文章目录
- [Week 24: 深度学习补遗:Vision Transformer (ViT) 复现](#Week 24: 深度学习补遗:Vision Transformer (ViT) 复现)
-
- 摘要
- Abstract
- [1. Patch Embedding](#1. Patch Embedding)
-
- [1.1 概要](#1.1 概要)
- [1.2 代码实现](#1.2 代码实现)
- [1.3 效果分析](#1.3 效果分析)
- [2. ViT Embedding](#2. ViT Embedding)
-
- [2.1 概要](#2.1 概要)
- [2.2 代码实现](#2.2 代码实现)
- [2.3 效果分析](#2.3 效果分析)
- [3. Vision Transformer 网络架构设计](#3. Vision Transformer 网络架构设计)
-
- [3.1 概要](#3.1 概要)
- [3.2 代码实现](#3.2 代码实现)
- [3.3 网络结构设计特点](#3.3 网络结构设计特点)
- 总结
Week 24: 深度学习补遗:Vision Transformer (ViT) 复现
摘要
本周对经典的ViT论文进行了复现,对于其Patch Embedding的相关理念进行了较为深入的理解。通过利用上周编写的Transformer模块进行快速复现,提高复现效率并且深入理解了ViT对Transformer的应用以及异同。
Abstract
This week involved reproducing the seminal ViT paper, gaining a deeper understanding of its Patch Embedding concepts. By leveraging the Transformer module developed last week for rapid implementation, we enhanced reproduction efficiency while gaining insight into ViT's application of the Transformer architecture and its key distinctions.
1. Patch Embedding
1.1 概要
将输入图像 x ∈ R B × C × H × W x\in\mathbb{R}^{B\times C\times H\times W} x∈RB×C×H×W 划分为大小为 p × p p\times p p×p 的非重叠 patch,并将每个 patch 投影到 d d d 维 embedding 空间,得到序列输入供 Transformer 使用。易知,patch 数量为 N = ( H p ) ⋅ ( W p ) N = \left(\frac{H}{p}\right)\cdot\left(\frac{W}{p}\right) N=(pH)⋅(pW)。单个 patch 投影每个 patch 的映射等价于 ( C , p , p ) ⟶ ( embed_dim , 1 , 1 ) (C,p,p)\longrightarrow(\text{embed\_dim},1,1) (C,p,p)⟶(embed_dim,1,1)。例如,对于 C = 3 , p = 16 , embed_dim = 768 C=3, p=16, \text{embed\_dim} =768 C=3,p=16,embed_dim=768,则单个 patch 从 (3,16,16) 映射到了 映射到了 映射到了(768,1,1)。
整张图的输出形状变化就是 ( B , C , H , W ) → patch_embed ( B , embed_dim , H p , W p ) . (B,C,H,W)\xrightarrow{\text{patch\_embed}}(B,\text{embed\_dim},\frac{H}{p},\frac{W}{p}). (B,C,H,W)patch_embed (B,embed_dim,pH,pW).
在实际操作中,使用步幅为 p p p、核为 p p p 的 2D 卷积等价于对每个 p × p p\times p p×p patch 进行共享线性映射,这样计算高效且便于硬件加速。
1.2 代码实现
python
# PatchEmbedding:将图像分块并线性投影
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.n_patches = (img_size // patch_size) ** 2
# 使用卷积层进行patch embedding
self.patch_embed = nn.Conv2d(
in_channels, embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x):
# x shape: (batch_size, in_channels, img_size, img_size)
x = self.patch_embed(x) # (batch_size, embed_dim, H/p, W/p)
x = x.flatten(2) # (batch_size, embed_dim, n_patches)
x = x.transpose(1, 2) # (batch_size, n_patches, embed_dim)
return x1.3 效果分析
patch_size 越小, N N N 增大,会令Transformer 的自注意力复杂度 O ( N 2 d ) O(N^2d) O(N2d)上升,需要折中选择。
2. ViT Embedding
2.1 概要
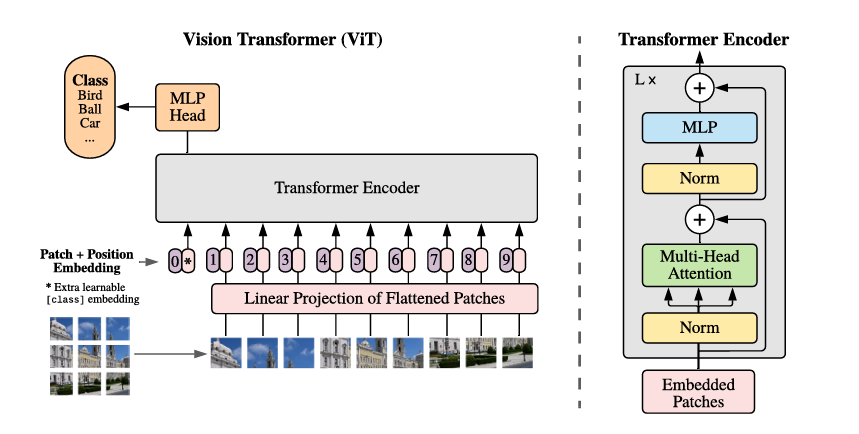
根据原论文,线性映射之后的Patches拼接上一个CLS token再加上位置信息(Positional Encoding),使模型既能聚合全局信息又保留位置信息。拼接 CLS token, X ′ = cls ; X patches ∈ R B × ( N + 1 ) × d X' = \\text{cls};\\; X_{\\text{patches}}\in\mathbb{R}^{B\times (N+1)\times d} X′=cls;Xpatches∈RB×(N+1)×d
2.2 代码实现
python
class ViTEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768, dropout=0.1):
super().__init__()
self.patch_embedding = PatchEmbedding(img_size, patch_size, in_channels, embed_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# 使用transformer模块中的PositionalEncoding
self.pos_encoding = PositionalEncoding(embed_dim, max_len=(img_size // patch_size) ** 2 + 1)
self.dropout = nn.Dropout(dropout)
# 初始化cls_token
nn.init.trunc_normal_(self.cls_token, std=0.02)
def forward(self, x):
batch_size = x.shape[0]
x = self.patch_embedding(x) # (batch_size, n_patches, embed_dim)
cls_tokens = self.cls_token.expand(batch_size, -1, -1) # (batch_size, 1, embed_dim)
x = torch.cat([cls_tokens, x], dim=1) # (batch_size, n_patches+1, embed_dim)
x = self.pos_encoding(x)
x = self.dropout(x)
return x2.3 效果分析
CLS token 提供单向聚合表示,适合分类任务;后续线性头读取 x : , 0 x:,0 x:,0 作为分类向量,CLS token通过注意力机制与全局交互,嵌入全局信息。
3. Vision Transformer 网络架构设计
3.1 概要
Vision Transformer (ViT) 的网络架构设计的核心在于将传统CNN的局部卷积操作替换为Transformer的全局自注意力机制。其网络结构可以表述为:
ViT ( X ) = ClassificationHead ( LayerNorm ( TransformerEncoder ( ViTEmbedding ( X ) ) ) ) 其中: X ∈ R B × C × H × W ViTEmbedding : R B × C × H × W → R B × ( N + 1 ) × D TransformerEncoder : R B × ( N + 1 ) × D → R B × ( N + 1 ) × D ClassificationHead : R D → R K \begin{aligned} \text{ViT}(X) &= \text{ClassificationHead}(\text{LayerNorm}(\text{TransformerEncoder}(\text{ViTEmbedding}(X)))) \\ \text{其中: } & X \in \mathbb{R}^{B \times C \times H \times W} \\ & \text{ViTEmbedding}: \mathbb{R}^{B \times C \times H \times W} \rightarrow \mathbb{R}^{B \times (N+1) \times D} \\ & \text{TransformerEncoder}: \mathbb{R}^{B \times (N+1) \times D} \rightarrow \mathbb{R}^{B \times (N+1) \times D} \\ & \text{ClassificationHead}: \mathbb{R}^{D} \rightarrow \mathbb{R}^{K} \end{aligned} ViT(X)其中: =ClassificationHead(LayerNorm(TransformerEncoder(ViTEmbedding(X))))X∈RB×C×H×WViTEmbedding:RB×C×H×W→RB×(N+1)×DTransformerEncoder:RB×(N+1)×D→RB×(N+1)×DClassificationHead:RD→RK
其中 N = H × W P 2 N = \frac{H \times W}{P^2} N=P2H×W 为patch数量, P P P 为patch大小, D D D 为嵌入维度, K K K 为类别数。这种设计通过分层的信息处理,实现了从局部像素到全局语义的逐步抽象。
3.2 代码实现
python
class VisionTransformer(nn.Module):
def __init__(self,
img_size=224,
patch_size=16,
in_channels=3,
embed_dim=768,
num_layers=12,
num_heads=12,
mlp_ratio=4,
num_classes=1000,
dropout=0.1):
super().__init__()
# 第一层:图像嵌入 - 将2D图像转换为1D序列
self.embedding = ViTEmbedding(img_size, patch_size, in_channels, embed_dim, dropout)
# 第二层:Transformer编码器栈 - 多层自注意力处理
hidden_dim = embed_dim * mlp_ratio
self.encoder_layers = nn.ModuleList([
EncoderLayer(embed_dim, num_heads, hidden_dim, dropout)
for _ in range(num_layers)
])
# 第三层:分类头 - 基于CLS token的最终预测
self.norm = LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes)
# 权重初始化策略
self.apply(self._init_weights)
def _init_weights(self, m):
"""专门针对ViT的权重初始化策略"""
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02) # 截断正态分布
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
# 阶段1:图像序列化嵌入 (B, C, H, W) -> (B, N+1, D)
x = self.embedding(x) # 包含CLS token和位置编码
# 阶段2:深度Transformer编码 (B, N+1, D) -> (B, N+1, D)
for layer in self.encoder_layers:
x = layer(x) # 每层包含自注意力和前馈网络
# 阶段3:最终归一化与分类 (B, N+1, D) -> (B, K)
x = self.norm(x)
cls_token = x[:, 0] # 提取CLS token用于分类
logits = self.head(cls_token)
return logits3.3 网络结构设计特点
ViT采用了清晰的三层式设计:嵌入层-编码层-分类层,每层职责明确:
- 嵌入层:负责视觉到序列的转换,是ViT区别于CNN的关键
- 编码层:复用标准Transformer编码器,实现深度特征提取
- 分类层:基于CLS token的全局信息聚合进行最终决策
与CNN使用全局池化不同,ViT采用CLS token作为分类的载体:
python
cls_token = x[:, 0] # 提取第一个token
logits = self.head(cls_token) # 直接用于分类这种设计允许模型通过自注意力机制动态学习哪些patch对分类最重要,实现了自适应的特征聚合。
总结
本周对ViT论文进行了快速复现,灵活运用了上周编写的Transformer代码,对Positional Encoding部分和EncoderLayer部分进行了复用,大大提高了论文的复现速度。同时通过对CLS_Token和Patch Embedding的构建,了解了在ViT中的整个Embedding流程,理解了ViT中的核心思想以及构建的逻辑。