ragflow的官方文档:
HTTP API 接口 |抹布流 --- HTTP API | RAGFlow
接着前文,我们已经创建了知识库,那么如何才能使用它呢?
当然也是通过网络API的形式去调用它。本文将讲解两种方式:
- Dify调用
- python源码调用
目录
[2.2. 确定IP地址](#2.2. 确定IP地址)
1.创建API-Key
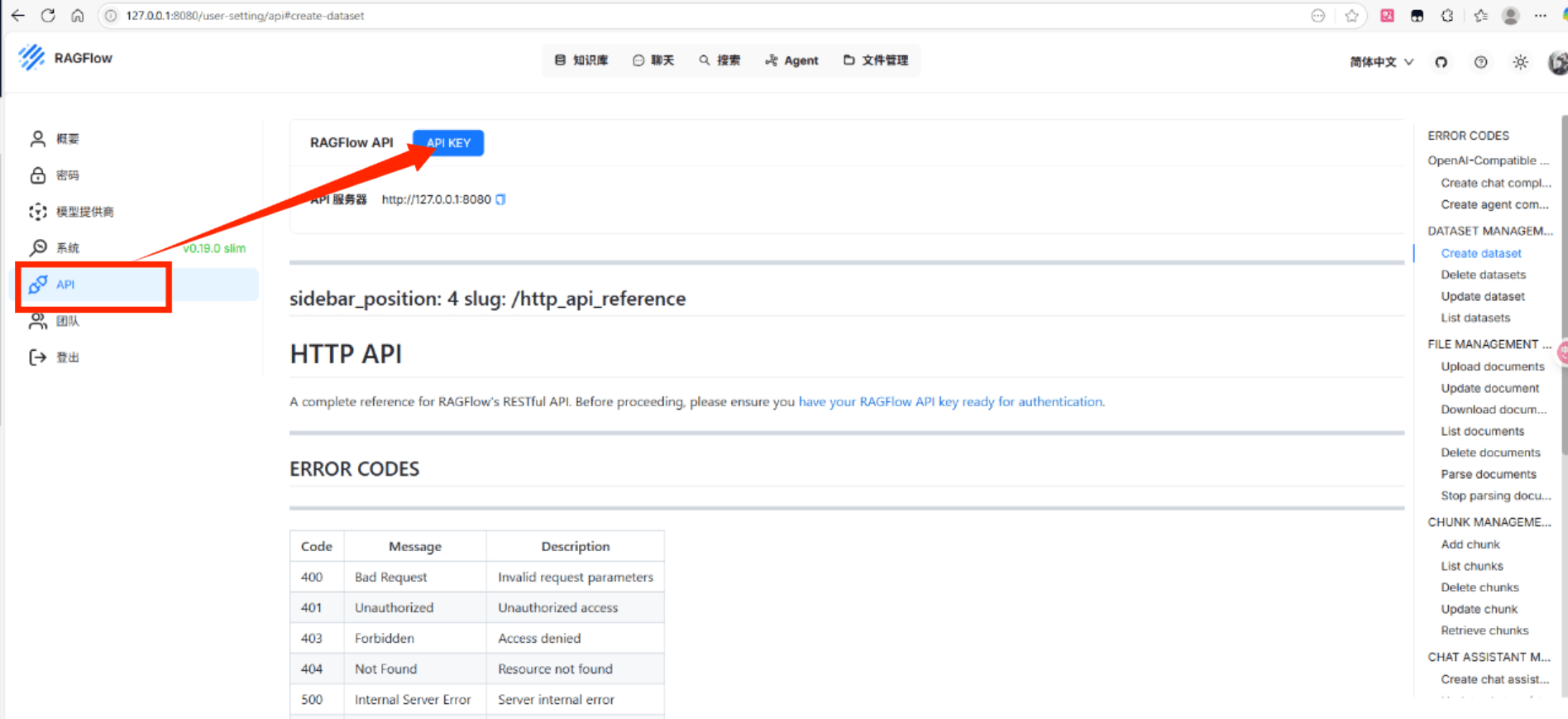
获取ragflow知识库ID:
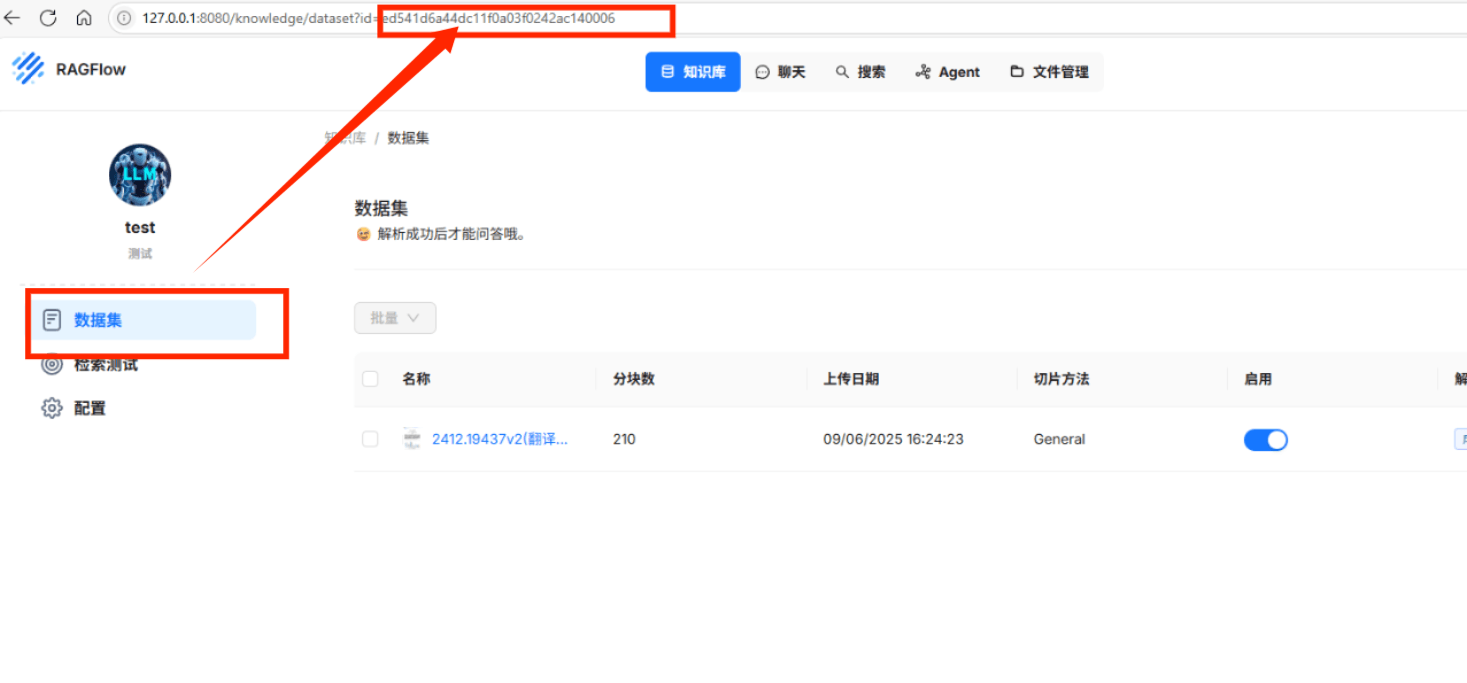
2.DIfy接入ragflow
看看官网如何讲解:External Knowledge API - Dify Docs
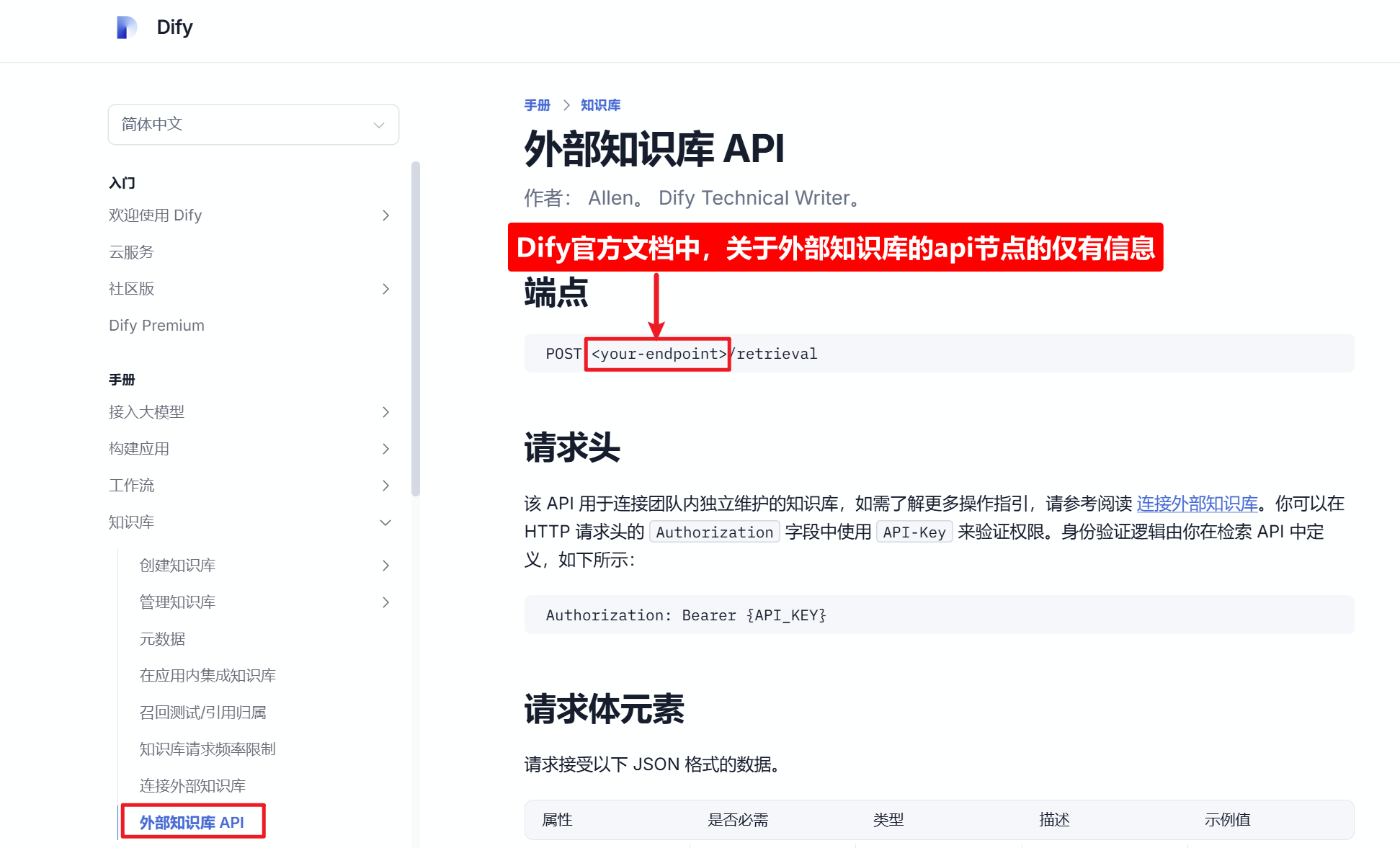
貌似找不出什么,因为这个节点肯定是由外部知识库定义,只要遵循Dify的端点定义要求就行了,即:url路径中要有一个/retrieval
2.1.确定ragflow的域名
接口是对外提供服务的,是后端服务,所以,他是ragflow-server提供的,我们可以看到,ragflow的容器中,ragflow-server是对外提供服务的,有两种服务:
- 一个是web网页端口的服务:默认是80端口,为了避免和dify端口冲突,我这里改为了8080端口,还有就是ssl端口443,我这里也改为了4434端口
- 另一个就是接口服务的端口:9380,这个就是我们的知识库接口对外的服务端口,web前端通过接口提供的服务,与后端进行数据交互

到这里,ragflow的外部知识库接口前面的节点就确定了:http://{你的IP}:9380
2.2. 确定IP地址
由于我们的项目是通过docker启动的,所以,统一使用 host.docker.internal:9380
这里解释一下这个域名:
host.docker.internal 是Docker提供的一种方便的机制,用于在开发和测试环境中从容器访问宿主机的服务。这个名称在Docker Desktop for Windows和Docker Desktop for Mac上是可用的,它允许容器中的应用程序访问宿主机上的服务和端口。
在不同的操作系统(如Windows和Mac)上,宿主机的IP地址可能会有所不同.host.docker.internal 提供了一个统一的名称,使得容器中的配置在不同平台上保持一致。
2.3.拼接完整域名
按照前面一步步推理,理论上来说,一个完整的api节点应该完整了,但是这就够了吗?
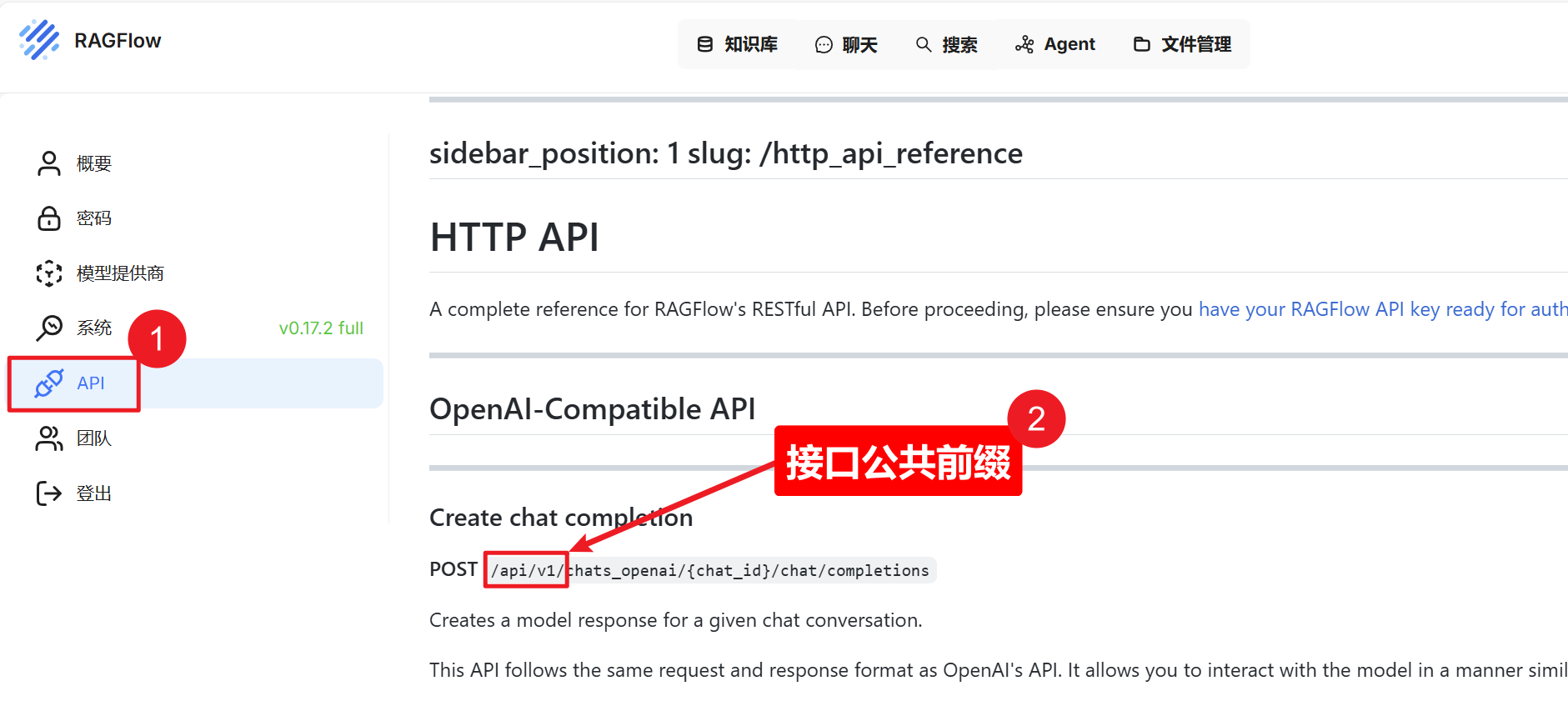
我们看下官方文档:
发现每个接口都有个公共前缀:/api/v1
这其实也是绝大多数后端服务的通行做法,加上前面我们拼接处的api节点,现在才算是完整的拼接出了api节点了:http://host.docker.internal:9380/api/v1/dify/retrieval
我们现在可以确定Dify中关于外部知识库的节点定义了,如下图:
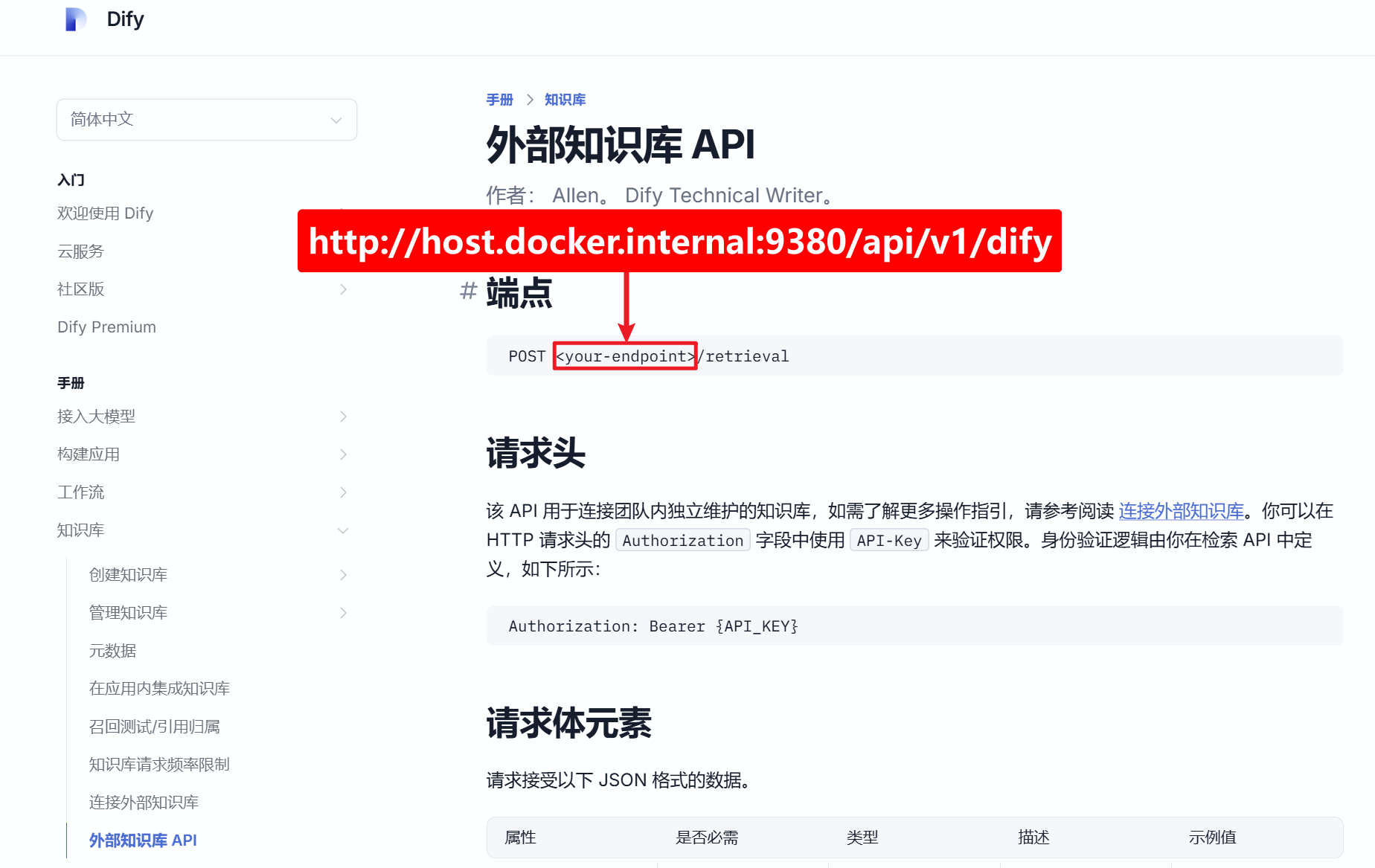
http://host.docker.internal:9380/api/v1/dify![]() http://host.docker.internal:9380/api/v1/dify
http://host.docker.internal:9380/api/v1/dify
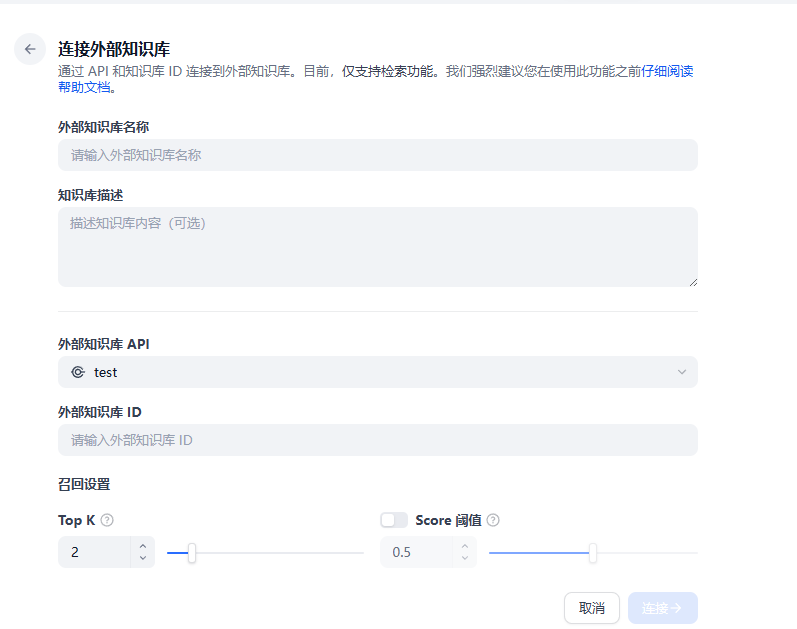
2.4.填写信息
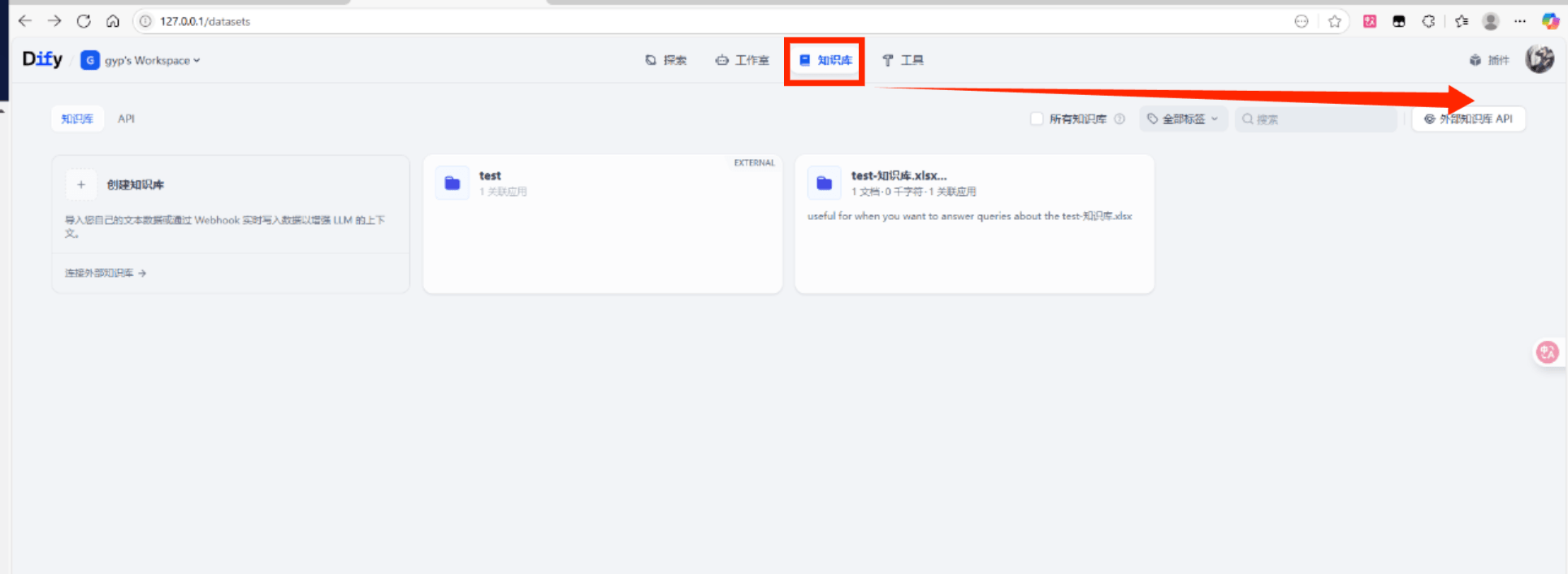
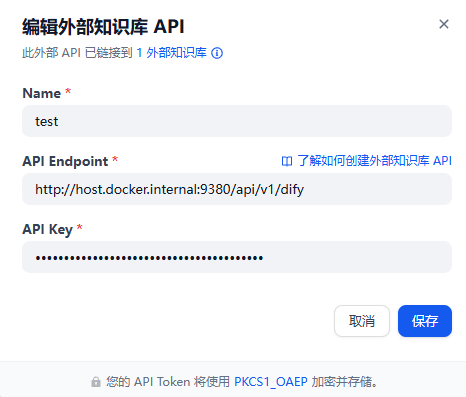
如果配置正确会显示出来。然后链接:
填写刚刚的外部知识库 API
3.聊天测试
创建一个聊天助手测试一下知识库,
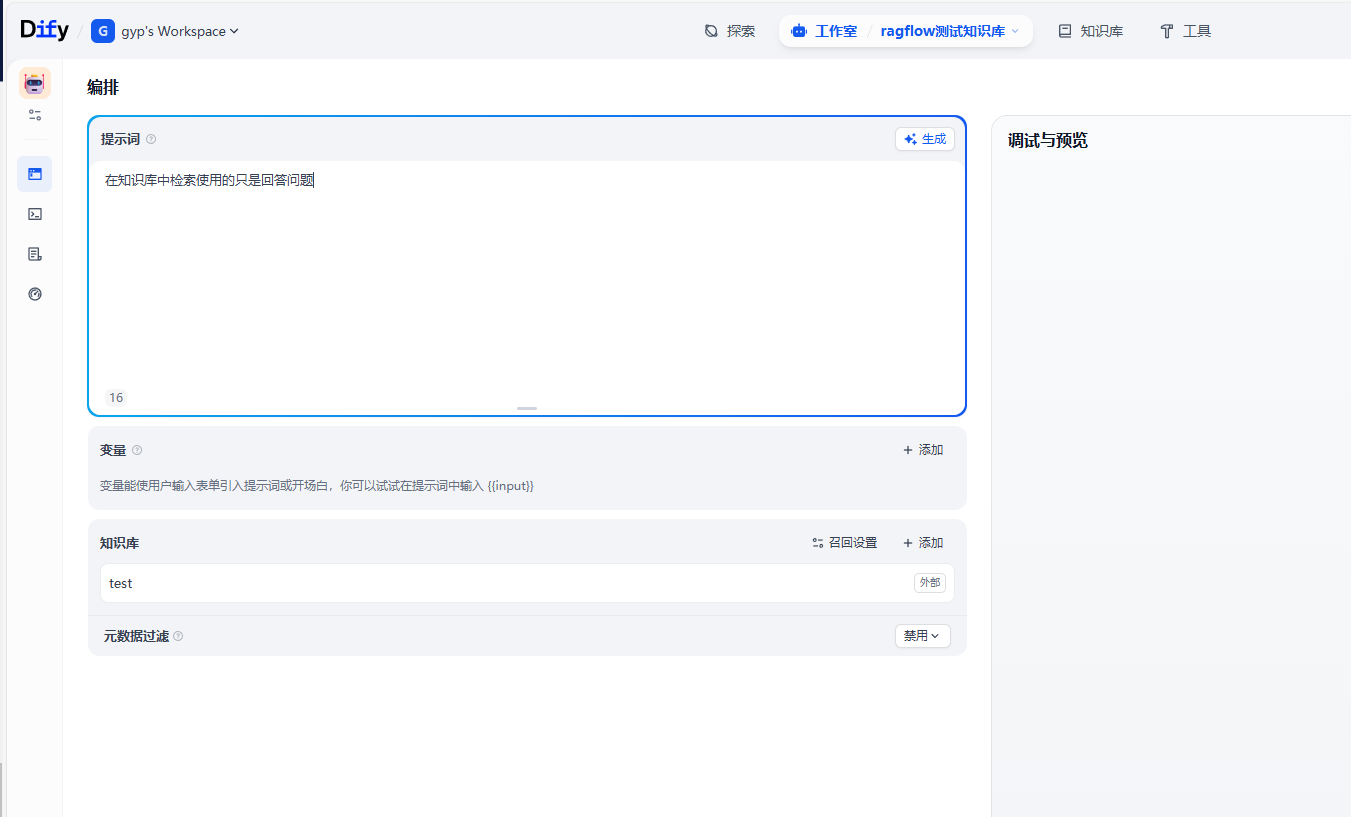
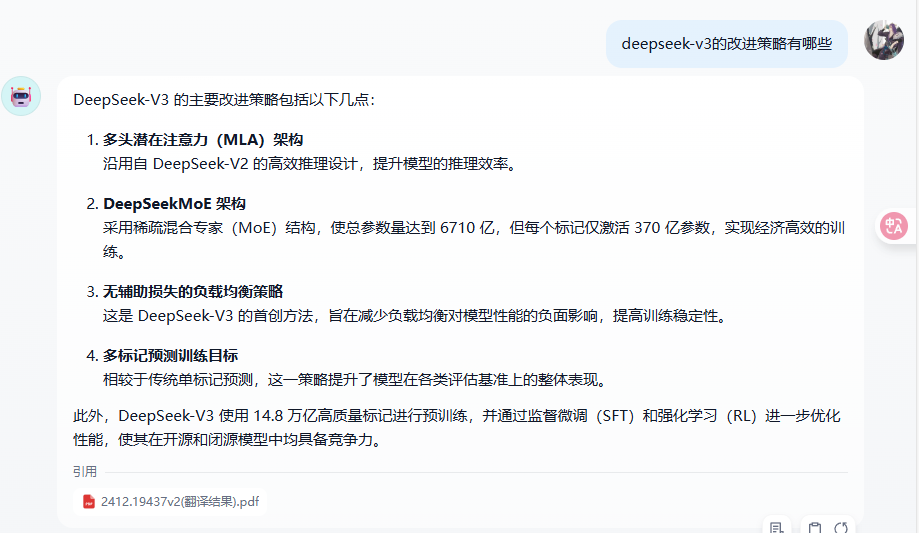
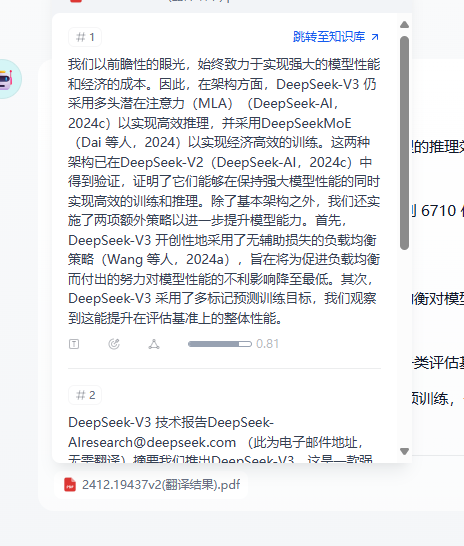
4.Python连接ragflow
Python 应用程序接口 |抹布流 --- Python API | RAGFlow
先安装所需要的包:
pip install ragflow-sdk
4.1.知识库管理
4.1.1.创建知识库
python
RAGFlow.create_dataset(
name: str,
avatar: Optional[str] = None,
description: Optional[str] = None,
embedding_model: Optional[str] = "BAAI/bge-large-zh-v1.5@BAAI",
permission: str = "me",
chunk_method: str = "naive",
pagerank: int = 0,
parser_config: DataSet.ParserConfig = None
) -> DataSet| 参数 | 类型 | 说明 | 可选值/默认值 |
|---|---|---|---|
| **name(必填)** | str | 数据集的唯一名称(最长128字符,不区分大小写) | - |
| avatar | str | 头像的Base64编码 | 默认:None |
| description | str | 数据集的简要描述 | 默认:None |
| permission | str | 数据集访问权限 | "me"(默认,仅自己可管理),"team"(全体团队成员可管理) |
| chunk_method | str | 数据集内容的分块方法 | "naive"(默认常规分块)、"manual"(手动)、"qa"(问答)、"table"(表格)、"paper"(论文)、"book"(书籍)、"laws"(法律)、"presentation"(演示文稿)、"picture"(图片)、"one"(单块)、"email"(邮件)、"knowledge-graph"(知识图谱) |
| pagerank | int | 数据集的PageRank值(影响排序权重) | 默认:0 |
| parser_config | dict | 解析器配置(根据chunk_method动态变化) |
详见下方说明 |
parser_config 详细说明(按分块方法)
| chunk_method | parser_config 配置 |
|---|---|
"naive"(常规) |
{"chunk_token_num":128, "delimiter":"\\n", "html4excel":False, "layout_recognize":True, "raptor":{"use_raptor":False}} |
"qa"(问答) |
{"raptor": {"use_raptor": False}} |
"manual"(手动) |
同上 |
"table"(表格) |
None |
"paper"(论文) |
同"qa" |
"book"(书籍) |
同"qa" |
"laws"(法律) |
同"qa" |
"picture"(图片) |
None |
"presentation"(演示) |
同"qa" |
"one"(单块) |
None |
"knowledge-graph"(知识图谱) |
{"chunk_token_num":128, "delimiter":"\\n", "entity_types":["organization","person","location","event","time"]} |
"email"(邮件) |
None |
简单的例子:
python
from ragflow_sdk import RAGFlow
rag_object = RAGFlow(api_key="***", base_url="http://host.docker.internal:9380")
#创建知识库
dataset = rag_object.create_dataset(name="gyp")在ragflow网站可以查看到:

4.1.2.删除知识库
python
RAGFlow.delete_datasets(ids: list[str] | None = None)按 ID 删除数据集。
如果为 None,则将删除所有数据集。
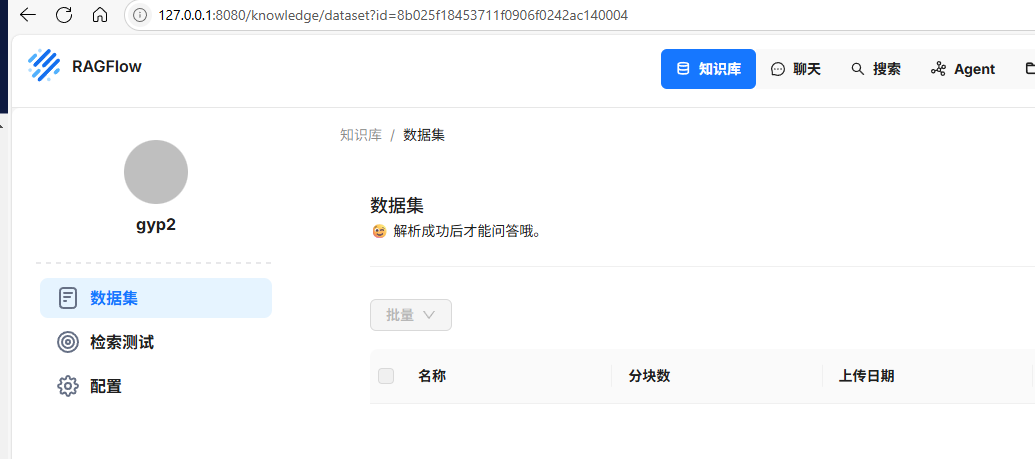
id:8b025f18453711f0906f0242ac140004
python
#8b025f18453711f0906f0242ac140004
rag_object.delete_datasets(ids=["8b025f18453711f0906f0242ac140004"])4.1.3.列出知识库
python
rag_object.list_datasets(
page: int = 1, #页码
page_size: int = 30,#每页数量
orderby: str = "create_time",#排序字段
desc: bool = True,#是否降序
id: str = None,#id
name: str = None#名称
) -> list[DataSet]
4.1.4.更新知识库
python
DataSet.update(update_message: dict)| 参数 | 类型 | 说明 | 约束/可选值 |
|---|---|---|---|
| update_message | dictstr, str|int | 包含待更新属性的字典,支持以下键: | - |
→ "name" |
str | 数据集的新名称 | - 仅限基本多语言平面(BMP)字符<br>- 最长128字符<br>- 不区分大小写 |
→ "avatar" |
str | 头像的Base64编码(Body参数) | - 最长65535字符 |
→ "embedding_model" |
str | 更新的嵌入模型名称(Body参数) | - 格式必须为 model_name@model_factory<br>- 最长255字符<br>- 需确保 chunk_count=0 才能更新 |
→ "permission" |
str | 数据集权限 | "me"(默认,仅自己可管理)<br>"team"(全体团队成员可管理) |
→ "pagerank" |
int | 数据集的PageRank值(影响排序权重) | - 默认值:0<br>- 范围:0 ~ 100 |
→ "chunk_method" |
enum<string> | 数据集内容的分块方法 | "naive"(默认常规)<br>"book"(书籍)<br>"email"(邮件)<br>"laws"(法律)<br>"manual"(手动)<br>"one"(单块)<br>"paper"(论文)<br>"picture"(图片)<br>"presentation"(演示文稿)<br>"qa"(问答)<br>"table"(表格)<br>"tag"(标签) |
python
from ragflow_sdk import RAGFlow
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
dataset = rag_object.list_datasets(name="kb_name")
dataset = dataset[0]
dataset.update({"embedding_model":"BAAI/bge-zh-v1.5", "chunk_method":"manual"})4.2.知识库文件管理
4.2.1.上传文件
python
DataSet.upload_documents(document_list: list[dict])#上传文件
python
dataset = rag_object.create_dataset(name="kb_name")
dataset.upload_documents([{"display_name": "1.txt", "blob": "<BINARY_CONTENT_OF_THE_DOC>"}, {"display_name": "2.pdf", "blob": "<BINARY_CONTENT_OF_THE_DOC>"}])
"display_name":(可选)要在数据集中显示的文件名。
"blob":(可选)要上传的文件的二进制内容。
4.2.2.更新文件
python
from ragflow_sdk import RAGFlow
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
dataset = rag_object.list_datasets(id='id')
dataset = dataset[0]
doc = dataset.list_documents(id="wdfxb5t547d")
doc = doc[0]
doc.update([{"parser_config": {"chunk_token_count": 256}}, {"chunk_method": "manual"}])4.2.3.下载文件
python
from ragflow_sdk import RAGFlow
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
dataset = rag_object.list_datasets(id="id")
dataset = dataset[0]
doc = dataset.list_documents(id="wdfxb5t547d")
doc = doc[0]
open("~/ragflow.txt", "wb+").write(doc.download())
print(doc)4.2.4.列出文件
python
from ragflow_sdk import RAGFlow
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
dataset = rag_object.create_dataset(name="kb_1")
filename1 = "~/ragflow.txt"
blob = open(filename1 , "rb").read()
dataset.upload_documents([{"name":filename1,"blob":blob}])
for doc in dataset.list_documents(keywords="rag", page=0, page_size=12):
print(doc)4.2.5.删除文件
python
from ragflow_sdk import RAGFlow
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
dataset = rag_object.list_datasets(name="kb_1")
dataset = dataset[0]
dataset.delete_documents(ids=["id_1","id_2"])4.2.6.解析文件
python
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
dataset = rag_object.create_dataset(name="dataset_name")
documents = [
{'display_name': 'test1.txt', 'blob': open('./test_data/test1.txt',"rb").read()},
{'display_name': 'test2.txt', 'blob': open('./test_data/test2.txt',"rb").read()},
{'display_name': 'test3.txt', 'blob': open('./test_data/test3.txt',"rb").read()}
]
dataset.upload_documents(documents)
documents = dataset.list_documents(keywords="test")
ids = []
for document in documents:
ids.append(document.id)
dataset.async_parse_documents(ids)
print("Async bulk parsing initiated.")4.2.7.停止解析
python
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
dataset = rag_object.create_dataset(name="dataset_name")
documents = [
{'display_name': 'test1.txt', 'blob': open('./test_data/test1.txt',"rb").read()},
{'display_name': 'test2.txt', 'blob': open('./test_data/test2.txt',"rb").read()},
{'display_name': 'test3.txt', 'blob': open('./test_data/test3.txt',"rb").read()}
]
dataset.upload_documents(documents)
documents = dataset.list_documents(keywords="test")
ids = []
for document in documents:
ids.append(document.id)
dataset.async_parse_documents(ids)
print("Async bulk parsing initiated.")
dataset.async_cancel_parse_documents(ids)
print("Async bulk parsing cancelled.")