DAY 53 对抗生成网络
知识点回顾:
- 对抗生成网络的思想:关注损失从何而来
- 生成器、判别器
- nn.sequential容器:适合于按顺序运算的情况,简化前向传播写法
- leakyReLU介绍:避免relu的神经元失活现象
ps;如果你学有余力,对于gan的损失函数的理解,建议去找找视频看看,如果只是用,没必要学
**作业:**对于心脏病数据集,对于病人这个不平衡的样本用GAN来学习并生成病人样本,观察不用GAN和用GAN的F1分数差异。
1、对抗生成网络的思想:关注损失从何而来

2、生成器、判别器
python
# (A) 生成器 (Generator)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(LATENT_DIM, 16),
nn.ReLU(),
nn.Linear(16, 32),
nn.ReLU(),
nn.Linear(32, 4),# 最后的维度只要和目标数据对齐即可
nn.Tanh() # 输出范围是 [-1, 1]
)
def forward(self, x):
return self.model(x) # 因为没有像之前一样做定义x=某些东西,所以现在可以直接输出模型
python
# (B) 判别器 (Discriminator)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(4, 32),
nn.LeakyReLU(0.2), # LeakyReLU 是 GAN 中的常用选择
nn.Linear(32, 16),
nn.LeakyReLU(0.2), # 负斜率参数为0.2
nn.Linear(16, 1), # 这里最后输出1个神经元,所以用sigmoid激活函数
nn.Sigmoid() # 输出 0 到 1 的概率
)
def forward(self, x):
return self.model(x)3、nn.sequential容器:适合于按顺序运算的情况,简化前向传播写法

4、leakyReLU介绍:避免relu的神经元失活现象

作业:
不使用GAN:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data=pd.read_csv('heart.csv')
# 查看数据
# print(data.info())
# print(data.head())
continous_features=['age','trestbps','chol','thalach','oldpeak','cp']
discrete_features=['sex','fbs','restecg','exang','slope','ca','thal']
# for feature in discrete_features:
# print(f"\n{feature}的取值:")
# print(data[feature].value_counts())
# 缺失值处理,改数据集中无缺失值
# data.isnull().sum()
# 异常值除非录入错误,通常不处理,防止模型过拟合
# 可视化分析
# fig,axes=plt.subplots(2,3,figsize=(12,8))
# for i,feature in enumerate(continous_features):
# row=i//3
# col=i%3
# axes[row,col].boxplot(data[feature])
# axes[row,col].set_title(f'Boxplot of {feature}')
# axes[row,col].set_ylabel(feature)
# plt.tight_layout()
# plt.show()
# fig1, axes1 = plt.subplots(2, 4, figsize=(12, 8))
# for i,feature in enumerate(discrete_features):
# row=i//4
# col=i%4
# sns.countplot(x=feature, data=data, ax=axes1[row, col])
# axes1[row, col].set_title(f'Countplot of {feature}')
# axes1[row, col].set_xlabel(feature)
# plt.tight_layout()
# plt.show()
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression #逻辑回归分类器
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
x=data.drop(['target'],axis=1)
y=data['target']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=42)
# 打印训练集和测试集的形状
print(f"训练集形状: {x_train.shape}, 测试集形状: {x_test.shape}")
# Logistic Regression
lr_model=LogisticRegression()
lr_model.fit(x_train,y_train)
lr_predictions=lr_model.predict(x_test)
print('分类报告:')
print(classification_report(y_test,lr_predictions))
print('混淆矩阵:')
print(confusion_matrix(y_test,lr_predictions))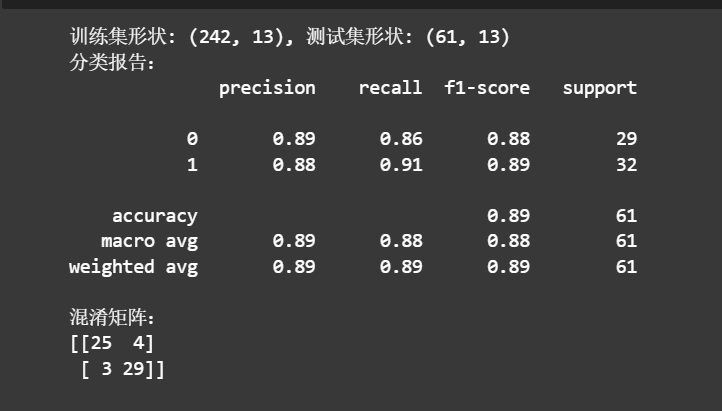
使用GAN:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data=pd.read_csv('heart.csv')
continous_features=['age','trestbps','chol','thalach','oldpeak','cp']
discrete_features=['sex','fbs','restecg','exang','slope','ca','thal']
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
LATENT_DIM = 13 # 潜在空间的维度,这里根据任务复杂程度任选
EPOCHS = 10000 # 训练的回合数,一般需要比较长的时间
BATCH_SIZE = 32 # 每批次训练的样本数
LR = 0.0002 # 学习率
BETA1 = 0.5 # Adam优化器的参数
# 检查是否有可用的GPU,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# (A) 生成器 (Generator)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(LATENT_DIM, 16),
nn.ReLU(),
nn.Linear(16, 32),
nn.ReLU(),
nn.Linear(32, 13),# 最后的维度只要和目标数据对齐即可
nn.Tanh() # 输出范围是 [-1, 1]
)
def forward(self, x):
return self.model(x) # 因为没有像之前一样做定义x=某些东西,所以现在可以直接输出模型
# (B) 判别器 (Discriminator)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(13, 32),
nn.LeakyReLU(0.2), # LeakyReLU 是 GAN 中的常用选择
nn.Linear(32, 16),
nn.LeakyReLU(0.2), # 负斜率参数为0.2
nn.Linear(16, 1), # 这里最后输出1个神经元,所以用sigmoid激活函数
nn.Sigmoid() # 输出 0 到 1 的概率
)
def forward(self, x):
return self.model(x)
X=data.drop('target',axis=1)
y=data['target']
# 病人数据
X_class0=X[y==1]
# 数据缩放到 [-1, 1]
scaler = MinMaxScaler(feature_range=(-1, 1))
X_scaled = scaler.fit_transform(X_class0)
# 转换为 PyTorch Tensor 并创建 DataLoader
# 注意需要将数据类型转为 float
real_data_tensor = torch.from_numpy(X_scaled).float()
dataset = TensorDataset(real_data_tensor)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
print(f"成功加载并预处理数据。用于训练的样本数量: {len(X_scaled)}")
print(f"数据特征维度: {X_scaled.shape[1]}")
# --- 3. 初始化生成器和判别器 ---
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# print(generator)
# print(discriminator)
# --- 4. 定义损失函数和优化器 ---
criterion = nn.BCELoss() # 二元交叉熵损失
# 分别为生成器和判别器设置优化器
g_optimizer = optim.Adam(generator.parameters(), lr=LR, betas=(BETA1, 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=LR, betas=(BETA1, 0.999))
# --- 5. 执行训练循环 ---
print("\n--- 开始训练 ---")
for epoch in range(EPOCHS):
for i, (real_data,) in enumerate(dataloader):
# 将数据移动到设备
real_data = real_data.to(device)
# 获取当前批次中样本的数量,real_data 的形状通常是 [batch_size, channels, height, width],size (0) 表示获取第 0 维的大小,即批次大小
current_batch_size = real_data.size(0)
# 创建真实和虚假的标签
# 创建一个形状为 [batch_size, 1] 的张量,所有元素初始化为 1,表示这些是真实样本
real_labels = torch.ones(current_batch_size, 1).to(device)
fake_labels = torch.zeros(current_batch_size, 1).to(device)
# ---------------------
# 训练判别器
# ---------------------
d_optimizer.zero_grad() # 梯度清零
# (1) 用真实数据训练
real_output = discriminator(real_data)
d_loss_real = criterion(real_output, real_labels)
# (2) 用假数据训练
noise = torch.randn(current_batch_size, LATENT_DIM).to(device)
# 使用 .detach() 防止在训练判别器时梯度流回生成器,这里我们未来再说
fake_data = generator(noise).detach()
fake_output = discriminator(fake_data)
d_loss_fake = criterion(fake_output, fake_labels)
# 总损失并反向传播
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
d_optimizer.step()
# ---------------------
# 训练生成器
# ---------------------
g_optimizer.zero_grad() # 梯度清零
# 生成新的假数据,并尝试"欺骗"判别器
noise = torch.randn(current_batch_size, LATENT_DIM).to(device)
fake_data = generator(noise)
fake_output = discriminator(fake_data)
# 计算生成器的损失,目标是让判别器将假数据误判为真(1)
g_loss = criterion(fake_output, real_labels)
# 反向传播并更新生成器
g_loss.backward()
g_optimizer.step()
# 每 1000 个 epoch 打印一次训练状态
if (epoch + 1) % 1000 == 0:
print(
f"Epoch [{epoch+1}/{EPOCHS}], "
f"Discriminator Loss: {d_loss.item():.4f}, "
f"Generator Loss: {g_loss.item():.4f}"
)
print("--- 训练完成 ---")
# --- 6. 生成新数据并进行可视化对比 ---
# 设置替代中文字体(适用于Linux)
plt.rcParams["font.family"] = ["WenQuanYi Micro Hei"]
plt.rcParams['axes.unicode_minus'] = False
print("\n--- 生成并可视化结果 ---")
# 将生成器设为评估模式
generator.eval()
# 使用 torch.no_grad() 来关闭梯度计算
with torch.no_grad():
# 生成50个新样本数量
num_new_samples = 50
noise = torch.randn(num_new_samples, LATENT_DIM).to(device)
generated_data_scaled = generator(noise)
# 将生成的数据从GPU移到CPU,并转换为numpy数组
generated_data_scaled_np = generated_data_scaled.cpu().numpy()
# 逆向转换回原始尺度
generated_data = scaler.inverse_transform(generated_data_scaled_np)
real_data_original_scale = scaler.inverse_transform(X_scaled)
# 可视化对比
fig, axes = plt.subplots(4, 4, figsize=(12, 10))
fig.suptitle('真实数据 vs. GAN生成数据 的特征分布对比 (PyTorch)', fontsize=16)
# feature_names = data.feature_names
# feature_names = data.columns
feature_names = X.columns # 直接从预处理后的数据获取列名
for i in range(13):
ax = axes.flatten()[i]
ax.hist(real_data_original_scale[:, i], bins=10, density=True, alpha=0.6, label='Real Data')
ax.hist(generated_data[:, i], bins=10, density=True, alpha=0.6, label='Generated Data')
ax.set_title(feature_names[i])
ax.legend()
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
# 将生成的数据与真实数据并排打印出来看看
print("\n前5个真实样本 (Setosa):")
print(pd.DataFrame(real_data_original_scale[:5], columns=feature_names))
print("\nGAN生成的5个新样本:")
print(pd.DataFrame(generated_data[:5], columns=feature_names))
# 将生成的数据从GPU移到CPU,并转换为numpy数组
generated_data_scaled_np = generated_data_scaled.cpu().numpy()
# 逆向转换回原始尺度
generated_data = scaler.inverse_transform(generated_data_scaled_np)
real_data_original_scale = scaler.inverse_transform(X_scaled)
# 将生成的数据转换为 DataFrame
generated_df = pd.DataFrame(generated_data, columns=data.drop('target', axis=1).columns)
# 假设生成的数据目标标签都为 1,可根据实际情况修改
generated_df['target'] = 1
# 合并原始数据和生成的数据
combined_data = pd.concat([data, generated_df], ignore_index=True)
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression #逻辑回归分类器
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
# 使用合并后的数据划分训练集和测试集
x = combined_data.drop(['target'], axis=1)
y = combined_data['target']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 打印训练集和测试集的形状
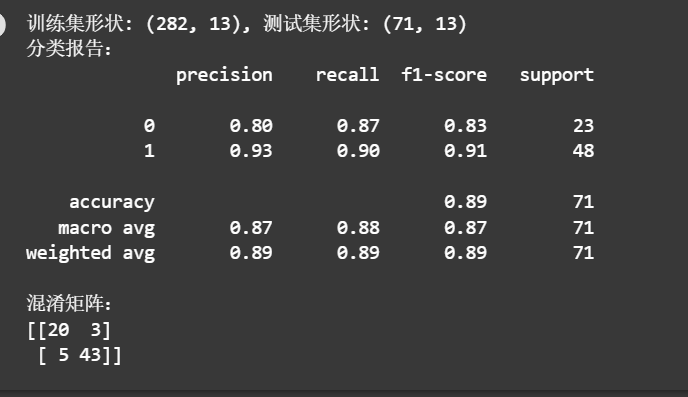
print(f"训练集形状: {x_train.shape}, 测试集形状: {x_test.shape}")
# Logistic Regression
lr_model = LogisticRegression()
lr_model.fit(x_train, y_train)
lr_predictions = lr_model.predict(x_test)
print('分类报告:')
print(classification_report(y_test, lr_predictions))
print('混淆矩阵:')
print(confusion_matrix(y_test, lr_predictions))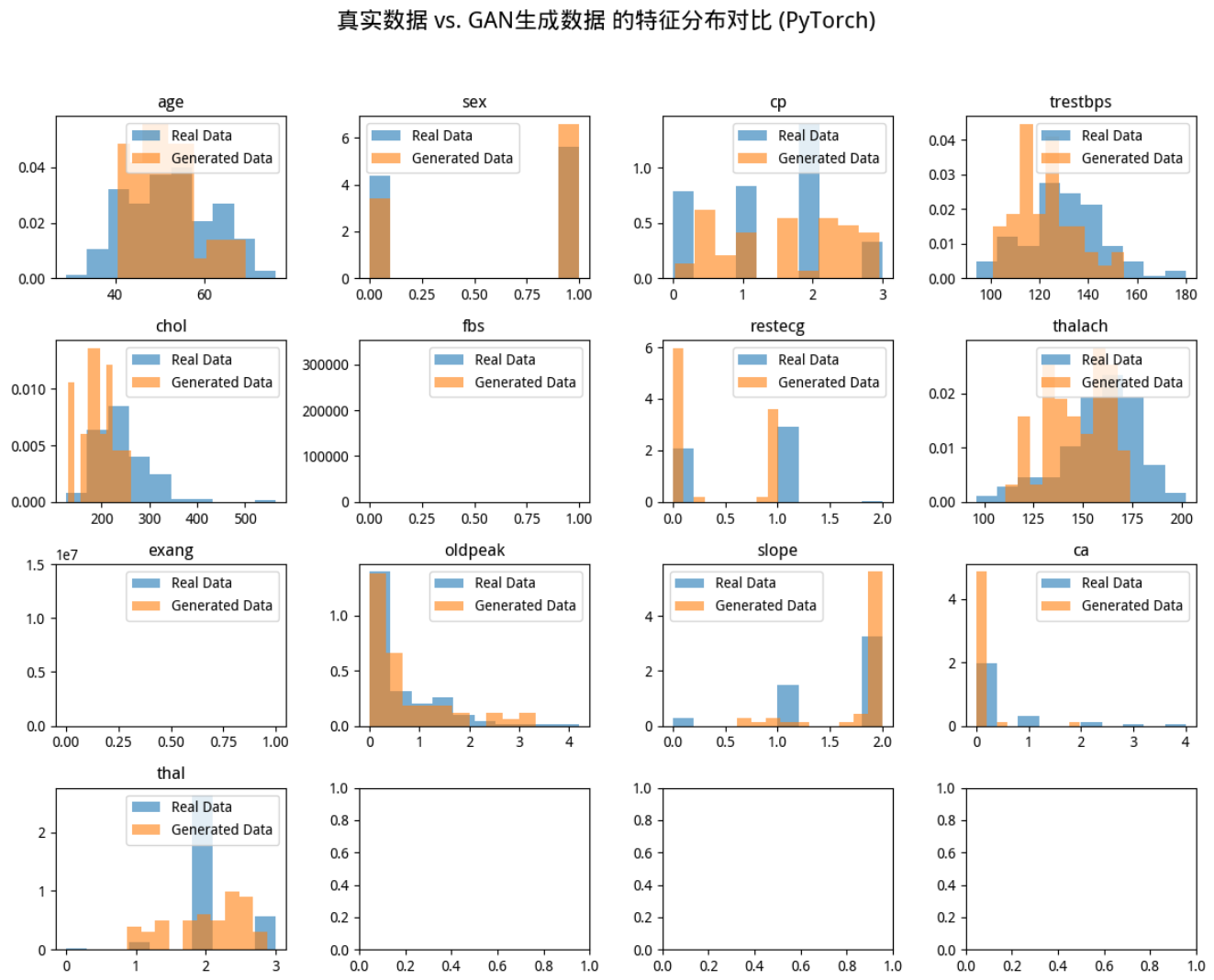
总结对比:
一、样本分布变化的影响(GAN 生成样本的作用)
- 不做处理:原始数据中类别分布天然存在不平衡风险(虽这里差异不算极端,但仍有倾向)。模型直接学习原始分布,对少数类的识别难度更高,F1 分数受类别平衡度影响更明显。
- GAN 生成类别 1 样本(:通过补充类别 1 的样本,调整了训练数据中类别分布,让模型在学习时能更 "公平" 接触两类特征,尤其缓解了类别 1 样本不足导致的学习偏差,提升了对类别 1 的预测稳定性,进而影响 F1 分数。
二、模型学习难度与预测稳定性
- precision(精确率):聚焦 "预测为某类时,实际真的是该类的比例"。GAN 补充样本后,类别 1 的特征多样性增加,模型对类别 1 的预测更 "精准"(第二张图类别 1 precision 0.93 → 第一张图 0.88 ),说明误判为类别 1 的情况减少。
- recall(召回率):关注 "实际为某类的样本中,被模型正确识别的比例"。GAN 补充样本让模型学到更多类别 1 的特征模式,召回率提升(第二张图类别 1 recall 0.90 → 第一张图 0.91 ,虽细微但体现趋势),漏判减少。
- F1 分数:是精确率和召回率的调和平均,对两者的平衡更敏感。GAN 优化后,类别 0 和 1 的 F1 分数差异缩小(第二张图类别 0 0.83、类别 1 0.91 → 第一张图类别 0 0.88、类别 1 0.89 ),整体模型对两类的 "兼顾能力" 更均衡,这是数据分布优化带来的直接结果。
简单总结:GAN 通过补充类别 1 样本,优化了数据分布,让模型对两类的预测更均衡、精准,最终体现为 F1 分数的差异 ------ 尤其让类别 1 的 F1 更稳定,整体模型的 "综合识别能力" 更优 。本质是 "数据分布→模型学习→指标表现" 的链式影响,GAN 在 "数据分布" 环节做了优化,进而传导到下游指标。