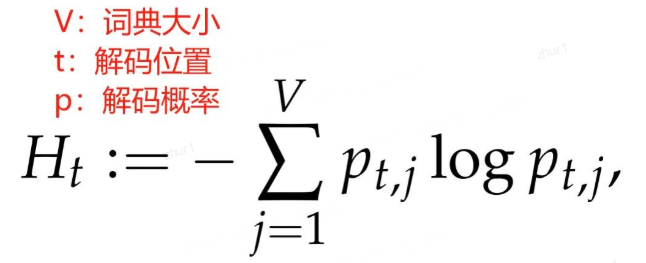Qwen团队新发现:大模型推理能力的提高仅由少数高熵 Token 贡献
不要让低概率token主导了LLM的强化学习过程
一 低概率词元问题
论文:Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
在RL训练过程中,低概率词元(low-probability tokens)因其巨大的梯度幅值,在模型更新中产生了不成比例的主导效应。这种"梯度主导"现象会严重抑制对模型性能至关重要的高概率词元的有效学习,从而阻碍了模型能力的进一步提升。本文首先从理论上溯源了这一现象,揭示了其内在机理:对于一个典型的LLM,任何词元在网络中间层产生的梯度范数,其大小与( 1-兀)成正比,其中兀是该词元的生成概率。这一关系清晰地表明,词元概率越低,其梯度贡献越大,反之则越小。
基于这一核心洞察,提出了两种旨在恢复梯度平衡、简单而高效的方法,以缓解低概率词元的过度主导:
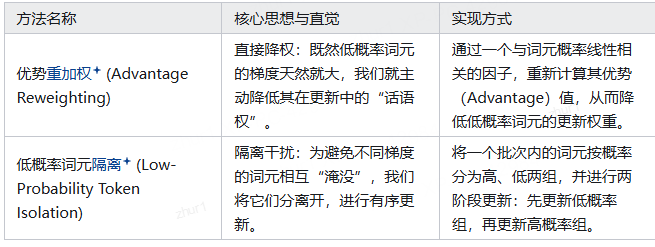
二 高熵token
论文:Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning
token 熵" 并不是针对于某个特定 token,而是在特定位置 t,对解码不确定性的度量
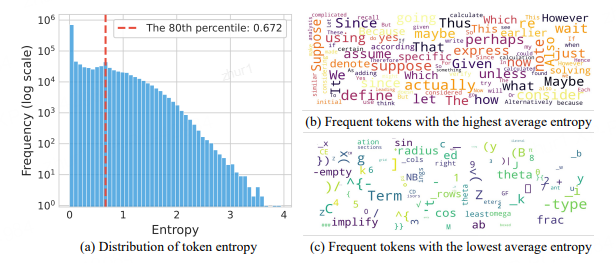
作者发现,生成推理链时每个位置的 token 熵值极度不均衡:只有少数 token 以高熵生成,而大多数 token 以低熵输出。具体地,80% 的token 熵低于0.67
熵最高的 token 通常用于连接两个连续推理部分之间的逻辑关系,比如wait、however 和 unless 等(对比或转折),thus 和 also(递进或补充),since 和 because (因果关系);在数学推导中,suppose、assume、given 和 define 等 token 频繁出现,用于引入假设、已知条件或定义
熵最低的 token 则倾向于完成当前句子部分或结束单词的构建,均表现出高度的确定性
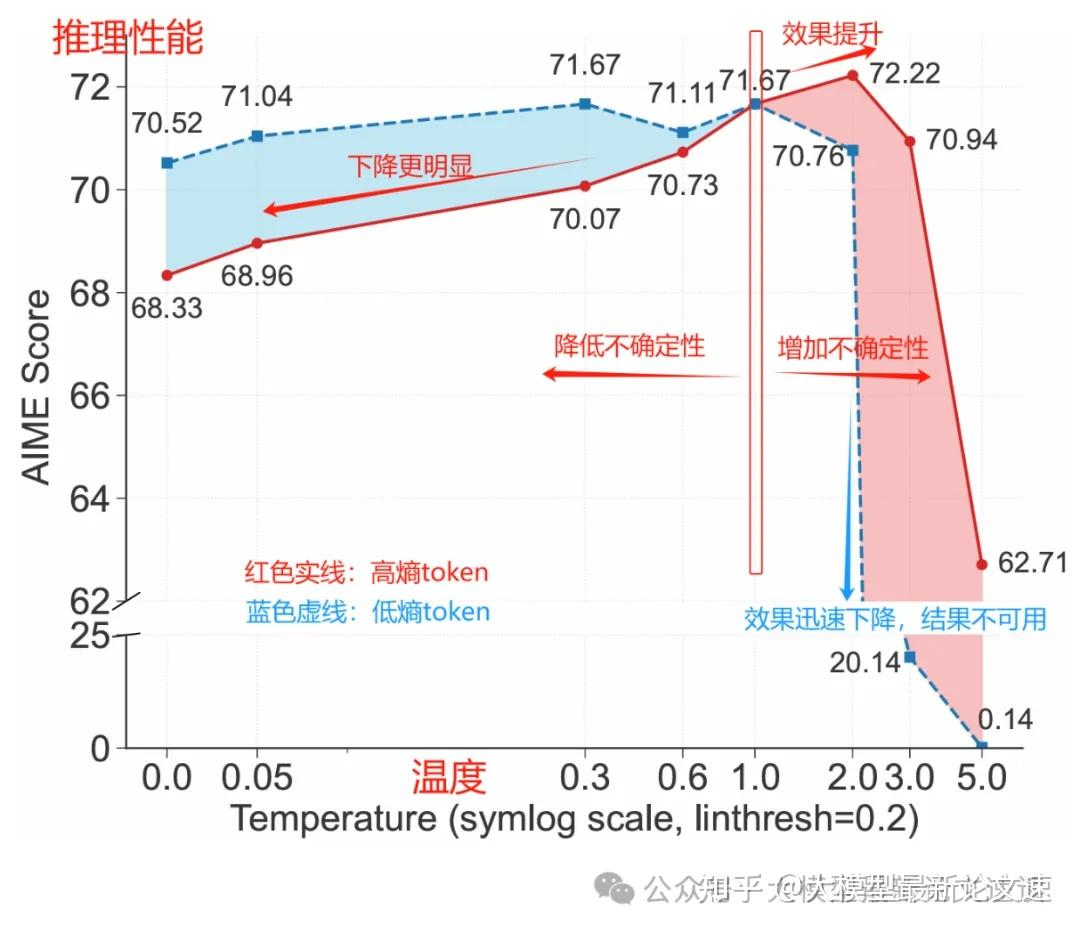
为了验证高熵 token 对推理性能的关键作用,作者通过控制解码温度来调整这些 token 在生成过程中的随机性。结果表明,适当提高高熵 token 的熵值可以提高推理正确率;反之,强行降低其熵值则会显著损害性能。这充分证明了在关键分叉 token 处保持较高的不确定性和探索度,对提高推理质量大有裨益。可见,少数高熵 token 确实是推理过程中应重点关注的"要害"
作者设计了这样的实验:利用 DAPO 算法训练 Qwen3-14B 模型,保存不同训练阶段下的 checkpoint,分别在各种数学推理基准上进行采样,识别各中间模型的高熵 token,然后分别计算这些它们与原始模型、训练完毕后的模型对应的高熵 token 重叠率,结果如下
可见在 RL 训练过程中,尽管与基础模型的重叠逐渐减少,但在收敛时(第 1360 步),基础模型的重叠率仍保持在 86% 以上,这表明 RL 训练在很大程度上保留了基础模型的高熵 token
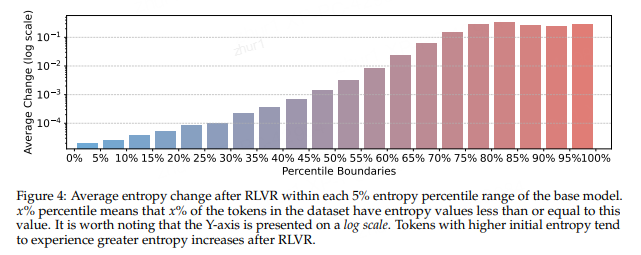
那么具体的熵值又是如何变化呢?下图是作者的统计结果,可见基础模型中初始熵较高的 token 在 RL 后往往表现出更大的熵增,这与三中的实验结论不谋而合,表明 RL 带来推理性能提升的原因之一,很可能就是因为高熵 token 的不确定性更强了,提高了大模型推理的灵活性