实战目的
学习一下通过 RAG 搭建个人知识库。
如果为了纯用,gemini 的 NotebookLM 效果更好,无脑用
背景知识
- RAG:信息检索系统与 LLM 相结合的技术架构。
- 向量:把非结构化数据(如文本、图片、音频)转换为计算机可计算的一种数值形式。从数据结构上来,它是一个浮点数数组(比如:List)。
- 向量数据库:一种专门用于存储、管理、和查询高维向量数据的数据库管理系统。可以快速找到这些向量的坐标。
- Dify:开源的 LLM 应用开发平台,内置完整的 RAG 管道,便捷处理向量数据库。
环境及软件
环境一览
- windows10 企业版
- Docker
- 安装 Dify 用
- Dify
- Ollama
- 用的 deepseek-r1-8b 模型
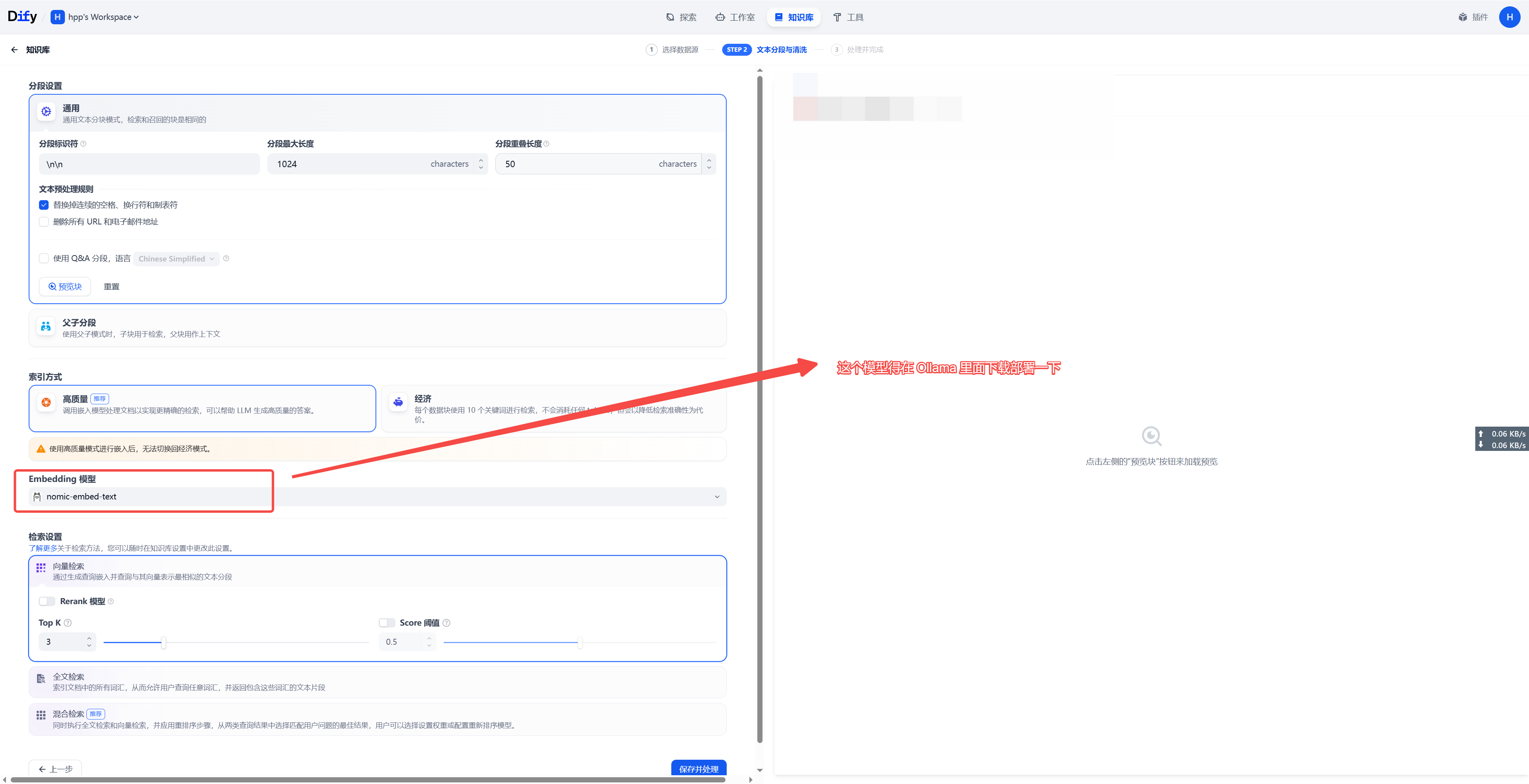
本地模型

Docker 安装 Dify 界面
这里不介绍怎么安装 Docker 和 Dify 了,结合 AI 和 官网自己弄吧。
Dify 通过脚本上传知识库文件
网页端有限制,一次最多 5 个还是 20 个,我本地的知识库数量早就超过了,所以需要使用脚本上传的方式。
上传知识库文件脚本
配置参数获取方式
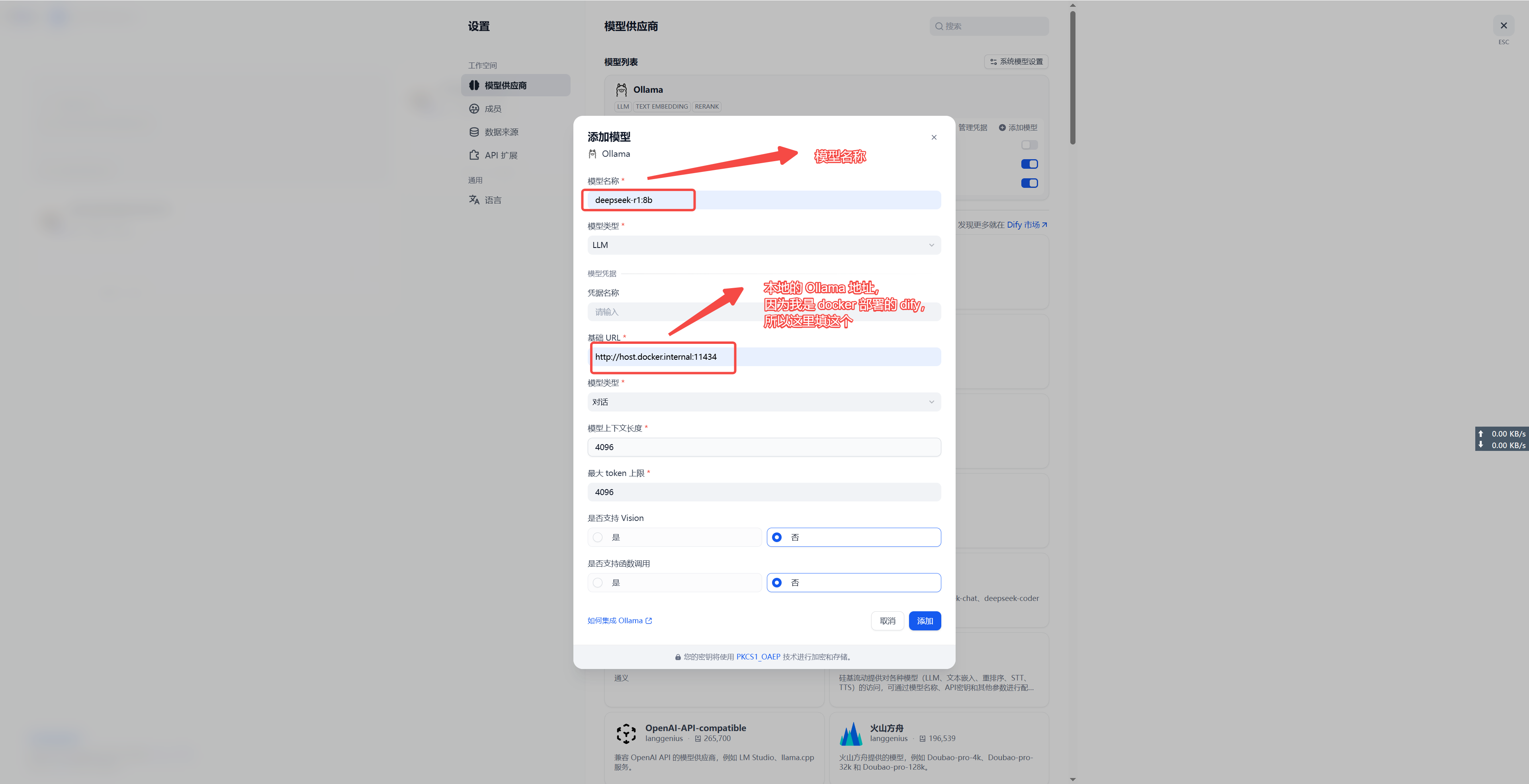
BASE_URL: 一般是固定的 http://localhost/v1
API_KEY: 在 dify 的服务 API 里面 API 密钥,可以新建。
DATASET_ID: 在网页端打开某个知识库,url 上的 uuid 就是的。
LOCAL_FOLDER: 就是你本地的知识库地址。
python
import os
import requests
import json
import time
# ================= 配置区域 =================
# Dify API 基础地址 (本地部署通常是 http://localhost/v1)
BASE_URL = "http://localhost/v1"
# 你的知识库 API Key
API_KEY = "xxx"
# 你的知识库 ID (Dataset ID)
DATASET_ID = "xxxx"
# 你的本地文档文件夹路径
LOCAL_FOLDER = r"C:\xxx\xxx\xxx\xxx\xxx"
# ===========================================
headers = {
"Authorization": f"Bearer {API_KEY}"
}
def get_existing_files():
"""获取知识库中已存在的文件列表,用于去重"""
existing_names = set()
page = 1
limit = 100
print("正在获取线上已存在文件列表...", end="")
while True:
try:
url = f"{BASE_URL}/datasets/{DATASET_ID}/documents?page={page}&limit={limit}"
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f"\n获取列表失败: {response.text}")
break
data = response.json()
docs = data.get('data', [])
if not docs:
break
for doc in docs:
existing_names.add(doc['name'])
if not data.get('has_more'):
break
page += 1
print(".", end="", flush=True)
except Exception as e:
print(f"\n获取列表异常: {e}")
break
print(f"\n已存在 {len(existing_names)} 个文件。")
return existing_names
def upload_file(file_path):
file_name = os.path.basename(file_path)
url = f"{BASE_URL}/datasets/{DATASET_ID}/document/create-by-file"
# 构造 multipart/form-data
# data 字段必须是 JSON 字符串,定义处理规则
data_payload = {
"indexing_technique": "high_quality", # 或 economy
"process_rule": {
"mode": "automatic" # 自动分段
}
}
try:
with open(file_path, 'rb') as f:
files = {
'file': (file_name, f),
'data': (None, json.dumps(data_payload)) # 注意 data 字段也是 form-data 的一部分
}
response = requests.post(url, headers=headers, files=files)
if response.status_code == 200:
print(f"[成功] {file_name}")
return True
else:
print(f"[失败] {file_name} -> {response.text}")
return False
except Exception as e:
print(f"[异常] {file_name} -> {e}")
return False
def main():
existing_files = get_existing_files()
# 遍历本地文件夹
for root, dirs, files in os.walk(LOCAL_FOLDER):
for file in files:
# 过滤隐藏文件或非目标格式
if file.startswith('.') or not file.lower().endswith(('.pdf', '.txt', '.md', '.docx')):
continue
if file in existing_files:
print(f"[跳过] {file} (已存在)")
continue
file_path = os.path.join(root, file)
# 添加一点延时,防止把本地 Ollama 打崩(Worker 解析需要资源)
upload_file(file_path)
time.sleep(1)
if __name__ == "__main__":
main()Dify 知识库搭建
知识库
demo知识库,可以保存到 md 文件里,喂给 ai
plain
# 绝密档案:核心员工详细画像 (2026版)
## 1. 基础身份信息
- **姓名**:李星河 (Li Xinghe)
- **员工工号**:TECH-8892-Z
- **职位**:高级混沌工程架构师 (Level P8)
- **入职日期**:2023年4月1日
- **办公地点**:上海市浦东新区张江高科"未来中心" C座 1402室(靠窗位置,左边放着一盆快枯死的仙人掌)。
- **身份证号后四位**:X921
## 2. 身体与生理特征
- **身高**:178.4 cm(他对外宣称 180 cm,禁止在周报中修正此数据)。
- **体重**:72 kg(周末暴饮暴食后会波动至 75 kg)。
- **血型**:RH 阴性 O 型(稀有血型,公司急救档案备注)。
- **过敏源**:
1. 芒果(食用后嘴唇会肿)。
2. **Lombok 插件**(心理过敏,看到代码里有 @Data 会立刻驳回合并请求)。
## 3. 薪资与福利规则(RAG 逻辑测试点)
- **基础月薪**:48,500 元人民币。
- **年终奖计算公式**:
- 如果当年 Git 提交数 > 1000 且 线上故障数 = 0,年终奖 = 6 个月薪资。
- 如果当年发生 P0 级故障,年终奖 = 0,且需要请全组喝一周奶茶。
- **当前状态**:2025年他因为误删测试库导致一次 P2 故障,目前年终奖系数被锁定为 1.5 个月。
## 4. 个人喜好与生活习惯
- **咖啡偏好**:只喝"瑞幸生椰拿铁",且必须是**少冰、不加糖**。如果买成热的,他会送给隔壁的前端组长。
- **通勤工具**:一辆改装过的"小牛电动车",车身贴着"Java 永不为奴"的贴纸。
- **午休习惯**:中午 12:30 - 13:00 必须午睡,期间如果被钉钉电话吵醒,下午的代码 Bug 率会上升 50%。
## 5. 隐秘背景(模型无法猜测的信息)
- **曾用 ID**:在 2018 年前,他曾是《星际争霸2》的职业选手,ID 叫 "Ghost_Code"。
- **家庭状况**:有一只名叫"塔克"的金毛犬,但这只狗其实是他合租室友的,他只负责喂食。
- **WIFI 密码**:他工位的个人热点名称是 `Error_404`,密码是 `Spring@Boot!2026`。
## 6. 社交雷区(Prompt 约束测试)
- **绝对禁忌**:千万不要在他面前夸赞 "Python 是世界上最好的语言",否则他会拉着你聊 3 个小时的 JVM 内存模型。
- **沟通技巧**:想让他快速修 Bug,必须带上一杯"一点点"波霸奶茶(三分甜)。ollama pull nomic-embed-text
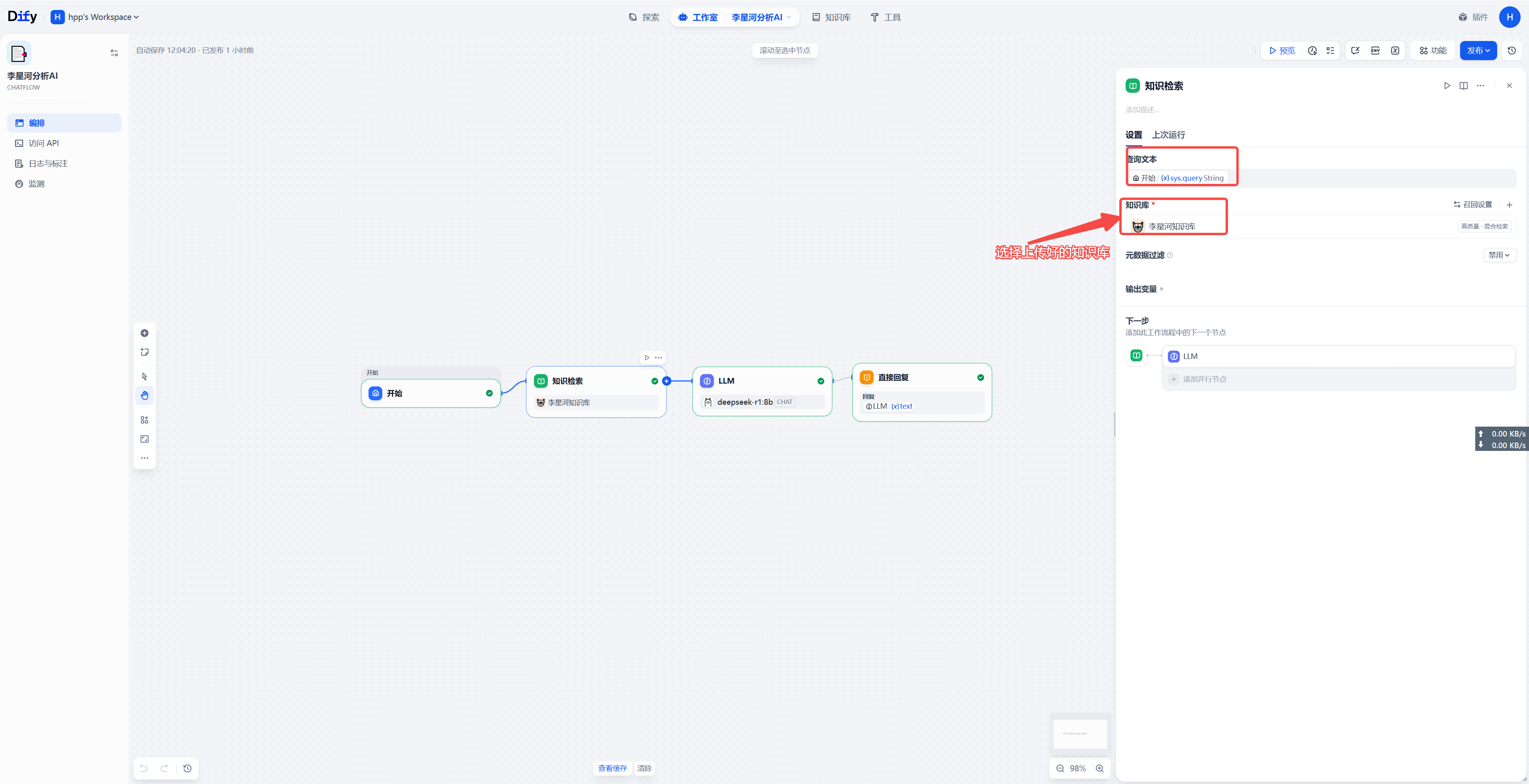
工作流选择与配置
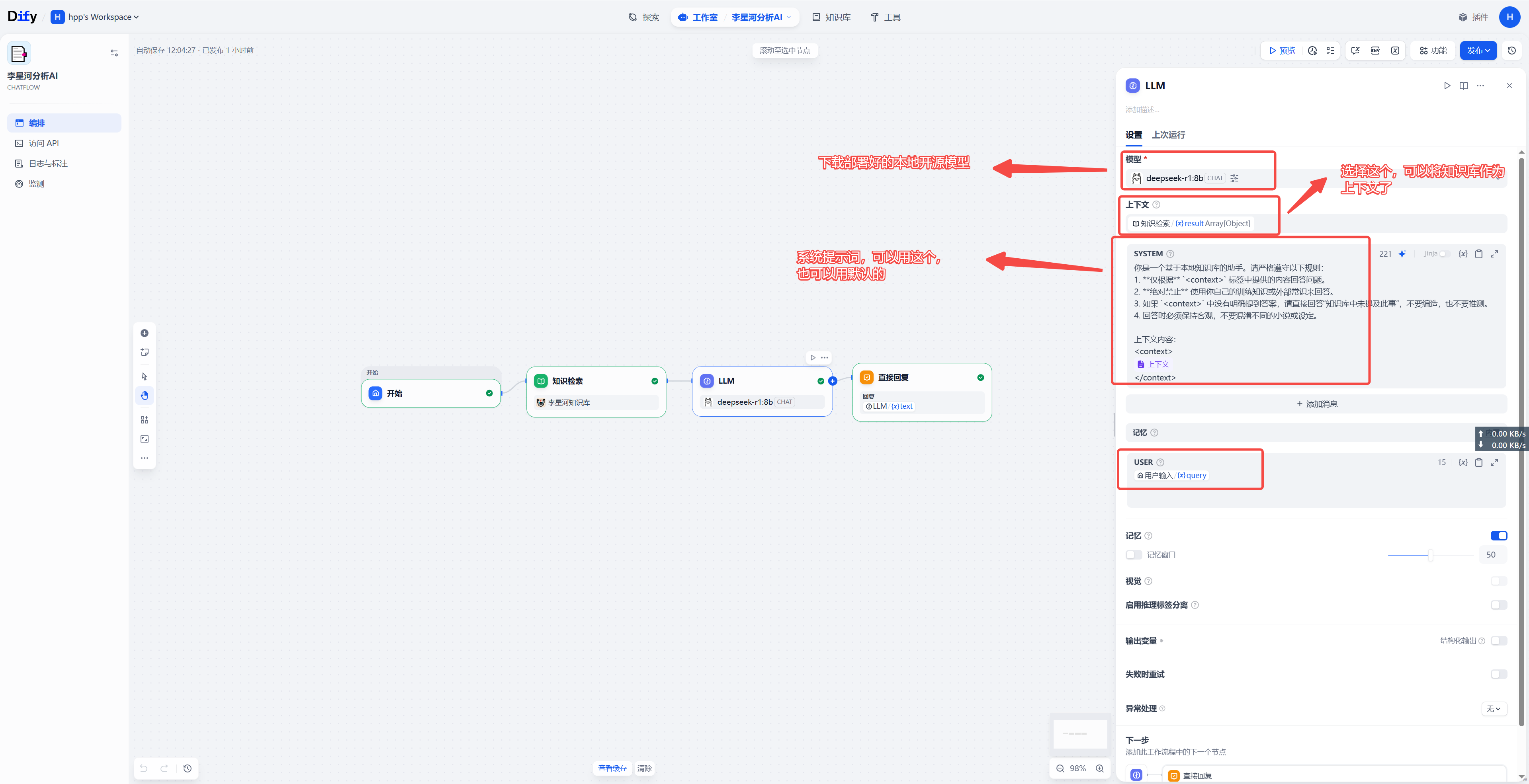
你是一个基于本地知识库的助手。请严格遵守以下规则:
- 仅根据
<context>标签中提供的内容回答问题。- 绝对禁止 使用你自己的训练知识或外部常识来回答。
- 如果
<context>中没有明确提到答案,请直接回答"知识库中未提及此事",不要编造,也不要推测。- 回答时必须保持客观,不要混淆不同的小说或设定。
上下文内容:
{{#context#}}
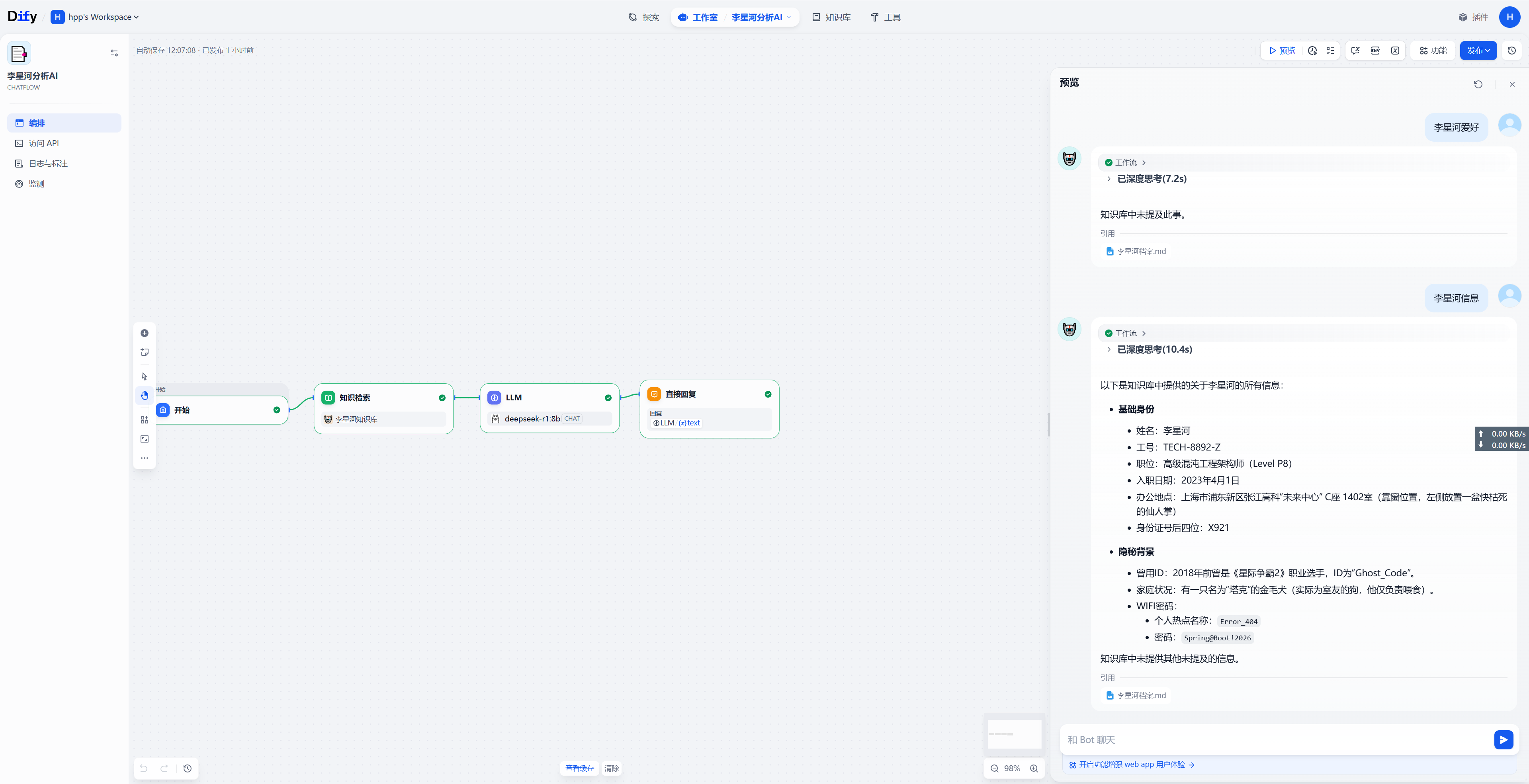
效果
展示