1.Mysql 查询语句的执行顺序?
from...join...on...where...group by...having...select...order by...limit
2.Mysql 如何实现多表查询?
inner join,left outer join,right outer join, full outer join(mysql不支持,需要使用left + right + union 实现),cross join,子查询 in,派生表,union
3.MYSQL 内连接和外连接的区别 ?
内连接就是做交集,外连接就是在做交集的基础上保留左或右的差集。
4.CHAR 和 VARCHAR 的区别?
char 无论有没有达到字段长度统统按照设定的来,varchar 则是动态变化,没到最大长度就是当前长度。
5.什么是事务?
事务就是遵循 ACID 原则的一系列业务执行,在数据库中的事务就是不同事务直接隔离,并保持原子性,要不都成功,要不都失败回滚,事务一定是从一个状态到另一个状态,并且做出的修改时永久的。
6.ACID 是什么?可以详细说一下吗?
A 是原子性,事务里的 SQL 要不都执行要不都不执行;
C 是一致性;事务总是从一个状态到达另一个状态。
I 是隔离性,不同事务直接保持隔离,看不到对方的执行;
D 是持久性,事务带来的变化是永久的;
7.并发事务带来哪些问题?
并发事务会因为事务隔离级别不同而导致不同的问题:
首先就是读未提交,不同事务并发执行,因为可以读其他事务尚未提交的数据,所以会导致读脏数据;
接着就是读已提交,虽然事务只能读已经提交后的数据,但是因为同一个事务中可能要重复读同一数据,在这个时间间隔,其他并发事务就有机会修改数据,导致无法重复读;
再者就是可重复读,通过行级锁,快照等机制,对当前事务读取的数据留存副本,即使被修改依旧可以读原先的数据,但是无法保证范围查询时多插入的合乎规则的数据的乱入,导致幻读;
最后就是串行事务,虽然解决了并发事务的问题,但是很明显不在讨论范围内。
8.怎么解决这些问题呢?MySQL 的默认隔离级别是?
MySQL,默认的隔离级别是可重复读,可以解决除开幻读外的问题,可以采用 MVCC 多版本控制利用快照实现可重复读,或者记录锁(锁定单行),间隙锁(锁定范围),临键锁(record + gap)。
9.MYSQL 支持的存储引擎有哪些,有什么区别 ?
MYSQL 支持的存储引擎有 MyISAM 和 InnoDB;
MyISAM 支持表级锁,InnoDB 支持行级锁;
MyISAM 不支持事务,InnoDB 支持事务;
MyISAM 不支持 MVCC,InnoDB 支持 MVCC;
MyISAM 不支持全文索引,InnoDB 支持全文索引;
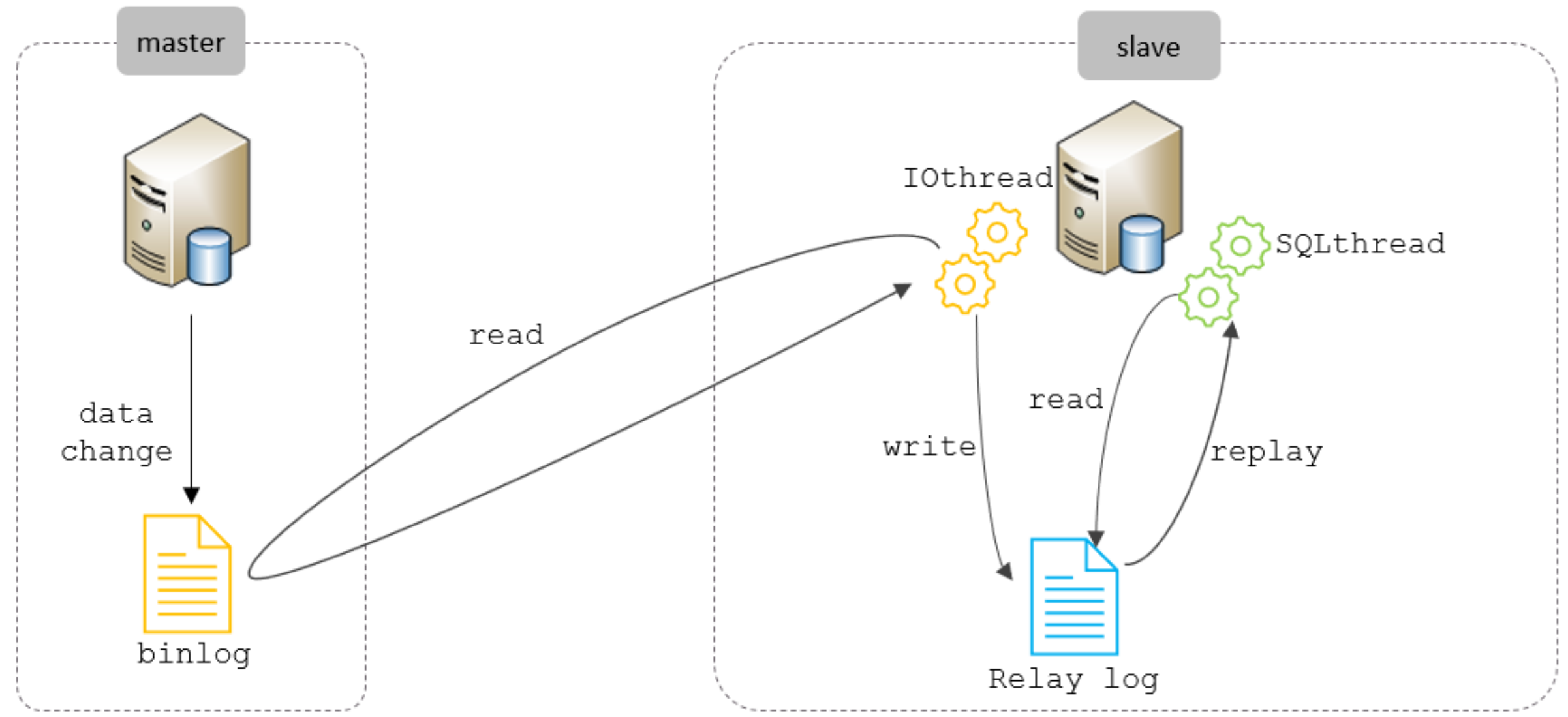
10.MYSQL 主从同步原理
MySql 主从同步原理其实就是 master 将库表的 DDL,DML 除开查询语句等 SQL 通过二进制的形式存储到 binlog 中,而 slave 则读取 master 的 slaver 持久化到 slave 的 relaylog 中,并重放 relaylog 中的语句,使得 slave 中的数据与 master 保持延迟同步。
11.读写分离的时候主从同步延时怎么解决?
读写分离即主库写,从库负责读,因为主从同步演示导致读数据读到了旧数据,可以通过强制某些需要强一致性的请求只能通过主库读,或者通过中间件监控从库延迟,当延迟过高则动态选择延迟低的从库或主库中读,亦或者,半同步复制主库写后,需要有从库返回已经同步 binlog 到 relaylog 成功后,主库才返回写成功到客户端。
12.Mysql 为什么要分库分表?分库分表的策略有哪些?分库分表后 id 主键如何处理?
分库分表主要是为了解决性能瓶颈和单机容量限制问题:
单表数据量过大(>千万或亿级):查询、插入、索引维护性能下降。
单库并发能力有限:MySQL 单机 QPS、连接数、I/O、CPU 都有瓶颈。
业务隔离需要:例如订单和用户分在不同库,方便扩展和维护。
数据迁移困难:如果业务增长快,早期设计的库表结构无法支撑未来数据量。
可用性需求:多库分布在不同节点,可以提高系统容错能力。
分库分表策略按照粒度分为两类:
分库策略:
按业务模块分库:如 user 库、order 库、product 库,适用于功能清晰的场景。
按数据范围分库:如按用户 ID、地域等哈希或范围映射到不同库。
分表策略:
垂直分表(列拆分):将一个表中不常用的字段或大字段(如文本/图片)拆出去。
水平分表(行拆分):将一个表的行按规则拆分成多个表。例如 order_0 ~ order_15。
分库分表后由于数据分布在多个表/库中,自增 ID 会发生冲突或失效,必须采用全局唯一 ID 策略。
常见的全局 ID 生成方案如下:
|-----------------|----------------------------------------|-----------------|
| 方案 | 描述 | 特点 |
| UUID | 使用 128 位随机 ID | 唯一但不排序,存储和查询性能差 |
| 数据库自增段 | 每个库分配不同自增起点+步长(如库1从1起,步长2,库2从2起) | 实现简单,但存在主从同步难题 |
| 雪花算法(Snowflake) | Twitter 开源,常用的 64 位 ID:时间戳 + 机器号 + 序列号 | 有序、高性能、分布式场景通用 |
13.不同数据库的区别
|-----------|----------------|------------------|----------------|------------------|
| 对比项 | MySQL | PostgreSQL | Oracle | SQL Server |
| 是否开源 | 是 | 是 | 否 | 否 |
| 事务支持 | 支持(InnoDB 引擎) | 强事务,符合 SQL 标准 | 强事务,ACID 非常健壮 | 强事务 |
| SQL 标准支持度 | 中等 | 非常高(接近 ANSI SQL) | 高,但有大量自定义扩展语法 | 高 |
| JSON 支持 | 一般(支持但功能有限) | 很强(JSONB、索引等) | 一般 | 一般 |
| 分区/分表支持 | 有限(需要手动控制) | 有 | 非常强大 | 有限 |
| 扩展能力 | 中等 | 很强(支持自定义函数、插件) | 非常强但封闭 | 较强但封闭 |
| 使用场景 | Web 系统、电商、内容平台 | 金融、GIS、数据科学、高一致性 | 企业级系统、ERP、大型项目 | 企业办公、Windows生态系统 |
14.数据库三范式
第一范式 1 NF:字段不可再分,如不会出现在一个字段里同时出现年龄和出生日期;
第二范式 2 NF:表只有唯一主键,即其他字段都只能直接或间接通过主键字段推出;
第三范式 3 NF:在 2 NF 的基础上,进一步取消间接引用。
15.MVCC

MVCC 就是多版本并发控制是 Mysql 实现读已提交和重复读的事务隔离级别的无锁机制,假如 MySql 使用行锁实现这两个隔离级别,就会造成并发事务的读阻塞,所以需要 MVCC 这个无锁机制;
MVCC 原理其实就分为两个,readView,undoLog,undoLog 就是当前数据的一个多版本链路记录,最新记录指向上一版本记录,以及记录当前数据更新执行的事务 ID;
以读已提交为例讲解 readView:
1.当前事务需要查询数据时,先根据自身事务 ID 与最新的 undolog 记录比较;
2.相等,则代表该数据的更新是事务自身修改的,所以这条记录可读;
3.否则,根据最小未提交事务 ID 判断
4.如果记录 ID 小于最小事务 ID 证明该记录已经提交,可以读;
5.否则,证明该记录是未提交事务更新的,需要回溯到上一版本记录继续判断,直到满足为止;
6.同一个事务里,每一次查询数据都执行一次 readView。
同理,重复读其实就是只在第一次读数据的时候 readView,后面的查询均使用第一次 readView 读到的数据。读未提交不需要任何处理,事务无论提交与否 sql 都执行成功,而串行实际就是表锁实现的,一个事务操作一个表,就给当前表上锁,其他事务阻塞。