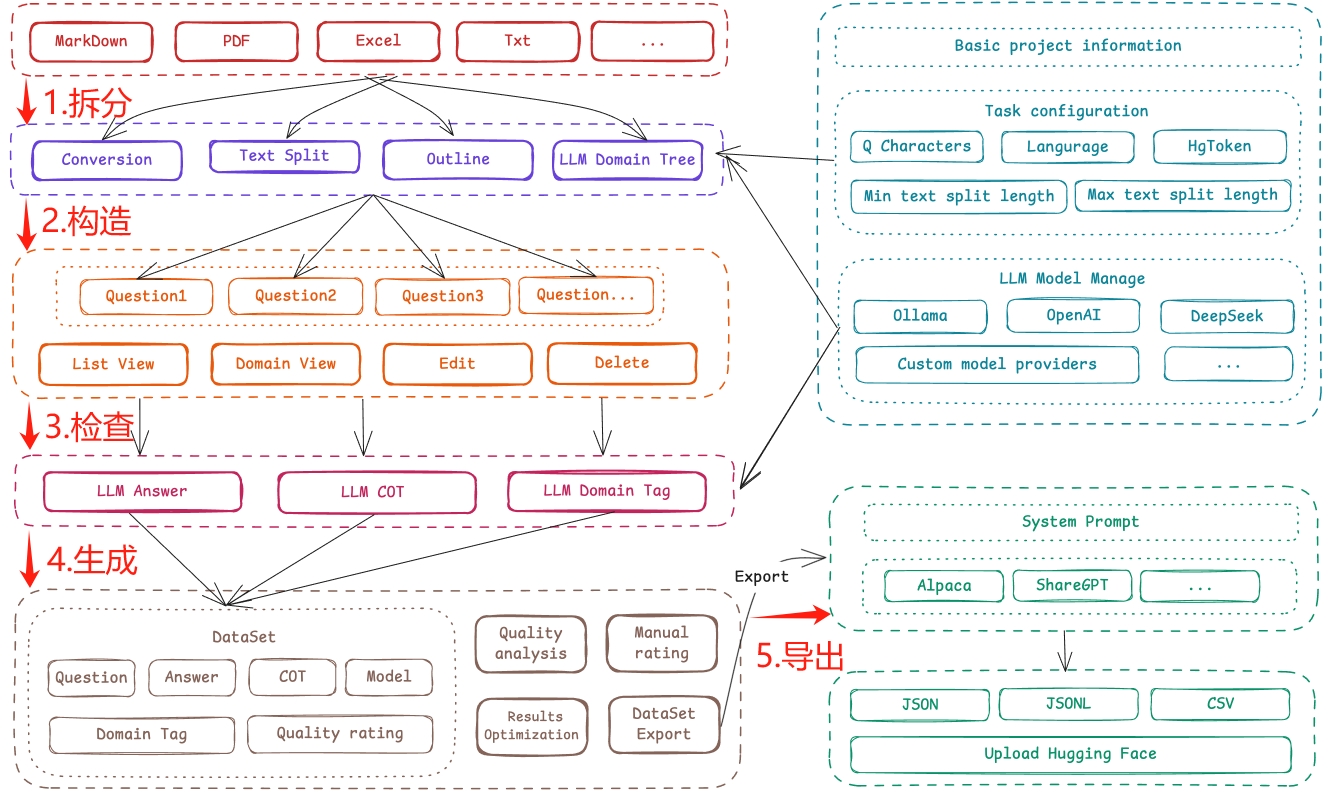
一、概述
Easy Dataset是一个专门为大型语言模型(LLM)创建微调数据集而设计的应用程序。它提供了一个直观的界面,用于上传特定领域的文件、智能分割内容、生成问题以及为模型微调生成高质量的训练数据。
使用Easy Dataset,您可以将领域知识转换为结构化数据集,与遵循OpenAI格式的所有LLM API兼容,使微调过程简单高效。
二、项目安装
项目的安装比较方便,有3种方式:
1.客户端安装:
比较简单,直接下载客户端,安装后即可使用。
2.源码安装:
可以修改源代码,功能调整,自主性较好。
源代码下载
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset安装依赖项
npm install启动开发服务器
npm run build
npm run start3.Docker容器安装:
克隆代码库
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset构建 Docker 映像
docker build -t easy-dataset .运行容器
docker run -d -p 1717:1717 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset easy-dataset注意:需要修改YOUR_LOCAL_DB_PATH为你自己的数据存储路径。
打开浏览器并导航至http://localhost:1717
本文使用第一种方式,下载windows客户端
https://github.com/ConardLi/easy-dataset/releases/tag/1.3.7
下载完成后,双击exe程序,下一步,下一步安装即可,很简单。
安装完成后,效果如下:
三、项目使用
准备原始文件
下载《网络安全法规摘编手册》pdf文件,这个是由兰州大学编写的。兰州大学是中国教育部直属的全国重点综合性大学,位列国家"双一流"、"985工程"和"211工程",属于中国高校第一梯队的中上水平。
链接如下:
https://jchyxy.lzu.edu.cn/jcyxy/upload/files/N20211112170341.pdf
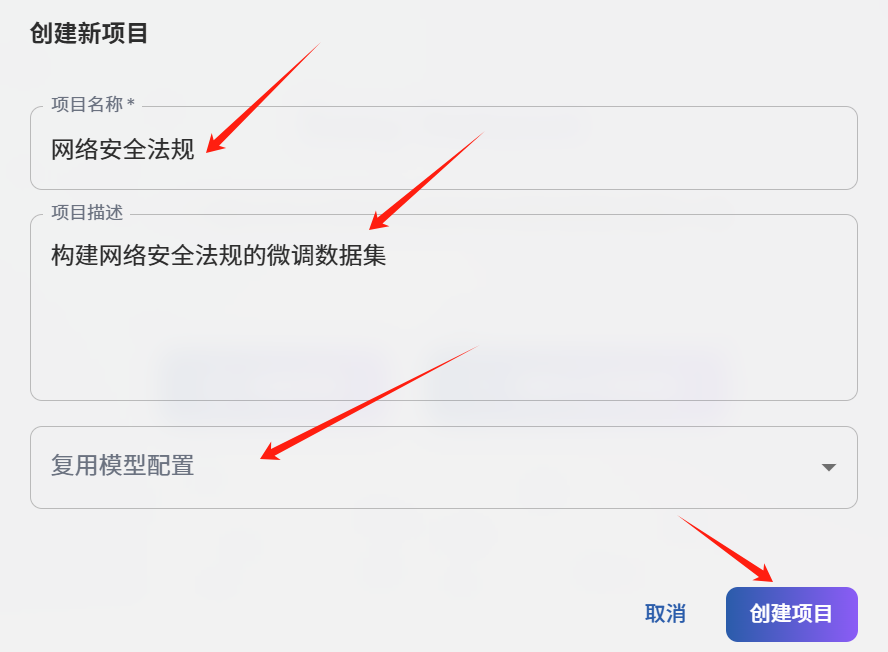
创建新项目
创建项目"网络安全法规",本文以生成法律法规的领域数据为例。如图所示。
项目名称:网络安全法规
项目描述:构建网络安全法规的微调数据集
模型配置
由于pdf文件比较大,有5M左右,可能会耗费很多tokens,使用收费的,有的不划算,所以打算本地启动大模型。
使用LM Studio软件,启动一个deepseek-r1-distill-llama-8b模型
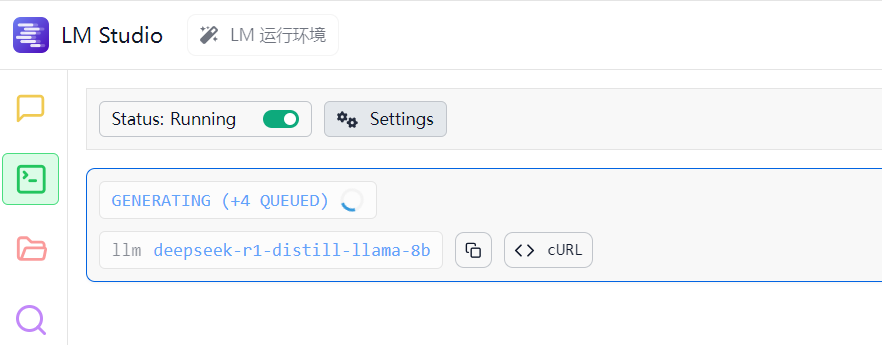
注意:模型最好选择deepseek-r1,v1,v3都行。
我测试用qwen3扫描pdf文件批量生成问题,有异常。
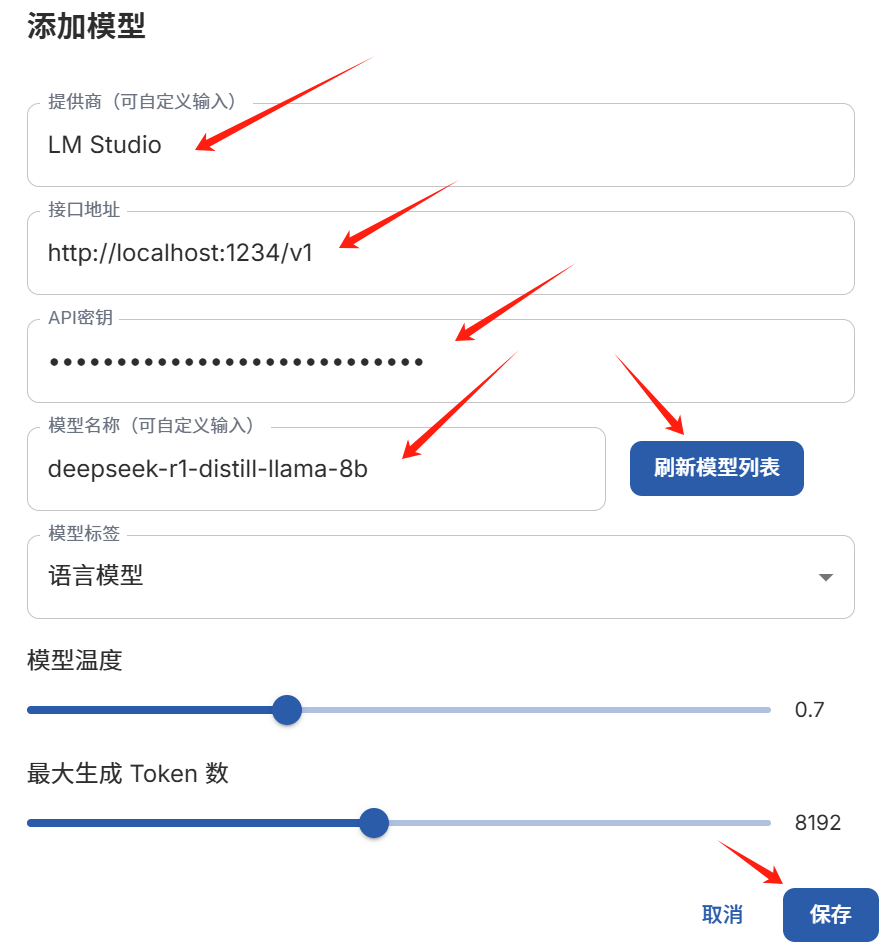
项目创建完成后,进行模型配置,这一步可以根据各自情况配置,配置也非常简单,选择"项目设置" -> "模型配置",如下图
确保刷新模型,能刷新出模型列表,然后选择即可。
拆分文本
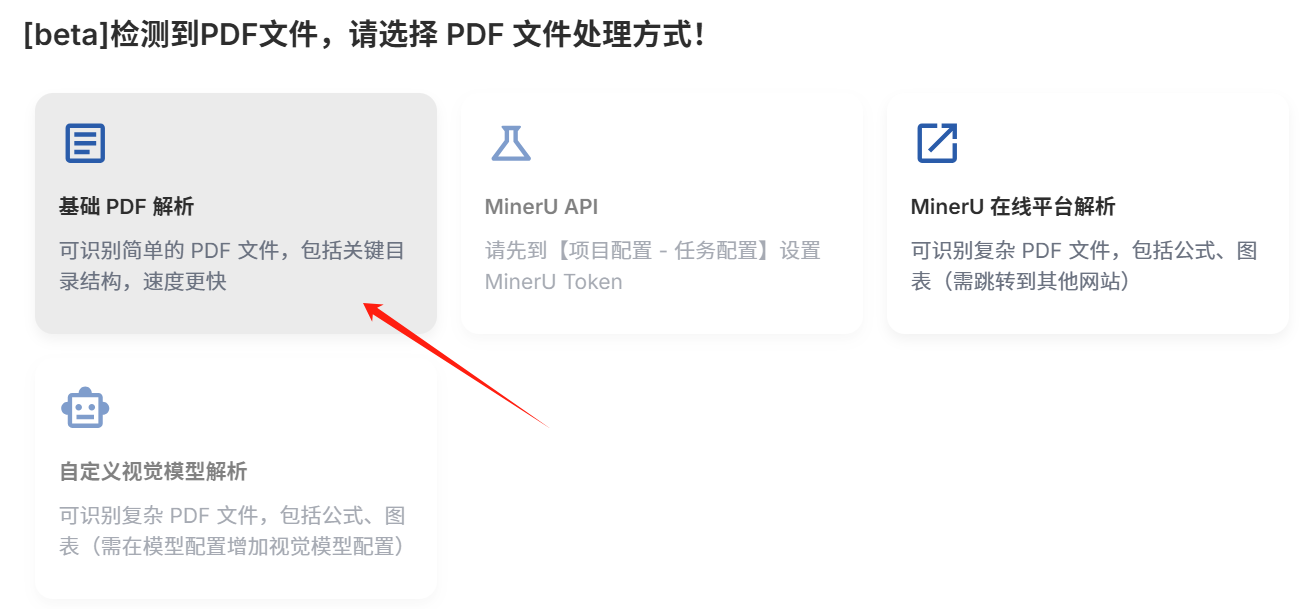
选择"文献处理",右边要选择AI模型,否则无法上传

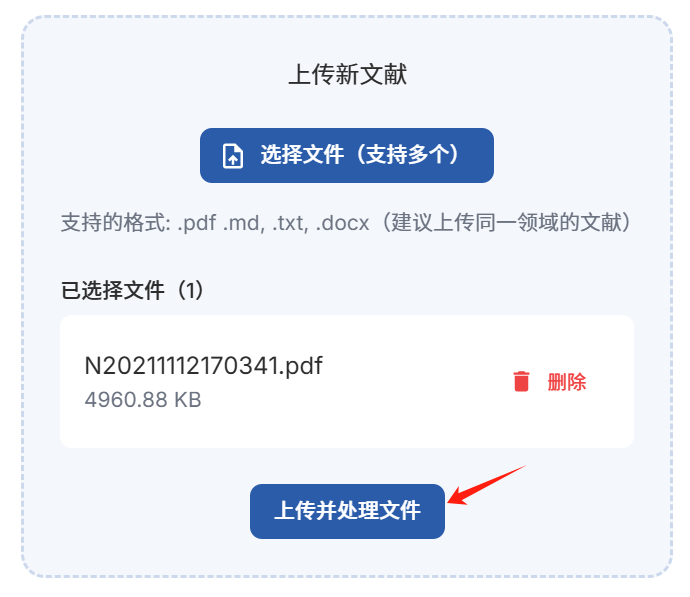
上传准备好的行业数据MD文件,选择基础PDF解析
点击上传并处理
可以全部选择拆分后的文本,然后批量生成问题,如下图。
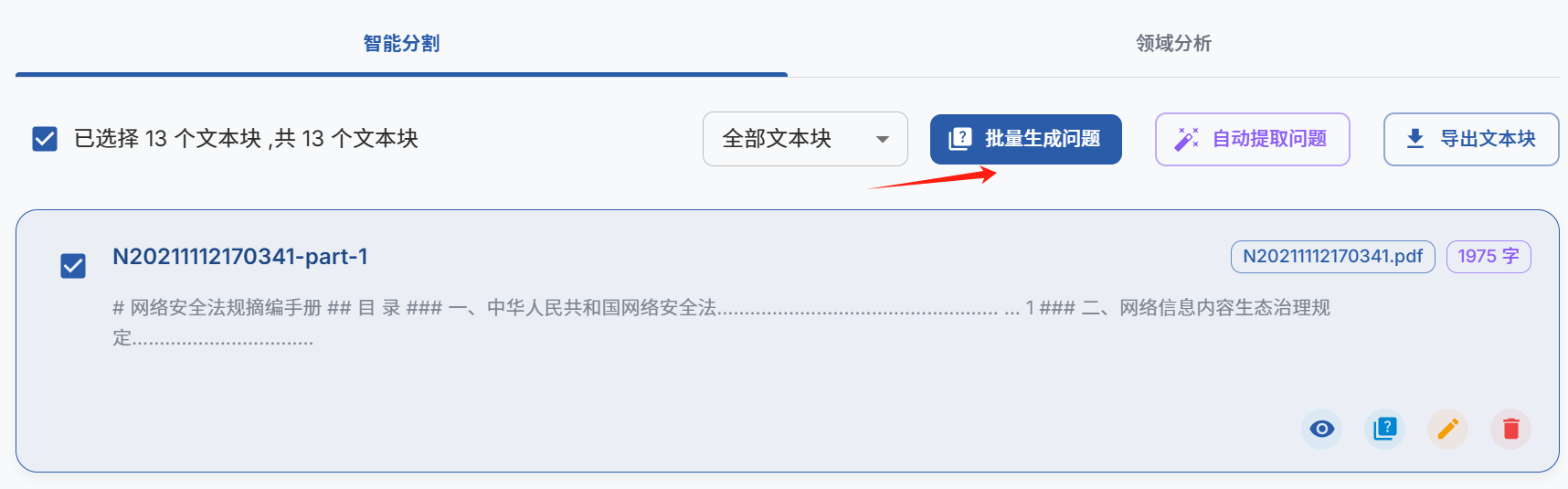
这里生成问题需要等待一段时间:
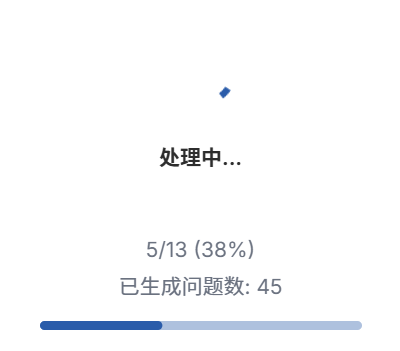
打开LM Studio,这里可以看到大模型运行过程

查看GPU使用率,最高在90%左右
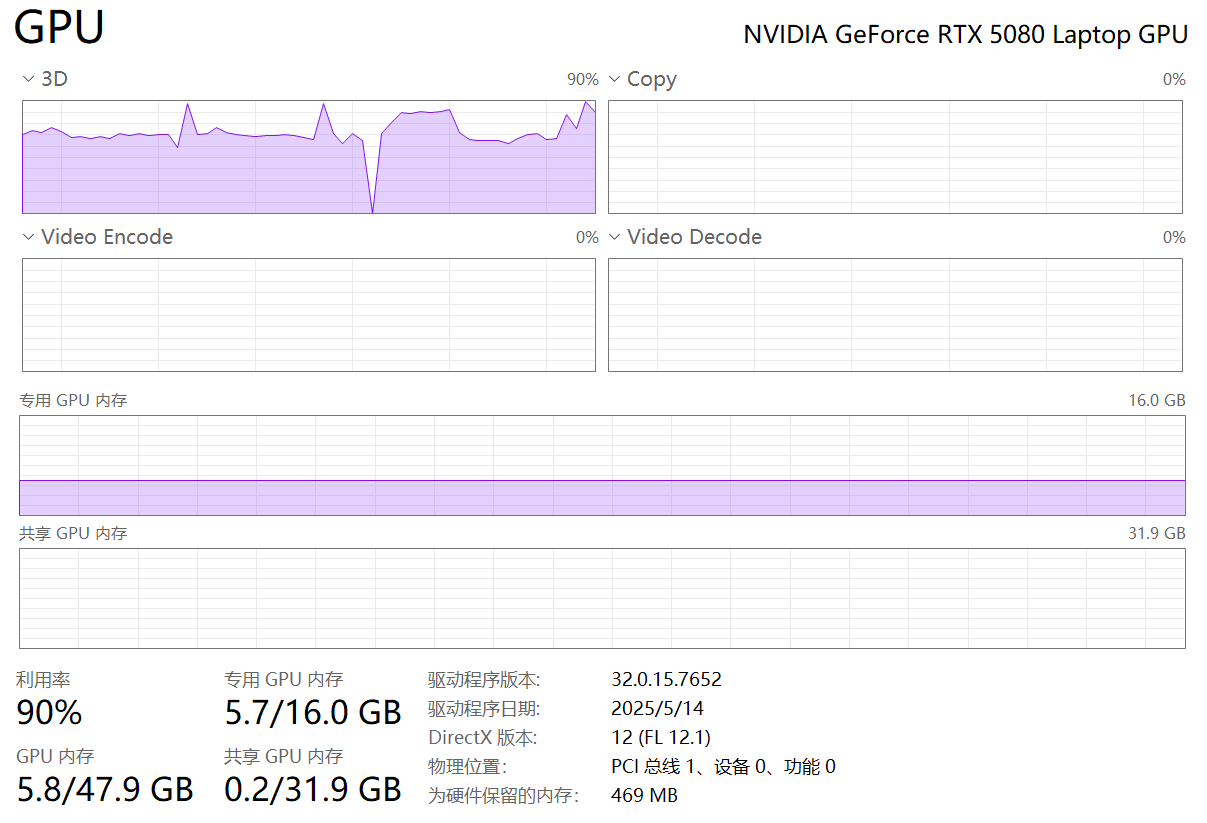
大概10分钟左右,就可以完成。
问题管理
选择"问题管理",勾选生成的问题,选择"批量构造数据集",过程仍需等待一段时间。
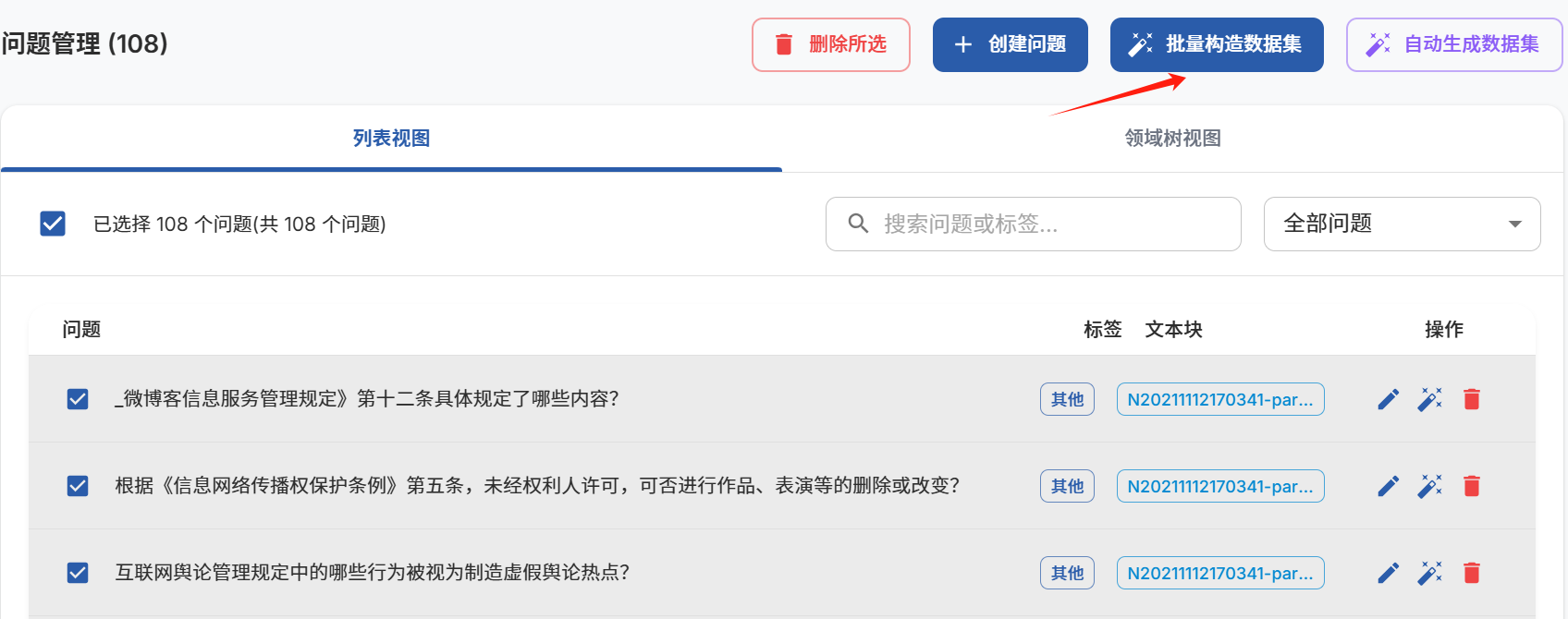
继续等待

这个过程比较漫长,也是比较耗费GPU的,90%左右的使用率。大概持续45分钟左右。
构建数据集
选择"导出数据集",下载构建好的网络安全行业数据。
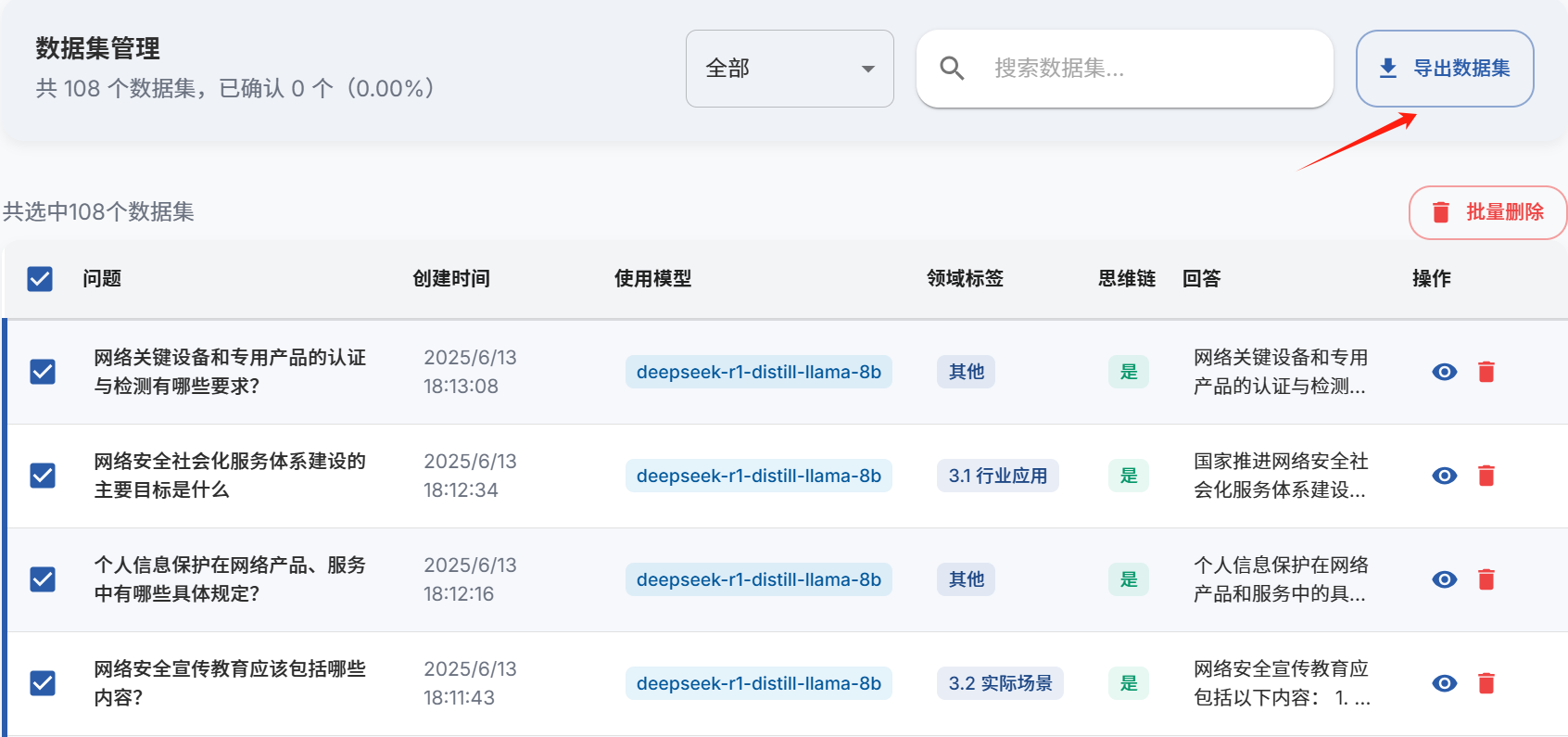
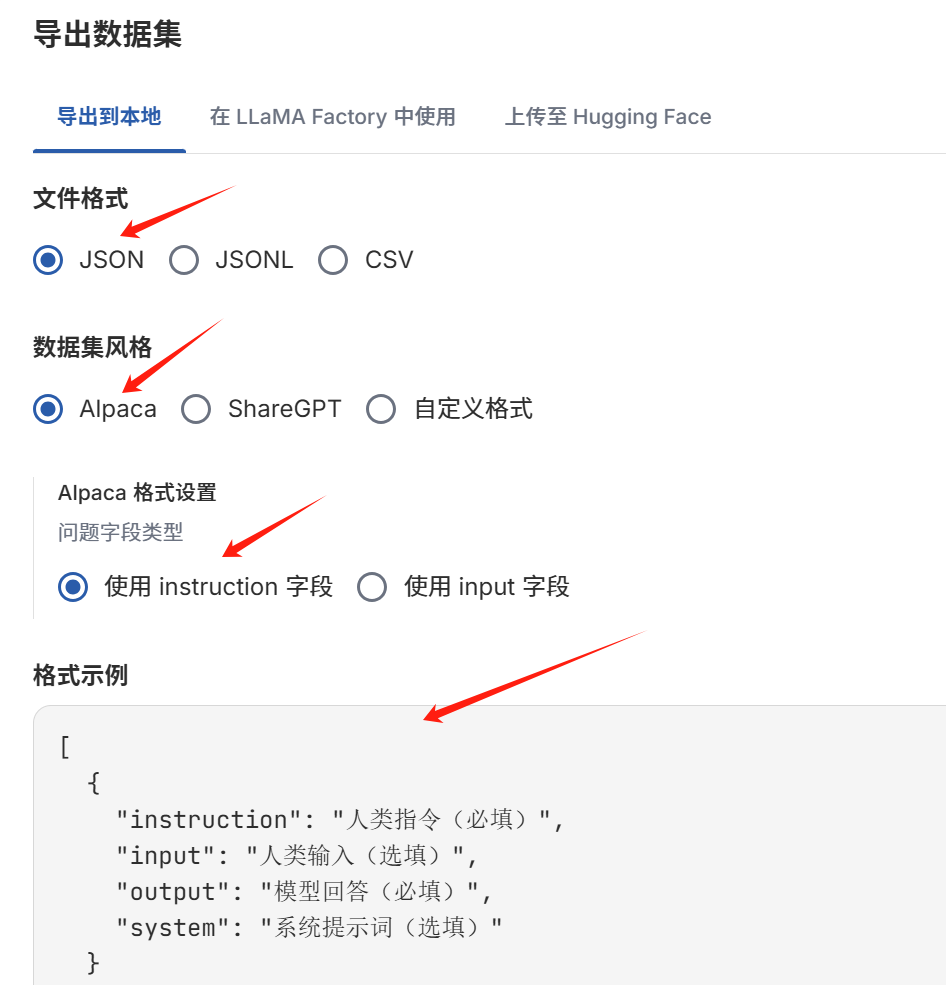
导出数据集,这里都是默认的。
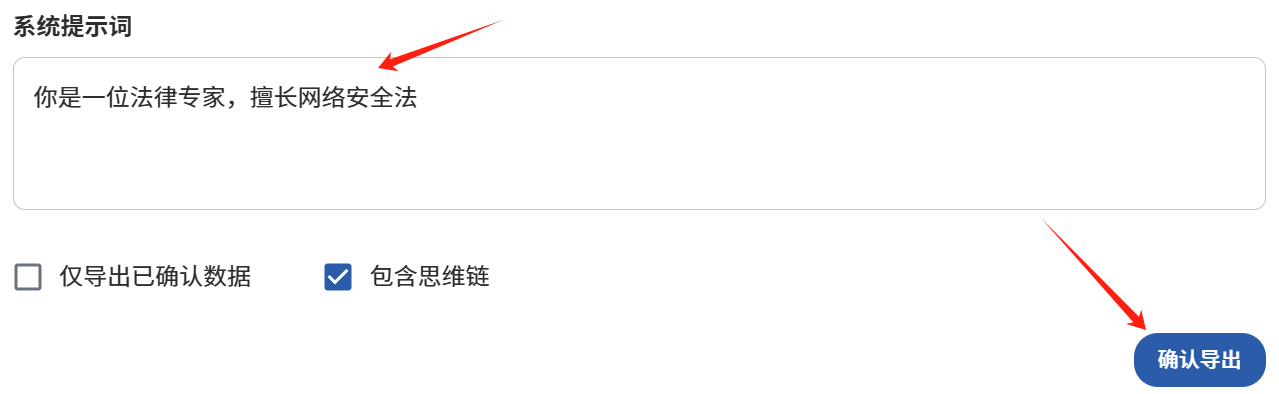
设置系统提示词"你是一位法律专家,擅长网络安全法"。
导出之后我们打开文件,可以看到导出的数据集案例。

至此,我们已利用 Easy Dataset 工具完成了"网络安全领域数据集" 的处理与生成。
虽然演示过程相对基础,但其过程充分展现了该工具的高度实用性:仅需执行三项核心操作,即可生成适用于微调的数据集。
本文参考链接:https://blog.csdn.net/weixin_46880696/article/details/147784014