背景:
在调用大语言模型时,除了安全问题另外一个让用户很头疼的问题就是实时大文本交互,如果你的问题内容很多,经常遇到LLM返回内容很简单,甚至内容被截断的问题,因为达到了最大token数限制。注意这提到的是实时交互,如果不是实时交互,通过RAG技术也可以解决很多大文本交互问题。在一些官网,比如deepseek,如下图:
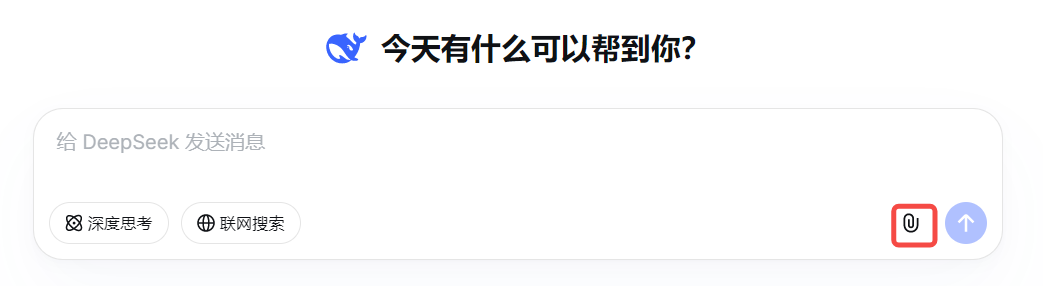
在网页中进行交互时,右下角会提供一个上传附件的功能,在这里你可以上传图片,文本等附件,而这些内容会被实时解读,而且可以上传较大文件内容(我上传过一个900Khtml文件,好像已经被告知有部分文件内容解析不了,600k大小是可以被完全解析的,600K纯文本内容基本可以满足我80%的需求了),但是问题又来了,我是想通过接口的形式进行调用,查了很多资料居然发现deepseek在发稿截止时官方并未提供可以上传附件的接口,只提供了普通对话接口。。。
经过多方查阅居然发现dify可以解决我的问题,dify平台的搭建和配置大家可以参考dify官方文档,在此基础上,我们进行问题的后续讨论。
一、技术栈:
-
dify 服务
-
大语言模型:Gpt-4.1
-
编程语音:python
二、 创建工作流
我们需要在dify中创建一个Chatflow ,通过调用Chatflow接口实现大文本内容的交互,步骤如下:
- 创建空白应用
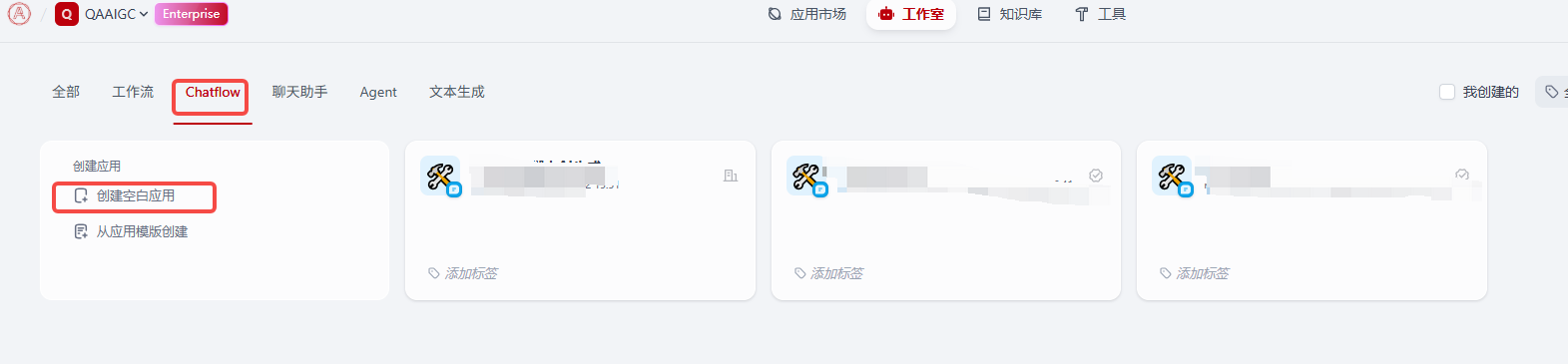
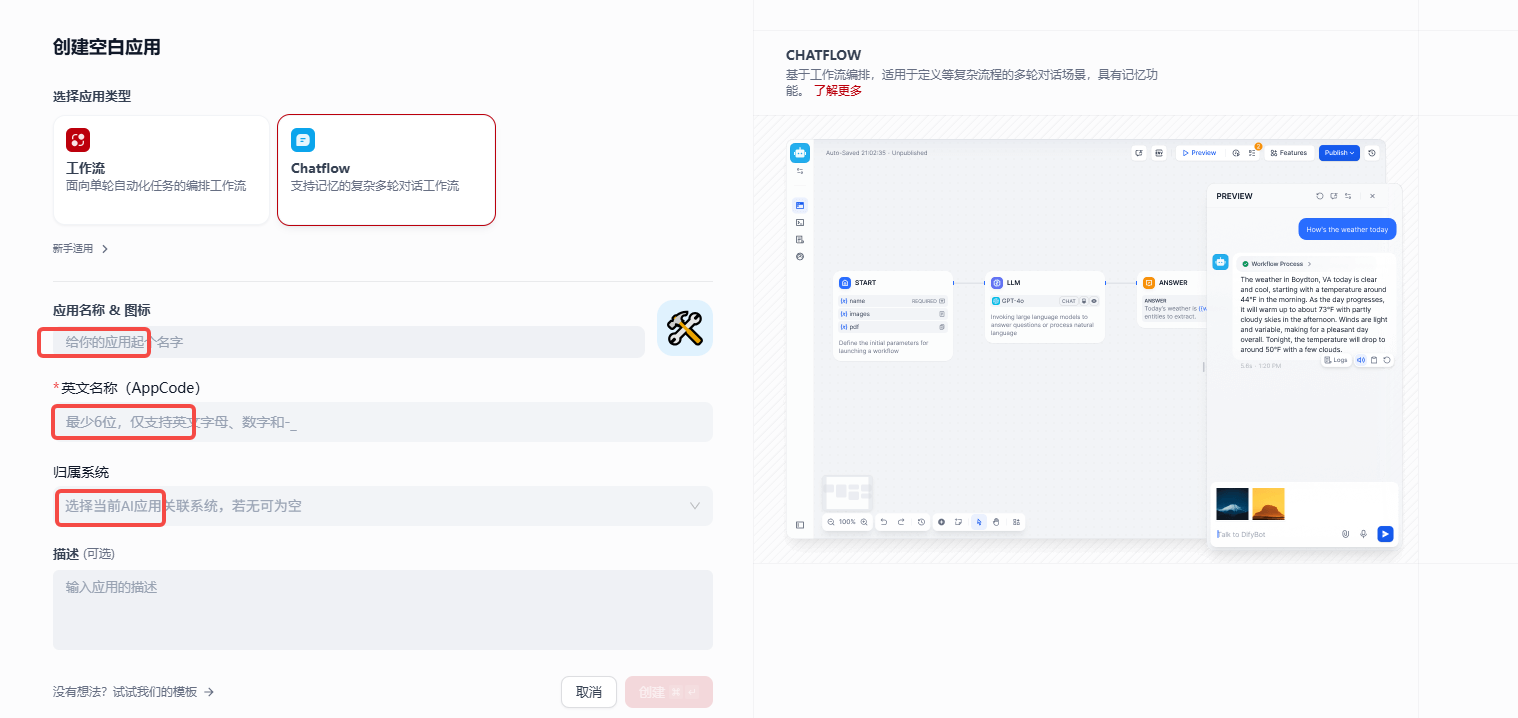
- 添加必要信息,因为我使用的是企业版,所以前面三项信息我这里都需要添加
- 创建工作流
我这边最终创建的工作流大致如下:
上面那条链路是处理图片分支,下面是处理文档分支
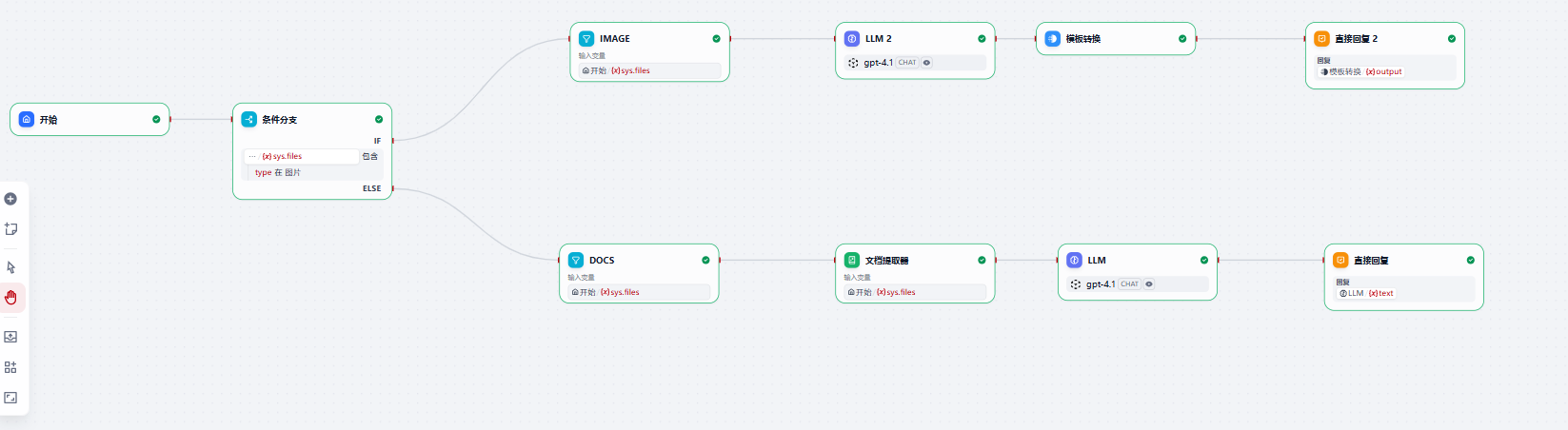
具体步骤如下:
【1】首先加入开始节点,使用系统默认配置
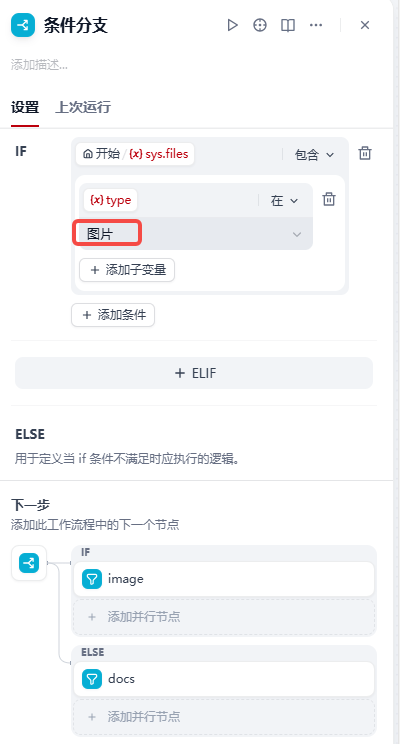
【2】加入条件节点,条件节点配置如下,如果文件类型是图片则走上面分支处理,其他情况都走下面路径处理:
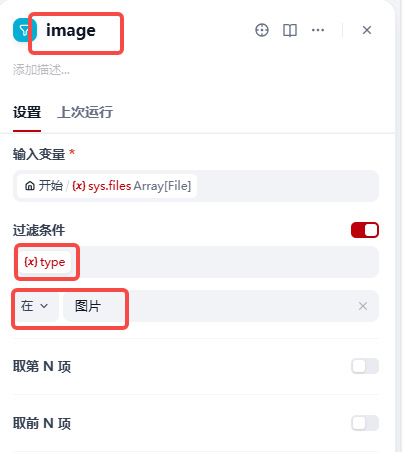
【3】 增加列表操作节点,将其名称命名为IMAGE代表处理图片节点,配置如下图:
【4】IMAGE节点后面添加大语言模型节点,配置如下图:
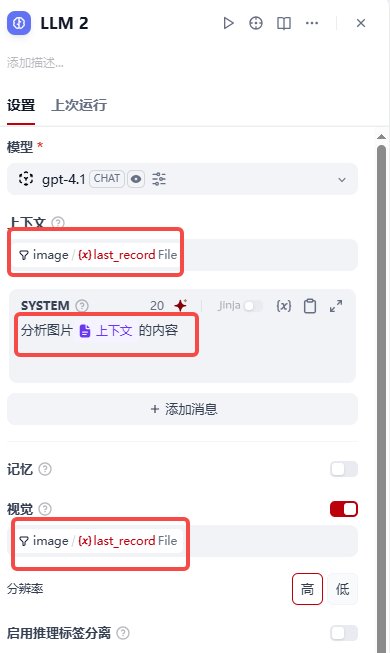
注:此处需要说明较多
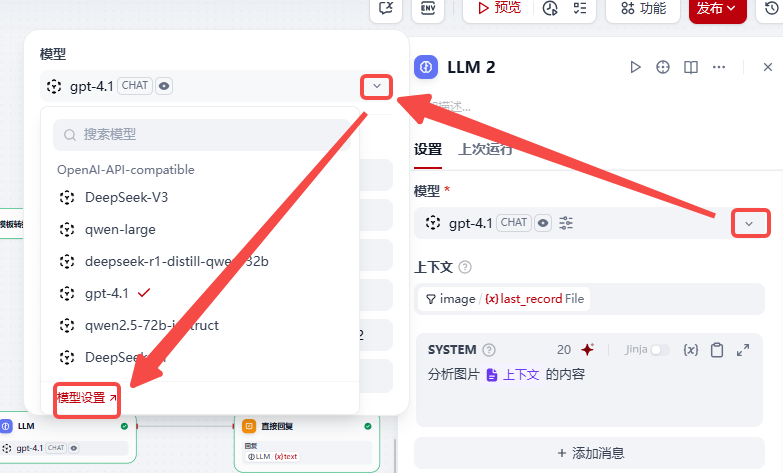
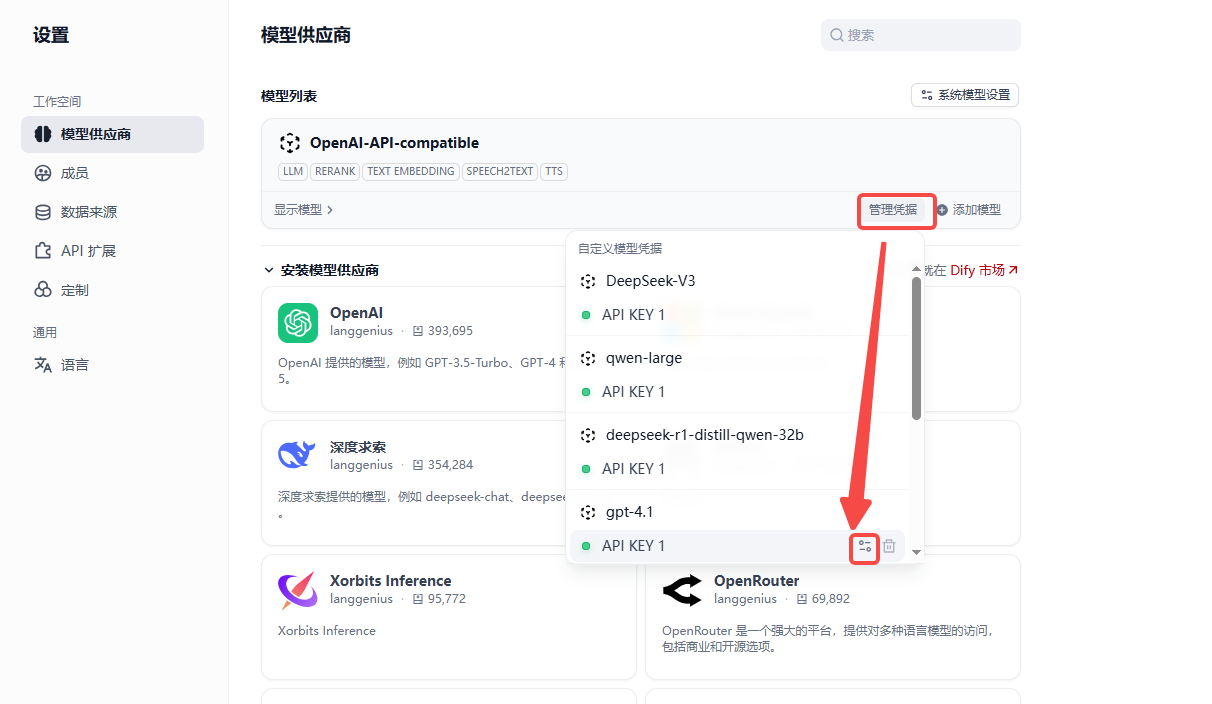
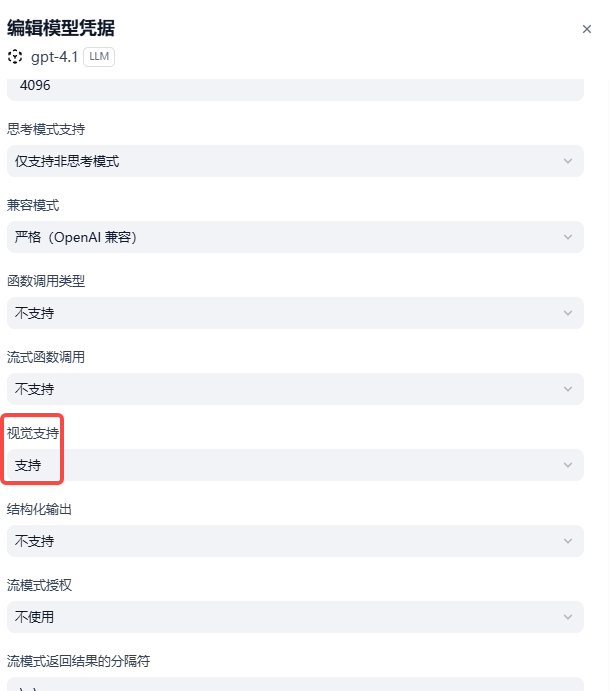
- LLM我选择的是Gpt4.1 ,需要到模型配置==》管理凭据 ==》 编辑中将视觉支持修改为支持
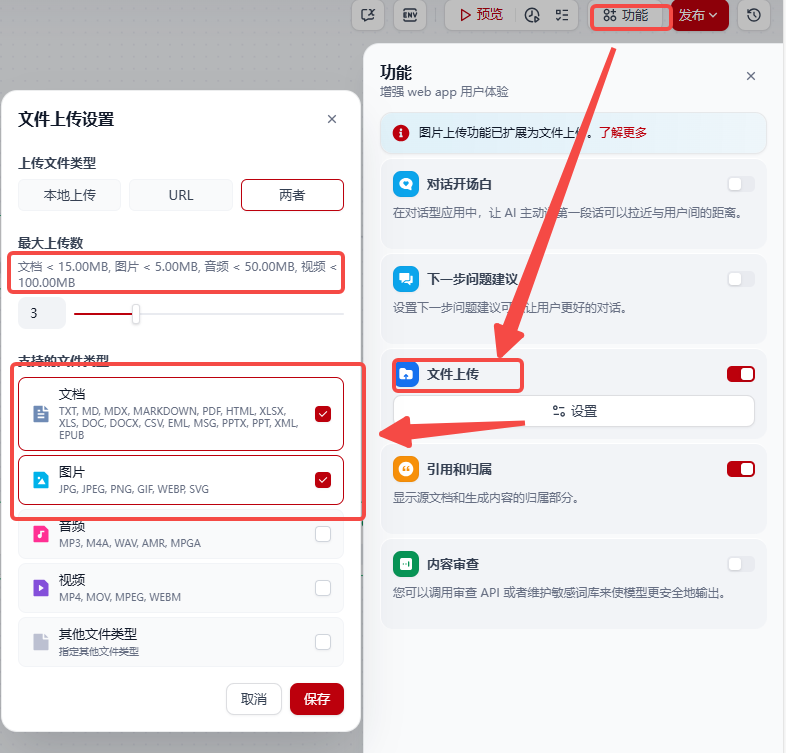
- 增加图片和文档上传能力
- 打开视觉开关,如果上面视觉支持为不支持,这步视觉开关是被disable的,无法打开,这步的变量选择要和上下文中保存一致
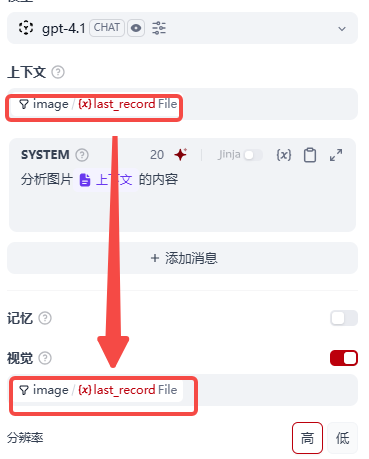
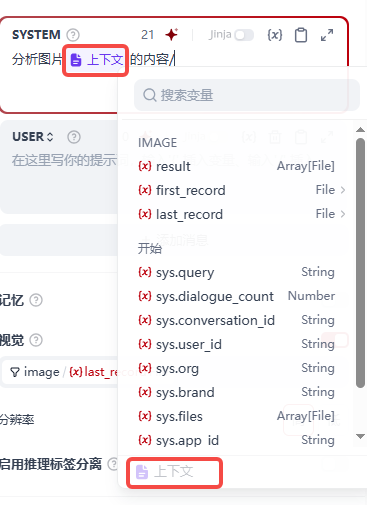
- 系统提示词中,输入 / 会自动弹出可选提示词,记得选择最下面的上下文,如下图我已经选择过了所以是灰色的
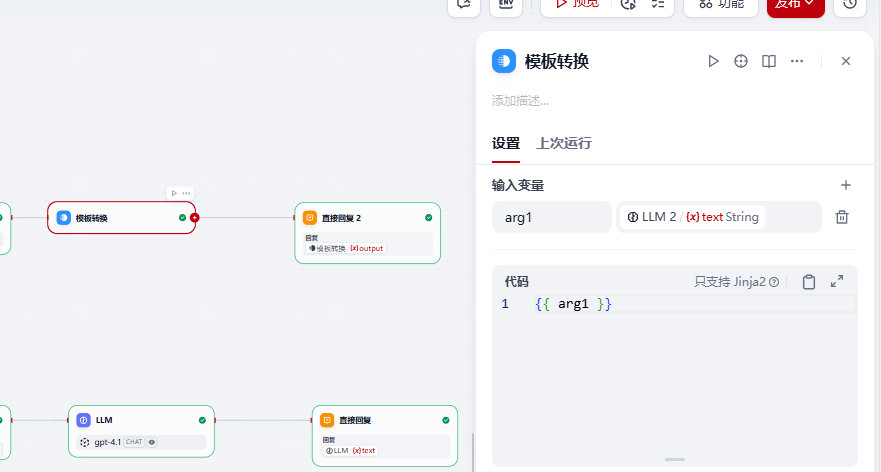
【5】添加模版转换节点配置如下:
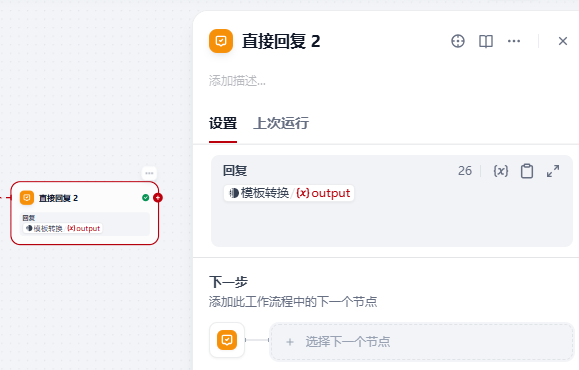
【6】添加回复节点
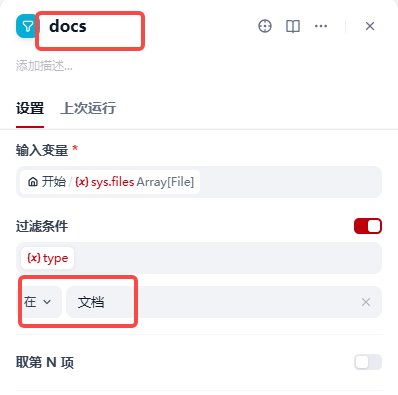
【7】在条件节点else分支添加列表节点,名称修改为DOCS,用于开始处理文档
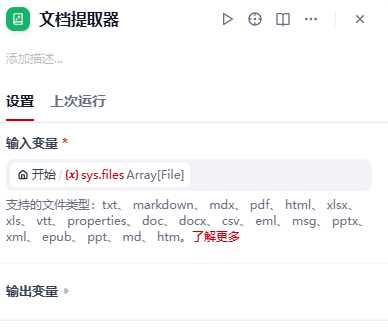
【8】添加文件提取器节点
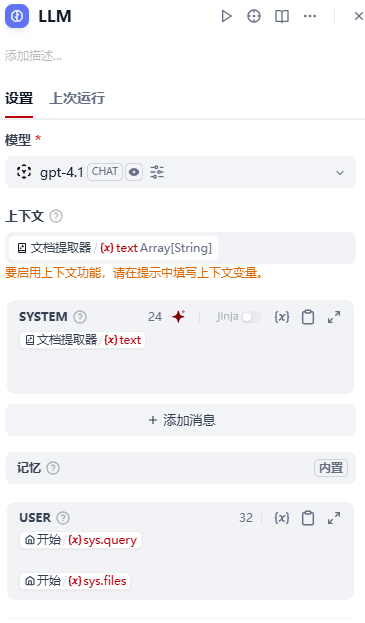
【9】添加LLM节点,参数设置如下
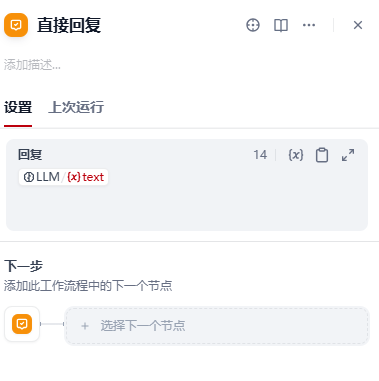
【10】添加回复节点
按照上面流程配置起来的工作流是对图片和文档单独处理,如果想同时传递多个附件文件,同时处理图片和文档,可以将条件分支去掉后就可以进行并行处理。
三、 功能验证:
3.1 图片验证
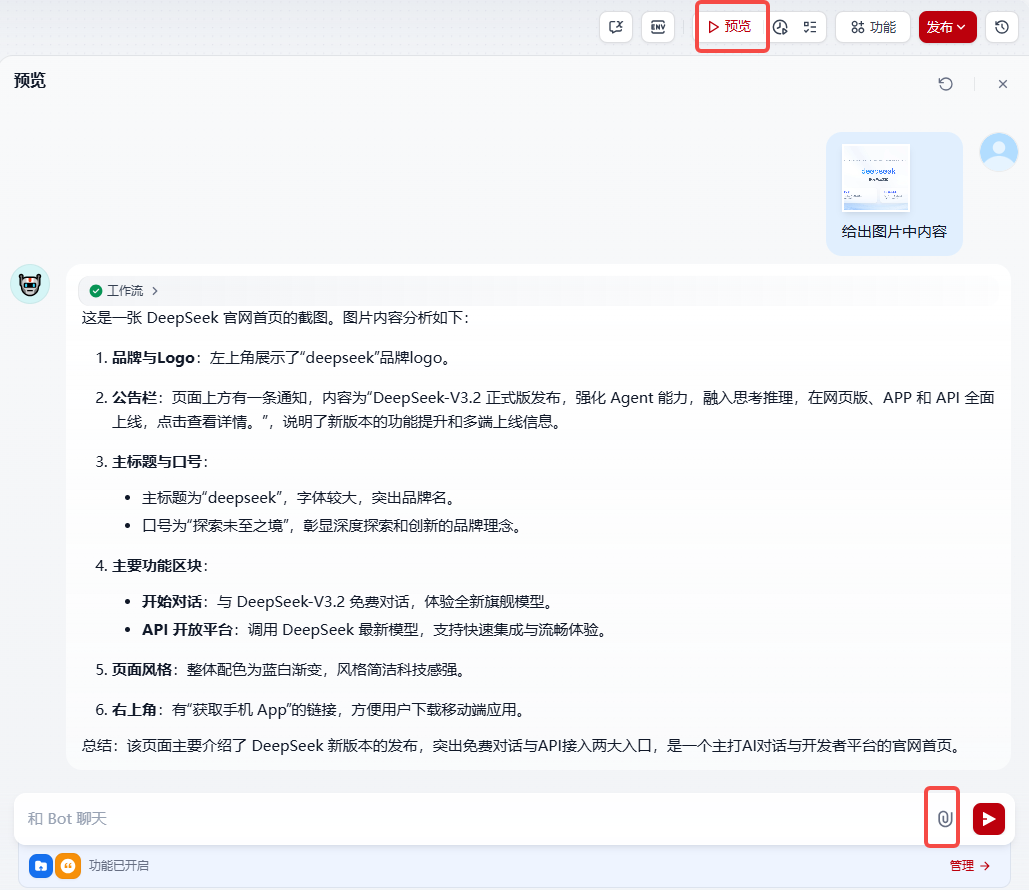
点击预览,发送一张deepseek主页图片,让他解析,结果如下图:
3.2 文档验证
我们将图片解析内容保存到txt文件里面,然后再上传dify,让他实时读取一下文档中内容:
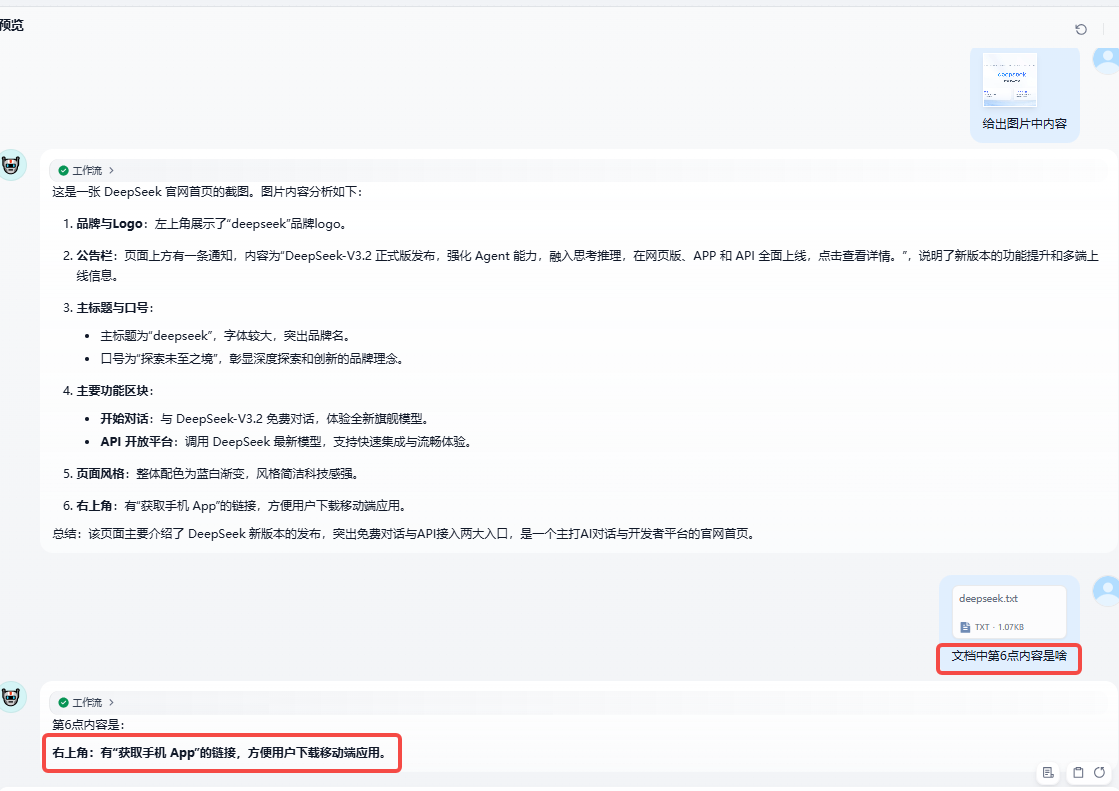
通过上面两张图可以看出,dify处理文件的工作流我们已经搭建好了,点击发布即可让外部应用进行接口调用了。
3.3 接口验证
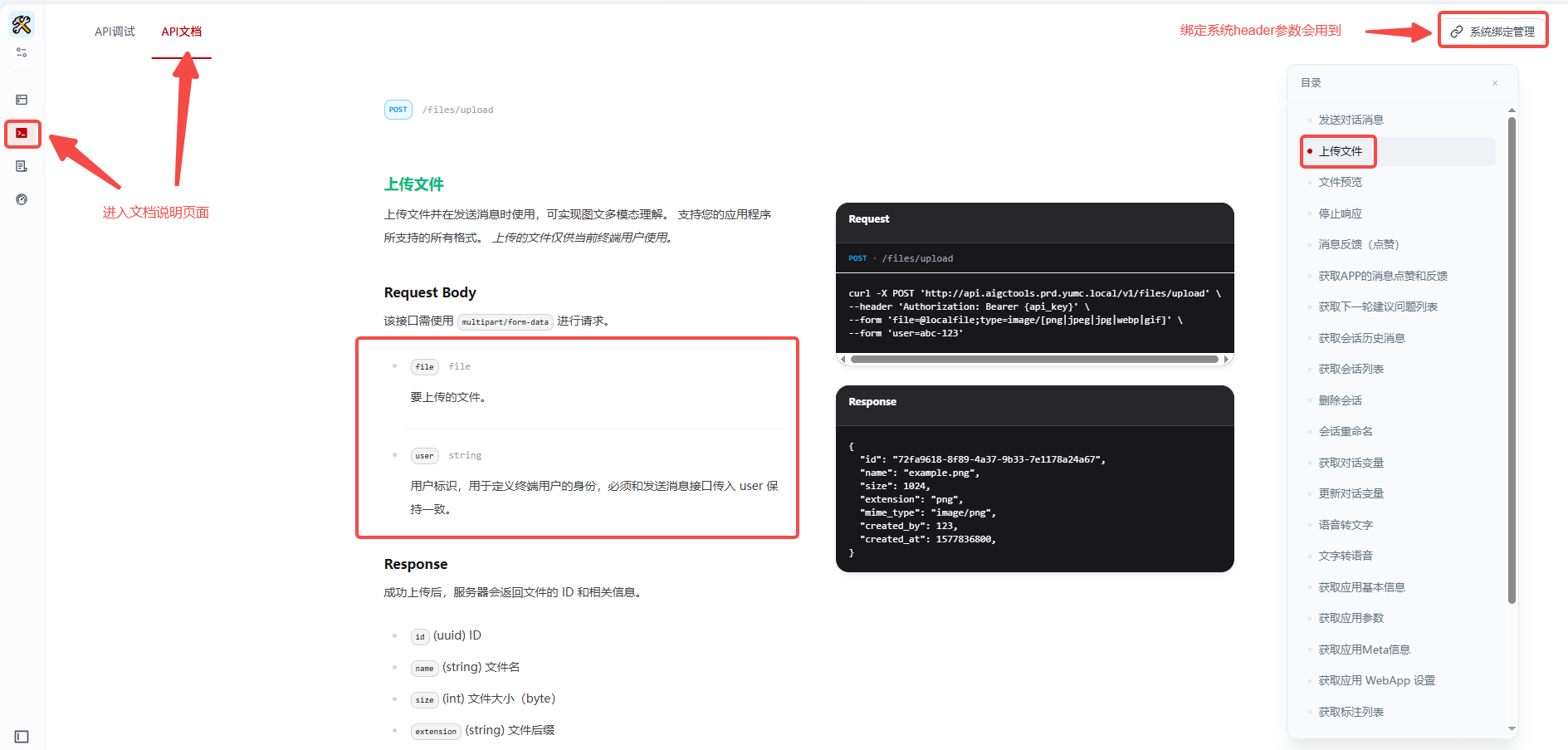
3.3.1 dify接口文档
3.3.1.1 上传文件接口
注: 在接口请求时header中一般会有三个参数需要添加**,**ak 、 sid 和 appCode , sid就是下图中系统绑定管理中添加, appCode 是在创建Chatflow时填入的应用名称,ak 是秘钥,如果dify是你自己搭建的,自然知道如何获取,如果是公司搭建的,则需要找dify管理员申请,当然不同公司处理方式不同,只要和管理员沟通清楚,这些参数都可以获取到。
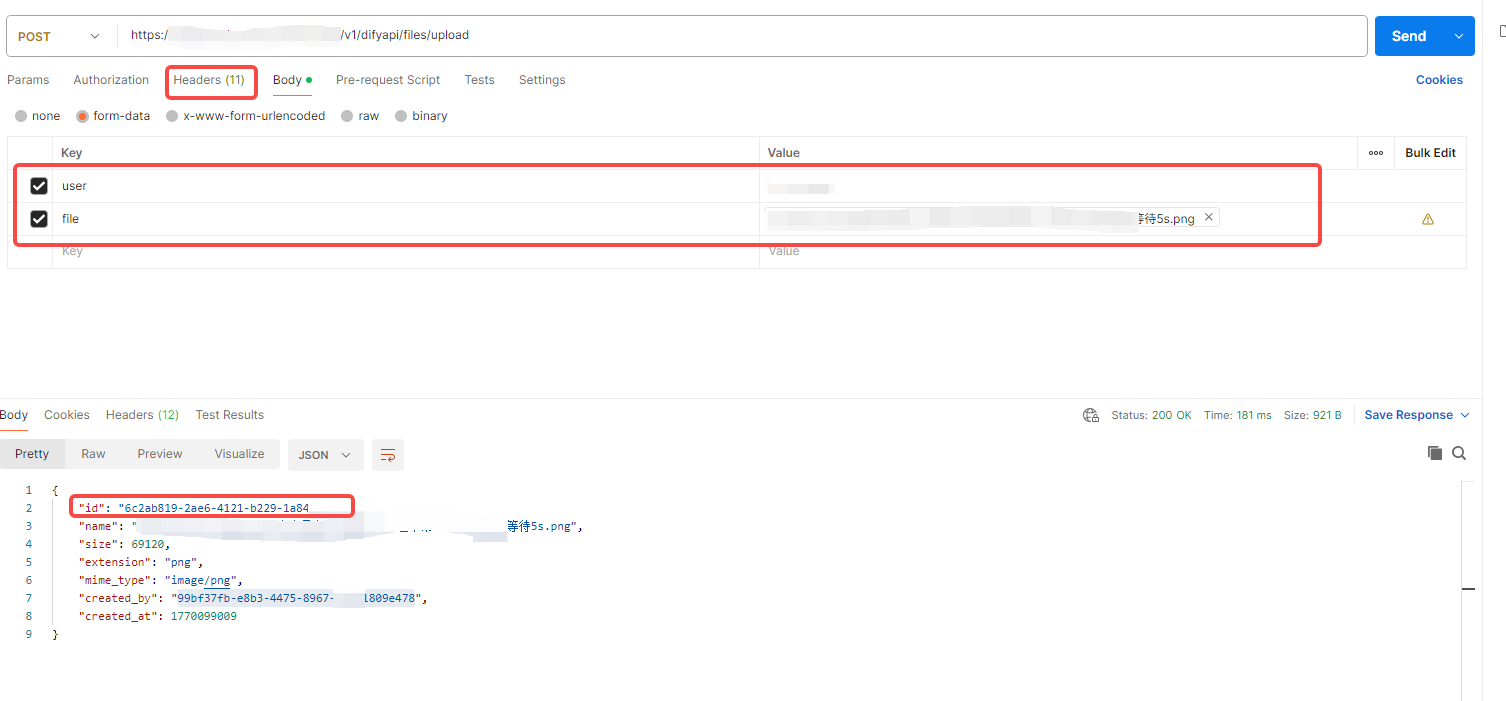
上传文件接口参数比较简单,post请求截图如下,用过post的应该都清楚如何填写,需要说明一下的是返回值中的id 字段就是接下来我们调用聊天接口需要传入的文件Id
python 请求代码如下:
python
def dify_upload_file_direct(file_path, user_id):
url = "https://******/api/v1/difyapi/files/upload"
headers = {
"ak": f"Bearer {os.getenv('API_KEY')}",
"sid": "1111",
"appCode": "*****"
}
with open(file_path, "rb") as file:
if '.png' in file_path:
my_file = {
"file": (os.path.basename(file_path), file, 'image/png'),
}
else:
my_file = {
"file": (os.path.basename(file_path), file),
}
my_data = {
"user": user_id
}
response = requests.post(url, data=my_data, headers=headers, files=my_file)
if response.status_code == 200:
file_data = response.json()
MyLog.info(f"上传成功!文件ID: {file_data['id']}")
return file_data['id']
else:
MyLog.info(f"上传失败: {response.status_code}, {response.text}")
return None说明:
我这里进行了偷懒处理,对于图片只处理了png图片,需要强调的是,文档上传问题不大,对于图片上传需要加上 'image/png' 这个参数,虽然这个参数在python requests请求中不是必填参数,但是对于有的dify服务器,需要带上这个参数,不然图片有可能被当做文档处理。
3.1.1.2 聊天接口
dify文档
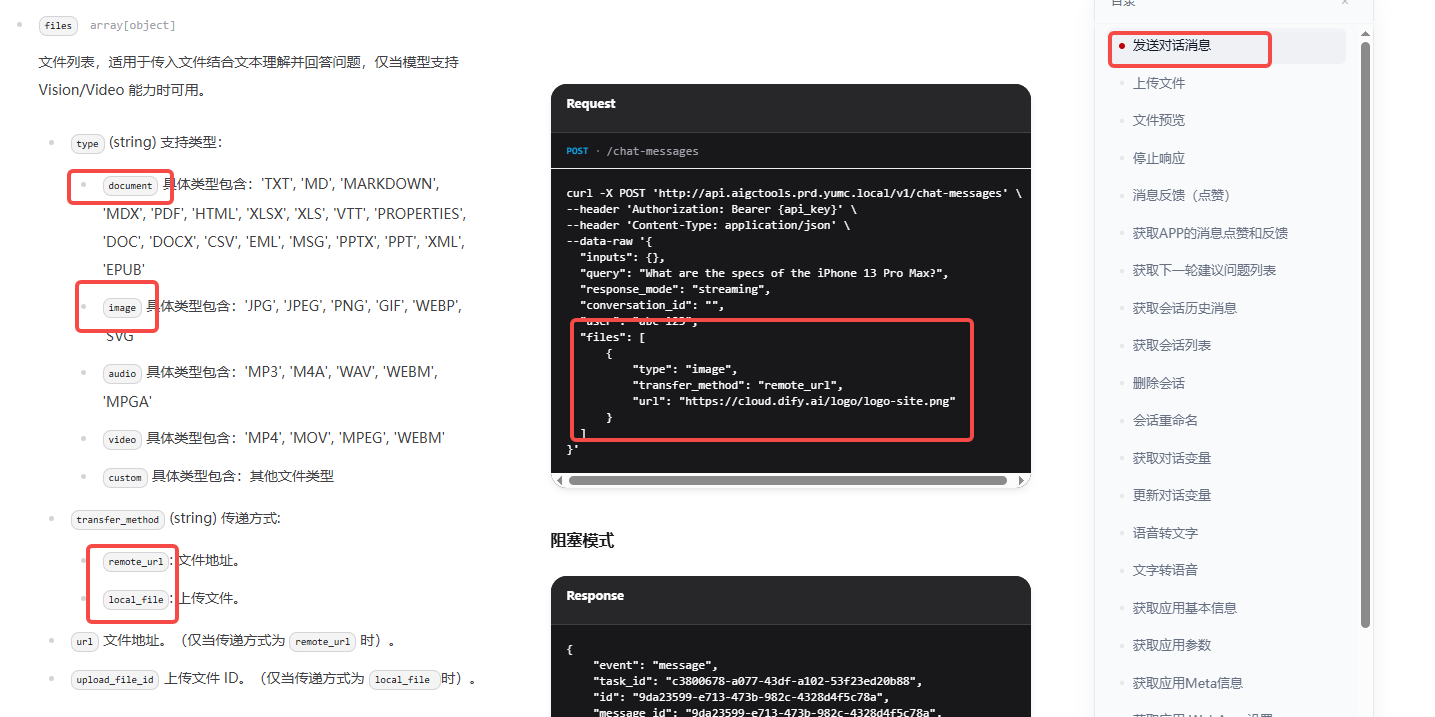
postman请求:
type 如果是image 对于图片,document 对应文档, 如果选择本地上传 upload_file_id 为上面图片上传接口返回的id, 参数transfer_method 为 "local_file"
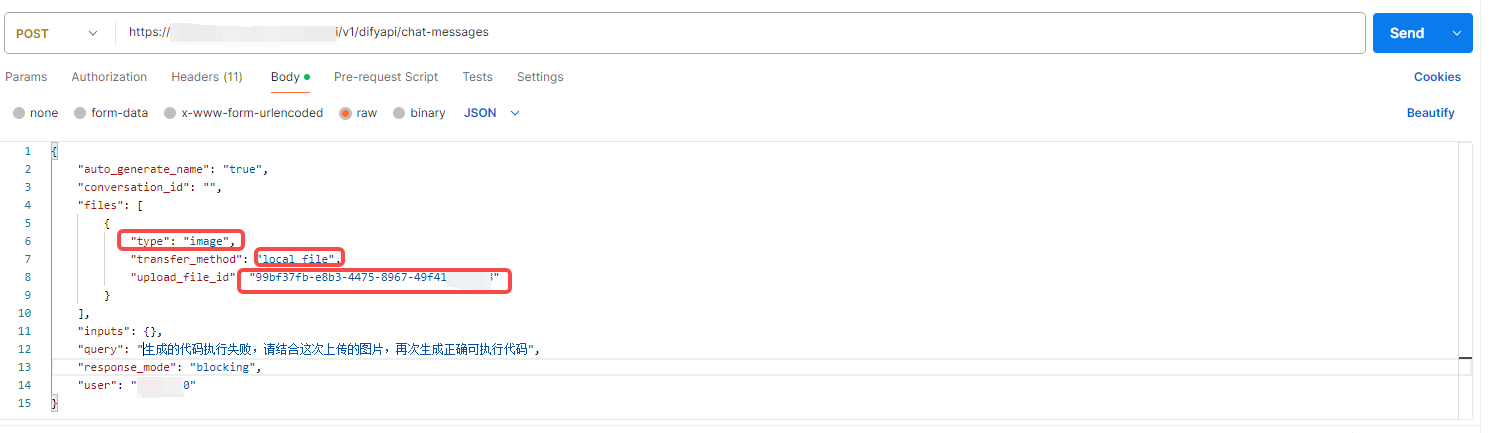
header参数和文件上传接口一致
python代码:
python
def dify_chat_with_structured_file(text_message, user_id, file_ids=None, file_type=None):
"""
使用结构化的消息格式包含文件ID
Args:
text_message: 文本消息
file_ids: 文件ID或列表,可以是:
- 字符串: 单个文件ID
- 列表: 多个文件ID
- 字典: {文件名: 文件ID}
"""
url = "https://*******/api/v1/difyapi/chat-messages"
headers = {
"ak": f"Bearer {os.getenv('API_KEY')}",
"sid": "1111",
"appCode": "******"
}
# # 构建消息内容
# content = []
#
# # 添加文本部分
# content.append({
# "type": "text",
# "text": text_message
# })
#
# # 添加文件引用部分
# if isinstance(file_ids, dict):
# # 字典形式:{文件名: 文件ID}
# file_info = "我上传了以下文件,请参考:\n"
# for filename, file_id in file_ids.items():
# file_info += f"- {filename}: {file_id}\n"
# content.append({
# "type": "text",
# "text": file_info
# })
# elif isinstance(file_ids, list):
# # 列表形式:多个文件ID
# file_info = f"我上传了 {len(file_ids)} 个文件,文件ID如下:\n"
# for i, file_id in enumerate(file_ids, 1):
# file_info += f"{i}. {file_id}\n"
# content.append({
# "type": "text",
# "text": file_info
# })
# else:
# # 单个文件ID
# content.append({
# "type": "text",
# "text": f"我上传了一个文件,文件ID是:{file_ids}"
# })
if file_ids:
my_file_data = [
{
"type": file_type,
"transfer_method": "local_file",
"upload_file_id": file_ids
}
]
else:
my_file_data = []
data = {
"auto_generate_name": "true",
"conversation_id": "",
"files": my_file_data,
"inputs": {},
"query": text_message,
"response_mode": "blocking",
"user": user_id
}
MyLog.info(f'发送给dfiy数据=================================\n{json.dumps(data, ensure_ascii=False)}')
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
res = json.dumps(response.json())
# MyLog.info(f"dify 响应内容为:\n{res}")
# 返回字典类型
return response.json()
else:
MyLog.info(f"dify返回失败: {response.status_code}, {response.text}")
return None注:上面函数只处理了单文件上传,和上面讲的工作流是匹配的,如果需要同时上传多个文件,需要稍微修改一下dify 工作流,然后打开代码注释部分,稍微适配一下即可使用。
如果文档对你有帮助,请动动小手帮忙点个赞。