。选择图表顶部的跟踪点。检查详细信息。
7.3 访问 Tempo
接下来,单击弹出窗口底部的 "Query with Tempo" 按钮。这将允许您可视化应用程序的 OpenTelemetry 跟踪。
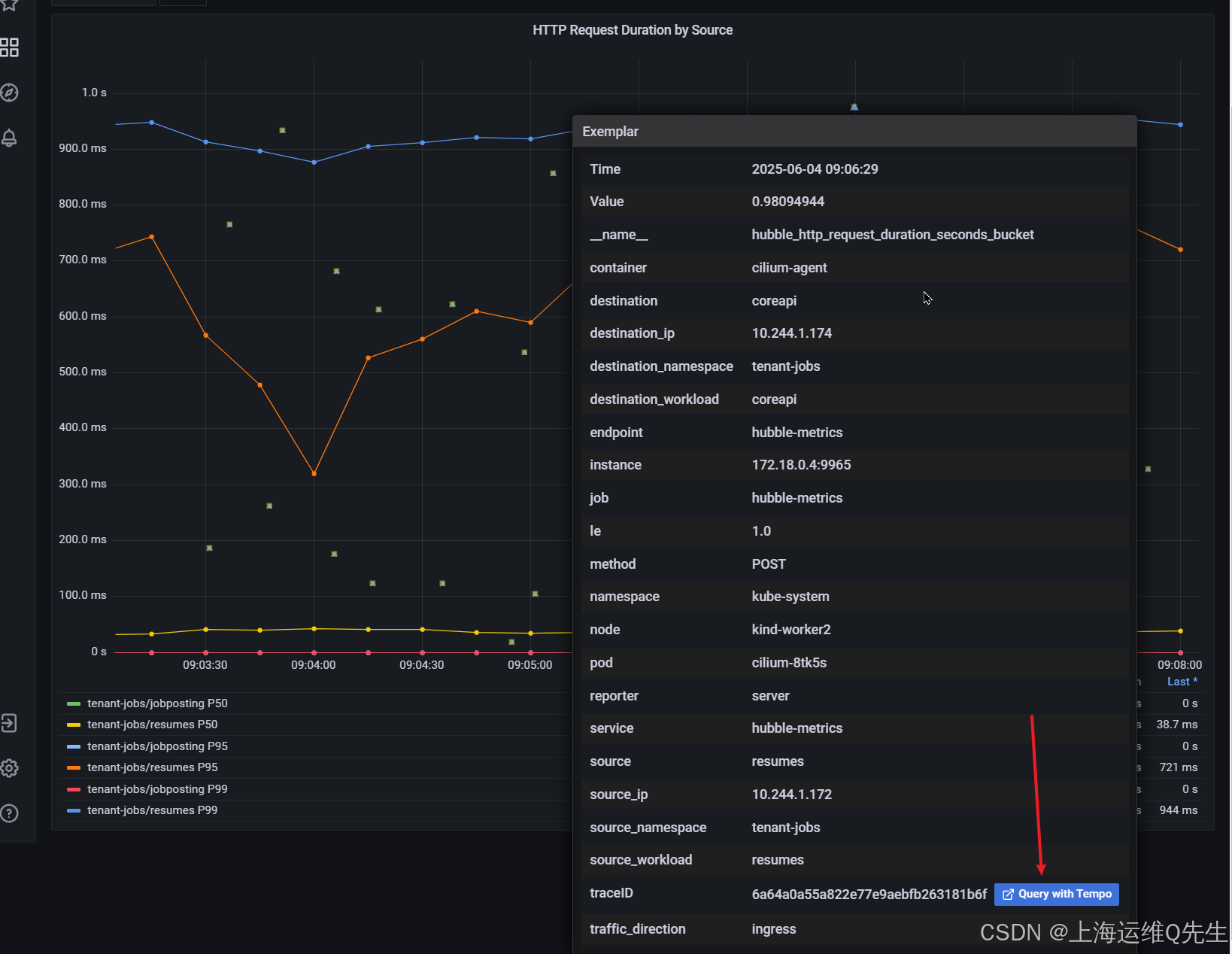
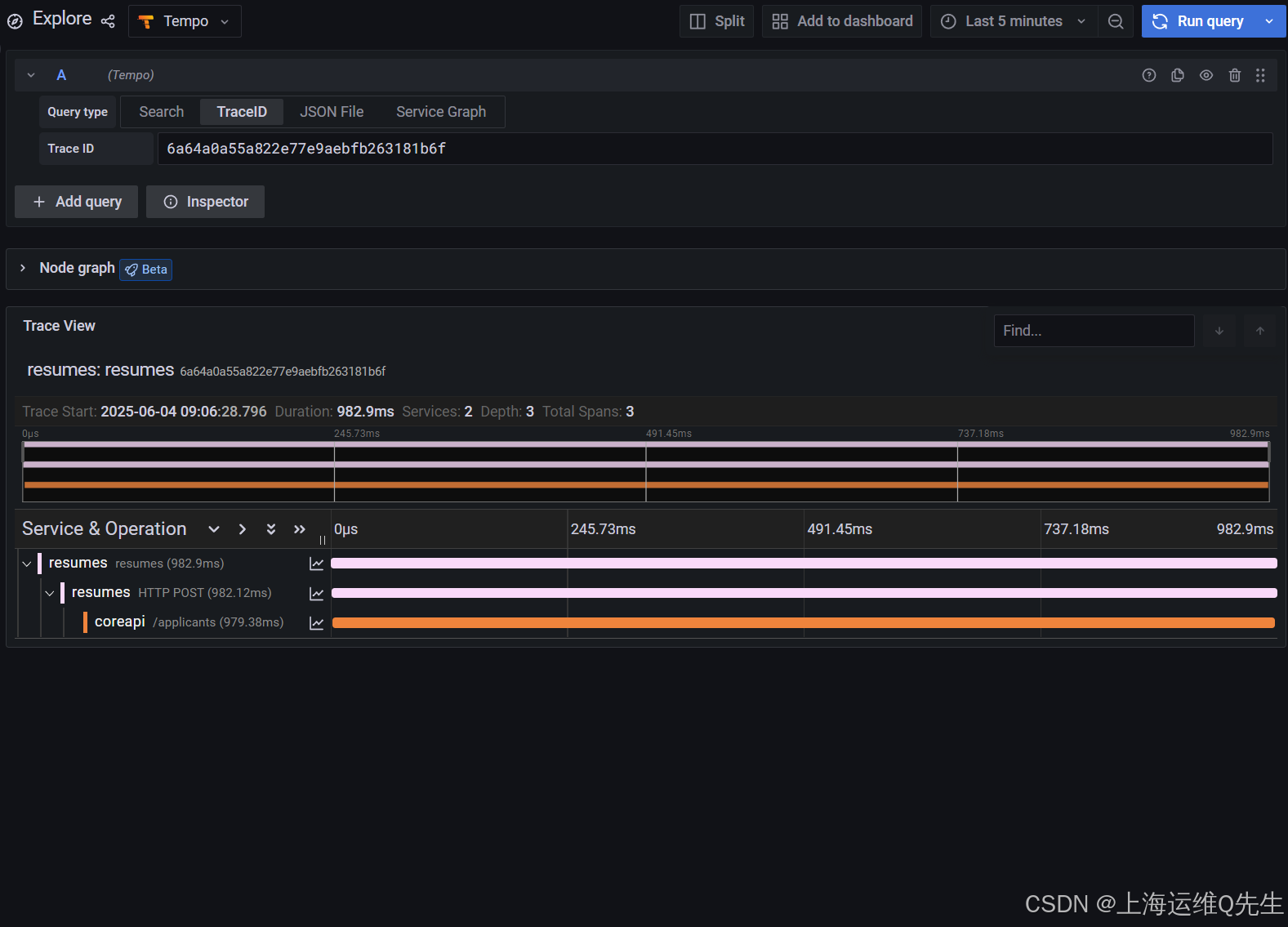
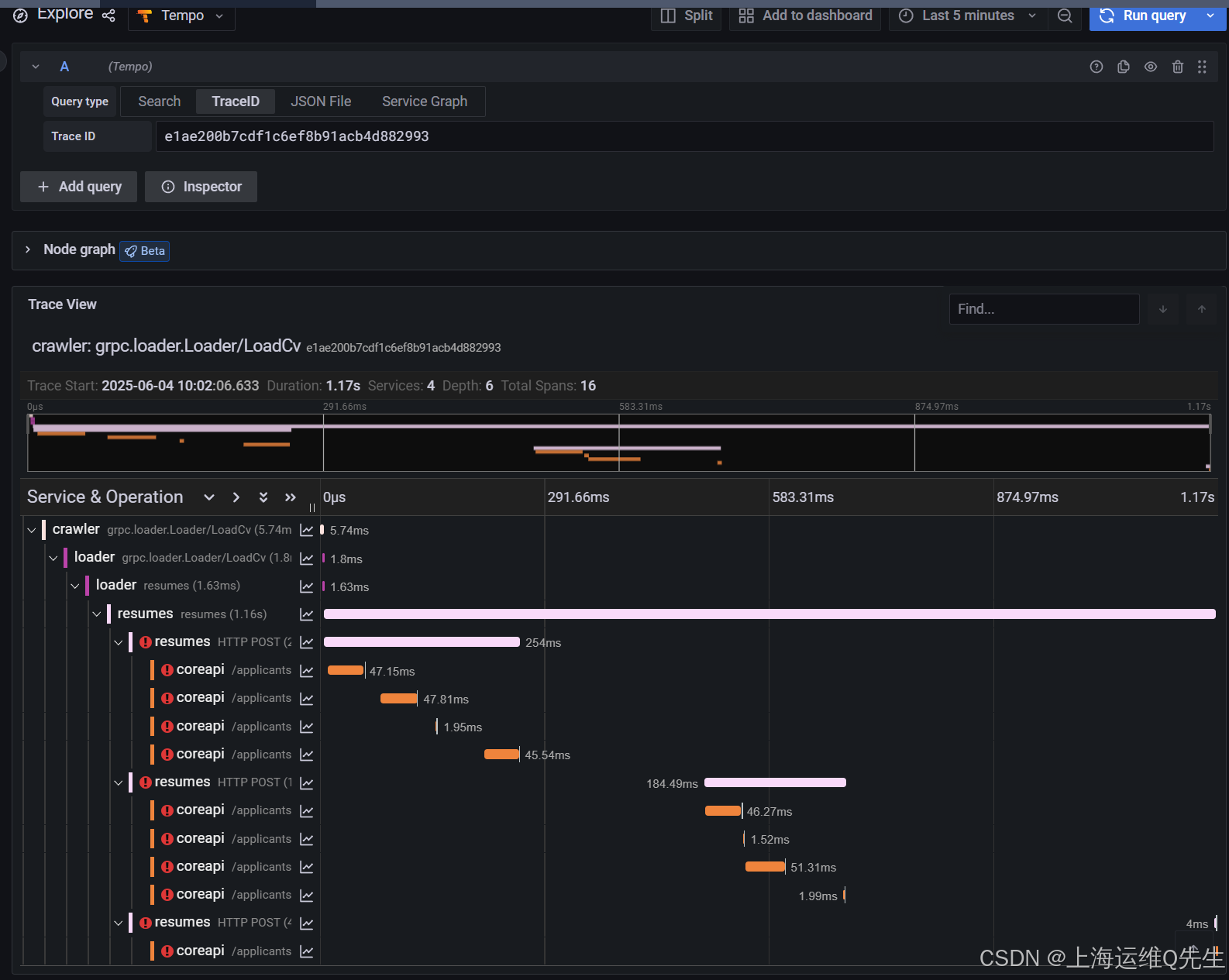
请注意, 加载程序请求的末尾(第 3 行,带有深粉色标记)和简历回复的开头(第 4 行,带有非常浅的粉红色标记)之间有一个长空格。这解释了为什么此请求具有较高的延迟(这是因为您从图表顶部选择了一个示例)。
在 Trace View 的顶部,有一个 Node graph 面板。打开它可查看显示交易中花费时间的有向图。
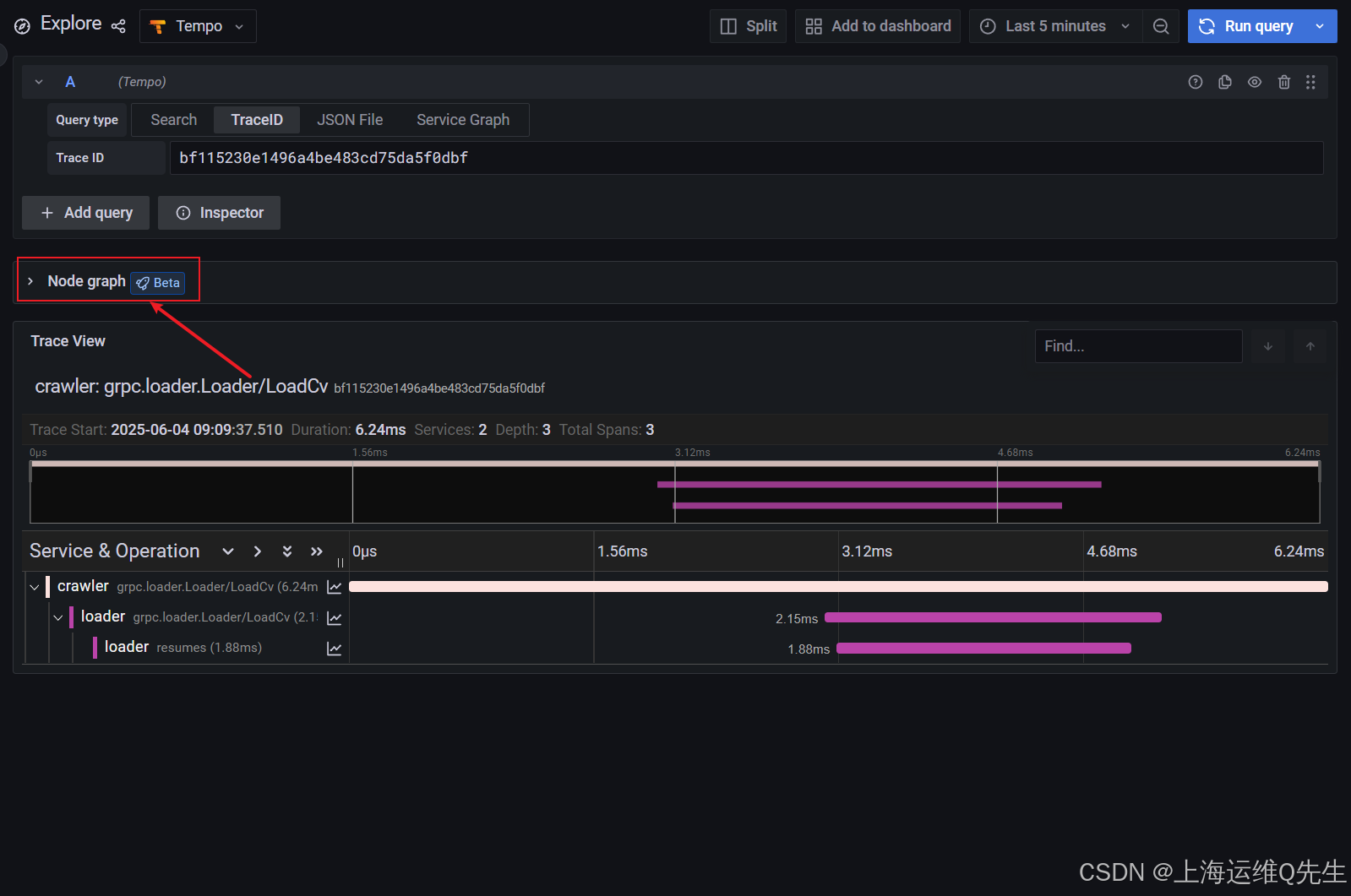
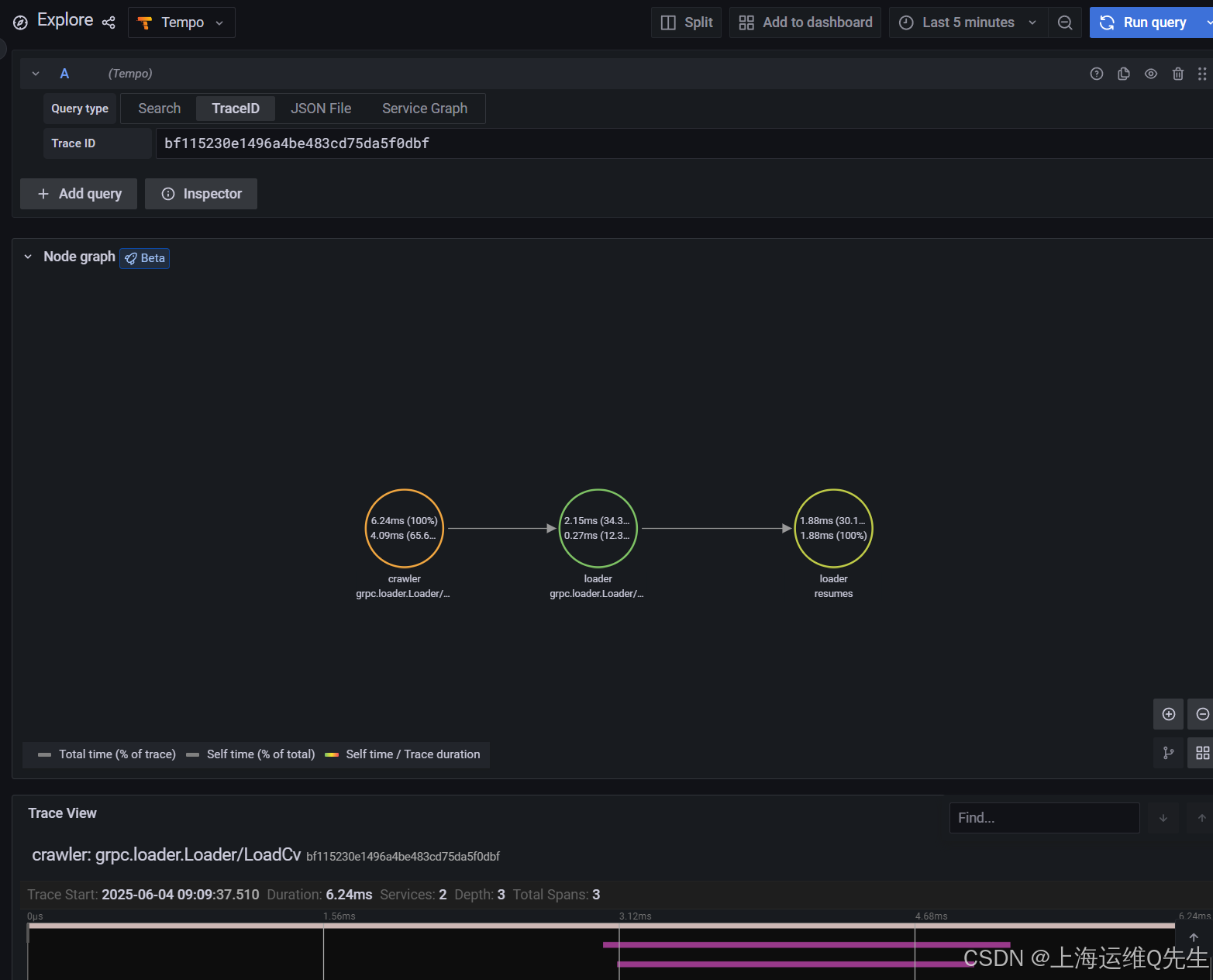
使用 Web 浏览器中的后退⬅️按钮返回预览视图。
现在,在图表的最底部选择一个请求,然后单击 "Query with Tempo" 按钮:
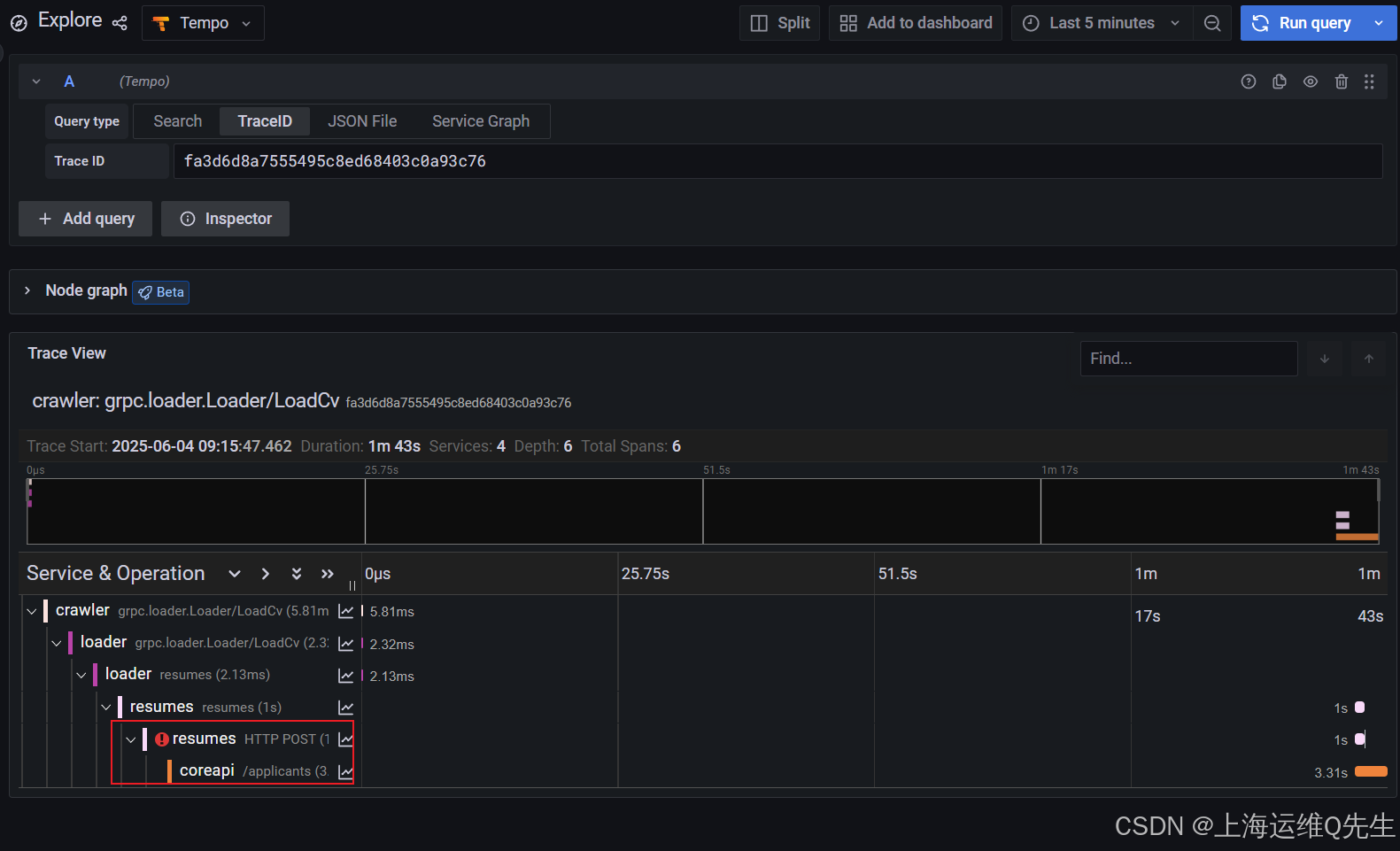
您很可能会在跟踪中看到 coreapi 服务的错误。resumes 组件正在尝试连接到 coreapi 但请求没有通过。resumes 实际上会多次重试连接,从而导致多个错误,直到成功为止。
如果您打开 Node graph (节点图形 ) 视图,您也将在那里重试:
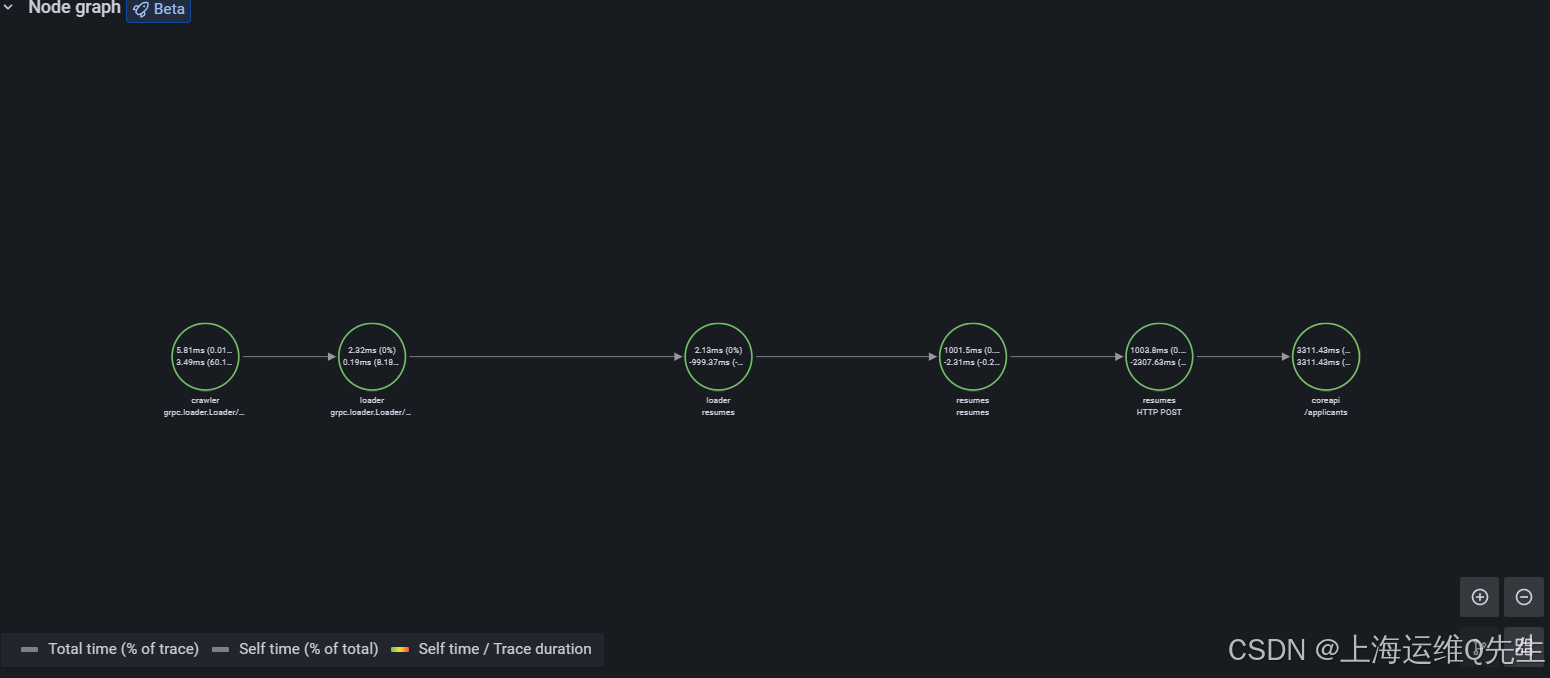
8. 最终实验
8.1 题目
应用程序已使用原始参数再次部署,但其中一个服务已损坏。
使用每项服务的 Grafana 控制面板,确定哪个服务损坏并修复它。
如果您遇到困难,请考虑以下提示。
- 提示1
首先查看传入的请求和相关错误。
浏览 Grafana 上的三个仪表板(coreapi、loader 和 elasticsearch-master)。
其中一项服务返回错误,是哪一项?
另一个服务根本不接受传入请求,是哪一个?
加载程序服务的请求数会减少,但这不是问题。这只是因为我们已将请求速率重置为其原始值。
- 提示2
分析跟踪以查找中断的请求。
在 Tempo 中打开一个跟踪,在跟踪中查找失败的服务以及重试的提示。这说明了服务失败的什么情况?
- 提示3
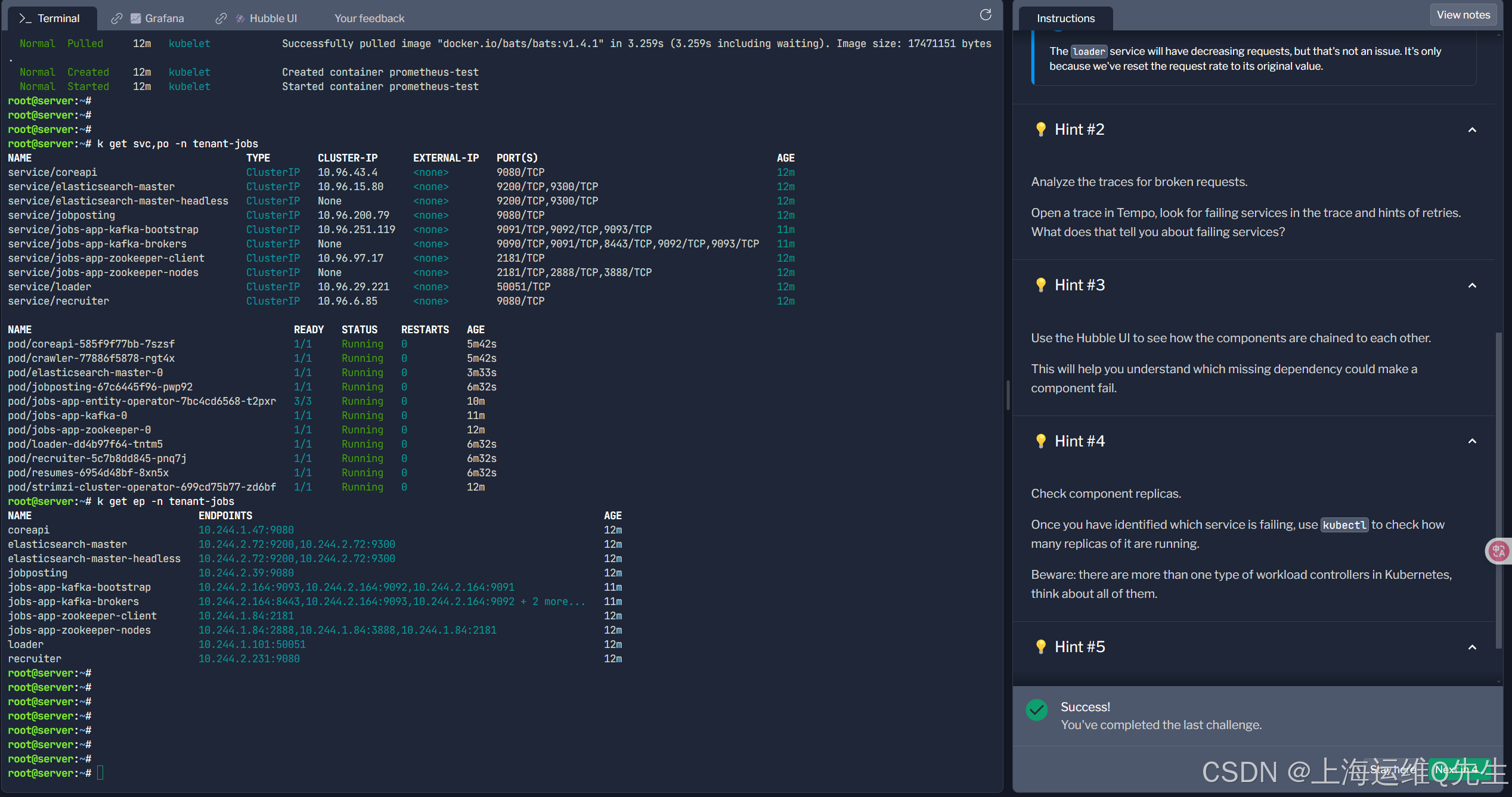
使用 Hubble UI 查看组件如何相互链接。
这将帮助您了解哪些缺失的依赖项会导致组件失败。
- 提示4
检查组件副本。
确定哪个服务失败后,请使用 kubectl 检查它有多少个副本正在运行。
当心:Kubernetes 中有不止一种类型的工作负载控制器,请考虑所有类型。
- 提示5
使用 kubectl 修复问题。该特定服务应使用一个副本运行。
8.2 解题
8.2.1 图形化界面确认问题
coreapi看上去没有数据
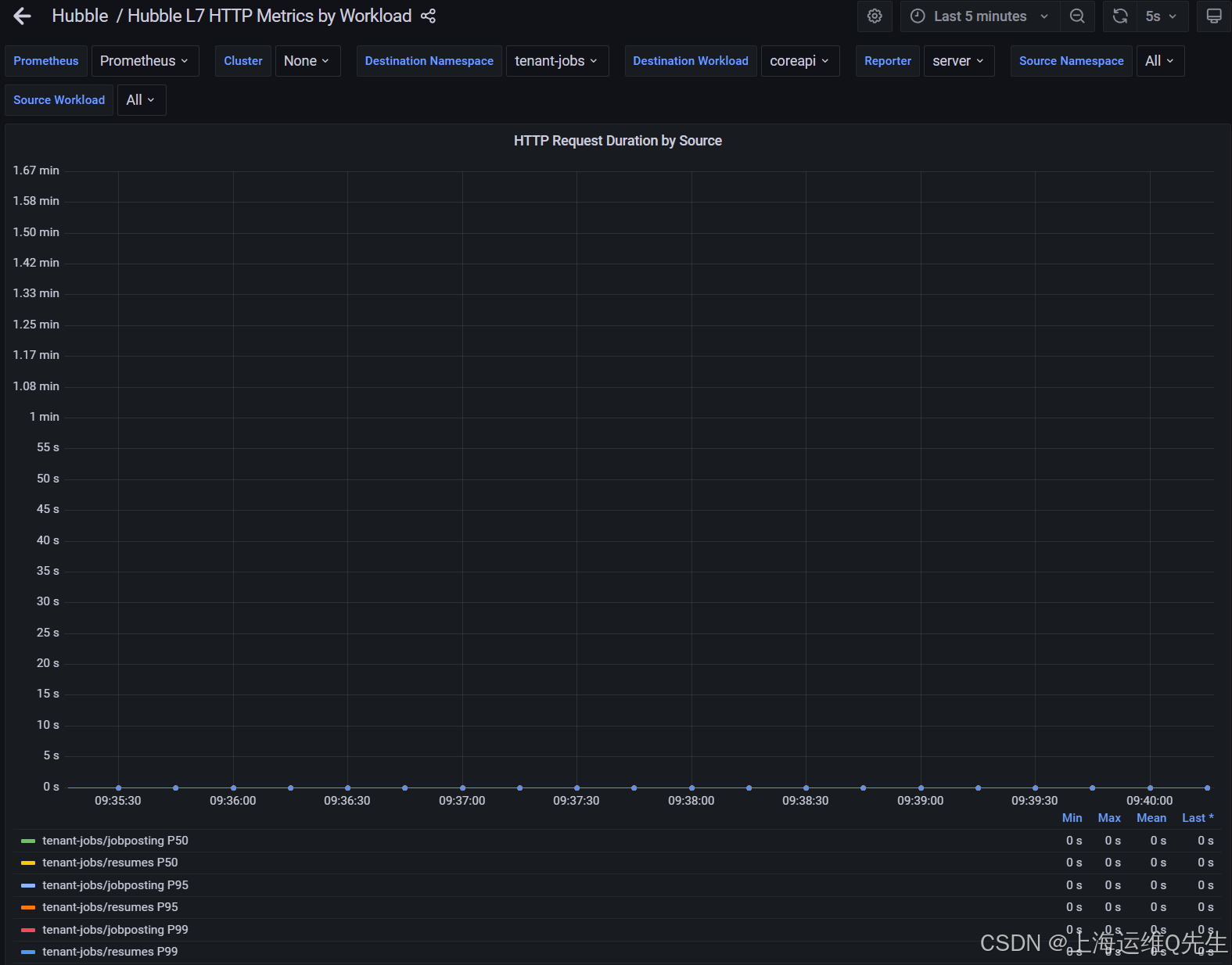
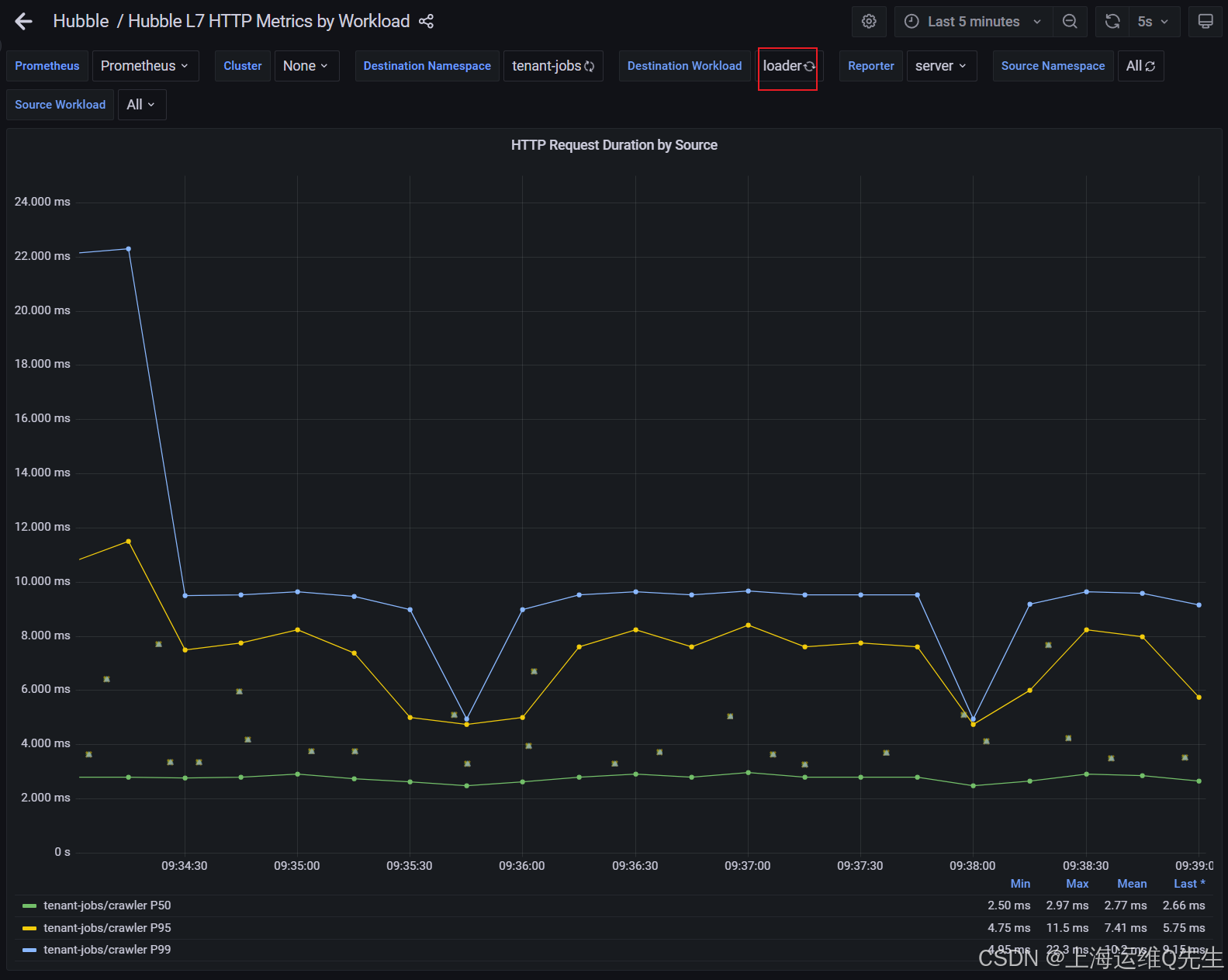
loader有返回
elasticsearch-master看上去好像也没数据
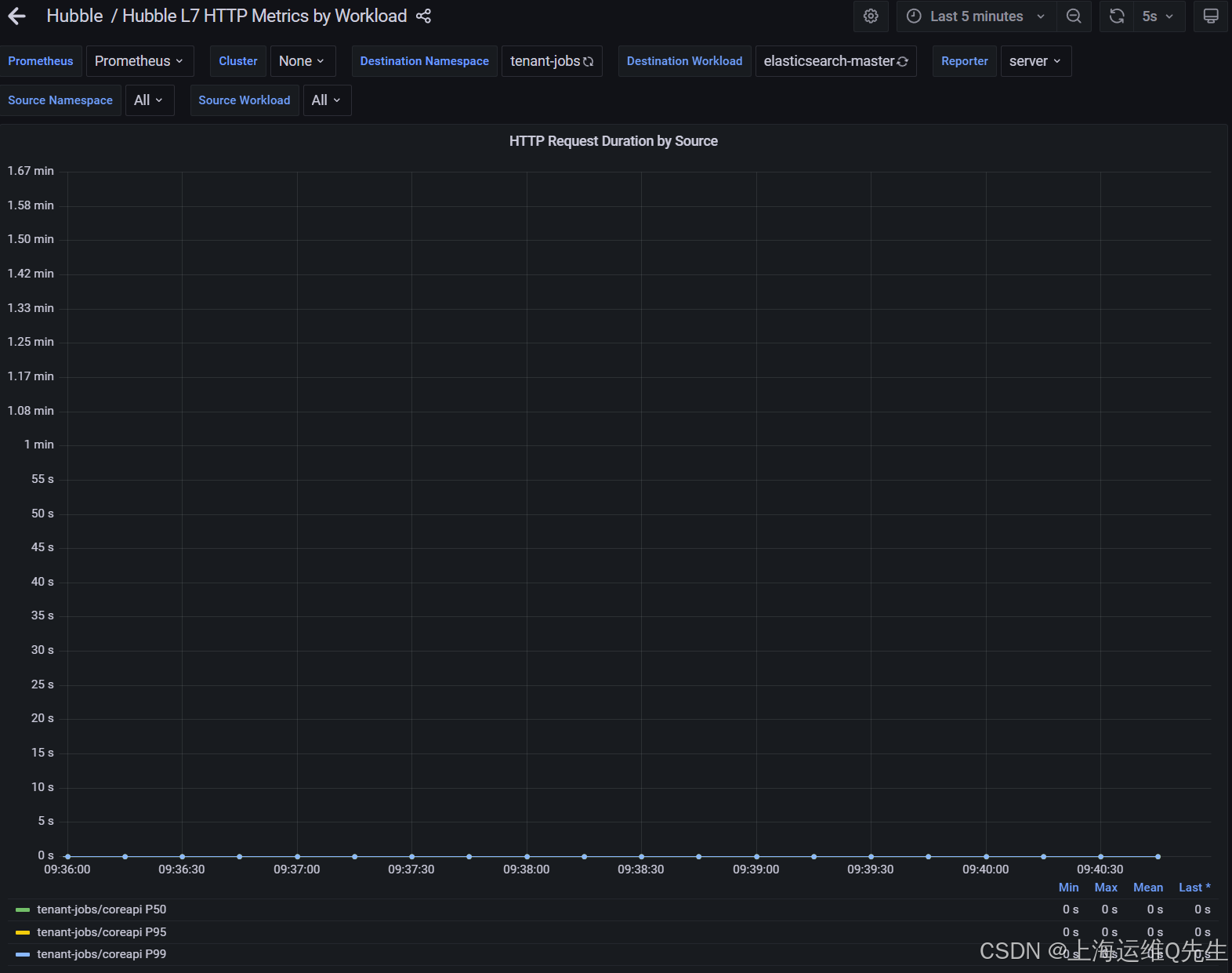
进一步调查发现coreapi是存在问题的
8.2.2 命令行下确认问题
查看下tenant-jobs下的pod情况
显然问题出在elasticsearch-master.tenant-jobs.svc.cluster.local:9200这个服务上
bash
root@server:~# k get po -n tenant-jobs
NAME READY STATUS RESTARTS AGE
coreapi-54dfb497c4-n8t5p 1/1 Running 0 19m
coreapi-585f9f77bb-48twp 0/1 Init:0/1 0 3m57s
crawler-77886f5878-g84qj 1/1 Running 0 18m
jobposting-67c6445f96-7dtll 1/1 Running 0 19m
jobs-app-entity-operator-7bc4cd6568-tg5ck 3/3 Running 0 22m
jobs-app-kafka-0 1/1 Running 0 22m
jobs-app-zookeeper-0 1/1 Running 0 23m
loader-dd4b97f64-f8d7q 1/1 Running 0 19m
recruiter-5c7b8dd845-clx42 1/1 Running 0 19m
resumes-6954d48bf-s5tpl 1/1 Running 0 19m
strimzi-cluster-operator-699cd75b77-nb4fw 1/1 Running 0 23m
root@server:~# k describe po -n tenant-jobs coreapi-585f9f77bb-48twp
Name: coreapi-585f9f77bb-48twp
Namespace: tenant-jobs
Priority: 0
Service Account: default
Node: kind-worker2/172.18.0.3
Start Time: Wed, 04 Jun 2025 02:33:28 +0000
Labels: app=coreapi
pod-template-hash=585f9f77bb
Annotations: <none>
Status: Pending
IP: 10.244.2.233
IPs:
IP: 10.244.2.233
Controlled By: ReplicaSet/coreapi-585f9f77bb
Init Containers:
wait-for-elasticsearch:
Container ID: containerd://4e12c079de57cdc32f0dc851a3185de25c4ac3011afa8f578efa04bcd07fd650
Image: curlimages/curl:latest
Image ID: docker.io/curlimages/curl@sha256:d43bdb28bae0be0998f3be83199bfb2b81e0a30b034b6d7586ce7e05de34c3fd
Port: <none>
Host Port: <none>
Command:
sh
-c
until curl -s -o /dev/null http://elasticsearch-master.tenant-jobs.svc.cluster.local:9200; do echo waiting for elasticsearch; sleep 5; done
State: Running
Started: Wed, 04 Jun 2025 02:33:29 +0000
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dmpxc (ro)
Containers:
coreapi:
Container ID:
Image: quay.io/isovalent/jobs-app-coreapi:v0.10.0
Image ID:
Port: 9080/TCP
Host Port: 0/TCP
State: Waiting
Reason: PodInitializing
Ready: False
Restart Count: 0
Environment:
ES_ENDPOINT: http://elastic:changeme@elasticsearch-master.tenant-jobs.svc.cluster.local:9200/
BOOTSTRAP: true
DEBUG: false
ENABLE_TRACING: true
LOG_SPANS: false
OTL_EXPORTER_ENABLED: true
HOST_IP: (v1:status.hostIP)
OTEL_EXPORTER_OTLP_ENDPOINT: http://$(HOST_IP):4317
ERROR_RATE: 0.01
SLEEP_RATE: 0.1
SLOW_REQUEST_DURATION_LOWER_BOUND: 0.1
SLOW_REQUEST_DURATION_UPPER_BOUND: 0.2
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dmpxc (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized False
Ready False
ContainersReady False
PodScheduled True
Volumes:
kube-api-access-dmpxc:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4m10s default-scheduler Successfully assigned tenant-jobs/coreapi-585f9f77bb-48twp to kind-worker2
Normal Pulling 4m9s kubelet Pulling image "curlimages/curl:latest"
Normal Pulled 4m9s kubelet Successfully pulled image "curlimages/curl:latest" in 664ms (664ms including waiting). Image size: 9555383 bytes.
Normal Created 4m9s kubelet Created container wait-for-elasticsearch
Normal Started 4m9s kubelet Started container wait-for-elasticsearch再确认这个svc发现elasticsearch-master没有ep存在
bash
root@server:~# k get svc -n tenant-jobs elasticsearch-master
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-master ClusterIP 10.96.117.68 <none> 9200/TCP,9300/TCP 25m
root@server:~# k get ep -n tenant-jobs elasticsearch-master
NAME ENDPOINTS AGE
elasticsearch-master <none> 25m通过命令发现statefulset的elasticsearch-master是0/0
bash
root@server:~# k get all -n tenant-jobs |grep ela
service/elasticsearch-master ClusterIP 10.96.117.68 <none> 9200/TCP,9300/TCP 26m
service/elasticsearch-master-headless ClusterIP None <none> 9200/TCP,9300/TCP 26m
statefulset.apps/elasticsearch-master 0/0 26m调度statefulset副本数
bash
root@server:~# k scale -n tenant-jobs statefulset --replicas=1 elasticsearch-master
statefulset.apps/elasticsearch-master scaled稍等片刻后tenant命名空间下面的pod都正常了
bash
root@server:~# k get po -n tenant-jobs
NAME READY STATUS RESTARTS AGE
coreapi-585f9f77bb-48twp 1/1 Running 0 9m52s
crawler-77886f5878-g84qj 1/1 Running 0 24m
elasticsearch-master-0 1/1 Running 0 99s
jobposting-67c6445f96-7dtll 1/1 Running 0 24m
jobs-app-entity-operator-7bc4cd6568-tg5ck 3/3 Running 0 28m
jobs-app-kafka-0 1/1 Running 0 28m
jobs-app-zookeeper-0 1/1 Running 0 29m
loader-dd4b97f64-f8d7q 1/1 Running 0 24m
recruiter-5c7b8dd845-clx42 1/1 Running 0 24m
resumes-6954d48bf-s5tpl 1/1 Running 0 24m
strimzi-cluster-operator-699cd75b77-nb4fw 1/1 Running 0 29m此时Grafana这边也正常了
看来应该没什么问题了.提交!
新徽章GET!
