各位大佬好,我是落羽!一个坚持不断学习进步的大学生。
如果您觉得我的文章有所帮助,欢迎多多互三分享交流,一起学习进步!
也欢迎关注我的blog主页: 落羽的落羽

文章目录
- 一、set和map是什么
- 二、set系列
-
- [1. set](#1. set)
- [2. multiset](#2. multiset)
- 三、map系列
-
- [1. map](#1. map)
- [2. multimap](#2. multimap)
一、set和map是什么
我们之前已经学习过了STL库中的部分容器,如string、vector、list、deque,这些容器统称之为序列式容器,因为它们的逻辑结构都是线性的,存储元素之间一般没有紧密的联系关系,即使交换元素位置,数据结构仍是线性的。这些序列式容器的元素是按照他们在容器中存储的位置来顺序保存和访问的。
关联式容器的逻辑结构则是非线性的结构,元素位置之间有紧密的关联关系,交换位置则存储结构会破坏。关联式容器有map/set系列和unordered_map/unorderer_set系列。
今天我们学习的set和map,底层是红黑树,红黑树是一棵平衡二叉搜索树。set是key搜索场景的结构,而map是key/value搜索场景的结构。
二、set系列
使用set系列的set、multiset,都需要#include <set>
1. set
set是不允许key值重复出现的平衡二叉搜索树。

- set的模板参数T,就是key的类型。
- set默认要求key值是小于比较,也就是这棵树中左子树key < 结点key < 右子树key,因为第二个模板参数默认传的是
less<T>。我们也可以自己传greater<T>使之变成大于比较,即这棵树中左子树key > 结点key > 右子树key。 - 由于set底层是红黑树,增删查效率是O(logN),效率很高,中序遍历默认是升序的。
set的几种构造方式:
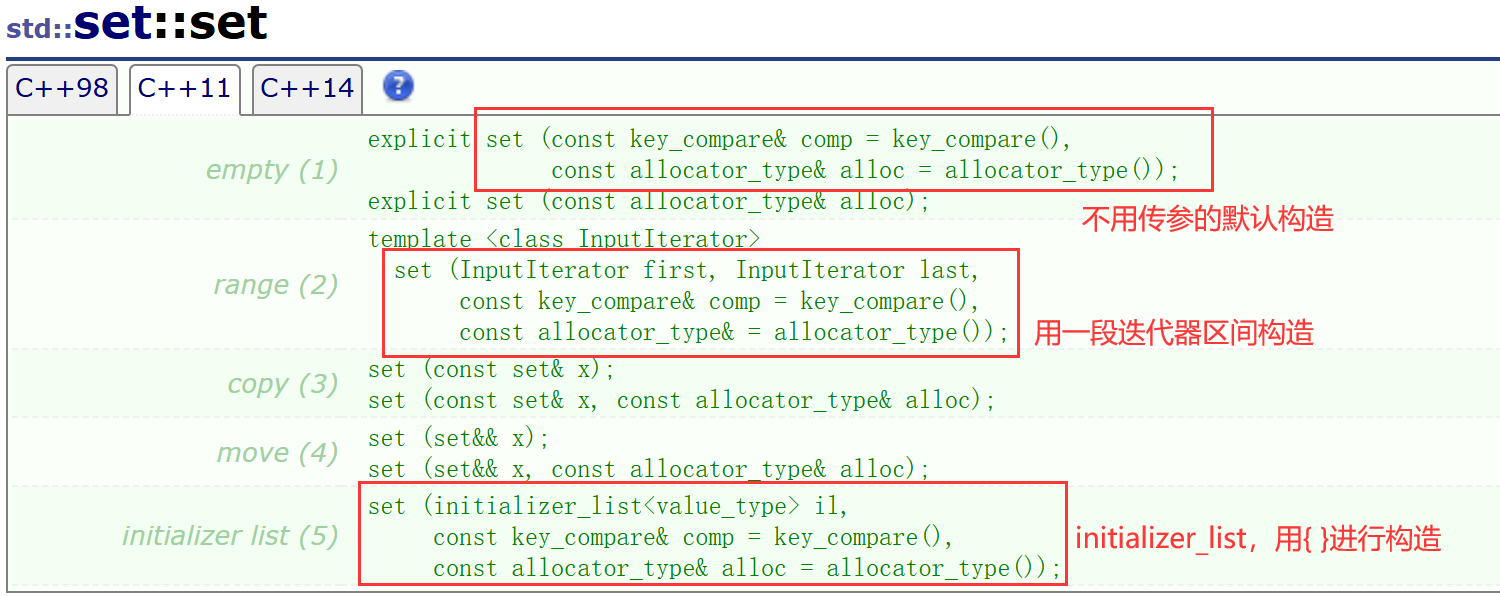
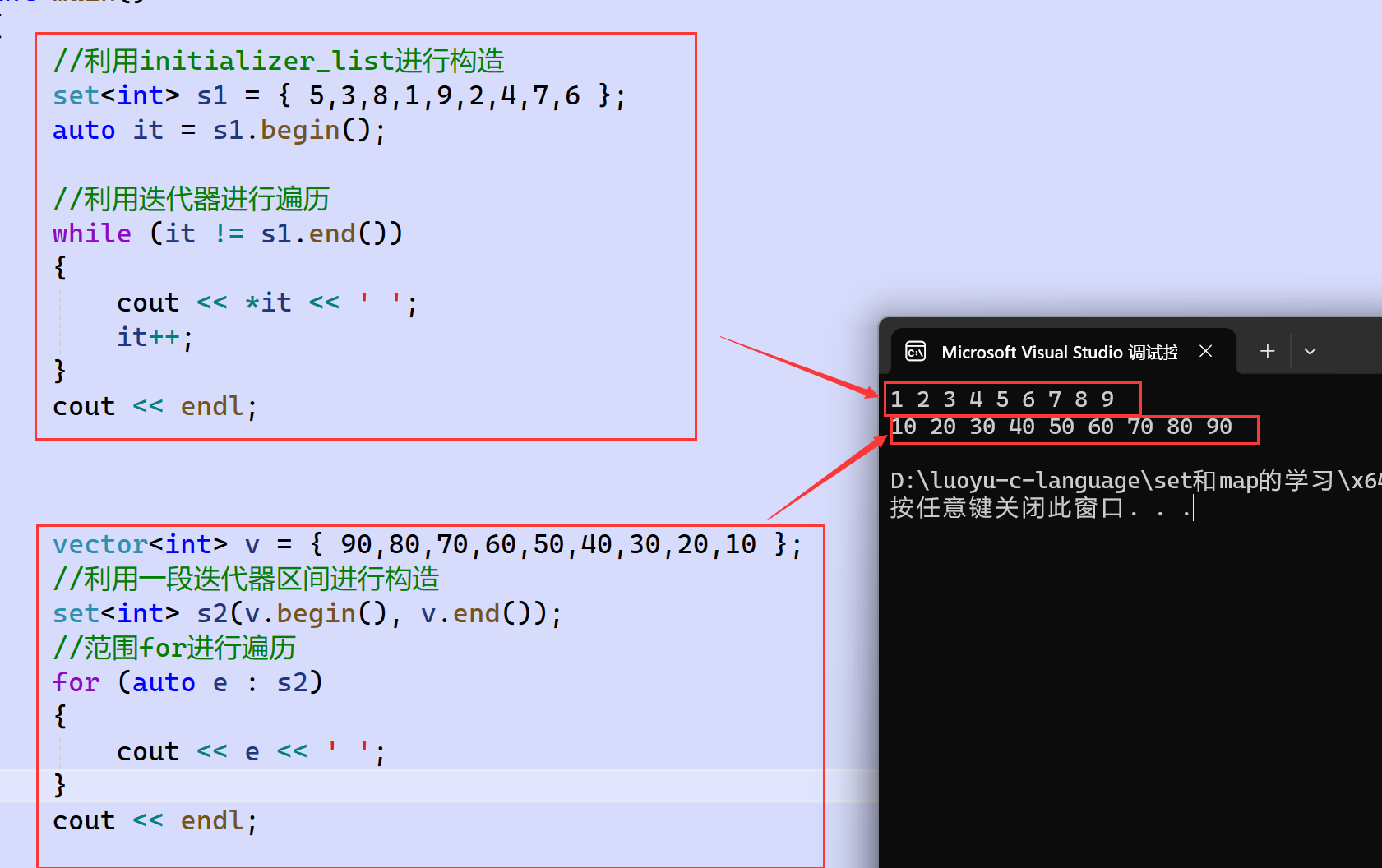
set也有迭代器,也有begin和end一系列接口。
set的begin()和end()是它的中序遍历序列的开头和结尾 ,begin是中序第一个结点,end是中序的最后一个结点的下一个位置。后面的容器也是一样,begin和end都是中序遍历的位置。不难想象,begin()返回的是最小key值结点的迭代器 。
set支持正向和反向迭代器,也支持范围for,迭代器++和范围for都是按照树的中序顺序进行遍历。但是set的iteritor和const_iteritor都不支持迭代器修改key,会破坏底层搜索树的结构。
set类中当然还有增删查等相关功能:
-
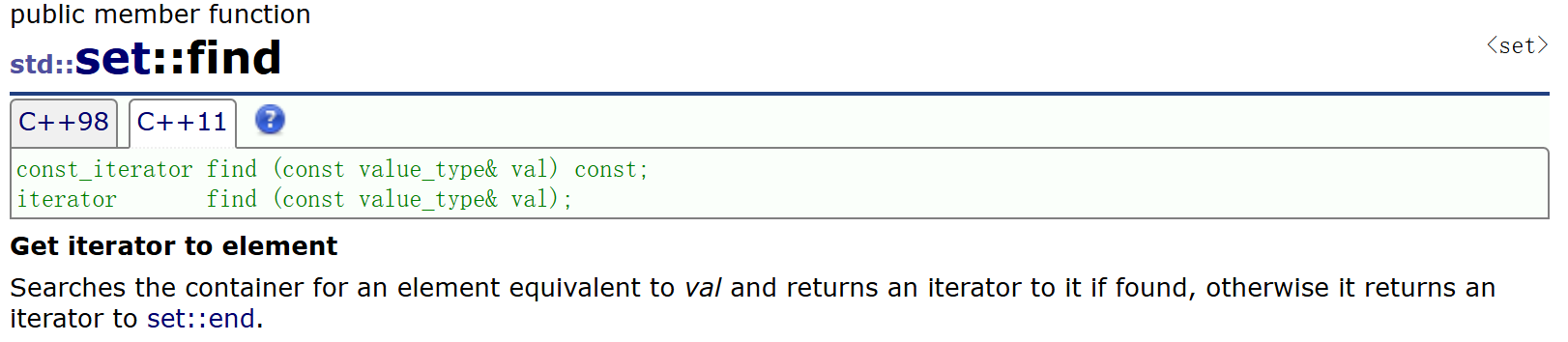
find:查找key为传参val的位置,若存在则返回这个位置的迭代器,若不存在则返回end()
-
count:记录set中key为传参的结点个数

这个函数的返回值是size_t类型,是key值为val的个数,但是由于set中不允许有重复key值,所以set类对象这个函数的返回值只能是0或1,也就可以依据是0或1判断某个key是否存在。换句话说,count也可以有查找判断key是否存在的功能。
-
insert:插入新的key
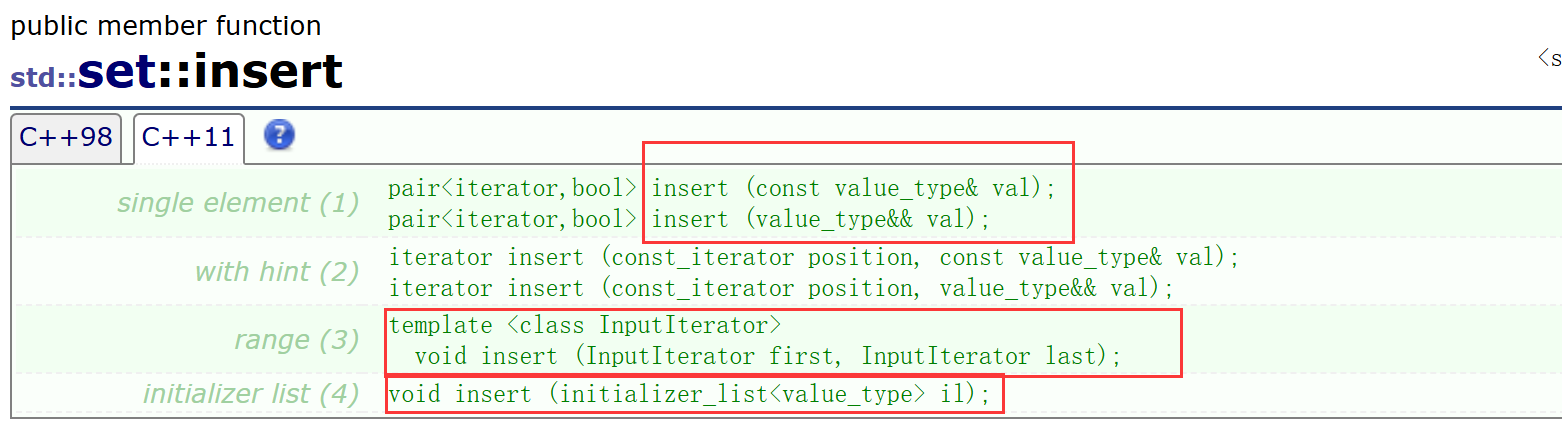 insert可以插入单个数据、一段迭代器区间、一段{ }列表。但由于set不允许有重复key值,所以插入内容中出现了重复key值则不会插入。这个过程实际是先进行了一次查找操作,在原set中找不到想新插入的key,才能进行插入。
insert可以插入单个数据、一段迭代器区间、一段{ }列表。但由于set不允许有重复key值,所以插入内容中出现了重复key值则不会插入。这个过程实际是先进行了一次查找操作,在原set中找不到想新插入的key,才能进行插入。 -
erase:删除结点

erase可以传一个迭代器删除这个迭代器的结点,可以传一段迭代器区间整体删除。也可以传一个key值删除这个key值的结点,找不到这个key结点则不删除,这种版本的erase返回值是size_t,和count道理一样,返回值代表删除的结点个数,1代表删除了一个结点,0代表没有删除结点,也可以用于判断删除是否成功。
演示:
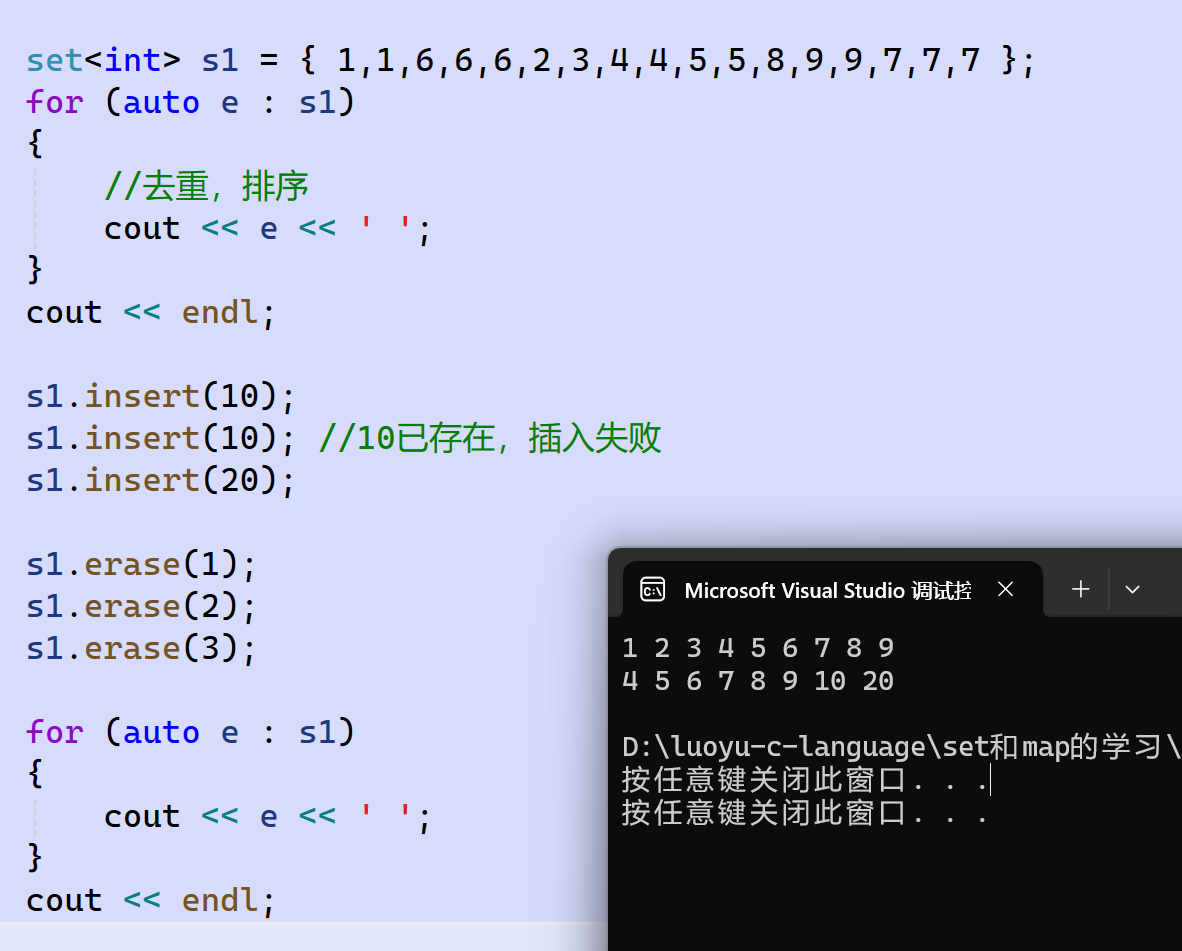
除此之外,set还有两个接口lower_bound、upper_bound:
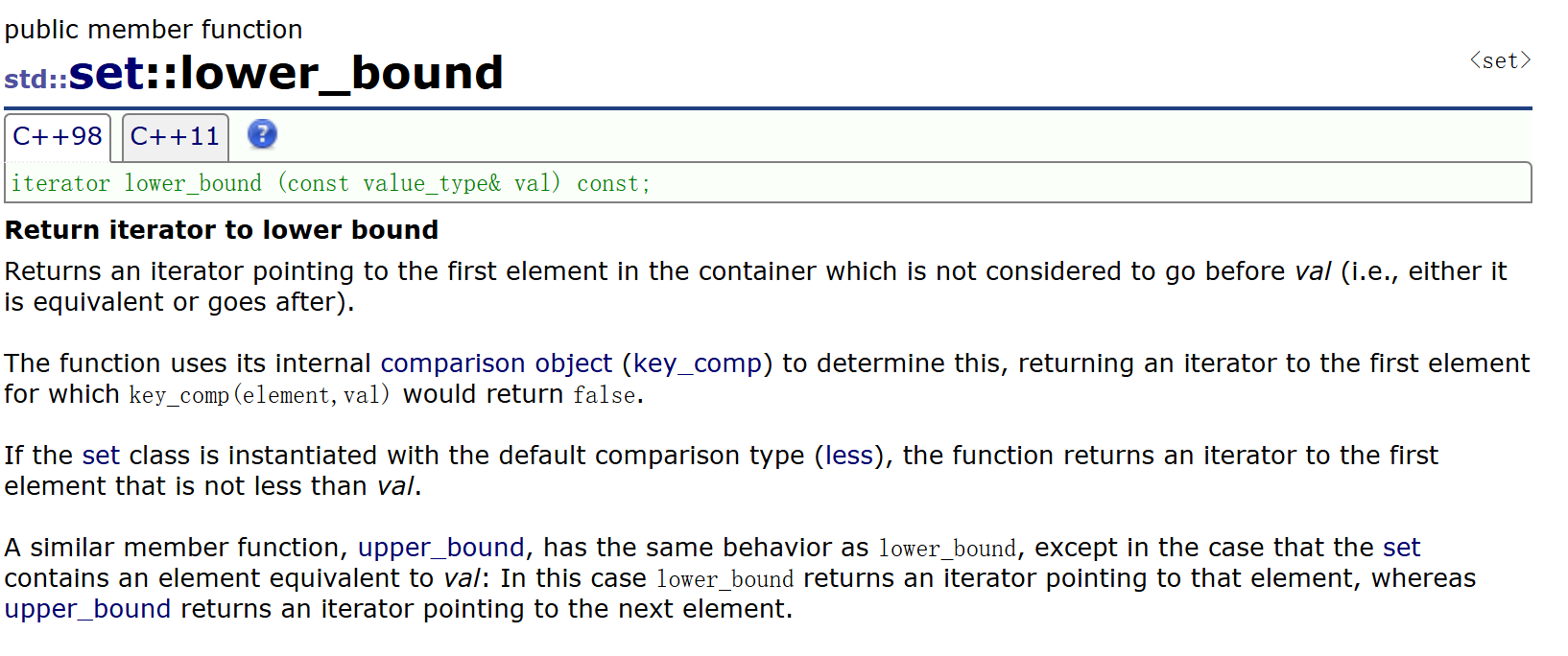
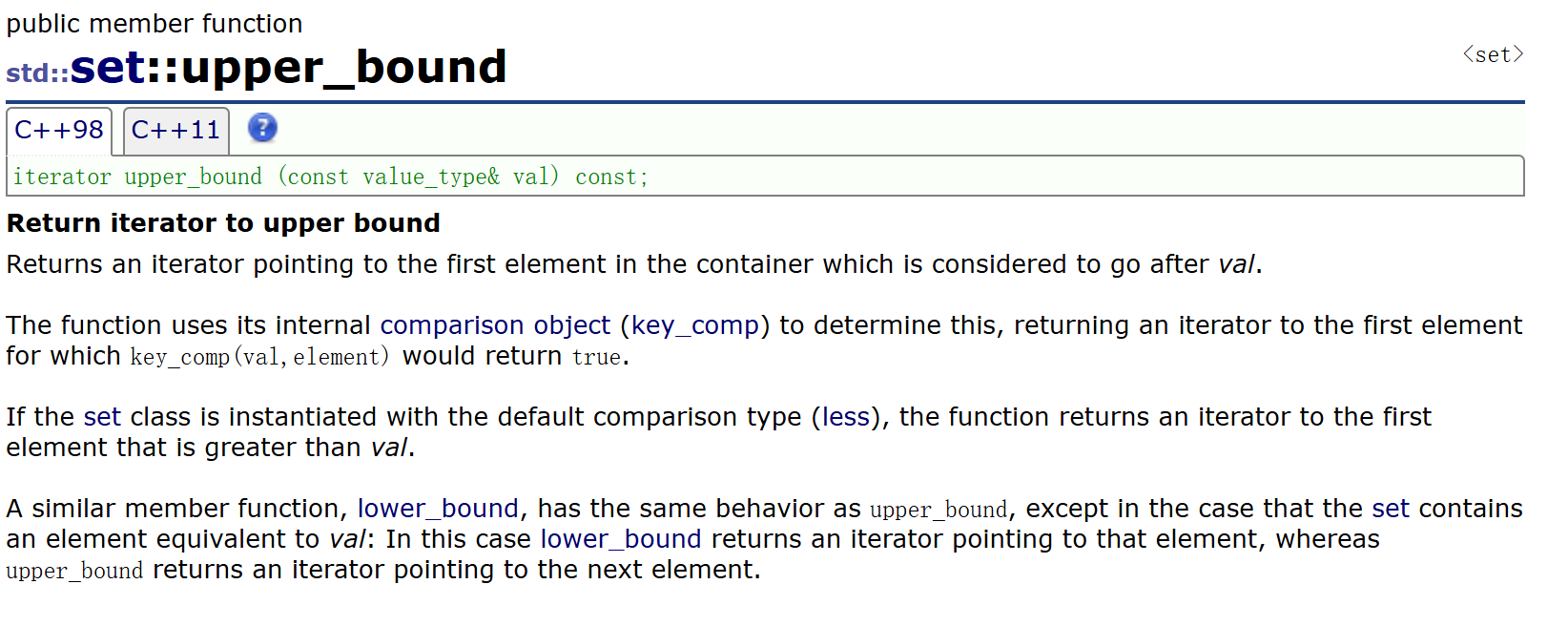
它们通常一起使用,lower_bound返回set中的第一个key值>=val值的结点的迭代器,upper_bound返回set中的第一个key值>val值的结点的迭代器 。它们的作用是找一段值的区间。
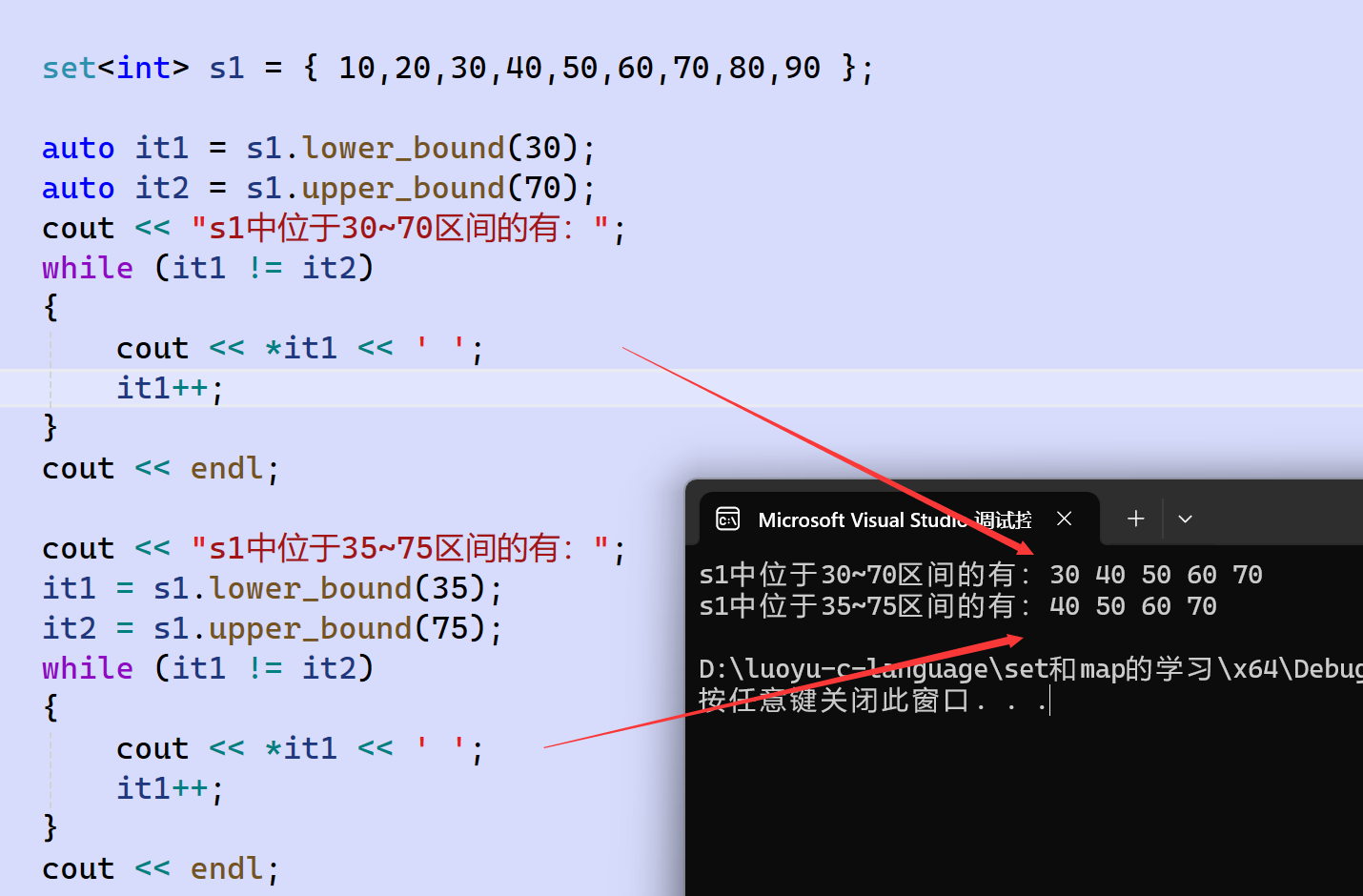
比如一个set中结点为{10, 20, 30, 40, 50, 60, 70, 80, 90},auto it1 = lower_bound(30);
则it1是结点30的迭代器,auto it2 = upper_bound(70);,则it2是结点70的迭代器。也就是说,it1和it2两个迭代器包含了30、40、50、60、70这段结点区间。
这两个函数的传参可以不是set中已存在的key值,比如上面的例子,传auto it1 = lower_bound(35);则it1是结点40的迭代器,auto it2 = upper_bound(75);,则it2是结点80的迭代器。
若它们找不到比val大的key结点,则返回end()。
演示:
2. multiset
multiset也是set系列的一种,相比于set,它支持key值的冗余,也就是可以存在重复的key值。相同的key可能在根结点key的左边或右边。它的使用与set大体类似,但find、insert、erase、count等与set的有所差异:
- find:multiset的key中可能有多个为val的结点。multiset的find是按照中序序列查找第一个key为val的结点,返回它的迭代器。
- insert:multiset支持存在重复的key,因此插入已存在key值的新结点也能成功。
- erase:multiset的这种erase版本
size_type erase (const value_type& val);会删除所有key值为val的结点,返回值是删除的结点的个数。因为multiset中可能有重复key值,所以返回值可能是任何非负整数。 - count:和set一样,也是记录返回key值为传参val的结点个数。因为multiset中可能有重复key值,所以返回值可能是任何非负整数。
只要理解了multiset和set的差异只在于muliset支持key重复存在,它们的接口的差异都很好理解了。
演示: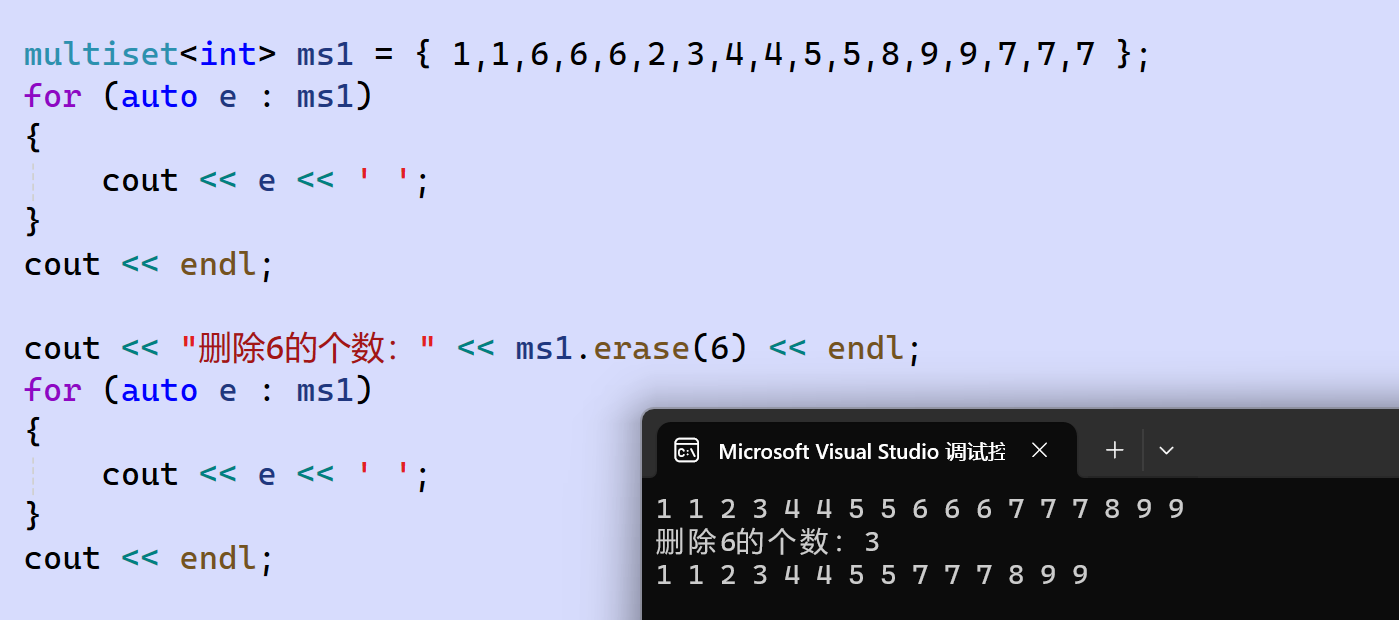
multiset也有lower_bound和upper_bound操作,和set道理一样。
multiset中还有一个equal_range,是查找key值为传参val的结点的区间。因为multiset中若有重复的key结点,则它们在中序序列中一定是连续的。equal_range就返回这一段迭代器区间。注意到它的返回类型是pair<iteritor, iteritor>,这就是两个迭代器的组合代表一段区间,关于pair具体下面再介绍。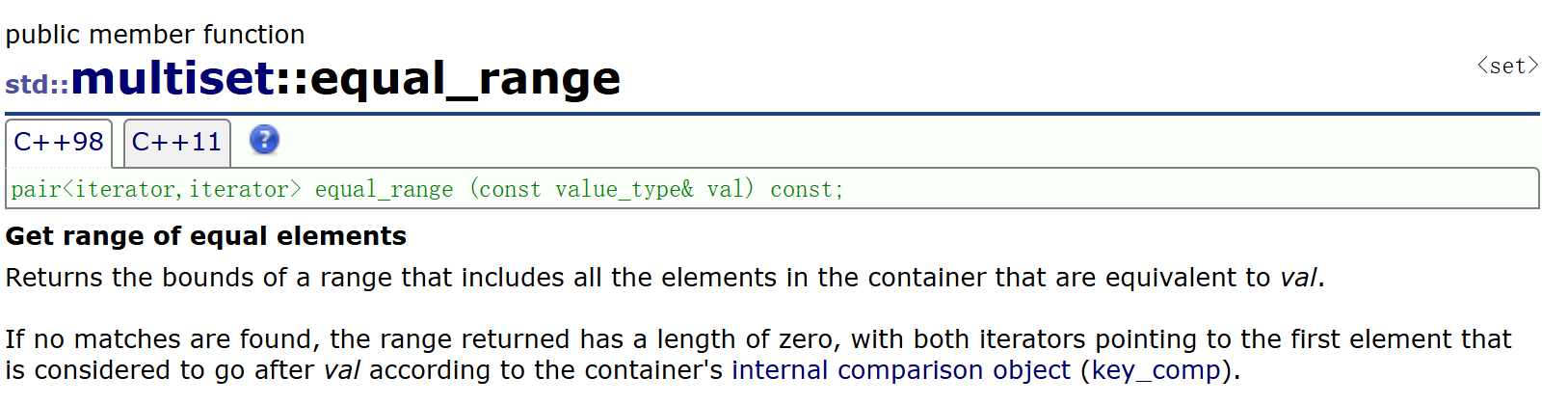
三、map系列
使用map系列的map、multimap,都需要#include <map>
1. map
set系列底层是key结构的红黑树,而map系列底层是key/value结构的红黑树。
map不允许key值重复出现的平衡二叉搜索树。
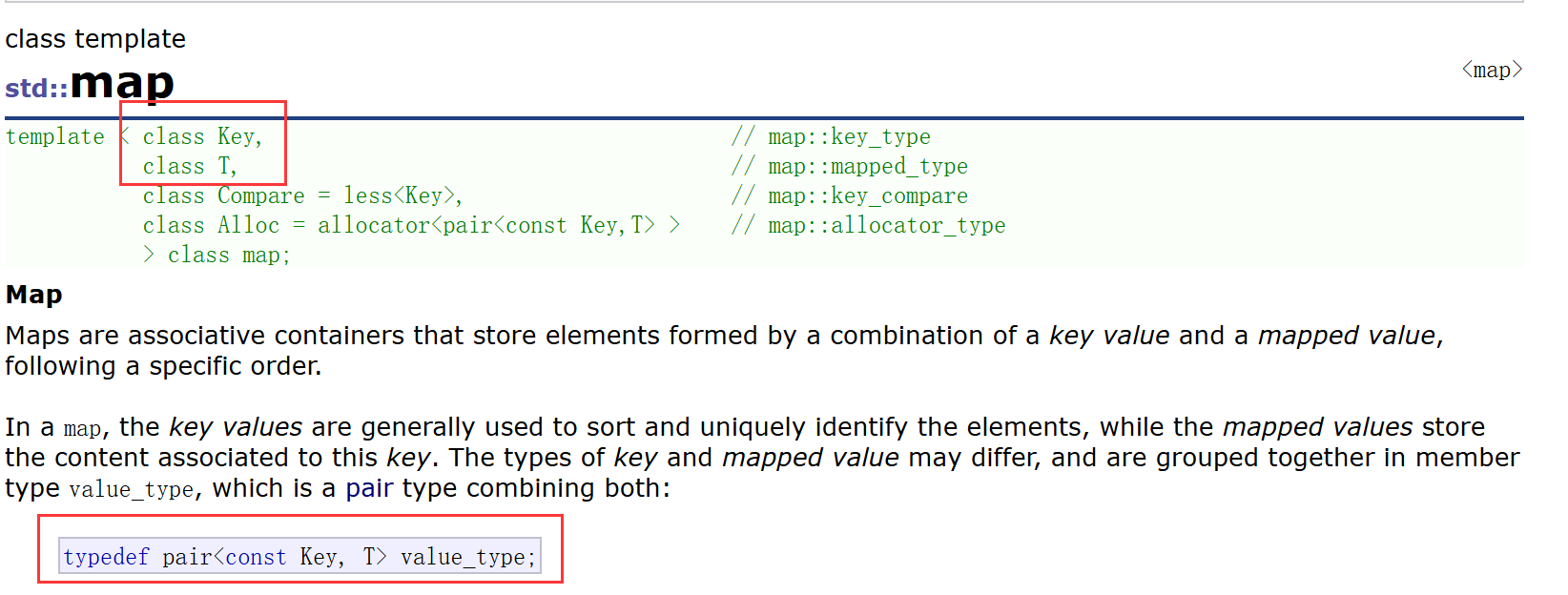
其中,Key是key的类型,T是value的类型。Compar默认传less要求支持小于比较。map的增删查改效率是O(N),迭代器也是走的中序遍历,按照key的有序顺序进行遍历。
而在map的结点中,它的key和value其实是被封装成一个叫pair的结构体来存储的:
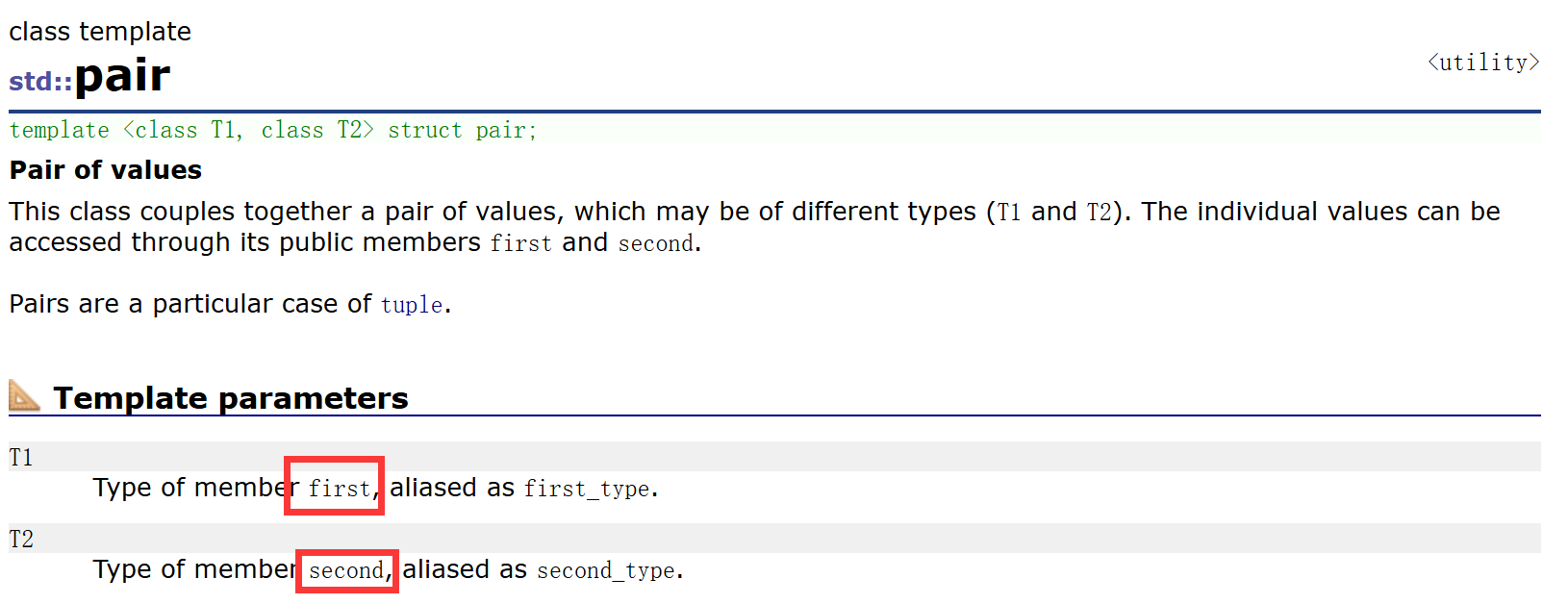
pair的结构其实很简单,就是两个类型的两个成员封装在一起,T1 first、T2 second。在map的结点中的pair,T1为key的类型,T2为value的类型,first就是key,second就是value。map的结点中,使用pair<Key, T>存储键值对数据。当然,pair类型中还有一些构造函数、拷贝构造函数,不多赘述。
map的构造、迭代器、其他操作大体和set都是相似的,区别只在于map可以修改value值,不能修改key值。查和删的操作只关注key,所以map的查和删和set一样。增的操作不仅要增key,还要增value:

第一个版本的insert返回类型是pair<iterator, bool>,如果key已在map中,则插入失败,返回的pair的first是已存在key所在节点的迭代器,second是false;如果key不在map中,插入成功,返回的pair的first是新插入key的结点迭代器,second是true 。也就是说,无论key插入失败成功,insert的返回值的first都是key结点的迭代器,意味着insert也能充当查找的功能,下面 的重载就是利用了这一点。
insert要求的参数是一个pair,这里其实就很灵活了。可以构造对象再传参、匿名对象传参、隐式类型转换传参:

相比set,map还可以修改value的功能。一种方法是通过迭代器,map的迭代器相当于指向pair的指针,利用迭代器->second = x;来完成修改。
另一种方法,map重载了[]操作符,但是用法很特殊:map的 中不是传寻常的下标,而是传key值,若这个key值在map中已存在,则返回它对应的value的引用;若这个key值不存在,则将这个key新插入进去,它的value则使用它的缺省值或调它的类型的默认构造,也返回value的引用。
value若是自定义类型,就有它的默认构造;内置类型也有默认构造,如int默认构造为0,指针默认构造为nullptr。
不难看出, 有查找+插入的功能,同时因为返回value的引用,也具备了修改的功能。map的 重载是一个非常重要的多功能接口,它的内部实现是这样的,利用刚才说的insert的特点:
cpp
T& operator[](const Key& key)
{
pair<iterator, bool> ret = insert({key, T()});
//it指向了key值的结点,不论这个key是已存在的还是新插入的
iterator it = ret.first;
//it相当于指向了pair,it的second就是value了
return it->second;
}map的 在一些特定场景下使用是很爽的,比如这样一个例子:统计字母出现个数。
不使用 可能要这么做:
cpp
vector<char> v = { 'a','b','c','b','a','c','a','a','b' };
//构建一个map<char,int>,char代表字母,int代表它的出现次数
map<char, int> countMap;
for (auto e : v)
{
//查找字母在不在map中
auto ret = countMap.find(e);
//不在,说明这个字母是第一次出现,插入{字母,1}
if (ret == countMap.end())
{
countMap.insert({ e,1 });
}
//这个字母存在,则它的出现次数+1
else
{
ret->second++;
}
}
for (auto e : countMap)
{
cout << e.first << ":" << e.second << "次" << endl;
}
cout << endl;
但使用 ,就更简洁了:
cpp
vector<char> v = { 'a','b','c','b','a','c','a','a','b' };
//构建一个map<char,int>,char代表字母,int代表它的出现次数
map<char, int> countMap;
for (auto e : v)
{
//字母不在,说明这个字母第一次出现,则插入,int默认构造成0,++一下就成1了
//字母在,也返回value的引用,也会++一次
countMap[e]++;
}
for (auto e : countMap)
{
cout << e.first << ":" << e.second << "次" << endl;
}
cout << endl;
没有问题!
2. multimap
multimap就是支持key重复出现的map,同一key值的不同结点的value也可以不一样 。multimap的增删查改相对于map也有一些不同,但是大概规律和multiset相对于set一样,比如find返回多个key值结点的中序遍历第一个。除此之外就是multimap不支持map的 。
本篇完,感谢阅读~