在開發 Dify 數據助理過程中,直接將原始數據(如 BigQuery JSON)丟給 LLM 並期望其產出精確的圖表代碼,往往是穩定性的噩夢。
雖然 MCP 提供了便利,但在處理大規模數據或複雜語意時,常會遇到 Token 溢出、數據類型錯誤 或 圖表類型誤判。
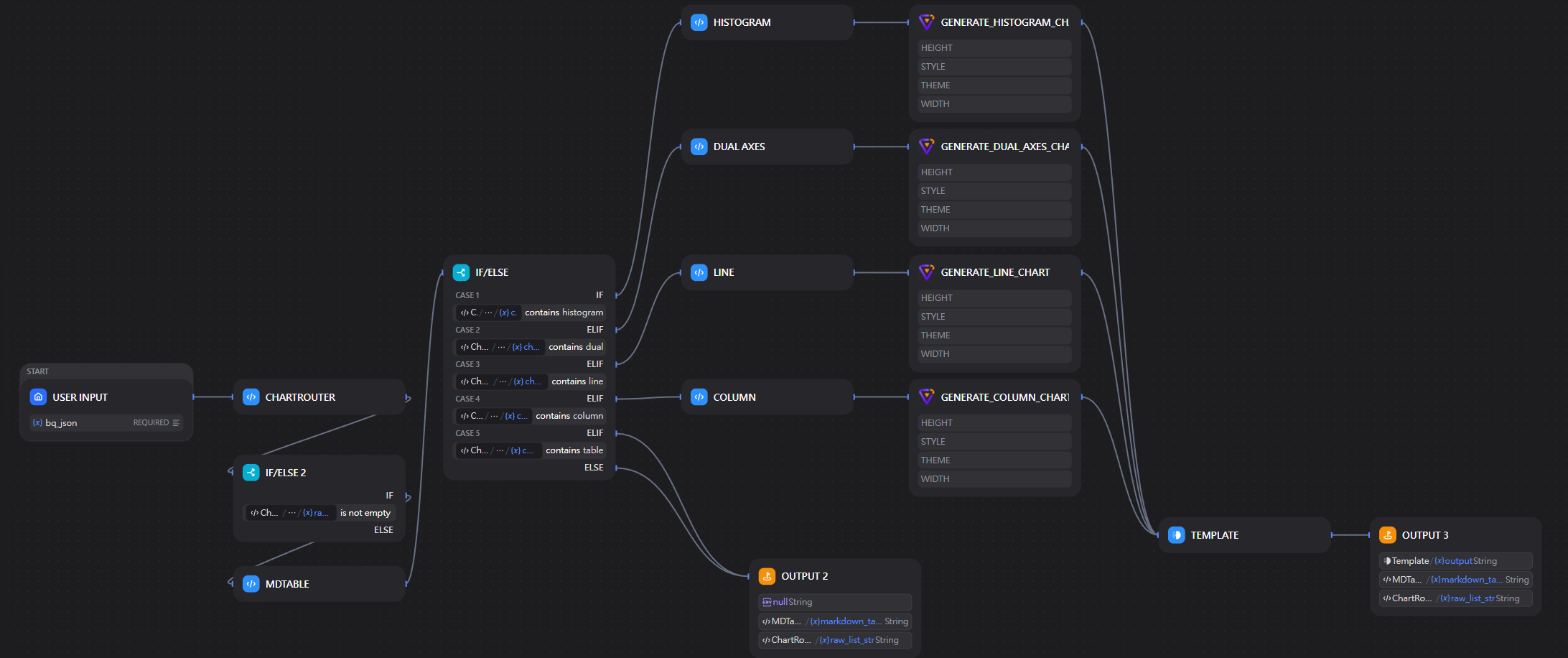
為了追求生產級的穩定性,我將原有的「純 Prompt 驅動」方案改進為 「Python 預處理 + 智慧語意路由 (Chart Router)」 的架構。本文將深度解析這套在 RTX 4090 環境下實測、穩定性極高的圖表生成邏輯。
⚠️ 為什麼純 Prompt 策略會失敗?
在早期版本中,我們常依賴 LLM 自行轉換格式,這會導致以下痛點:
- 資料量過載 (Context Overflow):原始 JSON 包含大量冗餘元數據,直接輸入會耗盡 Token。
- 類型不匹配 (Schema Mismatch) :AntV 要求的
category(String) 與value(Number) 嚴格定義,LLM 常在 JSON 轉換時將數字加上引號,導致渲染報錯。 - 圖表選型盲目:LLM 難以判斷數據的分佈狀態(例如該用柱狀圖對比,還是直方圖觀察分佈)。
🚀 核心架構:智慧圖表路由 (Chart Router)
我設計了一個 Python 核心節點,作為數據與視覺化組件之間的「路由媒介」。
1. 數據清洗與「強力解包」(Aggressive Unpack)
每個人處理的資料可能不相同,像我處理的是資料庫回傳的json文件,因此這方面得自行資料清洗一番,而和各位說明我這邊所做的幾個Feature。
- 數據校準 :將
TIMESTAMP自動轉為人體可讀的YYYY-MM-DD格式。 - 單位縮放 (Scaling) :當數值最大值大於 時,自動換算為 (M) 單位;大於 則換算為 (K),確保座標軸簡潔。
2. 基於語意的「標籤分類器」
透過定義 DIM_IDENTIFIERS (維度標籤) 與 TIME_IDENTIFIERS (時間趨勢標籤),系統能自動區分:
- 指標 (Metrics):真正的數值(如 Revenue, Count)。
- 維度 (Dimensions) :雖然型別可能是數字,但語意上是分類(如
year,group_id,status_code)。
🔸這是用Keyword Mapping的方式,彈性比較低,但勝在穩定。
🛠️ 圖表決策矩陣:如何選擇正確的「衣服」
我的系統會根據解析出的維度與指標數量,路由至不同的 AntV 生成節點:
| 數據特徵 | 路由目標 | 設計決策理由 |
|---|---|---|
| 包含時間維度 (Date/Time) | 折線圖 (Line) | 強調數據隨時間的連續性變動與趨勢。 |
| 單指標 + 類別 < 32 筆 | 柱狀圖 (Column) | 適合橫向對比不同分類的大小,視覺精確度高。 |
| 雙指標 (Two Metrics) | 雙軸圖 (Dual Axes) | 第一指標用柱狀、第二指標用折線,觀察兩者關聯性。 |
| 數據量大 + 分佈關鍵字 | 直方圖 (Histogram) | 利用平方根法 () 自動計算分箱數,觀察數據集散。 |
| 無數值或筆數過多 | Markdown Table | 保持資訊完整性,避免視覺過於擁擠導致信息遺失。 |
💻 關鍵實作範例 (Dify Workflow)
在我的 ChartGenerator 工作流中,核心邏輯被封裝在 Python 節點內:
python
# 核心決策片段
def route_chart(data, metrics, dims, row_count):
if row_count == 0:
return "text"
if not metrics:
return "table"
if len(metrics) >= 2:
return "dual"
if any(k in x_axis.lower() for k in TIME_IDENTIFIERS):
return "line"
if any(k in x_axis.lower() for k in ['range', 'bucket', 'bin']):
return "histogram"
return "column"我的Dify Workflow
為什麼這比單純的 Prompt 有效?
- 確定性:圖表類型由硬邏輯判定,不會受 LLM 隨機性的影響。
- Payload 優化 :Python 節點僅將處理後的
flattened_data傳給後續的 AntV 組件,大幅降低了傳輸負擔。
💡 結語與未來思考
希望上述內容可以給大家一些幫助,我們不能僅僅依賴MCP的強大,在作為生產用的工具,時間效率也是我們需要控制的環節。對於圖表製作追求穩定的話,我們還是將「格式標準」與「統計計算」交還給 Python 腳本。