前言
不到3B的参数量,仅需7GB显存,却能实现高精度的表格识别、公式解析、图像语义理解、视觉元素分割,甚至一键完成多模态PDF到MarkDown的转换------在多项评测中,它都拿下了SOTA成绩。相信最近不少人都被DeepSeek最新开源的DeepSeek-OCR刷屏了。
在视觉与语言多模态任务日益重要的今天,DeepSeek-OCR无疑提供了一个高性价比的图像识别解决方案。你可能会问:OCR不是早就有了吗?它不就是用来识别图片中的文字吗?为什么这次DeepSeek发布的OCR模型会引起如此大的关注?
实际上,OCR技术早已超越了"文字识别"的范畴。尤其是在大模型时代,它扮演着举足轻重的角色。大语言模型的训练离不开海量高质量数据,而这些数据往往来源于网页、文档、扫描书籍乃至图像。如何将这些非结构化内容准确、高效地转换为结构化文本(如MarkDown),OCR的处理能力尤为关键。
本期内容笔者就和大家一起回顾OCR技术的发展历程,从早期的深度学习模型,到如今的大模型时代。可以说,在多模态能力日益成为标配的今天,OCR已逐渐成为大模型的"眼睛",未来甚至可能决定各大语言模型训练数据的质量与规模。

一、OCR模型技术发展历史
1.1 OCR 1.0:理解世界从识字开始
在人工智能的发展历程中,OCR(Optical Character Recognition,光学字符识别) 是最早实现"机器理解文字"的技术之一。它让计算机首次具备了"看懂"图像中文字的能力------无论是扫描文档、票据还是街景招牌中的文字,都能被自动识别为可编辑、可检索的文本。可以说,OCR是机器"识字"之路的起点。
相信大家都是从深度学习开始入门大模型,而对于许多深度学习学习者来说,手写数字识别任务往往是大家入门的第一课,这其实正是早期OCR技术的典型应用场景。我们将那个以深度学习方法初步解决文字识别问题的阶段,称为OCR 1.0时代。

OCR 1.0 主要基于CNN(卷积神经网络)与LSTM(长短期记忆网络)结合的深度学习模型,例如CRNN、CTC等经典架构。其系统通常由两个独立模块构成:
- 文字检测:定位图像中的文本区域;
- 文字识别:将检测出的文字区域转换为具体文本内容。
这一阶段的技术核心是解决"机器如何读懂文字"的问题,重点提升识别准确率、字体鲁棒性及多语言支持能力。在实际应用中,OCR 1.0 已广泛应用于多个场景:
- 银行票据识别与自动化录入;
- 身份证、驾驶证、发票等证照信息提取;
- 扫描文档的数字化存档;
- 翻译软件中的实时摄像头翻译(如 Google Translate)。
这些应用极大地推动了信息数字化进程,成为"无纸化办公"与"自动化文档处理"的重要基础。

1.2 OCR2.0: 语义结构识别
随着信息载体的多样化,纯文本已不再是唯一的信息形式。图像、表格、公式、图纸、网页及PDF等复杂版式内容成为新的知识容器。传统OCR虽能识别字符,却往往无法理解内容之间的语义与结构关系------它能读出文字,却无法判断其是标题、表格项还是公式的一部分。
为突破这一瓶颈,OCR技术演进至2.0阶段,开始在模型中引入:
- 视觉 Transformer(Vision Transformer, ViT)结构;
- 布局分析(Layout Analysis) ;
- 视觉语言对齐(Vision-Language Alignment)
有了这些结构,OCR2.0时代的模型不仅能识别文字,还能输出带有结构信息的Markdown、HTML 或 JSON 文档,理解表格、公式、图形之间的关系。此时OCR模型已经由原先1.0时代的"看字"升级成了2.0时代的"看文档版面"。这一阶段的OCR代表模型有微软的LayoutLM,百度的PaddleOCR 2.0, DeepSeek最新出的DeepSeek-OCR也可以划分到这一类型中。
1.3 VLM:利用多模态模型看世界
2023年以来,大模型技术的爆发彻底改变了深度学习的格局。以GPT-4V、Gemini、Qwen-VL、InternVL等为代表的视觉语言模型(Vision-Language Model, VLM) ,让人工智能真正具备了"图文双修"的能力。
多模态技术的核心,在于将图像与文本映射到同一语义空间(Shared Semantic Space) 中。无论输入是图像还是文本,模型都能在高维表示中找到它们之间的语义对应关系,从而实现"以文释图、以图辅文"的理解与生成。
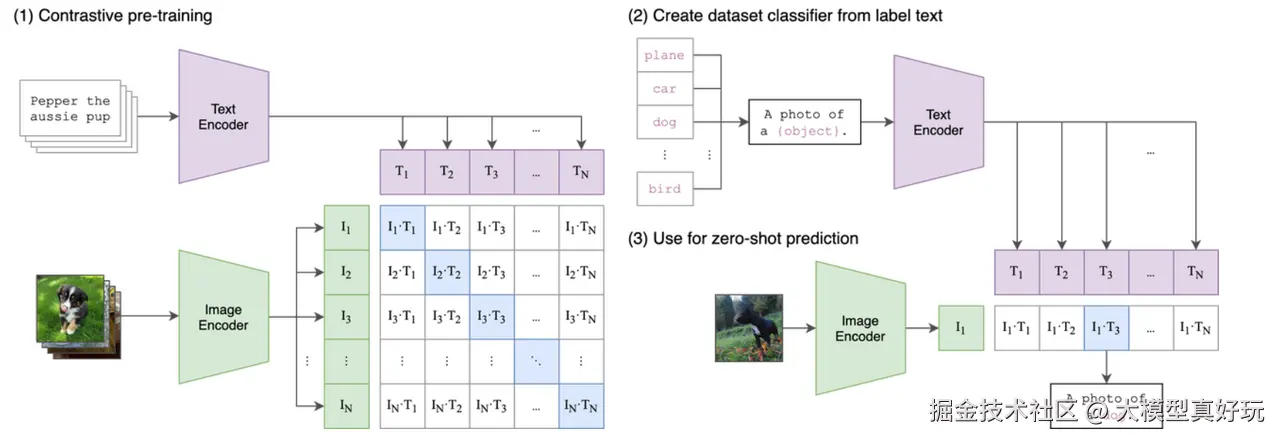
这类模型不仅能识别文字,还能理解图像中的语义内容,完成论文解析、图表理解、图纸识别乃至生成结构化Markdown文本等复杂任务。其实现依赖视觉编码器将图像转换为视觉特征,再经由语言模型对齐并输出文本描述。
然而,通用VLM模型在专业OCR任务中也存在局限:推理速度较慢,且在精细文字识别上容易出现疏忽(大家可以理解为因为模型参数过大运行速度较慢,模型主要是图片语义理解转化功能在转化方面自然有些许欠缺)。因此,目前出现了许多基于VLM微调的专业OCR模型,相比通用大模型,它们在特定任务中表现更优,例如:
- 图像实体识别;
- PDF版面分割;
- 信息抽取与结构化输出;
- PDF到MarkDown的一键转换。
这类模型可视为OCR 2.0的增强版,代表作品包括小红书发布的docs.ocr、Allen Institute的olmOCR等。它们在保持多模态理解能力的同时,显著提升了OCR任务的精度与效率。
二、主流VLM与OCR模型介绍
OCR 1.0时代的模型已逐渐无法满足当前复杂场景的需求。下面将为大家介绍目前主流的开源视觉语言模型(VLM)与新一代OCR模型。
2.1 开源VLM模型
2.1.1 InternVL 3.5
InternVL 3.5 由上海人工智能实验室联合多家科研团队于2025年推出,是继 InternVL 2.x 系列之后的重大升级。该模型参数量覆盖 8B 至 40B ,在图像理解、表格解析、跨模态检索和复杂推理等方面均有显著提升。特别值得一提的是,它引入了Cascade RL(级联强化学习) 策略,有效增强了模型在多步推理任务中的稳定性,使其在图表问答、科学文献解析等场景中表现优异。InternVL 3.5具备推理链条完整、跨模态任务性能强的优势,然而也面临大尺寸版本显存占用较高,对硬件有一定要求的弊端。

2.1.2 Qwen3-VL
Qwen3-VL 是阿里巴巴通义实验室于2025年发布的新一代视觉语言模型,也是 Qwen2.5-VL 的升级版本。模型参数量覆盖 3B、7B 至 72B,可满足从轻量化部署到高性能推理的各类需求,具备目标检测、图表理解、视频解析等全面的多模态能力。Qwen3-VL 在跨语言文档解析和长视频理解方面进行了专门优化,延续了 Qwen 系列在企业级开源社区中的广泛影响力。Qwen3-VL具备模型尺寸选择多样,兼顾性能与成本;在文档与图表解析方面表现突出。但同样也具有小参数版本能力一般,大参数版本对高端GPU依赖较强,推理延迟较高的缺点。

2.2 开源OCR模型
2.2.1 DeepSeek-OCR
DeepSeek-OCR 采用创新的视觉-文本压缩架构 ,其核心由 DeepEncoder 视觉压缩模块与 MoE 专家解码器组成。DeepEncoder 通过串联设计(窗口注意力 SAM-base → 16倍卷积压缩器 → CLIP-large)实现对高分辨率输入的高效 token 压缩。基于 DeepSeek-3B-MoE 的解码器仅激活约 570M 参数即可有效重建原始文本表示。该设计在处理长文档时,可将每页 token 数从数千压缩至仅 256 个,内存占用降低超过10倍 ,同时保持 97% 以上的准确率,尤其适用于长文档处理 与多页面批量任务。

2.2.2 PaddleOCR
PaddleOCR 是目前工业界应用最广泛的开源OCR工具库之一,坚持采用成熟的两阶段架构 (检测→识别),并为不同阶段提供了丰富的模型选择。在文本检测方面,支持 DB、EAST、SAST 等多种模型;在文本识别方面,则提供 CRNN、SVTR、PP-OCRv4 等选项,兼顾精度与效率。其最大优势在于丰富的垂类场景适配能力 ,包括表格、票据、手写体等专项优化模型,以及完善的工具链生态,覆盖从数据标注、模型训练到多端部署的全流程。
2.2.3 MonkeyOCR
MonkeyOCR 创新性地提出 Structure-Recognition-Relation (SRR) 三元组设计理念 ,在传统管道方法与端到端方法之间取得了良好平衡。该模型首先通过 DocLayout-YOLO 进行文档结构检测与分块,随后使用轻量级LLM对每个文本块进行识别,最后基于整体文档结构预测各区块之间的逻辑关系。这一设计既避免了管道方法中的错误累积问题,又显著降低了端到端方法的计算负担,使得模型在单张3090显卡上即可高效部署,在复杂版面解析任务中表现出色。

三、OCR大模型应用指南:三大场景最佳实践
在OCR领域,并没有"一家独大"的最强模型,不同模型往往在不同任务中表现出各自的优势。下面笔者将结合实际项目经验,为大家梳理三类典型应用场景下的模型选型建议。
3.1 长文档处理
在处理合同、财报、法律文书 等篇幅长、结构复杂且精度要求高的文档时,DeepSeek-OCR表现尤为出色。例如,在处理一份158页、带有大量批注的并购合同时,DeepSeek-OCR的批注关联准确率达到89.5%,能够完整保留条款间的逻辑关系,比传统Tesseract 5.0高出27个百分点。
这类场景通常包含大量表格、注释和交叉引用,DeepSeek-OCR采用的视觉-文本压缩技术能够在维持文档整体性的同时,避免分段处理带来的上下文断裂问题,确保关键数据的精确提取。
在DeepSeek-OCR发布之前,我们团队使用MinerU 处理固定版式报表也取得了不错的效果。MinerU并非单一框架,而是一个由阿里巴巴达摩院与OpenDataLab社区联合开源的工具集,支持灵活配置版面解析、结构化抽取和多模态VLM模型。它在处理学术论文、扫描件和复杂排版文档时表现突出,特别在公式、表格、图片引用等细节保留上效果优异,输出的Markdown文档能较好地还原原始语义。
3.2 论文与教育资料处理
对于学术论文、教材、科研资料 等专业文档的数字化处理,MonkeyOCR 和DeepSeek-OCR各有专长。
MonkeyOCR在处理含有复杂公式的学术文献时表现卓越。例如,在解析一篇62页、包含45个复杂公式的Nature论文时,其公式识别准确率达到92.1%,生成的LaTeX格式几乎无需修改即可直接使用。其SRR(Structure-Recognition-Relation)三元组设计能有效理解学术文档的层级结构和元素间关系。
DeepSeek-OCR则在处理交叉引用、参考文献和专业术语方面表现优异,特别适合构建学术文献知识库等需要深度语义理解的场景。在实际应用中,可结合两者优势:使用MonkeyOCR处理公式和图表,DeepSeek-OCR提取正文内容和进行语义理解,实现全面的学术资料数字化。
3.3 边缘计算与轻量化场景
在移动应用、IoT设备、边缘服务器等计算资源受限的环境中,模型的轻量化和推理效率至关重要。
MonkeyOCR 凭借其动态注意力机制,在树莓派4B上仅占用35%内存即可稳定运行,在Jetson AGX Xavier平台上能支持4路摄像头同时处理,非常适合智能零售、工业质检等对实时性要求较高的场景。
PaddleOCR 的轻量版模型在移动端表现出色,推理延迟可控制在100毫秒以内,支持Android/iOS原生部署,特别适合身份证识别、银行卡识别、车牌识别等短文本、固定版式的应用场景。
四、总结与展望
本篇分享系统梳理了OCR技术的发展脉络:从OCR 1.0时代基于CNN+LSTM的文本识别,到OCR 2.0时代引入ViT和版面分析的语义结构理解,再到当前融合多模态大模型的VLM阶段。文章详细分析了DeepSeek-OCR、PaddleOCR、MonkeyOCR等主流模型的架构特点,并针对长文档处理、学术资料数字化和边缘计算三大场景提供了实践指南。
未来OCR技术将朝着更深度的多模态融合与端到端结构化理解发展,轻量化技术与专用模型优化将推动OCR在边缘设备与实时场景的普及,使其真正成为大模型感知现实世界的"眼睛"。
以上就是本篇分享的全部内容。大家阅读后感兴趣可关注笔者掘金账号和专栏。同时笔者的相关教程专栏也广受好评, 低代码Agent开发相关文章已全部收录于笔者专栏《AI应用工厂:低代码智能体开发使用指南》。对于有经验喜欢写代码的开发者也可以阅读笔者的LangChain/LangGraph系列教程专栏,目前已经更完22节并还在持续更新中。该专栏融合了笔者在实战中积累的深度经验,系统讲解如何基于LangChain与LangGraph框架高效开发智能体,助你快速构建专业级应用。大家可关注笔者同名微信公众号: 大模型真好玩 , 每期分享涉及的代码均可在公众号私信: LangChain智能体开发获得。