KM曲线
在分析疾病的死亡率时,我们往往会纠结于怎样在逻辑架构中去考虑未死亡的人群,以及想研究两种药物的表现效果,但病人的指标表现都不明显,作用于其他指标且很难量化。
而KM曲线可以很好地反映人群在时间序列上的生存率,且能考虑到中途生存出院的数据,因为死亡率并不会等到病人都死亡了再去计算,而KM曲线对于这类数据的处理是出院人群不影响生存概率,即不会提高它,只是当做数据集的长度变短了,这样可以有效避免对于生存率和药物效果的误判。
这里举一个例子来说明:
R
library(survival)
library(survminer)
# 1. 生成模拟数据集
set.seed(123) # 确保结果可重复
n <- 100 # 样本量
# 创建数据集:时间、事件状态(1=发生事件,0=删失)、组别
time <- round(rexp(n, rate=1/50), 1) # 生存时间(指数分布)
status <- rbinom(n, size=1, prob=0.7) # 70%的概率发生事件
group <- sample(c("A", "B"), n, replace=TRUE) # 随机分组
# 创建数据框
surv_data <- data.frame(time, status, group)
# 查看前几行数据
head(surv_data)
# 2. 拟合KM模型
km_fit <- survfit(Surv(time, status) ~ group, data=surv_data)
# 3. 绘制KM曲线
ggsurvplot(km_fit,
data = surv_data,
pval = TRUE, # 显示p值
conf.int = TRUE, # 显示置信区间
risk.table = TRUE, # 显示风险表
palette = c("#E7B800", "#2E9FDF"), # 颜色
xlab = "Time (days)", # x轴标签
ylab = "Survival Probability", # y轴标签
title = "Kaplan-Meier Survival Curve", # 标题
legend.labs = c("Group A", "Group B")) # 图例标签
# 4. 查看汇总统计
summary(km_fit)
# 5. 计算中位生存时间
km_fit输出:
R
Call: survfit(formula = Surv(time, status) ~ group, data = surv_data)
group=A
time n.risk n.event survival std.err lower 95% CI upper 95% CI
0.2 61 1 0.9836 0.0163 0.95225 1.000
2.1 60 1 0.9672 0.0228 0.92354 1.000
2.8 58 1 0.9505 0.0278 0.89750 1.000
3.4 57 1 0.9339 0.0320 0.87327 0.999
7.3 54 1 0.9166 0.0357 0.84912 0.989
10.8 53 1 0.8993 0.0390 0.82594 0.979
13.0 51 1 0.8816 0.0421 0.80294 0.968
14.0 49 1 0.8636 0.0449 0.78001 0.956
14.1 48 1 0.8457 0.0474 0.75764 0.944
14.2 47 1 0.8277 0.0497 0.73575 0.931
15.3 45 1 0.8093 0.0519 0.71369 0.918
15.7 44 1 0.7909 0.0539 0.69203 0.904
15.8 42 1 0.7720 0.0558 0.67010 0.890
16.0 41 1 0.7532 0.0575 0.64852 0.875
19.0 40 1 0.7344 0.0591 0.62726 0.860
24.0 39 1 0.7156 0.0605 0.60630 0.845
28.2 38 1 0.6967 0.0618 0.58561 0.829
29.5 36 1 0.6774 0.0630 0.56449 0.813
31.5 35 1 0.6580 0.0641 0.54364 0.796
32.2 34 1 0.6387 0.0651 0.52304 0.780
34.3 33 1 0.6193 0.0659 0.50270 0.763
39.5 32 1 0.6000 0.0666 0.48258 0.746
48.3 29 1 0.5793 0.0675 0.46103 0.728
48.6 28 1 0.5586 0.0682 0.43975 0.710
48.7 27 1 0.5379 0.0687 0.41876 0.691
51.4 25 1 0.5164 0.0692 0.39703 0.672
56.5 23 1 0.4939 0.0698 0.37446 0.652
59.6 22 1 0.4715 0.0701 0.35225 0.631
62.7 21 1 0.4490 0.0703 0.33039 0.610
66.5 20 1 0.4266 0.0703 0.30887 0.589
72.0 18 1 0.4029 0.0702 0.28625 0.567
74.8 16 1 0.3777 0.0702 0.26235 0.544
78.2 13 1 0.3486 0.0706 0.23446 0.518
78.5 11 2 0.2853 0.0706 0.17566 0.463
81.0 9 1 0.2536 0.0695 0.14820 0.434
86.6 8 1 0.2219 0.0676 0.12207 0.403
92.8 7 1 0.1902 0.0650 0.09734 0.372
108.4 6 1 0.1585 0.0614 0.07417 0.339
136.3 4 1 0.1189 0.0574 0.04611 0.306
202.1 3 1 0.0792 0.0501 0.02294 0.274
224.9 2 1 0.0396 0.0376 0.00617 0.254
360.6 1 1 0.0000 NaN NA NA
Call: survfit(formula = Surv(time, status) ~ group, data = surv_data)
n events median 0.95LCL 0.95UCL
group=A 61 43 56.5 39.5 78.5
group=B 39 28 53.4 42.5 82.1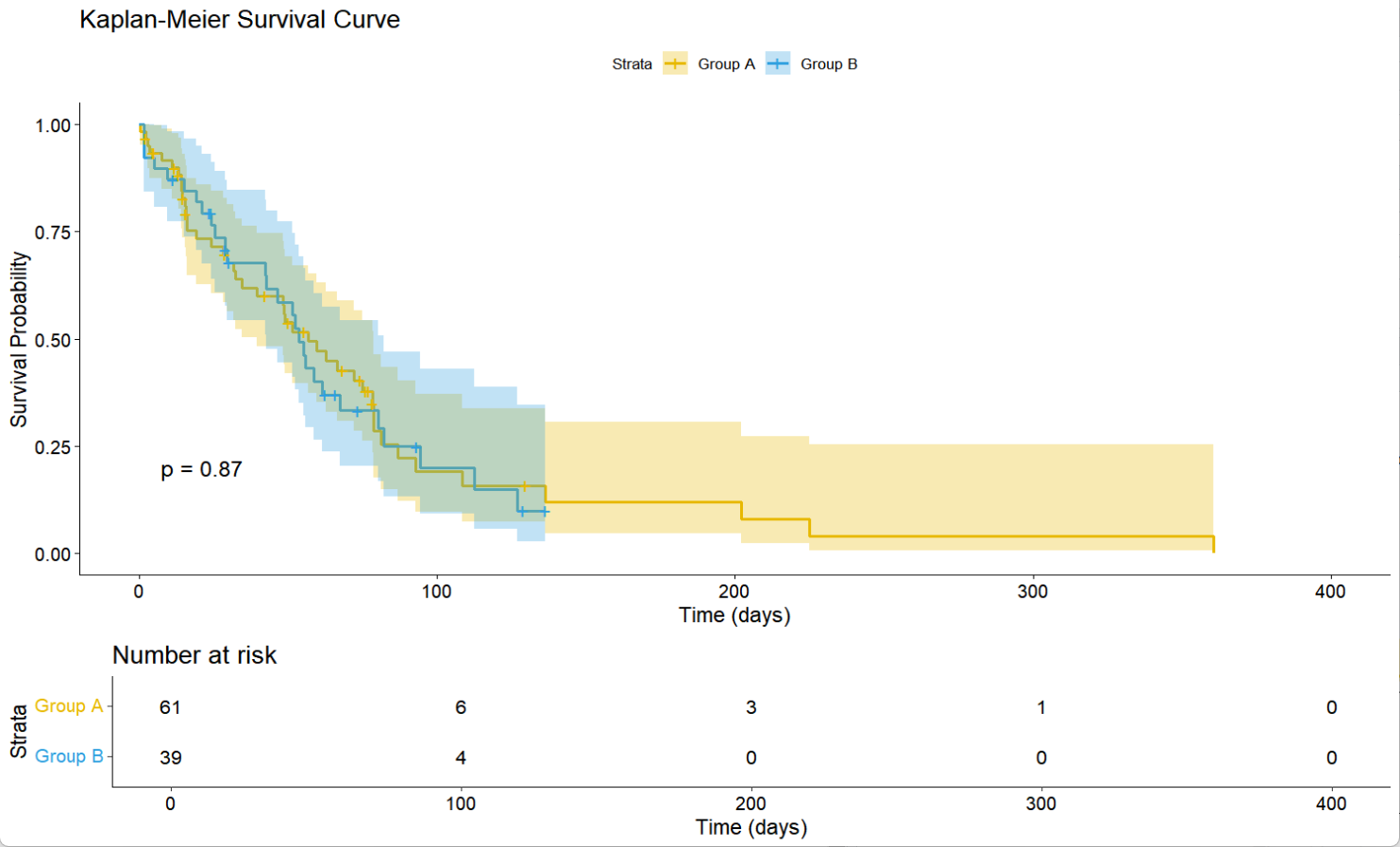
从输出中,我们可以观察到两组的中位生存时间很接近,说明两组数据的病人存活率差不多,而图片中两条曲线的趋势相近,且置信区间(图中的阴影部分)大部分重叠,更进一步说明了两组数据的差异性不大。最后观察p值远大于0.05,说明在统计上两组数据没有显著不同。但要注意的是,随着时间的推移,样本量的数量在急剧减少,在过了随访时间后,就很难跟踪到病人进一步的变化,所以要想确定结论是否是对的,还需要扩大数据量去进一步分析。