【论文速读】利用负信号蒸馏:用REDI框架提升LLM推理能力
论文信息
arXiv:2505.24850 cs.LG cs.AI cs.CL
Harnessing Negative Signals: Reinforcement Distillation from Teacher Data for LLM Reasoning
Authors: Shuyao Xu, Cheng Peng, Jiangxuan Long, Weidi Xu, Wei Chu, Yuan Qi一、研究背景:被浪费的"错误宝藏"
想象你在学数学题,老师只给你看正确解答,却从不讲解错误思路为啥错------这时候你可能会疑惑:"我怎么知道自己哪里容易踩坑?"
大语言模型(LLM)的蒸馏训练就面临类似问题。传统方法(如拒绝采样)只保留老师模型生成的正确推理痕迹(正样本),扔掉错误推理痕迹(负样本)。但这些负样本里藏着大量"避坑指南":比如模型常犯的逻辑错误、边界条件遗漏等。
举个例子,在数学推理中,老师模型可能试过错误的公式套用或步骤顺序,这些失败案例对小模型学习"如何避免犯错"至关重要。但现有方法白白浪费了这些信息,导致小模型只能"学正确答案",却"不懂错误根源",推理能力提升有限。
二、创新点:让错误成为"学习信号"
这篇论文的核心突破是:首次系统利用负样本进行强化蒸馏,提出两阶段框架REDI(Reinforcement Distillation),解决了三大问题:
- 负样本利用率低:传统方法丢弃负样本,REDI将其转化为可学习的损失信号。
- 稳定性与性能的矛盾 :现有方法(如DPO)依赖KL散度正则化,高正则化虽稳定但限制性能,低正则化则容易训练崩溃。REDI通过非对称加权损失(α参数)平衡两者,既避免崩溃又提升峰值性能。
- 数据效率低下:用更少数据(131k正负样本)超越需800k专有数据的模型,开源数据也能训出SOTA。
三、研究方法和思路:两步走的"纠错学习法"
阶段1:用正确答案打基础(SFT)
- 目标:让小模型先学会"正确推理的样子"。
- 方法 :用正样本(老师的正确推理痕迹)进行监督微调(SFT),优化目标是最大化生成正确痕迹的概率:
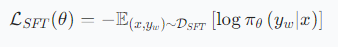
- 作用:建立基础推理能力,作为后续优化的起点。
阶段2:用错误答案做强化(REDI目标函数)
- 目标:让小模型学会"识别错误",避免重复老师的失误。
- 方法 :引入负样本,设计非对称加权损失函数,同时优化两个方向:
-
最大化正样本概率:让正确推理更可能被生成。
-
最小化负样本概率 :抑制错误推理,但通过参数α降低负样本的梯度权重(α∈0,1),避免过度惩罚导致模型"不敢推理"。
损失函数:
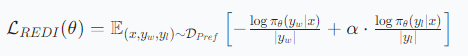
-
α的作用:α=1时等价于对称损失(易崩溃),α=0时退化为仅用正样本。实验发现α=0.8时平衡最佳。
-
实验验证:小数据也能超越大厂模型
- 数据:从Open-R1数据集提取78k正样本(D_SFT)和53k正负样本对(D_Pref),总数据量131k。
- 对比模型 :
- 基线:SFT(仅正样本)、SFT+DPO/SimPO(传统强化方法)。
- 竞品:DeepSeek-R1-Distill-Qwen-1.5B(用800k专有数据训练)。
- 结果 :
- Qwen-REDI-1.5B在MATH-500基准上达到83.1%准确率(pass@1),超过DeepSeek-R1-Distill-Qwen-1.5B的83.2%,且数据量仅为其1/6。
- 消融实验显示,REDI的非对称加权比对称损失(α=1)更稳定,比DPO/SimPO性能提升1-2%。
四、主要贡献:三大突破推动LLM蒸馏
- 方法论创新:提出REDI框架,首次在离线蒸馏中有效利用负样本,打破"负样本=无用数据"的固有认知。
- 性能提升:用开源数据实现1.5B模型SOTA,数据效率提升6倍,为小团队和开源社区提供低成本方案。
- 理论分析:揭示DPO等方法中KL正则化的"性能-稳定性"矛盾,为未来损失函数设计提供方向。
五、总结:错误是最好的老师
这篇论文证明,LLM的"错误"不是垃圾,而是珍贵的学习信号。REDI通过"先学对、再辨错"的两步法,让小模型既能掌握正确推理模式,又能识别常见错误,实现了推理能力的跨越式提升。更重要的是,其数据高效性(131k样本)和开源友好性(基于Open-R1),让更多研究者能复现和改进,推动LLM推理能力向低成本、高效化方向发展。
未来,REDI框架可进一步与在线RL结合,形成"离线蒸馏+在线优化"的完整链路,或许能解锁更复杂的推理场景------毕竟,连错误都能被利用的模型,才是真正"会学习"的模型。