执行一条SQL请求的过程是什么?
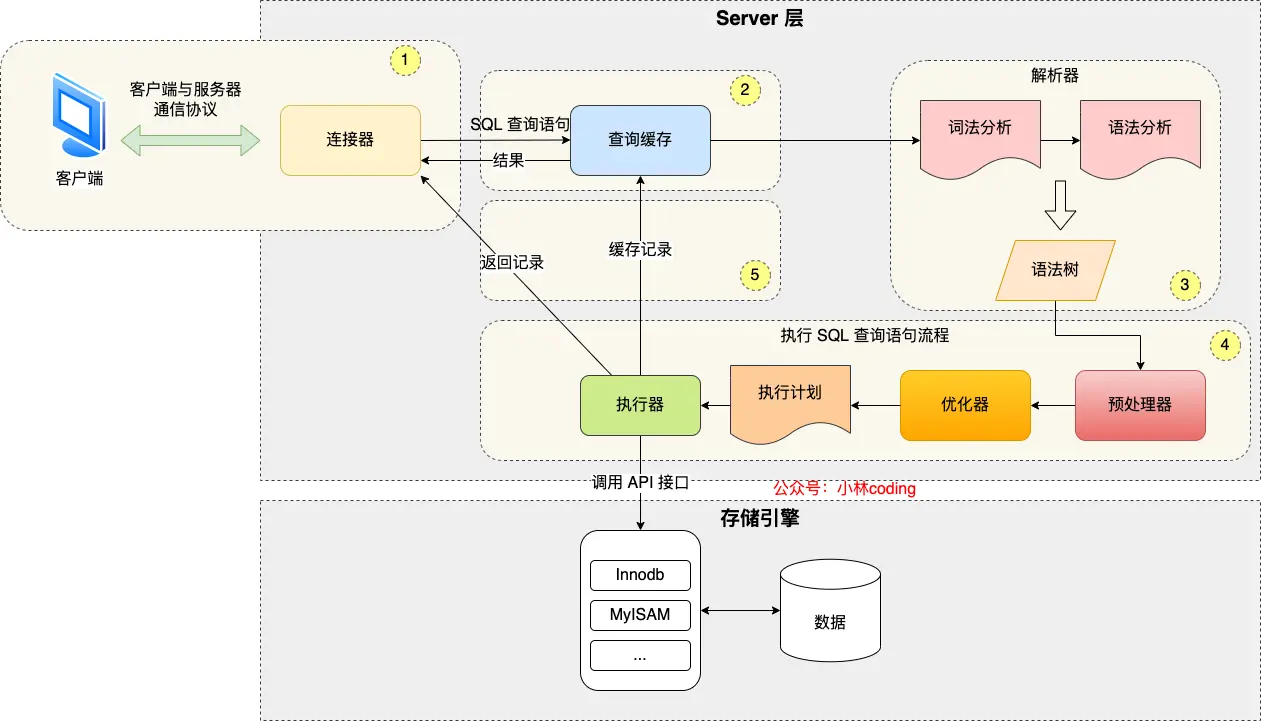
面试官您好,一条SQL查询语句在MySQL中的执行过程,是一个分工明确、层层递进的流水线作业。要理解这个过程,我们首先要了解MySQL的两大核心组件:Server层 和存储引擎层。
- Server层:负责建立连接、解析和优化SQL、管理事务等,这是MySQL的"大脑"。
- 存储引擎层 (如InnoDB):负责数据的实际存储和提取,这是MySQL的"双手和仓库"。
现在,我们可以把一次SQL查询,想象成一个顾客在一家大餐厅点餐的全过程:
第一步:门口迎宾与身份确认 (连接器 - Connector)
- 餐厅的比喻:顾客(客户端)来到餐厅门口,迎宾(连接器)会上前接待。
- MySQL的工作 :
- 客户端发起连接请求,连接器负责完成TCP握手。
- 然后,连接器会验证用户的身份(用户名和密码)。
- 验证通过后,它会检查用户的权限,看用户有哪些操作许可。
- 最后,它会从连接池中分配一个连接给客户端,或者建立一个新的连接。此后的所有操作,都在这个连接上进行。
第二步:服务员下单与理解菜单 (解析器 - Parser)
- 餐厅的比喻 :顾客点了一道菜(
SELECT * FROM users WHERE id = 1),服务员(解析器)拿出点单本。 - MySQL的工作 :
- 词法分析 :首先,解析器会将SQL语句打散成一个个最小的、不可再分的"单词"(Token),比如
SELECT,*,FROM,users等。 - 语法分析 :然后,它会根据MySQL的语法规则,来判断这条语句的语法是否正确。如果不正确(比如写成了
SELECT FROM users),就会直接报错。 - 构建语法树 :语法分析通过后,解析器会构建出一棵抽象语法树(AST)。这棵树清晰地表达了这条SQL要"做什么",比如"要查询"、"从users表"、"条件是id=1"。
- 词法分析 :首先,解析器会将SQL语句打散成一个个最小的、不可再分的"单词"(Token),比如
第三步:主厨的烹饪方案决策 (优化器 - Optimizer)
- 餐厅的比喻 :服务员把点菜单交给了主厨(优化器) 。主厨是整个厨房的灵魂,他要决定这道菜 "如何做才最高效"。
- MySQL的工作 :这是决定SQL查询性能最核心、最关键 的一步。优化器会根据语法树,并结合MySQL的统计信息,生成最终的执行计划(Execution Plan) 。
- 它会做大量的优化决策,比如:
- 选择最优索引 :这条
WHERE语句,是走主键索引快,还是走某个二级索引更快? - 决定表的连接顺序:对于多表JOIN,是先驱动A表再关联B表,还是反过来?
- 优化子查询等等。
- 选择最优索引 :这条
- 优化器的目标是找到一个成本最低的执行方案。
- 它会做大量的优化决策,比如:
第四步:厨师按菜谱操作 (执行器 - Executor)
- 餐厅的比喻 :主厨把最终的"菜谱"(执行计划)交给了厨师(执行器)。
- MySQL的工作 :
- 执行器在执行前,会再次检查用户是否有查询这张表的权限。
- 然后,它会完全按照执行计划,一步步地去调用存储引擎层提供的接口来操作数据。
- 比如,执行计划说"请使用
users表的主键索引,查找id=1的记录",执行器就会调用InnoDB引擎的接口,去获取这行数据。 - 执行器拿到存储引擎返回的数据后,可能会进行一些加工(比如排序、分组),最终将结果集返回给客户端。
关于查询缓存 (Query Cache)
- 在MySQL 8.0之前,还有一个查询缓存 模块,它位于解析器之前。如果一个SQL能完全命中缓存,就会直接返回结果。但由于缓存的命中条件极其苛刻(SQL语句和参数必须一模一样),且任何对表的更新都会导致该表所有缓存失效,维护成本高而命中率低,因此在MySQL 8.0中被彻底移除了。
总结一下 ,一条SQL的旅程就是:通过连接器 建立连接,由解析器 将其翻译成"机器能懂的语言"(语法树),再由优化器 制定出"最高效的执行方案",最后由执行器 调用存储引擎来完成实际的数据操作。
讲一讲MySQL的引擎吧,你有什么了解?
面试官您好,MySQL的存储引擎是其可插拔式架构的一大特色。它允许我们为不同的数据表选择不同的底层存储和处理机制,以适应不同的业务场景。
在众多存储引擎中,我主要熟悉和使用过以下三种最经典的引擎:
1. InnoDB:现代MySQL的"全能王者"(默认引擎)
InnoDB是MySQL 5.5之后默认的存储引擎 ,也是现在绝大多数应用场景的事实标准 。它是一个为高并发、高可靠性的在线事务处理(OLTP)场景而设计的、功能全面的引擎。
-
核心特性:
- 支持ACID事务 :这是它最重要的特性。
InnoDB提供了完整的事务支持,包括提交、回滚、以及崩溃恢复能力,能最大限度地保证数据的强一致性。 - 行级锁 (Row-Level Locking) :当进行更新或删除操作时,
InnoDB只锁定需要修改的行 ,而不是整张表。这使得它在高并发的读写场景下,性能表现极其出色,锁冲突的概率大大降低。 - 支持外键约束 (Foreign Key):能够在数据库层面强制保证数据的引用完整性。
- MVCC (多版本并发控制) :
InnoDB通过MVCC机制,实现了非阻塞的读操作,做到了"读写不加锁",极大地提升了并发读取的性能。
- 支持ACID事务 :这是它最重要的特性。
-
适用场景 :绝大多数的业务场景 ,特别是那些对数据一致性要求高、且有大量并发写入的应用,比如电商系统、金融系统、社交应用等。
2. MyISAM:曾经的"速度之星"
在InnoDB成为默认引擎之前,MyISAM是MySQL的默认引擎,它以其简单、高速的读取性能而闻名。
-
核心特性:
- 不支持事务 :这是它与
InnoDB最本质的区别,它不支持ACID。 - 表级锁 (Table-Level Locking) :
MyISAM的锁粒度非常粗。任何一个写操作(INSERT,UPDATE,DELETE)都会锁定整张表。这意味着,在写入时,所有其他的读写操作都必须排队等待。 - 不支持外键。
- 存储与索引 :它会将表数据(
.MYD文件)和索引(.MYI文件)分开存储。 - 一个特殊的优势 :它内部维护了一个计数器,所以执行
COUNT(*)来查询全表总行数时,速度极快,几乎是瞬间完成。
- 不支持事务 :这是它与
-
适用场景:
- 适用于那些 "读多写少"、甚至是纯粹的只读报表类应用。
- 对事务完整性要求不高的场景。
- 因为是表级锁,所以不适合高并发写入的场景。
3. Memory (HEAP):"快如闪电"的内存引擎
-
核心特性:
- 数据存储在内存中:这是它最大的特点,也是它速度极快的原因。
- 数据易失性 :因为数据在内存中,所以一旦数据库服务器重启或崩溃,表中的所有数据都会丢失。
- 不支持事务和外键 ,同样使用表级锁。
-
适用场景:
- 用于存储那些临时的、非持久化的、需要被高速访问的数据。
- 比如,用作一些查询的临时中间表,或者一些需要频繁访问的、但可以从其他地方重建的配置数据或缓存数据。
总结与选型
| 特性 | InnoDB (全能型) | MyISAM (读取型) | Memory (临时型) |
|---|---|---|---|
| 事务 | 支持 (ACID) | 不支持 | 不支持 |
| 锁级别 | 行级锁 | 表级锁 | 表级锁 |
| 外键 | 支持 | 不支持 | 不支持 |
| MVCC | 支持 | 不支持 | 不支持 |
| 崩溃恢复 | 支持 | 不支持 | 数据直接丢失 |
COUNT(*) |
扫表 (较慢) | 极快 | 较快 |
我的选型决策:
- 在今天,对于任何需要持久化存储的业务数据,我都会毫不犹豫地选择
InnoDB。它的功能全面性、数据安全性以及在高并发下的优秀表现,使其成为了无可替代的通用选择。 MyISAM和Memory则作为特殊用途 的引擎,只在一些非常特定的、能容忍其缺点的场景下(如纯读报表、临时数据缓存)才会考虑使用。
MySQL为什么InnoDB是默认引擎?
面试官您好,InnoDB之所以能够取代MyISAM,并在MySQL 5.5版本之后成为默认的存储引擎 ,其根本原因在于,InnoDB的设计和功能,完美地契合了现代互联网应用对数据处理的核心需求:高并发、高可靠性和数据强一致性。
我们可以从以下几个关键特性来理解,为什么InnoDB是现代应用的不二之选:
1. 强大的事务支持 (ACID) ------ 数据一致性的基石
- 现代应用的需求 :在绝大多数业务场景中,特别是电商、金融、社交 等领域,一系列数据库操作必须被当作一个不可分割的整体 来执行。比如,一个转账操作,必须保证"A账户扣款"和"B账户加款"这两个动作要么都成功,要么都失败。
- InnoDB的解决方案 :InnoDB提供了完整的ACID事务支持 。通过
START TRANSACTION,COMMIT,ROLLBACK等命令,它可以将多个SQL操作打包成一个逻辑单元,从而从数据库层面,强制保证了业务逻辑的数据一致性。 - MyISAM的短板 :MyISAM不支持事务。如果使用MyISAM来执行转账,一旦在扣款成功后、加款前发生系统崩溃,就会导致"钱凭空消失"的严重数据不一致问题。
2. 行级锁 (Row-Level Locking) ------ 高并发写入的保障
- 现代应用的需求 :互联网应用通常面临着海量的用户并发访问,特别是高并发的写入操作(比如秒杀场景下的下单、扣库存)。
- InnoDB的解决方案 :InnoDB采用了行级锁 。当一个事务需要修改某一行数据时,它只锁定这一行 ,而不会影响到其他线程对同一张表中其他行的读写。这极大地降低了锁的粒度 ,使得在高并发写入时,线程之间互相等待和阻塞的可能性大大减少,从而提供了极高的并发处理能力。
- MyISAM的短板 :MyISAM只支持表级锁。任何一个写操作都会锁定整张表。这意味着,当一个线程在修改表中的某一行时,所有其他想对这张表进行任何读写操作的线程,都必须排队等待。在高并发写入场景下,这会造成严重的性能瓶颈。
3. MVCC (多版本并发控制) ------ 高并发读取的利器
- InnoDB的另一个"黑科技" :除了行级锁,InnoDB还通过MVCC 机制,实现了非阻塞的读操作。
- 工作原理 :对于
SELECT查询,InnoDB通常不会去加锁,而是通过读取一个"快照"版本的数据,来实现"读写不冲突"。一个事务在读取数据时,另一个事务可以同时修改它,两者互不干扰。 - 结果 :这使得InnoDB在处理 "读多写多" 的混合并发场景时,性能极其出色。
4. 崩溃恢复能力 (Crash Recovery) ------ 数据可靠性的保障
- 现代应用的需求:生产系统必须是高可靠的,不能因为服务器突然断电或宕机,就导致已经提交的事务数据丢失。
- InnoDB的解决方案 :InnoDB拥有一套完善的日志系统,包括Redo Log(重做日志)和Undo Log(回滚日志) 。
- 通过Redo Log,InnoDB保证了所有已提交的事务,即使在数据库崩溃后,也能够通过日志进行前滚恢复 ,确保数据的持久性。
- MyISAM的短板 :MyISAM不具备崩溃恢复能力。如果服务器宕机,MyISAM表很可能会损坏,需要手动进行修复,且可能导致数据丢失。
总结一下 ,InnoDB凭借其对事务、行级锁、MVCC和崩溃恢复 的全面支持,构建了一个既能保证数据强一致性 和高可靠性 ,又能应对高并发读写 的强大存储引擎。这些特性,恰恰是现代OLTP(在线事务处理)应用最核心、最不可或缺的能力。因此,它取代MyISAM成为默认引擎,是技术发展的必然选择。
说一下MySQL的InnoDB与MyISAM的区别?
面试官您好,InnoDB和MyISAM是MySQL中最著名的两种存储引擎,它们在设计哲学和底层实现上有着本质的区别,这也决定了它们完全不同的适用场景。
我通常会从以下几个核心维度来对比它们:
1. 核心功能与可靠性:事务与外键
- InnoDB : 支持事务 (ACID) 。这是它最大的优势。它支持提交、回滚和崩溃恢复,能从数据库层面保证业务操作的原子性和数据一致性。同时,它也支持外键约束。
- MyISAM : 不支持事务和外键。这意味着,它无法保证复杂操作的数据一致性,一旦发生断电等意外,数据很可能处于一个中间状态。
- 影响 : 这一点直接决定了InnoDB是在线事务处理(OLTP) 应用(如电商、金融系统)的不二之选,而MyISAM则不适合这类对数据一致性要求高的场景。
2. 并发性能:锁的粒度
- InnoDB : 支持行级锁 (Row-Level Locking) ,并且通过MVCC(多版本并发控制) 实现了非阻塞的读。
- 优势 : 当进行写操作时,只锁定需要修改的行,大大减少了锁冲突,使得高并发的读写性能非常出色。
- MyISAM : 只支持表级锁 (Table-Level Locking) 。
- 劣势 : 任何一个
UPDATE或INSERT都会锁定整张表,导致其他所有读写操作都必须排队等待。在高并发写入的场景下,性能会急剧下降。
- 劣势 : 任何一个
- 影响 : InnoDB能够轻松应对高并发的混合读写负载,而MyISAM只适合 "读多写少" 的场景。
3. 索引结构与数据存储:聚簇 vs. 非聚簇
这是两者在物理存储上的一个根本区别,也深刻地影响了它们的查询性能。
-
InnoDB : 采用聚簇索引 (Clustered Index)。
- 结构 : 数据文件本身就是按照主键顺序组织的一棵B+树 ,叶子节点直接存储了完整的行数据。
- 优点 : 通过主键查询时,速度极快,因为找到索引就等于找到了数据,只需一次I/O。
- 缺点 :
- 辅助索引(二级索引)需要"回表" :辅助索引的叶子节点存储的是主键的值 。因此,通过辅助索引查询时,需要先找到主键值,再用主键值去聚簇索引中找到完整的行数据,这需要两次I/O。
- 主键的选择很关键: 正如您所说,主键不宜过大,因为所有辅助索引都会包含它;使用自增ID作为主键,可以保证新数据总是在末尾插入,避免了页分裂,性能最好。
-
MyISAM : 采用非聚簇索引 (Non-Clustered Index)。
- 结构 : 数据文件 (
.MYD) 和索引文件 (.MYI) 是相互分离的。 - 特点 : 无论是主键索引还是辅助索引,它们的叶子节点存储的都是一个指向数据文件中物理行位置的指针。
- 优缺点 : 主键查询和辅助索引查询的性能没有本质区别,都需要一次索引查询和一次数据文件查询。
- 结构 : 数据文件 (
4. 其他差异
COUNT(*)的效率 :- MyISAM : 内部维护了一个计数器,执行
SELECT COUNT(*) FROM table时,直接返回这个计数值,速度极快。 - InnoDB : 不保存这个计数值(因为MVCC的存在,不同事务看到的行数可能不同),需要进行全表扫描来计算总行数,当数据量大时,效率较低。
- MyISAM : 内部维护了一个计数器,执行
- 文件结构 :
- MyISAM : 每个表对应三个文件:
.frm(表结构)、.MYD(数据)、.MYI(索引)。 - InnoDB : 通常,所有表的数据和索引都存储在同一个表空间文件 (如
ibdata1)中,也可以配置为"独立表空间",让每个表对应一个.ibd文件。
- MyISAM : 每个表对应三个文件:
总结与选型
| 特性 | InnoDB (默认) | MyISAM |
|---|---|---|
| 事务 | 支持 | 不支持 |
| 锁级别 | 行级锁 | 表级锁 |
| 外键 | 支持 | 不支持 |
| MVCC | 支持 | 不支持 |
| 索引 | 聚簇索引 | 非聚簇索引 |
| 崩溃恢复 | 支持 | 不支持 |
结论:
- 在今天的应用开发中,对于所有需要高并发、数据一致性、高可靠性 的业务表,InnoDB是唯一的、也是最佳的选择。这也是为什么它会成为MySQL的默认存储引擎。
MyISAM则可以作为一种补充 ,用于一些对事务和并发写入要求不高的、以读取和分析为主 的场景,比如一些日志表、数据仓库的维度表等,可以利用其COUNT(*)快的特性。
数据管理里,数据文件大体分成哪几种数据文件?
面试官您好,在数据库管理中,特别是以MySQL的InnoDB存储引擎 为例,从物理存储的角度看,它的数据文件大体上可以分为三大类 :表空间文件、日志文件、以及其他辅助性文件。
第一类:表空间文件 (Tablespace Files) ------ 数据的最终归宿
这是真正存储我们表数据和索引的地方。InnoDB的表空间可以有两种管理模式:
-
共享表空间 (Shared Tablespace)
- 文件名 :通常是
ibdata1文件。 - 特点 :在默认配置下,所有数据库的所有表的数据和索引,都会被存放在这一个(或多个)共享的表空间文件中。
- 优点:管理相对简单。
- 缺点 :
- 难以管理:整个文件会随着数据增长而不断变大,即使删除了某个表,其占用的空间也很难被回收给操作系统,容易导致文件只增不减。
- 性能瓶颈:所有表的I/O操作都集中在一个文件上,可能成为性能瓶颈。
- 文件名 :通常是
-
独立表空间 (File-per-Table Tablespace) ------ 推荐的最佳实践
- 文件名 :每个表都会有自己独立的
.ibd文件(例如,users.ibd)。 - 如何开启 :这个模式在MySQL 5.6.6之后的版本中是默认开启 的,由参数
innodb_file_per_table = ON控制。 - 特点 :一张表的数据、索引、以及其他元数据,都独立地存储在它自己的
.ibd文件中 。共享表空间ibdata1此时只存放一些公共的系统数据,如数据字典、Undo日志等。 - 优点 :
- 管理方便 :删除或
TRUNCATE一张表时,可以直接删除对应的.ibd文件,空间会立刻被回收给操作系统。 - 性能更好:不同表的I/O操作分散在不同的文件中。
- 便于备份和恢复:可以对单个表进行物理备份和恢复。
- 管理方便 :删除或
- 结论 :在现代MySQL实践中,使用独立表空间是绝对的标准和最佳实践。
- 文件名 :每个表都会有自己独立的
第二类:日志文件 (Log Files) ------ 可靠性的保障
这些日志文件不直接存储表数据,但它们是保证InnoDB实现ACID特性 ,特别是持久性(Durability) 和崩溃恢复(Crash Recovery) 能力的关键。
-
重做日志 (Redo Log)
- 文件名 :通常是两个或多个名为
ib_logfile0,ib_logfile1的文件。 - 作用 :实现了WAL(Write-Ahead Logging)技术。当有数据需要修改时,InnoDB会先将这个修改操作以日志的形式,顺序地写入Redo Log文件(这非常快),然后再慢慢地将数据刷回到磁盘上的表空间文件中。
- 价值 :
- 提升性能:将随机的磁盘写操作,转换为了顺序的日志写操作,大大提升了写入性能。
- 崩溃恢复:如果数据库在数据还未完全刷盘时就宕机了,重启后,MySQL可以通过重放Redo Log中的记录,来恢复那些已经提交但未持久化的事务,保证数据不丢失。
- 文件名 :通常是两个或多个名为
-
撤销日志 (Undo Log)
- 存储位置 :它通常存储在共享表空间(
ibdata1) 中,也可以配置为独立的Undo表空间。 - 作用 :记录了数据被修改之前的"旧版本"。
- 价值 :
- 事务回滚 :当一个事务需要
ROLLBACK时,InnoDB就利用Undo Log中的旧数据来恢复到修改之前的状态。 - MVCC实现:在多版本并发控制中,当一个事务需要读取某一行数据,而这一行正在被另一个未提交的事务所修改时,InnoDB会通过Undo Log,找到这一行的"上一个版本"的数据返回给它,从而实现了非阻塞的读。
- 事务回滚 :当一个事务需要
- 存储位置 :它通常存储在共享表空间(
第三类:其他辅助性文件
-
二进制日志 (Binary Log / binlog)
- 这不是InnoDB特有的,而是MySQL Server层的日志。
- 作用 :记录了所有对数据库进行修改的SQL语句(或行的变更)。
- 价值 :
- 主从复制:在主从架构中,从库就是通过读取和重放主库的binlog,来实现数据同步的。
- 数据恢复:可以用于进行基于时间点的恢复(Point-in-Time Recovery)。
-
表定义文件 (
.frm)- 在MySQL 8.0之前,每个表都有一个
.frm文件,用于存储表的结构定义(字段、类型等)。在MySQL 8.0之后,这部分信息被统一存储在了数据字典中。
- 在MySQL 8.0之前,每个表都有一个
总结一下 ,MySQL的数据文件可以看作一个体系:.ibd文件是数据的"家" ,Redo/Undo Log是保证这个家"安全可靠"的保险和记录系统 ,而binlog则是整个小区(MySQL Server)的"监控录像",用于备份和同步。