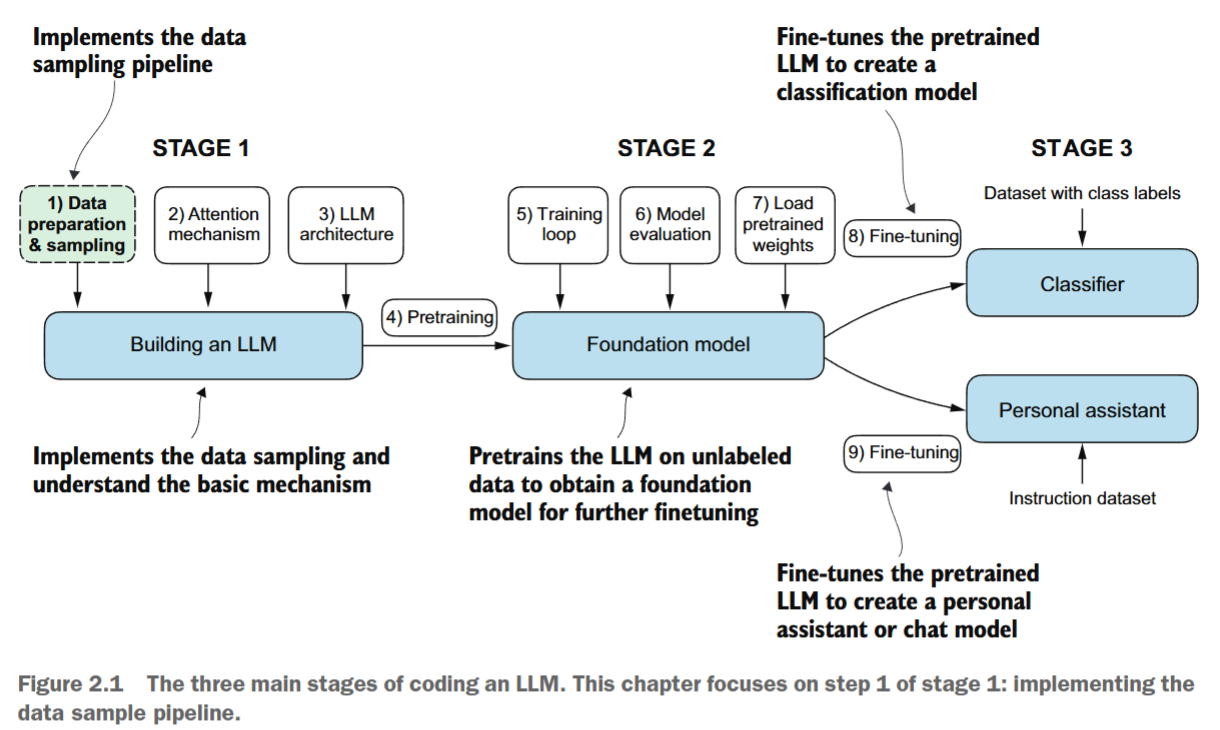
This chapter covers
- Preparing text for large language model training
- Splitting text into word and subword tokens
- Byte pair encoding as a more advanced way of tokenizing text
- Sampling training examples with a sliding window approach
- Converting tokens into vectors that feed into a large language model
你将学习如何为训练大型语言模型(LLMs)准备输入文本。这包括将文本拆分为单个单词和子词标记,然后将这些标记编码为适合LLM的向量表示。你还将了解高级标记化方案,如字节对编码(BPE)------这是GPT等流行LLM中使用的技术。最后,我们将实现一种采样和数据加载策略,以生成训练LLM所需的输入-输出对。
2.1 Understanding word embeddings
包括大型语言模型(LLMs)在内的深度神经网络模型无法直接处理原始文本。由于文本属于分类数据,它与实现和训练神经网络所使用的数学运算不兼容。因此,我们需要一种将单词表示为连续值向量的方法。
注意:不熟悉计算环境中向量和张量的读者可以在附录A的A.2.2节中了解更多信息。
将数据转换为向量格式的概念通常称为embedding。如图2.2所示,使用特定的神经网络层或其他预训练神经网络模型,我们可以对不同数据类型进行embedding,例如视频、音频和文本。但需要注意的是,不同数据格式需要不同的embedding模型。例如,为文本设计的embedding模型并不适用于embedding音频或视频数据。
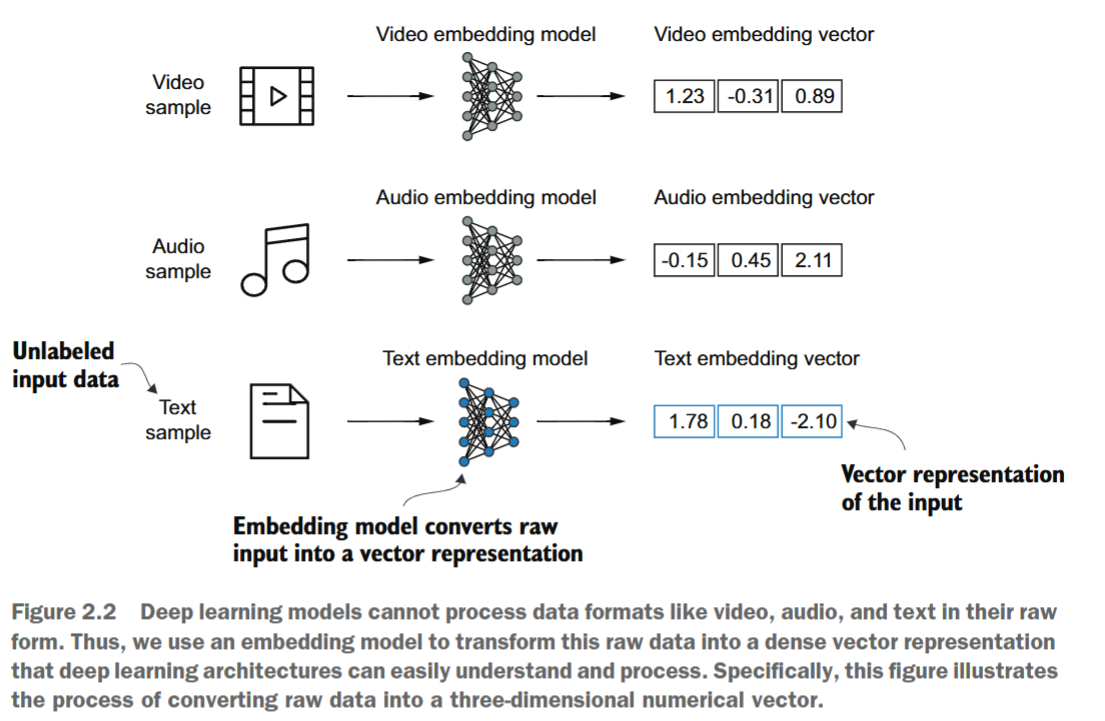
从核心上讲,嵌入是一种将离散对象(如单词、图像甚至整个文档)映射到连续向量空间中的点的过程------嵌入的主要目的是将非数值数据转换为神经网络可以处理的格式。
尽管词嵌入是最常见的文本嵌入形式,但也存在句子、段落或整篇文档的嵌入。句子或段落嵌入在检索增强生成中是常用选择。检索增强生成将生成(如生成文本)与检索(如搜索外部知识库)相结合,以便在生成文本时提取相关信息,这一技术超出了本书的范围。由于我们的目标是训练类似GPT的大型语言模型(这类模型学习逐词生成文本),因此我们将重点关注词嵌入。
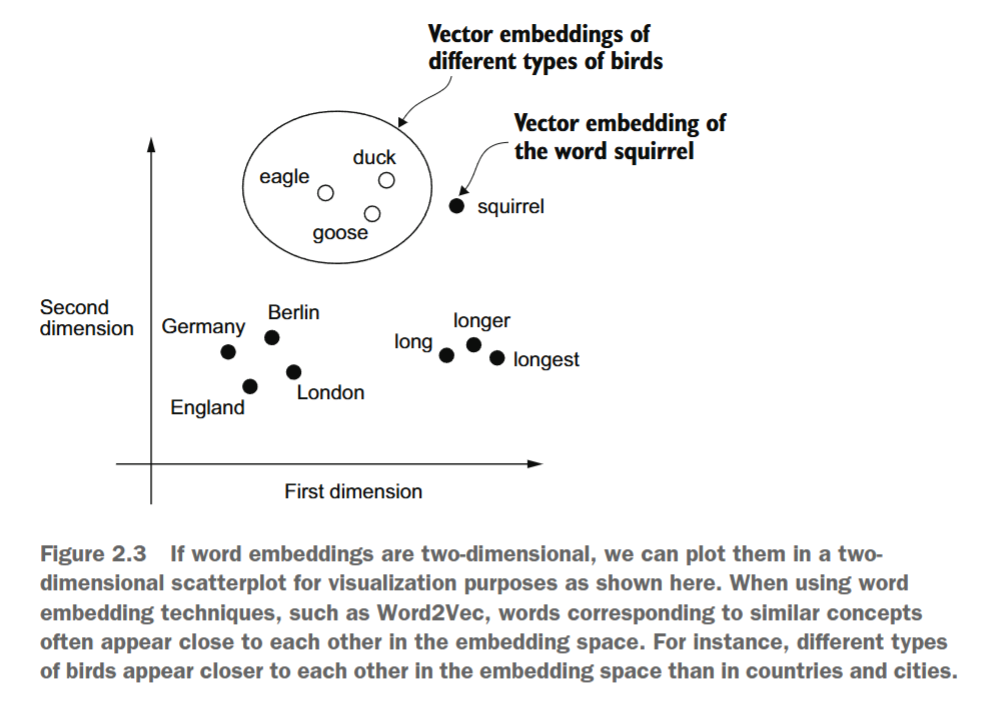
已经开发了多种算法和框架来生成词嵌入。早期且最流行的例子之一是Word2Vec方法。Word2Vec通过训练神经网络架构,在给定目标词的情况下预测其上下文(或反之)来生成词嵌入。Word2Vec的核心思想是:出现在相似上下文中的词往往具有相似的含义。因此,当将词嵌入投影到二维空间进行可视化时,相似的词会聚类在一起,如图2.3所示。
词嵌入可以有从一维到数千维不等的维度。更高的维度可能会捕捉到更细微的关系,但要以计算效率为代价。
虽然我们可以使用Word2Vec等预训练模型为机器学习模型生成嵌入,但大型语言模型(LLMs)通常会生成属于输入层的自有嵌入,并在训练过程中对其进行更新。 将嵌入作为LLM训练的一部分进行优化(而非使用Word2Vec)的优势在于,这些嵌入会针对当前的特定任务和数据进行优化。我们将在本章后面实现此类嵌入层。(正如我们将在第3章讨论的,LLMs还可以创建上下文相关的输出嵌入。)
遗憾的是,高维嵌入在可视化方面存在挑战,因为我们的感官感知和常见图形表示本质上局限于三维或更少维度,这就是图2.3在二维散点图中展示二维嵌入的原因。然而,在使用大型语言模型(LLMs)时,我们通常会使用维度高得多的嵌入。对于GPT-2和GPT-3而言,嵌入大小(通常称为模型隐藏状态的维度)因具体模型变体和规模而异,这是性能与效率之间的权衡。以具体示例来说,最小的GPT-2模型(1.17亿和1.25亿参数)使用768维的嵌入大小,而最大的GPT-3模型(1750亿参数)则使用12,288维的嵌入大小。
接下来,我们将逐步介绍为大型语言模型(LLM)准备嵌入所需的步骤,包括将文本拆分为单词、将单词转换为标记,以及将标记转换为嵌入向量。
2.2 Tokenizing text
我们来讨论如何将输入文本拆分为单个token,这是为大型语言模型(LLM)创建嵌入所需的预处理步骤。这些标记可以是单个单词或特殊字符(包括标点符号),如图2.4所示。
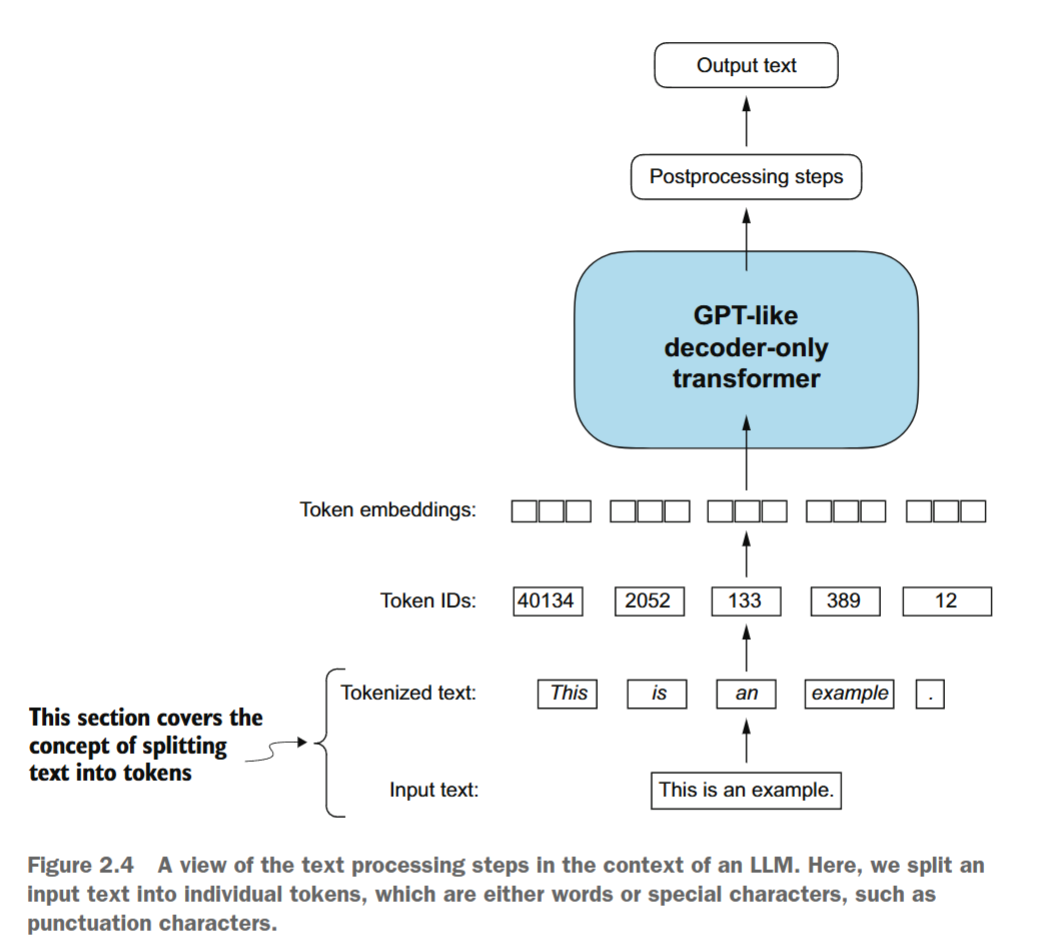
我们将用于大型语言模型(LLM)训练的标记化文本是伊迪丝·华顿(Edith Wharton)的短篇小说《裁决》(The Verdict),该作品已进入公共领域,因此可用于LLM训练任务。
https://github.com/rasbt/LLMs-from-scratch/tree/main 直接下载即可
我们的目标是将这个包含20,479个字符的短篇小说进行标记化处理,拆分为单个单词和特殊字符,然后将其转换为用于大型语言模型(LLM)训练的嵌入向量。
python
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
print(raw_text[:99])Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no
- The goal is to tokenize and embed this text for an LLM
- Let's develop a simple tokenizer based on some simple sample text that we can then later apply to the text above
- The following regular expression will split on whitespaces注意:在处理大型语言模型(LLMs)时,通常需要处理数百万篇文章和数十万本书籍------相当于数千GB的文本。然而,出于教学目的,使用较小的文本样本(如单本书籍)即可说明文本处理步骤背后的核心思想,并确保在消费级硬件上能够在合理时间内运行。
我们如何才能最好地分割这段文本以获得标记列表呢?为此,我们先稍作拓展,使用Python的正则表达式库re来进行说明。(你不必学习或记忆任何正则表达式语法,因为我们稍后会过渡到使用预构建的分词器。)
我们可以使用一些简单的示例文本,通过以下语法使用re.split命令按空白字符分割文本:
python
import re
text = "Hello, world. This, is a test."
result = re.split(r'(\s)', text)
print(result)'Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.'
插入一个讲解
正则表达式 re.split 中 r'(\s)' 的作用及解析
1. 正则表达式 r'(\s)' 的含义
-
r''(原始字符串):- 使用
r前缀表示这是一个原始字符串(raw string)。在原始字符串中,反斜杠\不作为转义字符处理,这有助于简化包含特殊字符的正则表达式的编写。例如,r'\n'表示两个字符:反斜杠\和字母n,而不是换行符。
- 使用
-
()(捕获组):- 括号用于定义一个捕获组。在正则表达式中,捕获组用于提取匹配到的特定部分。在
re.split中,使用捕获组会影响分割结果的行为。
- 括号用于定义一个捕获组。在正则表达式中,捕获组用于提取匹配到的特定部分。在
-
\s(空白字符):\s是一个元字符,匹配任何空白字符,包括空格(\t)、换行符(\n)、回车符(\r)等。- 在这个例子中,
\s匹配的是一个空格字符。
-
综合解释:
r'(\s)'的意思是匹配一个空白字符,并将其作为一个捕获组。这意味着匹配到的空白字符(即空格)会被单独提取出来,并在分割结果中保留。
2. re.split 中使用捕获组的行为
-
包含分隔符:
-
当你在
re.split的正则表达式中使用捕获组(即使用括号())时,匹配到的分隔符会被包含在返回的列表中。 -
示例 :
pythonimport re text = "Hello, world. This, is a test." result = re.split(r'(\s)', text) print(result)输出 :
['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']在这个例子中,分隔符(空格)被包含在结果列表中。
-
-
不包含分隔符:
-
如果不使用捕获组,即正则表达式中不包含括号
(),那么re.split会根据匹配到的分隔符进行分割,但不会将分隔符包含在结果列表中。 -
示例 :
pythonimport re text = "Hello, world. This, is a test." result = re.split(r'\s', text) print(result)输出 :
['Hello,', 'world.', 'This,', 'is', 'a', 'test.']在这个例子中,分隔符(空格)没有被包含在结果中。
-
这种简单的标记化方案大多能将示例文本分割为单个单词;然而,某些单词仍与标点符号连在一起,而我们希望将标点作为单独的列表项。此外,我们不将所有文本转换为小写,因为大小写有助于大型语言模型(LLMs)区分专有名词和普通名词、理解句子结构,并学习生成具有正确大小写的文本。
我们来修改正则表达式,使其按空白字符(\s)、逗号和句号(,.)进行分割:
python
result = re.split(r'([,.]|\s)', text)
print(result)'Hello', ',', '', ' ', 'world', '.', '', ' ', 'This', ',', '', ' ', 'is', ' ', 'a', ' ', 'test', '.', ''
剩下的一个小问题是,该列表中仍然包含空白字符。我们可以选择按如下方式安全地删除这些冗余字符:
python
# Strip whitespace from each item and then filter out any empty strings.
result = [item for item in result if item.strip()]
print(result)'Hello', ',', 'world', '.', 'This', ',', 'is', 'a', 'test', '.'
注意:在开发简单的分词器时,是否将空白字符编码为单独的字符或直接删除它们,取决于我们的应用及其需求。删除空白字符可减少内存和计算需求。然而,如果我们训练的模型对文本的精确结构敏感(例如对缩进和间距敏感的Python代码),保留空白字符可能会很有用。在这里,为了简化分词输出并使其更简洁,我们将删除空白字符。稍后,我们将切换到包含空白字符的分词方案。
我们在此设计的分词方案在简单的示例文本上效果良好。让我们进一步对其进行修改,使其能够处理其他类型的标点符号(如问号、引号和我们之前在伊迪丝·华顿短篇小说前100个字符中看到的双破折号)以及其他特殊字符:
python
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)'Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?'
正如我们从图2.5总结的结果中可以看到的,我们的分词方案现在能够成功处理文本中的各种特殊字符。
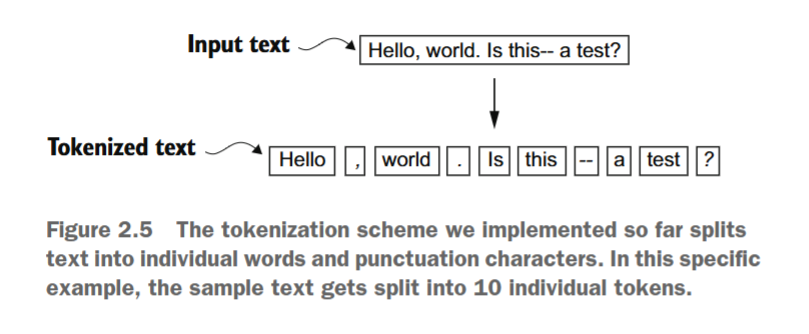
既然我们已经有了一个基本可用的分词器,现在让我们将其应用于伊迪丝·华顿的整篇短篇小说:
python
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(preprocessed[:30])'I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in'
2.3 Converting tokens into token IDs
接下来,我们将这些标记从Python字符串转换为整数表示形式,以生成标记ID。这种转换是将标记ID转换为嵌入向量之前的中间步骤。
要将之前生成的标记映射为标记ID,我们首先需要构建一个词汇表。如图2.6所示,该词汇表定义了如何将每个唯一的单词和特殊字符映射到一个唯一的整数。
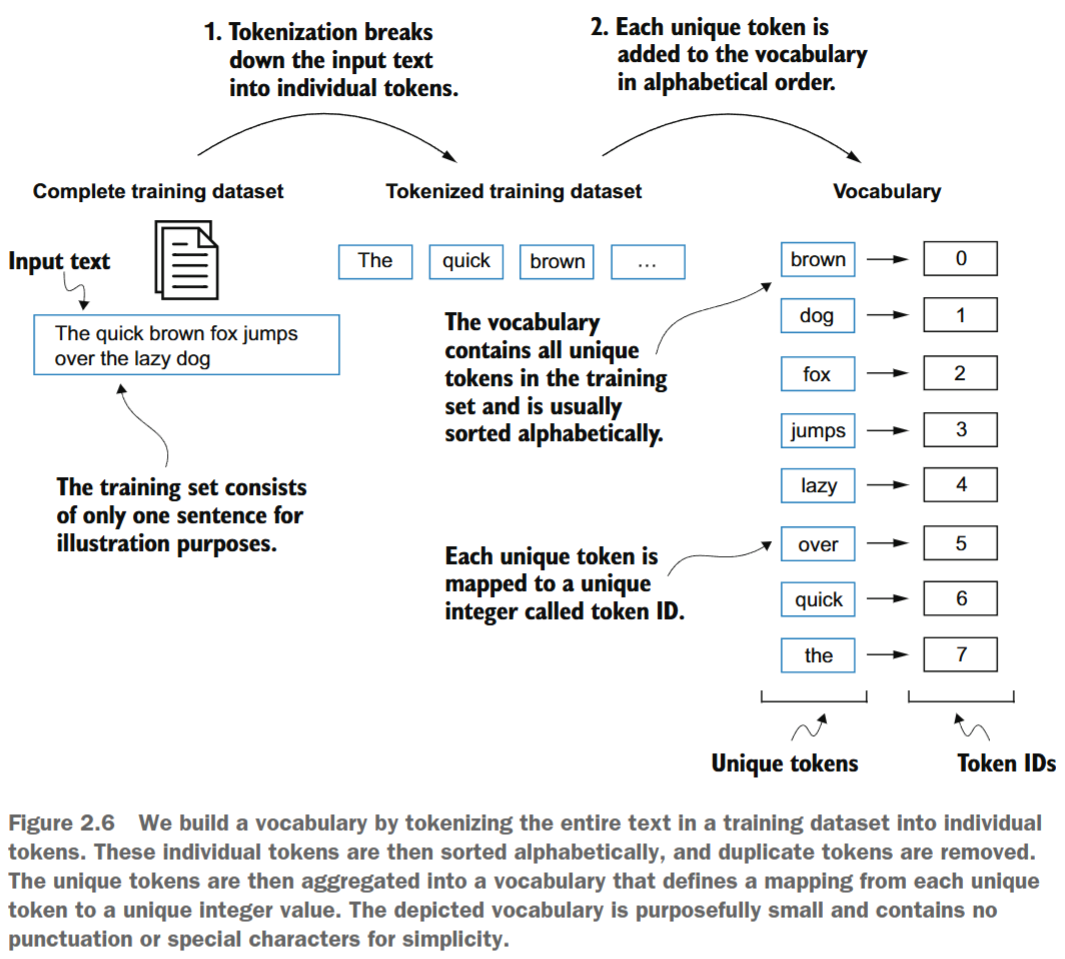
现在我们已经对伊迪丝·华顿的短篇小说进行了分词处理,并将其赋值给一个名为preprocessed的Python变量。接下来,我们需要创建一个包含所有唯一词元的列表,并按字母顺序对其进行排序,以确定词汇表的大小:
python
print(len(preprocessed))
all_words = sorted(set(preprocessed))
print(all_words[:20])
vocab_size = len(all_words)
print(vocab_size)4690
'!', '"', "'", '(', ')', ',', '--', '.', ':', ';', '?', 'A', 'Ah', 'Among', 'And', 'Are', 'Arrt', 'As', 'At', 'Be'
1130
通过此代码确定词汇表大小为1130后,我们创建该词汇表并打印其前51个条目用于说明。
python
vocab = {token:integer for integer,token in enumerate(all_words)}
for i, item in enumerate(vocab.items()):
print(item)
if i >= 50:
break('!', 0)
('"', 1)
("'", 2)
('(', 3)
(')', 4)
(',', 5)
('--', 6)
('.', 7)
(':', 8)
(';', 9)
('?', 10)
('A', 11)
('Ah', 12)
('Among', 13)
('And', 14)
('Are', 15)
('Arrt', 16)
('As', 17)
('At', 18)
('Be', 19)
('Begin', 20)
('Burlington', 21)
('But', 22)
('By', 23)
('Carlo', 24)
...
('Has', 47)
('He', 48)
('Her', 49)
('Hermia', 50)
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
如我们所见,该字典包含与唯一整数标签关联的单个标记。我们的下一个目标是应用此词汇表将新文本转换为标记ID(图2.7)。
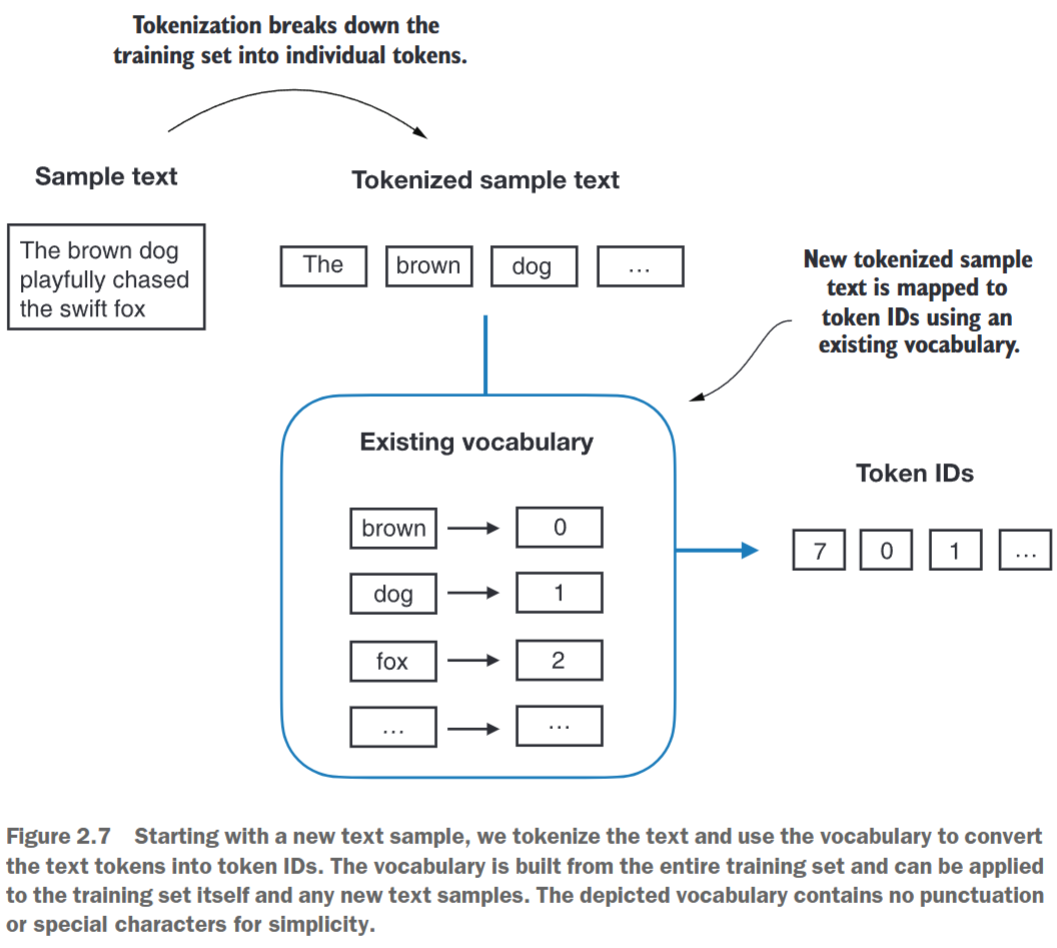
当我们希望将大型语言模型(LLM)的输出从数字转换回文本时,需要一种将标记ID转换为文本的方法。为此,我们可以创建词汇表的反向版本,将标记ID映射回对应的文本标记。
我们将在Python中实现一个完整的分词器类,该类包含一个encode方法,用于将文本拆分为标记,并通过词汇表执行字符串到整数的映射以生成标记ID。此外,我们还将实现一个decode方法,执行反向的整数到字符串的映射,将标记ID转换回文本。以下清单展示了此分词器实现的代码。

python
tokenizer = SimpleTokenizerV1(vocab)
text = """"It's the last he painted, you know,"
Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7
python
tokenizer.decode(ids)'" It' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.'
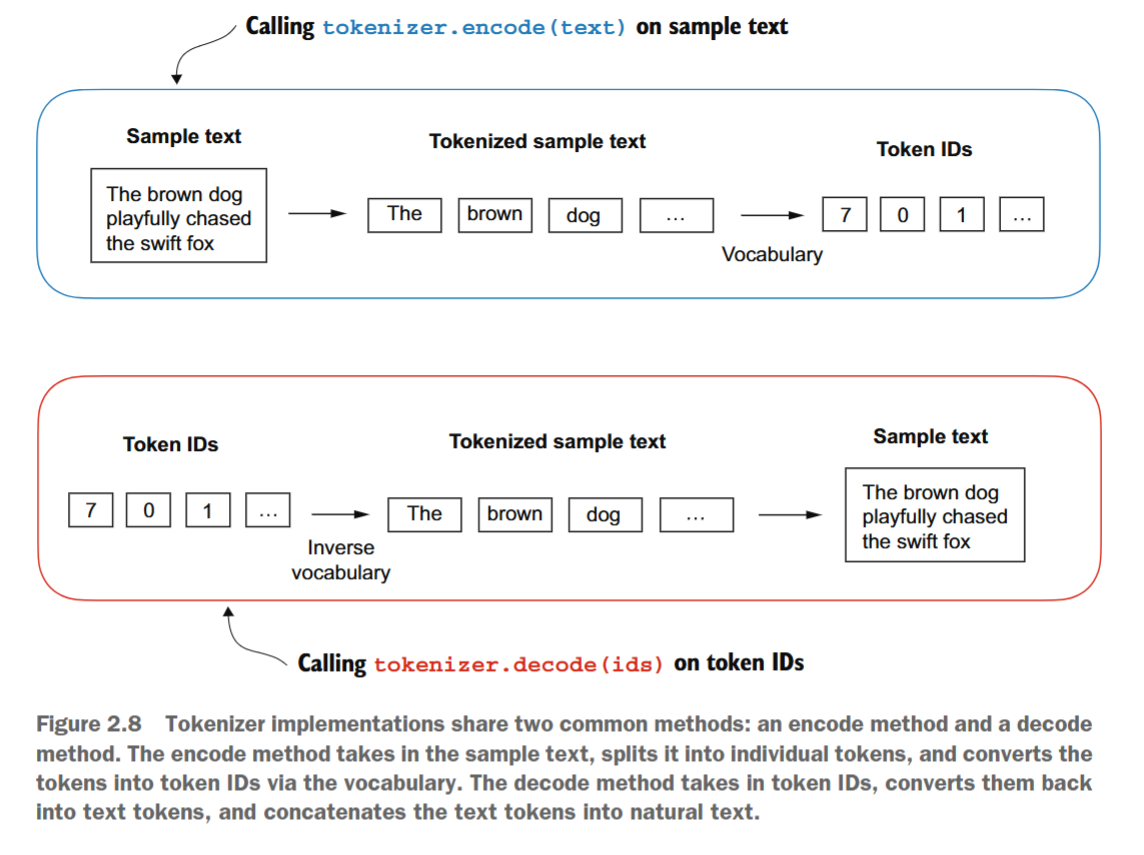
到目前为止,一切顺利。我们实现了一个分词器,能够根据训练集中的片段对文本进行分词和逆分词(将标记转换回文本)。现在,让我们将其应用于训练集中未包含的新文本样本:
问题在于,"Hello"这个词并未在短篇小说《裁决》(The Verdict)中使用过,因此它不存在于词汇表中。这凸显了在开发大型语言模型(LLMs)时,需要考虑使用大规模、多样化的训练集来扩展词汇表的必要性。
接下来,我们将在包含未知单词的文本上进一步测试分词器,并讨论可用于在训练期间为大型语言模型(LLM)提供更多上下文的额外特殊标记。
2.4 Adding special context tokens
我们需要修改分词器以处理未知单词,同时还需要解决特殊上下文标记的使用和添加问题,这些标记可增强模型对文本中上下文或其他相关信息的理解。例如,这些特殊标记可包括未知单词标记和文档边界标记。具体来说,我们将修改词汇表和分词器SimpleTokenizerV2,以支持两个新标记<|unk|>和<|endoftext|>,如图2.9所示。
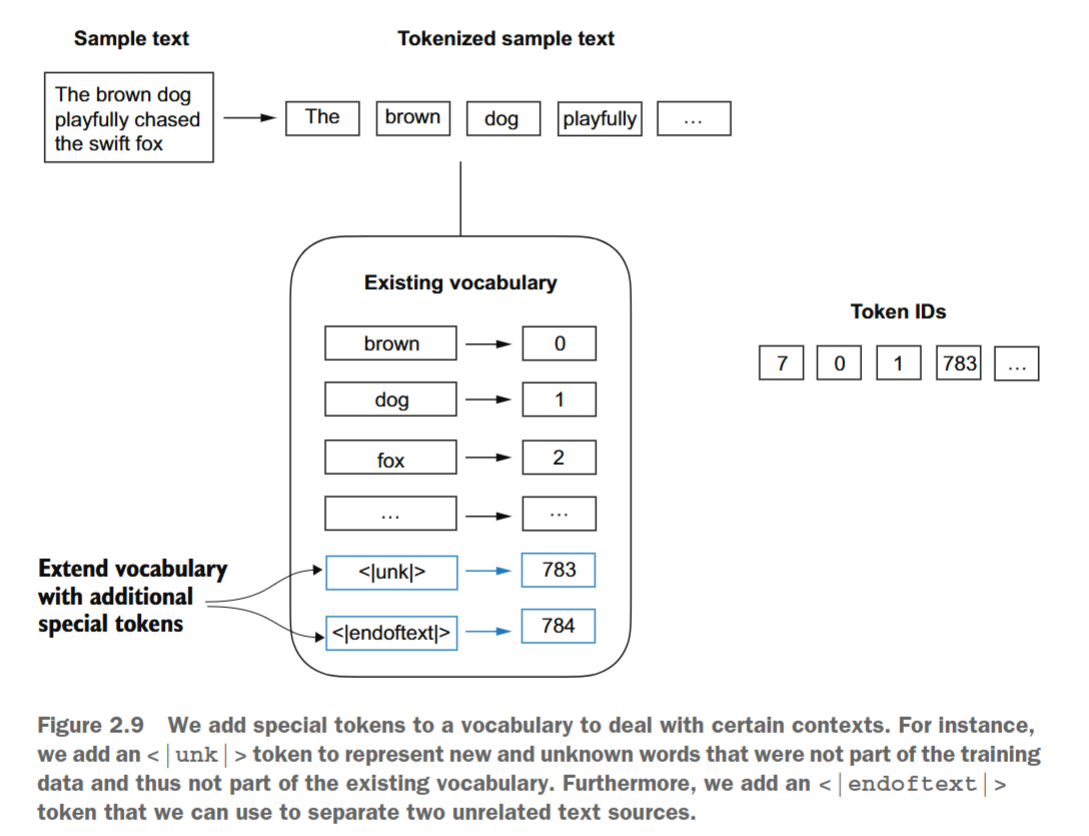
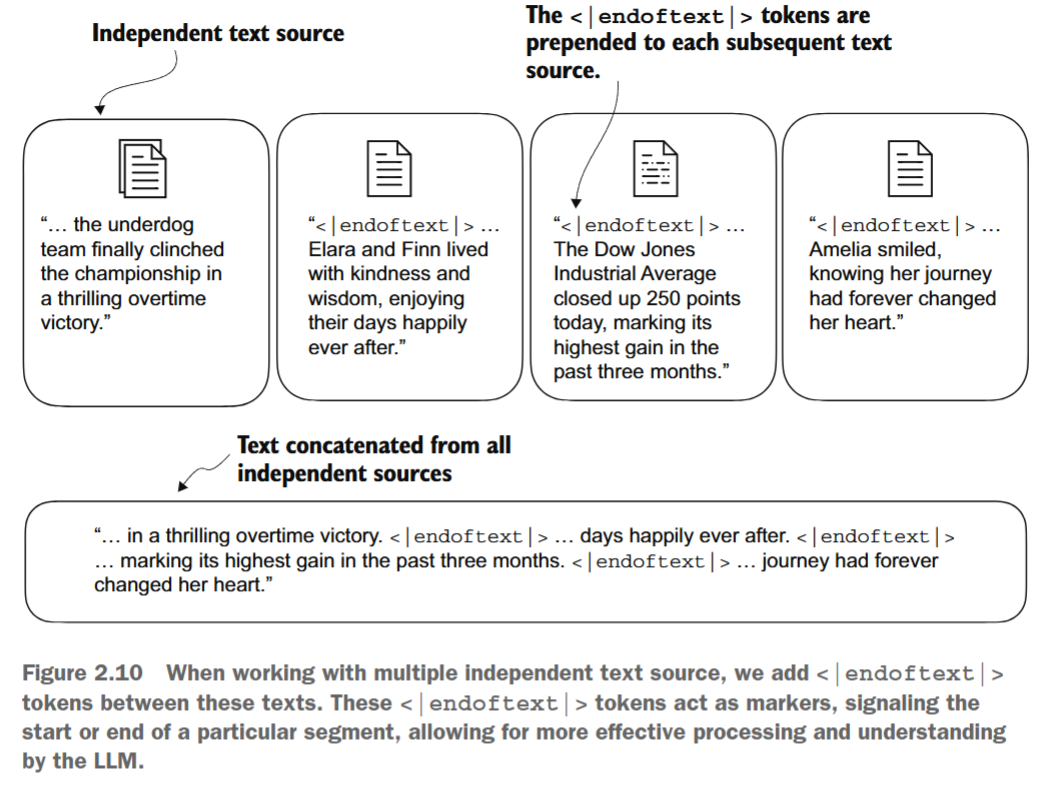
我们可以修改分词器,使其在遇到不属于词汇表的单词时使用<|unk|>标记。此外,我们还可以在不相关的文本之间添加一个标记。例如,在多个独立文档或书籍上训练类似GPT的大型语言模型(LLM)时,通常会在每个跟随前一个文本来源的文档或书籍前插入一个标记,如图2.10所示。这有助于LLM理解:尽管这些文本来源为了训练而被串联在一起,但它们实际上是不相关的。
现在,我们通过将这两个特殊标记和<|endoftext|>添加到所有唯一单词的列表中,来修改词汇表以包含它们:
python
all_tokens = sorted(list(set(preprocessed)))
all_tokens.extend(["<|endoftext|>", "<|unk|>"])
vocab = {token:integer for integer,token in enumerate(all_tokens)}
len(vocab.items())
for i, item in enumerate(list(vocab.items())[-5:]):
print(item)根据此打印语句的输出,新词汇表的大小为1132(之前的词汇表大小为1130)。作为额外的快速检查,我们打印更新后的词汇表的最后五个条目:
1132
('younger', 1127)
('your', 1128)
('yourself', 1129)
('<|endoftext|>', 1130)
('<|unk|>', 1131)
根据代码输出,我们可以确认这两个新的特殊标记确实已成功纳入词汇表。接下来,我们按如下清单所示对代码清单2.3中的分词器进行相应调整。
python
class SimpleTokenizerV2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = { i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
preprocessed = [
item if item in self.str_to_int
else "<|unk|>" for item in preprocessed
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)
return text现在让我们在实践中试用这个新的分词器。为此,我们将使用一个由两个独立且不相关的句子拼接而成的简单文本样本:
python
tokenizer = SimpleTokenizerV2(vocab)
text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))
print(text)
# Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace.
tokenizer.encode(text)
# [1131, 5, 355, 1126, 628, 975, 10, 1130, 55, 988, 956, 984, 722, 988, 1131, 7]
tokenizer.decode(tokenizer.encode(text))
# '<|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.'通过将此逆分词后的文本与原始输入文本进行比较,我们发现训练数据集(伊迪丝·华顿的短篇小说《裁决》)中不包含"Hello"和"palace"这两个单词。
根据不同的大型语言模型(LLM),部分研究者还会考虑使用以下额外特殊标记:
- BOS(序列开始)------该标记用于标记文本的开头,向LLM指示一段内容的起始位置。
- EOS(序列结束)------该标记位于文本末尾,尤其在拼接多个不相关文本时非常有用(类似<|endoftext|>)。例如,当合并两篇不同的维基百科文章或书籍时,EOS标记可指示前一段文本的结束和下一段的开始。
- PAD(填充)------当使用大于1的批量大小训练LLM时,批次中可能包含长度不同的文本。为确保所有文本长度一致,较短的文本会使用PAD标记进行扩展或"填充",直至达到批次中最长文本的长度。
GPT模型使用的分词器不需要上述任何标记;为简化起见,它仅使用<|endoftext|>标记。<|endoftext|>与EOS标记功能类似,也可用于填充。然而,如我们将在后续章节中探讨的,当对批量输入进行训练时,通常会使用掩码(mask),这意味着模型不会关注填充的标记。因此,选择何种特定标记进行填充变得无关紧要。
此外,GPT模型的分词器也不为未登录词(out-of-vocabulary words)使用<|unk|>标记。相反,GPT模型使用字节对编码(Byte Pair Encoding, BPE)分词器,该分词器将单词分解为子词单元,我们将在接下来的内容中讨论这一点。
2.5 Byte pair encoding
让我们来看一种基于字节对编码(BPE)概念的更复杂分词方案。BPE分词器曾被用于训练诸如GPT-2、GPT-3以及ChatGPT所使用的原始模型等大型语言模型。
由于实现字节对编码(BPE)可能相对复杂,我们将使用一个现有的Python开源库tiktoken(https://github.com/openai/tiktoken),它基于Rust源代码高效地实现了BPE算法。与其他Python库类似,我们可以通过终端使用Python的pip安装程序来安装tiktoken库:
python
import importlib
import tiktoken
print("tiktoken version:", importlib.metadata.version("tiktoken"))tiktoken version: 0.9.0
这个分词器的用法与我们之前通过encode方法实现的SimpleTokenizerV2类似:
python
tokenizer = tiktoken.get_encoding("gpt2")
text = (
"Hello, do you like tea? <|endoftext|> In the sunlit terraces"
"of someunknownPlace."
)
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 1659, 617, 34680, 27271, 13
python
strings = tokenizer.decode(integers)
print(strings)Hello, do you like tea? <|endoftext|> In the sunlit terracesof someunknownPlace.
基于标记ID和解码后的文本,我们可以得出两个值得注意的观察结果。首先,<|endoftext|>标记被分配了一个相对较大的标记ID,即50256。事实上,用于训练GPT-2、GPT-3以及ChatGPT原始模型等的BPE分词器,其词汇表总大小为50,257,其中<|endoftext|>被赋予了最大的标记ID。
其次,BPE分词器能够正确对未知单词(如someunknownPlace)进行编码和解码。BPE分词器可以处理任何未知单词,它是如何在不使用<|unk|>标记的情况下做到这一点的呢?
BPE的底层算法会将预定义词汇表中不存在的单词分解为更小的子词单元甚至单个字符,从而使其能够处理未登录词。因此,借助BPE算法,分词器在分词过程中遇到不熟悉的单词时,可以将其表示为一系列子词标记或字符,如图2.11所示。
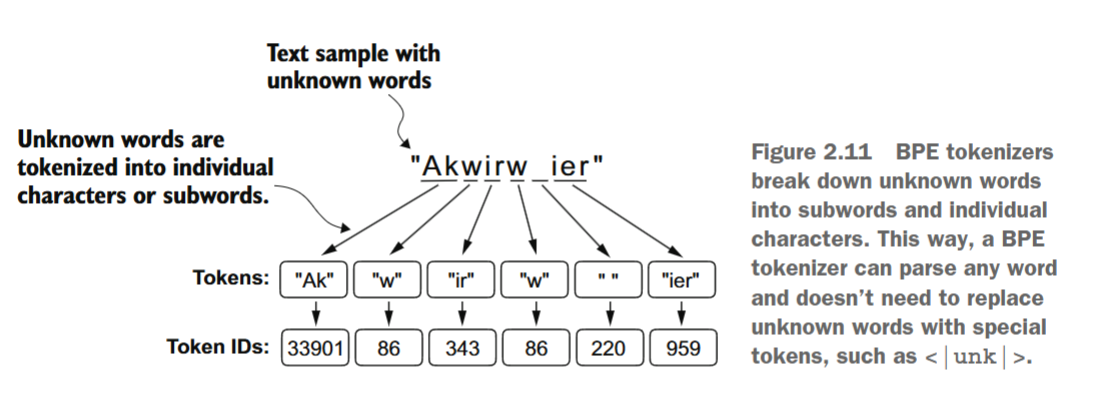
将未知单词分解为单个字符的能力确保了分词器(以及由此训练的大型语言模型)能够处理任何文本,即使其中包含训练数据中未出现的单词。
练习2.1 未知单词的字节对编码
使用tiktoken库中的BPE分词器对未知单词"Akwirw ier"进行处理,打印出各个标记的ID。然后,对该列表中的每个整数调用decode函数,重现图2.11所示的映射关系。最后,对标记ID调用decode方法,检查是否能重构原始输入"Akwirw ier"。
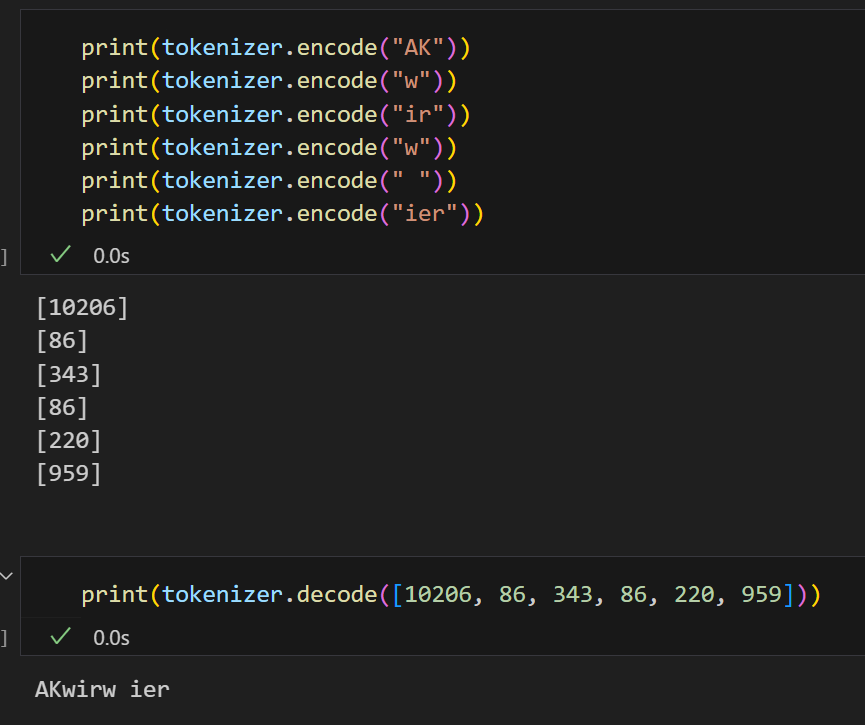
本书不打算详细讨论和实现字节对编码(BPE),但简而言之,它通过迭代地将高频字符合并为子词、再将高频子词合并为单词来构建词汇表。例如,BPE首先会将所有单个字符添加到词汇表中(如"a"、"b"等)。在下一阶段,它会将频繁共现的字符组合合并为子词。例如,"d"和"e"可能会合并为子词"de",这在许多英语单词中很常见。像"define"(定义)、"depend"(依赖)、"made"(制作)和"hidden"(隐藏)等单词中都有这种组合。这些合并操作由频率阈值决定。
我这里找到一个不错的视频作为补充:https://www.bilibili.com/video/BV1v9dSYLE6U/?spm_id_from=333.337.search-card.all.click\&vd_source=173edcc8f6052bd44ad224e1284119c3
图中,即视频中,定下了,找 3个 两个字母组成的组合。找到后算法就停止。

其实看本书就有个疑惑,这玩意中文该怎么办,毕竟语言上还是有较大差异的。这个up主的下个视频就有讲解:https://www.bilibili.com/video/BV1AYdiYpE65?spm_id_from=333.788.videopod.sections\&vd_source=173edcc8f6052bd44ad224e1284119c3
这个中文的问题就是,在推理的时候,3-4个字节的中文,可能会只输出两个字节。这样就会导致乱码(其实之前gpt的使用中就有出现),这种情况要么是增加中文预料来进行训练,这样就可以保证3-4个字节的强关联。或者就是碰到这种乱码进行舍弃。

2.6 Data sampling with a sliding window
为大型语言模型(LLM)创建嵌入的下一步是生成训练LLM所需的输入-目标对。这些输入-目标对是什么样的呢?正如我们已经了解的,LLM是通过预测文本中的下一个单词来进行预训练的,如图2.12所示。
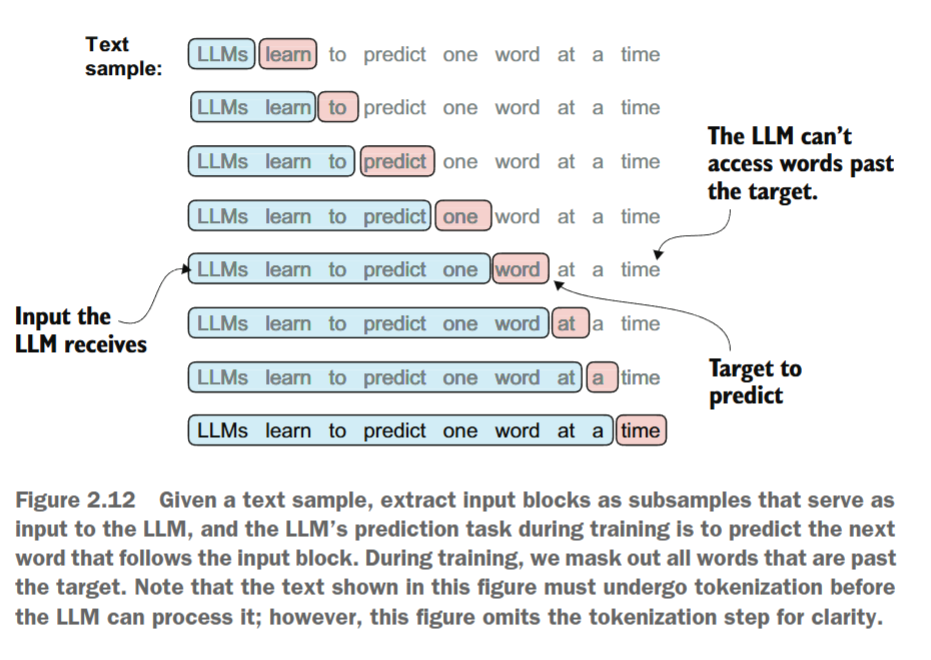
我们将实现一个数据加载器,使用滑动窗口方法从训练数据集中提取图2.12所示的输入-目标对。首先,我们将使用BPE分词器对整篇《裁决》短篇小说进行分词:
python
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
enc_text = tokenizer.encode(raw_text)
print(len(enc_text))5145
执行此代码将返回5145,即应用BPE分词器后训练集中的标记总数。
接下来,为了演示目的,我们从数据集中移除前50个标记,因为这会让后续步骤中的文本段落稍微更有趣一些:
python
enc_sample = enc_text[50:]为下一词预测任务创建输入-目标对的最简单、最直观的方法之一是创建两个变量x和y,其中x包含输入标记,y包含目标------即输入标记向右移动一位后的结果:
python
context_size = 4
x = enc_sample[:context_size]
y = enc_sample[1:context_size+1]
print(f"x: {x}")
print(f"y: {y}")
# x: [290, 4920, 2241, 287]
# y: [4920, 2241, 287, 257]通过处理输入以及作为输入右移一个位置的目标,我们可以创建下一词预测任务(见图2.12),如下所示:
python
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
print(context, "---->", desired)
[290] ----> 4920
[290, 4920] ----> 2241
[290, 4920, 2241] ----> 287
[290, 4920, 2241, 287] ----> 257这里提示下,python的切片操作,是左开右闭的。从索引0开始(包含索引0),到索引1结束(不包含索引1)
箭头(---->)左侧的所有内容均指LLM将接收的输入,箭头右侧的标记ID代表LLM需要预测的目标标记ID。我们重复之前的代码,但将标记ID转换为文本:
python
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
print(tokenizer.decode(context), "---->", tokenizer.decode([desired]))and ----> established
and established ----> himself
and established himself ----> in
and established himself in ----> a
我们现在已经创建了可用于大型语言模型(LLM)训练的输入-目标对。
在将标记转换为嵌入之前,我们还需完成最后一项任务:实现一个高效的数据加载器,使其能够遍历输入数据集并将输入和目标作为PyTorch张量(可将其视为多维数组)返回。具体而言,我们需要返回两个张量:一个是包含LLM输入文本的输入张量,另一个是包含LLM预测目标的目标张量,如图2.13所示。尽管该图为便于说明将标记以字符串格式呈现,但代码实现将直接操作标记ID,因为BPE分词器的encode方法会在单个步骤中同时完成分词和向标记ID的转换。

注意:为了实现高效的数据加载器,我们将使用PyTorch的内置Dataset和DataLoader类。有关安装PyTorch的更多信息和指导,请参阅附录A中的A.2.1.3节。
python
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
# Tokenize the entire text
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
assert len(token_ids) > max_length, "Number of tokenized inputs must at least be equal to max_length+1"
# Use a sliding window to chunk the book into overlapping sequences of max_length
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]插入一个stride对代码的影响
range(0, len(token_ids) - max_length, stride) 是用来控制滑动窗口的起始位置的。stride 参数决定了窗口每次滑动的步长,即每次窗口移动的 token 数量。
假设 token_ids 的长度是 10 (len(token_ids) = 10),max_length = 3,那么 len(token_ids) - max_length = 7。i 将从 0 开始,每次增加 stride 的值,直到 i + max_length 超过 len(token_ids)。
以下是一个简单的例子来解释 stride 的作用:
假设 token_ids = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9],max_length = 3,那么 len(token_ids) - max_length = 7。
-
stride=1:-
窗口的起始位置依次是 0, 1, 2, 3, 4, 5, 6。
-
对应的输入序列和目标序列如下:
i=0: input_chunk = [0, 1, 2] target_chunk = [1, 2, 3] i=1: input_chunk = [1, 2, 3] target_chunk = [2, 3, 4] i=2: input_chunk = [2, 3, 4] target_chunk = [3, 4, 5] i=3: input_chunk = [3, 4, 5] target_chunk = [4, 5, 6] i=4: input_chunk = [4, 5, 6] target_chunk = [5, 6, 7] i=5: input_chunk = [5, 6, 7] target_chunk = [6, 7, 8] i=6: input_chunk = [6, 7, 8] target_chunk = [7, 8, 9]
-
-
stride=2:-
窗口的起始位置依次是 0, 2, 4, 6。
-
对应的输入序列和目标序列如下:
i=0: input_chunk = [0, 1, 2] target_chunk = [1, 2, 3] i=2: input_chunk = [2, 3, 4] target_chunk = [3, 4, 5] i=4: input_chunk = [4, 5, 6] target_chunk = [5, 6, 7] i=6: input_chunk = [6, 7, 8] target_chunk = [7, 8, 9]
-
-
stride=3:-
窗口的起始位置依次是 0, 3, 6。
-
对应的输入序列和目标序列如下:
i=0: input_chunk = [0, 1, 2] target_chunk = [1, 2, 3] i=3: input_chunk = [3, 4, 5] target_chunk = [4, 5, 6] i=6: input_chunk = [6, 7, 8] target_chunk = [7, 8, 9]
-
总结来说,stride 决定了窗口每次滑动的步长。较小的 stride 会生成更多的重叠窗口,而较大的 stride 会减少窗口数量,窗口之间的重叠也更少。这种滑动窗口方法在处理序列数据(如文本、时间序列等)时非常有用,因为它允许模型在训练时看到数据的不同部分,并且可以通过调整 stride 来控制数据的重叠程度。
GPTDatasetV1类基于PyTorch的Dataset类,用于定义如何从数据集中获取单个数据行。其中,每行包含分配给输入块张量(input_chunk tensor)的若干标记ID(基于max_length参数),目标块张量(target_chunk tensor)则包含对应的目标。建议继续阅读下文,了解当我们将该数据集与PyTorch DataLoader结合使用时,从数据集中返回的数据形式------这将带来更直观清晰的理解。
注意:如果您对PyTorch Dataset类的结构(如清单2.5所示)不熟悉,请参考附录A中的A.6节,其中解释了PyTorch Dataset和DataLoader类的一般结构和用法。
以下代码使用GPTDatasetV1通过PyTorch的DataLoader按批次加载输入。
python
def create_dataloader_v1(txt, batch_size=4, max_length=256,
stride=128, shuffle=True, drop_last=True,
num_workers=0):
# Initialize the tokenizer
tokenizer = tiktoken.get_encoding("gpt2")
# Create dataset
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
# Create dataloader
# 创建数据加载器,用于批量加载数据
# 参数解释:
# dataset:数据集对象,要求必须实现__len__和__getitem__方法的python对象
# batch_size:每个batch的大小,默认为4
# shuffle:是否打乱数据,默认为True
# drop_last:如果数据集长度不能被batch_size整除,是否丢弃最后一个不完整的batch,默认为True
# num_workers:加载数据时使用的子进程数量,默认为0(主进程加载)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloader小插曲:这里简单讲一下batch_size
假设我们的数据集是 [1, 2, 3, 4, 5, 6, 7, 8],一共 8 个数据。
-
batch_size=2:-
数据会被分成 4 个批次。
-
每个批次包含 2 个数据。
-
输出的批次依次是:
[1, 2] [3, 4] [5, 6] [7, 8]
-
-
batch_size=3:-
数据会被分成 3 个批次。
-
前两个批次包含 3 个数据,最后一个批次包含 2 个数据。
-
输出的批次依次是:
[1, 2, 3] [4, 5, 6] [7, 8]
-
-
batch_size=3且drop_last=True:-
数据会被分成 2 个批次。
-
每个批次都包含 3 个数据。
-
最后一个不完整的批次(包含 2 个数据)会被丢弃。
-
输出的批次依次是:
[1, 2, 3] [4, 5, 6]
-
总结来说,batch_size 决定了每个批次有多少个数据,如果数据集的大小不能被 batch_size 整除,最后一个批次的数据量会少于 batch_size。如果设置 drop_last=True,则会丢弃这个不完整的批次。
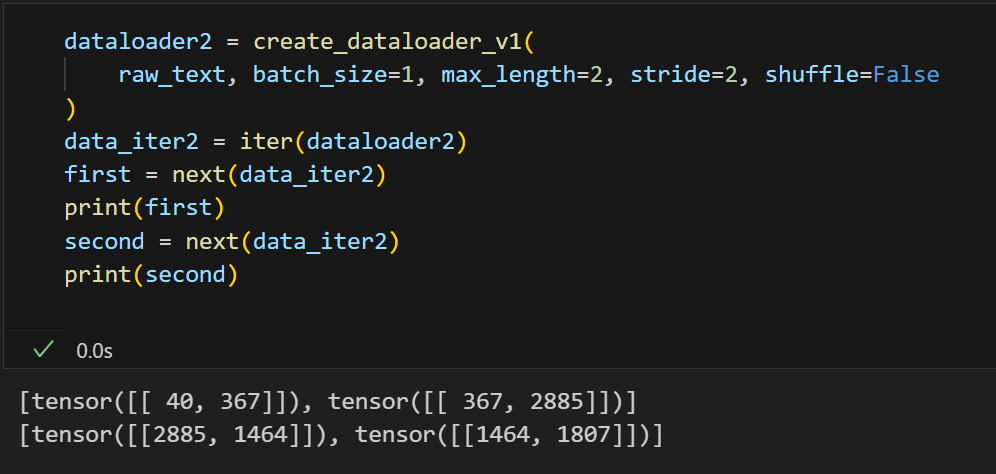
我们用批量大小为1、上下文大小为4的大型语言模型来测试数据加载器,以便直观理解清单2.5中的GPTDatasetV1类和清单2.6中的create_dataloader_v1函数如何协同工作:
python
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
dataloader = create_dataloader_v1(
raw_text, batch_size=1, max_length=4, stride=1, shuffle=False
)
# Converts dataloader into a Python iterator to fetch the next entry via
# Python's built-in next() function
data_iter = iter(dataloader)
first_batch = next(data_iter)
print(first_batch)
# [tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]
second_batch = next(data_iter)
print(second_batch)
# [tensor([[ 367, 2885, 1464, 1807]]), tensor([[2885, 1464, 1807, 3619]])]如果我们比较第一批和第二批数据,可以看到第二批的标记ID向右移动了一个位置(例如,第一批输入中的第二个ID是367,它是第二批输入中的第一个ID)。步长设置决定了各批次输入之间的移动位置数,这模拟了滑动窗口方法,如图2.14所示。

到目前为止,我们从数据加载器中采样的批量大小为1 (Batch sizes of ) 的情况适用于说明用途。如果您之前有深度学习的经验,可能知道小批量大小在训练期间需要的内存较少,但会导致模型更新的噪声更大。就像在常规深度学习中一样,批量大小是一种权衡,也是训练大型语言模型(LLMs)时需要进行实验的超参数。
我们简要来看一下如何使用数据加载器以大于1的批量大小进行采样:
python
dataloader = create_dataloader_v1(raw_text, batch_size=8, max_length=4, stride=4, shuffle=False)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Inputs:\n", inputs)
print("\nTargets:\n", targets)Inputs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Targets:
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])请注意,我们将步长增加到4以充分利用数据集(我们不会跳过任何一个单词)。这避免了批次之间的任何重叠,因为更多的重叠可能导致过拟合增加。
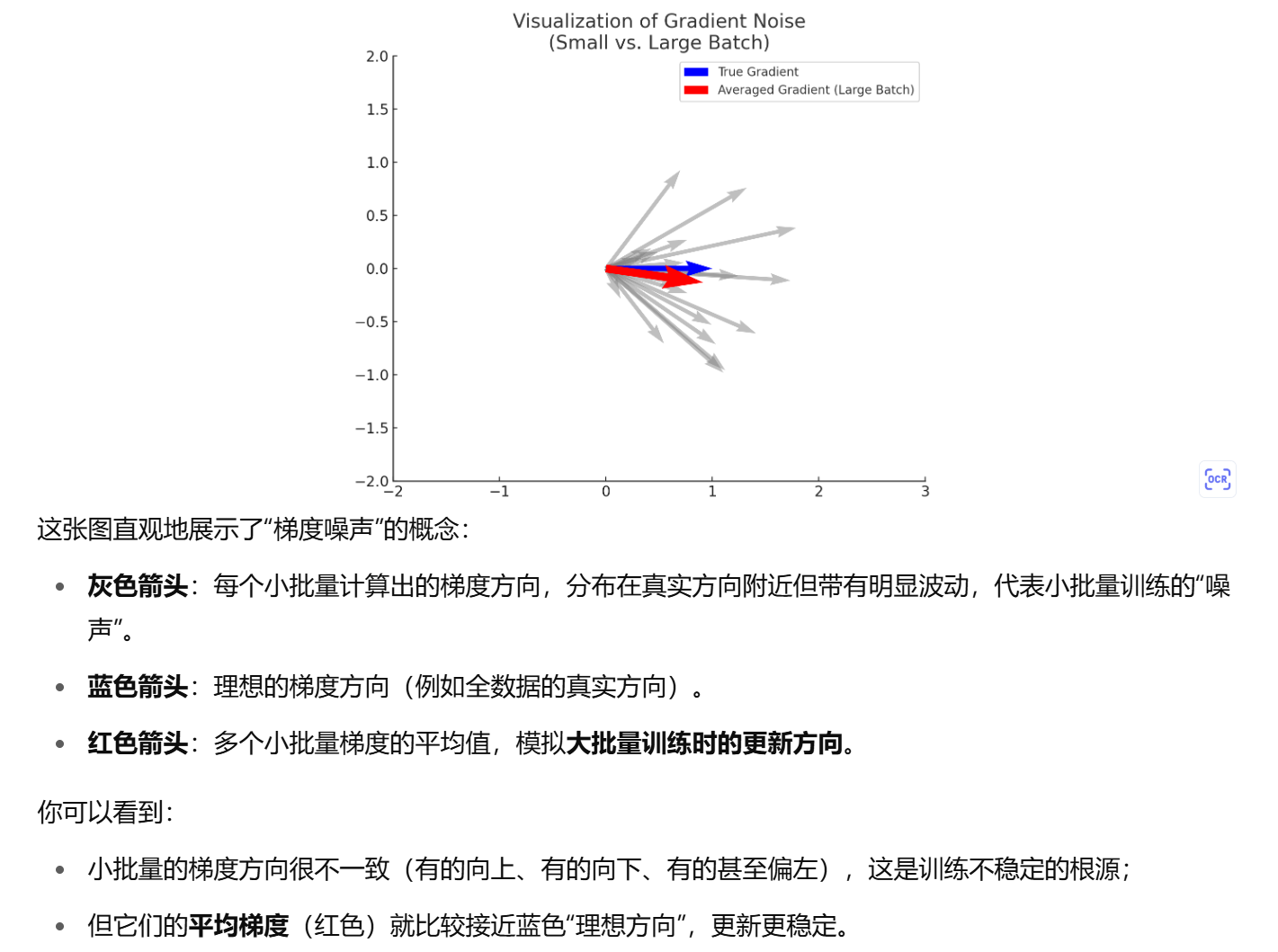
对小batch_size和大batch_size说下
小批量训练(如 batch size = 1)占用内存更小,但由于每次只基于单个样本更新参数,导致梯度噪声大、方向不稳定;而大批量训练内存开销更大,但能通过多个样本的平均梯度获得更稳定的更新方向。
 可是数学上,8个
可是数学上,8个 batch_size=1 ≈ 1个 batch_size=8?
没错:
- 假设你用
batch_size=1连续训练 8 步,每次根据一个样本计算梯度并更新参数; - 或者你用
batch_size=8一次性取 8 个样本,计算平均梯度后更新参数;
理论上:
如果优化器是纯 SGD(无动量、无自适应学习率等),在同样的数据、同样的初始参数下,多次
batch_size=1更新的期望 ≈ 一次batch_size=8更新的结果。
但是为什么实际训练行为不一样?
虽然数学期望一样,但训练路径和模型收敛行为往往不同,主要有这些原因:
- 每一步都在更新参数,路径发生变化
-
batch_size=1:- 每来一个样本就更新一次模型参数。
- 参数会逐步偏离原点,所以每个后续样本是在一个已改变的模型状态下参与训练。
- 换句话说,更新顺序会对训练路径产生影响(非交换性)。
-
batch_size=8:- 所有8个样本计算完再更新一次参数。
- 梯度是一次性平均后再更新,对前7个样本来说参数还是初始状态,对8个样本是"同步平等"的。
🔎 结论 :虽然结果期望相同,但训练过程路径是不同的。这也是为什么 batch_size=1 容易跳出局部最优,大批量更稳定但有时会卡住。
- 优化器行为不同(尤其是 Adam, RMSProp)
如果你使用的是现代优化器(如 Adam),这些优化器会根据过去的梯度历史统计量调整每个参数的学习率(如动量、方差等),那么:
batch_size=1每次更新,优化器内部状态也在变,统计量波动更大。batch_size=8每次只有一次更新,优化器状态更新频率更低,也更稳定。
- 正则化和 BatchNorm 等机制也会受到影响
例如:
- Dropout、BatchNorm、LayerNorm 等机制在小批量时行为不同(尤其是 batchnorm 对 batch 统计量很敏感);
- 训练动态不同会影响模型泛化性能。
一个例子讲解:





2.7 Creating token embeddings
为大型语言模型(LLM)训练准备输入文本的最后一步是将标记ID转换为嵌入向量,如图2.15所示。作为初步步骤,我们对这些嵌入权重必须使用用随机值进行初始化。这种初始化操作作为大型语言模型(LLM)学习过程的起点。在第5章中,我们将把嵌入权重的优化作为LLM训练的一部分。
由于类似GPT的大型语言模型(LLMs)是通过反向传播算法训练的深度神经网络,因此需要连续的向量表示(即嵌入)。
注意:如果您不熟悉神经网络如何通过反向传播进行训练,请阅读附录A中的B.4节。
让我们通过一个实际示例来了解标记ID到嵌入向量的转换是如何工作的。假设我们有以下四个输入标记,其ID分别为2、3、5和1。
为简单起见,假设我们只有一个仅包含6个单词的小词汇表(而非BPE分词器词汇表中的50,257个单词),并且我们希望创建大小为3的嵌入向量(在GPT-3中,嵌入维度为12,288)
使用vocab_size(词汇表大小)和output_dim(输出维度),我们可以在PyTorch中实例化一个嵌入层。为确保可复现性,将随机种子设置为123
python
input_ids = torch.tensor([2, 3, 5, 1])
vocab_size = 6
output_dim = 3
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)打印语句会输出嵌入层的底层权重矩阵:
python
print(embedding_layer.weight)Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)嵌入层的权重矩阵包含较小的随机值。这些值在LLM训练期间会作为LLM优化过程的一部分进行优化。此外,我们可以看到该权重矩阵有6行3列------词汇表中6个可能的标记各对应一行,3个嵌入维度各对应一列。
现在,让我们将其应用于一个标记(token)ID以获取嵌入向量:
python
print(embedding_layer(torch.tensor([3])))
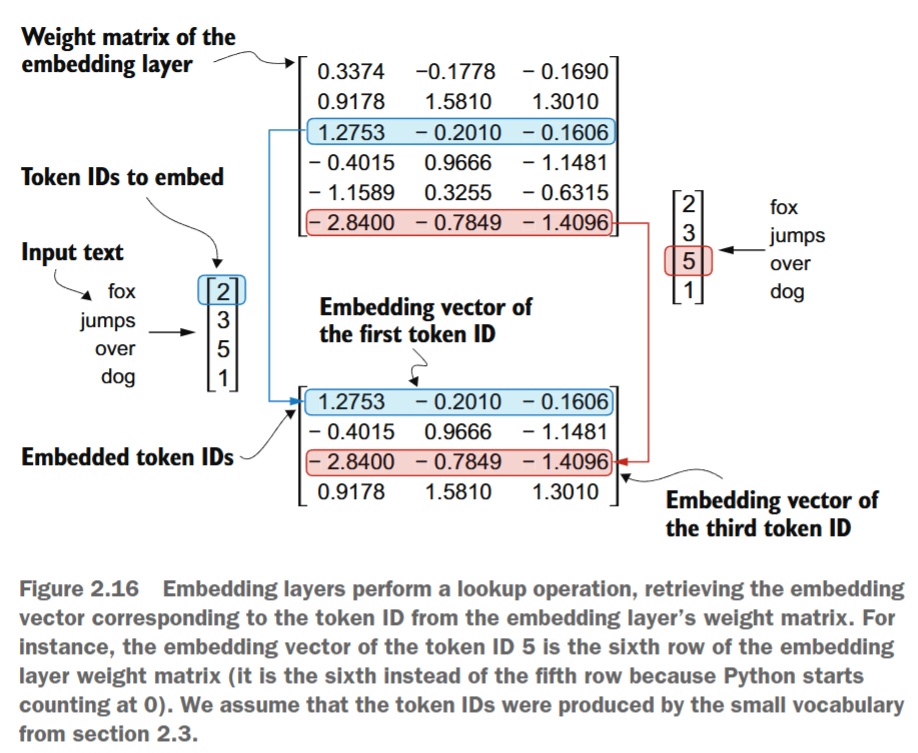
# tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)如果我们将标记ID为3的嵌入向量与之前的嵌入矩阵进行比较,会发现它与第四行完全一致(Python从0开始索引,因此对应索引为3的行)。换句话说,嵌入层本质上是一种查找操作,通过标记ID从嵌入层的权重矩阵中检索对应的行。
注意:对于熟悉独热编码(one-hot encoding)的读者,这里描述的嵌入层方法本质上是一种更高效的实现方式,相当于先进行独热编码,再在全连接层中执行矩阵乘法------GitHub上的补充代码(https://mng.bz/ZEB5)演示了这一点。由于嵌入层是等效于独热编码和矩阵乘法方法的更高效实现,因此它可以被视为一个可通过反向传播优化的神经网络层。
我们已经了解了如何将单个标记ID转换为三维嵌入向量。现在,我们将其应用于所有四个输入ID(torch.tensor(2, 3, 5, 1)):
python
print(embedding_layer(input_ids))tensor([[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-2.8400, -0.7849, -1.4096],
[ 0.9178, 1.5810, 1.3010]], grad_fn=<EmbeddingBackward0>)此输出矩阵中的每一行均通过从嵌入权重矩阵中执行查找操作获得,如图2.16所示。
现在我们已经从标记ID创建了嵌入向量,接下来我们将对这些嵌入向量进行一点小修改,以编码文本中标记的位置信息。
2.8 Encoding word positions
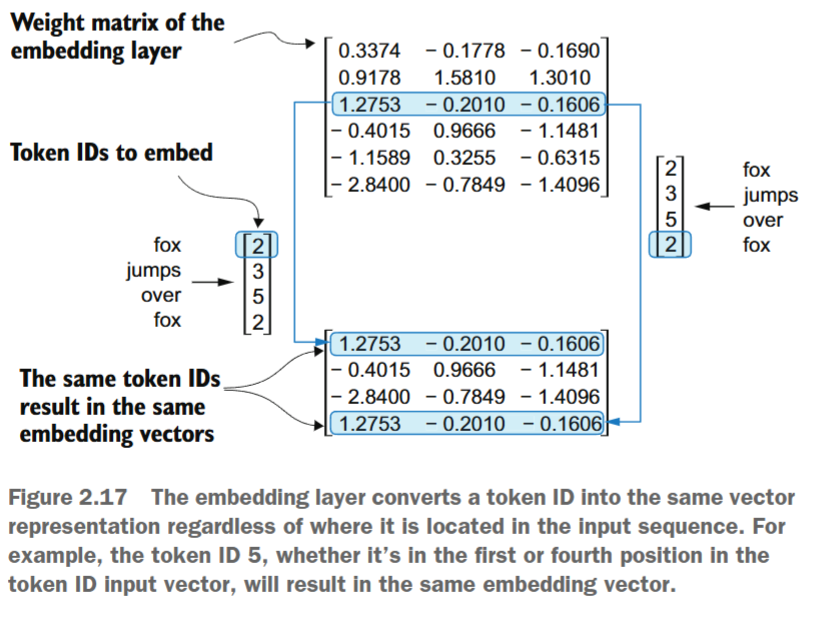
原则上, token embeddings是大型语言模型(LLM)的合适输入。然而,LLM的一个小缺点在于其自注意力机制(参见第3章)无法感知序列中标记的位置或顺序。前面介绍的嵌入层的工作方式是:同一个标记ID始终会被映射到相同的向量表示,无论该标记ID在输入序列中的位置如何,如图2.17所示。
原则上,标记ID这种确定性的、与位置无关的嵌入方式有利于可复现性。然而,由于大型语言模型(LLMs)的自注意力机制本身也不感知位置,因此向模型中注入额外的位置信息会有所帮助。
为实现这一点,我们可以使用两大类位置感知嵌入:相对位置嵌入 和绝对位置嵌入 。
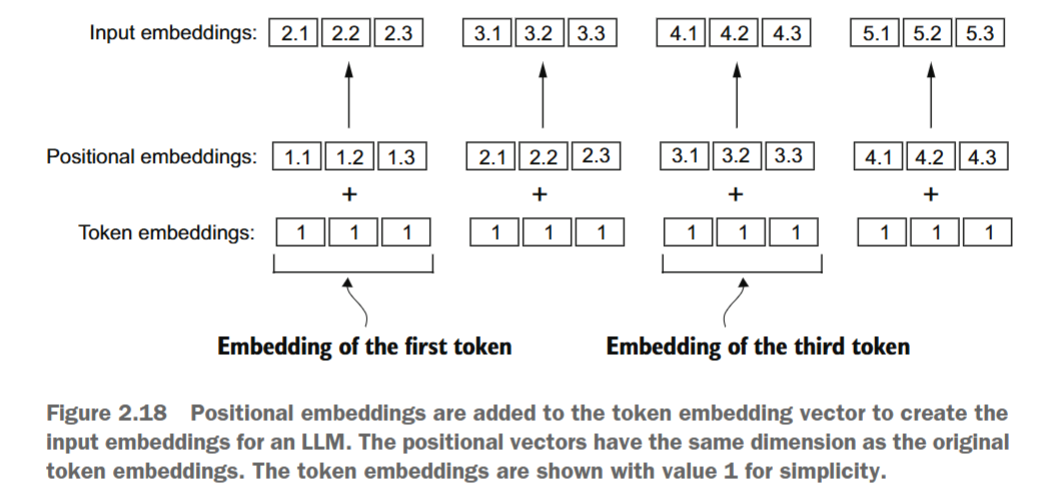
绝对位置嵌入直接与序列中的特定位置相关联。对于输入序列中的每个位置,会将一个唯一的嵌入添加到标记的嵌入中,以传达其确切位置。例如,第一个标记将具有特定的位置嵌入,第二个标记则具有另一个不同的嵌入,依此类推,如图2.18所示。
相对位置嵌入不关注标记的绝对位置,而是强调标记之间的相对位置或距离。这意味着模型学习的是"相隔多远"的关系,而非"具体处于哪个位置"。这种方式的优势在于,模型能够更好地泛化到不同长度的序列,即使是在训练中未见过的序列长度也能处理。
这两种位置嵌入的目的均是增强大型语言模型(LLMs)理解标记顺序和标记间关系的能力,从而确保更准确且具备上下文感知的预测。具体选择哪种位置嵌入方式,通常取决于特定的应用场景以及所处理数据的性质。
OpenAI的GPT模型使用绝对位置嵌入,这些嵌入是在训练过程中优化的,而非像原始Transformer模型中的位置编码那样固定或预定义。这一优化过程本身就是模型训练的一部分。现在,让我们创建初始位置嵌入以生成LLM的输入。
之前,为简单起见,我们聚焦于非常小的嵌入维度。现在,让我们考虑更实际且有用的嵌入维度,并将输入标记编码为256维的向量表示------这一维度小于原始GPT-3模型使用的维度(GPT-3中嵌入维度为12,288维),但对于实验来说仍然合理。此外,我们假设标记ID由我们之前实现的BPE分词器生成,其词汇表大小为50,257。
使用之前的标记嵌入层,如果我们从数据加载器中采样数据,会将每个批次中的每个标记嵌入为256维向量。如果批次大小为8(每个批次包含4个标记),结果将是一个8×4×256的张量。
我们先实例化数据加载器(参见2.6节):
python
vocab_size = 50257
output_dim = 256
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
max_length = 4
dataloader = create_dataloader_v1(
raw_text, batch_size=8, max_length=max_length,
stride=max_length, shuffle=False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Token IDs:\n", inputs)
print("\nInputs shape:\n", inputs.shape)Token IDs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Inputs shape:
torch.Size([8, 4])如我们所见,标记ID张量的维度为8×4,这意味着该数据批次包含8个文本样本,每个样本包含4个tokens
现在,我们使用嵌入层将这些token ID嵌入到256维向量中:
python
token_embeddings = token_embedding_layer(inputs)
print(token_embeddings.shape)
# uncomment & execute the following line to see how the embeddings look like
print(token_embeddings)torch.Size([8, 4, 256])
tensor([[[-0.3502, 0.2929, 0.9399, ..., -0.3335, 0.3599, -0.0525],
[-0.6917, 0.9379, 0.7913, ..., 1.0943, -0.0062, 1.7465],
[-0.8869, 0.9105, 1.2541, ..., 2.4367, -1.2882, -0.1280],
[-1.1652, 0.6081, -0.5275, ..., -0.5973, -0.7267, -0.5256]],
[[-0.7816, -0.4353, 0.5408, ..., 0.3087, 1.4998, -0.0660],
[ 1.2882, 1.4097, -0.0149, ..., 0.0225, -1.0610, 0.8812],
[-0.6565, -0.5853, -1.6767, ..., 0.3505, 0.4995, -0.6959],
[-0.3452, 0.8022, -0.5857, ..., 1.0069, -0.1275, 0.0197]],
[[ 0.3287, 0.2834, 0.2337, ..., -1.3443, -0.1275, -1.2106],
[ 1.0985, -0.2017, 0.2577, ..., -0.2373, 1.0872, 0.3803],
[ 1.2486, -1.1019, -0.6073, ..., 0.3542, 1.5883, 2.1269],
[-0.9754, 0.9887, 0.9275, ..., -0.5114, 0.1950, -2.2691]],
...,
[[ 0.2655, -0.0639, 0.4732, ..., 1.0692, -1.8653, 0.7222],
[-1.5919, 1.0667, 0.2686, ..., -0.0277, -0.7372, -0.0901],
[-0.9764, -0.5006, 0.3353, ..., 0.8471, -0.0928, 1.2547],
[-0.0997, 1.7160, 0.3318, ..., -0.5211, 0.6449, 2.9187]],
[[ 0.2459, 0.5796, -0.5931, ..., -1.1949, -0.0422, 0.0267],
[-0.8778, -2.1186, -1.6405, ..., 0.0159, -0.7301, -0.2694],
...
[-2.4941, 0.0871, 0.9936, ..., 2.4681, -0.8427, -1.0882],
[-1.2021, 0.0664, -0.8492, ..., 0.5843, -1.8557, 1.9824],
[-0.8489, -0.0110, 0.5707, ..., -0.9871, -0.8531, 0.1625]]],
grad_fn=<EmbeddingBackward0>)
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...对于GPT模型的绝对位置嵌入方法,我们只需创建另一个与token_embedding_layer具有相同嵌入维度的嵌入层:
python
context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
# uncomment & execute the following line to see how the embedding layer weights look like
print(pos_embedding_layer.weight)Parameter containing:
tensor([[-0.7497, -0.8066, -0.9359, ..., -0.1787, -0.3815, -2.1684],
[ 0.2493, -1.6384, 0.9950, ..., 1.0164, -0.3670, -0.7973],
[-2.2207, -0.2814, -0.6703, ..., -1.2844, 1.7460, 1.5246],
[-0.9561, -1.2158, -0.0514, ..., 0.3257, 1.9410, -1.8463]],
requires_grad=True)
python
pos_embeddings = pos_embedding_layer(torch.arange(max_length))
print(pos_embeddings.shape)
# uncomment & execute the following line to see how the embeddings look like
print(pos_embeddings)torch.Size([4, 256])
tensor([[-0.7497, -0.8066, -0.9359, ..., -0.1787, -0.3815, -2.1684],
[ 0.2493, -1.6384, 0.9950, ..., 1.0164, -0.3670, -0.7973],
[-2.2207, -0.2814, -0.6703, ..., -1.2844, 1.7460, 1.5246],
[-0.9561, -1.2158, -0.0514, ..., 0.3257, 1.9410, -1.8463]],
grad_fn=<EmbeddingBackward0>)位置嵌入的输入通常是一个占位符向量torch.arange(context_length),其中包含从0、1......一直到最大输入长度减1的数字序列。context_length是一个变量,表示大型语言模型(LLM)支持的输入尺寸。在这里,我们将其设定为与输入文本的最大长度相近。在实际应用中,输入文本可能超过支持的上下文长度,此时我们必须对文本进行截断。
如我们所见,位置嵌入张量由四个256维向量组成。现在我们可以将这些向量直接添加到标记嵌入中,其中PyTorch会将4×256维的位置嵌入张量添加到八个批次中每个4×256维的标记嵌入张量上:
python
input_embeddings = token_embeddings + pos_embeddings
print(input_embeddings.shape)
# uncomment & execute the following line to see how the embeddings look like
print(input_embeddings)torch.Size([8, 4, 256])
tensor([[[-1.0999e+00, -5.1374e-01, 4.0256e-03, ..., -5.1217e-01,
-2.1650e-02, -2.2209e+00],
[-4.4246e-01, -7.0057e-01, 1.7863e+00, ..., 2.1107e+00,
-3.7322e-01, 9.4920e-01],
[-3.1076e+00, 6.2915e-01, 5.8382e-01, ..., 1.1523e+00,
4.5783e-01, 1.3966e+00],
[-2.1213e+00, -6.0774e-01, -5.7887e-01, ..., -2.7164e-01,
1.2143e+00, -2.3719e+00]],
[[-1.5313e+00, -1.2419e+00, -3.9502e-01, ..., 1.2997e-01,
1.1183e+00, -2.2343e+00],
[ 1.5375e+00, -2.2874e-01, 9.8011e-01, ..., 1.0389e+00,
-1.4281e+00, 8.3904e-02],
[-2.8773e+00, -8.6666e-01, -2.3471e+00, ..., -9.3387e-01,
2.2456e+00, 8.2869e-01],
[-1.3013e+00, -4.1366e-01, -6.3708e-01, ..., 1.3326e+00,
1.8136e+00, -1.8265e+00]],
[[-4.2098e-01, -5.2328e-01, -7.0215e-01, ..., -1.5230e+00,
-5.0904e-01, -3.3790e+00],
[ 1.3477e+00, -1.8401e+00, 1.2527e+00, ..., 7.7904e-01,
7.2017e-01, -4.1694e-01],
[-9.7210e-01, -1.3832e+00, -1.2776e+00, ..., -9.3016e-01,
3.3343e+00, 3.6515e+00],
...
[-3.4228e+00, -2.1500e-01, -1.5196e+00, ..., -7.0003e-01,
-1.0968e-01, 3.5070e+00],
[-1.8050e+00, -1.2268e+00, 5.1931e-01, ..., -6.6141e-01,
1.0879e+00, -1.6838e+00]]], grad_fn=<AddBackward0>)
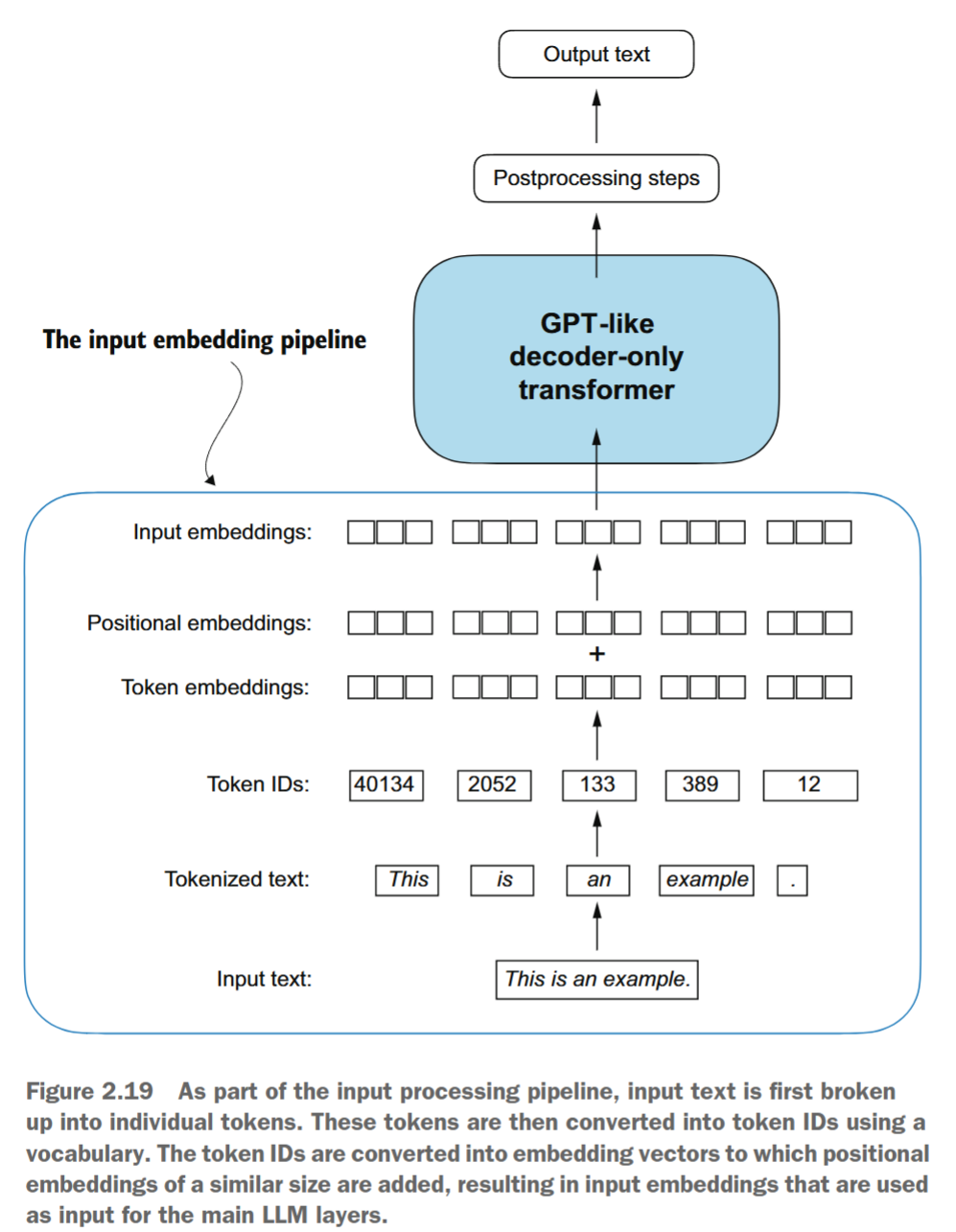
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...如图2.19所示,我们创建的 input_embeddings 是已嵌入的输入示例,可以由大型语言模型(LLM)的主要模块进行处理------我们将在下一章开始实现这些模块。
疑问
1. 位置嵌入层 pos_embedding_layer = torch.nn.Embedding(context_length, output_dim) 是做什么的?
这句代码创建了一个 位置嵌入(Positional Embedding)层,它的目的是为输入序列的每个"位置"生成一个向量表示。
参数说明:
python
torch.nn.Embedding(num_embeddings, embedding_dim)num_embeddings:词表大小(或者位置数量)。这里是context_length,即序列最大长度,比如 4。embedding_dim:每个位置对应的向量维度,也就是模型处理 token 的向量维度。这里是output_dim = 256。
如果你设置:
python
context_length = 4
output_dim = 256
pos_embedding_layer = torch.nn.Embedding(4, 256)那么你就创建了一个矩阵(Embedding table)大小为 [4, 256]。表示有 4 个位置,每个位置都有一个 256 维的向量。
这些向量是 可学习的参数,模型会在训练过程中调整它们。
2. 调用嵌入层 pos_embeddings = pos_embedding_layer(torch.arange(max_length)) 是做什么的?
这一行是把输入的 位置索引 映射为位置向量(embedding):
分解说明:
python
torch.arange(max_length) # 生成 [0, 1, 2, ..., max_length-1]假设 max_length = 4,那么你得到:
python
tensor([0, 1, 2, 3])这是一个位置索引向量(位置编号)。
然后你把这个输入喂给嵌入层:
python
pos_embedding_layer(tensor([0, 1, 2, 3]))就会输出一个形状为 [4, 256] 的张量,每一行都是对应位置的向量。
非常棒的问题!我们来详细讲解你提到的关键点:
3. pos_embedding_layer(tensor([0, 1, 2, 3])) 为什么会返回形状为 [4, 256]?这256维的数据是怎么来的?
答案简洁版:
- 是的,最初的 256 维向量是随机初始化的;
- 但这些向量是 模型的可学习参数,会随着训练过程被优化。
- 初始化权重本身就是 Embedding 层最初的值
✅ 第一步:理解 torch.nn.Embedding
python
pos_embedding_layer = torch.nn.Embedding(num_embeddings=4, embedding_dim=256)这创建了一个"嵌入表":
- 有 4 行,表示 4 个位置(0, 1, 2, 3);
- 每行是一个 256 维向量;
- 所以这是一个 4, 256 的矩阵,也可以叫做查找表或权重矩阵。
PyTorch 会自动初始化这个矩阵中的权重,默认使用的方法是:
Xavier/Glorot Uniform 分布(或者其他类似的方法),也就是随机初始化的浮点数。
✅ 第二步:你调用 pos_embedding_layer(tensor([0, 1, 2, 3])) 做了什么?
这是在"查表":
- 传入的
[0, 1, 2, 3]是位置索引; - 它会从刚才的
[4, 256]的矩阵中,拿出第 0、1、2、3 行; - 得到一个
[4, 256]的结果,每行表示一个位置的向量。
这就像你在查"第几行"的数据,每一行是256维向量。
✅ 第三步:这些向量是怎么参与训练的?
pos_embedding_layer.weight 是带有 requires_grad=True 的参数:
python
Parameter containing:
tensor([...], requires_grad=True)也就是说,这些位置向量会随着模型的误差反向传播(backpropagation)过程被更新。
所以:
- 一开始它是随机初始化的向量;
- 但随着模型训练,它会学到:第 0 个位置该有什么向量,第 1 个位置又该是什么向量;
- 这样模型就可以理解序列中的顺序和结构。
如果你想"看"一下这些初始化权重,可以试试这句:
python
print(pos_embedding_layer.weight) # 查看位置嵌入矩阵Parameter containing:
tensor([[-0.7497, -0.8066, -0.9359, ..., -0.1787, -0.3815, -2.1684],
[ 0.2493, -1.6384, 0.9950, ..., 1.0164, -0.3670, -0.7973],
[-2.2207, -0.2814, -0.6703, ..., -1.2844, 1.7460, 1.5246],
[-0.9561, -1.2158, -0.0514, ..., 0.3257, 1.9410, -1.8463]],
requires_grad=True)🔧 如果你想"手动"初始化它
你也可以自己设置这些值,例如用全 0、全 1 或某种分布:
python
with torch.no_grad():
pos_embedding_layer.weight.fill_(1.0) # 全部填充为 1.0或者更高级的,比如你要用 sin/cos 方式初始化(类似 Transformer 的原始位置编码),也可以:
python
with torch.no_grad():
pos_embedding_layer.weight[:] = your_custom_tensor4. 为什么可以直接加:input_embeddings = token_embeddings + pos_embeddings?
这是 绝对位置编码的核心思想:
token_embeddings是词嵌入,每个 token 都有一个[batch_size, seq_len, embedding_dim]的表示。pos_embeddings是位置嵌入,是每个位置一个[seq_len, embedding_dim]的表示。
假设我们有:
python
token_embeddings.shape = [8, 4, 256] # batch_size = 8, 序列长度 = 4, 向量维度 = 256
pos_embeddings.shape = [4, 256] # 每个位置一个向量为了相加时维度匹配,PyTorch 会自动 广播 pos_embeddings:
python
token_embeddings + pos_embeddings # 会自动扩展成 [8, 4, 256] + [4, 256]相当于每个样本的第 i 个 token 都加上第 i 个位置向量,起到了"告诉模型这个 token 在第几位"的作用。
5. "位置编码是不是每个样本都应该不同?为什么看起来好像都加的是同一个位置向量?"
✅ 正确的理解:位置编码对所有样本共享,同一位置加同一向量,是对的!
📌 为什么可以"共享"?
因为 位置和词是两个正交的信息来源:
token_embeddings:告诉模型 "这个词是啥";pos_embeddings:告诉模型 "这个词在第几位";
模型并不关心第 i 个位置是哪个样本的第 i 个位置,它只关心第 i 个 token 的位置属性。
换句话说:
- 所有 batch 中的第 0 个 token ,都加上 位置 0 的向量;
- 所有第 1 个 token,加位置 1 的向量;
- ......依此类推。
这是符合语言建模的直觉的 ------ 无论是"你吃饭了没"还是"他吃饭了没","吃"在第 1 个位置上,就应该收到同样的位置编码向量。
广播到底做了什么?
pos_embeddings.shape = [4, 256]
通过广播后变成:
[8, 4, 256] ------ 每个样本都复制一份 pos_embeddings。
所以其实效果等价于:
python
pos_embeddings_broadcasted = pos_embeddings.unsqueeze(0).repeat(8, 1, 1)
# shape: [8, 4, 256]
input_embeddings = token_embeddings + pos_embeddings_broadcasted也就是说,每个样本用的是 同一份位置向量,只是复制成 batch 的大小。
Summary
- 大型语言模型(LLMs)无法直接处理原始文本,因此需要将文本数据转换为数值向量(即嵌入)。嵌入可将离散数据(如单词或图像)转换为连续向量空间,使其适用于神经网络操作。
- 第一步,原始文本被拆分为标记(可以是单词或字符)。然后,这些标记被转换为整数表示,称为标记ID。
- 特殊标记(如<|unk|>和<|endoftext|>)可被添加以增强模型的理解能力,并处理各种上下文场景,例如未知词汇或标记不相关文本之间的边界。
- 用于GPT-2和GPT-3等大型语言模型的字节对编码(BPE)分词器可以通过将未知单词分解为子词单元或单个字符来高效处理它们。
- 我们在分词后的数据上使用滑动窗口方法来生成用于大型语言模型(LLM)训练的输入-目标对。
- Embedding layers in PyTorch function as a lookup operation, retrieving vectors corresponding to token IDs. The resulting embedding vectors provide continuous representations of tokens, which is crucial for training deep learning models like LLMs.
- While token embeddings provide consistent vector representations for each token, they lack a sense of the token's position in a sequence. To rectify this, two main types of positional embeddings exist: absolute and relative. OpenAI's GPT models utilize absolute positional embeddings, which are added to the token embedding vectors and are optimized during the model training.