研究背景与意义
研究背景与意义
随着全球安全形势的日益复杂,安检工作的重要性愈发凸显。特别是在公共场所和交通枢纽,如何有效地检测和识别潜在的爆炸物成为了一个亟待解决的技术难题。传统的安检手段往往依赖于人工检查和简单的物理检测,效率低下且容易受到人为因素的影响。因此,基于计算机视觉的自动化检测系统应运而生,成为提升安检效率和准确性的关键技术之一。
在众多计算机视觉算法中,YOLO(You Only Look Once)系列因其高效的实时目标检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,结合了深度学习的优势,能够在复杂背景下快速、准确地识别和分类多种目标。通过对YOLOv11的改进,我们可以进一步提升其在安检领域的应用效果,尤其是在爆炸物检测方面。
本研究所使用的数据集包含3700张经过精心标注的图像,涵盖了六类不同的爆炸物,包括裸露液体爆炸物、裸露固体爆炸物、隐藏液体爆炸物、隐藏固体爆炸物、正常液体和正常固体。这些数据的多样性和丰富性为模型的训练提供了坚实的基础,使其能够在实际应用中具备更强的适应性和鲁棒性。通过对这些图像的深度学习训练,改进后的YOLOv11模型将能够更准确地识别和分类不同类型的爆炸物,从而在安检过程中提供更为可靠的技术支持。
综上所述,基于改进YOLOv11的安检爆炸物检测系统不仅能够提高安检的自动化水平,还能有效降低人为失误的风险,提升公共安全保障能力。随着技术的不断进步,该系统有望在未来的安检工作中发挥更为重要的作用,为维护社会安全贡献力量。
图片演示
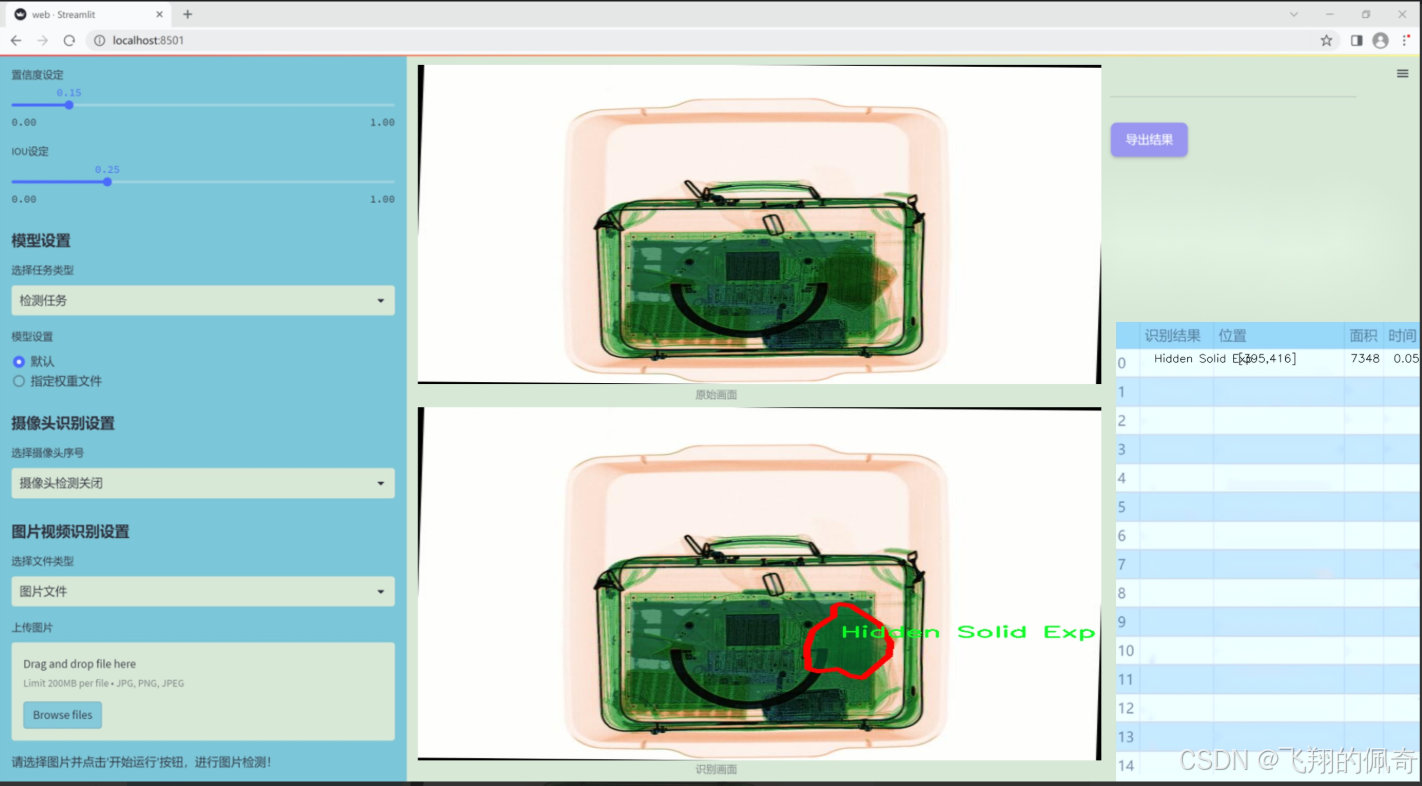
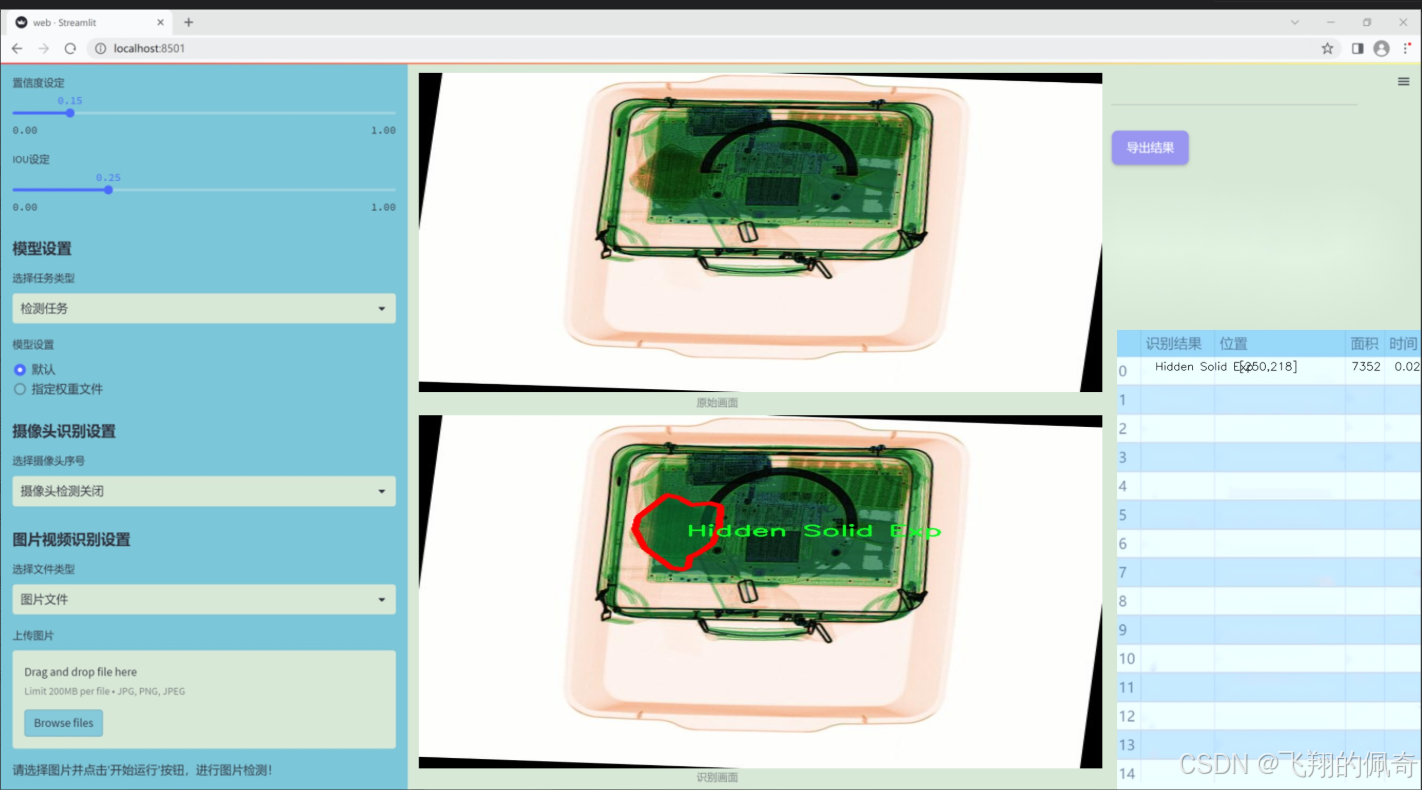
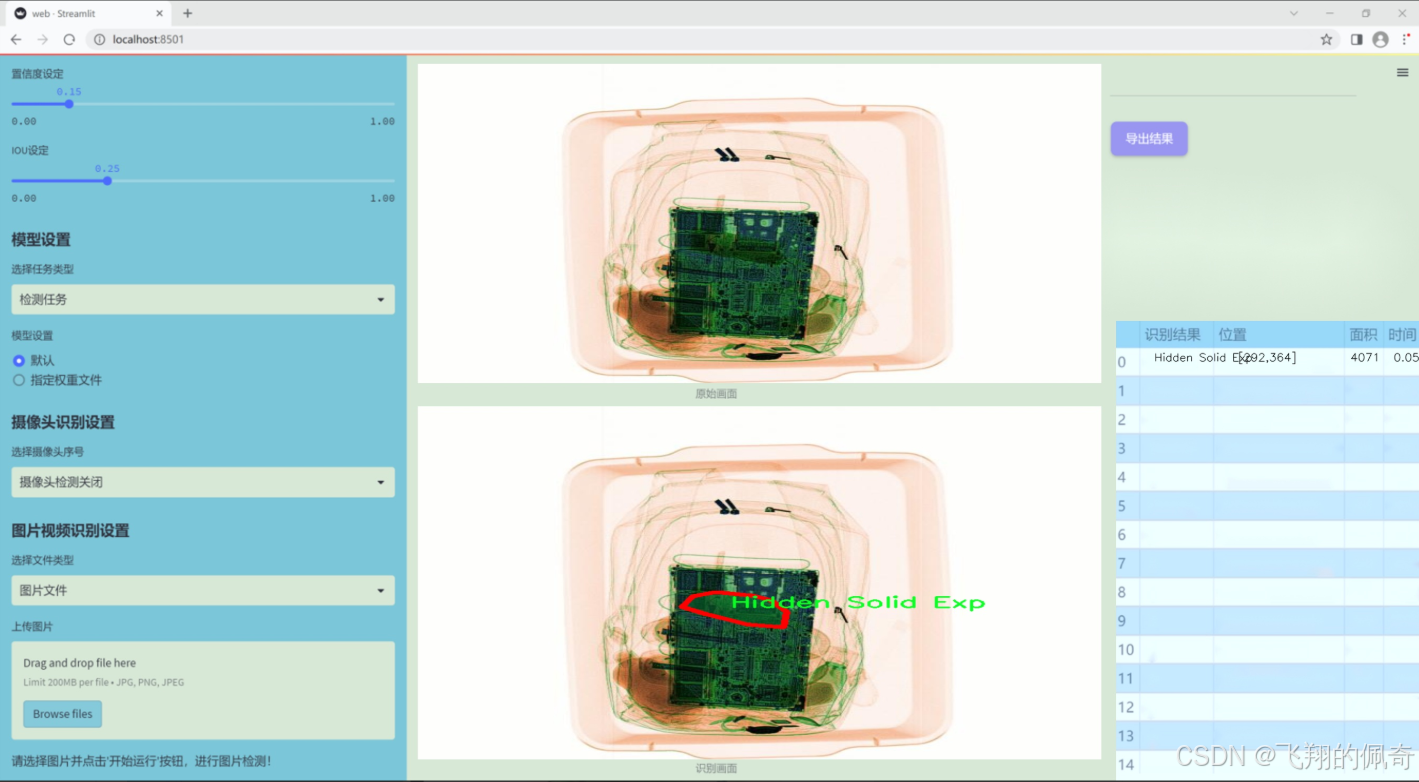
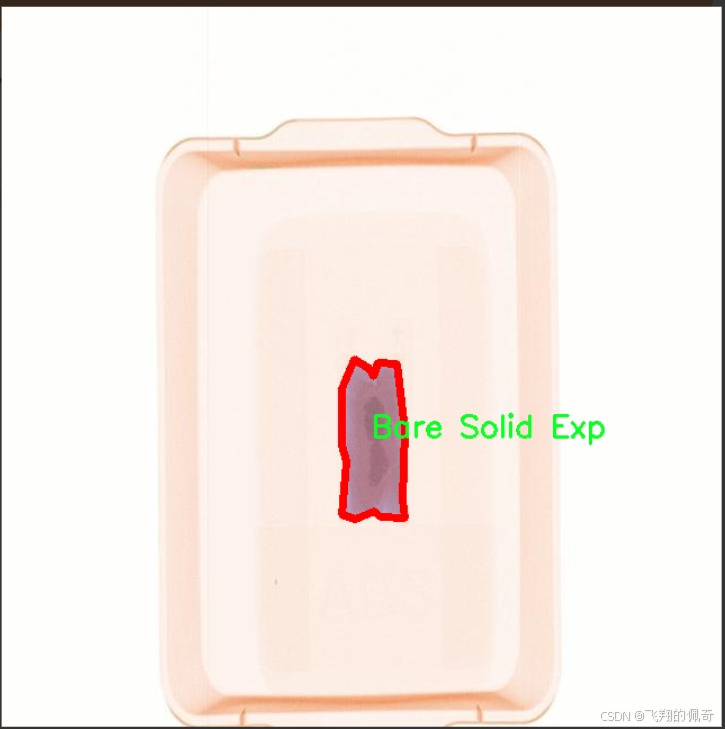
数据集信息展示
本项目数据集信息介绍
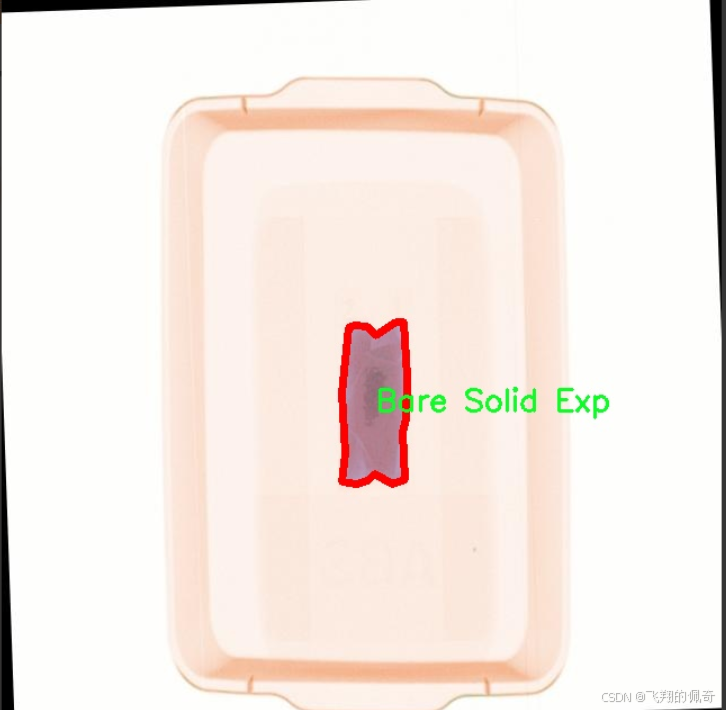
本项目所使用的数据集名为"SSTLabs",旨在为改进YOLOv11的安检爆炸物检测系统提供强有力的支持。该数据集专注于爆炸物的多样性和复杂性,涵盖了六个主要类别,分别为"Bare Liquid Exp"(裸露液体爆炸物)、"Bare Solid Exp"(裸露固体爆炸物)、"Hidden Liquid Exp"(隐藏液体爆炸物)、"Hidden Solid Exp"(隐藏固体爆炸物)、"Normal Liquid Exp"(正常液体爆炸物)和"Normal Solid Exp"(正常固体爆炸物)。这些类别的设定不仅考虑到了爆炸物的物理状态(液体或固体),还细分了其是否处于可见状态或隐藏状态,从而使得数据集在安检场景中的应用更加全面和精准。
在安检领域,爆炸物的检测面临着诸多挑战,尤其是在处理复杂的环境和多样化的物品时。通过对这六个类别的深入研究和数据收集,SSTLabs数据集为模型训练提供了丰富的样本,确保了不同类型爆炸物的特征能够被有效捕捉。数据集中的每个类别均包含大量的标注图像,这些图像不仅展示了爆炸物的外观特征,还考虑了不同的拍摄角度和光照条件,增强了模型的鲁棒性。
此外,数据集的设计充分考虑了实际应用中的多样性,确保模型在面对真实场景时能够做出准确的判断。通过利用SSTLabs数据集,研究人员能够训练出更为高效的YOLOv11模型,从而提高安检系统在爆炸物检测方面的准确性和可靠性。总之,SSTLabs数据集不仅为本项目提供了坚实的数据基础,也为未来的安检技术发展奠定了重要的理论和实践基础。



项目核心源码讲解(再也不用担心看不懂代码逻辑)
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
class KACNConvNDLayer(nn.Module):
def init (self, conv_class, norm_class, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, dropout=0.0):
super(KACNConvNDLayer, self).init()
# 初始化输入和输出维度、卷积参数等
self.inputdim = input_dim # 输入维度
self.outdim = output_dim # 输出维度
self.degree = degree # 多项式的阶数
self.kernel_size = kernel_size # 卷积核大小
self.padding = padding # 填充
self.stride = stride # 步幅
self.dilation = dilation # 膨胀
self.groups = groups # 分组卷积的组数
self.ndim = ndim # 数据的维度(1D, 2D, 3D)
self.dropout = None # dropout层初始化为None
# 如果dropout比例大于0,则根据维度选择合适的dropout层
if dropout > 0:
if ndim == 1:
self.dropout = nn.Dropout1d(p=dropout)
elif ndim == 2:
self.dropout = nn.Dropout2d(p=dropout)
elif ndim == 3:
self.dropout = nn.Dropout3d(p=dropout)
# 检查分组卷积的有效性
if groups <= 0:
raise ValueError('groups must be a positive integer')
if input_dim % groups != 0:
raise ValueError('input_dim must be divisible by groups')
if output_dim % groups != 0:
raise ValueError('output_dim must be divisible by groups')
# 初始化层归一化和多项式卷积层
self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])
self.poly_conv = nn.ModuleList([conv_class((degree + 1) * input_dim // groups,
output_dim // groups,
kernel_size,
stride,
padding,
dilation,
groups=1,
bias=False) for _ in range(groups)])
# 注册一个缓冲区,用于存储多项式的系数
arange_buffer_size = (1, 1, -1,) + tuple(1 for _ in range(ndim))
self.register_buffer("arange", torch.arange(0, degree + 1, 1).view(*arange_buffer_size))
# 使用Kaiming均匀分布初始化卷积层的权重
for conv_layer in self.poly_conv:
nn.init.normal_(conv_layer.weight, mean=0.0, std=1 / (input_dim * (degree + 1) * kernel_size ** ndim))
def forward_kacn(self, x, group_index):
# 前向传播函数,处理每个组的输入
x = torch.tanh(x) # 应用tanh激活函数
x = x.acos().unsqueeze(2) # 计算反余弦并增加维度
x = (x * self.arange).flatten(1, 2) # 与系数相乘并展平
x = x.cos() # 计算余弦值
x = self.poly_conv[group_index](x) # 通过对应的卷积层
x = self.layer_norm[group_index](x) # 进行层归一化
if self.dropout is not None:
x = self.dropout(x) # 如果有dropout,则应用dropout
return x
def forward(self, x):
# 前向传播函数,处理所有组的输入
split_x = torch.split(x, self.inputdim // self.groups, dim=1) # 按组分割输入
output = []
for group_ind, _x in enumerate(split_x):
y = self.forward_kacn(_x.clone(), group_ind) # 对每个组调用forward_kacn
output.append(y.clone()) # 保存输出
y = torch.cat(output, dim=1) # 合并所有组的输出
return y代码说明:
KACNConvNDLayer: 这是一个自定义的卷积层类,支持任意维度的卷积操作(1D, 2D, 3D)。
初始化参数: 在构造函数中,初始化输入输出维度、卷积参数、分组等,并进行必要的参数验证。
dropout层: 根据输入的维度选择合适的dropout层。
前向传播: forward_kacn函数实现了对每个组的前向传播逻辑,包括激活函数、卷积操作和层归一化。
输出合并: forward函数负责将输入按组分割并调用forward_kacn,最后将所有组的输出合并。
这个程序文件定义了一个名为 kacn_conv.py 的 PyTorch 模块,主要用于实现一种新的卷积层,称为 KACN(K-阶激活卷积网络)。该模块支持多维卷积(1D、2D 和 3D),并通过自定义的激活函数和多项式卷积操作来增强特征提取能力。
首先,文件导入了 PyTorch 的核心库和神经网络模块。接着,定义了一个名为 KACNConvNDLayer 的类,它继承自 nn.Module。这个类的构造函数接收多个参数,包括卷积类型、归一化类型、输入和输出维度、卷积核大小、分组数、填充、步幅、扩张、维度数量和 dropout 比例。构造函数中对这些参数进行了初始化,并进行了必要的验证,例如确保分组数为正整数,并且输入和输出维度能够被分组数整除。
在构造函数中,还创建了一个包含归一化层的模块列表和一个包含多项式卷积层的模块列表。多项式卷积层的数量与分组数相同,每个卷积层的输入通道数是输入维度的一个分组,输出通道数是输出维度的一个分组。随后,使用 Kaiming 正态分布初始化卷积层的权重,以帮助模型更好地训练。
forward_kacn 方法是该类的核心,负责执行前向传播。首先对输入进行双曲正切激活,然后计算反余弦,接着通过乘以预先定义的 arange 张量来扩展特征,最后通过多项式卷积层和归一化层处理输出。如果设置了 dropout,则在输出前应用 dropout。
forward 方法负责处理整个输入张量。它将输入张量按组分割,然后对每个组调用 forward_kacn 方法进行处理,最后将所有组的输出拼接在一起。
接下来,文件定义了三个子类:KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer,分别用于实现 3D、2D 和 1D 的 KACN 卷积层。这些子类在初始化时调用父类的构造函数,并传入相应的卷积和归一化层类型。
总的来说,这个程序文件实现了一种灵活且可扩展的卷积层,能够适应不同维度的输入,并通过自定义的激活和卷积操作来提高模型的表现。
10.3 fast_kan_conv.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
class RadialBasisFunction(nn.Module):
def init (self, grid_min: float = -2., grid_max: float = 2., num_grids: int = 8, denominator: float = None):
super().init ()
创建一个线性空间的网格,范围从grid_min到grid_max,包含num_grids个点
grid = torch.linspace(grid_min, grid_max, num_grids)
将网格设置为不可训练的参数
self.grid = torch.nn.Parameter(grid, requires_grad=False)
计算分母,默认是网格范围除以网格数量减一
self.denominator = denominator or (grid_max - grid_min) / (num_grids - 1)
def forward(self, x):
# 计算径向基函数的输出
# 通过将输入x与网格进行比较,计算高斯函数的值
return torch.exp(-((x[..., None] - self.grid) / self.denominator) ** 2)class FastKANConvNDLayer(nn.Module):
def init (self, conv_class, norm_class, input_dim, output_dim, kernel_size, groups=1, padding=0, stride=1, dilation=1, ndim: int = 2, grid_size=8, base_activation=nn.SiLU, grid_range=-2, 2, dropout=0.0):
super(FastKANConvNDLayer, self).init ()
初始化输入和输出维度、卷积参数等
self.inputdim = input_dim
self.outdim = output_dim
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.dilation = dilation
self.groups = groups
self.ndim = ndim
self.grid_size = grid_size
self.base_activation = base_activation()
self.grid_range = grid_range
# 验证groups参数的有效性
if groups <= 0:
raise ValueError('groups must be a positive integer')
if input_dim % groups != 0:
raise ValueError('input_dim must be divisible by groups')
if output_dim % groups != 0:
raise ValueError('output_dim must be divisible by groups')
# 创建基础卷积层和样条卷积层
self.base_conv = nn.ModuleList([conv_class(input_dim // groups, output_dim // groups, kernel_size, stride, padding, dilation, groups=1, bias=False) for _ in range(groups)])
self.spline_conv = nn.ModuleList([conv_class(grid_size * input_dim // groups, output_dim // groups, kernel_size, stride, padding, dilation, groups=1, bias=False) for _ in range(groups)])
# 创建归一化层
self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])
# 初始化径向基函数
self.rbf = RadialBasisFunction(grid_range[0], grid_range[1], grid_size)
# 初始化dropout层
self.dropout = None
if dropout > 0:
if ndim == 1:
self.dropout = nn.Dropout1d(p=dropout)
if ndim == 2:
self.dropout = nn.Dropout2d(p=dropout)
if ndim == 3:
self.dropout = nn.Dropout3d(p=dropout)
# 使用Kaiming均匀分布初始化卷积层的权重
for conv_layer in self.base_conv:
nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')
for conv_layer in self.spline_conv:
nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')
def forward_fast_kan(self, x, group_index):
# 对输入应用基础激活函数,并进行线性变换
base_output = self.base_conv[group_index](self.base_activation(x))
if self.dropout is not None:
x = self.dropout(x)
# 计算样条基函数
spline_basis = self.rbf(self.layer_norm[group_index](x))
spline_basis = spline_basis.moveaxis(-1, 2).flatten(1, 2)
# 通过样条卷积层得到输出
spline_output = self.spline_conv[group_index](spline_basis)
# 将基础输出和样条输出相加
x = base_output + spline_output
return x
def forward(self, x):
# 将输入按照组进行分割
split_x = torch.split(x, self.inputdim // self.groups, dim=1)
output = []
for group_ind, _x in enumerate(split_x):
# 对每一组进行快速KAN卷积
y = self.forward_fast_kan(_x.clone(), group_ind)
output.append(y.clone())
# 将所有组的输出拼接在一起
y = torch.cat(output, dim=1)
return y代码核心部分解释:
RadialBasisFunction: 这个类实现了一个径向基函数(RBF),用于生成高斯函数的输出。它通过输入与预定义网格的差异来计算输出。
FastKANConvNDLayer: 这是一个通用的卷积层类,支持多维卷积(1D、2D、3D)。它包含基础卷积和样条卷积,使用径向基函数来增强卷积的表达能力。初始化时会检查参数的有效性,并创建必要的卷积和归一化层。
forward_fast_kan: 这是核心的前向传播方法,首先通过基础卷积处理输入,然后通过样条卷积处理经过归一化和RBF处理的输入,最后将两者的输出相加。
forward: 这个方法负责将输入分割成多个组,并对每个组调用forward_fast_kan,最后将所有组的输出拼接在一起。
这个程序文件 fast_kan_conv.py 实现了一个快速的 KAN 卷积层,主要用于深度学习中的卷积操作。它使用了径向基函数(Radial Basis Function, RBF)来构建卷积层,并且支持多维卷积(1D、2D、3D)。以下是对代码的详细讲解。
首先,文件导入了 PyTorch 库及其神经网络模块。接着定义了一个 RadialBasisFunction 类,这个类继承自 nn.Module,用于生成径向基函数。构造函数中,使用 torch.linspace 创建了一个从 grid_min 到 grid_max 的均匀网格,并将其设置为不可训练的参数。denominator 用于控制基函数的平滑程度,默认值是网格范围除以网格数量减一。
forward 方法实现了径向基函数的计算,输入 x 会被转换为与网格的距离,然后通过指数函数生成基函数的输出。
接下来是 FastKANConvNDLayer 类,它是快速 KAN 卷积层的核心实现。构造函数中,接收多个参数来配置卷积层的行为,包括输入和输出维度、卷积核大小、分组数、填充、步幅、扩张率、维度数、网格大小、基础激活函数、网格范围和 dropout 概率。该类首先进行了一些参数的有效性检查,确保分组数为正整数,并且输入和输出维度可以被分组数整除。
在构造函数中,创建了多个基础卷积层和样条卷积层,分别使用 conv_class 和 norm_class 进行初始化。样条卷积层的输入维度是基于网格大小和输入维度计算的。接着,实例化了一个 RadialBasisFunction 对象用于生成基函数。
如果 dropout 概率大于零,根据维度数选择相应的 dropout 类型。最后,使用 Kaiming 均匀分布初始化卷积层的权重,以便于更好的训练开始。
forward_fast_kan 方法实现了快速 KAN 卷积的前向传播。它首先对输入应用基础激活函数,然后进行线性变换。接着,计算经过层归一化后的输入的样条基函数,并将其传递给样条卷积层。最终,基础输出和样条输出相加,得到最终的输出。
forward 方法将输入 x 按照分组数进行拆分,并对每个分组调用 forward_fast_kan 方法进行处理,最后将所有分组的输出拼接在一起。
最后,定义了三个类 FastKANConv3DLayer、FastKANConv2DLayer 和 FastKANConv1DLayer,分别继承自 FastKANConvNDLayer,用于实现 3D、2D 和 1D 的快速 KAN 卷积层。这些类在初始化时调用父类的构造函数,并指定相应的卷积和归一化类。
总体而言,这个文件实现了一个灵活且高效的卷积层,能够在多维数据上进行卷积操作,并利用径向基函数增强了模型的表达能力。
10.4 metaformer.py
以下是保留的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MF_Attention(nn.Module):
"""
实现Transformer中的自注意力机制: https://arxiv.org/abs/1706.03762.
"""
def init (self, dim, head_dim=32, num_heads=None, qkv_bias=False,
attn_drop=0., proj_drop=0., proj_bias=False):
super().init()
# 设置每个头的维度和头的数量
self.head_dim = head_dim
self.scale = head_dim ** -0.5 # 缩放因子
self.num_heads = num_heads if num_heads else dim // head_dim
if self.num_heads == 0:
self.num_heads = 1
self.attention_dim = self.num_heads * self.head_dim
# 定义Q、K、V的线性变换
self.qkv = nn.Linear(dim, self.attention_dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop) # 注意力的dropout
self.proj = nn.Linear(self.attention_dim, dim, bias=proj_bias) # 输出的线性变换
self.proj_drop = nn.Dropout(proj_drop) # 输出的dropout
def forward(self, x):
B, H, W, C = x.shape # B: 批量大小, H: 高度, W: 宽度, C: 通道数
N = H * W # 计算总的token数量
# 计算Q、K、V
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # 将Q、K、V分开
# 计算注意力分数
attn = (q @ k.transpose(-2, -1)) * self.scale # 矩阵乘法并缩放
attn = attn.softmax(dim=-1) # softmax归一化
attn = self.attn_drop(attn) # 应用dropout
# 计算输出
x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim) # 加权求和
x = self.proj(x) # 线性变换
x = self.proj_drop(x) # 应用dropout
return xclass Mlp(nn.Module):
"""
实现多层感知机(MLP),用于MetaFormer模型。
"""
def init (self, dim, mlp_ratio=4, out_features=None, act_layer=nn.ReLU, drop=0., bias=False):
super().init ()
in_features = dim
out_features = out_features or in_features
hidden_features = int(mlp_ratio * in_features) # 隐藏层特征数
drop_probs = (drop, drop) # dropout概率
# 定义MLP的两层线性变换
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)
self.act = act_layer() # 激活函数
self.drop1 = nn.Dropout(drop_probs[0]) # 第一个dropout
self.fc2 = nn.Linear(hidden_features, out_features, bias=bias)
self.drop2 = nn.Dropout(drop_probs[1]) # 第二个dropout
def forward(self, x):
x = self.fc1(x) # 第一层线性变换
x = self.act(x) # 激活
x = self.drop1(x) # 第一个dropout
x = self.fc2(x) # 第二层线性变换
x = self.drop2(x) # 第二个dropout
return xclass MetaFormerBlock(nn.Module):
"""
实现一个MetaFormer块。
"""
def init (self, dim,
token_mixer=nn.Identity, mlp=Mlp,
norm_layer=nn.LayerNorm,
drop=0., drop_path=0.,
layer_scale_init_value=None, res_scale_init_value=None):
super().init()
self.norm1 = norm_layer(dim) # 第一层归一化
self.token_mixer = token_mixer(dim=dim, drop=drop) # token混合器
self.drop_path1 = nn.Identity() if drop_path <= 0. else nn.Dropout(drop_path) # 路径dropout
self.layer_scale1 = nn.Identity() if layer_scale_init_value is None else nn.Parameter(torch.ones(dim) * layer_scale_init_value) # 层缩放
self.res_scale1 = nn.Identity() if res_scale_init_value is None else nn.Parameter(torch.ones(dim) * res_scale_init_value) # 残差缩放
self.norm2 = norm_layer(dim) # 第二层归一化
self.mlp = mlp(dim=dim, drop=drop) # MLP
self.drop_path2 = nn.Identity() if drop_path <= 0. else nn.Dropout(drop_path) # 路径dropout
self.layer_scale2 = nn.Identity() if layer_scale_init_value is None else nn.Parameter(torch.ones(dim) * layer_scale_init_value) # 层缩放
self.res_scale2 = nn.Identity() if res_scale_init_value is None else nn.Parameter(torch.ones(dim) * res_scale_init_value) # 残差缩放
def forward(self, x):
x = x.permute(0, 2, 3, 1) # 转换维度
x = self.res_scale1(x) + self.layer_scale1(self.drop_path1(self.token_mixer(self.norm1(x)))) # 第一部分
x = self.res_scale2(x) + self.layer_scale2(self.drop_path2(self.mlp(self.norm2(x)))) # 第二部分
return x.permute(0, 3, 1, 2) # 转换回原始维度代码说明:
MF_Attention: 实现了自注意力机制,包含了Q、K、V的计算,注意力分数的计算,以及最终的输出变换。
Mlp: 实现了一个简单的多层感知机,包含两个线性层和激活函数,支持dropout。
MetaFormerBlock: 组合了归一化、token混合、MLP等操作,形成一个完整的MetaFormer块。支持残差连接和层缩放。
这些类是构建MetaFormer模型的核心组件,分别负责自注意力计算、MLP操作和模块组合。
这个程序文件 metaformer.py 实现了一种名为 MetaFormer 的深度学习模型,主要用于处理图像数据。文件中定义了多个类,每个类代表模型中的一个组件或操作。以下是对代码的详细说明。
首先,导入了一些必要的库,包括 torch 和 torch.nn,以及一些特定的模块,如 DropPath 和 to_2tuple。这些库提供了构建神经网络所需的基本功能。
接下来,定义了多个模块。Scale 类用于通过元素乘法对输入向量进行缩放。SquaredReLU 和 StarReLU 是自定义的激活函数,分别实现了平方的 ReLU 和带有可学习缩放和偏置的 StarReLU。
MF_Attention 类实现了基本的自注意力机制,采用了多头注意力的方式。它将输入的特征通过线性变换生成查询、键和值,然后计算注意力权重,并通过这些权重对值进行加权求和,最后通过线性层进行投影。
RandomMixing 类实现了一种随机混合操作,使用一个随机生成的矩阵对输入进行变换,旨在增加模型的多样性。
LayerNormGeneral 类实现了一种通用的层归一化,可以适应不同的输入形状和归一化维度。它允许选择是否使用缩放和偏置,并支持多种输入格式。
LayerNormWithoutBias 类是一个优化过的层归一化实现,不使用偏置,直接调用了 PyTorch 的 F.layer_norm 函数。
SepConv 类实现了分离卷积,采用了深度可分离卷积的结构,首先通过一个线性层进行逐点卷积,然后进行深度卷积,最后再通过另一个线性层进行输出。
Pooling 类实现了一种特定的池化操作,旨在从输入中提取特征并减去原始输入,以实现特征增强。
Mlp 类实现了多层感知机(MLP),包含两个线性层和激活函数,支持 dropout 操作。
ConvolutionalGLU 类实现了一种卷积门控线性单元(GLU),结合了卷积操作和门控机制,以增强特征提取能力。
MetaFormerBlock 和 MetaFormerCGLUBlock 类分别实现了 MetaFormer 的基本块,包含了归一化、token 混合、MLP 和残差连接等操作。它们通过组合不同的模块,形成了更复杂的网络结构。
整个文件的设计旨在提供灵活的组件,使得用户可以根据需要构建不同的 MetaFormer 模型。每个模块都经过精心设计,以便在图像处理任务中实现高效的特征提取和信息传递。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻